LECTURE 8. Pipelining: Datapath and Control
|
|
|
- Willa Garrett
- 5 years ago
- Views:
Transcription
1 LECTURE 8 Pipelining: Datapath and Control
2 PIPELINED DATAPATH As with the single-cycle and multi-cycle implementations, we will start by looking at the datapath for pipelining. We already know that pipelining involves breaking up instructions into five stages: IF Instruction Fetch ID Instruction Decode EX Execution MEM Memory Access WB Write Back We will start by taking a look at the single-cycle datapath, divided into stages.
3 PIPELINED DATAPATH
4 PIPELINED DATAPATH As we can see, each of the steps maps nicely in order onto the single-cycle datapath. Instruction fields and data generally move from left-to-right as they progress through each stage. The two exceptions are: The WB stage places the result back into the register file in the middle of the datapath à leads to data hazards. The selection of the next value of the PC either the incremented PC or the branch address à leads to control hazards.
5 PIPELINED DATAPATH One way to visualize pipelining is to consider the execution of each instruction independently, as if it has the datapath all to itself. We can place these datapaths on a timeline to see their relationship. The stages are represented by the datapath element being used, shaded according to use.
6 PIPELINED DATAPATH In reality, these instructions are not executing in their own datapaths, they share a datapath. The first instruction uses instruction memory in its IF stage in cycle 1. Then, in cycle 2, the second instruction uses instruction memory for its own IF stage. For this to work, we need to add registers to store data between cycles.
7 PIPELINED DATAPATH
8 PIPELINED DATAPATH The previous slide shows the addition of pipeline registers (in blue) which are used to hold data between cycles. Following our laundry analogy, these might be like baskets between the washer, dryer, etc that hold a clothing load between steps. During each cycle, an instruction advances from one pipeline register to the next pipeline register. Note that the registers are labeled by the stages that they separate. Pipeline registers are as wide as necessary to hold all of the data passed into them. For instance, IF/ID is 64 bits wide because it must hold a 32-bit instruction and a 32-bit PC+4 result.
9 PIPELINED DATAPATH FOR LOAD WORD Let s walk through the datapath using the load word instruction as an example. Load word is a good instruction to start with because it is active in every stage of the pipelined datapath. Note that in the following datapaths, the right half of registers or memory are shaded when they are being read. The left half is shaded when they are being written. lw $rt, immed($rs) opcode rs rt immed The load word instruction adds immed to the contents of $rs to obtain the address in memory whose contents are written to $rt.
10 PIPELINED DATAPATH FOR LOAD WORD Instruction Fetch (IF) The instruction is read from memory using the contents of PC and placed in the IF/ID register. The PC address is incremented by 4 and written back to the PC register, as well as placed in the IF/ID register in case the instruction needs it later. Note: the datapath does not know that we are performing a load word at this point so it forwards the PC+4 value just in case.
11 PIPELINED DATAPATH FOR LOAD WORD: IF
12 PIPELINED DATAPATH FOR LOAD WORD Instruction Decode and Register File Read (ID): The registers $rs and $rt are read from the register file and stored in the ID/EX pipeline register. Remember, we don t know what the instruction is yet. The 16-bit immediate field is sign-extended to 32-bits and stored in the ID/EX pipeline register. The PC+4 value is copied from the IF/ID register into the ID/EX register in case the instruction needs it later.
13 PIPELINED DATAPATH FOR LOAD WORD: ID
14 PIPELINED DATAPATH FOR LOAD WORD Execute or Address Calculation (EX): From the ID/EX pipeline register, take the contents of $rs and the sign-extended immediate field as inputs to the ALU, which performs an add operation. The sum is placed in the EX/MEM pipeline register.
15 PIPELINED DATAPATH FOR LOAD WORD: EX
16 PIPELINED DATAPATH FOR LOAD WORD Memory Access (MEM): Take the address stored in the EX/MEM pipeline register and use it to access data memory. The data read from memory is stored in the MEM/WB pipeline register.
17 PIPELINED DATAPATH FOR LOAD WORD: MEM
18 PIPELINED DATAPATH FOR LOAD WORD Write Back (WB): Read the data from the MEM/WB register and write it back to the register file in the middle of the datapath.
19 PIPELINED DATAPATH FOR LOAD WORD: WB
20 PIPELINED DATAPATH FOR LOAD WORD It s important to note that any information we need will have to be passed from pipeline register to pipeline register while instruction executes. Because the instructions share the elements, we cannot assume anything from a previous cycle is still there. We must carry the data with us as we move along the data path. So by now you should be wondering about the last step. How does the WB stage know which register to write to? The IF/ID pipeline register should no longer contain the necessary instruction field it s already been overwritten by three other instructions at this point. We ll see the solution soon, but let s look at store word first.
21 PIPELINED DATAPATH FOR STORE WORD The IF and ID stages are identical for all instructions. At these stages of execution, we still do not know which instruction we are actually executing so we perform general operations that either apply to all instructions or may speculatively apply to a select few instructions.
22 PIPELINED DATAPATH FOR STORE WORD: IF
23 PIPELINED DATAPATH FOR STORE WORD: ID
24 PIPELINED DATAPATH FOR STORE WORD Execute or Address Calculation (EX): From the ID/EX pipeline register, take the contents of $rs and the sign-extended immediate field as inputs to the ALU, which performs an add operation. The sum is placed in the EX/MEM pipeline register. The contents of the $rt register are copied from the ID/EX pipeline register to the EX/MEM pipeline register.
25 PIPELINED DATAPATH FOR STORE WORD: EX
26 PIPELINED DATAPATH FOR STORE WORD Memory Access (MEM): Take the address stored in the EX/MEM pipeline register and use it to access data memory. Take the contents of $rt from the EX/MEM pipeline and write it to data memory at the address specified. Note that in order to use the $rt field in the MEM stage, we have to carry it with us from the ID stage. This means copying it in every pipeline register until we use it.
27 PIPELINED DATAPATH FOR STORE WORD: MEM
28 PIPELINED DATAPATH FOR STORE WORD Write Back (WB): We re already done with the store word instruction so we don t have to do anything.
29 PIPELINED DATAPATH FOR STORE WORD: WB
30 PIPELINED DATAPATH In both the load and store word datapaths, we can notice another important point: every datapath element is used in only one pipeline stage. If this wasn t the case, we d create a structural hazard. Let s say we used the ALU from the EX stage to both increment PC in the IF stage and perform operations in the EX stage. This is fine for a single instruction, but what happens if we re executing multiple instructions and one is currently in the IF stage and another is in the EX stage? Which one gets to use the ALU? Clearly, we d have an issue. So, we add redundancy to our datapath in order to gain the speed improvements from pipelining.
31 PIPELINED DATAPATH FOR LOAD WORD Ok, so let s look back at load word s WB stage. Remember that we have a problem? We don t know to which register we need to write back. What s the solution?
32 PIPELINED DATAPATH FOR LOAD WORD: WB
33 PIPELINED DATAPATH FOR LOAD WORD Ok, so let s look back at load word s WB stage. Remember that we have a problem? We don t know to which register we need to write back. What s the solution? That s right! Carry the information through each stage using the pipeline registers. To do this, we ll modify the datapath a little bit. Now, we ll pass the write register number from the MEM/WB pipeline register along with the data. This register number is initially discovered in the ID stage and must be passed through the pipeline registers until we need it in the WB stage.
34 PIPELINED DATAPATH FOR LOAD WORD: WB
35 PIPELINED DATAPATH Consider the 5 instruction sequence below. lw $10, 20($1) sub $11, $2, $3 add $12, $3, $4 lw $13, 24($1) add $14, $5, $6 First, take note of the fact that we have no data hazards since no instruction depends on data from a previous instruction. We also have no control hazards since we are not branching or jumping. So, we can safely pipeline without stalls.
36 PIPELINED DATAPATH We can start by diagramming the individual datapaths used by every instruction This allows us to see which stage each instruction is executing in a given clock cycle.
37 PIPELINED DATAPATH We can also chart the stages themselves rather than the elements being used in the cycle
38 PIPELINED DATAPATH On the next slide, we show a single datapath as it is being used by the 5 instructions at once. The cycle depicted is cycle 5. In this cycle, the first load word is executing its WB stage while the last add instruction is executing its IF stage.
39 PIPELINED DATAPATH
40 PIPELINED DATAPATH
41 PIPELINED DATAPATH In the following slides, we walk through all 9 cycles required to fully complete the 5 instructions in our sample sequence. We will start with clock cycle 1 and highlight the relevant datapath lines according to the instruction being executed in each particular stage.
42 PIPELINED DATAPATH lw $10, 20($1) Cycle 1
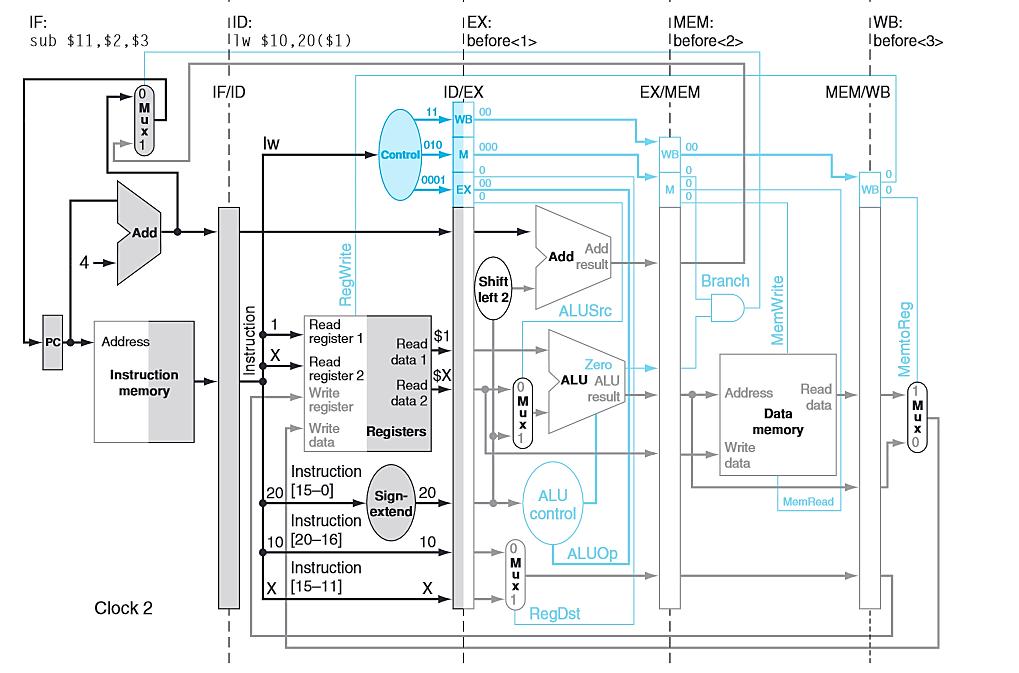
43 PIPELINED DATAPATH sub $11,$2,$3 lw $10, 20($1) Cycle 2
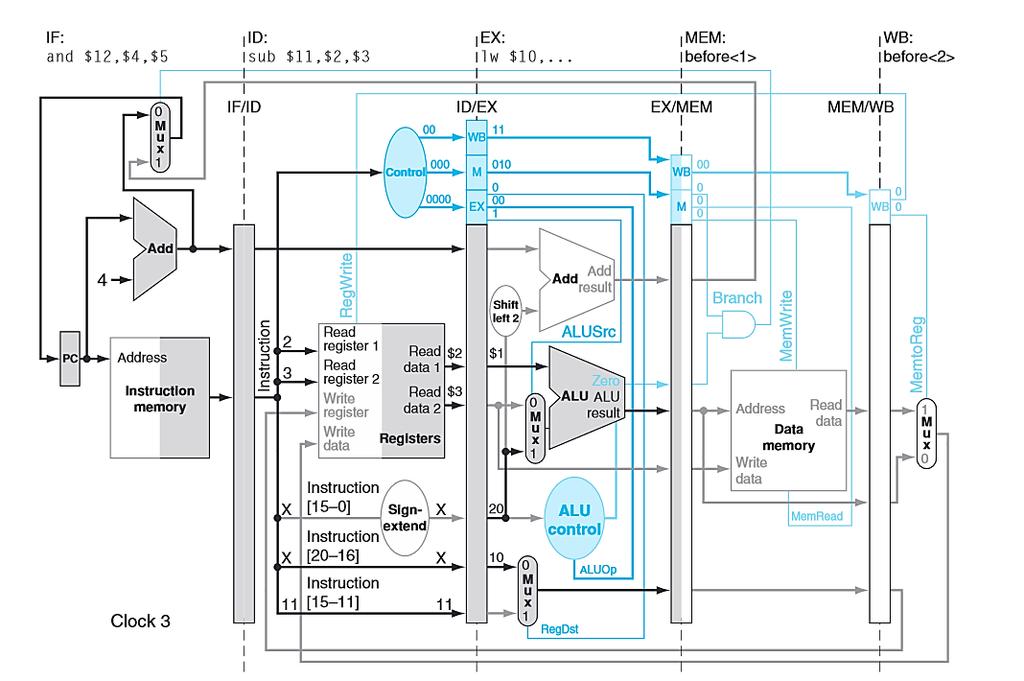
44 PIPELINED DATAPATH add $12,$3,$4 sub $11,$2,$3 lw $10, 20($1) Cycle 3
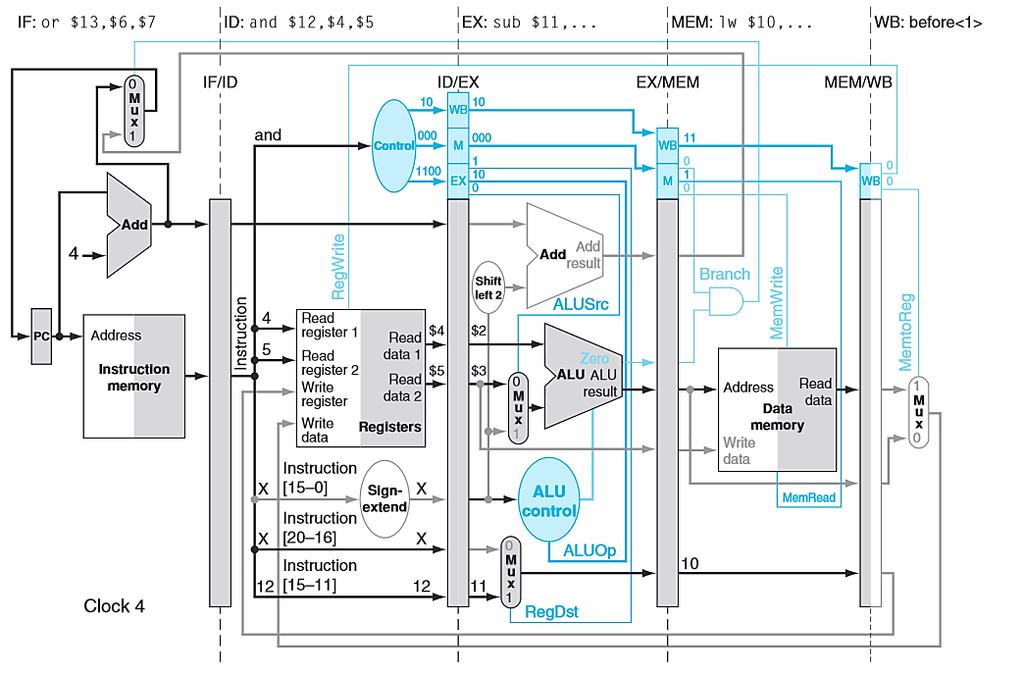
45 PIPELINED DATAPATH lw $13, 24($1) add $12,$3,$4 sub $11,$2,$3 lw $10, 20($1) Cycle 4
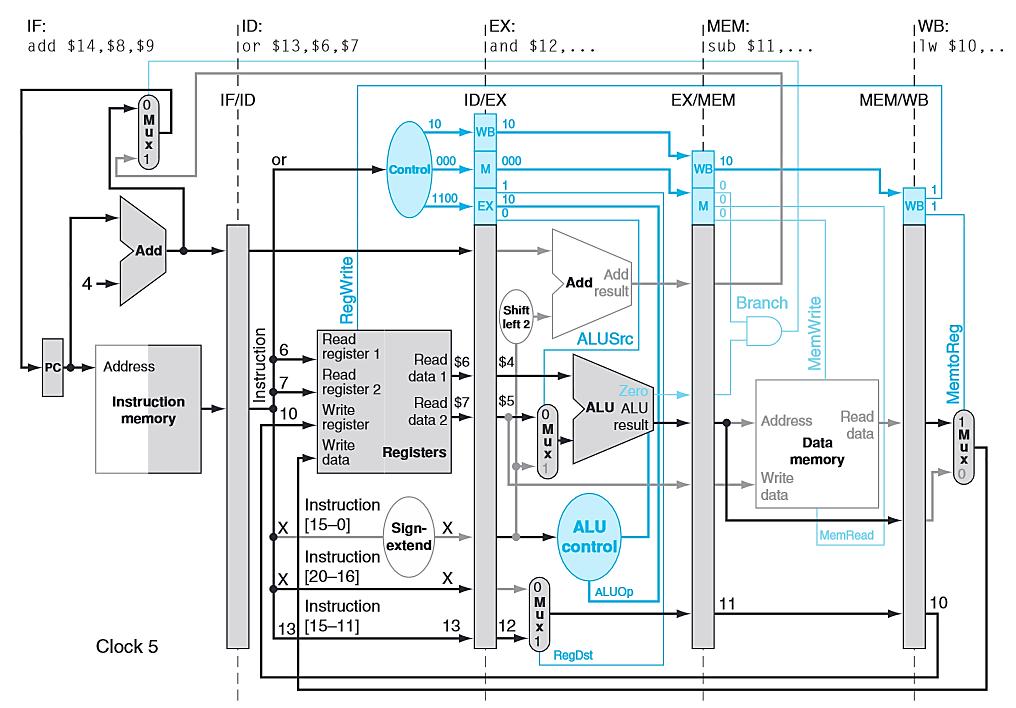
46 PIPELINED DATAPATH add $14,$5,$6 lw $13, 24($1) add $12,$3,$4 sub $11,$2,$3 lw $10, 20($1) Cycle 5
47 PIPELINED DATAPATH add $14,$5,$6 lw $13, 24($1) add $12,$3,$4 sub $11,$2,$3 Cycle 6
48 PIPELINED DATAPATH add $14,$5,$6 lw $13, 24($1) add $12,$3,$4 Cycle 7
49 PIPELINED DATAPATH add $14,$5,$6 lw $13, 24($1) Cycle 8
50 PIPELINED DATAPATH add $14,$5,$6 Cycle 9
51 PIPELINED CONTROL Now, let s add control to our pipelined datapath. We ll start with a simple control scheme and deal with pipeline hazards later. A lot of the control logic is borrowed from the single-cycle and multi-cycle implementations.
52 PIPELINED CONTROL
53 PIPELINED CONTROL Let s remind ourselves of the roles of these control lines. Opcode ALU op Operation Funct ALU action ALU Control Input lw 00 Load word N/A add 0010 sw 00 Store word N/A add 0010 beq 01 Branch equal N/A subtract 0110 R-type 10 Add add 0010 R-type 10 Subtract subtract 0110 R-type 10 AND AND 0000 R-type 10 OR OR 0001 R-type 10 Set on less than slt 0111
54 PIPELINED CONTROL 1-Bit Signal Name Effect When Deasserted Effect When Asserted RegDst The register file destination number for the Write register comes from the rt field. The register file destination number for the Write register comes from the rd field. RegWrite None Write register is written with the value of the Write data input. ALUSrc The first ALU operand is Read Data 2. The first ALU operand is sign-ext immediate field. PCSrc PC is replaced by PC+4. PC is replaced by branch target. MemRead None Content of memory at the location specified by the Address input is put on the Memory data output. MemWrite None The Write Data input is written to the Address input. MemtoReg The value fed to the register file is from the ALU. The value fed to the register file input comes from Memory.
55 PIPELINED CONTROL Let s remind ourselves of the roles of these control lines. Notice now that we re grouping the control lines based on their relevant stage. EX MEM WB Instr. RegDst ALUOp 1 ALUOp2 ALUSrc Branch MemRead MemWrite RegWrite MemToReg R lw sw X X beq X X
56 PIPELINED CONTROL Unlike the multi-cycle implementation, we assume that the PC is written on every clock cycle so there is no explicit control signal for writing PC. We also assume that the pipeline registers are written on every clock cycle. As we just saw in the previous slide, we can handle controlling 5 instructions at once by dividing the control signals into 5 groups one for each pipeline stage.
57 PIPELINED CONTROL: IF The only relevant control signals in this stage are the control signals to read instruction memory and write to PC. These control signals are always asserted however so we don t need to worry about them.
58 PIPELINED CONTROL: ID As in the previous stage, the same actions take place during every cycle so we do not have to be concerned with any optional control lines. Notice the RegWrite signal physically resides in this component of the datapath but it is a control line of the WB stage.
59 PIPELINE CONTROL: EX The relevant control signals in this stage are: RegDst ALUOp ALUSrc
60 PIPELINE CONTROL: MEM The relevant control signals in this stage are: Branch MemRead MemWrite PCSrc is also computed in this stage but it is a product of two other control signals, so we don t worry about it when designing our Control unit.
61 PIPELINE CONTROL: WB The relevant control signals in this stage are: MemtoReg RegWrite Note that RegWrite is our one exception. It actually appears in ID s phase of the pipeline but it is a control signal for the WB stage.
62 PIPELINED CONTROL As before, we need to preserve the context of an instruction as it moves through the datapath. We cannot reach back in the datapath for some information about how to execute the instruction it will have already been overwritten.
63 PIPELINED CONTROL We must pass along the control line values for the last 3 stages. Remember, the first 2 stages are universal. For example, the RegWrite and MemtoReg values, decoded after the second stage, must be passed through the EX and MEM stages to the WB stage.
64 PIPELINED CONTROL Our pipeline registers have been extended to handle the control information as well.
65
66 PIPELINED CONTROL Consider the following instructions. lw $10, 20($1) sub $11, $2, $3 and $12, $4, $5 or $13, $6, $7 add $14, $8, $9 Let s examine, in all the detail, how these simple instructions are executed in a pipelined datapath. Note again that we have no control or data hazards. Each slide following will show the datapath state in a subsequent clock cycle.
67
68
69
70
71
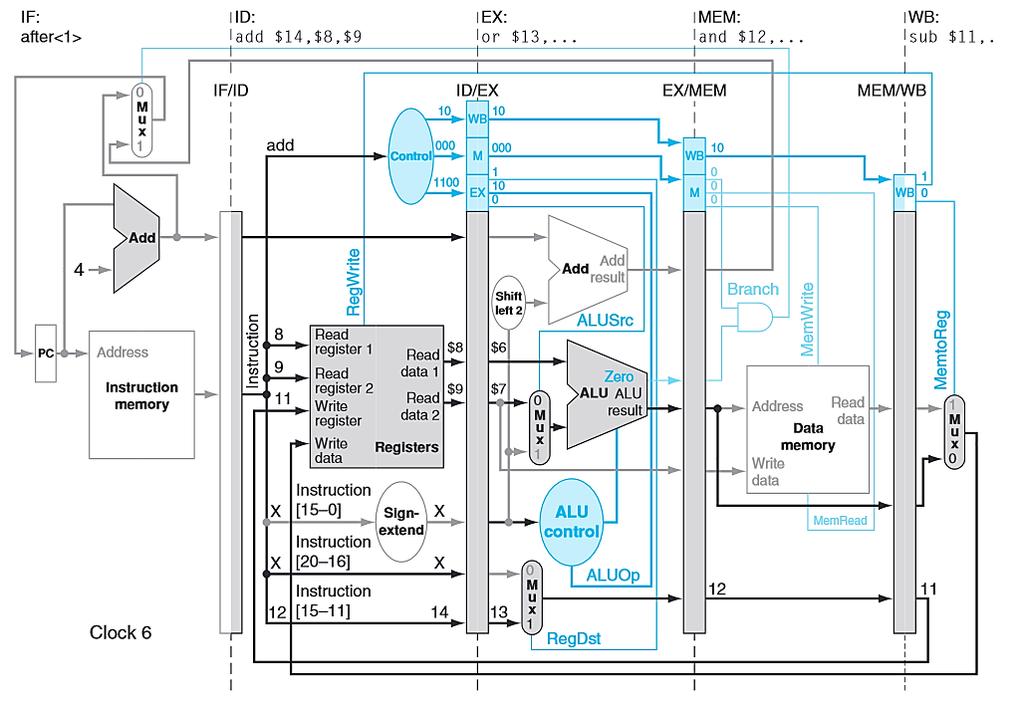
72
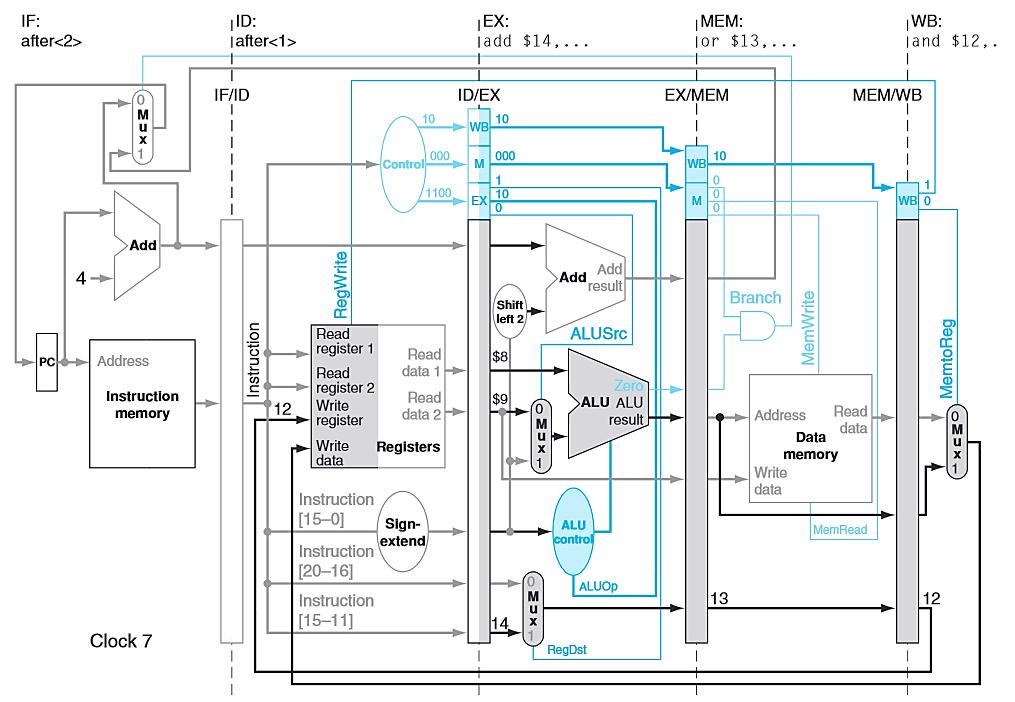
73
74
75
RISC Design: Pipelining
 RISC Design: Pipelining Virendra Singh Associate Professor Computer Architecture and Dependable Systems Lab Department of Electrical Engineering Indian Institute of Technology Bombay http://www.ee.iitb.ac.in/~viren/
RISC Design: Pipelining Virendra Singh Associate Professor Computer Architecture and Dependable Systems Lab Department of Electrical Engineering Indian Institute of Technology Bombay http://www.ee.iitb.ac.in/~viren/
Selected Solutions to Problem-Set #3 COE 608: Computer Organization and Architecture Single Cycle Datapath and Control
 Selected Solutions to Problem-Set #3 COE 608: Computer Organization and Architecture Single Cycle Datapath and Control 4.1. Done in the class 4.2. Try it yourself Q4.3. 4.3.1 a. Logic Only b. Logic Only
Selected Solutions to Problem-Set #3 COE 608: Computer Organization and Architecture Single Cycle Datapath and Control 4.1. Done in the class 4.2. Try it yourself Q4.3. 4.3.1 a. Logic Only b. Logic Only
Computer Architecture
 Computer Architecture An Introduction Virendra Singh Associate Professor Computer Architecture and Dependable Systems Lab Department of Electrical Engineering Indian Institute of Technology Bombay http://www.ee.iitb.ac.in/~viren/
Computer Architecture An Introduction Virendra Singh Associate Professor Computer Architecture and Dependable Systems Lab Department of Electrical Engineering Indian Institute of Technology Bombay http://www.ee.iitb.ac.in/~viren/
7/19/2012. IF for Load (Review) CSE 2021: Computer Organization. EX for Load (Review) ID for Load (Review) WB for Load (Review) MEM for Load (Review)
 CSE 2021: Computer Organization. EX for Load (Review) ID for Load (Review) WB for Load (Review) MEM for Load (Review)") CSE 2021: Computer Organization IF for Load (Review) Lecture-11 CPU Design : Pipelining-2 Review, Hazards Shakil M. Khan CSE-2021 July-19-2012 2 ID for Load (Review) EX for Load (Review) CSE-2021 July-19-2012
CSE 2021: Computer Organization IF for Load (Review) Lecture-11 CPU Design : Pipelining-2 Review, Hazards Shakil M. Khan CSE-2021 July-19-2012 2 ID for Load (Review) EX for Load (Review) CSE-2021 July-19-2012
CSE 2021: Computer Organization
 CSE 2021: Computer Organization Lecture-11 CPU Design : Pipelining-2 Review, Hazards Shakil M. Khan IF for Load (Review) CSE-2021 July-14-2011 2 ID for Load (Review) CSE-2021 July-14-2011 3 EX for Load
CSE 2021: Computer Organization Lecture-11 CPU Design : Pipelining-2 Review, Hazards Shakil M. Khan IF for Load (Review) CSE-2021 July-14-2011 2 ID for Load (Review) CSE-2021 July-14-2011 3 EX for Load
Pipelining A B C D. Readings: Example: Doing the laundry. Ann, Brian, Cathy, & Dave. each have one load of clothes to wash, dry, and fold
 Pipelining Readings: 4.5-4.8 Example: Doing the laundry Ann, Brian, Cathy, & Dave A B C D each have one load of clothes to wash, dry, and fold Washer takes 30 minutes Dryer takes 40 minutes Folder takes
Pipelining Readings: 4.5-4.8 Example: Doing the laundry Ann, Brian, Cathy, & Dave A B C D each have one load of clothes to wash, dry, and fold Washer takes 30 minutes Dryer takes 40 minutes Folder takes
A B C D. Ann, Brian, Cathy, & Dave each have one load of clothes to wash, dry, and fold. Time
 Pipelining Readings: 4.5-4.8 Example: Doing the laundry A B C D Ann, Brian, Cathy, & Dave each have one load of clothes to wash, dry, and fold Washer takes 30 minutes Dryer takes 40 minutes Folder takes
Pipelining Readings: 4.5-4.8 Example: Doing the laundry A B C D Ann, Brian, Cathy, & Dave each have one load of clothes to wash, dry, and fold Washer takes 30 minutes Dryer takes 40 minutes Folder takes
CSEN 601: Computer System Architecture Summer 2014
 CSEN 601: Cmputer System Architecture Summer 2014 Practice Assignment 7 Slutin Exercise 7-1: Based n the MIPS pipeline implementatin yu studied, what are the cntrl signals that have t be stred in the ID/EX
CSEN 601: Cmputer System Architecture Summer 2014 Practice Assignment 7 Slutin Exercise 7-1: Based n the MIPS pipeline implementatin yu studied, what are the cntrl signals that have t be stred in the ID/EX
Chapter 4. Pipelining Analogy. The Processor. Pipelined laundry: overlapping execution. Parallelism improves performance. Four loads: Non-stop:
 Chapter 4 The Processor Part II Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup p = 2n/(0.5n + 1.5) 4 =
Chapter 4 The Processor Part II Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup p = 2n/(0.5n + 1.5) 4 =
7/11/2012. Single Cycle (Review) CSE 2021: Computer Organization. Multi-Cycle Implementation. Single Cycle with Jump. Pipelining Analogy
 CSE 2021: Computer Organization. Multi-Cycle Implementation. Single Cycle with Jump. Pipelining Analogy") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10 CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan CSE-2021 July-12-2012 2 Single Cycle with Jump Multi-Cycle Implementation
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10 CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan CSE-2021 July-12-2012 2 Single Cycle with Jump Multi-Cycle Implementation
Lecture 4: Introduction to Pipelining
 Lecture 4: Introduction to Pipelining Pipelining Laundry Example Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, and fold Washer takes 30 minutes A B C D Dryer takes 40 minutes Folder
Lecture 4: Introduction to Pipelining Pipelining Laundry Example Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, and fold Washer takes 30 minutes A B C D Dryer takes 40 minutes Folder
Lecture Topics. Announcements. Today: Pipelined Processors (P&H ) Next: continued. Milestone #4 (due 2/23) Milestone #5 (due 3/2)
 Next: continued. Milestone #4 (due 2/23) Milestone #5 (due 3/2)") Lecture Topics Today: Pipelined Processors (P&H 4.5-4.10) Next: continued 1 Announcements Milestone #4 (due 2/23) Milestone #5 (due 3/2) 2 1 ISA Implementations Three different strategies: single-cycle
Lecture Topics Today: Pipelined Processors (P&H 4.5-4.10) Next: continued 1 Announcements Milestone #4 (due 2/23) Milestone #5 (due 3/2) 2 1 ISA Implementations Three different strategies: single-cycle
EECE 321: Computer Organiza5on
 EECE 321: Computer Organiza5on Mohammad M. Mansour Dept. of Electrical and Compute Engineering American University of Beirut Lecture 21: Pipelining Processor Pipelining Same principles can be applied to
EECE 321: Computer Organiza5on Mohammad M. Mansour Dept. of Electrical and Compute Engineering American University of Beirut Lecture 21: Pipelining Processor Pipelining Same principles can be applied to
CS 110 Computer Architecture Lecture 11: Pipelining
 CS 110 Computer Architecture Lecture 11: Pipelining Instructor: Sören Schwertfeger http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on
CS 110 Computer Architecture Lecture 11: Pipelining Instructor: Sören Schwertfeger http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on
Pipelined Processor Design
 Pipelined Processor Design COE 38 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Pipelining versus Serial
Pipelined Processor Design COE 38 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Pipelining versus Serial
IF ID EX MEM WB 400 ps 225 ps 350 ps 450 ps 300 ps
 CSE 30321 Computer Architecture I Fall 2010 Homework 06 Pipelined Processors 85 points Assigned: November 2, 2010 Due: November 9, 2010 PLEASE DO THE ASSIGNMENT ON THIS HANDOUT!!! Problem 1: (25 points)
CSE 30321 Computer Architecture I Fall 2010 Homework 06 Pipelined Processors 85 points Assigned: November 2, 2010 Due: November 9, 2010 PLEASE DO THE ASSIGNMENT ON THIS HANDOUT!!! Problem 1: (25 points)
IF ID EX MEM WB 400 ps 225 ps 350 ps 450 ps 300 ps
 CSE 30321 Computer Architecture I Fall 2011 Homework 06 Pipelined Processors 75 points Assigned: November 1, 2011 Due: November 8, 2011 PLEASE DO THE ASSIGNMENT ON THIS HANDOUT!!! Problem 1: (15 points)
CSE 30321 Computer Architecture I Fall 2011 Homework 06 Pipelined Processors 75 points Assigned: November 1, 2011 Due: November 8, 2011 PLEASE DO THE ASSIGNMENT ON THIS HANDOUT!!! Problem 1: (15 points)
EE 457 Homework 5 Redekopp Name: Score: / 100_
 EE 457 Homework 5 Redekopp Name: Score: / 100_ Single-Cycle CPU The following exercises are taken from Hennessy and Patterson, CO&D 2 nd, 3 rd, and 4 th Ed. 1.) (6 pts.) Review your class notes. a. Is
EE 457 Homework 5 Redekopp Name: Score: / 100_ Single-Cycle CPU The following exercises are taken from Hennessy and Patterson, CO&D 2 nd, 3 rd, and 4 th Ed. 1.) (6 pts.) Review your class notes. a. Is
6.S084 Tutorial Problems L19 Control Hazards in Pipelined Processors
 6.S084 Tutorial Problems L19 Control Hazards in Pipelined Processors Options for dealing with data and control hazards: stall, bypass, speculate 6.S084 Worksheet - 1 of 10 - L19 Control Hazards in Pipelined
6.S084 Tutorial Problems L19 Control Hazards in Pipelined Processors Options for dealing with data and control hazards: stall, bypass, speculate 6.S084 Worksheet - 1 of 10 - L19 Control Hazards in Pipelined
CMSC 611: Advanced Computer Architecture
 CMSC 611: Advanced Computer Architecture Pipelining Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science
CMSC 611: Advanced Computer Architecture Pipelining Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science
EECS150 - Digital Design Lecture 2 - Synchronous Digital Systems Review Part 1. Outline
 EECS5 - Digital Design Lecture 2 - Synchronous Digital Systems Review Part January 2, 2 John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www-inst.eecs.berkeley.edu/~cs5
EECS5 - Digital Design Lecture 2 - Synchronous Digital Systems Review Part January 2, 2 John Wawrzynek Electrical Engineering and Computer Sciences University of California, Berkeley http://www-inst.eecs.berkeley.edu/~cs5
You are Here! Processor Design Process. Agenda. Agenda 10/25/12. CS 61C: Great Ideas in Computer Architecture Single Cycle MIPS CPU Part II
 /26/2 CS 6C: Great Ideas in Computer Architecture Single Cycle MIPS CPU Part II /25/2 ructors: Krste Asanovic, Randy H. Katz hcp://inst.eecs.berkeley.edu/~cs6c/fa2 Fall 22 - - Lecture #26 Parallel Requests
/26/2 CS 6C: Great Ideas in Computer Architecture Single Cycle MIPS CPU Part II /25/2 ructors: Krste Asanovic, Randy H. Katz hcp://inst.eecs.berkeley.edu/~cs6c/fa2 Fall 22 - - Lecture #26 Parallel Requests
Suggested Readings! Lecture 12" Introduction to Pipelining! Example: We have to build x cars...! ...Each car takes 6 steps to build...! ! Readings!
 1! CSE 30321 Lecture 12 Introduction to Pipelining! CSE 30321 Lecture 12 Introduction to Pipelining! 2! Suggested Readings!! Readings!! H&P: Chapter 4.5-4.7!! (Over the next 3-4 lectures)! Lecture 12"
1! CSE 30321 Lecture 12 Introduction to Pipelining! CSE 30321 Lecture 12 Introduction to Pipelining! 2! Suggested Readings!! Readings!! H&P: Chapter 4.5-4.7!! (Over the next 3-4 lectures)! Lecture 12"
CS420/520 Computer Architecture I
 CS42/52 Computer rchitecture I Designing a Pipeline Processor (C4: ppendix ) Dr. Xiaobo Zhou Department of Computer Science CS42/52 pipeline. UC. Colorado Springs dapted from UCB97 & UCB3 Branch Jump Recap:
CS42/52 Computer rchitecture I Designing a Pipeline Processor (C4: ppendix ) Dr. Xiaobo Zhou Department of Computer Science CS42/52 pipeline. UC. Colorado Springs dapted from UCB97 & UCB3 Branch Jump Recap:
ECE473 Computer Architecture and Organization. Pipeline: Introduction
 Computer Architecture and Organization Pipeline: Introduction Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 11.1 The Laundry Analogy Student A,
Computer Architecture and Organization Pipeline: Introduction Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 11.1 The Laundry Analogy Student A,
Single-Cycle CPU The following exercises are taken from Hennessy and Patterson, CO&D 2 nd, 3 rd, and 4 th Ed.
 EE 357 Homework 7 Redekopp Name: Lec: 9:30 / 11:00 Score: Submit answers via Blackboard for all problems except 5.) and 6.). For those questions, submit a hardcopy with your answers, diagrams, circuit
EE 357 Homework 7 Redekopp Name: Lec: 9:30 / 11:00 Score: Submit answers via Blackboard for all problems except 5.) and 6.). For those questions, submit a hardcopy with your answers, diagrams, circuit
Instruction Level Parallelism. Data Dependence Static Scheduling
 Instruction Level Parallelism Data Dependence Static Scheduling Basic Block A straight line code sequence with no branches in except to the entry and no branches out except at the exit Loop: L.D ADD.D
Instruction Level Parallelism Data Dependence Static Scheduling Basic Block A straight line code sequence with no branches in except to the entry and no branches out except at the exit Loop: L.D ADD.D
Asanovic/Devadas Spring Pipeline Hazards. Krste Asanovic Laboratory for Computer Science M.I.T.
 Pipeline Hazards Krste Asanovic Laboratory for Computer Science M.I.T. Pipelined DLX Datapath without interlocks and jumps 31 0x4 RegDst RegWrite inst Inst rs1 rs2 rd1 ws wd rd2 GPRs Imm Ext A B OpSel
Pipeline Hazards Krste Asanovic Laboratory for Computer Science M.I.T. Pipelined DLX Datapath without interlocks and jumps 31 0x4 RegDst RegWrite inst Inst rs1 rs2 rd1 ws wd rd2 GPRs Imm Ext A B OpSel
RISC Central Processing Unit
 RISC Central Processing Unit Lan-Da Van ( 范倫達 ), Ph. D. Department of Computer Science National Chiao Tung University Taiwan, R.O.C. Spring, 2014 ldvan@cs.nctu.edu.tw http://www.cs.nctu.edu.tw/~ldvan/
RISC Central Processing Unit Lan-Da Van ( 范倫達 ), Ph. D. Department of Computer Science National Chiao Tung University Taiwan, R.O.C. Spring, 2014 ldvan@cs.nctu.edu.tw http://www.cs.nctu.edu.tw/~ldvan/
FMP For More Practice
 FP 6.-6 For ore Practice Labeling Pipeline Diagrams with 6.5 [2] < 6.3> To understand how pipeline works, let s consider these five instructions going through the pipeline: lw $, 2($) sub $, $2, $3 and
FP 6.-6 For ore Practice Labeling Pipeline Diagrams with 6.5 [2] < 6.3> To understand how pipeline works, let s consider these five instructions going through the pipeline: lw $, 2($) sub $, $2, $3 and
CZ3001 ADVANCED COMPUTER ARCHITECTURE
 CZ3001 ADVANCED COMPUTER ARCHITECTURE Lab 3 Report Abstract Pipelining is a process in which successive steps of an instruction sequence are executed in turn by a sequence of modules able to operate concurrently,
CZ3001 ADVANCED COMPUTER ARCHITECTURE Lab 3 Report Abstract Pipelining is a process in which successive steps of an instruction sequence are executed in turn by a sequence of modules able to operate concurrently,
Computer Hardware. Pipeline
 Computer Hardware Pipeline Conventional Datapath 2.4 ns is required to perform a single operation (i.e. 416.7 MHz). Register file MUX B 0.6 ns Clock 0.6 ns 0.2 ns Function unit 0.8 ns MUX D 0.2 ns c. Production
Computer Hardware Pipeline Conventional Datapath 2.4 ns is required to perform a single operation (i.e. 416.7 MHz). Register file MUX B 0.6 ns Clock 0.6 ns 0.2 ns Function unit 0.8 ns MUX D 0.2 ns c. Production
Computer Science 246. Advanced Computer Architecture. Spring 2010 Harvard University. Instructor: Prof. David Brooks
 Advanced Computer Architecture Spring 2010 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture Outline Instruction-Level Parallelism Scoreboarding (A.8) Instruction Level Parallelism
Advanced Computer Architecture Spring 2010 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture Outline Instruction-Level Parallelism Scoreboarding (A.8) Instruction Level Parallelism
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science !!! Basic MIPS integer pipeline Branches with one
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science !!! Basic MIPS integer pipeline Branches with one
CMP 301B Computer Architecture. Appendix C
 CMP 301B Computer Architecture Appendix C Dealing with Exceptions What should be done when an exception arises and many instructions are in the pipeline??!! Force a trap instruction in the next IF stage
CMP 301B Computer Architecture Appendix C Dealing with Exceptions What should be done when an exception arises and many instructions are in the pipeline??!! Force a trap instruction in the next IF stage
Dynamic Scheduling I
 basic pipeline started with single, in-order issue, single-cycle operations have extended this basic pipeline with multi-cycle operations multiple issue (superscalar) now: dynamic scheduling (out-of-order
basic pipeline started with single, in-order issue, single-cycle operations have extended this basic pipeline with multi-cycle operations multiple issue (superscalar) now: dynamic scheduling (out-of-order
CS521 CSE IITG 11/23/2012
 Parallel Decoding and issue Parallel execution Preserving the sequential consistency of execution and exception processing 1 slide 2 Decode/issue data Issue bound fetch Dispatch bound fetch RS RS RS RS
Parallel Decoding and issue Parallel execution Preserving the sequential consistency of execution and exception processing 1 slide 2 Decode/issue data Issue bound fetch Dispatch bound fetch RS RS RS RS
ECE 2300 Digital Logic & Computer Organization. More Pipelined Microprocessor
 ECE 2300 Digital ogic & Computer Organization Spring 2018 ore Pipelined icroprocessor ecture 18: 1 nnouncements No instructor office hour today Rescheduled to onday pril 16, 4:00-5:30pm Prelim 2 review
ECE 2300 Digital ogic & Computer Organization Spring 2018 ore Pipelined icroprocessor ecture 18: 1 nnouncements No instructor office hour today Rescheduled to onday pril 16, 4:00-5:30pm Prelim 2 review
CS 61C: Great Ideas in Computer Architecture. Pipelining Hazards. Instructor: Senior Lecturer SOE Dan Garcia
 CS 61C: Geat Ideas in Compute Achitectue Pipelining Hazads Instucto: Senio Lectue SOE Dan Gacia 1 Geat Idea #4: Paallelism So9wae Paallel Requests Assigned to compute e.g. seach Gacia Paallel Theads Assigned
CS 61C: Geat Ideas in Compute Achitectue Pipelining Hazads Instucto: Senio Lectue SOE Dan Gacia 1 Geat Idea #4: Paallelism So9wae Paallel Requests Assigned to compute e.g. seach Gacia Paallel Theads Assigned
Embedded Hardware (1) Kai Huang
 Kai Huang") Ebedded Hardware () Kai Hang News: PS4 and Xbo One are Coing /9/203 kai.hang@t 2 The Hardware Xbo One PS4 CPU PS4 /9/203 kai.hang@t 3 Xbo One sei-csto 86 AMD APU 28n 8-core Jagar CPU CPU freqency.6 GHz.75
Ebedded Hardware () Kai Hang News: PS4 and Xbo One are Coing /9/203 kai.hang@t 2 The Hardware Xbo One PS4 CPU PS4 /9/203 kai.hang@t 3 Xbo One sei-csto 86 AMD APU 28n 8-core Jagar CPU CPU freqency.6 GHz.75
Pipelined Architecture (2A) Young Won Lim 4/10/18
 Young Won Lim 4/10/18") Pipelined Architecture (2A) Copyright (c) 2014-2018 Young W. Lim. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2
Pipelined Architecture (2A) Copyright (c) 2014-2018 Young W. Lim. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2
Pipelined Architecture (2A) Young Won Lim 4/7/18
 Young Won Lim 4/7/18") Pipelined Architecture (2A) Copyright (c) 2014-2018 Young W. Lim. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2
Pipelined Architecture (2A) Copyright (c) 2014-2018 Young W. Lim. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2
EN164: Design of Computing Systems Lecture 22: Processor / ILP 3
 EN164: Design of Computing Systems Lecture 22: Processor / ILP 3 Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
EN164: Design of Computing Systems Lecture 22: Processor / ILP 3 Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
Pipelining and ISA Design
 Pipelined instuc.on Execu.on 1 Pipelining and ISA Design MIPS Instuc:on Set designed fo pipelining All instuc:ons ae 32- bits Easie to fetch and decode in one cycle x86: 1- to 17- byte instuc:ons (x86
Pipelined instuc.on Execu.on 1 Pipelining and ISA Design MIPS Instuc:on Set designed fo pipelining All instuc:ons ae 32- bits Easie to fetch and decode in one cycle x86: 1- to 17- byte instuc:ons (x86
Chapter 16 - Instruction-Level Parallelism and Superscalar Processors
 Chapter 16 - Instruction-Level Parallelism and Superscalar Processors Luis Tarrataca luis.tarrataca@gmail.com CEFET-RJ L. Tarrataca Chapter 16 - Superscalar Processors 1 / 78 Table of Contents I 1 Overview
Chapter 16 - Instruction-Level Parallelism and Superscalar Processors Luis Tarrataca luis.tarrataca@gmail.com CEFET-RJ L. Tarrataca Chapter 16 - Superscalar Processors 1 / 78 Table of Contents I 1 Overview
CS61C : Machine Structures
 Election Data is now available Puple Ameica! inst.eecs.bekeley.edu/~cs61c CS61C : Machine Stuctues Lectue 31 Pipelined Execution, pat II 2004-11-10 Lectue PSOE Dan Gacia www.cs.bekeley.edu/~ddgacia The
Election Data is now available Puple Ameica! inst.eecs.bekeley.edu/~cs61c CS61C : Machine Stuctues Lectue 31 Pipelined Execution, pat II 2004-11-10 Lectue PSOE Dan Gacia www.cs.bekeley.edu/~ddgacia The
COSC4201. Scoreboard
 COSC4201 Scoreboard Prof. Mokhtar Aboelaze York University Based on Slides by Prof. L. Bhuyan (UCR) Prof. M. Shaaban (RIT) 1 Overcoming Data Hazards with Dynamic Scheduling In the pipeline, if there is
COSC4201 Scoreboard Prof. Mokhtar Aboelaze York University Based on Slides by Prof. L. Bhuyan (UCR) Prof. M. Shaaban (RIT) 1 Overcoming Data Hazards with Dynamic Scheduling In the pipeline, if there is
Pipelined Beta. Handouts: Lecture Slides. Where are the registers? Spring /10/01. L16 Pipelined Beta 1
 Pipelined Beta Where are the registers? Handouts: Lecture Slides L16 Pipelined Beta 1 Increasing CPU Performance MIPS = Freq CPI MIPS = Millions of Instructions/Second Freq = Clock Frequency, MHz CPI =
Pipelined Beta Where are the registers? Handouts: Lecture Slides L16 Pipelined Beta 1 Increasing CPU Performance MIPS = Freq CPI MIPS = Millions of Instructions/Second Freq = Clock Frequency, MHz CPI =
Computer Elements and Datapath. Microarchitecture Implementation of an ISA
 6.823, L5--1 Computer Elements and atapath Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 status lines Microarchitecture Implementation of an ISA ler control points 6.823, L5--2
6.823, L5--1 Computer Elements and atapath Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 status lines Microarchitecture Implementation of an ISA ler control points 6.823, L5--2
Understanding Engineers #2
 Understanding Engineers #! The graduate with a Science degree asks, "Why does it work?"! The graduate with an Engineering degree asks, "How does it work?"! The graduate with an Accounting degree asks,
Understanding Engineers #! The graduate with a Science degree asks, "Why does it work?"! The graduate with an Engineering degree asks, "How does it work?"! The graduate with an Accounting degree asks,
Instruction Level Parallelism Part II - Scoreboard
 Course on: Advanced Computer Architectures Instruction Level Parallelism Part II - Scoreboard Prof. Cristina Silvano Politecnico di Milano email: cristina.silvano@polimi.it 1 Basic Assumptions We consider
Course on: Advanced Computer Architectures Instruction Level Parallelism Part II - Scoreboard Prof. Cristina Silvano Politecnico di Milano email: cristina.silvano@polimi.it 1 Basic Assumptions We consider
Project 5: Optimizer Jason Ansel
 Project 5: Optimizer Jason Ansel Overview Project guidelines Benchmarking Library OoO CPUs Project Guidelines Use optimizations from lectures as your arsenal If you decide to implement one, look at Whale
Project 5: Optimizer Jason Ansel Overview Project guidelines Benchmarking Library OoO CPUs Project Guidelines Use optimizations from lectures as your arsenal If you decide to implement one, look at Whale
Parallel architectures Electronic Computers LM
 Parallel architectures Electronic Computers LM 1 Architecture Architecture: functional behaviour of a computer. For instance a processor which executes DLX code Implementation: a logical network implementing
Parallel architectures Electronic Computers LM 1 Architecture Architecture: functional behaviour of a computer. For instance a processor which executes DLX code Implementation: a logical network implementing
CS429: Computer Organization and Architecture
 CS429: Computer Organization and Architecture Dr. Bill Young Department of Computer Sciences University of Texas at Austin Last updated: November 8, 2017 at 09:27 CS429 Slideset 14: 1 Overview What s wrong
CS429: Computer Organization and Architecture Dr. Bill Young Department of Computer Sciences University of Texas at Austin Last updated: November 8, 2017 at 09:27 CS429 Slideset 14: 1 Overview What s wrong
EECS 470. Tomasulo s Algorithm. Lecture 4 Winter 2018
 omasulo s Algorithm Winter 2018 Slides developed in part by Profs. Austin, Brehob, Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, yson, Vijaykumar, and Wenisch of Carnegie Mellon University,
omasulo s Algorithm Winter 2018 Slides developed in part by Profs. Austin, Brehob, Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, yson, Vijaykumar, and Wenisch of Carnegie Mellon University,
EECS 470 Lecture 5. Intro to Dynamic Scheduling (Scoreboarding) Fall 2018 Jon Beaumont
 Fall 2018 Jon Beaumont") Intro to Dynamic Scheduling (Scoreboarding) Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Many thanks to Prof. Martin and Roth of University of Pennsylvania for most of these slides.
Intro to Dynamic Scheduling (Scoreboarding) Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Many thanks to Prof. Martin and Roth of University of Pennsylvania for most of these slides.
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Out-of-Order Execution and Register Rename In Search of Parallelism rivial Parallelism is limited What is trivial parallelism? In-order: sequential instructions do not have
CSE 502: Computer Architecture Out-of-Order Execution and Register Rename In Search of Parallelism rivial Parallelism is limited What is trivial parallelism? In-order: sequential instructions do not have
Computer Architecture and Organization:
 Computer Architecture and Organization: L03: Register transfer and System Bus By: A. H. Abdul Hafez Abdul.hafez@hku.edu.tr, ah.abdulhafez@gmail.com 1 CAO, by Dr. A.H. Abdul Hafez, CE Dept. HKU Outlines
Computer Architecture and Organization: L03: Register transfer and System Bus By: A. H. Abdul Hafez Abdul.hafez@hku.edu.tr, ah.abdulhafez@gmail.com 1 CAO, by Dr. A.H. Abdul Hafez, CE Dept. HKU Outlines
ICS312 Machine-level and Systems Programming
 Computer Architecture and Programming: Examples and Sample Problems ICS312 Machine-level and Systems Programming Henri Casanova (henric@hawaii.edu) 0000 1100 Somehow, the is initialized to some content,
Computer Architecture and Programming: Examples and Sample Problems ICS312 Machine-level and Systems Programming Henri Casanova (henric@hawaii.edu) 0000 1100 Somehow, the is initialized to some content,
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Out-of-Order Execution and Register Rename In Search of Parallelism rivial Parallelism is limited What is trivial parallelism? In-order: sequential instructions do not have
CSE 502: Computer Architecture Out-of-Order Execution and Register Rename In Search of Parallelism rivial Parallelism is limited What is trivial parallelism? In-order: sequential instructions do not have
Out-of-Order Execution. Register Renaming. Nima Honarmand
 Out-of-Order Execution & Register Renaming Nima Honarmand Out-of-Order (OOO) Execution (1) Essence of OOO execution is Dynamic Scheduling Dynamic scheduling: processor hardware determines instruction execution
Out-of-Order Execution & Register Renaming Nima Honarmand Out-of-Order (OOO) Execution (1) Essence of OOO execution is Dynamic Scheduling Dynamic scheduling: processor hardware determines instruction execution
EECS 470 Lecture 4. Pipelining & Hazards II. Winter Prof. Ronald Dreslinski h8p://
 Wenisch 26 -- Portions ustin, Brehob, Falsafi, Hill, Hoe, ipasti, artin, Roth, Shen, Smith, Sohi, Tyson, Vijaykumar EECS 4 ecture 4 Pipelining & Hazards II Winter 29 GS STTION Prof. Ronald Dreslinski h8p://www.eecs.umich.edu/courses/eecs4
Wenisch 26 -- Portions ustin, Brehob, Falsafi, Hill, Hoe, ipasti, artin, Roth, Shen, Smith, Sohi, Tyson, Vijaykumar EECS 4 ecture 4 Pipelining & Hazards II Winter 29 GS STTION Prof. Ronald Dreslinski h8p://www.eecs.umich.edu/courses/eecs4
CISC 662 Graduate Computer Architecture. Lecture 9 - Scoreboard
 CISC 662 Graduate Computer Architecture Lecture 9 - Scoreboard Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture tes from John Hennessy and David Patterson s: Computer
CISC 662 Graduate Computer Architecture Lecture 9 - Scoreboard Michela Taufer http://www.cis.udel.edu/~taufer/teaching/cis662f07 Powerpoint Lecture tes from John Hennessy and David Patterson s: Computer
OOO Execution & Precise State MIPS R10000 (R10K)
") OOO Execution & Precise State in MIPS R10000 (R10K) Nima Honarmand CDB. CDB.V Spring 2018 :: CSE 502 he Problem with P6 Map able + Regfile value R value Head Retire Dispatch op RS 1 2 V1 FU V2 ail Dispatch
OOO Execution & Precise State in MIPS R10000 (R10K) Nima Honarmand CDB. CDB.V Spring 2018 :: CSE 502 he Problem with P6 Map able + Regfile value R value Head Retire Dispatch op RS 1 2 V1 FU V2 ail Dispatch
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Speculation and raps in Out-of-Order Cores What is wrong with omasulo s? Branch instructions Need branch prediction to guess what to fetch next Need speculative execution
CSE 502: Computer Architecture Speculation and raps in Out-of-Order Cores What is wrong with omasulo s? Branch instructions Need branch prediction to guess what to fetch next Need speculative execution
On the Rules of Low-Power Design
 On the Rules of Low-Power Design (and Why You Should Break Them) Prof. Todd Austin University of Michigan austin@umich.edu A long time ago, in a not so far away place The Rules of Low-Power Design P =
On the Rules of Low-Power Design (and Why You Should Break Them) Prof. Todd Austin University of Michigan austin@umich.edu A long time ago, in a not so far away place The Rules of Low-Power Design P =
Topics. Low Power Techniques. Based on Penn State CSE477 Lecture Notes 2002 M.J. Irwin and adapted from Digital Integrated Circuits 2002 J.
 Topics Low Power Techniques Based on Penn State CSE477 Lecture Notes 2002 M.J. Irwin and adapted from Digital Integrated Circuits 2002 J. Rabaey Review: Energy & Power Equations E = C L V 2 DD P 0 1 +
Topics Low Power Techniques Based on Penn State CSE477 Lecture Notes 2002 M.J. Irwin and adapted from Digital Integrated Circuits 2002 J. Rabaey Review: Energy & Power Equations E = C L V 2 DD P 0 1 +
Digital Integrated CircuitDesign
 Digital Integrated CircuitDesign Lecture 13 Building Blocks (Multipliers) Register Adder Shift Register Adib Abrishamifar EE Department IUST Acknowledgement This lecture note has been summarized and categorized
Digital Integrated CircuitDesign Lecture 13 Building Blocks (Multipliers) Register Adder Shift Register Adib Abrishamifar EE Department IUST Acknowledgement This lecture note has been summarized and categorized
CS61c: Introduction to Synchronous Digital Systems
 CS61c: Introduction to Synchronous Digital Systems J. Wawrzynek March 4, 2006 Optional Reading: P&H, Appendix B 1 Instruction Set Architecture Among the topics we studied thus far this semester, was the
CS61c: Introduction to Synchronous Digital Systems J. Wawrzynek March 4, 2006 Optional Reading: P&H, Appendix B 1 Instruction Set Architecture Among the topics we studied thus far this semester, was the
Instructor: Dr. Mainak Chaudhuri. Instructor: Dr. S. K. Aggarwal. Instructor: Dr. Rajat Moona
 NPTEL Online - IIT Kanpur Instructor: Dr. Mainak Chaudhuri Instructor: Dr. S. K. Aggarwal Course Name: Department: Program Optimization for Multi-core Architecture Computer Science and Engineering IIT
NPTEL Online - IIT Kanpur Instructor: Dr. Mainak Chaudhuri Instructor: Dr. S. K. Aggarwal Course Name: Department: Program Optimization for Multi-core Architecture Computer Science and Engineering IIT
Dynamic Scheduling II
 so far: dynamic scheduling (out-of-order execution) Scoreboard omasulo s algorithm register renaming: removing artificial dependences (WAR/WAW) now: out-of-order execution + precise state advanced topic:
so far: dynamic scheduling (out-of-order execution) Scoreboard omasulo s algorithm register renaming: removing artificial dependences (WAR/WAW) now: out-of-order execution + precise state advanced topic:
Problem: hazards delay instruction completion & increase the CPI. Compiler scheduling (static scheduling) reduces impact of hazards
 reduces impact of hazards") Dynamic Scheduling Pipelining: Issue instructions in every cycle (CPI 1) Problem: hazards delay instruction completion & increase the CPI Compiler scheduling (static scheduling) reduces impact of hazards
Dynamic Scheduling Pipelining: Issue instructions in every cycle (CPI 1) Problem: hazards delay instruction completion & increase the CPI Compiler scheduling (static scheduling) reduces impact of hazards
CMSC 611: Advanced Computer Architecture
 CMSC 611: Advanced Compute Achitectue Pipelining Some mateial adapted fom Mohamed Younis, UMBC CMSC 611 Sp 2003 couse slides Some mateial adapted fom Hennessy & Patteson / 2003 Elsevie Science Pipeline
CMSC 611: Advanced Compute Achitectue Pipelining Some mateial adapted fom Mohamed Younis, UMBC CMSC 611 Sp 2003 couse slides Some mateial adapted fom Hennessy & Patteson / 2003 Elsevie Science Pipeline
Registers. CS152 Computer Architecture and Engineering Lecture 3
 CS52 Computer rchitecture and Engineering Lecture 3 Logic Design, Technology, and Delay January 28, 24 John Kubiatowicz (wwwcsberkeleyedu/~kubitron) lecture slides: http://www-insteecsberkeleyedu/~cs52/
CS52 Computer rchitecture and Engineering Lecture 3 Logic Design, Technology, and Delay January 28, 24 John Kubiatowicz (wwwcsberkeleyedu/~kubitron) lecture slides: http://www-insteecsberkeleyedu/~cs52/
CS61C : Machine Structures
 inst.eecs.bekeley.edu/~cs61c CS61C : Machine Stuctues Lectue 29 Intoduction to Pipelined Execution Lectue PSOE Dan Gacia www.cs.bekeley.edu/~ddgacia Bionic Eyes let blind see! Johns Hopkins eseaches have
inst.eecs.bekeley.edu/~cs61c CS61C : Machine Stuctues Lectue 29 Intoduction to Pipelined Execution Lectue PSOE Dan Gacia www.cs.bekeley.edu/~ddgacia Bionic Eyes let blind see! Johns Hopkins eseaches have
EECS 470. Lecture 9. MIPS R10000 Case Study. Fall 2018 Jon Beaumont
 MIPS R10000 Case Study Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Multiprocessor SGI Origin Using MIPS R10K Many thanks to Prof. Martin and Roth of University of Pennsylvania for
MIPS R10000 Case Study Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Multiprocessor SGI Origin Using MIPS R10K Many thanks to Prof. Martin and Roth of University of Pennsylvania for
Instructor: Randy H. Katz hap://inst.eecs.berkeley.edu/~cs61c/fa13. Fall Lecture #20. Warehouse Scale Computer
 CS 61C: Geat Ideas in Compute Achitectue Contol and Pipelining Instucto: Randy H. Katz hap://inst.eecs.bekeley.edu/~cs61c/fa13 11/5/13 Fall 2013 - - Lectue #20 1 So0wae Paallel Requests Assigned to compute
CS 61C: Geat Ideas in Compute Achitectue Contol and Pipelining Instucto: Randy H. Katz hap://inst.eecs.bekeley.edu/~cs61c/fa13 11/5/13 Fall 2013 - - Lectue #20 1 So0wae Paallel Requests Assigned to compute
ECE 4750 Computer Architecture, Fall 2016 T09 Advanced Processors: Superscalar Execution
 ECE 4750 Computer Architecture, Fall 2016 T09 Advanced Processors: Superscalar Execution School of Electrical and Computer Engineering Cornell University revision: 2016-11-28-17-33 1 In-Order Dual-Issue
ECE 4750 Computer Architecture, Fall 2016 T09 Advanced Processors: Superscalar Execution School of Electrical and Computer Engineering Cornell University revision: 2016-11-28-17-33 1 In-Order Dual-Issue
Department Computer Science and Engineering IIT Kanpur
 NPTEL Online - IIT Bombay Course Name Parallel Computer Architecture Department Computer Science and Engineering IIT Kanpur Instructor Dr. Mainak Chaudhuri file:///e /parallel_com_arch/lecture1/main.html[6/13/2012
NPTEL Online - IIT Bombay Course Name Parallel Computer Architecture Department Computer Science and Engineering IIT Kanpur Instructor Dr. Mainak Chaudhuri file:///e /parallel_com_arch/lecture1/main.html[6/13/2012
Basic electronics Prof. T.S. Natarajan Department of Physics Indian Institute of Technology, Madras Lecture- 24
 Basic electronics Prof. T.S. Natarajan Department of Physics Indian Institute of Technology, Madras Lecture- 24 Mathematical operations (Summing Amplifier, The Averager, D/A Converter..) Hello everybody!
Basic electronics Prof. T.S. Natarajan Department of Physics Indian Institute of Technology, Madras Lecture- 24 Mathematical operations (Summing Amplifier, The Averager, D/A Converter..) Hello everybody!
Precise State Recovery. Out-of-Order Pipelines
 Precise State Recovery in Out-of-Order Pipelines Nima Honarmand Recall Our Generic OOO Pipeline Instruction flow (pipeline front-end) is in-order Register and memory execution are OOO And, we need a final
Precise State Recovery in Out-of-Order Pipelines Nima Honarmand Recall Our Generic OOO Pipeline Instruction flow (pipeline front-end) is in-order Register and memory execution are OOO And, we need a final
DELD MODEL ANSWER DEC 2018
 2018 DELD MODEL ANSWER DEC 2018 Q 1. a ) How will you implement Full adder using half-adder? Explain the circuit diagram. [6] An adder is a digital logic circuit in electronics that implements addition
2018 DELD MODEL ANSWER DEC 2018 Q 1. a ) How will you implement Full adder using half-adder? Explain the circuit diagram. [6] An adder is a digital logic circuit in electronics that implements addition
Instruction Level Parallelism III: Dynamic Scheduling
 Instruction Level Parallelism III: Dynamic Scheduling Reading: Appendix A (A-67) H&P Chapter 2 Instruction Level Parallelism III: Dynamic Scheduling 1 his Unit: Dynamic Scheduling Application OS Compiler
Instruction Level Parallelism III: Dynamic Scheduling Reading: Appendix A (A-67) H&P Chapter 2 Instruction Level Parallelism III: Dynamic Scheduling 1 his Unit: Dynamic Scheduling Application OS Compiler
U. Wisconsin CS/ECE 752 Advanced Computer Architecture I
 U. Wisconsin CS/ECE 752 Advanced Computer Architecture I Prof. Karu Sankaralingam Unit 5: Dynamic Scheduling I Slides developed by Amir Roth of University of Pennsylvania with sources that included University
U. Wisconsin CS/ECE 752 Advanced Computer Architecture I Prof. Karu Sankaralingam Unit 5: Dynamic Scheduling I Slides developed by Amir Roth of University of Pennsylvania with sources that included University
First Name: Last Name: Lab Cover Page. Teaching Assistant to whom you are submitting
 Student Information First Name School of Computer Science Faculty of Engineering and Computer Science Last Name Student ID Number Lab Cover Page Please complete all (empty) fields: Course Name: DIGITAL
Student Information First Name School of Computer Science Faculty of Engineering and Computer Science Last Name Student ID Number Lab Cover Page Please complete all (empty) fields: Course Name: DIGITAL
Tomasolu s s Algorithm
 omasolu s s Algorithm Fall 2007 Prof. homas Wenisch http://www.eecs.umich.edu/courses/eecs4 70 Floating Point Buffers (FLB) ag ag ag Storage Bus Floating Point 4 3 Buffers FLB 6 5 5 4 Control 2 1 1 Result
omasolu s s Algorithm Fall 2007 Prof. homas Wenisch http://www.eecs.umich.edu/courses/eecs4 70 Floating Point Buffers (FLB) ag ag ag Storage Bus Floating Point 4 3 Buffers FLB 6 5 5 4 Control 2 1 1 Result
EC4205 Microprocessor and Microcontroller
 EC4205 Microprocessor and Microcontroller Webcast link: https://sites.google.com/a/bitmesra.ac.in/aminulislam/home All announcement made through webpage: check back often Students are welcome outside the
EC4205 Microprocessor and Microcontroller Webcast link: https://sites.google.com/a/bitmesra.ac.in/aminulislam/home All announcement made through webpage: check back often Students are welcome outside the
Computer Architecture ( L), Fall 2017 HW 3: Branch handling and GPU SOLUTIONS
, Fall 2017 HW 3: Branch handling and GPU SOLUTIONS") Computer Architecture (263-2210-00L), Fall 2017 HW 3: Branch handling and GPU SOLUTIONS Instructor: Prof. Onur Mutlu TAs: Hasan Hassan, Arash Tavakkol, Mohammad Sadr, Lois Orosa, Juan Gomez Luna Assigned:
Computer Architecture (263-2210-00L), Fall 2017 HW 3: Branch handling and GPU SOLUTIONS Instructor: Prof. Onur Mutlu TAs: Hasan Hassan, Arash Tavakkol, Mohammad Sadr, Lois Orosa, Juan Gomez Luna Assigned:
EECS 470 Lecture 8. P6 µarchitecture. Fall 2018 Jon Beaumont Core 2 Microarchitecture
 P6 µarchitecture Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Core 2 Microarchitecture Many thanks to Prof. Martin and Roth of University of Pennsylvania for most of these slides. Portions
P6 µarchitecture Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Core 2 Microarchitecture Many thanks to Prof. Martin and Roth of University of Pennsylvania for most of these slides. Portions
DIGITAL UTILITY SUB- SYSTEMS
 DIGITAL UTILITY SUB- SYSTEMS INTRODUCTION... 138 bandpass filters... 138 digital delay... 139 digital divide-by-1, 2, 4, or 8... 140 digital divide-by-2, 3, 4... 140 digital divide-by-4... 141 digital
DIGITAL UTILITY SUB- SYSTEMS INTRODUCTION... 138 bandpass filters... 138 digital delay... 139 digital divide-by-1, 2, 4, or 8... 140 digital divide-by-2, 3, 4... 140 digital divide-by-4... 141 digital
Lesson 7. Digital Signal Processors
 Lesson 7 Digital Signal Processors Instructional Objectives After going through this lesson the student would learn o Architecture of a Real time Signal Processing Platform o Different Errors introduced
Lesson 7 Digital Signal Processors Instructional Objectives After going through this lesson the student would learn o Architecture of a Real time Signal Processing Platform o Different Errors introduced
Disclaimer. Primer. Agenda. previous work at the EIT Department, activities at Ericsson
 Disclaimer Know your Algorithm! Architectural Trade-offs in the Implementation of a Viterbi Decoder This presentation is based on my previous work at the EIT Department, and is not connected to current
Disclaimer Know your Algorithm! Architectural Trade-offs in the Implementation of a Viterbi Decoder This presentation is based on my previous work at the EIT Department, and is not connected to current
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Out-of-Order Schedulers Data-Capture Scheduler Dispatch: read available operands from ARF/ROB, store in scheduler Commit: Missing operands filled in from bypass Issue: When
CSE 502: Computer Architecture Out-of-Order Schedulers Data-Capture Scheduler Dispatch: read available operands from ARF/ROB, store in scheduler Commit: Missing operands filled in from bypass Issue: When
Multiple Predictors: BTB + Branch Direction Predictors
 Constructive Computer Architecture: Branch Prediction: Direction Predictors Arvind Computer Science & Artificial Intelligence Lab. Massachusetts Institute of Technology October 28, 2015 http://csg.csail.mit.edu/6.175
Constructive Computer Architecture: Branch Prediction: Direction Predictors Arvind Computer Science & Artificial Intelligence Lab. Massachusetts Institute of Technology October 28, 2015 http://csg.csail.mit.edu/6.175
This Figure here illustrates the operation for a 2-input OR gate for all four possible input combinations.
 Course: B.Sc. Applied Physical Science (Computer Science) Year & Sem.: IInd Year, Sem - IIIrd Subject: Computer Science Paper No.: IX Paper Title: Computer System Architecture Lecture No.: 5 Lecture Title:
Course: B.Sc. Applied Physical Science (Computer Science) Year & Sem.: IInd Year, Sem - IIIrd Subject: Computer Science Paper No.: IX Paper Title: Computer System Architecture Lecture No.: 5 Lecture Title:
Controller Implementation--Part I. Cascading Edge-triggered Flip-Flops
 Controller Implementation--Part I Alternative controller FSM implementation approaches based on: Classical Moore and Mealy machines Time state: Divide and Counter Jump counters Microprogramming (ROM) based
Controller Implementation--Part I Alternative controller FSM implementation approaches based on: Classical Moore and Mealy machines Time state: Divide and Counter Jump counters Microprogramming (ROM) based
Novel Low-Overhead Operand Isolation Techniques for Low-Power Datapath Synthesis
 Novel Low-Overhead Operand Isolation Techniques for Low-Power Datapath Synthesis N. Banerjee, A. Raychowdhury, S. Bhunia, H. Mahmoodi, and K. Roy School of Electrical and Computer Engineering, Purdue University,
Novel Low-Overhead Operand Isolation Techniques for Low-Power Datapath Synthesis N. Banerjee, A. Raychowdhury, S. Bhunia, H. Mahmoodi, and K. Roy School of Electrical and Computer Engineering, Purdue University,
8 Fraction Book. 8.1 About this part. 8.2 Pieces of Cake. Name 55
 Name 8 Fraction Book 8. About this part This book is intended to be an enjoyable supplement to the standard text and workbook material on fractions. Understanding why the rules are what they are, and why
Name 8 Fraction Book 8. About this part This book is intended to be an enjoyable supplement to the standard text and workbook material on fractions. Understanding why the rules are what they are, and why
Logical Trunked. Radio (LTR) Theory of Operation
 Theory of Operation") Logical Trunked Radio (LTR) Theory of Operation An Introduction to the Logical Trunking Radio Protocol on the Motorola Commercial and Professional Series Radios Contents 1. Introduction...2 1.1 Logical
Logical Trunked Radio (LTR) Theory of Operation An Introduction to the Logical Trunking Radio Protocol on the Motorola Commercial and Professional Series Radios Contents 1. Introduction...2 1.1 Logical
Remember that represents the set of all permutations of {1, 2,... n}
 20180918 Remember that represents the set of all permutations of {1, 2,... n} There are some basic facts about that we need to have in hand: 1. Closure: If and then 2. Associativity: If and and then 3.
20180918 Remember that represents the set of all permutations of {1, 2,... n} There are some basic facts about that we need to have in hand: 1. Closure: If and then 2. Associativity: If and and then 3.