Processors Processing Processors. The meta-lecture
|
|
|
- Shon Gallagher
- 6 years ago
- Views:
Transcription
1 Simulators 5SIA0


2 Processors Processing Processors The meta-lecture
3 Why Simulators? Your Friend Harm
4 Why Simulators? Harm Loves Tractors Harm
5 Why Simulators? The outside world Unfortunately for Harm you need to go outside to drive tractors Harm
6 Why Simulators? The outside world And the outside world is filled with dangers Harm
7 Why Simulators? The outside world And the outside world is filled with dangers Harm Rain!


8 Why Simulators? The outside world And the outside world is filled with dangers Rain! Scary Animals! Harm
9 Why Simulators? Harm
10 Why Simulators? So Harm uses his PC Harm
11 Why Simulators? Harm
12 Why Simulators? Oh No! My PC is too slow to run Farming Simulator Harm
13 Why Simulators? Oh No! My PC is too slow to run Farming Simulator Harm You



14 Why Simulators? Stand back! I m a computer architect! Oh No! My PC is too slow to run Farming Simulator Obligatory cape Harm You
15 How to help Harm? Of course you have many ideas on how to speed-up Harms computer. But which ones should you apply? You
16 Design Space Exploration Options
17 Design Space Exploration Options Buy (or build) all hardware options
18 Design Space Exploration Options Buy (or build) all hardware options Gee that sounds expensive...
19 Design Space Exploration Options Buy (or build) all hardware options Use analytical models
20 Design Space Exploration Options Buy (or build) all hardware options Use analytical models How reliable is that?
21 Design Space Exploration Options Buy (or build) all hardware options Use analytical models Simulate the design points!
22 Design Space Exploration Options Buy (or build) all hardware options Use analytical models Simulate the design points! Hey, I like simulators, That sounds promising :)
23 What to simulate for?
24 What to simulate for? Performance Energy Power (!=Energy) Thermal
25 What to simulate for? Performance Energy Power (!=Energy) Thermal What details to simulate?
26 What to simulate for? Performance Energy Power (!=Energy) Thermal What details to simulate? Cycle accurate vs Functionality Caches Full operating system Disk accesses Background tasks...

27 What to simulate for? Performance Energy Power (!=Energy) Thermal What details to simulate? Cycle accurate vs Functionality Caches Full operating system Disk accesses Background tasks...
28 All the details: RTL Simulation
29 All the details: RTL Simulation Simulate at gate level:
30 All the details: RTL Simulation Simulate at gate level: - modelsim/questasim (Mentor) ncsim (Cadence) VCS (Synopsys) Icarus Verilog (Open Source!)...
31 All the details: RTL Simulation Simulate at gate level: - modelsim/questasim (Mentor) ncsim (Cadence) VCS (Synopsys) Icarus Verilog (Open Source!)... Advantages: - - No need to build a custom simulator if you need RTL to build hardware anyway Highest level of precision and detail
32 All the details: RTL Simulation Simulate at gate level: - modelsim/questasim (Mentor) ncsim (Cadence) VCS (Synopsys) Icarus Verilog (Open Source!)... Advantages: - - No need to build a custom simulator if you need RTL to build hardware anyway Highest level of precision and detail Disadvantage: - Horribly slow for realistic designs
33 All the details: RTL Simulation Simulate at gate level: - modelsim/questasim (Mentor) ncsim (Cadence) VCS (Synopsys) Icarus Verilog (Open Source!)... Advantages: - - No need to build a custom simulator if you need RTL to build hardware anyway Highest level of precision and detail Disadvantage: Nvidia GPU with > 1 Billion transistors Small tests take over 8 hours! [1] [1] - Horribly slow for realistic designs
34 Computer Architect Simulating Simulating! modified from
35 Slightly less horribly slow: Hardware Emulation RTL description of Target Architecture
36 Slightly less horribly slow: Hardware Emulation RTL description of Target Architecture Synthesize for FPGA (slow)
 Emulate on FPGA (fast!")
37 Slightly less horribly slow: Hardware Emulation RTL description of Target Architecture Synthesize for FPGA (slow) Emulate on FPGA (fast!) Note: instrumentation required to get detailed information out!


38 Levels of detail in Simulation Full-System versus User-level Cycle Accurate versus Functional Execution- versus Trace-driven
39 Full-system versus User-Level To OS or not to OS?
40 Full-system versus User-Level To OS or not to OS? Full-System
41 Full-system versus User-Level To OS or not to OS? Full-System
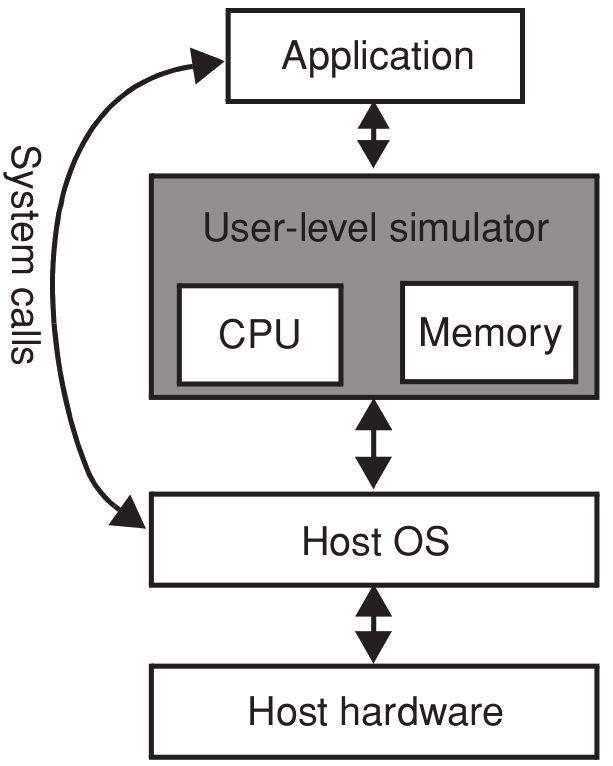
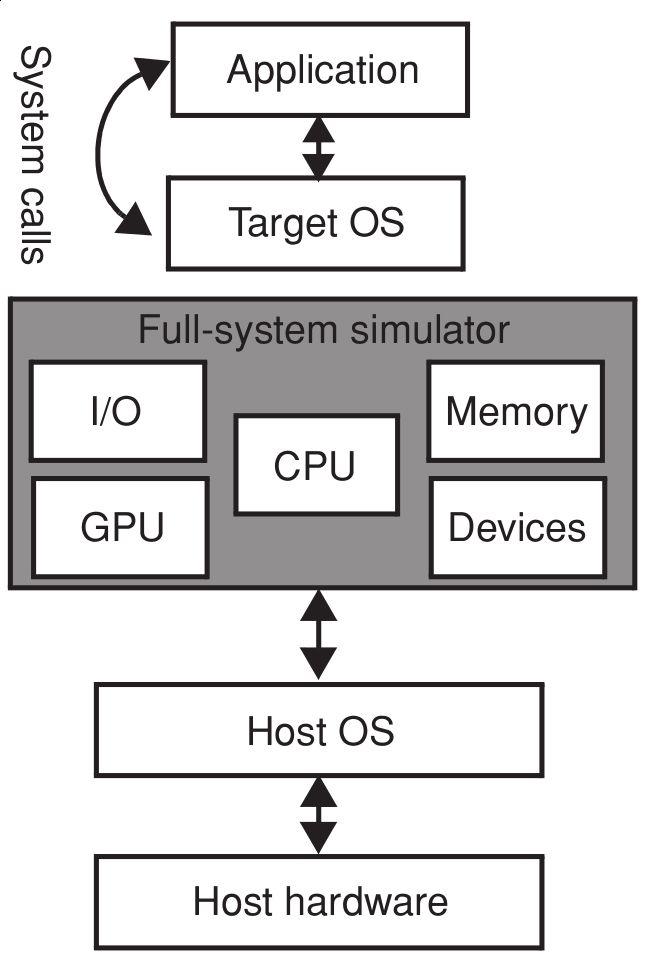
42 Full-system versus User-Level To OS or not to OS? Full-System User-Level
43 User-Level Famous example: Simple Scalar [1] Advantages Fast to develop and update to new architectures Usually accurate enough Disadvantages Any time spent in the OS is not modelled accurately. Can have severe impact, database applications spent 20-30% of their time in OS mode. [1]
44 Cycle Accurate versus Functional
45 Cycle Accurate versus Functional Cycle Accurate
46 Cycle Accurate versus Functional Cycle Accurate
47 Cycle Accurate versus Functional Cycle Accurate Functional
48 Cycle Accurate versus Functional Functional - no/limited model of the micro architecture An (add) instruction of the target can be translated to an (add) instruction on the host, and be simulated that way. Example 1: Simple Scalar sim-fast Example 2: QEMU, Full-system emulator using dynamic translation Cycle Accurate - includes model of the micro architecture Block resources in the pipeline when instruction executes Use target branch predictor scheme Out-of-order execution Example: Simple Scalar sim-outorder
49 Intermezzo - Internals of dynamic translation Target Binary Magic Translate Native Instructions
50 Intermezzo - Internals of dynamic translation Target Binary Magic Translate Native Instructions int32_t instructions[]={ 0x3FE9, 0xA701, 0xEF02, 0x8FF0 }; execute(instructions);
51 Intermezzo - Internals of dynamic translation Target Binary Magic Translate Native Instructions int32_t instructions[]={ 0x3FE9, 0xA701, 0xEF02, 0x8FF0 }; execute(instructions); Question Implement the execute function in regular C
52 Intermezzo - Internals of dynamic translation void execute(int32_t* instructions){ //declare a pointer to a function that returns void // and has no arguments void (fp*)(void); //set the function pointer to the first instruction fp=instructions; //call the function //Note: make sure the last instruction in the list returns fp(); } int32_t instructions[]={ 0x3FE9, 0xA701, 0xEF02, 0x8FF0 }; execute(instructions);
53 Execution- versus Trace-driven
54 Execution- versus Trace-driven Application Binary Execution-Driven Simulator Metrics Execution Driven: Application executes on simulator
55 Execution- versus Trace-driven Application Binary Execution-Driven Simulator Metrics Execution Driven: Application executes on simulator Application Binary Execution-Driven Simulator Instruction Trace Trace-Driven Simulator Trace Driven: simulator uses trace as input Metrics
56 Execution- versus Trace-driven Application Binary Execution-Driven Simulator Metrics Execution Driven: Application executes on simulator Application Binary Execution-Driven Simulator Instruction Trace mov mov mov mov int Trace-Driven Simulator Trace Driven: simulator uses trace as input edx,len ecx,msg ebx,1 eax,4 0x80 Metrics
57 Execution- versus Trace-driven Application Binary Why would a sane person do this? Execution-Driven Simulator Metrics Execution Driven: Application executes on simulator Application Binary Execution-Driven Simulator Instruction Trace mov mov mov mov int Trace-Driven Simulator Trace Driven: simulator uses trace as input edx,len ecx,msg ebx,1 eax,4 0x80 Metrics
58 Execution- versus Trace-driven Application Binary Execution-Driven Simulator Metrics Execution Driven: Application executes on simulator mov mov mov mov int edx,len ecx,msg ebx,1 eax,4 0x80 Execution-Driven Simulator Application Binary OR ISA compatible Processor Instruction Trace Trace-Driven Simulator Trace Driven: simulator uses trace as input Metrics
59 Trace-driven Simulation Advantages Trace collection only required once Trace collection can be done with ISA compatible processor Trace simulator does not need to simulate all instructions, can skip ahead in trace if not implemented
60 Trace-driven Simulation Advantages Trace collection only required once Trace collection can be done with ISA compatible processor Trace simulator does not need to simulate all instructions, can skip ahead in trace if not implemented Disadvantages Cannot speculatively execute code (trace is fixed) Trace file can become huge for large applications (hundreds of GBs)
61 Mixing Simulation Strategies Direct-execution Parts execute directly on the host (e.g. using dynamic translation such as QEMU) Other parts are executed on cycle accurate simulation Use case: Interested in memory accesses and memory behavior. Execute only loads and stores on the simulator, emulate the rest directly on the host machine

62 Simulation in the Multiprocessor Era
63 Simulation in the Multiprocessor Era
64 Parallelisation in all levels of the simulation stack Benchmark Target Processor Simulator Host Platform
65 Parallelisation in all levels of the simulation stack Multi-threaded application Benchmark N Target Processor Simulator Host Platform
66 Parallelisation in all levels of the simulation stack Multi-threaded application Benchmark N Target Processor Simulator Host Platform A multi-threaded application running on a single core target processor. Question: Does this make sense?
67 Parallelisation in all levels of the simulation stack Multi-threaded application Benchmark N Multi-core target processor Target Processor A B...? Simulator Host Platform
68 Parallelisation in all levels of the simulation stack Multi-threaded application Benchmark N Multi-core target processor Target Processor A B...? Simulator Host Platform A multi-core processor running on a single threaded simulator. Question: Does this make sense?
69 Parallelisation in all levels of the simulation stack Multi-threaded application Benchmark N Multi-core target processor Target Processor A B...? Simulator Multi-threaded simulator Host Platform N
70 Parallelisation in all levels of the simulation stack Multi-threaded application Benchmark N Multi-core target processor Target Processor A B...? Simulator Multi-threaded simulator Host Platform N A multi-threaded simulator running on a single-core host. Question: Does this make sense?
71 Parallelisation in all levels of the simulation stack Multi-threaded application Benchmark N Multi-core target processor Target Processor A B...? Simulator Multi-threaded simulator N Host Platform Multi-core host platform A B...?
72 Parallelisation in all levels of the simulation stack Multi-threaded application Multi-core target processor Benchmark N Target Processor A B...? Simulator Multi-threaded simulator N Host Platform Multi-core host platform A B...? But how to build a fast, multi-threaded simulator?
73 Parallelisation in all levels of the simulation stack But how to build a fast, multi-threaded simulator? Simulator Multi-threaded simulator N
74 Parallel Simulation Techniques Discrete event simulation Quantum simulation Slack simulation

75 Parallel Simulation Techniques Discrete event simulation Quantum simulation Not schrödinger's cat quantum though Slack simulation
76 Space Granularity The textbook implicitly assumes the smallest hardware block that can be mapped to a simulator thread is a full target core. Holds for almost all real-world simulators, which severely limits the parallelism
77 Space Granularity The textbook implicitly assumes the smallest hardware block that can be mapped to a simulator thread is a full target core. Holds for almost all real-world simulators, which severely limits the parallelism Exception is RTL simulation, there the blocks can be smaller. The Rocketick simulator even appears to use GPUs! [1] [1]
78 Discrete-Event Simulation A logical choice for a simulator time step is one cycle for the fastest core.
79 Discrete-Event Simulation Disadvantage
80 Discrete-Event Simulation Disadvantage Under utilisation of the host platform if threads are idle for synchronisation
81 Discrete-Event Simulation Is it really this bad? What assumption did the author of the book make here? Disadvantage Under utilisation of the host platform if threads are idle for synchronisation
82 Discrete-Event Simulation Every target processor Pn is mapped to a separate host core Is it really this bad? What assumption did the author of the book make here? Disadvantage Under utilisation of the host platform if threads are idle for synchronisation
83 Target vs Host Cores There is no relation between the number of target cores and the number of host cores!!!
84 Target vs Host Cores There is no relation between the number of target cores and the number of host cores!!!
85 Multi-threaded application Benchmark N Multi-core target processor Target Processor A B...? Simulator Multi-threaded simulator N Host Platform Multi-core host platform A B...?
86 Discrete-Event Simulation
87 Discrete-Event Simulation Utilisation of host depends on variation in processing time of a cycle, but also on the amount of host cores! 1 Host core 1 P4 P3 P2 P1
88 Quantum Simulation Synchronize threads at larger time-steps, e.g. 3 cycles
89 Quantum Simulation Synchronize threads at larger time-steps, e.g. 3 cycles Advantage Utilisation improves, because the variation of processing is amortized over longer sections of simulation Disadvantage No longer cycle accurate
90 Slack Simulation Start with discrete-event simulation schedule
91 Slack Simulation Instead of waiting in the red areas, use slack to process ahead

92 Slack Simulation Instead of waiting in the red areas, use slack to process ahead
93 Slack Simulation Side-effect: Drift The cores might be simulating different points in time, and could drift apart Mitigation Allow a maximum drift (or slack), and synchronize when this value is exceeded
94 Slack Simulation Side-effect: Drift The cores might be simulating different points in time, and could drift apart Mitigation Allow a maximum drift (or slack), and synchronize when this value is exceeded Max slack of 2
95 Slack versus Quantum simulation In quantum simulation, the core simulation times always stay within a cycle window, which is fixed in global time. Also in slack simulation the simulation times stay within a window, but with the key difference that this is a sliding window.
96 Slack versus Quantum simulation In quantum simulation, the core simulation times always stay within a cycle window, which is fixed in global time. Also in slack simulation the simulation times stay within a window, but with the key difference that this is a sliding window. Typically much less synchronisation!
97 Still not good enough From the paper Graphite: a Distributed Parallel Simulator for Multicores Simulation slowdown is as low as 41 versus native execution [1] Graphite: A Distributed Parallel Simulator for Multicores - Jason E. Miller et al.
98 Still not good enough From the paper Graphite: a Distributed Parallel Simulator for Multicores Simulation slowdown is as low as 41 versus native execution That still sounds slow [1] Graphite: A Distributed Parallel Simulator for Multicores - Jason E. Miller et al.
99 Still not good enough From the paper Graphite: a Distributed Parallel Simulator for Multicores Simulation slowdown is as low as 41 versus native execution Well... That still sounds slow [1] Graphite: A Distributed Parallel Simulator for Multicores - Jason E. Miller et al.
100 Still not good enough From the paper Graphite: a Distributed Parallel Simulator for Multicores Simulation slowdown is as low as 41 versus native execution Yes :( That still sounds slow [1] Graphite: A Distributed Parallel Simulator for Multicores - Jason E. Miller et al.
101 Question What can we do if it still takes weeks or months to simulate a full benchmark? 0 cycles 1e16
102 Workload Sampling Naive Approach Only simulate first X cycles fixed length 0 cycles 1e12
103 Workload Sampling Often benchmarks start with reading settings and initialisation. Most likely not representative of workload! fixed length 0 cycles 1e12
104 Workload Sampling Fix Use functional simulation to skip over the initial section skip init with functional sim init fixed length 0 cycles 1e12
105 Workload Sampling Question Is the window always a good representation of the benchmark? Why/why not? skip init with functional sim init fixed length 0 cycles 1e12

106 Program Modes Real world programs spend time in different modes, which can have very different characteristics
107 Workload Sampling Sample uniformly over the program, hopefully capturing the dominant modes uniform sampling skip init with functional sim init fixed length 0 cycles 1e12
108 Workload Sampling Sample uniformly over the program, hopefully capturing the dominant modes uniform sampling skip init with functional sim init However, if the window size is very small, the micro-architecture is not initialized correctly! E.g.: the branch predictor and caches fixed length 0 cycles 1e12
109 Workload Sampling Solution: add warm up period before every window uniform sampling skip init with functional sim init fixed length 0 cycles 1e12
110 Workload Sampling Solution: add warm up period before every window uniform sampling skip init with functional sim init Question How long should we warm-up? fixed length 0 cycles 1e12
111 Workload Sampling [1] SMARTS: accelerating microarchitecture simulation via rigorous statistical sampling - Roland E. Wunderlich et al. Solution: add warm up period before every window uniform sampling skip init with functional sim init fixed length 0 Some numbers suggested by SMARTS [1] to get a feeling for the scale: - Initializing caches cycles - Initializing branch prediction, reorder buffers, etc (micro architectural structures.) 4000 cycles - window size 1000 cycles cycles 1e12
112 Workload Sampling uniform sampling skip init with functional sim init fixed length 0 cycles 1e12
113 Workload Sampling mode sampling uniform sampling skip init with functional sim init fixed length 0 cycles 1e12
114 Workload Sampling mode sampling uniform sampling skip init with functional sim init Profile for modes in the application, and select representative windows. Typically the window size can be larger, so less windows + warm-up is required fixed length 0 cycles 1e12
115 Summary Why Simulators Simulation detail Full-System vs User-level Functional vs Cycle Accurate (micro-arch.) vs Gate-Level Execution- vs Trace-driven (Fast) Multiprocessor Simulation More accurate than models Cheaper than building hardware Discrete event Quantum slack Workload Sampling Summary (the meta lecture)
 vs Gate-Level Execution- vs Trace-driven (Fast) Multiprocessor Simulation More accurate than models Cheaper than building hardware Discrete event Quantum slack Workload Sampling")
116 Summary Why Simulators Simulation detail Full-System vs User-level Functional vs Cycle Accurate (micro-arch.) vs Gate-Level Execution- vs Trace-driven (Fast) Multiprocessor Simulation More accurate than models Cheaper than building hardware Discrete event Quantum slack Workload Sampling Summary (the meta lecture) You can read about all of this in your textbook, chapter 9
COTSon: Infrastructure for system-level simulation
 COTSon: Infrastructure for system-level simulation Ayose Falcón, Paolo Faraboschi, Daniel Ortega HP Labs Exascale Computing Lab http://sites.google.com/site/hplabscotson MICRO-41 tutorial November 9, 28
COTSon: Infrastructure for system-level simulation Ayose Falcón, Paolo Faraboschi, Daniel Ortega HP Labs Exascale Computing Lab http://sites.google.com/site/hplabscotson MICRO-41 tutorial November 9, 28
Outline Simulators and such. What defines a simulator? What about emulation?
 Outline Simulators and such Mats Brorsson & Mladen Nikitovic ICT Dept of Electronic, Computer and Software Systems (ECS) What defines a simulator? Why are simulators needed? Classifications Case studies
Outline Simulators and such Mats Brorsson & Mladen Nikitovic ICT Dept of Electronic, Computer and Software Systems (ECS) What defines a simulator? Why are simulators needed? Classifications Case studies
SW simulation and Performance Analysis
 SW simulation and Performance Analysis In Multi-Processing Embedded Systems Eugenio Villar University of Cantabria Context HW/SW Embedded Systems Design Flow HW/SW Simulation Performance Analysis Design
SW simulation and Performance Analysis In Multi-Processing Embedded Systems Eugenio Villar University of Cantabria Context HW/SW Embedded Systems Design Flow HW/SW Simulation Performance Analysis Design
Project 5: Optimizer Jason Ansel
 Project 5: Optimizer Jason Ansel Overview Project guidelines Benchmarking Library OoO CPUs Project Guidelines Use optimizations from lectures as your arsenal If you decide to implement one, look at Whale
Project 5: Optimizer Jason Ansel Overview Project guidelines Benchmarking Library OoO CPUs Project Guidelines Use optimizations from lectures as your arsenal If you decide to implement one, look at Whale
CS4617 Computer Architecture
 1/26 CS4617 Computer Architecture Lecture 2 Dr J Vaughan September 10, 2014 2/26 Amdahl s Law Speedup = Execution time for entire task without using enhancement Execution time for entire task using enhancement
1/26 CS4617 Computer Architecture Lecture 2 Dr J Vaughan September 10, 2014 2/26 Amdahl s Law Speedup = Execution time for entire task without using enhancement Execution time for entire task using enhancement
Overview. 1 Trends in Microprocessor Architecture. Computer architecture. Computer architecture
 Overview 1 Trends in Microprocessor Architecture R05 Robert Mullins Computer architecture Scaling performance and CMOS Where have performance gains come from? Modern superscalar processors The limits of
Overview 1 Trends in Microprocessor Architecture R05 Robert Mullins Computer architecture Scaling performance and CMOS Where have performance gains come from? Modern superscalar processors The limits of
Ramon Canal NCD Master MIRI. NCD Master MIRI 1
 Wattch, Hotspot, Hotleakage, McPAT http://www.eecs.harvard.edu/~dbrooks/wattch-form.html http://lava.cs.virginia.edu/hotspot http://lava.cs.virginia.edu/hotleakage http://www.hpl.hp.com/research/mcpat/
Wattch, Hotspot, Hotleakage, McPAT http://www.eecs.harvard.edu/~dbrooks/wattch-form.html http://lava.cs.virginia.edu/hotspot http://lava.cs.virginia.edu/hotleakage http://www.hpl.hp.com/research/mcpat/
What is a Simulation? Simulation & Modeling. Why Do Simulations? Emulators versus Simulators. Why Do Simulations? Why Do Simulations?
 What is a Simulation? Simulation & Modeling Introduction and Motivation A system that represents or emulates the behavior of another system over time; a computer simulation is one where the system doing
What is a Simulation? Simulation & Modeling Introduction and Motivation A system that represents or emulates the behavior of another system over time; a computer simulation is one where the system doing
CSE502: Computer Architecture Welcome to CSE 502
 Welcome to CSE 502 Introduction & Review Today s Lecture Course Overview Course Topics Grading Logistics Academic Integrity Policy Homework Quiz Key basic concepts for Computer Architecture Course Overview
Welcome to CSE 502 Introduction & Review Today s Lecture Course Overview Course Topics Grading Logistics Academic Integrity Policy Homework Quiz Key basic concepts for Computer Architecture Course Overview
SATSim: A Superscalar Architecture Trace Simulator Using Interactive Animation
 SATSim: A Superscalar Architecture Trace Simulator Using Interactive Animation Mark Wolff Linda Wills School of Electrical and Computer Engineering Georgia Institute of Technology {wolff,linda.wills}@ece.gatech.edu
SATSim: A Superscalar Architecture Trace Simulator Using Interactive Animation Mark Wolff Linda Wills School of Electrical and Computer Engineering Georgia Institute of Technology {wolff,linda.wills}@ece.gatech.edu
Introduction to co-simulation. What is HW-SW co-simulation?
 Introduction to co-simulation CPSC489-501 Hardware-Software Codesign of Embedded Systems Mahapatra-TexasA&M-Fall 00 1 What is HW-SW co-simulation? A basic definition: Manipulating simulated hardware with
Introduction to co-simulation CPSC489-501 Hardware-Software Codesign of Embedded Systems Mahapatra-TexasA&M-Fall 00 1 What is HW-SW co-simulation? A basic definition: Manipulating simulated hardware with
Recent Advances in Simulation Techniques and Tools
 Recent Advances in Simulation Techniques and Tools Yuyang Li, li.yuyang(at)wustl.edu (A paper written under the guidance of Prof. Raj Jain) Download Abstract: Simulation refers to using specified kind
Recent Advances in Simulation Techniques and Tools Yuyang Li, li.yuyang(at)wustl.edu (A paper written under the guidance of Prof. Raj Jain) Download Abstract: Simulation refers to using specified kind
Supporting x86-64 Address Translation for 100s of GPU Lanes. Jason Power, Mark D. Hill, David A. Wood
 Supporting x86-64 Address Translation for 100s of GPU s Jason Power, Mark D. Hill, David A. Wood Summary Challenges: CPU&GPUs physically integrated, but logically separate; This reduces theoretical bandwidth,
Supporting x86-64 Address Translation for 100s of GPU s Jason Power, Mark D. Hill, David A. Wood Summary Challenges: CPU&GPUs physically integrated, but logically separate; This reduces theoretical bandwidth,
Parallel Computing 2020: Preparing for the Post-Moore Era. Marc Snir
 Parallel Computing 2020: Preparing for the Post-Moore Era Marc Snir THE (CMOS) WORLD IS ENDING NEXT DECADE So says the International Technology Roadmap for Semiconductors (ITRS) 2 End of CMOS? IN THE LONG
Parallel Computing 2020: Preparing for the Post-Moore Era Marc Snir THE (CMOS) WORLD IS ENDING NEXT DECADE So says the International Technology Roadmap for Semiconductors (ITRS) 2 End of CMOS? IN THE LONG
CUDA Threads. Terminology. How it works. Terminology. Streaming Multiprocessor (SM) A SM processes block of threads
 A SM processes block of threads") Terminology CUDA Threads Bedrich Benes, Ph.D. Purdue University Department of Computer Graphics Streaming Multiprocessor (SM) A SM processes block of threads Streaming Processors (SP) also called CUDA
Terminology CUDA Threads Bedrich Benes, Ph.D. Purdue University Department of Computer Graphics Streaming Multiprocessor (SM) A SM processes block of threads Streaming Processors (SP) also called CUDA
Performance Evaluation of Multi-Threaded System vs. Chip-Multi-Processor System
 Performance Evaluation of Multi-Threaded System vs. Chip-Multi-Processor System Ho Young Kim, Robert Maxwell, Ankil Patel, Byeong Kil Lee Abstract The purpose of this study is to analyze and compare the
Performance Evaluation of Multi-Threaded System vs. Chip-Multi-Processor System Ho Young Kim, Robert Maxwell, Ankil Patel, Byeong Kil Lee Abstract The purpose of this study is to analyze and compare the
Improving GPU Performance via Large Warps and Two-Level Warp Scheduling
 Improving GPU Performance via Large Warps and Two-Level Warp Scheduling Veynu Narasiman The University of Texas at Austin Michael Shebanow NVIDIA Chang Joo Lee Intel Rustam Miftakhutdinov The University
Improving GPU Performance via Large Warps and Two-Level Warp Scheduling Veynu Narasiman The University of Texas at Austin Michael Shebanow NVIDIA Chang Joo Lee Intel Rustam Miftakhutdinov The University
Statistical Simulation of Multithreaded Architectures
 Statistical Simulation of Multithreaded Architectures Joshua L. Kihm and Daniel A. Connors University of Colorado at Boulder Department of Electrical and Computer Engineering UCB 425, Boulder, CO, 80309
Statistical Simulation of Multithreaded Architectures Joshua L. Kihm and Daniel A. Connors University of Colorado at Boulder Department of Electrical and Computer Engineering UCB 425, Boulder, CO, 80309
Track and Vertex Reconstruction on GPUs for the Mu3e Experiment
 Track and Vertex Reconstruction on GPUs for the Mu3e Experiment Dorothea vom Bruch for the Mu3e Collaboration GPU Computing in High Energy Physics, Pisa September 11th, 2014 Physikalisches Institut Heidelberg
Track and Vertex Reconstruction on GPUs for the Mu3e Experiment Dorothea vom Bruch for the Mu3e Collaboration GPU Computing in High Energy Physics, Pisa September 11th, 2014 Physikalisches Institut Heidelberg
Performance Evaluation of Recently Proposed Cache Replacement Policies
 University of Jordan Computer Engineering Department Performance Evaluation of Recently Proposed Cache Replacement Policies CPE 731: Advanced Computer Architecture Dr. Gheith Abandah Asma Abdelkarim January
University of Jordan Computer Engineering Department Performance Evaluation of Recently Proposed Cache Replacement Policies CPE 731: Advanced Computer Architecture Dr. Gheith Abandah Asma Abdelkarim January
Simulation Performance Optimization of Virtual Prototypes Sammidi Mounika, B S Renuka
 Simulation Performance Optimization of Virtual Prototypes Sammidi Mounika, B S Renuka Abstract Virtual prototyping is becoming increasingly important to embedded software developers, engineers, managers
Simulation Performance Optimization of Virtual Prototypes Sammidi Mounika, B S Renuka Abstract Virtual prototyping is becoming increasingly important to embedded software developers, engineers, managers
High-Performance Pipelined Architecture of Elliptic Curve Scalar Multiplication Over GF(2 m )
") High-Performance Pipelined Architecture of Elliptic Curve Scalar Multiplication Over GF(2 m ) Abstract: This paper proposes an efficient pipelined architecture of elliptic curve scalar multiplication (ECSM)
High-Performance Pipelined Architecture of Elliptic Curve Scalar Multiplication Over GF(2 m ) Abstract: This paper proposes an efficient pipelined architecture of elliptic curve scalar multiplication (ECSM)
Console Games Are Just Like Mobile Games* (* well, not really. But they are more alike than you
 Console Games Are Just Like Mobile Games* (* well, not really. But they are more alike than you think ) Hi, I m Brian Currently a Software Architect at Zynga, and CTO of CastleVille Legends (for ios/android)
Console Games Are Just Like Mobile Games* (* well, not really. But they are more alike than you think ) Hi, I m Brian Currently a Software Architect at Zynga, and CTO of CastleVille Legends (for ios/android)
ECE 124 Digital Circuits and Systems Winter 2011 Introduction Calendar Description:
 ECE 124 Digital Circuits and Systems Winter 2011 Introduction Calendar Description: Number systems. Switching algebra. Hardware description languages. Simplification of Boolean functions. Combinational
ECE 124 Digital Circuits and Systems Winter 2011 Introduction Calendar Description: Number systems. Switching algebra. Hardware description languages. Simplification of Boolean functions. Combinational
Challenges in Transition
 Challenges in Transition Keynote talk at International Workshop on Software Engineering Methods for Parallel and High Performance Applications (SEM4HPC 2016) 1 Kazuaki Ishizaki IBM Research Tokyo kiszk@acm.org
Challenges in Transition Keynote talk at International Workshop on Software Engineering Methods for Parallel and High Performance Applications (SEM4HPC 2016) 1 Kazuaki Ishizaki IBM Research Tokyo kiszk@acm.org
EE 280 Introduction to Digital Logic Design
 EE 280 Introduction to Digital Logic Design Lecture 1. Introduction EE280 Lecture 1 1-1 Instructors: EE 280 Introduction to Digital Logic Design Dr. Lukasz Kurgan (section A1) office: ECERF 6 th floor,
EE 280 Introduction to Digital Logic Design Lecture 1. Introduction EE280 Lecture 1 1-1 Instructors: EE 280 Introduction to Digital Logic Design Dr. Lukasz Kurgan (section A1) office: ECERF 6 th floor,
EECS150 - Digital Design Lecture 28 Course Wrap Up. Recap 1
 EECS150 - Digital Design Lecture 28 Course Wrap Up Dec. 5, 2013 Prof. Ronald Fearing Electrical Engineering and Computer Sciences University of California, Berkeley (slides courtesy of Prof. John Wawrzynek)
EECS150 - Digital Design Lecture 28 Course Wrap Up Dec. 5, 2013 Prof. Ronald Fearing Electrical Engineering and Computer Sciences University of California, Berkeley (slides courtesy of Prof. John Wawrzynek)
CS61c: Introduction to Synchronous Digital Systems
 CS61c: Introduction to Synchronous Digital Systems J. Wawrzynek March 4, 2006 Optional Reading: P&H, Appendix B 1 Instruction Set Architecture Among the topics we studied thus far this semester, was the
CS61c: Introduction to Synchronous Digital Systems J. Wawrzynek March 4, 2006 Optional Reading: P&H, Appendix B 1 Instruction Set Architecture Among the topics we studied thus far this semester, was the
Final Report: DBmbench
 18-741 Final Report: DBmbench Yan Ke (yke@cs.cmu.edu) Justin Weisz (jweisz@cs.cmu.edu) Dec. 8, 2006 1 Introduction Conventional database benchmarks, such as the TPC-C and TPC-H, are extremely computationally
18-741 Final Report: DBmbench Yan Ke (yke@cs.cmu.edu) Justin Weisz (jweisz@cs.cmu.edu) Dec. 8, 2006 1 Introduction Conventional database benchmarks, such as the TPC-C and TPC-H, are extremely computationally
Architecture ISCA 16 Luis Ceze, Tom Wenisch
 Architecture 2030 @ ISCA 16 Luis Ceze, Tom Wenisch Mark Hill (CCC liaison, mentor) LIVE! Neha Agarwal, Amrita Mazumdar, Aasheesh Kolli (Student volunteers) Context Many fantastic community formation/visioning
Architecture 2030 @ ISCA 16 Luis Ceze, Tom Wenisch Mark Hill (CCC liaison, mentor) LIVE! Neha Agarwal, Amrita Mazumdar, Aasheesh Kolli (Student volunteers) Context Many fantastic community formation/visioning
Like Mobile Games* Currently a Distinguished i Engineer at Zynga, and CTO of FarmVille 2: Country Escape (for ios/android/kindle)
") Console Games Are Just Like Mobile Games* (* well, not really. But they are more alike than you think ) Hi, I m Brian Currently a Distinguished i Engineer at Zynga, and CTO of FarmVille 2: Country Escape
Console Games Are Just Like Mobile Games* (* well, not really. But they are more alike than you think ) Hi, I m Brian Currently a Distinguished i Engineer at Zynga, and CTO of FarmVille 2: Country Escape
Performance Metrics, Amdahl s Law
 ecture 26 Computer Science 61C Spring 2017 March 20th, 2017 Performance Metrics, Amdahl s Law 1 New-School Machine Structures (It s a bit more complicated!) Software Hardware Parallel Requests Assigned
ecture 26 Computer Science 61C Spring 2017 March 20th, 2017 Performance Metrics, Amdahl s Law 1 New-School Machine Structures (It s a bit more complicated!) Software Hardware Parallel Requests Assigned
Digital Systems Design
 Digital Systems Design Digital Systems Design and Test Dr. D. J. Jackson Lecture 1-1 Introduction Traditional digital design Manual process of designing and capturing circuits Schematic entry System-level
Digital Systems Design Digital Systems Design and Test Dr. D. J. Jackson Lecture 1-1 Introduction Traditional digital design Manual process of designing and capturing circuits Schematic entry System-level
EECS 470. Tomasulo s Algorithm. Lecture 4 Winter 2018
 omasulo s Algorithm Winter 2018 Slides developed in part by Profs. Austin, Brehob, Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, yson, Vijaykumar, and Wenisch of Carnegie Mellon University,
omasulo s Algorithm Winter 2018 Slides developed in part by Profs. Austin, Brehob, Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, yson, Vijaykumar, and Wenisch of Carnegie Mellon University,
Overview of Design Methodology. A Few Points Before We Start 11/4/2012. All About Handling The Complexity. Lecture 1. Put things into perspective
 Overview of Design Methodology Lecture 1 Put things into perspective ECE 156A 1 A Few Points Before We Start ECE 156A 2 All About Handling The Complexity Design and manufacturing of semiconductor products
Overview of Design Methodology Lecture 1 Put things into perspective ECE 156A 1 A Few Points Before We Start ECE 156A 2 All About Handling The Complexity Design and manufacturing of semiconductor products
Matthew Grossman Mentor: Rick Brownrigg
 Matthew Grossman Mentor: Rick Brownrigg Outline What is a WMS? JOCL/OpenCL Wavelets Parallelization Implementation Results Conclusions What is a WMS? A mature and open standard to serve georeferenced imagery
Matthew Grossman Mentor: Rick Brownrigg Outline What is a WMS? JOCL/OpenCL Wavelets Parallelization Implementation Results Conclusions What is a WMS? A mature and open standard to serve georeferenced imagery
Trace Based Switching For A Tightly Coupled Heterogeneous Core
 Trace Based Switching For A Tightly Coupled Heterogeneous Core Shru% Padmanabha, Andrew Lukefahr, Reetuparna Das, Sco@ Mahlke Micro- 46 December 2013 University of Michigan Electrical Engineering and Computer
Trace Based Switching For A Tightly Coupled Heterogeneous Core Shru% Padmanabha, Andrew Lukefahr, Reetuparna Das, Sco@ Mahlke Micro- 46 December 2013 University of Michigan Electrical Engineering and Computer
Lecture 1. Tinoosh Mohsenin
 Lecture 1 Tinoosh Mohsenin Today Administrative items Syllabus and course overview Digital systems and optimization overview 2 Course Communication Email Urgent announcements Web page http://www.csee.umbc.edu/~tinoosh/cmpe650/
Lecture 1 Tinoosh Mohsenin Today Administrative items Syllabus and course overview Digital systems and optimization overview 2 Course Communication Email Urgent announcements Web page http://www.csee.umbc.edu/~tinoosh/cmpe650/
Challenges of in-circuit functional timing testing of System-on-a-Chip
 Challenges of in-circuit functional timing testing of System-on-a-Chip David and Gregory Chudnovsky Institute for Mathematics and Advanced Supercomputing Polytechnic Institute of NYU Deep sub-micron devices
Challenges of in-circuit functional timing testing of System-on-a-Chip David and Gregory Chudnovsky Institute for Mathematics and Advanced Supercomputing Polytechnic Institute of NYU Deep sub-micron devices
AN EFFICIENT APPROACH TO MINIMIZE POWER AND AREA IN CARRY SELECT ADDER USING BINARY TO EXCESS ONE CONVERTER
 AN EFFICIENT APPROACH TO MINIMIZE POWER AND AREA IN CARRY SELECT ADDER USING BINARY TO EXCESS ONE CONVERTER K. RAMAMOORTHY 1 T. CHELLADURAI 2 V. MANIKANDAN 3 1 Department of Electronics and Communication
AN EFFICIENT APPROACH TO MINIMIZE POWER AND AREA IN CARRY SELECT ADDER USING BINARY TO EXCESS ONE CONVERTER K. RAMAMOORTHY 1 T. CHELLADURAI 2 V. MANIKANDAN 3 1 Department of Electronics and Communication
CS429: Computer Organization and Architecture
 CS429: Computer Organization and Architecture Dr. Bill Young Department of Computer Sciences University of Texas at Austin Last updated: November 8, 2017 at 09:27 CS429 Slideset 14: 1 Overview What s wrong
CS429: Computer Organization and Architecture Dr. Bill Young Department of Computer Sciences University of Texas at Austin Last updated: November 8, 2017 at 09:27 CS429 Slideset 14: 1 Overview What s wrong
PROBE: Prediction-based Optical Bandwidth Scaling for Energy-efficient NoCs
 PROBE: Prediction-based Optical Bandwidth Scaling for Energy-efficient NoCs Li Zhou and Avinash Kodi Technologies for Emerging Computer Architecture Laboratory (TEAL) School of Electrical Engineering and
PROBE: Prediction-based Optical Bandwidth Scaling for Energy-efficient NoCs Li Zhou and Avinash Kodi Technologies for Emerging Computer Architecture Laboratory (TEAL) School of Electrical Engineering and
Welcome to 6.S084! Computation Structures (special)
") Welcome to 6.S084! Computation Structures (special) Spring 2018 6.S084 Course Staff Instructors Arvind arvind@csail.mit.edu Daniel Sanchez sanchez@csail.mit.edu Teaching Assistants Silvina Hanono Wachman
Welcome to 6.S084! Computation Structures (special) Spring 2018 6.S084 Course Staff Instructors Arvind arvind@csail.mit.edu Daniel Sanchez sanchez@csail.mit.edu Teaching Assistants Silvina Hanono Wachman
Instructor: Dr. Mainak Chaudhuri. Instructor: Dr. S. K. Aggarwal. Instructor: Dr. Rajat Moona
 NPTEL Online - IIT Kanpur Instructor: Dr. Mainak Chaudhuri Instructor: Dr. S. K. Aggarwal Course Name: Department: Program Optimization for Multi-core Architecture Computer Science and Engineering IIT
NPTEL Online - IIT Kanpur Instructor: Dr. Mainak Chaudhuri Instructor: Dr. S. K. Aggarwal Course Name: Department: Program Optimization for Multi-core Architecture Computer Science and Engineering IIT
Power of Realtime 3D-Rendering. Raja Koduri
 Power of Realtime 3D-Rendering Raja Koduri 1 We ate our GPU cake - vuoi la botte piena e la moglie ubriaca And had more too! 16+ years of (sugar) high! In every GPU generation More performance and performance-per-watt
Power of Realtime 3D-Rendering Raja Koduri 1 We ate our GPU cake - vuoi la botte piena e la moglie ubriaca And had more too! 16+ years of (sugar) high! In every GPU generation More performance and performance-per-watt
Introduction (concepts and definitions)
") Objectives: Introduction (digital system design concepts and definitions). Advantages and drawbacks of digital techniques compared with analog. Digital Abstraction. Synchronous and Asynchronous Systems.
Objectives: Introduction (digital system design concepts and definitions). Advantages and drawbacks of digital techniques compared with analog. Digital Abstraction. Synchronous and Asynchronous Systems.
Interconnect-Power Dissipation in a Microprocessor
 4/2/2004 Interconnect-Power Dissipation in a Microprocessor N. Magen, A. Kolodny, U. Weiser, N. Shamir Intel corporation Technion - Israel Institute of Technology 4/2/2004 2 Interconnect-Power Definition
4/2/2004 Interconnect-Power Dissipation in a Microprocessor N. Magen, A. Kolodny, U. Weiser, N. Shamir Intel corporation Technion - Israel Institute of Technology 4/2/2004 2 Interconnect-Power Definition
1) Fixed point [15 points] a) What are the primary reasons we might use fixed point rather than floating point? [2]
![1) Fixed point [15 points] a) What are the primary reasons we might use fixed point rather than floating point? [2]](/thumbs/96/126801547.jpg "1) Fixed point [15 points] a) What are the primary reasons we might use fixed point rather than floating point? [2]") 473 Fall 2018 Homework 2 Answers Due on Gradescope by 5pm on December 11 th. 165 points. Notice that the last problem is a group assignment (groups of 2 or 3). Digital Signal Processing and other specialized
473 Fall 2018 Homework 2 Answers Due on Gradescope by 5pm on December 11 th. 165 points. Notice that the last problem is a group assignment (groups of 2 or 3). Digital Signal Processing and other specialized
Assessing and. Rui Wang, Assistant professor Dept. of Information and Communication Tongji University.
 Assessing and Understanding Performance Rui Wang, Assistant professor Dept. of Information and Communication Tongji University it Email: ruiwang@tongji.edu.cn 4.1 Introduction Pi Primary reason for examining
Assessing and Understanding Performance Rui Wang, Assistant professor Dept. of Information and Communication Tongji University it Email: ruiwang@tongji.edu.cn 4.1 Introduction Pi Primary reason for examining
A Static Power Model for Architects
 A Static Power Model for Architects J. Adam Butts and Guri Sohi University of Wisconsin-Madison {butts,sohi}@cs.wisc.edu 33rd International Symposium on Microarchitecture Monterey, California December,
A Static Power Model for Architects J. Adam Butts and Guri Sohi University of Wisconsin-Madison {butts,sohi}@cs.wisc.edu 33rd International Symposium on Microarchitecture Monterey, California December,
Welcome to 6.111! Introductory Digital Systems Laboratory
 Welcome to 6.111! Introductory Digital Systems Laboratory Handouts: Info form (yellow) Course Calendar Safety Memo Kit Checkout Form Lecture slides Lectures: Chris Terman TAs: Karthik Balakrishnan HuangBin
Welcome to 6.111! Introductory Digital Systems Laboratory Handouts: Info form (yellow) Course Calendar Safety Memo Kit Checkout Form Lecture slides Lectures: Chris Terman TAs: Karthik Balakrishnan HuangBin
Parallel Multi-core Verilog HDL Simulation
 University of Massachusetts - Amherst ScholarWorks@UMass Amherst Doctoral Dissertations May 2014 - current Dissertations and Theses Summer 2014 Parallel Multi-core Verilog HDL Simulation Tariq B. Ahmad
University of Massachusetts - Amherst ScholarWorks@UMass Amherst Doctoral Dissertations May 2014 - current Dissertations and Theses Summer 2014 Parallel Multi-core Verilog HDL Simulation Tariq B. Ahmad
Department Computer Science and Engineering IIT Kanpur
 NPTEL Online - IIT Bombay Course Name Parallel Computer Architecture Department Computer Science and Engineering IIT Kanpur Instructor Dr. Mainak Chaudhuri file:///e /parallel_com_arch/lecture1/main.html[6/13/2012
NPTEL Online - IIT Bombay Course Name Parallel Computer Architecture Department Computer Science and Engineering IIT Kanpur Instructor Dr. Mainak Chaudhuri file:///e /parallel_com_arch/lecture1/main.html[6/13/2012
Welcome to 6.111! Introductory Digital Systems Laboratory
 Welcome to 6.111! Introductory Digital Systems Laboratory Handouts: Info form (yellow) Course Calendar Lecture slides Lectures: Ike Chuang Chris Terman TAs: Javier Castro Eric Fellheimer Jae Lee Willie
Welcome to 6.111! Introductory Digital Systems Laboratory Handouts: Info form (yellow) Course Calendar Lecture slides Lectures: Ike Chuang Chris Terman TAs: Javier Castro Eric Fellheimer Jae Lee Willie
Copyright 2003 The McGraw-Hill Companies, Inc. Permission required for reproduction or display. Slides prepared by Walid A. Najjar & Brian J.
 Introduction to Computing Systems from bits & gates to C & beyond Chapter 1 Welcome Aboard! This course is about: What computers consist of How computers work How they are organized internally What are
Introduction to Computing Systems from bits & gates to C & beyond Chapter 1 Welcome Aboard! This course is about: What computers consist of How computers work How they are organized internally What are
ΕΠΛ 605: Προχωρημένη Αρχιτεκτονική
 ΕΠΛ 605: Προχωρημένη Αρχιτεκτονική Υπολογιστών Presentation of UniServer Horizon 2020 European project findings: X-Gene server chips, voltage-noise characterization, high-bandwidth voltage measurements,
ΕΠΛ 605: Προχωρημένη Αρχιτεκτονική Υπολογιστών Presentation of UniServer Horizon 2020 European project findings: X-Gene server chips, voltage-noise characterization, high-bandwidth voltage measurements,
High Speed ECC Implementation on FPGA over GF(2 m )
") Department of Electronic and Electrical Engineering University of Sheffield Sheffield, UK Int. Conf. on Field-programmable Logic and Applications (FPL) 2-4th September, 2015 1 Overview Overview Introduction
Department of Electronic and Electrical Engineering University of Sheffield Sheffield, UK Int. Conf. on Field-programmable Logic and Applications (FPL) 2-4th September, 2015 1 Overview Overview Introduction
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Out-of-Order Schedulers Data-Capture Scheduler Dispatch: read available operands from ARF/ROB, store in scheduler Commit: Missing operands filled in from bypass Issue: When
CSE 502: Computer Architecture Out-of-Order Schedulers Data-Capture Scheduler Dispatch: read available operands from ARF/ROB, store in scheduler Commit: Missing operands filled in from bypass Issue: When
REVOLUTIONIZING THE COMPUTING LANDSCAPE AND BEYOND.
 December 3-6, 2018 Santa Clara Convention Center CA, USA REVOLUTIONIZING THE COMPUTING LANDSCAPE AND BEYOND. https://tmt.knect365.com/risc-v-summit @risc_v ACCELERATING INFERENCING ON THE EDGE WITH RISC-V
December 3-6, 2018 Santa Clara Convention Center CA, USA REVOLUTIONIZING THE COMPUTING LANDSCAPE AND BEYOND. https://tmt.knect365.com/risc-v-summit @risc_v ACCELERATING INFERENCING ON THE EDGE WITH RISC-V
Architecting Systems of the Future, page 1
 Architecting Systems of the Future featuring Eric Werner interviewed by Suzanne Miller ---------------------------------------------------------------------------------------------Suzanne Miller: Welcome
Architecting Systems of the Future featuring Eric Werner interviewed by Suzanne Miller ---------------------------------------------------------------------------------------------Suzanne Miller: Welcome
Precise State Recovery. Out-of-Order Pipelines
 Precise State Recovery in Out-of-Order Pipelines Nima Honarmand Recall Our Generic OOO Pipeline Instruction flow (pipeline front-end) is in-order Register and memory execution are OOO And, we need a final
Precise State Recovery in Out-of-Order Pipelines Nima Honarmand Recall Our Generic OOO Pipeline Instruction flow (pipeline front-end) is in-order Register and memory execution are OOO And, we need a final
History and Perspective of Simulation in Manufacturing.
 History and Perspective of Simulation in Manufacturing Leon.mcginnis@gatech.edu Oliver.rose@unibw.de Agenda Quick review of the content of the paper Short synthesis of our observations/conclusions Suggested
History and Perspective of Simulation in Manufacturing Leon.mcginnis@gatech.edu Oliver.rose@unibw.de Agenda Quick review of the content of the paper Short synthesis of our observations/conclusions Suggested
CS Computer Architecture Spring Lecture 04: Understanding Performance
 CS 35101 Computer Architecture Spring 2008 Lecture 04: Understanding Performance Taken from Mary Jane Irwin (www.cse.psu.edu/~mji) and Kevin Schaffer [Adapted from Computer Organization and Design, Patterson
CS 35101 Computer Architecture Spring 2008 Lecture 04: Understanding Performance Taken from Mary Jane Irwin (www.cse.psu.edu/~mji) and Kevin Schaffer [Adapted from Computer Organization and Design, Patterson
Mohit Arora. The Art of Hardware Architecture. Design Methods and Techniques. for Digital Circuits. Springer
 Mohit Arora The Art of Hardware Architecture Design Methods and Techniques for Digital Circuits Springer Contents 1 The World of Metastability 1 1.1 Introduction 1 1.2 Theory of Metastability 1 1.3 Metastability
Mohit Arora The Art of Hardware Architecture Design Methods and Techniques for Digital Circuits Springer Contents 1 The World of Metastability 1 1.1 Introduction 1 1.2 Theory of Metastability 1 1.3 Metastability
Revisiting Dynamic Thermal Management Exploiting Inverse Thermal Dependence
 Revisiting Dynamic Thermal Management Exploiting Inverse Thermal Dependence Katayoun Neshatpour George Mason University kneshatp@gmu.edu Amin Khajeh Broadcom Corporation amink@broadcom.com Houman Homayoun
Revisiting Dynamic Thermal Management Exploiting Inverse Thermal Dependence Katayoun Neshatpour George Mason University kneshatp@gmu.edu Amin Khajeh Broadcom Corporation amink@broadcom.com Houman Homayoun
Blackfin Online Learning & Development
 Presentation Title: Introduction to VisualDSP++ Tools Presenter Name: Nicole Wright Chapter 1:Introduction 1a:Module Description 1b:CROSSCORE Products Chapter 2: ADSP-BF537 EZ-KIT Lite Configuration 2a:
Presentation Title: Introduction to VisualDSP++ Tools Presenter Name: Nicole Wright Chapter 1:Introduction 1a:Module Description 1b:CROSSCORE Products Chapter 2: ADSP-BF537 EZ-KIT Lite Configuration 2a:
DASH: Deadline-Aware High-Performance Memory Scheduler for Heterogeneous Systems with Hardware Accelerators
 DASH: Deadline-Aware High-Performance Memory Scheduler for Heterogeneous Systems with Hardware Accelerators Hiroyuki Usui, Lavanya Subramanian Kevin Chang, Onur Mutlu DASH source code is available at GitHub
DASH: Deadline-Aware High-Performance Memory Scheduler for Heterogeneous Systems with Hardware Accelerators Hiroyuki Usui, Lavanya Subramanian Kevin Chang, Onur Mutlu DASH source code is available at GitHub
Model checking in the cloud VIGYAN SINGHAL OSKI TECHNOLOGY
 Model checking in the cloud VIGYAN SINGHAL OSKI TECHNOLOGY Views are biased by Oski experience Service provider, only doing model checking Using off-the-shelf tools (Cadence, Jasper, Mentor, OneSpin Synopsys)
Model checking in the cloud VIGYAN SINGHAL OSKI TECHNOLOGY Views are biased by Oski experience Service provider, only doing model checking Using off-the-shelf tools (Cadence, Jasper, Mentor, OneSpin Synopsys)
An Overview of Computer Architecture and System Simulation
 An Overview of Computer Architecture and System Simulation J. Manuel Colmenar José L. Risco-Martín and Juan Lanchares C.E.S. Felipe II Dept. of Computer Architecture and Automation U. Complutense de Madrid
An Overview of Computer Architecture and System Simulation J. Manuel Colmenar José L. Risco-Martín and Juan Lanchares C.E.S. Felipe II Dept. of Computer Architecture and Automation U. Complutense de Madrid
Static Power and the Importance of Realistic Junction Temperature Analysis
 White Paper: Virtex-4 Family R WP221 (v1.0) March 23, 2005 Static Power and the Importance of Realistic Junction Temperature Analysis By: Matt Klein Total power consumption of a board or system is important;
White Paper: Virtex-4 Family R WP221 (v1.0) March 23, 2005 Static Power and the Importance of Realistic Junction Temperature Analysis By: Matt Klein Total power consumption of a board or system is important;
TABLE OF CONTENTS CHAPTER TITLE PAGE
 TABLE OF CONTENTS CHAPTER TITLE PAGE DECLARATION ACKNOWLEDGEMENT ABSTRACT ABSTRAK TABLE OF CONTENTS LIST OF TABLES LIST OF FIGURES LIST OF ABBREVIATIONS i i i i i iv v vi ix xi xiv 1 INTRODUCTION 1 1.1
TABLE OF CONTENTS CHAPTER TITLE PAGE DECLARATION ACKNOWLEDGEMENT ABSTRACT ABSTRAK TABLE OF CONTENTS LIST OF TABLES LIST OF FIGURES LIST OF ABBREVIATIONS i i i i i iv v vi ix xi xiv 1 INTRODUCTION 1 1.1
CS/EE 181a 2010/11 Lecture 1
 CS/EE 181a 2010/11 Lecture 1 CS/EE 181 is about designing digital CMOS systems. Functional Specification Approximate domain of CS181 Circuit Specification Simulation Architectural Specification Abstract
CS/EE 181a 2010/11 Lecture 1 CS/EE 181 is about designing digital CMOS systems. Functional Specification Approximate domain of CS181 Circuit Specification Simulation Architectural Specification Abstract
NVIDIA SLI AND STUTTER AVOIDANCE:
 NVIDIA SLI AND STUTTER AVOIDANCE: A Recipe for Smooth Gaming and Perfect Scaling with Multiple GPUs NVIDIA SLI AND STUTTER AVOIDANCE: Iain Cantlay (Developer Technology Engineer) Lars Nordskog (Developer
NVIDIA SLI AND STUTTER AVOIDANCE: A Recipe for Smooth Gaming and Perfect Scaling with Multiple GPUs NVIDIA SLI AND STUTTER AVOIDANCE: Iain Cantlay (Developer Technology Engineer) Lars Nordskog (Developer
CS4961 Parallel Programming. Lecture 1: Introduction 08/24/2010. Course Details Time and Location: TuTh, 9:10-10:30 AM, WEB L112 Course Website
 Parallel Programming Lecture 1: Introduction Mary Hall August 24, 2010 1 Course Details Time and Location: TuTh, 9:10-10:30 AM, WEB L112 Course Website - http://www.eng.utah.edu/~cs4961/ Instructor: Mary
Parallel Programming Lecture 1: Introduction Mary Hall August 24, 2010 1 Course Details Time and Location: TuTh, 9:10-10:30 AM, WEB L112 Course Website - http://www.eng.utah.edu/~cs4961/ Instructor: Mary
EECS 470 Lecture 5. Intro to Dynamic Scheduling (Scoreboarding) Fall 2018 Jon Beaumont
 Fall 2018 Jon Beaumont") Intro to Dynamic Scheduling (Scoreboarding) Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Many thanks to Prof. Martin and Roth of University of Pennsylvania for most of these slides.
Intro to Dynamic Scheduling (Scoreboarding) Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Many thanks to Prof. Martin and Roth of University of Pennsylvania for most of these slides.
An Efficent Real Time Analysis of Carry Select Adder
 An Efficent Real Time Analysis of Carry Select Adder Geetika Gesu Department of Electronics Engineering Abha Gaikwad-Patil College of Engineering Nagpur, Maharashtra, India E-mail: geetikagesu@gmail.com
An Efficent Real Time Analysis of Carry Select Adder Geetika Gesu Department of Electronics Engineering Abha Gaikwad-Patil College of Engineering Nagpur, Maharashtra, India E-mail: geetikagesu@gmail.com
Pipelined Processor Design
 Pipelined Processor Design COE 38 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Pipelining versus Serial
Pipelined Processor Design COE 38 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Pipelining versus Serial
EECS 470 Lecture 8. P6 µarchitecture. Fall 2018 Jon Beaumont Core 2 Microarchitecture
 P6 µarchitecture Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Core 2 Microarchitecture Many thanks to Prof. Martin and Roth of University of Pennsylvania for most of these slides. Portions
P6 µarchitecture Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Core 2 Microarchitecture Many thanks to Prof. Martin and Roth of University of Pennsylvania for most of these slides. Portions
A Novel Design of High-Speed Carry Skip Adder Operating Under a Wide Range of Supply Voltages
 A Novel Design of High-Speed Carry Skip Adder Operating Under a Wide Range of Supply Voltages Jalluri srinivisu,(m.tech),email Id: jsvasu494@gmail.com Ch.Prabhakar,M.tech,Assoc.Prof,Email Id: skytechsolutions2015@gmail.com
A Novel Design of High-Speed Carry Skip Adder Operating Under a Wide Range of Supply Voltages Jalluri srinivisu,(m.tech),email Id: jsvasu494@gmail.com Ch.Prabhakar,M.tech,Assoc.Prof,Email Id: skytechsolutions2015@gmail.com
Course Outcome of M.Tech (VLSI Design)
") Course Outcome of M.Tech (VLSI Design) PVL108: Device Physics and Technology The students are able to: 1. Understand the basic physics of semiconductor devices and the basics theory of PN junction. 2.
Course Outcome of M.Tech (VLSI Design) PVL108: Device Physics and Technology The students are able to: 1. Understand the basic physics of semiconductor devices and the basics theory of PN junction. 2.
Architectural Core Salvaging in a Multi-Core Processor for Hard-Error Tolerance
 Architectural Core Salvaging in a Multi-Core Processor for Hard-Error Tolerance Michael D. Powell, Arijit Biswas, Shantanu Gupta, and Shubu Mukherjee SPEARS Group, Intel Massachusetts EECS, University
Architectural Core Salvaging in a Multi-Core Processor for Hard-Error Tolerance Michael D. Powell, Arijit Biswas, Shantanu Gupta, and Shubu Mukherjee SPEARS Group, Intel Massachusetts EECS, University
EE241 - Spring 2013 Advanced Digital Integrated Circuits. Projects. Groups of 3 Proposals in two weeks (2/20) Topics: Lecture 5: Transistor Models
 Topics: Lecture 5: Transistor Models") EE241 - Spring 2013 Advanced Digital Integrated Circuits Lecture 5: Transistor Models Projects Groups of 3 Proposals in two weeks (2/20) Topics: Soft errors in datapaths Soft errors in memory Integration
EE241 - Spring 2013 Advanced Digital Integrated Circuits Lecture 5: Transistor Models Projects Groups of 3 Proposals in two weeks (2/20) Topics: Soft errors in datapaths Soft errors in memory Integration
EE382V: Embedded System Design and Modeling
 EE382V: Embedded System Design and - Introduction Andreas Gerstlauer Electrical and Computer Engineering University of Texas at Austin gerstl@ece.utexas.edu : Outline Introduction Embedded systems System-level
EE382V: Embedded System Design and - Introduction Andreas Gerstlauer Electrical and Computer Engineering University of Texas at Austin gerstl@ece.utexas.edu : Outline Introduction Embedded systems System-level
High Performance Tor Experimentation from the Magic of Dynamic ELFs
 High Performance Tor Experimentation from the Magic of Dynamic ELFs Justin Tracey 1 Rob Jansen 2 Ian Goldberg 1 1 University of Waterloo 2 U.S. Naval Research Laboratory CSET 2018 Tracey, Jansen, Goldberg
High Performance Tor Experimentation from the Magic of Dynamic ELFs Justin Tracey 1 Rob Jansen 2 Ian Goldberg 1 1 University of Waterloo 2 U.S. Naval Research Laboratory CSET 2018 Tracey, Jansen, Goldberg
FIFO WITH OFFSETS HIGH SCHEDULABILITY WITH LOW OVERHEADS. RTAS 18 April 13, Björn Brandenburg
 FIFO WITH OFFSETS HIGH SCHEDULABILITY WITH LOW OVERHEADS RTAS 18 April 13, 2018 Mitra Nasri Rob Davis Björn Brandenburg FIFO SCHEDULING First-In-First-Out (FIFO) scheduling extremely simple very low overheads
FIFO WITH OFFSETS HIGH SCHEDULABILITY WITH LOW OVERHEADS RTAS 18 April 13, 2018 Mitra Nasri Rob Davis Björn Brandenburg FIFO SCHEDULING First-In-First-Out (FIFO) scheduling extremely simple very low overheads
Chapter 4. Pipelining Analogy. The Processor. Pipelined laundry: overlapping execution. Parallelism improves performance. Four loads: Non-stop:
 Chapter 4 The Processor Part II Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup p = 2n/(0.5n + 1.5) 4 =
Chapter 4 The Processor Part II Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup p = 2n/(0.5n + 1.5) 4 =
Design and Implementation of Complex Multiplier Using Compressors
 Design and Implementation of Complex Multiplier Using Compressors Abstract: In this paper, a low-power high speed Complex Multiplier using compressor circuit is proposed for fast digital arithmetic integrated
Design and Implementation of Complex Multiplier Using Compressors Abstract: In this paper, a low-power high speed Complex Multiplier using compressor circuit is proposed for fast digital arithmetic integrated
Best Instruction Per Cycle Formula >>>CLICK HERE<<<
 Best Instruction Per Cycle Formula 6 Performance tuning, 7 Perceived performance, 8 Performance Equation, 9 See also is the average instructions per cycle (IPC) for this benchmark. Even. Click Card to
Best Instruction Per Cycle Formula 6 Performance tuning, 7 Perceived performance, 8 Performance Equation, 9 See also is the average instructions per cycle (IPC) for this benchmark. Even. Click Card to
A New network multiplier using modified high order encoder and optimized hybrid adder in CMOS technology
 Inf. Sci. Lett. 2, No. 3, 159-164 (2013) 159 Information Sciences Letters An International Journal http://dx.doi.org/10.12785/isl/020305 A New network multiplier using modified high order encoder and optimized
Inf. Sci. Lett. 2, No. 3, 159-164 (2013) 159 Information Sciences Letters An International Journal http://dx.doi.org/10.12785/isl/020305 A New network multiplier using modified high order encoder and optimized
Exercise 3: Sound volume robot
 ETH Course 40-048-00L: Electronics for Physicists II (Digital) 1: Setup uc tools, introduction : Solder SMD Arduino Nano board 3: Build application around ATmega38P 4: Design your own PCB schematic 5:
ETH Course 40-048-00L: Electronics for Physicists II (Digital) 1: Setup uc tools, introduction : Solder SMD Arduino Nano board 3: Build application around ATmega38P 4: Design your own PCB schematic 5:
Table of Contents HOL ADV
 Table of Contents Lab Overview - - Horizon 7.1: Graphics Acceleartion for 3D Workloads and vgpu... 2 Lab Guidance... 3 Module 1-3D Options in Horizon 7 (15 minutes - Basic)... 5 Introduction... 6 3D Desktop
Table of Contents Lab Overview - - Horizon 7.1: Graphics Acceleartion for 3D Workloads and vgpu... 2 Lab Guidance... 3 Module 1-3D Options in Horizon 7 (15 minutes - Basic)... 5 Introduction... 6 3D Desktop
Game Architecture. 4/8/16: Multiprocessor Game Loops
 Game Architecture 4/8/16: Multiprocessor Game Loops Monolithic Dead simple to set up, but it can get messy Flow-of-control can be complex Top-level may have too much knowledge of underlying systems (gross
Game Architecture 4/8/16: Multiprocessor Game Loops Monolithic Dead simple to set up, but it can get messy Flow-of-control can be complex Top-level may have too much knowledge of underlying systems (gross
Introduction. Reading: Chapter 1. Courtesy of Dr. Dansereau, Dr. Brown, Dr. Vranesic, Dr. Harris, and Dr. Choi.
 Introduction Reading: Chapter 1 Courtesy of Dr. Dansereau, Dr. Brown, Dr. Vranesic, Dr. Harris, and Dr. Choi http://csce.uark.edu +1 (479) 575-6043 yrpeng@uark.edu Why study logic design? Obvious reasons
Introduction Reading: Chapter 1 Courtesy of Dr. Dansereau, Dr. Brown, Dr. Vranesic, Dr. Harris, and Dr. Choi http://csce.uark.edu +1 (479) 575-6043 yrpeng@uark.edu Why study logic design? Obvious reasons
EE19D Digital Electronics. Lecture 1: General Introduction
 EE19D Digital Electronics Lecture 1: General Introduction 1 What are we going to discuss? Some Definitions Digital and Analog Quantities Binary Digits, Logic Levels and Digital Waveforms Introduction to
EE19D Digital Electronics Lecture 1: General Introduction 1 What are we going to discuss? Some Definitions Digital and Analog Quantities Binary Digits, Logic Levels and Digital Waveforms Introduction to
CUDA-Accelerated Satellite Communication Demodulation
 CUDA-Accelerated Satellite Communication Demodulation Renliang Zhao, Ying Liu, Liheng Jian, Zhongya Wang School of Computer and Control University of Chinese Academy of Sciences Outline Motivation Related
CUDA-Accelerated Satellite Communication Demodulation Renliang Zhao, Ying Liu, Liheng Jian, Zhongya Wang School of Computer and Control University of Chinese Academy of Sciences Outline Motivation Related
Creating the Right Environment for Machine Learning Codesign. Cliff Young, Google AI
 Creating the Right Environment for Machine Learning Codesign Cliff Young, Google AI 1 Deep Learning has Reinvigorated Hardware GPUs AlexNet, Speech. TPUs Many Google applications: AlphaGo and Translate,
Creating the Right Environment for Machine Learning Codesign Cliff Young, Google AI 1 Deep Learning has Reinvigorated Hardware GPUs AlexNet, Speech. TPUs Many Google applications: AlphaGo and Translate,
Ps3 Computing Instruction Set Definition Reduced
 Ps3 Computing Instruction Set Definition Reduced (Compare scalar processors, whose instructions operate on single data items.) that feature instructions for a form of vector processing on multiple (vectorized)
Ps3 Computing Instruction Set Definition Reduced (Compare scalar processors, whose instructions operate on single data items.) that feature instructions for a form of vector processing on multiple (vectorized)
Multi-core Platforms for
 20 JUNE 2011 Multi-core Platforms for Immersive-Audio Applications Course: Advanced Computer Architectures Teacher: Prof. Cristina Silvano Student: Silvio La Blasca 771338 Introduction on Immersive-Audio
20 JUNE 2011 Multi-core Platforms for Immersive-Audio Applications Course: Advanced Computer Architectures Teacher: Prof. Cristina Silvano Student: Silvio La Blasca 771338 Introduction on Immersive-Audio
MS Project :Trading Accuracy for Power with an Under-designed Multiplier Architecture Parag Kulkarni Adviser : Prof. Puneet Gupta Electrical Eng.
 MS Project :Trading Accuracy for Power with an Under-designed Multiplier Architecture Parag Kulkarni Adviser : Prof. Puneet Gupta Electrical Eng., UCLA - http://nanocad.ee.ucla.edu/ 1 Outline Introduction
MS Project :Trading Accuracy for Power with an Under-designed Multiplier Architecture Parag Kulkarni Adviser : Prof. Puneet Gupta Electrical Eng., UCLA - http://nanocad.ee.ucla.edu/ 1 Outline Introduction
Computational Efficiency of the GF and the RMF Transforms for Quaternary Logic Functions on CPUs and GPUs
 5 th International Conference on Logic and Application LAP 2016 Dubrovnik, Croatia, September 19-23, 2016 Computational Efficiency of the GF and the RMF Transforms for Quaternary Logic Functions on CPUs
5 th International Conference on Logic and Application LAP 2016 Dubrovnik, Croatia, September 19-23, 2016 Computational Efficiency of the GF and the RMF Transforms for Quaternary Logic Functions on CPUs