DASH: Deadline-Aware High-Performance Memory Scheduler for Heterogeneous Systems with Hardware Accelerators
|
|
|
- Roger Gaines
- 5 years ago
- Views:
Transcription

1 DASH: Deadline-Aware High-Performance Memory Scheduler for Heterogeneous Systems with Hardware Accelerators Hiroyuki Usui, Lavanya Subramanian Kevin Chang, Onur Mutlu DASH source code is available at GitHub
2 Current SoC Architectures CPU CPU CPU CPU Shared Cache HWA HWA HWA DRAM Controller Heterogeneous agents: CPUs and HWAs HWA : Hardware Accelerator DRAM Main memory is shared by CPUs and HWAs Interference How to schedule memory requests from CPUs and HWAs to mitigate interference? 2
3 DASH Scheduler: Executive Summary Problem: Hardware accelerators (HWAs) and CPUs share the same memory subsystem and interfere with each other in main memory Goal: Design a memory scheduler that improves CPU performance while meeting HWAs deadlines Challenge: Different HWAs have different memory access characteristics and different deadlines, which current schedulers do not smoothly handle Memory-intensive and long-deadline HWAs significantly degrade CPU performance when they become high priority (due to slow progress) Short-deadline HWAs sometimes miss their deadlines despite high priority Solution: DASH Memory Scheduler Prioritize HWAs over CPU anytime when the HWA is not making good progress Application-aware scheduling for CPUs and HWAs Key Results: 1) Improves CPU performance for a wide variety of workloads by 9.5% 2) Meets 100% deadline met ratio for HWAs DASH source code freely available on the GitHub 3
4 Outline Introduction Problem with Existing Memory Schedulers for Heterogeneous Systems DASH: Key Ideas DASH: Scheduling Policy Evaluation and Results Conclusion 4
5 Outline Introduction Problem with Existing Memory Schedulers for Heterogeneous Systems DASH: Key Ideas DASH: Scheduling Policy Evaluation and Results Conclusion 5
6 Existing QoS-Aware Scheduling Scheme Dynamic Prioritization for a CPU-GPU System [Jeong et al., DAC 2012] Dynamically adjust GPU priority based on its progress Lower GPU priority if GPU is making a good progress to achieve its target frame rate We apply this scheme for a wide variety of HWAs Compare HWA s current progress against expected progress Current Progress : Expected Progress : (The number of finished memory requests for a period) (The number of total memory requests for a period ) (Elapsed cycles in a period) (Total cycles in a period) Every scheduling unit, dynamically adjust HWA priority If Expected Progress > EmergentThreshold (=0.9) : HWA > CPU If (Current Progress) > (Expected Progress) : HWA < CPU If (Current Progress) <= (Expected Progress) : HWA = CPU 6
7 Problems in Dynamic Prioritization Dynamic Prioritization for a CPU-HWA system Compares HWA s current progress against expected progress Current Progress : Expected Progress : (The number of finished memory requests for a period) (The number of total memory requests for a period ) (Elapsed cycles in a period) (Total cycles in a period) Every scheduling unit, dynamically adjust HWA priority If Expected Progress > EmergentThreshold (=0.9) : HWA > CPU If (Current Progress) > (Expected Progress) : HWA < CPU If (Current Progress) <= (Expected Progress) : HWA = CPU 1. An HWA is prioritized over CPU cores only when it is closed to HWA s deadline The HWA often misses deadlines 2. This scheme does not consider the diverse memory access characteristics of CPUs and HWAs It treats each CPU and each HWA equally Missing opportunities to improve system performance 7
8 Outline Introduction Problem with Existing Memory Schedulers for Heterogeneous Systems DASH: Key Ideas DASH: Scheduling Policy Evaluation and Results Conclusion 8
9 Key Idea 1: Distributed Priority Problem 1: An HWA is prioritized over CPU cores only when it is close to HWA s deadline Key Idea 1: Distributed Prioritization for a CPU-HWA system Compares HWA s current progress against expected progress Current Progress : Expected Progress : (The number of finished memory requests for a period) (The number of total memory requests for a period ) (Elapsed cycles in a period) (Total cycles in a period) Dynamically adjust HWA priority based on its progress every scheduling unit If Expected Progress > EmergentThreshold (=0.9) : HWA > CPU If (Current Progress) > (Expected Progress) : HWA < CPU If (Current Progress) <= (Expected Progress) : HWA > CPU Prioritize HWAs over CPU anytime when the HWA is not making good progress 9
10 Example: Scheduling HWA and CPU Requests Scheduling requests from 2 CPU applications and a HWA CPU-A : memory non-intensive application CPU-B : memory intensive application CPU-A DRAM Alone Execution Timeline Computation Req x1 Req x1 Req x1 A A A time CPU-B DRAM HWA Req x7 B B B B Req x10 DRAM H H H H H H H H H H B B B T COMPUTATION Period = 20T Deadline for 10 Requests 10
11 DASH: Distributed Priority Distributed Priority (Scheduling unit = 4T) CPU-A CPU-B HWA DRAM Req x1 Req x7 Req x10 H H H H HWA>CPU Current : 0 / 10 Expected : 0 / 20 11
12 DASH: Distributed Priority Distributed Priority (Scheduling unit = 4T) CPU-A CPU-B HWA DRAM Req x1 Req x7 H H H H COMPUTATION Req x10 A B B B HWA<CPU Current : 4 / 10 Expected : 5 / 20 12
13 DASH: Distributed Priority Distributed Priority (Scheduling unit = 4T) CPU-A CPU-B HWA Req x1 Req x7 Req x10 COMPUTATION Req x1 H H H H A B B B H H DRAM H H HWA>CPU Current : 4 / 10 Expected : 8 / 20 13
14 DASH: Distributed Priority Distributed Priority (Scheduling unit = 4T) CPU-A CPU-B HWA Req x1 Req x1 Req x1 Req x7 Req x10 COMPUTATION H H H H A B B B H H A B B B DRAM H H HWA<CPU Current : 8 / 10 Expected : 12 / 20 14
15 DASH: Distributed Priority Distributed Priority (Scheduling unit = 4T) CPU-A CPU-B HWA Req x1 Req x1 Req x1 Req x7 Req x10 COMPUTATION H H H H A B B B H H A B B B H A B DRAM H H H HWA>CPU Current : 8 / 10 Expected : 16 / 20 15
16 Problem2: Application-unawareness Problem 2 (Application-unawareness): Existing memory schedulers for heterogeneous systems do no consider the diverse memory access characteristics of CPUs and HWAs Application-unawareness causes two problems Problem 2.1: When a HWA has high priority (i.e., not measuring up to its expected progress), it interferes with all CPU cores for a long time Problem 2.2: A HWA with a short period misses its deadlines due to fluctuations in available memory bandwidth (due to priority changes of other HWAs) 16

17 Problem 2.1 and Its Solution Problem 2.1 Restated: When HWA is low priority, it is deprioritized too much It becomes high priority as a result and destroys CPU progress Goal: Avoid making the HWA high priority as much as possible HWA delays both A and B CPU-A CPU-B HWA Req x1 Req x7 Req x10 COMPUTATION Req x1 H H H H A B B B H H DRAM H H High Priority When When high low priority, HWA no causes HWA request all CPUs served to stall 17
18 Key Idea 2.1: Application-aware Scheduling for CPUs Key Idea 2.1: HWA priority over CPUs should depend on CPU memory intensity Not all CPUs are equal Memory-intensive cores are much less vulnerable to memory access latency Memory-non-intensive cores are much more vulnerable to latency While HWA has low priority, HWA is prioritized over memory-intensive cores Distributed Priority Application-aware Scheduling DRAM A B B B B H A H H H B B A > B > H when HWA is low priority A > H > B A: Memory-non-intensive, B: Memory-intensive 18
19 DASH: Application-aware Scheduling Distributed Priority (Scheduling unit = 4T) CPU-A CPU-B HWA Req x1 Req x1 Req x1 Req x7 High Priority Low Priority High Priority Low Priority High Priority Req x10 H H H H A B B B H H A B B B H A B DRAM H H H
20 DASH: Application-aware Scheduling Distributed Priority (Scheduling unit = 4T) CPU-A CPU-B HWA Req x1 Req x1 Req x1 Req x7 High Priority Low Priority High Priority Low Priority High Priority Req x10 H H H H A B B B H H A B B B H A B DRAM H H H Application-aware Scheduling (Scheduling unit = 4T) CPU-A CPU-B HWA DRAM Req x1 Req x7 High Priority Req x10 H H H H HWA>CPU-A&B Current : 0 / 10 Expected : 0 / 20 20
21 DASH: Application-aware Scheduling Distributed Priority (Scheduling unit = 4T) CPU-A CPU-B HWA Req x1 Req x1 Req x1 Req x7 High Priority Low Priority High Priority Low Priority High Priority Req x10 H H H H A B B B H H A B B B H A B DRAM H H H Application-aware Scheduling (Scheduling unit = 4T) CPU-A CPU-B HWA DRAM Req x1 Req x7 High Priority Low Priority Req x10 H H H H A H CPU-A > HWA > CPU-B Current : 4 / 10 Expected : 4 / 20 H H 21
22 DASH: Application-aware Scheduling Distributed Priority (Scheduling unit = 4T) CPU-A CPU-B HWA Req x1 Req x1 Req x1 Req x7 High Priority Low Priority High Priority Low Priority High Priority Req x10 H H H H A B B B H H A B B B H A B DRAM H H H Application-aware Scheduling (Scheduling unit = 4T) CPU-A CPU-B HWA DRAM Req x1 Req x7 High Priority Low Priority Low Priority Req x10 H H H H A H H H A H H CPU-A > HWA > CPU-B Current : 7 / 10 Expected : 8 / 20 H 22
23 DASH: Application-aware Scheduling Distributed Priority (Scheduling unit = 4T) CPU-A CPU-B HWA Req x1 Req x1 Req x1 Req x7 High Priority Low Priority High Priority Low Priority High Priority Req x10 H H H H A B B B H H A B B B H A B DRAM H H H Application-aware Scheduling (Scheduling unit = 4T) CPU-A CPU-B HWA Req x1 Req x7 High Priority Low Priority Low Priority Low Priority Req x10 DRAM H H H H A H H H A H H H A B B B CPU-A > HWA > CPU-B Current : 10 / 10 Expected : 12 / 20 23
24 DASH: Application-aware Scheduling Distributed Priority (Scheduling unit = 4T) CPU-A CPU-B HWA Req x1 Req x1 Req x1 Req x7 High Priority Low Priority High Priority Low Priority High Priority Req x10 H H H H A B B B H H A B B B H A B DRAM H H H Application-aware Scheduling (Scheduling unit = 4T) CPU-A CPU-B HWA DRAM Req x1 Req x7 High Priority Low Priority Low Priority Low Priority Low Priority Req x10 H H H H A Saved Cycles H H H A H H H A B B B B B B B 24
25 Problem 2.2 and Its Solution Problem 2.2: A HWA with a short-deadline-period misses its deadlines due to fluctuations in available memory bandwidth (due to priority changes of other HWAs) Key Idea 2.2: Estimate the worst-case memory access latency and give a short-deadline-period HWA the highest priority for (WorstCaseLatency) * (NumberOfRequests) cycles close to its deadline Period start HWA-A HWA-B Period 63,041 Cycles 5,447 Cycles Bandwidth 8.32 GB/s 475 MB/s HWA-A: meets all its deadlines HWA-B: misses a deadline every 2000 periods WorstCaseLatency = trc : the minimum time between two DRAM row ACTIVATE commands (WorstCaseLatency)*(#OfRequests) cycles deadline Low Priority High Priority 25
26 DASH: Summary of Key Ideas 1. Distributed priority 2. Application-aware scheduling 3. Worst-case memory access latency based prioritization 26
27 Outline Introduction Problem with Existing Memory Schedulers for Heterogeneous Systems DASH: Key Ideas DASH: Scheduling Policy Evaluation and Results Conclusion 27
28 DASH: Scheduling Policy DASH scheduling policy 1. Short-deadline-period HWAs with high priority 2. Long-deadline-period HWAs with high priority 3. Memory non-intensive CPU applications 4. Long-deadline-period HWAs with low priority 5. Memory-intensive CPU applications 6. Short-deadline-period HWAs with low priority 28
29 DASH: Scheduling Policy DASH scheduling policy 1. Short-deadline-period HWAs with high priority 2. Long-deadline-period HWAs with high priority 3. Memory non-intensive CPU applications 4. Long-deadline-period HWAs with low priority 5. Memory-intensive CPU applications 6. Short-deadline-period HWAs with low priority Switch probabilistically 29
30 Outline Introduction Problem with Existing Memory Schedulers for Heterogeneous Systems DASH: Key Ideas DASH: Scheduling Policy Evaluation and Results Conclusion 30
31 Experimental Methodology (1/2) New Heterogeneous System Simulator We have released this at GitHub ( Configurations 8 CPUs (2.66GHz), 32KB/L1, 4MB Shared/L2 4 HWAs DDR DRAM x 2 channels Workloads CPUs: 80 multi-programmed workloads SPEC CPU2006, TPC, NAS parallel benchmark HWAs: Metrics Image processing Image recognition [Lee+ ICCD 2009] [Viola and Jones CVPR 2001] CPUs : Weighted Speedup HWAs : Deadline met ratio (%) 31
32 Experimental Methodology (2/2) Parameters of the HWAs Period Bandwidth Deadline Group IMG : Image Processing 33 ms 360MB/s Long HES : Hessian 2 us 478MB/s Short MAT : Matching (1) 20fps 35.4 us 8.32 GB/s Long MAT : Matching (2) 30fps 23.6 us 5.55 GB/s Long RSZ : Resize us GB/s Long DET : Detect us GB/s Short Configurations of 4 HWAs Config-A Config-B Configuration IMG x 2, HES, MAT(2) HES, MAT(1), RSZ, DET 32
33 Evaluated Memory Schedulers FRFCFS-St, TCM-St: FRFCFS or TCM with static priority for HWAs HWAs always have higher priority than CPUs FRFCFS-St: FRFCFS [Zuravleff and Robinson US Patent 1997, Rixner et al. ISCA 2000] for CPUs Prioritizes row-buffer hits and older requests TCM-St: TCM [Kim+ MICRO 2010] for CPUs Always prioritizes memory-non-intensive applications Shuffles thread ranks of memory-intensive applications FRFCFS-Dyn: FRFCFS with dynamic priority for HWAs [Jeong et al., DAC 2012] HWA s priority is dynamically adjusted based on its progress FRFCFS-Dyn0.9: EmergentThreshold = 0.9 for all HWAs (Only after 90% of the HWA s period elapsed, the HWA has higher priority than CPUs) FRFCFS-DynOpt: Each HWA has different EmergentThreshold to meet its deadline Config-A Config-B IMG HES MAT HES MAT RSZ DET DASH: Distributed Priority + Application-aware scheduling for CPUs + HWAs TCM is used for CPUs to classify memory intensity of CPUs EmergentThreshold = 0.8 for all HWAs 33
34 Performance and Deadline Met Ratio Weighted Speedup for CPUs FRFCFS-St TCM-St FRFCFS-Dyn0.9 FRFCFS-DynOpt DASH Weighted Speedup Deadline Met Ratio (%) for HWAs IMG HES MAT RSZ DET FRFCFS-St TCM-St FRFCFS-Dyn FRFCFS-DynOpt DASH
35 Performance and Deadline Met Ratio Weighted Speedup for CPUs FRFCFS-St TCM-St FRFCFS-Dyn0.9 FRFCFS-DynOpt DASH Weighted Speedup 1. DASH achieves 100% deadline met ratio Deadline Met Ratio (%) for HWAs IMG HES MAT RSZ DET FRFCFS-St TCM-St FRFCFS-Dyn FRFCFS-DynOpt DASH
36 Performance and Deadline Met Ratio Weighted Speedup for CPUs FRFCFS-St TCM-St FRFCFS-Dyn0.9 FRFCFS-DynOpt DASH +9.5% Weighted Speedup 1. DASH achieves 100% deadline met ratio 2. Deadline DASH achieves Met Ratio better (%) performance HWAs(+9.5%) than FRFCFS-DynOpt that meets the most of HWAs deadlines (Optimized for HWAs) IMG HES MAT RSZ DET FRFCFS-St TCM-St FRFCFS-Dyn FRFCFS-DynOpt DASH
37 Performance and Deadline Met Ratio Weighted Speedup for CPUs FRFCFS-St TCM-St FRFCFS-Dyn0.9 FRFCFS-DynOpt DASH +9.5% Weighted Speedup 1. DASH achieves 100% deadline met ratio 2. Deadline DASH achieves Met Ratio better (%) performance HWAs(+9.5%) than FRFCFS-DynOpt that meets the most of HWAs deadlines (Optimized for HWAs) IMG HES MAT RSZ DET 3. DASH achieves comparable performance to FRFCFS-Dyn0.9 FRFCFS-St that frequently misses HWAs deadlines (Optimized for CPUs) TCM-St FRFCFS-Dyn FRFCFS-DynOpt DASH
38 DASH Scheduler: Summary Problem: Hardware accelerators (HWAs) and CPUs share the same memory subsystem and interfere with each other in main memory Goal: Design a memory scheduler that improves CPU performance while meeting HWAs deadlines Challenge: Different HWAs have different memory access characteristics and different deadlines, which current schedulers do not smoothly handle Memory-intensive and long-deadline HWAs significantly degrade CPU performance when they become high priority (due to slow progress) Short-deadline HWAs sometimes miss their deadlines despite high priority Solution: DASH Memory Scheduler Prioritize HWAs over CPU anytime when the HWA is not making good progress Application-aware scheduling for CPUs and HWAs Key Results: 1) Improves CPU performance for a wide variety of workloads by 9.5% 2) Meets 100% deadline met ratio for HWAs DASH source code freely available on the GitHub 38
39 DASH: Deadline-Aware High-Performance Memory Scheduler for Heterogeneous Systems with Hardware Accelerators Hiroyuki Usui, Lavanya Subramanian Kevin Chang, Onur Mutlu DASH source code is available at GitHub
40 Backup Slides 40
41 Probabilistic Switching of Priorities Each Long-deadline-period HWA x has probability P b (x) Scheduling using P b (x) With a probability P b x Memory-intensive applications > Long-deadline-period HWA x With a probability 1 P b x Memory-intensive applications < Long-deadline-period HWA x Controlling P b (x) Initial : P b (x) = 0 Every SwitchingUnit: If CurrentProgress > ExpectedProgress : P b x += 1% If CurrentProgress < ExpectedProgress : P b x = 5% 41
42 Priorities for Multiple Short-deadline-period HWAs Period(a) UPL(a) HWA-a Low High Low High Low High High Priority interfere interfere Period(b) HWA-b Low High Low Priority UPL(b) A HWA with shorter deadline period is given higher priority (HWA-a > HWA-b) UPL = Urgent Period Length : trc x NumberOfRequests + α During UPL(b), HWA-a will interfere HWA-b for (UPL(a) x 2) cycles at maximum UPL b /Period(a) = 2 HWA(b) might fail the deadline due to the interference from HWA-a 42
43 Priorities for Multiple Short-deadline-period HWAs Period(a) UPL(a) HWA-a Low High Low High Low High High Priority Period(b) HWA-b Low High High High Low Priority UPL(b) A HWA with shorter deadline period is given higher priority (HWA-a > HWA-b) UPL = Urgent Period Length : trc x NumberOfRequests + α During UPL(b), HWA-a will interfere HWA-b for (UPL(a) x 2) cycles at maximum UPL b /Period(a) = 2 HWA(b) might fail the deadline due to the interference from HWA-a HWA-b is prioritized when the time remaining in the period is (UPL(b) + UPL(a) x 2) cycles 43
44 Storage required for DASH 20 bytes for each long-deadline-period HWA 12 bytes for each short-deadline-period HWA For long-deadline-period HWA Name Curr-Req Total-Req Curr-Cyc Total-Cyc Pb Function Number of requests completed in a deadline period Total Number of requests to be completed in a deadline period Number of cycles elapsed in a deadline period Total number of cycles in a deadline period Probability for the priority switching between memory-intensive applications and HWA For a short-deadline-period HWA Name Priority-Cyc Curr-Cyc Total-Cyc Function Indicates when the priority is transitioned to high Number of cycles elapsed in a deadline period Total number of cycles elapsed in a deadline period 44
45 Simulation Parameter Details SchedulingUnit : 1000 CPU cycles SwitchingUnit : 500 CPU cycles ClusterFactor : 0.15 Fraction of total memory bandwidth allocated to memory-nonintensive CPU applications 45
46 Performance breakdown of DASH DA-D : Distributed Priority DA-D+L : DA-D + application-aware priority for CPUs DA-D+L+S : DA-D+L + worst-case latency based priority for short-deadline HWAs DA-D+L+S+P (DASH) : DA-D+L+S + probabilistic prioritization 46
47 Performance breakdown of DASH DA-D : Distributed Priority DA-D+L : DA-D + application-aware priority for CPUs DA-D+L+S Distributed : DA-D+L priority + worst-case improves latency performance based priority (Max for short-deadline +9.5%) HWAs DA-D+L+S+P (DASH) : DA-D+L+S + probabilistic prioritization 47
48 Performance breakdown of DASH DA-D : Distributed Priority DA-D+L : DA-D + application-aware priority for CPUs DA-D+L+S : DA-D+L + worst-case latency based priority for short-deadline HWAs DA-D+L+S+P (DASH) : DA-D+L+S + probabilistic prioritization 48 Application-aware priority for CPUs improves performance especially as the memory intensity increases (Max +7.6%)

 : DA-D+L+S + probabilistic")
49 Performance breakdown of DASH DA-D Probabilistic : Distributed prioritization Priority achieves good balance between DA-D+L : DA-D + application-aware priority for CPUs DA-D+L+S performance : DA-D+L and + worst-case fairness latency based priority for short-deadline HWAs DA-D+L+S+P (DASH) : DA-D+L+S + probabilistic prioritization 49
50 Performance breakdown of DASH Deadline Met Ratio Name IMG HES MAT RSZ DET Deadline group Long Short Long Long Short FRFCFS-DynOpt DA-D DA-D+L DA-D+L+S DA-D+L+S+P Short-deadline HWAs (HES and DET) misses deadlines on distributed priority (DA-D) and application-aware priority for CPU (DA-D+L) 2. Worst-case latency based priority (DA-D+L+S) enables short-deadline HWAs to meet their deadline 50
51 Impact of EmergentThreshold CPU performance sensitivity to EmergentThreshold DASH can meet all deadlines with a high EmergentThreshold value (=0.8) 51
52 Impact of EmergentThreshold Emergent Threshold Deadline-met ratio(%) of FRFCFS-Dyn Config-A Config-B HES MAT HES MAT RSZ DET
53 Impact of EmergentThreshold Emergent Threshold Deadline-met ratio(%) of DASH Config-A Config-B HES MAT HES MAT RSZ DET
54 Impact of ClusterFactor CPU performance sensitivity to Cluster Factor ClusterFactor is an effective knob for trading off CPU performance and fairness 54
")

55 Evaluations with GPUs 8 CPUs + 4 HWA (Config-A) + GPU 6 GPU traces : 3D mark and game +10.1% 55

56 Sensitivity to Number of Agents As the number of agents increases, DASH achieves greater performance improvement 8HWAs : IMG x 2, MAT x 2, HES x 2, RSZ x 1, DET x 1 56
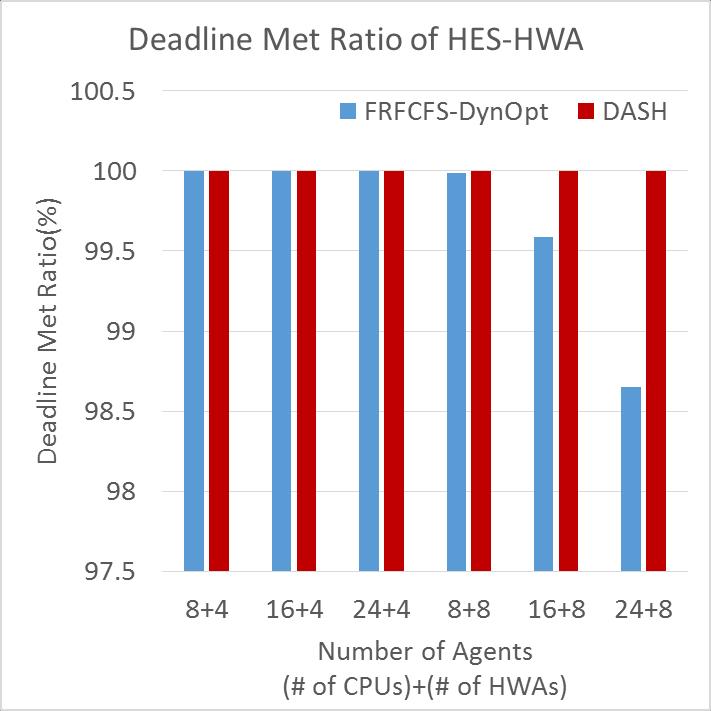
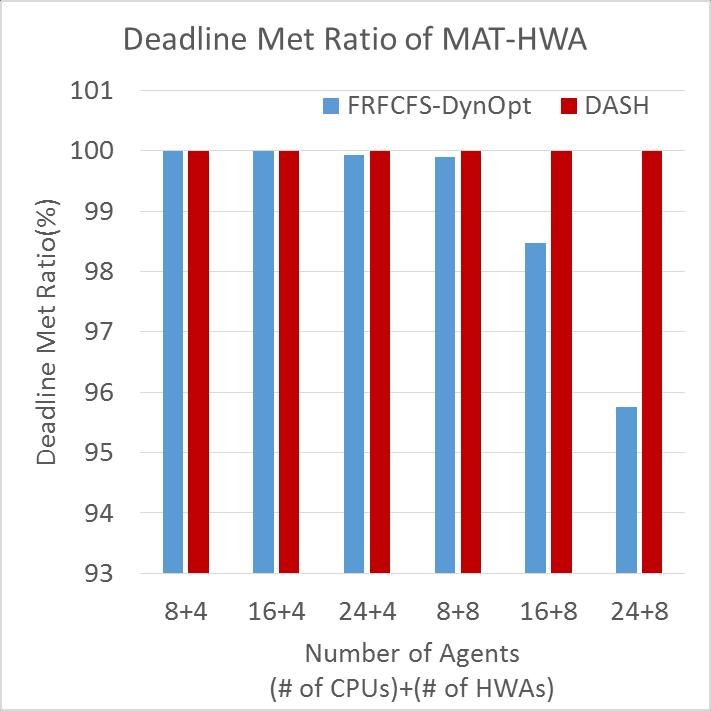
57 Sensitivity to Number of Agents 57

58 Sensitivity to Number of Channels 58
59 DASH: Application-aware scheduling for HWAs Categorize HWAs as long-deadline-period vs. shortdeadline-period statically Adjust the priorities of each dynamically Short-deadline-period HWA: becomes high priority if time remaining in period = trc x NumberOfRequests + α Long-deadline-period HWA: becomes high priority if Current progress Expected progress 59
Mosaic: A GPU Memory Manager with Application-Transparent Support for Multiple Page Sizes
 Mosaic: A GPU Memory Manager with Application-Transparent Support for Multiple Page Sizes Rachata Ausavarungnirun Joshua Landgraf Vance Miller Saugata Ghose Jayneel Gandhi Christopher J. Rossbach Onur
Mosaic: A GPU Memory Manager with Application-Transparent Support for Multiple Page Sizes Rachata Ausavarungnirun Joshua Landgraf Vance Miller Saugata Ghose Jayneel Gandhi Christopher J. Rossbach Onur
Improving GPU Performance via Large Warps and Two-Level Warp Scheduling
 Improving GPU Performance via Large Warps and Two-Level Warp Scheduling Veynu Narasiman The University of Texas at Austin Michael Shebanow NVIDIA Chang Joo Lee Intel Rustam Miftakhutdinov The University
Improving GPU Performance via Large Warps and Two-Level Warp Scheduling Veynu Narasiman The University of Texas at Austin Michael Shebanow NVIDIA Chang Joo Lee Intel Rustam Miftakhutdinov The University
ΕΠΛ 605: Προχωρημένη Αρχιτεκτονική
 ΕΠΛ 605: Προχωρημένη Αρχιτεκτονική Υπολογιστών Presentation of UniServer Horizon 2020 European project findings: X-Gene server chips, voltage-noise characterization, high-bandwidth voltage measurements,
ΕΠΛ 605: Προχωρημένη Αρχιτεκτονική Υπολογιστών Presentation of UniServer Horizon 2020 European project findings: X-Gene server chips, voltage-noise characterization, high-bandwidth voltage measurements,
PROBE: Prediction-based Optical Bandwidth Scaling for Energy-efficient NoCs
 PROBE: Prediction-based Optical Bandwidth Scaling for Energy-efficient NoCs Li Zhou and Avinash Kodi Technologies for Emerging Computer Architecture Laboratory (TEAL) School of Electrical Engineering and
PROBE: Prediction-based Optical Bandwidth Scaling for Energy-efficient NoCs Li Zhou and Avinash Kodi Technologies for Emerging Computer Architecture Laboratory (TEAL) School of Electrical Engineering and
Image Processing Architectures (and their future requirements)
") Lecture 16: Image Processing Architectures (and their future requirements) Visual Computing Systems Smart phone processing resources Example SoC: Qualcomm Snapdragon Image credit: Qualcomm Apple A7 (iphone
Lecture 16: Image Processing Architectures (and their future requirements) Visual Computing Systems Smart phone processing resources Example SoC: Qualcomm Snapdragon Image credit: Qualcomm Apple A7 (iphone
Performance Evaluation of Recently Proposed Cache Replacement Policies
 University of Jordan Computer Engineering Department Performance Evaluation of Recently Proposed Cache Replacement Policies CPE 731: Advanced Computer Architecture Dr. Gheith Abandah Asma Abdelkarim January
University of Jordan Computer Engineering Department Performance Evaluation of Recently Proposed Cache Replacement Policies CPE 731: Advanced Computer Architecture Dr. Gheith Abandah Asma Abdelkarim January
RANA: Towards Efficient Neural Acceleration with Refresh-Optimized Embedded DRAM
 RANA: Towards Efficient Neural Acceleration with Refresh-Optimized Embedded DRAM Fengbin Tu, Weiwei Wu, Shouyi Yin, Leibo Liu, Shaojun Wei Institute of Microelectronics Tsinghua University The 45th International
RANA: Towards Efficient Neural Acceleration with Refresh-Optimized Embedded DRAM Fengbin Tu, Weiwei Wu, Shouyi Yin, Leibo Liu, Shaojun Wei Institute of Microelectronics Tsinghua University The 45th International
Supporting x86-64 Address Translation for 100s of GPU Lanes. Jason Power, Mark D. Hill, David A. Wood
 Supporting x86-64 Address Translation for 100s of GPU s Jason Power, Mark D. Hill, David A. Wood Summary Challenges: CPU&GPUs physically integrated, but logically separate; This reduces theoretical bandwidth,
Supporting x86-64 Address Translation for 100s of GPU s Jason Power, Mark D. Hill, David A. Wood Summary Challenges: CPU&GPUs physically integrated, but logically separate; This reduces theoretical bandwidth,
Performance Metrics, Amdahl s Law
 ecture 26 Computer Science 61C Spring 2017 March 20th, 2017 Performance Metrics, Amdahl s Law 1 New-School Machine Structures (It s a bit more complicated!) Software Hardware Parallel Requests Assigned
ecture 26 Computer Science 61C Spring 2017 March 20th, 2017 Performance Metrics, Amdahl s Law 1 New-School Machine Structures (It s a bit more complicated!) Software Hardware Parallel Requests Assigned
Exploring Computation- Communication Tradeoffs in Camera Systems
 Exploring Computation- Communication Tradeoffs in Camera Systems Amrita Mazumdar Thierry Moreau Sung Kim Meghan Cowan Armin Alaghi Luis Ceze Mark Oskin Visvesh Sathe IISWC 2017 1 Camera applications are
Exploring Computation- Communication Tradeoffs in Camera Systems Amrita Mazumdar Thierry Moreau Sung Kim Meghan Cowan Armin Alaghi Luis Ceze Mark Oskin Visvesh Sathe IISWC 2017 1 Camera applications are
Evaluation of CPU Frequency Transition Latency
 Evaluation of CPU Frequency Transition Latency Abdelhafid Mazouz 1 Alexandre Laurent 1 Benoît Pradelle 1 William Jalby 1 1 University of Versailles Saint-Quentin-en-Yvelines, France ENA-HPC 2013, Dresden
Evaluation of CPU Frequency Transition Latency Abdelhafid Mazouz 1 Alexandre Laurent 1 Benoît Pradelle 1 William Jalby 1 1 University of Versailles Saint-Quentin-en-Yvelines, France ENA-HPC 2013, Dresden
GPU-accelerated track reconstruction in the ALICE High Level Trigger
 GPU-accelerated track reconstruction in the ALICE High Level Trigger David Rohr for the ALICE Collaboration Frankfurt Institute for Advanced Studies CHEP 2016, San Francisco ALICE at the LHC The Large
GPU-accelerated track reconstruction in the ALICE High Level Trigger David Rohr for the ALICE Collaboration Frankfurt Institute for Advanced Studies CHEP 2016, San Francisco ALICE at the LHC The Large
Measuring and Evaluating Computer System Performance
 Measuring and Evaluating Computer System Performance Performance Marches On... But what is performance? The bottom line: Performance Car Time to Bay Area Speed Passengers Throughput (pmph) Ferrari 3.1
Measuring and Evaluating Computer System Performance Performance Marches On... But what is performance? The bottom line: Performance Car Time to Bay Area Speed Passengers Throughput (pmph) Ferrari 3.1
NetApp Sizing Guidelines for MEDITECH Environments
 Technical Report NetApp Sizing Guidelines for MEDITECH Environments Brahmanna Chowdary Kodavali, NetApp March 2016 TR-4190 TABLE OF CONTENTS 1 Introduction... 4 1.1 Scope...4 1.2 Audience...5 2 MEDITECH
Technical Report NetApp Sizing Guidelines for MEDITECH Environments Brahmanna Chowdary Kodavali, NetApp March 2016 TR-4190 TABLE OF CONTENTS 1 Introduction... 4 1.1 Scope...4 1.2 Audience...5 2 MEDITECH
Creating Intelligence at the Edge
 Creating Intelligence at the Edge Vladimir Stojanović E3S Retreat September 8, 2017 The growing importance of machine learning Page 2 Applications exploding in the cloud Huge interest to move to the edge
Creating Intelligence at the Edge Vladimir Stojanović E3S Retreat September 8, 2017 The growing importance of machine learning Page 2 Applications exploding in the cloud Huge interest to move to the edge
GPU-accelerated SDR Implementation of Multi-User Detector for Satellite Return Links
 DLR.de Chart 1 GPU-accelerated SDR Implementation of Multi-User Detector for Satellite Return Links Chen Tang chen.tang@dlr.de Institute of Communication and Navigation German Aerospace Center DLR.de Chart
DLR.de Chart 1 GPU-accelerated SDR Implementation of Multi-User Detector for Satellite Return Links Chen Tang chen.tang@dlr.de Institute of Communication and Navigation German Aerospace Center DLR.de Chart
Image Processing Architectures (and their future requirements)
") Lecture 17: Image Processing Architectures (and their future requirements) Visual Computing Systems Smart phone processing resources Qualcomm snapdragon Image credit: Qualcomm Apple A7 (iphone 5s) Chipworks
Lecture 17: Image Processing Architectures (and their future requirements) Visual Computing Systems Smart phone processing resources Qualcomm snapdragon Image credit: Qualcomm Apple A7 (iphone 5s) Chipworks
Re-Visiting Power Measurement for the Green500
 Re-Visiting Power Measurement for the Green500 Thomas R. W. Scogland (LLNL/CASC, Green500) The Green500 List and its Continuing 1 Evolution BoF, November 2014 Level 1 Requirements Workload phase: Measure
Re-Visiting Power Measurement for the Green500 Thomas R. W. Scogland (LLNL/CASC, Green500) The Green500 List and its Continuing 1 Evolution BoF, November 2014 Level 1 Requirements Workload phase: Measure
COTSon: Infrastructure for system-level simulation
 COTSon: Infrastructure for system-level simulation Ayose Falcón, Paolo Faraboschi, Daniel Ortega HP Labs Exascale Computing Lab http://sites.google.com/site/hplabscotson MICRO-41 tutorial November 9, 28
COTSon: Infrastructure for system-level simulation Ayose Falcón, Paolo Faraboschi, Daniel Ortega HP Labs Exascale Computing Lab http://sites.google.com/site/hplabscotson MICRO-41 tutorial November 9, 28
Use Nvidia Performance Primitives (NPP) in Deep Learning Training. Yang Song
 in Deep Learning Training. Yang Song") Use Nvidia Performance Primitives (NPP) in Deep Learning Training Yang Song Outline Introduction Function Categories Performance Results Deep Learning Specific Further Information What is NPP? Image+Signal
Use Nvidia Performance Primitives (NPP) in Deep Learning Training Yang Song Outline Introduction Function Categories Performance Results Deep Learning Specific Further Information What is NPP? Image+Signal
Performance Evaluation of Multi-Threaded System vs. Chip-Multi-Processor System
 Performance Evaluation of Multi-Threaded System vs. Chip-Multi-Processor System Ho Young Kim, Robert Maxwell, Ankil Patel, Byeong Kil Lee Abstract The purpose of this study is to analyze and compare the
Performance Evaluation of Multi-Threaded System vs. Chip-Multi-Processor System Ho Young Kim, Robert Maxwell, Ankil Patel, Byeong Kil Lee Abstract The purpose of this study is to analyze and compare the
Processors Processing Processors. The meta-lecture
 Simulators 5SIA0 Processors Processing Processors The meta-lecture Why Simulators? Your Friend Harm Why Simulators? Harm Loves Tractors Harm Why Simulators? The outside world Unfortunately for Harm you
Simulators 5SIA0 Processors Processing Processors The meta-lecture Why Simulators? Your Friend Harm Why Simulators? Harm Loves Tractors Harm Why Simulators? The outside world Unfortunately for Harm you
Scheduling and Communication Synthesis for Distributed Real-Time Systems
 Scheduling and Communication Synthesis for Distributed Real-Time Systems Department of Computer and Information Science Linköpings universitet 1 of 30 Outline Motivation System Model and Architecture Scheduling
Scheduling and Communication Synthesis for Distributed Real-Time Systems Department of Computer and Information Science Linköpings universitet 1 of 30 Outline Motivation System Model and Architecture Scheduling
Deadline scheduling: can your mobile device last longer?
 Deadline scheduling: can your mobile device last longer? Juri Lelli, Mario Bambagini, Giuseppe Lipari Linux Plumbers Conference 202 San Diego (CA), USA, August 3 TeCIP Insitute, Scuola Superiore Sant'Anna
Deadline scheduling: can your mobile device last longer? Juri Lelli, Mario Bambagini, Giuseppe Lipari Linux Plumbers Conference 202 San Diego (CA), USA, August 3 TeCIP Insitute, Scuola Superiore Sant'Anna
SSD Firmware Implementation Project Lab. #1
 SSD Firmware Implementation Project Lab. #1 Sang Phil Lim (lsfeel0204@gmail.com) SKKU VLDB Lab. 2011 03 24 Contents Project Overview Lab. Time Schedule Project #1 Guide FTL Simulator Development Project
SSD Firmware Implementation Project Lab. #1 Sang Phil Lim (lsfeel0204@gmail.com) SKKU VLDB Lab. 2011 03 24 Contents Project Overview Lab. Time Schedule Project #1 Guide FTL Simulator Development Project
Apache Spark Performance Troubleshooting at Scale: Challenges, Tools and Methods
 Apache Spark Performance Troubleshooting at Scale: Challenges, Tools and Methods Luca Canali, CERN About Luca Computing engineer and team lead at CERN IT Hadoop and Spark service, database services Joined
Apache Spark Performance Troubleshooting at Scale: Challenges, Tools and Methods Luca Canali, CERN About Luca Computing engineer and team lead at CERN IT Hadoop and Spark service, database services Joined
On the Off-chip Memory Latency of Real-Time Systems: Is DDR DRAM Really the Best Option? Mohamed Hassan
 On the Off-chip Memory Latency of eal-time Systems: Is DD DAM eally the Best Option? Mohamed Hassan Motivation 2 PEDICTABILITY DAMs 3 LDAM 4 esults 5 Outline Historically, SAMs have been the option for
On the Off-chip Memory Latency of eal-time Systems: Is DD DAM eally the Best Option? Mohamed Hassan Motivation 2 PEDICTABILITY DAMs 3 LDAM 4 esults 5 Outline Historically, SAMs have been the option for
The Xbox One System on a Chip and Kinect Sensor
 The Xbox One System on a Chip and Kinect Sensor John Sell, Patrick O Connor, Microsoft Corporation 1 Abstract The System on a Chip at the heart of the Xbox One entertainment console is one of the largest
The Xbox One System on a Chip and Kinect Sensor John Sell, Patrick O Connor, Microsoft Corporation 1 Abstract The System on a Chip at the heart of the Xbox One entertainment console is one of the largest
Computational Efficiency of the GF and the RMF Transforms for Quaternary Logic Functions on CPUs and GPUs
 5 th International Conference on Logic and Application LAP 2016 Dubrovnik, Croatia, September 19-23, 2016 Computational Efficiency of the GF and the RMF Transforms for Quaternary Logic Functions on CPUs
5 th International Conference on Logic and Application LAP 2016 Dubrovnik, Croatia, September 19-23, 2016 Computational Efficiency of the GF and the RMF Transforms for Quaternary Logic Functions on CPUs
COMET DISTRIBUTED ELEVATOR CONTROLLER CASE STUDY
 COMET DISTRIBUTED ELEVATOR CONTROLLER CASE STUDY System Description: The distributed system has multiple nodes interconnected via LAN and all communications between nodes are via loosely coupled message
COMET DISTRIBUTED ELEVATOR CONTROLLER CASE STUDY System Description: The distributed system has multiple nodes interconnected via LAN and all communications between nodes are via loosely coupled message
Energy Efficiency Benefits of Reducing the Voltage Guardband on the Kepler GPU Architecture
 Energy Efficiency Benefits of Reducing the Voltage Guardband on the Kepler GPU Architecture Jingwen Leng Yazhou Zu Vijay Janapa Reddi The University of Texas at Austin {jingwen, yazhou.zu}@utexas.edu,
Energy Efficiency Benefits of Reducing the Voltage Guardband on the Kepler GPU Architecture Jingwen Leng Yazhou Zu Vijay Janapa Reddi The University of Texas at Austin {jingwen, yazhou.zu}@utexas.edu,
Track and Vertex Reconstruction on GPUs for the Mu3e Experiment
 Track and Vertex Reconstruction on GPUs for the Mu3e Experiment Dorothea vom Bruch for the Mu3e Collaboration GPU Computing in High Energy Physics, Pisa September 11th, 2014 Physikalisches Institut Heidelberg
Track and Vertex Reconstruction on GPUs for the Mu3e Experiment Dorothea vom Bruch for the Mu3e Collaboration GPU Computing in High Energy Physics, Pisa September 11th, 2014 Physikalisches Institut Heidelberg
Final Report: DBmbench
 18-741 Final Report: DBmbench Yan Ke (yke@cs.cmu.edu) Justin Weisz (jweisz@cs.cmu.edu) Dec. 8, 2006 1 Introduction Conventional database benchmarks, such as the TPC-C and TPC-H, are extremely computationally
18-741 Final Report: DBmbench Yan Ke (yke@cs.cmu.edu) Justin Weisz (jweisz@cs.cmu.edu) Dec. 8, 2006 1 Introduction Conventional database benchmarks, such as the TPC-C and TPC-H, are extremely computationally
Investigation of Timescales for Channel, Rate, and Power Control in a Metropolitan Wireless Mesh Testbed1
 Investigation of Timescales for Channel, Rate, and Power Control in a Metropolitan Wireless Mesh Testbed1 1. Introduction Vangelis Angelakis, Konstantinos Mathioudakis, Emmanouil Delakis, Apostolos Traganitis,
Investigation of Timescales for Channel, Rate, and Power Control in a Metropolitan Wireless Mesh Testbed1 1. Introduction Vangelis Angelakis, Konstantinos Mathioudakis, Emmanouil Delakis, Apostolos Traganitis,
Warp-Aware Trace Scheduling for GPUS. James Jablin (Brown) Thomas Jablin (UIUC) Onur Mutlu (CMU) Maurice Herlihy (Brown)
 Thomas Jablin (UIUC) Onur Mutlu (CMU) Maurice Herlihy (Brown)") Warp-Aware Trace Scheduling for GPUS James Jablin (Brown) Thomas Jablin (UIUC) Onur Mutlu (CMU) Maurice Herlihy (Brown) Historical Trends in GFLOPS: CPUs vs. GPUs Theoretical GFLOP/s 3250 3000 2750 2500
Warp-Aware Trace Scheduling for GPUS James Jablin (Brown) Thomas Jablin (UIUC) Onur Mutlu (CMU) Maurice Herlihy (Brown) Historical Trends in GFLOPS: CPUs vs. GPUs Theoretical GFLOP/s 3250 3000 2750 2500
CS4617 Computer Architecture
 1/26 CS4617 Computer Architecture Lecture 2 Dr J Vaughan September 10, 2014 2/26 Amdahl s Law Speedup = Execution time for entire task without using enhancement Execution time for entire task using enhancement
1/26 CS4617 Computer Architecture Lecture 2 Dr J Vaughan September 10, 2014 2/26 Amdahl s Law Speedup = Execution time for entire task without using enhancement Execution time for entire task using enhancement
CUDA-Accelerated Satellite Communication Demodulation
 CUDA-Accelerated Satellite Communication Demodulation Renliang Zhao, Ying Liu, Liheng Jian, Zhongya Wang School of Computer and Control University of Chinese Academy of Sciences Outline Motivation Related
CUDA-Accelerated Satellite Communication Demodulation Renliang Zhao, Ying Liu, Liheng Jian, Zhongya Wang School of Computer and Control University of Chinese Academy of Sciences Outline Motivation Related
An FPGA-Based Back End for Real Time, Multi-Beam Transient Searches Over a Wide Dispersion Measure Range
 An FPGA-Based Back End for Real Time, Multi-Beam Transient Searches Over a Wide Dispersion Measure Range Larry D'Addario 1, Nathan Clarke 2, Robert Navarro 1, and Joseph Trinh 1 1 Jet Propulsion Laboratory,
An FPGA-Based Back End for Real Time, Multi-Beam Transient Searches Over a Wide Dispersion Measure Range Larry D'Addario 1, Nathan Clarke 2, Robert Navarro 1, and Joseph Trinh 1 1 Jet Propulsion Laboratory,
Energy Efficient Soft Real-Time Computing through Cross-Layer Predictive Control
 Energy Efficient Soft Real-Time Computing through Cross-Layer Predictive Control Guangyi Cao and Arun Ravindran Department of Electrical and Computer Engineering University of North Carolina at Charlotte
Energy Efficient Soft Real-Time Computing through Cross-Layer Predictive Control Guangyi Cao and Arun Ravindran Department of Electrical and Computer Engineering University of North Carolina at Charlotte
Project 5: Optimizer Jason Ansel
 Project 5: Optimizer Jason Ansel Overview Project guidelines Benchmarking Library OoO CPUs Project Guidelines Use optimizations from lectures as your arsenal If you decide to implement one, look at Whale
Project 5: Optimizer Jason Ansel Overview Project guidelines Benchmarking Library OoO CPUs Project Guidelines Use optimizations from lectures as your arsenal If you decide to implement one, look at Whale
Interactive Media and Game Development Master s
 Interactive Media and Game Development Master s Project Drizzle: Design and Implementation of a Lightweight Cloud Game Engine with Latency Compensation Jiawei Sun December 2017 Thesis Advisor: Committee
Interactive Media and Game Development Master s Project Drizzle: Design and Implementation of a Lightweight Cloud Game Engine with Latency Compensation Jiawei Sun December 2017 Thesis Advisor: Committee
Low-Power CMOS VLSI Design
 Low-Power CMOS VLSI Design ( 范倫達 ), Ph. D. Department of Computer Science, National Chiao Tung University, Taiwan, R.O.C. Fall, 2017 ldvan@cs.nctu.edu.tw http://www.cs.nctu.tw/~ldvan/ Outline Introduction
Low-Power CMOS VLSI Design ( 范倫達 ), Ph. D. Department of Computer Science, National Chiao Tung University, Taiwan, R.O.C. Fall, 2017 ldvan@cs.nctu.edu.tw http://www.cs.nctu.tw/~ldvan/ Outline Introduction
Sourjya Bhaumik, Shoban Chandrabose, Kashyap Jataprolu, Gautam Kumar, Paul Polakos, Vikram Srinivasan, Thomas Woo
 CloudIQ Anand Muralidhar (anand.muralidhar@alcatel-lucent.com) Sourjya Bhaumik, Shoban Chandrabose, Kashyap Jataprolu, Gautam Kumar, Paul Polakos, Vikram Srinivasan, Thomas Woo Load(%) Baseband processing
CloudIQ Anand Muralidhar (anand.muralidhar@alcatel-lucent.com) Sourjya Bhaumik, Shoban Chandrabose, Kashyap Jataprolu, Gautam Kumar, Paul Polakos, Vikram Srinivasan, Thomas Woo Load(%) Baseband processing
CS Computer Architecture Spring Lecture 04: Understanding Performance
 CS 35101 Computer Architecture Spring 2008 Lecture 04: Understanding Performance Taken from Mary Jane Irwin (www.cse.psu.edu/~mji) and Kevin Schaffer [Adapted from Computer Organization and Design, Patterson
CS 35101 Computer Architecture Spring 2008 Lecture 04: Understanding Performance Taken from Mary Jane Irwin (www.cse.psu.edu/~mji) and Kevin Schaffer [Adapted from Computer Organization and Design, Patterson
Trace Based Switching For A Tightly Coupled Heterogeneous Core
 Trace Based Switching For A Tightly Coupled Heterogeneous Core Shru% Padmanabha, Andrew Lukefahr, Reetuparna Das, Sco@ Mahlke Micro- 46 December 2013 University of Michigan Electrical Engineering and Computer
Trace Based Switching For A Tightly Coupled Heterogeneous Core Shru% Padmanabha, Andrew Lukefahr, Reetuparna Das, Sco@ Mahlke Micro- 46 December 2013 University of Michigan Electrical Engineering and Computer
Architectural Core Salvaging in a Multi-Core Processor for Hard-Error Tolerance
 Architectural Core Salvaging in a Multi-Core Processor for Hard-Error Tolerance Michael D. Powell, Arijit Biswas, Shantanu Gupta, and Shubu Mukherjee SPEARS Group, Intel Massachusetts EECS, University
Architectural Core Salvaging in a Multi-Core Processor for Hard-Error Tolerance Michael D. Powell, Arijit Biswas, Shantanu Gupta, and Shubu Mukherjee SPEARS Group, Intel Massachusetts EECS, University
FIFO WITH OFFSETS HIGH SCHEDULABILITY WITH LOW OVERHEADS. RTAS 18 April 13, Björn Brandenburg
 FIFO WITH OFFSETS HIGH SCHEDULABILITY WITH LOW OVERHEADS RTAS 18 April 13, 2018 Mitra Nasri Rob Davis Björn Brandenburg FIFO SCHEDULING First-In-First-Out (FIFO) scheduling extremely simple very low overheads
FIFO WITH OFFSETS HIGH SCHEDULABILITY WITH LOW OVERHEADS RTAS 18 April 13, 2018 Mitra Nasri Rob Davis Björn Brandenburg FIFO SCHEDULING First-In-First-Out (FIFO) scheduling extremely simple very low overheads
Embedded System Hardware - Reconfigurable Hardware -
 2 Embedded System Hardware - Reconfigurable Hardware - Peter Marwedel Informatik 2 TU Dortmund Germany GOPs/J Courtesy: Philips Hugo De Man, IMEC, 27 Energy Efficiency of FPGAs 2, 28-2- Reconfigurable
2 Embedded System Hardware - Reconfigurable Hardware - Peter Marwedel Informatik 2 TU Dortmund Germany GOPs/J Courtesy: Philips Hugo De Man, IMEC, 27 Energy Efficiency of FPGAs 2, 28-2- Reconfigurable
Advances in Antenna Measurement Instrumentation and Systems
 Advances in Antenna Measurement Instrumentation and Systems Steven R. Nichols, Roger Dygert, David Wayne MI Technologies Suwanee, Georgia, USA Abstract Since the early days of antenna pattern recorders,
Advances in Antenna Measurement Instrumentation and Systems Steven R. Nichols, Roger Dygert, David Wayne MI Technologies Suwanee, Georgia, USA Abstract Since the early days of antenna pattern recorders,
On-chip Networks in Multi-core era
 Friday, October 12th, 2012 On-chip Networks in Multi-core era Davide Zoni PhD Student email: zoni@elet.polimi.it webpage: home.dei.polimi.it/zoni Outline 2 Introduction Technology trends and challenges
Friday, October 12th, 2012 On-chip Networks in Multi-core era Davide Zoni PhD Student email: zoni@elet.polimi.it webpage: home.dei.polimi.it/zoni Outline 2 Introduction Technology trends and challenges
Recent Advances in Simulation Techniques and Tools
 Recent Advances in Simulation Techniques and Tools Yuyang Li, li.yuyang(at)wustl.edu (A paper written under the guidance of Prof. Raj Jain) Download Abstract: Simulation refers to using specified kind
Recent Advances in Simulation Techniques and Tools Yuyang Li, li.yuyang(at)wustl.edu (A paper written under the guidance of Prof. Raj Jain) Download Abstract: Simulation refers to using specified kind
Scheduling in WiMAX Networks
 Scheduling in WiMAX Networks Ritun Patney and Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu Ritun@cse.wustl.edu Presented at WiMAX Forum AATG F2F Meeting, Washington
Scheduling in WiMAX Networks Ritun Patney and Raj Jain Washington University in Saint Louis Saint Louis, MO 63130 Jain@cse.wustl.edu Ritun@cse.wustl.edu Presented at WiMAX Forum AATG F2F Meeting, Washington
4G Mobile Broadband LTE
 4G Mobile Broadband LTE Part I Dr Stefan Parkvall Principal Researcher Ericson Research Data overtaking Voice Data is overtaking voice......but previous cellular systems designed primarily for voice Rapid
4G Mobile Broadband LTE Part I Dr Stefan Parkvall Principal Researcher Ericson Research Data overtaking Voice Data is overtaking voice......but previous cellular systems designed primarily for voice Rapid
The Critical Role of Firmware and Flash Translation Layers in Solid State Drive Design
 The Critical Role of Firmware and Flash Translation Layers in Solid State Drive Design Robert Sykes Director of Applications OCZ Technology Flash Memory Summit 2012 Santa Clara, CA 1 Introduction This
The Critical Role of Firmware and Flash Translation Layers in Solid State Drive Design Robert Sykes Director of Applications OCZ Technology Flash Memory Summit 2012 Santa Clara, CA 1 Introduction This
CT-Bus : A Heterogeneous CDMA/TDMA Bus for Future SOC
 CT-Bus : A Heterogeneous CDMA/TDMA Bus for Future SOC Bo-Cheng Charles Lai 1 Patrick Schaumont 1 Ingrid Verbauwhede 1,2 1 UCLA, EE Dept. 2 K.U.Leuven 42 Westwood Plaza Los Angeles, CA 995 Abstract- CDMA
CT-Bus : A Heterogeneous CDMA/TDMA Bus for Future SOC Bo-Cheng Charles Lai 1 Patrick Schaumont 1 Ingrid Verbauwhede 1,2 1 UCLA, EE Dept. 2 K.U.Leuven 42 Westwood Plaza Los Angeles, CA 995 Abstract- CDMA
Parallel Simulation of Social Agents using Cilk and OpenCL
 D. Moser, A. Riener, K. Zia, A. Ferscha Department for Pervasive Computing, JKU Linz/Austria Parallel Simulation of Social Agents using Cilk and OpenCL DS-RT 2011 15th International Symposium on Distributed
D. Moser, A. Riener, K. Zia, A. Ferscha Department for Pervasive Computing, JKU Linz/Austria Parallel Simulation of Social Agents using Cilk and OpenCL DS-RT 2011 15th International Symposium on Distributed
Power of Realtime 3D-Rendering. Raja Koduri
 Power of Realtime 3D-Rendering Raja Koduri 1 We ate our GPU cake - vuoi la botte piena e la moglie ubriaca And had more too! 16+ years of (sugar) high! In every GPU generation More performance and performance-per-watt
Power of Realtime 3D-Rendering Raja Koduri 1 We ate our GPU cake - vuoi la botte piena e la moglie ubriaca And had more too! 16+ years of (sugar) high! In every GPU generation More performance and performance-per-watt
Experience with new architectures: moving from HELIOS to Marconi
 Experience with new architectures: moving from HELIOS to Marconi Serhiy Mochalskyy, Roman Hatzky 3 rd Accelerated Computing For Fusion Workshop November 28 29 th, 2016, Saclay, France High Level Support
Experience with new architectures: moving from HELIOS to Marconi Serhiy Mochalskyy, Roman Hatzky 3 rd Accelerated Computing For Fusion Workshop November 28 29 th, 2016, Saclay, France High Level Support
Outline Simulators and such. What defines a simulator? What about emulation?
 Outline Simulators and such Mats Brorsson & Mladen Nikitovic ICT Dept of Electronic, Computer and Software Systems (ECS) What defines a simulator? Why are simulators needed? Classifications Case studies
Outline Simulators and such Mats Brorsson & Mladen Nikitovic ICT Dept of Electronic, Computer and Software Systems (ECS) What defines a simulator? Why are simulators needed? Classifications Case studies
Challenges in Transition
 Challenges in Transition Keynote talk at International Workshop on Software Engineering Methods for Parallel and High Performance Applications (SEM4HPC 2016) 1 Kazuaki Ishizaki IBM Research Tokyo kiszk@acm.org
Challenges in Transition Keynote talk at International Workshop on Software Engineering Methods for Parallel and High Performance Applications (SEM4HPC 2016) 1 Kazuaki Ishizaki IBM Research Tokyo kiszk@acm.org
The world s first collaborative machine-intelligence competition to overcome spectrum scarcity
 The world s first collaborative machine-intelligence competition to overcome spectrum scarcity Paul Tilghman Program Manager, DARPA/MTO 8/11/16 1 This slide intentionally left blank 2 This slide intentionally
The world s first collaborative machine-intelligence competition to overcome spectrum scarcity Paul Tilghman Program Manager, DARPA/MTO 8/11/16 1 This slide intentionally left blank 2 This slide intentionally
Dynamic Adaptive Operating Systems -- I/O
 Dynamic Adaptive Operating Systems -- I/O Seetharami R. Seelam Patricia J. Teller University of Texas at El Paso El Paso, TX 16 November 2005 SC 05, Seattle, WA 1 Goals Present a summary of our ongoing
Dynamic Adaptive Operating Systems -- I/O Seetharami R. Seelam Patricia J. Teller University of Texas at El Paso El Paso, TX 16 November 2005 SC 05, Seattle, WA 1 Goals Present a summary of our ongoing
Wireless Communication
 Wireless Communication Systems @CS.NCTU Lecture 14: Full-Duplex Communications Instructor: Kate Ching-Ju Lin ( 林靖茹 ) 1 Outline What s full-duplex Self-Interference Cancellation Full-duplex and Half-duplex
Wireless Communication Systems @CS.NCTU Lecture 14: Full-Duplex Communications Instructor: Kate Ching-Ju Lin ( 林靖茹 ) 1 Outline What s full-duplex Self-Interference Cancellation Full-duplex and Half-duplex
Game Architecture. 4/8/16: Multiprocessor Game Loops
 Game Architecture 4/8/16: Multiprocessor Game Loops Monolithic Dead simple to set up, but it can get messy Flow-of-control can be complex Top-level may have too much knowledge of underlying systems (gross
Game Architecture 4/8/16: Multiprocessor Game Loops Monolithic Dead simple to set up, but it can get messy Flow-of-control can be complex Top-level may have too much knowledge of underlying systems (gross
Data acquisition and Trigger (with emphasis on LHC)
") Lecture 2 Data acquisition and Trigger (with emphasis on LHC) Introduction Data handling requirements for LHC Design issues: Architectures Front-end, event selection levels Trigger Future evolutions Conclusion
Lecture 2 Data acquisition and Trigger (with emphasis on LHC) Introduction Data handling requirements for LHC Design issues: Architectures Front-end, event selection levels Trigger Future evolutions Conclusion
DARPA BAA (MOABB) Frequently Asked Questions
 Frequently Asked Questions") DARPA BAA 16 13 (MOABB) Frequently Asked Questions 1) Question: Is DARPA BAA 16 13 a follow on requirement? If so, is there an incumbent contract number for this opportunity? If not, is this a new requirement?
DARPA BAA 16 13 (MOABB) Frequently Asked Questions 1) Question: Is DARPA BAA 16 13 a follow on requirement? If so, is there an incumbent contract number for this opportunity? If not, is this a new requirement?
Analysis of Dynamic Power Management on Multi-Core Processors
 Analysis of Dynamic Power Management on Multi-Core Processors W. Lloyd Bircher and Lizy K. John Laboratory for Computer Architecture Department of Electrical and Computer Engineering The University of
Analysis of Dynamic Power Management on Multi-Core Processors W. Lloyd Bircher and Lizy K. John Laboratory for Computer Architecture Department of Electrical and Computer Engineering The University of
Console Architecture 1
 Console Architecture 1 Overview What is a console? Console components Differences between consoles and PCs Benefits of console development The development environment Console game design PS3 in detail
Console Architecture 1 Overview What is a console? Console components Differences between consoles and PCs Benefits of console development The development environment Console game design PS3 in detail
A GPU-Based Real- Time Event Detection Framework for Power System Frequency Data Streams
 Engineering Conferences International ECI Digital Archives Modeling, Simulation, And Optimization for the 21st Century Electric Power Grid Proceedings Fall 10-24-2012 A GPU-Based Real- Time Event Detection
Engineering Conferences International ECI Digital Archives Modeling, Simulation, And Optimization for the 21st Century Electric Power Grid Proceedings Fall 10-24-2012 A GPU-Based Real- Time Event Detection
GPU-based data analysis for Synthetic Aperture Microwave Imaging
 GPU-based data analysis for Synthetic Aperture Microwave Imaging 1 st IAEA Technical Meeting on Fusion Data Processing, Validation and Analysis 1 st -3 rd June 2015 J.C. Chorley 1, K.J. Brunner 1, N.A.
GPU-based data analysis for Synthetic Aperture Microwave Imaging 1 st IAEA Technical Meeting on Fusion Data Processing, Validation and Analysis 1 st -3 rd June 2015 J.C. Chorley 1, K.J. Brunner 1, N.A.
Evaluation of CPU Frequency Transition Latency
 Noname manuscript No. (will be inserted by the editor) Evaluation of CPU Frequency Transition Latency Abdelhafid Mazouz Alexandre Laurent Benoît Pradelle William Jalby Abstract Dynamic Voltage and Frequency
Noname manuscript No. (will be inserted by the editor) Evaluation of CPU Frequency Transition Latency Abdelhafid Mazouz Alexandre Laurent Benoît Pradelle William Jalby Abstract Dynamic Voltage and Frequency
Data acquisition and Trigger (with emphasis on LHC)
") Lecture 2! Introduction! Data handling requirements for LHC! Design issues: Architectures! Front-end, event selection levels! Trigger! Upgrades! Conclusion Data acquisition and Trigger (with emphasis on
Lecture 2! Introduction! Data handling requirements for LHC! Design issues: Architectures! Front-end, event selection levels! Trigger! Upgrades! Conclusion Data acquisition and Trigger (with emphasis on
WAFTL: A Workload Adaptive Flash Translation Layer with Data Partition
 WAFTL: A Workload Adaptive Flash Translation Layer with Data Partition Qingsong Wei Bozhao Gong, Suraj Pathak, Bharadwaj Veeravalli, Lingfang Zeng and Kanzo Okada Data Storage Institute, A-STAR, Singapore
WAFTL: A Workload Adaptive Flash Translation Layer with Data Partition Qingsong Wei Bozhao Gong, Suraj Pathak, Bharadwaj Veeravalli, Lingfang Zeng and Kanzo Okada Data Storage Institute, A-STAR, Singapore
Radio Interface and Radio Access Techniques for LTE-Advanced
 TTA IMT-Advanced Workshop Radio Interface and Radio Access Techniques for LTE-Advanced Motohiro Tanno Radio Access Network Development Department NTT DoCoMo, Inc. June 11, 2008 Targets for for IMT-Advanced
TTA IMT-Advanced Workshop Radio Interface and Radio Access Techniques for LTE-Advanced Motohiro Tanno Radio Access Network Development Department NTT DoCoMo, Inc. June 11, 2008 Targets for for IMT-Advanced
Parallel Computing 2020: Preparing for the Post-Moore Era. Marc Snir
 Parallel Computing 2020: Preparing for the Post-Moore Era Marc Snir THE (CMOS) WORLD IS ENDING NEXT DECADE So says the International Technology Roadmap for Semiconductors (ITRS) 2 End of CMOS? IN THE LONG
Parallel Computing 2020: Preparing for the Post-Moore Era Marc Snir THE (CMOS) WORLD IS ENDING NEXT DECADE So says the International Technology Roadmap for Semiconductors (ITRS) 2 End of CMOS? IN THE LONG
System Level Analysis of Fast, Per-Core DVFS using On-Chip Switching Regulators
 System Level Analysis of Fast, Per-Core DVFS using On-Chip Switching s Wonyoung Kim, Meeta S. Gupta, Gu-Yeon Wei and David Brooks School of Engineering and Applied Sciences, Harvard University, 33 Oxford
System Level Analysis of Fast, Per-Core DVFS using On-Chip Switching s Wonyoung Kim, Meeta S. Gupta, Gu-Yeon Wei and David Brooks School of Engineering and Applied Sciences, Harvard University, 33 Oxford
CROSS-LAYER DESIGN FOR QoS WIRELESS COMMUNICATIONS
 CROSS-LAYER DESIGN FOR QoS WIRELESS COMMUNICATIONS Jie Chen, Tiejun Lv and Haitao Zheng Prepared by Cenker Demir The purpose of the authors To propose a Joint cross-layer design between MAC layer and Physical
CROSS-LAYER DESIGN FOR QoS WIRELESS COMMUNICATIONS Jie Chen, Tiejun Lv and Haitao Zheng Prepared by Cenker Demir The purpose of the authors To propose a Joint cross-layer design between MAC layer and Physical
Cherry Picking: Exploiting Process Variations in the Dark Silicon Era
 Cherry Picking: Exploiting Process Variations in the Dark Silicon Era Siddharth Garg University of Waterloo Co-authors: Bharathwaj Raghunathan, Yatish Turakhia and Diana Marculescu # Transistors Power/Dark
Cherry Picking: Exploiting Process Variations in the Dark Silicon Era Siddharth Garg University of Waterloo Co-authors: Bharathwaj Raghunathan, Yatish Turakhia and Diana Marculescu # Transistors Power/Dark
Real-Time Face Detection and Tracking for High Resolution Smart Camera System
 Digital Image Computing Techniques and Applications Real-Time Face Detection and Tracking for High Resolution Smart Camera System Y. M. Mustafah a,b, T. Shan a, A. W. Azman a,b, A. Bigdeli a, B. C. Lovell
Digital Image Computing Techniques and Applications Real-Time Face Detection and Tracking for High Resolution Smart Camera System Y. M. Mustafah a,b, T. Shan a, A. W. Azman a,b, A. Bigdeli a, B. C. Lovell
Lecture 21: Links and Signaling
 Lecture 21: Links and Signaling CSE 123: Computer Networks Alex C. Snoeren HW 3 due Wed 3/15 Lecture 21 Overview Quality of Service Signaling Channel characteristics Types of physical media Modulation
Lecture 21: Links and Signaling CSE 123: Computer Networks Alex C. Snoeren HW 3 due Wed 3/15 Lecture 21 Overview Quality of Service Signaling Channel characteristics Types of physical media Modulation
Performance Metrics. Computer Architecture. Outline. Objectives. Basic Performance Metrics. Basic Performance Metrics
 Computer Architecture Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr nizamettinaydin@gmail.com Performance Metrics http://www.yildiz.edu.tr/~naydin 1 2 Objectives How can we meaningfully measure and compare
Computer Architecture Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr nizamettinaydin@gmail.com Performance Metrics http://www.yildiz.edu.tr/~naydin 1 2 Objectives How can we meaningfully measure and compare
Author: Yih-Yih Lin. Correspondence: Yih-Yih Lin Hewlett-Packard Company MR Forest Street Marlboro, MA USA
 4 th European LS-DYNA Users Conference MPP / Linux Cluster / Hardware I A Correlation Study between MPP LS-DYNA Performance and Various Interconnection Networks a Quantitative Approach for Determining
4 th European LS-DYNA Users Conference MPP / Linux Cluster / Hardware I A Correlation Study between MPP LS-DYNA Performance and Various Interconnection Networks a Quantitative Approach for Determining
An evaluation of debayering algorithms on GPU for real-time panoramic video recording
 An evaluation of debayering algorithms on GPU for real-time panoramic video recording Ragnar Langseth, Vamsidhar Reddy Gaddam, Håkon Kvale Stensland, Carsten Griwodz, Pål Halvorsen University of Oslo /
An evaluation of debayering algorithms on GPU for real-time panoramic video recording Ragnar Langseth, Vamsidhar Reddy Gaddam, Håkon Kvale Stensland, Carsten Griwodz, Pål Halvorsen University of Oslo /
IMPROVING SCALABILITY IN MMOGS - A NEW ARCHITECTURE -
 IMPROVING SCALABILITY IN MMOGS - A NEW ARCHITECTURE - by Philippe David & Ariel Vardi Georgia Institute of Technology Outline 1.MMOGs: tremendous growth 2.Traditional MMOGs architecture and its flaws 3.Related
IMPROVING SCALABILITY IN MMOGS - A NEW ARCHITECTURE - by Philippe David & Ariel Vardi Georgia Institute of Technology Outline 1.MMOGs: tremendous growth 2.Traditional MMOGs architecture and its flaws 3.Related
Dynamic Time-Threshold Based Scheme for Voice Calls in Cellular Networks
 Dynamic Time-Threshold Based Scheme for Voice Calls in Cellular Networks Idil Candan and Muhammed Salamah Computer Engineering Department, Eastern Mediterranean University, Gazimagosa, TRNC, Mersin 10
Dynamic Time-Threshold Based Scheme for Voice Calls in Cellular Networks Idil Candan and Muhammed Salamah Computer Engineering Department, Eastern Mediterranean University, Gazimagosa, TRNC, Mersin 10
Measurement Driven Deployment of a Two-Tier Urban Mesh Access Network
 Measurement Driven Deployment of a Two-Tier Urban Mesh Access Network J. Camp, J. Robinson, C. Steger, E. Knightly Rice Networks Group MobiSys 2006 6/20/06 Two-Tier Mesh Architecture Limited Gateway Nodes
Measurement Driven Deployment of a Two-Tier Urban Mesh Access Network J. Camp, J. Robinson, C. Steger, E. Knightly Rice Networks Group MobiSys 2006 6/20/06 Two-Tier Mesh Architecture Limited Gateway Nodes
3.5: Multimedia Operating Systems Resource Management. Resource Management Synchronization. Process Management Multimedia
 Chapter 2: Basics Chapter 3: Multimedia Systems Communication Aspects and Services Multimedia Applications and Communication Multimedia Transfer and Control Protocols Quality of Service and 3.5: Multimedia
Chapter 2: Basics Chapter 3: Multimedia Systems Communication Aspects and Services Multimedia Applications and Communication Multimedia Transfer and Control Protocols Quality of Service and 3.5: Multimedia
DDR4 memory interface: Solving PCB design challenges
 DDR4 memory interface: Solving PCB design challenges Chang Fei Yee - July 23, 2014 Introduction DDR SDRAM technology has reached its 4th generation. The DDR4 SDRAM interface achieves a maximum data rate
DDR4 memory interface: Solving PCB design challenges Chang Fei Yee - July 23, 2014 Introduction DDR SDRAM technology has reached its 4th generation. The DDR4 SDRAM interface achieves a maximum data rate
Air Force Institute of Technology. A CubeSat Mission for Locating and Mapping Spot Beams of GEO Comm-Satellites
 Air Force Institute of Technology A CubeSat Mission for Locating and Mapping Spot Beams of GEO Comm-Satellites Lt. Jake LaSarge PI: Dr. Jonathan Black Dr. Brad King Dr. Gary Duke August 9, 2015 1 Outline
Air Force Institute of Technology A CubeSat Mission for Locating and Mapping Spot Beams of GEO Comm-Satellites Lt. Jake LaSarge PI: Dr. Jonathan Black Dr. Brad King Dr. Gary Duke August 9, 2015 1 Outline
Multiuser Scheduling and Power Sharing for CDMA Packet Data Systems
 Multiuser Scheduling and Power Sharing for CDMA Packet Data Systems Sandeep Vangipuram NVIDIA Graphics Pvt. Ltd. No. 10, M.G. Road, Bangalore 560001. sandeep84@gmail.com Srikrishna Bhashyam Department
Multiuser Scheduling and Power Sharing for CDMA Packet Data Systems Sandeep Vangipuram NVIDIA Graphics Pvt. Ltd. No. 10, M.G. Road, Bangalore 560001. sandeep84@gmail.com Srikrishna Bhashyam Department
2009 SEAri Annual Research Summit. Research Report. Design for Survivability: Concept Generation and Evaluation in Dynamic Tradespace Exploration
 29 Research Report Design for Survivability: Concept Generation and Evaluation in Dynamic Tradespace Exploration Matthew Richards, Ph.D. (Research Affiliate, SEAri) October 2, 29 Cambridge, MA Massachusetts
29 Research Report Design for Survivability: Concept Generation and Evaluation in Dynamic Tradespace Exploration Matthew Richards, Ph.D. (Research Affiliate, SEAri) October 2, 29 Cambridge, MA Massachusetts
Rocksmith PC Configuration and FAQ
 Rocksmith PC Configuration and FAQ September 27, 2012 Contents: Rocksmith Minimum Specs Audio Device Configuration Rocksmith Audio Configuration Rocksmith Audio Configuration (Advanced Mode) Rocksmith
Rocksmith PC Configuration and FAQ September 27, 2012 Contents: Rocksmith Minimum Specs Audio Device Configuration Rocksmith Audio Configuration Rocksmith Audio Configuration (Advanced Mode) Rocksmith
Data Center Energy Trends
 Data Center Energy Trends Data center electricity usage Increased by 56% from 2005 to 2010 1.1% to 1.5% total world electricity usage 1.7% to 2.2% total US electricity (Note: Includes impact of 2008 recession.)
Data Center Energy Trends Data center electricity usage Increased by 56% from 2005 to 2010 1.1% to 1.5% total world electricity usage 1.7% to 2.2% total US electricity (Note: Includes impact of 2008 recession.)
A fully digital clock and data recovery with fast frequency offset acquisition technique for MIPI LLI applications
 LETTER IEICE Electronics Express, Vol.10, No.10, 1 7 A fully digital clock and data recovery with fast frequency offset acquisition technique for MIPI LLI applications June-Hee Lee 1, 2, Sang-Hoon Kim
LETTER IEICE Electronics Express, Vol.10, No.10, 1 7 A fully digital clock and data recovery with fast frequency offset acquisition technique for MIPI LLI applications June-Hee Lee 1, 2, Sang-Hoon Kim
Enhancing System Architecture by Modelling the Flash Translation Layer
 Enhancing System Architecture by Modelling the Flash Translation Layer Robert Sykes Sr. Dir. Firmware August 2014 OCZ Storage Solutions A Toshiba Group Company Introduction This presentation will discuss
Enhancing System Architecture by Modelling the Flash Translation Layer Robert Sykes Sr. Dir. Firmware August 2014 OCZ Storage Solutions A Toshiba Group Company Introduction This presentation will discuss
Computer Architecture ( L), Fall 2017 HW 3: Branch handling and GPU SOLUTIONS
, Fall 2017 HW 3: Branch handling and GPU SOLUTIONS") Computer Architecture (263-2210-00L), Fall 2017 HW 3: Branch handling and GPU SOLUTIONS Instructor: Prof. Onur Mutlu TAs: Hasan Hassan, Arash Tavakkol, Mohammad Sadr, Lois Orosa, Juan Gomez Luna Assigned:
Computer Architecture (263-2210-00L), Fall 2017 HW 3: Branch handling and GPU SOLUTIONS Instructor: Prof. Onur Mutlu TAs: Hasan Hassan, Arash Tavakkol, Mohammad Sadr, Lois Orosa, Juan Gomez Luna Assigned:
CUDA 를활용한실시간 IMAGE PROCESSING SYSTEM 구현. Chang Hee Lee
 1 CUDA 를활용한실시간 IMAGE PROCESSING SYSTEM 구현 Chang Hee Lee Overview Thin film transistor(tft) LCD : Inspection Object Type of Defect Type of Inspection Instrument Brief Lighting / Focusing Optic Magnification
1 CUDA 를활용한실시간 IMAGE PROCESSING SYSTEM 구현 Chang Hee Lee Overview Thin film transistor(tft) LCD : Inspection Object Type of Defect Type of Inspection Instrument Brief Lighting / Focusing Optic Magnification
Technical Paper Review: Are All Games Equally Cloud-Gaming-Friendly? An Electromyographic Approach
 Technical Paper Review: Are All Games Equally Cloud-Gaming-Friendly? An Electromyographic Approach Kumar Gaurav CS300 October 21, 2014 1 / 19 Overview 1 Introduction 2 Related Work 3 Approach 4 Results
Technical Paper Review: Are All Games Equally Cloud-Gaming-Friendly? An Electromyographic Approach Kumar Gaurav CS300 October 21, 2014 1 / 19 Overview 1 Introduction 2 Related Work 3 Approach 4 Results
Fall 2004; E6316: Analog Systems in VLSI; 4 bit Flash A/D converter
 Fall 2004; E6316: Analog Systems in VLSI; 4 bit Flash A/D converter Nagendra Krishnapura (nkrishna@vitesse.com) due on 21 Dec. 2004 You are required to design a 4bit Flash A/D converter at 500 MS/s. The
Fall 2004; E6316: Analog Systems in VLSI; 4 bit Flash A/D converter Nagendra Krishnapura (nkrishna@vitesse.com) due on 21 Dec. 2004 You are required to design a 4bit Flash A/D converter at 500 MS/s. The
Move Evaluation Tree System
 Move Evaluation Tree System Hiroto Yoshii hiroto-yoshii@mrj.biglobe.ne.jp Abstract This paper discloses a system that evaluates moves in Go. The system Move Evaluation Tree System (METS) introduces a tree
Move Evaluation Tree System Hiroto Yoshii hiroto-yoshii@mrj.biglobe.ne.jp Abstract This paper discloses a system that evaluates moves in Go. The system Move Evaluation Tree System (METS) introduces a tree