SATSim: A Superscalar Architecture Trace Simulator Using Interactive Animation
|
|
|
- Dwight Jacobs
- 6 years ago
- Views:
Transcription
1 SATSim: A Superscalar Architecture Trace Simulator Using Interactive Animation Mark Wolff Linda Wills School of Electrical and Computer Engineering Georgia Institute of Technology {wolff,linda.wills}@ece.gatech.edu Abstract This paper describes an interactive animation tool, SATSim, which conveys superscalar architecture concepts. It has been used in an advanced undergraduate computer architecture course to visualize the complicated behavioral patterns of superscalar architectures, such as out-oforder execution, in-order commitment, and the impact of branch mispredictions and cache misses. SATSim allows students to interactively change hardware configuration parameters and to observe their effects visually in a more accessible manner than is currently possible with existing simulators or with traditional static media. Introduction As the complexity of superscalar architectures increases, the underlying concepts of dynamic scheduling and speculative execution become increasingly difficult to explain without some form of visualization. These architectures typically exhibit complex behavioral patterns involving concurrent, out-of-order execution of instructions on multiple functional units and the resolution of data and control dependencies on the fly. Static visual aids, such as diagrams on whiteboards, slides, or in textbooks, are limited in their ability to simultaneously convey both the structural relationships between components of a superscalar architecture and the temporal relationships between instructions as they progress through the pipeline and utilize architectural resources. An alternative is to use a superscalar architectural simulator. However, existing simulators [6,7,8,9] have been designed primarily for performing research, in which the focus is on accurately modeling the effects of architectural mechanisms so that their performance characteristics can be studied. Most of these simulators do not attempt to visually convey the behavior of the architectural mechanisms themselves and how they interact. They are often designed to accurately model a particular architecture and are often too complex to be suitable for students who are new to superscalar architecture concepts. More importantly, these simulators are typically not interactive: a machine configuration is specified and the simulation summarizes performance and resource utilization results as output. It is not easy to observe what is going on during the simulation (e.g., what the components are doing and how they interact), and it is not possible to interactively experiment with the simulation (e.g., to force a branch misprediction or a cache miss at any point during simulation in order to observe its effect). This paper describes SATSim: Superscalar Architecture Trace Simulator. SATSim is being used at Georgia Tech in an undergraduate seniorlevel course on advanced computer architecture. SATSim provides an animated and interactive visualization aid for teaching some of the important concepts associated with superscalar architectures. These concepts include out-of-order execution, inorder commitment, dynamic resolution of data dependencies using register renaming and reservation stations, and the performance effects of branch prediction accuracy and cache hit rates. Simulator Details SATSim reads instructions from a trace file and displays them as they progress through a simulated microarchitecture. The user can configure the microarchitecture by selecting the superscalar factor,
2 the number of reservation stations per execution unit, the number of reorder and rename buffer entries, and the number of each type of execution unit. In addition, the user can specify branch prediction accuracy, cache miss rates, and cache miss penalties, using the dialog box shown in Figure 1. SATSim models the behavior of the specified microarchitecture, avoiding processor-specific idiosyncrasies that tend to confuse the concepts. Branch prediction and cache functionality are generated statistically with manual override to illustrate the effect of a misprediction. The trace file input is in MIPs format. The simulator decodes all instructions into one of only five types, integer, floating point, branch, load, and store. Source and destination registers are decoded so that data dependencies and renaming resource utilization can be accurately portrayed. Figure 2 shows a screen shot of the animation in progress. Figure 3 shows the animation window as it progresses through six simulated clock cycles. In particular, instruction 5 is shown going from issue to commitment. Each instruction is given a three-digit name so that it can be displayed and tracked by the user as it progresses through the simulated processor. The simulator displays the status of all in-flight instructions. Instructions are shown as they occupy locations in the pipeline, rename buffer, reorder buffer, reservation stations, and execution units. Instructions acquire color as their destination register is renamed, and lose color once their result has been broadcast. The color, or lack of color, for the instruction providing data to each source register, is displayed for instructions that occupy a reservation station. The current color assignment, if any, for each of the registers is also displayed. The status of each instruction is updated on each simulated clock cycle. Running performance metrics are also updated and displayed on each clock cycle. The animation has three interactive features that are useful for explaining and understanding superscalar architecture concepts. The user can force the next fetched branch instruction to be mispredicted, and then observe the resulting performance impact. The user can force the next fetched line of instructions to miss in the instruction cache. And, the user can force the next load instruction that executes to miss in the data cache. During the simulation, the user has control of the animation speed. The animation can be set to update the display every 1, 10, 100, or 1000 clock cycles. The user can single step through the animation, set the animation to 1, 2, or 10 screen updates per second, or let it run as fast as possible. The user can also allow the simulation to run to the end of the trace file without updating the screen. When the simulation ends, the program writes pertinent performance and utilization data to a tabdelimited text file. Table 1 lists the data that is written to disk after each simulation. Date and Time All Simulation Parameters Trace File Name Total Cycles Number Instructions Committed Number of Each Instruction Type Fetched Total Icache Misses Total Miss Penalty Total Stall Cycles Total Dcache Misses Reorder Rename Integer Execution Floating Point Execution Branch Execution Memory Execution Integer Reservation Floating Point Reservation Branch Reservation Memory Reservation Table 1. Data Collection SATSim runs on Windows 9x or NT. The program was developed using Microsoft Visual C++ Version 6. Simulator Use The simulator is currently used in an advanced undergraduate computer architecture course to assist students with understanding superscalar architecture concepts. One associated assignment asks the students to discuss the effects of branch prediction accuracy and cache hit rates on the performance of superscalar architectures. Another assignment asks the student to explore the design space by varying the architectural parameters, and then discuss the tradeoffs between chip-area cost (based on a given cost model), cycle time, and architectural resources.
3 The simulator allows students to explore the design space. Then, the archived data allows for more thorough analysis of design tradeoffs. Through these assignments, the students were able to explore the difficult concepts of dynamic scheduling and speculative execution. Conclusions and Future Work SATSim and the associated assignments assist students with understanding superscalar architecture concepts. Significant improvement was observed, through quizzes and class participation, in the students comprehension, as compared to previous courses. SATSim conveys important fundamental concepts in superscalar architecture design and their associated nomenclature. Once this conceptual foundation is in place, more advanced concepts can be discussed, such as trace caches, branch predication, data prediction, vector processors, SIMD ISA extensions, and multiprocessor systems. Enhancements to SATSim include: an online help system will be incorporated, a browse function will be added for selecting input and output files, and a utility for running simulations in batch mode will be included. Real-time visualization of resource utilization information will also be added. [5] Yeager, K.C., The Mips R10000 Superscalar Microprocessor, IEEE Micro, April 1996, p [6] Douglas C. Burger and Todd M. Austin, The SimpleScalar Tool Set, Version 2.0, Computer Architecture News, 25 (3), pp , June, 1997[7] Moura, C., SuperDLX A Generic Superscalar Simulator, ACAPS Technical Memo 64, McGill University School of Computer Science. [8]DLXview, xview/ [9] Larry B. Hostetler & Brian Mirtich. DLXsim --- A Simulator for DLX The simulator can be downloaded from tml References [1] Hennesey, J.L., Patterson, D.A., Computer Architecture A Quantitative Approach, 2 nd. Ed., Morgan Kaufmann Publishers, [2] Flynn, M.J., Computer Architecture Pipelined and Parallel Processor design, Jones and Bartlett Publishers, [3] Song, S.P., Denman, M., Chang, J., The PowerPC 604 RISC Microprocessor, IEEE Micro, October 1994, p [4] Kessler, R.E., The Alpha Microprocessor, IEEE Micro, March 1999, p


4 Figure 1. Screenshot of the Trace Options dialog Figure 2. Screenshot of animation


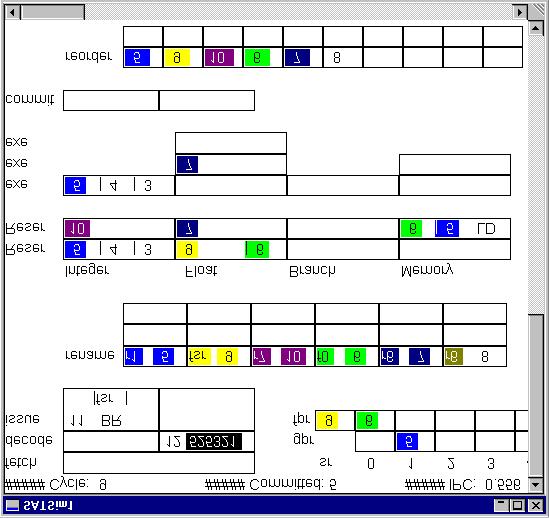

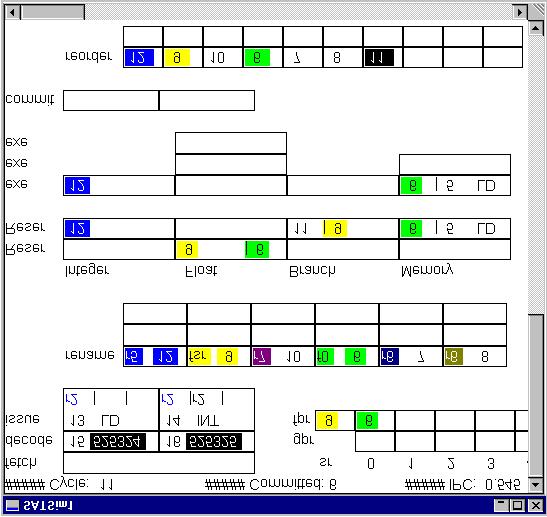
5 Figure 3. Sequence of Animation Steps
Chapter 16 - Instruction-Level Parallelism and Superscalar Processors
 Chapter 16 - Instruction-Level Parallelism and Superscalar Processors Luis Tarrataca luis.tarrataca@gmail.com CEFET-RJ L. Tarrataca Chapter 16 - Superscalar Processors 1 / 78 Table of Contents I 1 Overview
Chapter 16 - Instruction-Level Parallelism and Superscalar Processors Luis Tarrataca luis.tarrataca@gmail.com CEFET-RJ L. Tarrataca Chapter 16 - Superscalar Processors 1 / 78 Table of Contents I 1 Overview
Final Report: DBmbench
 18-741 Final Report: DBmbench Yan Ke (yke@cs.cmu.edu) Justin Weisz (jweisz@cs.cmu.edu) Dec. 8, 2006 1 Introduction Conventional database benchmarks, such as the TPC-C and TPC-H, are extremely computationally
18-741 Final Report: DBmbench Yan Ke (yke@cs.cmu.edu) Justin Weisz (jweisz@cs.cmu.edu) Dec. 8, 2006 1 Introduction Conventional database benchmarks, such as the TPC-C and TPC-H, are extremely computationally
Project 5: Optimizer Jason Ansel
 Project 5: Optimizer Jason Ansel Overview Project guidelines Benchmarking Library OoO CPUs Project Guidelines Use optimizations from lectures as your arsenal If you decide to implement one, look at Whale
Project 5: Optimizer Jason Ansel Overview Project guidelines Benchmarking Library OoO CPUs Project Guidelines Use optimizations from lectures as your arsenal If you decide to implement one, look at Whale
Chapter 4. Pipelining Analogy. The Processor. Pipelined laundry: overlapping execution. Parallelism improves performance. Four loads: Non-stop:
 Chapter 4 The Processor Part II Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup p = 2n/(0.5n + 1.5) 4 =
Chapter 4 The Processor Part II Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup p = 2n/(0.5n + 1.5) 4 =
Out-of-Order Execution. Register Renaming. Nima Honarmand
 Out-of-Order Execution & Register Renaming Nima Honarmand Out-of-Order (OOO) Execution (1) Essence of OOO execution is Dynamic Scheduling Dynamic scheduling: processor hardware determines instruction execution
Out-of-Order Execution & Register Renaming Nima Honarmand Out-of-Order (OOO) Execution (1) Essence of OOO execution is Dynamic Scheduling Dynamic scheduling: processor hardware determines instruction execution
Computer Science 246. Advanced Computer Architecture. Spring 2010 Harvard University. Instructor: Prof. David Brooks
 Advanced Computer Architecture Spring 2010 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture Outline Instruction-Level Parallelism Scoreboarding (A.8) Instruction Level Parallelism
Advanced Computer Architecture Spring 2010 Harvard University Instructor: Prof. dbrooks@eecs.harvard.edu Lecture Outline Instruction-Level Parallelism Scoreboarding (A.8) Instruction Level Parallelism
EN164: Design of Computing Systems Lecture 22: Processor / ILP 3
 EN164: Design of Computing Systems Lecture 22: Processor / ILP 3 Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
EN164: Design of Computing Systems Lecture 22: Processor / ILP 3 Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
Performance Evaluation of Recently Proposed Cache Replacement Policies
 University of Jordan Computer Engineering Department Performance Evaluation of Recently Proposed Cache Replacement Policies CPE 731: Advanced Computer Architecture Dr. Gheith Abandah Asma Abdelkarim January
University of Jordan Computer Engineering Department Performance Evaluation of Recently Proposed Cache Replacement Policies CPE 731: Advanced Computer Architecture Dr. Gheith Abandah Asma Abdelkarim January
Asanovic/Devadas Spring Pipeline Hazards. Krste Asanovic Laboratory for Computer Science M.I.T.
 Pipeline Hazards Krste Asanovic Laboratory for Computer Science M.I.T. Pipelined DLX Datapath without interlocks and jumps 31 0x4 RegDst RegWrite inst Inst rs1 rs2 rd1 ws wd rd2 GPRs Imm Ext A B OpSel
Pipeline Hazards Krste Asanovic Laboratory for Computer Science M.I.T. Pipelined DLX Datapath without interlocks and jumps 31 0x4 RegDst RegWrite inst Inst rs1 rs2 rd1 ws wd rd2 GPRs Imm Ext A B OpSel
EECS 470. Lecture 9. MIPS R10000 Case Study. Fall 2018 Jon Beaumont
 MIPS R10000 Case Study Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Multiprocessor SGI Origin Using MIPS R10K Many thanks to Prof. Martin and Roth of University of Pennsylvania for
MIPS R10000 Case Study Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Multiprocessor SGI Origin Using MIPS R10K Many thanks to Prof. Martin and Roth of University of Pennsylvania for
7/11/2012. Single Cycle (Review) CSE 2021: Computer Organization. Multi-Cycle Implementation. Single Cycle with Jump. Pipelining Analogy
 CSE 2021: Computer Organization. Multi-Cycle Implementation. Single Cycle with Jump. Pipelining Analogy") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10 CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan CSE-2021 July-12-2012 2 Single Cycle with Jump Multi-Cycle Implementation
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10 CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan CSE-2021 July-12-2012 2 Single Cycle with Jump Multi-Cycle Implementation
Instruction Level Parallelism Part II - Scoreboard
 Course on: Advanced Computer Architectures Instruction Level Parallelism Part II - Scoreboard Prof. Cristina Silvano Politecnico di Milano email: cristina.silvano@polimi.it 1 Basic Assumptions We consider
Course on: Advanced Computer Architectures Instruction Level Parallelism Part II - Scoreboard Prof. Cristina Silvano Politecnico di Milano email: cristina.silvano@polimi.it 1 Basic Assumptions We consider
Outline Simulators and such. What defines a simulator? What about emulation?
 Outline Simulators and such Mats Brorsson & Mladen Nikitovic ICT Dept of Electronic, Computer and Software Systems (ECS) What defines a simulator? Why are simulators needed? Classifications Case studies
Outline Simulators and such Mats Brorsson & Mladen Nikitovic ICT Dept of Electronic, Computer and Software Systems (ECS) What defines a simulator? Why are simulators needed? Classifications Case studies
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Out-of-Order Schedulers Data-Capture Scheduler Dispatch: read available operands from ARF/ROB, store in scheduler Commit: Missing operands filled in from bypass Issue: When
CSE 502: Computer Architecture Out-of-Order Schedulers Data-Capture Scheduler Dispatch: read available operands from ARF/ROB, store in scheduler Commit: Missing operands filled in from bypass Issue: When
ECE 4750 Computer Architecture, Fall 2016 T09 Advanced Processors: Superscalar Execution
 ECE 4750 Computer Architecture, Fall 2016 T09 Advanced Processors: Superscalar Execution School of Electrical and Computer Engineering Cornell University revision: 2016-11-28-17-33 1 In-Order Dual-Issue
ECE 4750 Computer Architecture, Fall 2016 T09 Advanced Processors: Superscalar Execution School of Electrical and Computer Engineering Cornell University revision: 2016-11-28-17-33 1 In-Order Dual-Issue
7/19/2012. IF for Load (Review) CSE 2021: Computer Organization. EX for Load (Review) ID for Load (Review) WB for Load (Review) MEM for Load (Review)
 CSE 2021: Computer Organization. EX for Load (Review) ID for Load (Review) WB for Load (Review) MEM for Load (Review)") CSE 2021: Computer Organization IF for Load (Review) Lecture-11 CPU Design : Pipelining-2 Review, Hazards Shakil M. Khan CSE-2021 July-19-2012 2 ID for Load (Review) EX for Load (Review) CSE-2021 July-19-2012
CSE 2021: Computer Organization IF for Load (Review) Lecture-11 CPU Design : Pipelining-2 Review, Hazards Shakil M. Khan CSE-2021 July-19-2012 2 ID for Load (Review) EX for Load (Review) CSE-2021 July-19-2012
CSE 2021: Computer Organization
 CSE 2021: Computer Organization Lecture-11 CPU Design : Pipelining-2 Review, Hazards Shakil M. Khan IF for Load (Review) CSE-2021 July-14-2011 2 ID for Load (Review) CSE-2021 July-14-2011 3 EX for Load
CSE 2021: Computer Organization Lecture-11 CPU Design : Pipelining-2 Review, Hazards Shakil M. Khan IF for Load (Review) CSE-2021 July-14-2011 2 ID for Load (Review) CSE-2021 July-14-2011 3 EX for Load
CMP 301B Computer Architecture. Appendix C
 CMP 301B Computer Architecture Appendix C Dealing with Exceptions What should be done when an exception arises and many instructions are in the pipeline??!! Force a trap instruction in the next IF stage
CMP 301B Computer Architecture Appendix C Dealing with Exceptions What should be done when an exception arises and many instructions are in the pipeline??!! Force a trap instruction in the next IF stage
Precise State Recovery. Out-of-Order Pipelines
 Precise State Recovery in Out-of-Order Pipelines Nima Honarmand Recall Our Generic OOO Pipeline Instruction flow (pipeline front-end) is in-order Register and memory execution are OOO And, we need a final
Precise State Recovery in Out-of-Order Pipelines Nima Honarmand Recall Our Generic OOO Pipeline Instruction flow (pipeline front-end) is in-order Register and memory execution are OOO And, we need a final
Overview. 1 Trends in Microprocessor Architecture. Computer architecture. Computer architecture
 Overview 1 Trends in Microprocessor Architecture R05 Robert Mullins Computer architecture Scaling performance and CMOS Where have performance gains come from? Modern superscalar processors The limits of
Overview 1 Trends in Microprocessor Architecture R05 Robert Mullins Computer architecture Scaling performance and CMOS Where have performance gains come from? Modern superscalar processors The limits of
EECS 470 Lecture 8. P6 µarchitecture. Fall 2018 Jon Beaumont Core 2 Microarchitecture
 P6 µarchitecture Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Core 2 Microarchitecture Many thanks to Prof. Martin and Roth of University of Pennsylvania for most of these slides. Portions
P6 µarchitecture Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Core 2 Microarchitecture Many thanks to Prof. Martin and Roth of University of Pennsylvania for most of these slides. Portions
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier
 Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science !!! Basic MIPS integer pipeline Branches with one
Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science !!! Basic MIPS integer pipeline Branches with one
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Out-of-Order Execution and Register Rename In Search of Parallelism rivial Parallelism is limited What is trivial parallelism? In-order: sequential instructions do not have
CSE 502: Computer Architecture Out-of-Order Execution and Register Rename In Search of Parallelism rivial Parallelism is limited What is trivial parallelism? In-order: sequential instructions do not have
Quantifying the Complexity of Superscalar Processors
 Quantifying the Complexity of Superscalar Processors Subbarao Palacharla y Norman P. Jouppi z James E. Smith? y Computer Sciences Department University of Wisconsin-Madison Madison, WI 53706, USA subbarao@cs.wisc.edu
Quantifying the Complexity of Superscalar Processors Subbarao Palacharla y Norman P. Jouppi z James E. Smith? y Computer Sciences Department University of Wisconsin-Madison Madison, WI 53706, USA subbarao@cs.wisc.edu
Dynamic Scheduling I
 basic pipeline started with single, in-order issue, single-cycle operations have extended this basic pipeline with multi-cycle operations multiple issue (superscalar) now: dynamic scheduling (out-of-order
basic pipeline started with single, in-order issue, single-cycle operations have extended this basic pipeline with multi-cycle operations multiple issue (superscalar) now: dynamic scheduling (out-of-order
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Out-of-Order Execution and Register Rename In Search of Parallelism rivial Parallelism is limited What is trivial parallelism? In-order: sequential instructions do not have
CSE 502: Computer Architecture Out-of-Order Execution and Register Rename In Search of Parallelism rivial Parallelism is limited What is trivial parallelism? In-order: sequential instructions do not have
On the Rules of Low-Power Design
 On the Rules of Low-Power Design (and Why You Should Break Them) Prof. Todd Austin University of Michigan austin@umich.edu A long time ago, in a not so far away place The Rules of Low-Power Design P =
On the Rules of Low-Power Design (and Why You Should Break Them) Prof. Todd Austin University of Michigan austin@umich.edu A long time ago, in a not so far away place The Rules of Low-Power Design P =
Processors Processing Processors. The meta-lecture
 Simulators 5SIA0 Processors Processing Processors The meta-lecture Why Simulators? Your Friend Harm Why Simulators? Harm Loves Tractors Harm Why Simulators? The outside world Unfortunately for Harm you
Simulators 5SIA0 Processors Processing Processors The meta-lecture Why Simulators? Your Friend Harm Why Simulators? Harm Loves Tractors Harm Why Simulators? The outside world Unfortunately for Harm you
Pipelined Processor Design
 Pipelined Processor Design COE 38 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Pipelining versus Serial
Pipelined Processor Design COE 38 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Pipelining versus Serial
CS61c: Introduction to Synchronous Digital Systems
 CS61c: Introduction to Synchronous Digital Systems J. Wawrzynek March 4, 2006 Optional Reading: P&H, Appendix B 1 Instruction Set Architecture Among the topics we studied thus far this semester, was the
CS61c: Introduction to Synchronous Digital Systems J. Wawrzynek March 4, 2006 Optional Reading: P&H, Appendix B 1 Instruction Set Architecture Among the topics we studied thus far this semester, was the
EE 382C EMBEDDED SOFTWARE SYSTEMS. Literature Survey Report. Characterization of Embedded Workloads. Ajay Joshi. March 30, 2004
 EE 382C EMBEDDED SOFTWARE SYSTEMS Literature Survey Report Characterization of Embedded Workloads Ajay Joshi March 30, 2004 ABSTRACT Security applications are a class of emerging workloads that will play
EE 382C EMBEDDED SOFTWARE SYSTEMS Literature Survey Report Characterization of Embedded Workloads Ajay Joshi March 30, 2004 ABSTRACT Security applications are a class of emerging workloads that will play
Memory-Level Parallelism Aware Fetch Policies for Simultaneous Multithreading Processors
 Memory-Level Parallelism Aware Fetch Policies for Simultaneous Multithreading Processors STIJN EYERMAN and LIEVEN EECKHOUT Ghent University A thread executing on a simultaneous multithreading (SMT) processor
Memory-Level Parallelism Aware Fetch Policies for Simultaneous Multithreading Processors STIJN EYERMAN and LIEVEN EECKHOUT Ghent University A thread executing on a simultaneous multithreading (SMT) processor
IF ID EX MEM WB 400 ps 225 ps 350 ps 450 ps 300 ps
 CSE 30321 Computer Architecture I Fall 2011 Homework 06 Pipelined Processors 75 points Assigned: November 1, 2011 Due: November 8, 2011 PLEASE DO THE ASSIGNMENT ON THIS HANDOUT!!! Problem 1: (15 points)
CSE 30321 Computer Architecture I Fall 2011 Homework 06 Pipelined Processors 75 points Assigned: November 1, 2011 Due: November 8, 2011 PLEASE DO THE ASSIGNMENT ON THIS HANDOUT!!! Problem 1: (15 points)
EECS 470 Lecture 5. Intro to Dynamic Scheduling (Scoreboarding) Fall 2018 Jon Beaumont
 Fall 2018 Jon Beaumont") Intro to Dynamic Scheduling (Scoreboarding) Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Many thanks to Prof. Martin and Roth of University of Pennsylvania for most of these slides.
Intro to Dynamic Scheduling (Scoreboarding) Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Many thanks to Prof. Martin and Roth of University of Pennsylvania for most of these slides.
EECS 470. Tomasulo s Algorithm. Lecture 4 Winter 2018
 omasulo s Algorithm Winter 2018 Slides developed in part by Profs. Austin, Brehob, Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, yson, Vijaykumar, and Wenisch of Carnegie Mellon University,
omasulo s Algorithm Winter 2018 Slides developed in part by Profs. Austin, Brehob, Falsafi, Hill, Hoe, Lipasti, Martin, Roth, Shen, Smith, Sohi, yson, Vijaykumar, and Wenisch of Carnegie Mellon University,
Design Challenges in Multi-GHz Microprocessors
 Design Challenges in Multi-GHz Microprocessors Bill Herrick Director, Alpha Microprocessor Development www.compaq.com Introduction Moore s Law ( Law (the trend that the demand for IC functions and the
Design Challenges in Multi-GHz Microprocessors Bill Herrick Director, Alpha Microprocessor Development www.compaq.com Introduction Moore s Law ( Law (the trend that the demand for IC functions and the
Lecture Topics. Announcements. Today: Pipelined Processors (P&H ) Next: continued. Milestone #4 (due 2/23) Milestone #5 (due 3/2)
 Next: continued. Milestone #4 (due 2/23) Milestone #5 (due 3/2)") Lecture Topics Today: Pipelined Processors (P&H 4.5-4.10) Next: continued 1 Announcements Milestone #4 (due 2/23) Milestone #5 (due 3/2) 2 1 ISA Implementations Three different strategies: single-cycle
Lecture Topics Today: Pipelined Processors (P&H 4.5-4.10) Next: continued 1 Announcements Milestone #4 (due 2/23) Milestone #5 (due 3/2) 2 1 ISA Implementations Three different strategies: single-cycle
COTSon: Infrastructure for system-level simulation
 COTSon: Infrastructure for system-level simulation Ayose Falcón, Paolo Faraboschi, Daniel Ortega HP Labs Exascale Computing Lab http://sites.google.com/site/hplabscotson MICRO-41 tutorial November 9, 28
COTSon: Infrastructure for system-level simulation Ayose Falcón, Paolo Faraboschi, Daniel Ortega HP Labs Exascale Computing Lab http://sites.google.com/site/hplabscotson MICRO-41 tutorial November 9, 28
Improving GPU Performance via Large Warps and Two-Level Warp Scheduling
 Improving GPU Performance via Large Warps and Two-Level Warp Scheduling Veynu Narasiman The University of Texas at Austin Michael Shebanow NVIDIA Chang Joo Lee Intel Rustam Miftakhutdinov The University
Improving GPU Performance via Large Warps and Two-Level Warp Scheduling Veynu Narasiman The University of Texas at Austin Michael Shebanow NVIDIA Chang Joo Lee Intel Rustam Miftakhutdinov The University
Using Variable-MHz Microprocessors to Efficiently Handle Uncertainty in Real-Time Systems
 Using Variable-MHz Microprocessors to Efficiently Handle Uncertainty in Real-Time Systems Eric Rotenberg Center for Embedded Systems Research (CESR) Department of Electrical & Computer Engineering North
Using Variable-MHz Microprocessors to Efficiently Handle Uncertainty in Real-Time Systems Eric Rotenberg Center for Embedded Systems Research (CESR) Department of Electrical & Computer Engineering North
An Evaluation of Speculative Instruction Execution on Simultaneous Multithreaded Processors
 An Evaluation of Speculative Instruction Execution on Simultaneous Multithreaded Processors STEVEN SWANSON, LUKE K. McDOWELL, MICHAEL M. SWIFT, SUSAN J. EGGERS and HENRY M. LEVY University of Washington
An Evaluation of Speculative Instruction Execution on Simultaneous Multithreaded Processors STEVEN SWANSON, LUKE K. McDOWELL, MICHAEL M. SWIFT, SUSAN J. EGGERS and HENRY M. LEVY University of Washington
Low-Power Design for Embedded Processors
 Low-Power Design for Embedded Processors BILL MOYER, MEMBER, IEEE Invited Paper Minimization of power consumption in portable and batterypowered embedded systems has become an important aspect of processor
Low-Power Design for Embedded Processors BILL MOYER, MEMBER, IEEE Invited Paper Minimization of power consumption in portable and batterypowered embedded systems has become an important aspect of processor
Computer Architecture A Quantitative Approach
 Computer Architecture A Quantitative Approach Fourth Edition John L. Hennessy Stanford University David A. Patterson University of California at Berkeley With Contributions by Andrea C. Arpaci-Dusseau
Computer Architecture A Quantitative Approach Fourth Edition John L. Hennessy Stanford University David A. Patterson University of California at Berkeley With Contributions by Andrea C. Arpaci-Dusseau
COSC4201. Scoreboard
 COSC4201 Scoreboard Prof. Mokhtar Aboelaze York University Based on Slides by Prof. L. Bhuyan (UCR) Prof. M. Shaaban (RIT) 1 Overcoming Data Hazards with Dynamic Scheduling In the pipeline, if there is
COSC4201 Scoreboard Prof. Mokhtar Aboelaze York University Based on Slides by Prof. L. Bhuyan (UCR) Prof. M. Shaaban (RIT) 1 Overcoming Data Hazards with Dynamic Scheduling In the pipeline, if there is
CS429: Computer Organization and Architecture
 CS429: Computer Organization and Architecture Dr. Bill Young Department of Computer Sciences University of Texas at Austin Last updated: November 8, 2017 at 09:27 CS429 Slideset 14: 1 Overview What s wrong
CS429: Computer Organization and Architecture Dr. Bill Young Department of Computer Sciences University of Texas at Austin Last updated: November 8, 2017 at 09:27 CS429 Slideset 14: 1 Overview What s wrong
Ramon Canal NCD Master MIRI. NCD Master MIRI 1
 Wattch, Hotspot, Hotleakage, McPAT http://www.eecs.harvard.edu/~dbrooks/wattch-form.html http://lava.cs.virginia.edu/hotspot http://lava.cs.virginia.edu/hotleakage http://www.hpl.hp.com/research/mcpat/
Wattch, Hotspot, Hotleakage, McPAT http://www.eecs.harvard.edu/~dbrooks/wattch-form.html http://lava.cs.virginia.edu/hotspot http://lava.cs.virginia.edu/hotleakage http://www.hpl.hp.com/research/mcpat/
U. Wisconsin CS/ECE 752 Advanced Computer Architecture I
 U. Wisconsin CS/ECE 752 Advanced Computer Architecture I Prof. Karu Sankaralingam Unit 5: Dynamic Scheduling I Slides developed by Amir Roth of University of Pennsylvania with sources that included University
U. Wisconsin CS/ECE 752 Advanced Computer Architecture I Prof. Karu Sankaralingam Unit 5: Dynamic Scheduling I Slides developed by Amir Roth of University of Pennsylvania with sources that included University
IF ID EX MEM WB 400 ps 225 ps 350 ps 450 ps 300 ps
 CSE 30321 Computer Architecture I Fall 2010 Homework 06 Pipelined Processors 85 points Assigned: November 2, 2010 Due: November 9, 2010 PLEASE DO THE ASSIGNMENT ON THIS HANDOUT!!! Problem 1: (25 points)
CSE 30321 Computer Architecture I Fall 2010 Homework 06 Pipelined Processors 85 points Assigned: November 2, 2010 Due: November 9, 2010 PLEASE DO THE ASSIGNMENT ON THIS HANDOUT!!! Problem 1: (25 points)
CLIPPER: Counter-based Low Impact Processor Power Estimation at Run-time
 CLIPPER: Counter-based Low Impact Processor Power Estimation at Run-time Jorgen Peddersen, Sri Parameswaran School of Computer Science and Engineering The University of New South Wales & National ICT Australia
CLIPPER: Counter-based Low Impact Processor Power Estimation at Run-time Jorgen Peddersen, Sri Parameswaran School of Computer Science and Engineering The University of New South Wales & National ICT Australia
Copyright The McGraw-Hill Companies, Inc. Permission required for reproduction or display. Computing Layers
 Chapter 3 Digital Logic Structures Original slides from Gregory Byrd, North Carolina State University Modified by Chris Wilcox, Sanjay Rajopadhye Colorado State University Computing Layers Problems Algorithms
Chapter 3 Digital Logic Structures Original slides from Gregory Byrd, North Carolina State University Modified by Chris Wilcox, Sanjay Rajopadhye Colorado State University Computing Layers Problems Algorithms
Dynamic Scheduling II
 so far: dynamic scheduling (out-of-order execution) Scoreboard omasulo s algorithm register renaming: removing artificial dependences (WAR/WAW) now: out-of-order execution + precise state advanced topic:
so far: dynamic scheduling (out-of-order execution) Scoreboard omasulo s algorithm register renaming: removing artificial dependences (WAR/WAW) now: out-of-order execution + precise state advanced topic:
Tomasolu s s Algorithm
 omasolu s s Algorithm Fall 2007 Prof. homas Wenisch http://www.eecs.umich.edu/courses/eecs4 70 Floating Point Buffers (FLB) ag ag ag Storage Bus Floating Point 4 3 Buffers FLB 6 5 5 4 Control 2 1 1 Result
omasolu s s Algorithm Fall 2007 Prof. homas Wenisch http://www.eecs.umich.edu/courses/eecs4 70 Floating Point Buffers (FLB) ag ag ag Storage Bus Floating Point 4 3 Buffers FLB 6 5 5 4 Control 2 1 1 Result
Computer Elements and Datapath. Microarchitecture Implementation of an ISA
 6.823, L5--1 Computer Elements and atapath Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 status lines Microarchitecture Implementation of an ISA ler control points 6.823, L5--2
6.823, L5--1 Computer Elements and atapath Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 status lines Microarchitecture Implementation of an ISA ler control points 6.823, L5--2
Dynamic MIPS Rate Stabilization in Out-of-Order Processors
 Dynamic Rate Stabilization in Out-of-Order Processors Jinho Suh and Michel Dubois Ming Hsieh Dept of EE University of Southern California Outline Motivation Performance Variability of an Out-of-Order Processor
Dynamic Rate Stabilization in Out-of-Order Processors Jinho Suh and Michel Dubois Ming Hsieh Dept of EE University of Southern California Outline Motivation Performance Variability of an Out-of-Order Processor
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Speculation and raps in Out-of-Order Cores What is wrong with omasulo s? Branch instructions Need branch prediction to guess what to fetch next Need speculative execution
CSE 502: Computer Architecture Speculation and raps in Out-of-Order Cores What is wrong with omasulo s? Branch instructions Need branch prediction to guess what to fetch next Need speculative execution
Problem: hazards delay instruction completion & increase the CPI. Compiler scheduling (static scheduling) reduces impact of hazards
 reduces impact of hazards") Dynamic Scheduling Pipelining: Issue instructions in every cycle (CPI 1) Problem: hazards delay instruction completion & increase the CPI Compiler scheduling (static scheduling) reduces impact of hazards
Dynamic Scheduling Pipelining: Issue instructions in every cycle (CPI 1) Problem: hazards delay instruction completion & increase the CPI Compiler scheduling (static scheduling) reduces impact of hazards
Instruction Level Parallelism III: Dynamic Scheduling
 Instruction Level Parallelism III: Dynamic Scheduling Reading: Appendix A (A-67) H&P Chapter 2 Instruction Level Parallelism III: Dynamic Scheduling 1 his Unit: Dynamic Scheduling Application OS Compiler
Instruction Level Parallelism III: Dynamic Scheduling Reading: Appendix A (A-67) H&P Chapter 2 Instruction Level Parallelism III: Dynamic Scheduling 1 his Unit: Dynamic Scheduling Application OS Compiler
Inherent Time Redundancy (ITR): Using Program Repetition for Low-Overhead Fault Tolerance
: Using Program Repetition for Low-Overhead Fault Tolerance") Inherent Time Redundancy (ITR): Using Program Repetition for Low-Overhead Fault Tolerance Vimal Reddy, Eric Rotenberg Center for Efficient, Secure and Reliable Computing, ECE, North Carolina State University
Inherent Time Redundancy (ITR): Using Program Repetition for Low-Overhead Fault Tolerance Vimal Reddy, Eric Rotenberg Center for Efficient, Secure and Reliable Computing, ECE, North Carolina State University
Computer Architecture ( L), Fall 2017 HW 3: Branch handling and GPU SOLUTIONS
, Fall 2017 HW 3: Branch handling and GPU SOLUTIONS") Computer Architecture (263-2210-00L), Fall 2017 HW 3: Branch handling and GPU SOLUTIONS Instructor: Prof. Onur Mutlu TAs: Hasan Hassan, Arash Tavakkol, Mohammad Sadr, Lois Orosa, Juan Gomez Luna Assigned:
Computer Architecture (263-2210-00L), Fall 2017 HW 3: Branch handling and GPU SOLUTIONS Instructor: Prof. Onur Mutlu TAs: Hasan Hassan, Arash Tavakkol, Mohammad Sadr, Lois Orosa, Juan Gomez Luna Assigned:
Mitigating Inductive Noise in SMT Processors
 Mitigating Inductive Noise in SMT Processors Wael El-Essawy and David H. Albonesi Department of Electrical and Computer Engineering, University of Rochester ABSTRACT Simultaneous Multi-Threading, although
Mitigating Inductive Noise in SMT Processors Wael El-Essawy and David H. Albonesi Department of Electrical and Computer Engineering, University of Rochester ABSTRACT Simultaneous Multi-Threading, although
CS Computer Architecture Spring Lecture 04: Understanding Performance
 CS 35101 Computer Architecture Spring 2008 Lecture 04: Understanding Performance Taken from Mary Jane Irwin (www.cse.psu.edu/~mji) and Kevin Schaffer [Adapted from Computer Organization and Design, Patterson
CS 35101 Computer Architecture Spring 2008 Lecture 04: Understanding Performance Taken from Mary Jane Irwin (www.cse.psu.edu/~mji) and Kevin Schaffer [Adapted from Computer Organization and Design, Patterson
Pre-Silicon Validation of Hyper-Threading Technology
 Pre-Silicon Validation of Hyper-Threading Technology David Burns, Desktop Platforms Group, Intel Corp. Index words: microprocessor, validation, bugs, verification ABSTRACT Hyper-Threading Technology delivers
Pre-Silicon Validation of Hyper-Threading Technology David Burns, Desktop Platforms Group, Intel Corp. Index words: microprocessor, validation, bugs, verification ABSTRACT Hyper-Threading Technology delivers
FPGA Based 70MHz Digital Receiver for RADAR Applications
 Technology Volume 1, Issue 1, July-September, 2013, pp. 01-07, IASTER 2013 www.iaster.com, Online: 2347-6109, Print: 2348-0017 FPGA Based 70MHz Digital Receiver for RADAR Applications ABSTRACT Dr. M. Kamaraju
Technology Volume 1, Issue 1, July-September, 2013, pp. 01-07, IASTER 2013 www.iaster.com, Online: 2347-6109, Print: 2348-0017 FPGA Based 70MHz Digital Receiver for RADAR Applications ABSTRACT Dr. M. Kamaraju
Evolution of DSP Processors. Kartik Kariya EE, IIT Bombay
 Evolution of DSP Processors Kartik Kariya EE, IIT Bombay Agenda Expected features of DSPs Brief overview of early DSPs Multi-issue DSPs Case Study: VLIW based Processor (SPXK5) for Mobile Applications
Evolution of DSP Processors Kartik Kariya EE, IIT Bombay Agenda Expected features of DSPs Brief overview of early DSPs Multi-issue DSPs Case Study: VLIW based Processor (SPXK5) for Mobile Applications
DAT105: Computer Architecture
 Department of Computer Science & Engineering Chalmers University of Techlogy DAT05: Computer Architecture Exercise 6 (Old exam questions) By Minh Quang Do 2007-2-2 Question 4a [2006/2/22] () Loop: LD F0,0(R)
Department of Computer Science & Engineering Chalmers University of Techlogy DAT05: Computer Architecture Exercise 6 (Old exam questions) By Minh Quang Do 2007-2-2 Question 4a [2006/2/22] () Loop: LD F0,0(R)
DSP VLSI Design. DSP Systems. Byungin Moon. Yonsei University
 Byungin Moon Yonsei University Outline What is a DSP system? Why is important DSP? Advantages of DSP systems over analog systems Example DSP applications Characteristics of DSP systems Sample rates Clock
Byungin Moon Yonsei University Outline What is a DSP system? Why is important DSP? Advantages of DSP systems over analog systems Example DSP applications Characteristics of DSP systems Sample rates Clock
6.S084 Tutorial Problems L19 Control Hazards in Pipelined Processors
 6.S084 Tutorial Problems L19 Control Hazards in Pipelined Processors Options for dealing with data and control hazards: stall, bypass, speculate 6.S084 Worksheet - 1 of 10 - L19 Control Hazards in Pipelined
6.S084 Tutorial Problems L19 Control Hazards in Pipelined Processors Options for dealing with data and control hazards: stall, bypass, speculate 6.S084 Worksheet - 1 of 10 - L19 Control Hazards in Pipelined
Parallel architectures Electronic Computers LM
 Parallel architectures Electronic Computers LM 1 Architecture Architecture: functional behaviour of a computer. For instance a processor which executes DLX code Implementation: a logical network implementing
Parallel architectures Electronic Computers LM 1 Architecture Architecture: functional behaviour of a computer. For instance a processor which executes DLX code Implementation: a logical network implementing
Lecture Topics. Announcements. Today: Memory Management (Stallings, chapter ) Next: continued. Self-Study Exercise #6. Project #4 (due 10/11)
 Next: continued. Self-Study Exercise #6. Project #4 (due 10/11)") Lecture Topics Today: Memory Management (Stallings, chapter 7.1-7.4) Next: continued 1 Announcements Self-Study Exercise #6 Project #4 (due 10/11) Project #5 (due 10/18) 2 Memory Hierarchy 3 Memory Hierarchy
Lecture Topics Today: Memory Management (Stallings, chapter 7.1-7.4) Next: continued 1 Announcements Self-Study Exercise #6 Project #4 (due 10/11) Project #5 (due 10/18) 2 Memory Hierarchy 3 Memory Hierarchy
Instructor: Dr. Mainak Chaudhuri. Instructor: Dr. S. K. Aggarwal. Instructor: Dr. Rajat Moona
 NPTEL Online - IIT Kanpur Instructor: Dr. Mainak Chaudhuri Instructor: Dr. S. K. Aggarwal Course Name: Department: Program Optimization for Multi-core Architecture Computer Science and Engineering IIT
NPTEL Online - IIT Kanpur Instructor: Dr. Mainak Chaudhuri Instructor: Dr. S. K. Aggarwal Course Name: Department: Program Optimization for Multi-core Architecture Computer Science and Engineering IIT
CS521 CSE IITG 11/23/2012
 Parallel Decoding and issue Parallel execution Preserving the sequential consistency of execution and exception processing 1 slide 2 Decode/issue data Issue bound fetch Dispatch bound fetch RS RS RS RS
Parallel Decoding and issue Parallel execution Preserving the sequential consistency of execution and exception processing 1 slide 2 Decode/issue data Issue bound fetch Dispatch bound fetch RS RS RS RS
CSE502: Computer Architecture Welcome to CSE 502
 Welcome to CSE 502 Introduction & Review Today s Lecture Course Overview Course Topics Grading Logistics Academic Integrity Policy Homework Quiz Key basic concepts for Computer Architecture Course Overview
Welcome to CSE 502 Introduction & Review Today s Lecture Course Overview Course Topics Grading Logistics Academic Integrity Policy Homework Quiz Key basic concepts for Computer Architecture Course Overview
Architectural Core Salvaging in a Multi-Core Processor for Hard-Error Tolerance
 Architectural Core Salvaging in a Multi-Core Processor for Hard-Error Tolerance Michael D. Powell, Arijit Biswas, Shantanu Gupta, and Shubu Mukherjee SPEARS Group, Intel Massachusetts EECS, University
Architectural Core Salvaging in a Multi-Core Processor for Hard-Error Tolerance Michael D. Powell, Arijit Biswas, Shantanu Gupta, and Shubu Mukherjee SPEARS Group, Intel Massachusetts EECS, University
An ahead pipelined alloyed perceptron with single cycle access time
 An ahead pipelined alloyed perceptron with single cycle access time David Tarjan Dept. of Computer Science University of Virginia Charlottesville, VA 22904 dtarjan@cs.virginia.edu Kevin Skadron Dept. of
An ahead pipelined alloyed perceptron with single cycle access time David Tarjan Dept. of Computer Science University of Virginia Charlottesville, VA 22904 dtarjan@cs.virginia.edu Kevin Skadron Dept. of
Efficiently Exploiting Memory Level Parallelism on Asymmetric Coupled Cores in the Dark Silicon Era
 28 Efficiently Exploiting Memory Level Parallelism on Asymmetric Coupled Cores in the Dark Silicon Era GEORGE PATSILARAS, NIKET K. CHOUDHARY, and JAMES TUCK, North Carolina State University Extracting
28 Efficiently Exploiting Memory Level Parallelism on Asymmetric Coupled Cores in the Dark Silicon Era GEORGE PATSILARAS, NIKET K. CHOUDHARY, and JAMES TUCK, North Carolina State University Extracting
An Overview of Computer Architecture and System Simulation
 An Overview of Computer Architecture and System Simulation J. Manuel Colmenar José L. Risco-Martín and Juan Lanchares C.E.S. Felipe II Dept. of Computer Architecture and Automation U. Complutense de Madrid
An Overview of Computer Architecture and System Simulation J. Manuel Colmenar José L. Risco-Martín and Juan Lanchares C.E.S. Felipe II Dept. of Computer Architecture and Automation U. Complutense de Madrid
CS 110 Computer Architecture Lecture 11: Pipelining
 CS 110 Computer Architecture Lecture 11: Pipelining Instructor: Sören Schwertfeger http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on
CS 110 Computer Architecture Lecture 11: Pipelining Instructor: Sören Schwertfeger http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on
Exploring Heterogeneity within a Core for Improved Power Efficiency
 Computer Engineering Exploring Heterogeneity within a Core for Improved Power Efficiency Sudarshan Srinivasan Nithesh Kurella Israel Koren Sandip Kundu May 2, 215 CE Tech Report # 6 Available at http://www.eng.biu.ac.il/segalla/computer-engineering-tech-reports/
Computer Engineering Exploring Heterogeneity within a Core for Improved Power Efficiency Sudarshan Srinivasan Nithesh Kurella Israel Koren Sandip Kundu May 2, 215 CE Tech Report # 6 Available at http://www.eng.biu.ac.il/segalla/computer-engineering-tech-reports/
CS4617 Computer Architecture
 1/26 CS4617 Computer Architecture Lecture 2 Dr J Vaughan September 10, 2014 2/26 Amdahl s Law Speedup = Execution time for entire task without using enhancement Execution time for entire task using enhancement
1/26 CS4617 Computer Architecture Lecture 2 Dr J Vaughan September 10, 2014 2/26 Amdahl s Law Speedup = Execution time for entire task without using enhancement Execution time for entire task using enhancement
Power Issues with Embedded Systems. Rabi Mahapatra Computer Science
 Power Issues with Embedded Systems Rabi Mahapatra Computer Science Plan for today Some Power Models Familiar with technique to reduce power consumption Reading assignment: paper by Bill Moyer on Low-Power
Power Issues with Embedded Systems Rabi Mahapatra Computer Science Plan for today Some Power Models Familiar with technique to reduce power consumption Reading assignment: paper by Bill Moyer on Low-Power
DeCoR: A Delayed Commit and Rollback Mechanism for Handling Inductive Noise in Processors
 DeCoR: A Delayed Commit and Rollback Mechanism for Handling Inductive Noise in Processors Meeta S. Gupta, Krishna K. Rangan, Michael D. Smith, Gu-Yeon Wei and David Brooks School of Engineering and Applied
DeCoR: A Delayed Commit and Rollback Mechanism for Handling Inductive Noise in Processors Meeta S. Gupta, Krishna K. Rangan, Michael D. Smith, Gu-Yeon Wei and David Brooks School of Engineering and Applied
A High Definition Motion JPEG Encoder Based on Epuma Platform
 Available online at www.sciencedirect.com Procedia Engineering 29 (2012) 2371 2375 2012 International Workshop on Information and Electronics Engineering (IWIEE) A High Definition Motion JPEG Encoder Based
Available online at www.sciencedirect.com Procedia Engineering 29 (2012) 2371 2375 2012 International Workshop on Information and Electronics Engineering (IWIEE) A High Definition Motion JPEG Encoder Based
MLP-Aware Runahead Threads in a Simultaneous Multithreading Processor
 MLP-Aware Runahead Threads in a Simultaneous Multithreading Processor Kenzo Van Craeynest, Stijn Eyerman, and Lieven Eeckhout Department of Electronics and Information Systems (ELIS), Ghent University,
MLP-Aware Runahead Threads in a Simultaneous Multithreading Processor Kenzo Van Craeynest, Stijn Eyerman, and Lieven Eeckhout Department of Electronics and Information Systems (ELIS), Ghent University,
Meltdown & Spectre. Side-channels considered harmful. Qualcomm Mobile Security Summit May, San Diego, CA. Moritz Lipp
 Meltdown & Spectre Side-channels considered harmful Qualcomm Mobile Security Summit 2018 17 May, 2018 - San Diego, CA Moritz Lipp (@mlqxyz) Michael Schwarz (@misc0110) Flashback Qualcomm Mobile Security
Meltdown & Spectre Side-channels considered harmful Qualcomm Mobile Security Summit 2018 17 May, 2018 - San Diego, CA Moritz Lipp (@mlqxyz) Michael Schwarz (@misc0110) Flashback Qualcomm Mobile Security
Compiler Optimisation
 Compiler Optimisation 6 Instruction Scheduling Hugh Leather IF 1.18a hleather@inf.ed.ac.uk Institute for Computing Systems Architecture School of Informatics University of Edinburgh 2018 Introduction This
Compiler Optimisation 6 Instruction Scheduling Hugh Leather IF 1.18a hleather@inf.ed.ac.uk Institute for Computing Systems Architecture School of Informatics University of Edinburgh 2018 Introduction This
Department Computer Science and Engineering IIT Kanpur
 NPTEL Online - IIT Bombay Course Name Parallel Computer Architecture Department Computer Science and Engineering IIT Kanpur Instructor Dr. Mainak Chaudhuri file:///e /parallel_com_arch/lecture1/main.html[6/13/2012
NPTEL Online - IIT Bombay Course Name Parallel Computer Architecture Department Computer Science and Engineering IIT Kanpur Instructor Dr. Mainak Chaudhuri file:///e /parallel_com_arch/lecture1/main.html[6/13/2012
OOO Execution & Precise State MIPS R10000 (R10K)
") OOO Execution & Precise State in MIPS R10000 (R10K) Nima Honarmand CDB. CDB.V Spring 2018 :: CSE 502 he Problem with P6 Map able + Regfile value R value Head Retire Dispatch op RS 1 2 V1 FU V2 ail Dispatch
OOO Execution & Precise State in MIPS R10000 (R10K) Nima Honarmand CDB. CDB.V Spring 2018 :: CSE 502 he Problem with P6 Map able + Regfile value R value Head Retire Dispatch op RS 1 2 V1 FU V2 ail Dispatch
Instruction Level Parallelism. Data Dependence Static Scheduling
 Instruction Level Parallelism Data Dependence Static Scheduling Basic Block A straight line code sequence with no branches in except to the entry and no branches out except at the exit Loop: L.D ADD.D
Instruction Level Parallelism Data Dependence Static Scheduling Basic Block A straight line code sequence with no branches in except to the entry and no branches out except at the exit Loop: L.D ADD.D
LV-Link 3.0 Software Interface for LabVIEW
 LV-Link 3.0 Software Interface for LabVIEW LV-Link Software Interface for LabVIEW LV-Link is a library of VIs (Virtual Instruments) that enable LabVIEW programmers to access the data acquisition features
LV-Link 3.0 Software Interface for LabVIEW LV-Link Software Interface for LabVIEW LV-Link is a library of VIs (Virtual Instruments) that enable LabVIEW programmers to access the data acquisition features
Trace Based Switching For A Tightly Coupled Heterogeneous Core
 Trace Based Switching For A Tightly Coupled Heterogeneous Core Shru% Padmanabha, Andrew Lukefahr, Reetuparna Das, Sco@ Mahlke Micro- 46 December 2013 University of Michigan Electrical Engineering and Computer
Trace Based Switching For A Tightly Coupled Heterogeneous Core Shru% Padmanabha, Andrew Lukefahr, Reetuparna Das, Sco@ Mahlke Micro- 46 December 2013 University of Michigan Electrical Engineering and Computer
FUNCTIONAL VERIFICATION: APPROACHES AND CHALLENGES
 FUNCTIONAL VERIFICATION: APPROACHES AND CHALLENGES A. MOLINA and O. CADENAS Computer Architecture Department, Universitat Politècnica de Catalunya, Barcelona, Spain amolina@ac.upc.edu School of System
FUNCTIONAL VERIFICATION: APPROACHES AND CHALLENGES A. MOLINA and O. CADENAS Computer Architecture Department, Universitat Politècnica de Catalunya, Barcelona, Spain amolina@ac.upc.edu School of System
CHALLENGES IN PROCESSOR MODELING AND VALIDATION
 Guest Editors Introduction: CHALLENGES IN PROCESSOR MODELING AND VALIDATION Pradip Bose IBM T.J. Watson Research Center Thomas M. Conte North Carolina State University Todd M. Austin Intel Corporation
Guest Editors Introduction: CHALLENGES IN PROCESSOR MODELING AND VALIDATION Pradip Bose IBM T.J. Watson Research Center Thomas M. Conte North Carolina State University Todd M. Austin Intel Corporation
ECE473 Computer Architecture and Organization. Pipeline: Introduction
 Computer Architecture and Organization Pipeline: Introduction Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 11.1 The Laundry Analogy Student A,
Computer Architecture and Organization Pipeline: Introduction Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 11.1 The Laundry Analogy Student A,
Computer Architecture and Organization:
 Computer Architecture and Organization: L03: Register transfer and System Bus By: A. H. Abdul Hafez Abdul.hafez@hku.edu.tr, ah.abdulhafez@gmail.com 1 CAO, by Dr. A.H. Abdul Hafez, CE Dept. HKU Outlines
Computer Architecture and Organization: L03: Register transfer and System Bus By: A. H. Abdul Hafez Abdul.hafez@hku.edu.tr, ah.abdulhafez@gmail.com 1 CAO, by Dr. A.H. Abdul Hafez, CE Dept. HKU Outlines
REAL TIME DIGITAL SIGNAL PROCESSING. Introduction
 REAL TIME DIGITAL SIGNAL Introduction Why Digital? A brief comparison with analog. PROCESSING Seminario de Electrónica: Sistemas Embebidos Advantages The BIG picture Flexibility. Easily modifiable and
REAL TIME DIGITAL SIGNAL Introduction Why Digital? A brief comparison with analog. PROCESSING Seminario de Electrónica: Sistemas Embebidos Advantages The BIG picture Flexibility. Easily modifiable and
A Static Power Model for Architects
 A Static Power Model for Architects J. Adam Butts and Guri Sohi University of Wisconsin-Madison {butts,sohi}@cs.wisc.edu 33rd International Symposium on Microarchitecture Monterey, California December,
A Static Power Model for Architects J. Adam Butts and Guri Sohi University of Wisconsin-Madison {butts,sohi}@cs.wisc.edu 33rd International Symposium on Microarchitecture Monterey, California December,
CUDA Threads. Terminology. How it works. Terminology. Streaming Multiprocessor (SM) A SM processes block of threads
 A SM processes block of threads") Terminology CUDA Threads Bedrich Benes, Ph.D. Purdue University Department of Computer Graphics Streaming Multiprocessor (SM) A SM processes block of threads Streaming Processors (SP) also called CUDA
Terminology CUDA Threads Bedrich Benes, Ph.D. Purdue University Department of Computer Graphics Streaming Multiprocessor (SM) A SM processes block of threads Streaming Processors (SP) also called CUDA
Best Instruction Per Cycle Formula >>>CLICK HERE<<<
 Best Instruction Per Cycle Formula 6 Performance tuning, 7 Perceived performance, 8 Performance Equation, 9 See also is the average instructions per cycle (IPC) for this benchmark. Even. Click Card to
Best Instruction Per Cycle Formula 6 Performance tuning, 7 Perceived performance, 8 Performance Equation, 9 See also is the average instructions per cycle (IPC) for this benchmark. Even. Click Card to
How a processor can permute n bits in O(1) cycles
 cycles") How a processor can permute n bits in O(1) cycles Ruby Lee, Zhijie Shi, Xiao Yang Princeton Architecture Lab for Multimedia and Security (PALMS) Department of Electrical Engineering Princeton University
How a processor can permute n bits in O(1) cycles Ruby Lee, Zhijie Shi, Xiao Yang Princeton Architecture Lab for Multimedia and Security (PALMS) Department of Electrical Engineering Princeton University
Performance Evaluation of Multi-Threaded System vs. Chip-Multi-Processor System
 Performance Evaluation of Multi-Threaded System vs. Chip-Multi-Processor System Ho Young Kim, Robert Maxwell, Ankil Patel, Byeong Kil Lee Abstract The purpose of this study is to analyze and compare the
Performance Evaluation of Multi-Threaded System vs. Chip-Multi-Processor System Ho Young Kim, Robert Maxwell, Ankil Patel, Byeong Kil Lee Abstract The purpose of this study is to analyze and compare the