USAGE OF COMPUTER VISION AND MACHINE LEARNING TO SOLVE 3D MAZES VISHNU NATH KAMALNATH THESIS
|
|
|
- Magnus Park
- 5 years ago
- Views:
Transcription
1 USAGE OF COMPUTER VISION AND MACHINE LEARNING TO SOLVE 3D MAZES BY VISHNU NATH KAMALNATH THESIS Submitted in partial fulfillment of the requirements for the degree of Master of Science in Computer Science in the Graduate College of the University of Illinois at Urbana-Champaign, 2013 Urbana, Illinois Advisers: Professor Stephen Levinson Assistant Professor Paris Smaragdis
2 Abstract This thesis deals with incorporating artificial intelligence into a humanoid robot by making a cognitive model of the learning process. The goal is to teach a specialized humanoid robot, the icub robot, to solve any puzzle, wherein a ball of a given color would be placed at the start position of the maze, and the robot would navigate the ball through obstacles and get the ball to the finish position. The robot would be able to move the ball through the maze by physically tilting the base of the puzzle with its hand. In the process, the robot would utilize the most efficient way possible. If no possible path exists, the robot would not begin to solve the maze. The first approach was to test the feasibility of the project and an open loop offline-learning algorithm was used to test if the robot could physically solve a given maze. Once this proved successful, the robot was then given multiple mazes that were labeled with the best path, so that it would be able to pick up on the ideal policy on its own, as a result of supervised learning. Once sufficient training was provided, the robot was tested on multiple patterns of mazes that were not seen beforehand by the robot. The robot correctly solved all test mazes that were given to it, giving it a final accuracy rate of 100%. ii
3 Acknowledgments First and foremost, I would like to thank my advisors, Dr. Stephen Levinson and Dr. Paris Smaragdis, who have supported me throughout my research with their patience and deep knowledge of the subject. They have always been there to support me and to give suggestions to improvise my research project. I attribute the level of my thesis to their constant effort and support, and without them, this thesis would not have been completed. One cannot hope for more distinguished thesis advisors in the field of machine learning. I would like to thank Luke Wendt, a Ph.D. student and a good friend, who has always been supportive of me since the very first days of my research. He recommended great books to aid me in my research and to improve my understanding of the harder concepts in machine learning and statistics. He was also my partner in the computer vision course and a lot of the progress that was made in this research experiment is directly related to the vision course. This project required a lot of tools, especially for modeling and simulation. It was Aaron Silver, a Ph.D. student and another good friend, who taught me how to use these tools. It was Aaron who patiently taught me how to begin programming a humanoid robot and spent hours on end scrutinizing his own code for me to learn. Last but not least, I would like to thank my parents for their constant support and encouragement. It was they who provided me with all the resources to become a good student and also encouraged me to enter the world of academia. iii
4 Table of Contents CHAPTER 1. INTRODUCTION... 1 CHAPTER 2. ROBOT KINEMATICS... 2 CHAPTER 3. COMPUTER VISION Offline Analysis of Maze Online Analysis of Maze RGB Threshold Selection Selection of Appropriate Grid Size CHAPTER 4. MACHINE LEARNING CHAPTER 5. EXPERIMENTAL RESULTS Open Loop Test Closed Loop Test Figures Showing the Final Path CHAPTER 6. CONCLUSION Recommended Future Studies REFERENCES iv
5 CHAPTER 1. INTRODUCTION The field of robotics has improved in leaps and bounds over the past half century. Robots have gone from mere characters in science fiction novels to indispensable servants in several fields. Assembly lines, previously staffed by humans, are now giving way to industrial robots that perform the same task hundreds of times faster, with an even better accuracy rate. As a result, it is more imperative than ever before to design robots that can perceive their surroundings and intelligently work within their environment, rather than being programmed for every possible case by a human programmer. The celebrated science fiction author Isaac Asimov has written quite a few works in the field of Artificial Intelligence. In his book I, Robot, Asimov talks about how robots would play a part in our daily lives in the near future. He goes onto predict that one day robots might be capable of emotion and they may love or hate their masters, in effect mimicking the behavior of any random human being [1]. I felt that this concept was very intriguing and it was this novel that got me into the field of Artificial Intelligence. This thesis explores the physical manipulation of the three axes of the plane of the board on which the maze is built, to roll the ball from the start point to the target or end point. The challenging part of this study is that the robot is not pre-programmed to solve the maze in question, but rather learns/infers that the goal is to solve the maze using the shortest path. Q-Learning (SARSA) was used as the learning method and the robot used was the icub humanoid robot. Chapter 2 speaks about the robot, its DH parameters and other robot hardware. Chapter 3 discusses the computer vision aspect of the project and the approaches used to solve the vision problem, while Chapter 4 discusses the Q-learning approach and the results obtained. 1

6 CHAPTER 2. ROBOT KINEMATICS The icub robot has 53 degrees of freedom. However, for the task to be accomplished, the right hand is of utmost importance since the gun would be held in the right arm. In order to get the right hand raised to the appropriate level, the first task is the computation of the DH matrices of all the joints from the robot center to the tip of the right hand. Then, the transformation matrices need to be determined in order to apply the principles of inverse kinematics. The reference frame of all the joints in the torso of the icub is given in figure 1 given below [2]. Figure 1: The x axis is in red, the y axis is in green and the z axis is in blue Furthermore, the default orientation of the right palm is given in figure 2 below, with the same color coding as above for the axes. This chapter is taken from previously published work from the degree candidate. The work has been published at the AAAI Spring Symposium 2013, Palo Alto, CA titled Learning to Fire at Targets by an icub Humanoid Robot. The authors have given permission to reprint their work. [3] 2


7 Figure 2: Default position of the right arm Also, the location of the origin of the coordinate reference frame for the icub is given in figure 3, as shown below [2]. Figure 3: The origin of the coordinate reference frame 3
8 Since the origin has been obtained, the next step is the computation of the DH parameters of the right arm in default position [4]. They have been tabulated in table 1 given below [3]. Table 1: DH Parameters of Right Arm Link a d α θ π/ π/2 - π/ π/2 - π/ π/2 - π/ π/2 - π/ π/2 - π/ π/2 π/ π/2 - π/ π/2 π/ π A simulation was run on MATLAB to double check whether the DH matrices were computed correctly. The simulation is shown in figure 4 below. 4

9 Figure 4: Position vectors of all joints As can be seen from figure 4, all the values in table 1 match the anticipated values, and the right arm is in rest along the torso of the icub robot. This led to the conclusion that the DH parameters have been computed correctly. The next step was to compute the homogenous transformation matrices and the final transformation matrix [3]. The matrices were computed to be as follows 5
10 Using the aforementioned transition matrices, we proceeded to get the right arm into firing position by having the shoulder roll, elbow and wrist yaw set to π/2. The simulation result was a perfect match to what we wanted and is shown in figure 5. 6

11 Figure 5: New position vectors of right hand From the positioning of the right arm in figure 5, it can be inferred that all calculations performed are accurate and would deliver all the anticipated results. This concludes the chapter on humanoid kinematics. 7
12 CHAPTER 3. COMPUTER VISION 3.1 Offline Analysis of Maze First the maze must be studied to obtain a control policy. This is done by analyzing a top down view of the maze. Since it is very difficult to provide a perfect orthographic view of the maze, an inverse homography must be applied to this step as well. Therefore the first thing that must be done is identification of features with known geometric relation to each other. At least four must be present to determine the inverse homography [4]. The easiest way to go about doing this is to place high contrast color markers on each corner of the maze. The color red was selected because it was not present in the maze or the surrounding background. The ball was also chosen to be red. In the initial top down analysis no ball will be present. Color thresholding provides a binary image indicating where high concentrations of red are present. Thresholding the original RGB values appear to be overly sensitive. This sensitivity can be removed by first converting to HSV coordinates. A segmentation algorithm, like RasterScan, can be used to label contiguous regions and sort them by size [4]. The four largest regions are expected to be the four corner markers. The geometry of the corners is known and therefore with a bit of logic labels can be applied to the compass markers. The markers are assumed to be related in a square manner from the top down perspective. Using this information, an inverse homography can be computed to obtain the correct top down perspective of the maze. All surrounding border content can be cropped off. The maze wall and open path are the only things that remain after this step. Choosing colors that are easily distinguished, e.g., yellow and green, allows thresholding of the open path. Again, a RasterScan will provide the open contiguous path of the maze. Once a path is obtained, it can be discretized into a grid. Important features in the image need to be tagged, like the start and goal. A high contrast color or a fiducial marker could be used or a manual user interface would work as well. Once a start and finish location are specified, reinforcement learning can 8
13 begin. The reinforcement learning simulates trial and error runs of a simulated maze environment. The control actions involve course wrist motion with long pauses. After each action the ball is at rest in one of the corners of the maze. After a sufficiently long run time value iteration converges and an optimal policy is obtained. Filtering of the optimal policy provides more general control domains. The final filtered control policy corresponding to this is then saved for online control [5]. The projected view its labels is shown in figure 6 and its inverse homography is shown in figure 7. As long as the canter of the markers and the ball in the projected view are roughly in the same plane as the center of the ball and markers in the top down view, their transformations should be isomorphic. Figure 6: Abstraction of maze with markers 9

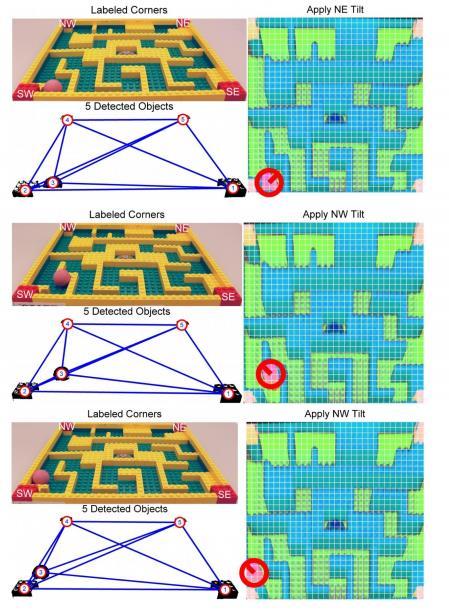
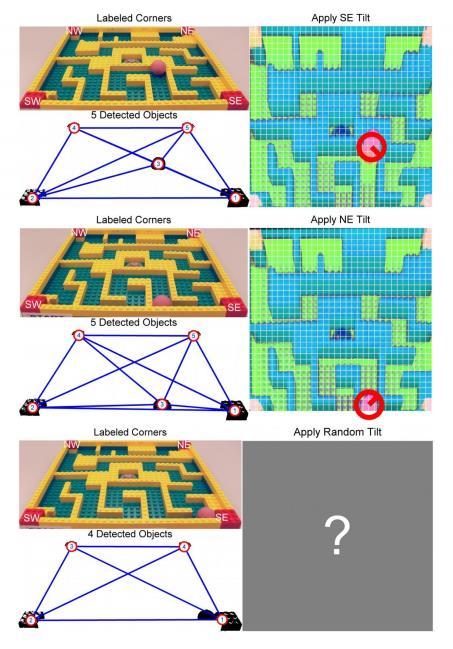
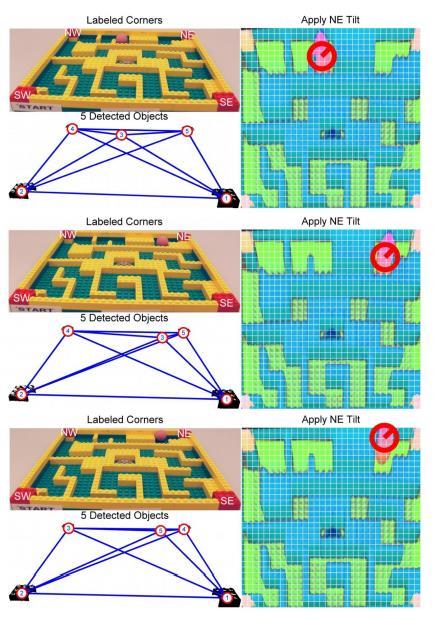
14 Figure 7: Unprojected coordinates of the maze after inverse homography 3.2 Online Analysis of Maze Once the optimal control policy is obtained, any maze can be solved online with Bert. The maze is now viewed from a projected perspective. HSV (Hue-saturation-value) color thresholding provides a binary image indicating where high concentrations of red are present, which in turn indicates the location of the corner markers and the ball. A RasterScan segmentation approach returns the largest 5 objects in the field of vision of the robot. With the known geometry of the board on which the maze is built, the markers and the ball can be labeled. From the markers, an inverse homography would return the unprojected coordinates of the maze. This inverse homography is the applied to the ball s location. After cropping and discretizing the resulting projected image, the ball s location with respect to the grid and maze can be accurately determined. The application of the optimum control policy used in the offline analysis of the maze would result in the movement of the ball. Due to this design, the robot would move the board along one of the 3 possible axes and wait for a period of time before leveling the board once 10

15 again. During this period, the ball would have progressed to another corner of the maze that is closer to the goal. 3.3 RGB Threshold Selection As mentioned before, it is known that the only red colored objects in the field of view are the four corner markers of the board and the ball itself. Therefore, it is important to threshold the RGB values of the image to facilitate the identification of the ball in the image. The RGB values of various points of the image were picked and are shown in figure 8 below. Figure 8: RGB values at various points on the board 11
16 As can be seen from figure 8, the unmapped RGB values have a very wide variation in value for seemingly similar colors. This indicates that the raw RGB values are not suitable for thresholding, but rather the HSV values are better suited. 3.4 Selection of Appropriate Grid Size The final problem that needs to be tackled, with respect to computer vision, is the resolution of the projected image of the maze i.e. the image that would be the input for online analysis for the robot. It is imperative to find the right resolution for sampling the image. Sampling below the threshold would cause degradation in the maze and may result in open segments of the maze, when in reality there are none. The resulting learned policy would then fail. On the other hand, sampling above the threshold would produce a finer resolution which would cause an exponential increase in the time taken by the learning algorithm to converge upon a solution. This issue is referred to as the curse of dimensionality in literature and is present in all uniformed dynamic programming schemes [6]. Consider figure 9 shown below. The resolution of the images from left to right are 16x16, 32x32 and 50x50 respectively. Clearly, the resolution on the left is too low since information about the ball on the grid would be lost. The robot would be able to identify the location of the ball only in terms of 4 quadrants, which would cause a large number of errors, and is definitely not the anticipated output. The image on the right displays what it is like to have a very high resolution. The location of the ball would definitely be determined, but the convergence of the learning algorithm would take unacceptable time. The image at the middle has a resolution that is a compromise between the two resolutions. This image 12

17 divides the maze into a resolution of 32x32, and can be used to determine the location of the ball with respect to the grid with sufficient accuracy and satisfactory running time. Figure 9: Determination of the resolution of the maze 13
18 CHAPTER 4. MACHINE LEARNING It is impossible for a human programmer to program every possible maze combination for the robot to solve. It is possible, however, to come up with a few examples and indicate whether the robot has obtained the correct solution or not using the best possible method. Furthermore, there is a heavy emphasis on the ability of this learning algorithm to be able to perform on-line with reasonable speed and accuracy. This forms the basis of reinforcement learning and is the fundamental algorithm that has been used to enable the robot to determine the shortest path given any maze. The update equation for temporal difference Q-Learning is given by ( ) ( ) ( ( ) ( ) ( )) (4.1) Where Q(s,a) is the Q-value of action a at state s, R(s) is the reward function of the state s, α is the learning rate and γ is the discount factor [7]. An examination of (4.1) shows that Q-learning backs up the best Q-value from the state reached in the observed transition. It pays no attention to the actual policy being followed and so is called an off-policy learning algorithm. As a result, there is no point in coming up with the optimum policy to shoot down a target if one is using an unmodified Q-learning approach [8]. Clearly, there is a need to come up with a learning algorithm that utilizes a policy that would maximize the probability of the robot solving the maze. Such an algorithm is of the on-policy type algorithm and is called the SARSA algorithm. SARSA stands for State-Action-Reward-State-Action and utilizes the optimum policy for updating the Q-values. The update equation for SARSA is given by ( ) ( ) ( ( ) ( ) ( )) (4.2) 14
19 The difference between (4.1) and (4.2) is the omission of the max term of the new Q-value. This means that SARSA actually waits until an action is taken and backs up the Q-value for that action [7]. If a greedy agent exists that always the action with the best Q-value, the two algorithms are identical. However, when exploration is needed, the algorithms vary significantly. For the objective of finding the shortest path to solve a maze, heavy exploration (or at least the consideration) of all possible paths is mandatory. Q-learning is more flexible than SARSA, i.e. an agent that learns by Q-learning can behave well even when guided by a random or adversarial exploration policy. However, SARSA is more realistic than Q-learning [9]. For example, if the overall policy is even partly controlled by other agents, it is better to learn a Q-value function for what will actually happen rather than what the agent would like to happen. Since the environment being dealt with has a lot of unknowns, accompanied by several independent agents at work, it is better to use a SARSA approach. The optimum policy is given by equation (4.3). ( ) (4.3) In equation (4.3), the posterior probability P(h e) is obtained in the standard way, by applying Bayes rule on the observations till date. This is how the feedback loop is created that would allow constant improvisation. The learning for this problem was done with value iteration of a discrete state-action space. The algorithm used a sample based quality space [10]. The specific algorithm used came from [11] and is given below. Here, φ is an index of discretized space and θ is the value at that index. The control space was U = {0,1,2,3,4} where 0 is a random action and {1,2,3,4} is a wrist tilt in the direction {North East, North West, South West, South East} respectively. The state space corresponds to the location in the n x 15
20 n discretized path space of the maze. The value of α and γ were set to 0.99 and an exploration function of Ɛ = was used. The pseudo-code of the algorithm is given below. 16

21 CHAPTER 5. EXPERIMENTAL RESULTS 5.1 Open Loop Test The very first step was to determine the feasibility of the problem. The icub robot was programmed to solve a particular maze in open loop. This first step was crucial, since it allowed us to explore the basic command interface for the problem, as well as demonstrated that the robot is physically capable of rotating the wrist sufficiently to roll the ball in any direction. At this stage, challenges dealing with grasping the board and field of view were addressed. Multiple iterations of the test were run at this stage and the robot completed the task every single time. This provided great confidence in the feasibility of the task. Figure 10 shows the robot during such a trial run during the open loop test. Figure 10 : icub during open loop test 17

22 5.2 Closed Loop Test Once it was determined that the robot could actually solve a given maze, the robot was trained over 20 different types of mazes. With each maze, it was given the start point and end point, and the robot had to determine the optimum policy of the goal, which is to get the ball from the start point to the end point using the shortest path. At the end of this point, the robot was tested on a random maze which it had never seen before. This sub-chapter discusses the results obtained at this stage of the experiment. The first step was to perform the step of inverse homography. The robot correctly identified the four corners of the board and the determined corners are shown in figure 11 below. Figure 11 : Corner estimation of the board Once the four corners have been identified, they were used to perform inverse homography so that it would be more convenient for the robot to see the projections of the ball and the interior walls of the maze. The resultant projected image is shown in figure 12 below. 18

23 Figure 12 : Projected image after inverse homography The ball can be easily identified by performing Hough Circle Transform, an approach similar to that discussed in section 3.3. The identification of the ball in this image is shown in figure
24 Figure 13 : Detection of the ball using Hough Circle Transform However, as discussed in section 3.3, the raw RGB values cannot be used to determine the location of the ball inside the maze. As a result, at this point in the on-line analysis, the raw RGB image is no longer used. Instead, the image is converted into HSV type and the analysis takes place on that. The resultant conversion of the image into HSV is shown in figure


25 Figure 14 : HSV Image Upon performing the RasterScan that was mentioned in sections 3.1 and 3.2, the four corners can be obtained. The path threshold of the maze can be easily determined from this image, in addition to the splitting of the image into a resolution of 32 x 32. Figure 15 shows the resultant image. Figure 15 : Path Thresholding 21

26 The robot would then label the path with a starting point and an ending point. The starting point would be labeled in green color, while the ending point would be labeled in red color. Figure 16 shows this visualization on the path below. Figure 16 : Start and end points labeled At this stage, the icub robot applies the normalized log value function to the threshold path. Figure 17 shows the normalized log value function of the path of the current maze, along with its color key. 22

27 Figure 17 : Normalized log value function of the path The last step is to apply the optimal control policy that has been learned from the multiple training iterations. The generated optimal control policy is shown in figure 18 for the current maze. 23

28 Figure 18 : Optimal Control Policy As can be seen from figure 18, the learning algorithm outputs a path with reasonable accuracy, but the individual grids are susceptible to noise. As a result, it is extremely likely that the robot would have an unstable movement, between the start and end point, that is governed by a random probability distribution function. In order to remove the effect of noise on the movement of the ball, a smoothing operation is performed [13]. This is the final step of the on-line computation and then the robot merely has to follow the output path. Figure 19 shows the output path after the smoothing operation has been performed. 24

29 Figure 19 ; Control Policy after Smoothing 5.3 Figures Showing the Final Path This sub-chapter contains figures that trace the ball and its associated rule from the start point to the end point. They are shown below in sequential order. 25
30 26
31 27
32 28
33 29
34 30
35 31
36 32
37 33
38 34
39 35
40 36
41 CHAPTER 6. CONCLUSION The increase in computing power and the development of better vision and learning algorithms have enabled the on-line processing of streams of visual data on a commercial CPU, in contrast to the immense computational power needed to achieve similar results just decade ago. The ability of robots to intelligently alter their environment, based on sensory perceptions, is gaining more traction than ever before. This thesis set out to achieve only a small subset of this vast and even abstract problem. The results confirmed that it is possible for robots to learn from their environments and alter their work environment to make it better. It is only the definition of better that is ambiguous and care must be taken to ensure that the robot/agent does not have the wrong definition of better. This thesis spoke about every module that needs to be implemented in order to have a humanoid robot solve a 3D maze using a colored ball. While it is relatively easy for a human to control the robot and perform this task, or even pre-program the robot, what is of special interest is the fact that the robot is completely autonomous. Existing learning algorithms were modified, specifically Q-learning and SARSA, to reduce the number of iterations it takes to converge upon the optimum policy. Lastly, this research project enabled me to work with extremely complex devices and write a program that consists of approximately half a million lines of code. 6.1 Recommended Future Studies The next step for this design is to test this learning experiment on various other objects to see if the robot is capable of grasping the connection between any two objects, and to eventually determine if the ability to make a connection between two new objects can be developed. A good example would be to 37
42 see if the robot would be able to screw a light bulb into a socket. After a couple of such trial-and-error experiments, the next step would be to determine if new connections can be made from various combinations of items that the robot has previously seen. This ability is crucial for robots to be able to come up with ideas that perhaps humans have not thought of. The first instance of this experiment would be to give the robot a pencil and an old cassette tape that has been jammed. The goal would be to rewind the tape just a little so that it is no longer jammed. As humans, we have discovered that using any cylindrical object (most commonly a pencil) of the right dimensions would achieve this task. The goal is to determine if a robot would be able to make that connection or not. The answer to this question would change the face of artificial intelligence and robotics as we understand and know it today. This is the future work that the author hopes to complete in the future. 38
43 REFERENCES [1] I. Asimov, I, Robot, Spectra, [2] "icub Robot Wiki," [Online]. [Accessed ]. [3] V. Nath and S. Levinson, "Learning to Fire at Targets by an icub Humanoid Robot," in AAAI Spring Symposium, Palo Alto, [4] J. Han, M. Kamber and J. Pei, Data Mining: Concepts and Techniques, 2nd ed., Morgan Kaufmann, [5] S. Russell and P. Norvig, Artificial Intelligence, A Modern Approach, Ner Jersey: Prentice Hall, [6] M. W. Spong, S. Hutchinson and M. Vidyasagar, Robot Modelling and Control, New Jersey: John Wiley & Sons, [7] D. Barber, Bayesian Reasoning and Machine Learning, Cambridge: University Press, [8] Michalski, Carbonell and T. Mitchell, Machine Learning, Palo Alto: Tioga Publishing Company, [9] D. Michie, On Machine Intelligence, New York: John Wiley & Sons, [10] H. Wells, The War of the Worlds, New York: NYRB Classics, [11] P. Kormushev, S. Calinon, R. Saegusa and G. Metta, "Learning the skill of archery by a humanoid icub," in 2010 IEEE-RAS International Conference on Humanoid Robotics, Nashville, [12] R. S. Sutton and A. G. Barto, Reinforcement learning: An Introduction, Cambridge: MIT Press,
44 [13] O. Sigaud and O. Buffet, Markov Decision Processes in Artificial Intelligence, Wiley, [14] L. Buşoniu, R. Babuška, B. De Schutter and D. Ernst, Reinforcement Learning and Dynamic Programming Using Function Approximators, CRC Press, [15] D. Forsyth and Ponce, Computer Vision: A Modern Approach, Prentice Hall,
Vishnu Nath. Usage of computer vision and humanoid robotics to create autonomous robots. (Ximea Currera RL04C Camera Kit)
") Vishnu Nath Usage of computer vision and humanoid robotics to create autonomous robots (Ximea Currera RL04C Camera Kit) Acknowledgements Firstly, I would like to thank Ivan Klimkovic of Ximea Corporation,
Vishnu Nath Usage of computer vision and humanoid robotics to create autonomous robots (Ximea Currera RL04C Camera Kit) Acknowledgements Firstly, I would like to thank Ivan Klimkovic of Ximea Corporation,
Deep Green. System for real-time tracking and playing the board game Reversi. Final Project Submitted by: Nadav Erell
 Deep Green System for real-time tracking and playing the board game Reversi Final Project Submitted by: Nadav Erell Introduction to Computational and Biological Vision Department of Computer Science, Ben-Gurion
Deep Green System for real-time tracking and playing the board game Reversi Final Project Submitted by: Nadav Erell Introduction to Computational and Biological Vision Department of Computer Science, Ben-Gurion
Artificial Neural Network based Mobile Robot Navigation
 Artificial Neural Network based Mobile Robot Navigation István Engedy Budapest University of Technology and Economics, Department of Measurement and Information Systems, Magyar tudósok körútja 2. H-1117,
Artificial Neural Network based Mobile Robot Navigation István Engedy Budapest University of Technology and Economics, Department of Measurement and Information Systems, Magyar tudósok körútja 2. H-1117,
UNIT VI. Current approaches to programming are classified as into two major categories:
 Unit VI 1 UNIT VI ROBOT PROGRAMMING A robot program may be defined as a path in space to be followed by the manipulator, combined with the peripheral actions that support the work cycle. Peripheral actions
Unit VI 1 UNIT VI ROBOT PROGRAMMING A robot program may be defined as a path in space to be followed by the manipulator, combined with the peripheral actions that support the work cycle. Peripheral actions
Chapter 4 SPEECH ENHANCEMENT
 44 Chapter 4 SPEECH ENHANCEMENT 4.1 INTRODUCTION: Enhancement is defined as improvement in the value or Quality of something. Speech enhancement is defined as the improvement in intelligibility and/or
44 Chapter 4 SPEECH ENHANCEMENT 4.1 INTRODUCTION: Enhancement is defined as improvement in the value or Quality of something. Speech enhancement is defined as the improvement in intelligibility and/or
Advanced Techniques for Mobile Robotics Location-Based Activity Recognition
 Advanced Techniques for Mobile Robotics Location-Based Activity Recognition Wolfram Burgard, Cyrill Stachniss, Kai Arras, Maren Bennewitz Activity Recognition Based on L. Liao, D. J. Patterson, D. Fox,
Advanced Techniques for Mobile Robotics Location-Based Activity Recognition Wolfram Burgard, Cyrill Stachniss, Kai Arras, Maren Bennewitz Activity Recognition Based on L. Liao, D. J. Patterson, D. Fox,
MECHANICAL DESIGN LEARNING ENVIRONMENTS BASED ON VIRTUAL REALITY TECHNOLOGIES
 INTERNATIONAL CONFERENCE ON ENGINEERING AND PRODUCT DESIGN EDUCATION 4 & 5 SEPTEMBER 2008, UNIVERSITAT POLITECNICA DE CATALUNYA, BARCELONA, SPAIN MECHANICAL DESIGN LEARNING ENVIRONMENTS BASED ON VIRTUAL
INTERNATIONAL CONFERENCE ON ENGINEERING AND PRODUCT DESIGN EDUCATION 4 & 5 SEPTEMBER 2008, UNIVERSITAT POLITECNICA DE CATALUNYA, BARCELONA, SPAIN MECHANICAL DESIGN LEARNING ENVIRONMENTS BASED ON VIRTUAL
Learning and Using Models of Kicking Motions for Legged Robots
 Learning and Using Models of Kicking Motions for Legged Robots Sonia Chernova and Manuela Veloso Computer Science Department Carnegie Mellon University Pittsburgh, PA 15213 {soniac, mmv}@cs.cmu.edu Abstract
Learning and Using Models of Kicking Motions for Legged Robots Sonia Chernova and Manuela Veloso Computer Science Department Carnegie Mellon University Pittsburgh, PA 15213 {soniac, mmv}@cs.cmu.edu Abstract
Reinforcement Learning Simulations and Robotics
 Reinforcement Learning Simulations and Robotics Models Partially observable noise in sensors Policy search methods rather than value functionbased approaches Isolate key parameters by choosing an appropriate
Reinforcement Learning Simulations and Robotics Models Partially observable noise in sensors Policy search methods rather than value functionbased approaches Isolate key parameters by choosing an appropriate
Fast, Robust Colour Vision for the Monash Humanoid Andrew Price Geoff Taylor Lindsay Kleeman
 Fast, Robust Colour Vision for the Monash Humanoid Andrew Price Geoff Taylor Lindsay Kleeman Intelligent Robotics Research Centre Monash University Clayton 3168, Australia andrew.price@eng.monash.edu.au
Fast, Robust Colour Vision for the Monash Humanoid Andrew Price Geoff Taylor Lindsay Kleeman Intelligent Robotics Research Centre Monash University Clayton 3168, Australia andrew.price@eng.monash.edu.au
Developing Frogger Player Intelligence Using NEAT and a Score Driven Fitness Function
 Developing Frogger Player Intelligence Using NEAT and a Score Driven Fitness Function Davis Ancona and Jake Weiner Abstract In this report, we examine the plausibility of implementing a NEAT-based solution
Developing Frogger Player Intelligence Using NEAT and a Score Driven Fitness Function Davis Ancona and Jake Weiner Abstract In this report, we examine the plausibility of implementing a NEAT-based solution
Real-World Reinforcement Learning for Autonomous Humanoid Robot Charging in a Home Environment
 Real-World Reinforcement Learning for Autonomous Humanoid Robot Charging in a Home Environment Nicolás Navarro, Cornelius Weber, and Stefan Wermter University of Hamburg, Department of Computer Science,
Real-World Reinforcement Learning for Autonomous Humanoid Robot Charging in a Home Environment Nicolás Navarro, Cornelius Weber, and Stefan Wermter University of Hamburg, Department of Computer Science,
COMPACT FUZZY Q LEARNING FOR AUTONOMOUS MOBILE ROBOT NAVIGATION
 COMPACT FUZZY Q LEARNING FOR AUTONOMOUS MOBILE ROBOT NAVIGATION Handy Wicaksono, Khairul Anam 2, Prihastono 3, Indra Adjie Sulistijono 4, Son Kuswadi 5 Department of Electrical Engineering, Petra Christian
COMPACT FUZZY Q LEARNING FOR AUTONOMOUS MOBILE ROBOT NAVIGATION Handy Wicaksono, Khairul Anam 2, Prihastono 3, Indra Adjie Sulistijono 4, Son Kuswadi 5 Department of Electrical Engineering, Petra Christian
Booklet of teaching units
 International Master Program in Mechatronic Systems for Rehabilitation Booklet of teaching units Third semester (M2 S1) Master Sciences de l Ingénieur Université Pierre et Marie Curie Paris 6 Boite 164,
International Master Program in Mechatronic Systems for Rehabilitation Booklet of teaching units Third semester (M2 S1) Master Sciences de l Ingénieur Université Pierre et Marie Curie Paris 6 Boite 164,
Creating a Poker Playing Program Using Evolutionary Computation
 Creating a Poker Playing Program Using Evolutionary Computation Simon Olsen and Rob LeGrand, Ph.D. Abstract Artificial intelligence is a rapidly expanding technology. We are surrounded by technology that
Creating a Poker Playing Program Using Evolutionary Computation Simon Olsen and Rob LeGrand, Ph.D. Abstract Artificial intelligence is a rapidly expanding technology. We are surrounded by technology that
Toward an Augmented Reality System for Violin Learning Support
 Toward an Augmented Reality System for Violin Learning Support Hiroyuki Shiino, François de Sorbier, and Hideo Saito Graduate School of Science and Technology, Keio University, Yokohama, Japan {shiino,fdesorbi,saito}@hvrl.ics.keio.ac.jp
Toward an Augmented Reality System for Violin Learning Support Hiroyuki Shiino, François de Sorbier, and Hideo Saito Graduate School of Science and Technology, Keio University, Yokohama, Japan {shiino,fdesorbi,saito}@hvrl.ics.keio.ac.jp
Robot Autonomy Project Auto Painting. Team: Ben Ballard Jimit Gandhi Mohak Bhardwaj Pratik Chatrath
 Robot Autonomy Project Auto Painting Team: Ben Ballard Jimit Gandhi Mohak Bhardwaj Pratik Chatrath Goal -Get HERB to paint autonomously Overview Initial Setup of Environment Problems to Solve Paintings:HERB,
Robot Autonomy Project Auto Painting Team: Ben Ballard Jimit Gandhi Mohak Bhardwaj Pratik Chatrath Goal -Get HERB to paint autonomously Overview Initial Setup of Environment Problems to Solve Paintings:HERB,
USING VALUE ITERATION TO SOLVE SEQUENTIAL DECISION PROBLEMS IN GAMES
 USING VALUE ITERATION TO SOLVE SEQUENTIAL DECISION PROBLEMS IN GAMES Thomas Hartley, Quasim Mehdi, Norman Gough The Research Institute in Advanced Technologies (RIATec) School of Computing and Information
USING VALUE ITERATION TO SOLVE SEQUENTIAL DECISION PROBLEMS IN GAMES Thomas Hartley, Quasim Mehdi, Norman Gough The Research Institute in Advanced Technologies (RIATec) School of Computing and Information
Visual Interpretation of Hand Gestures as a Practical Interface Modality
 Visual Interpretation of Hand Gestures as a Practical Interface Modality Frederik C. M. Kjeldsen Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate
Visual Interpretation of Hand Gestures as a Practical Interface Modality Frederik C. M. Kjeldsen Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate
Robot Task-Level Programming Language and Simulation
 Robot Task-Level Programming Language and Simulation M. Samaka Abstract This paper presents the development of a software application for Off-line robot task programming and simulation. Such application
Robot Task-Level Programming Language and Simulation M. Samaka Abstract This paper presents the development of a software application for Off-line robot task programming and simulation. Such application
CS325 Artificial Intelligence Robotics I Autonomous Robots (Ch. 25)
") CS325 Artificial Intelligence Robotics I Autonomous Robots (Ch. 25) Dr. Cengiz Günay, Emory Univ. Günay Robotics I Autonomous Robots (Ch. 25) Spring 2013 1 / 15 Robots As Killers? The word robot coined
CS325 Artificial Intelligence Robotics I Autonomous Robots (Ch. 25) Dr. Cengiz Günay, Emory Univ. Günay Robotics I Autonomous Robots (Ch. 25) Spring 2013 1 / 15 Robots As Killers? The word robot coined
Learning via Delayed Knowledge A Case of Jamming. SaiDhiraj Amuru and R. Michael Buehrer
 Learning via Delayed Knowledge A Case of Jamming SaiDhiraj Amuru and R. Michael Buehrer 1 Why do we need an Intelligent Jammer? Dynamic environment conditions in electronic warfare scenarios failure of
Learning via Delayed Knowledge A Case of Jamming SaiDhiraj Amuru and R. Michael Buehrer 1 Why do we need an Intelligent Jammer? Dynamic environment conditions in electronic warfare scenarios failure of
An Intuitional Method for Mobile Robot Path-planning in a Dynamic Environment
 An Intuitional Method for Mobile Robot Path-planning in a Dynamic Environment Ching-Chang Wong, Hung-Ren Lai, and Hui-Chieh Hou Department of Electrical Engineering, Tamkang University Tamshui, Taipei
An Intuitional Method for Mobile Robot Path-planning in a Dynamic Environment Ching-Chang Wong, Hung-Ren Lai, and Hui-Chieh Hou Department of Electrical Engineering, Tamkang University Tamshui, Taipei
Artificial Beacons with RGB-D Environment Mapping for Indoor Mobile Robot Localization
 Sensors and Materials, Vol. 28, No. 6 (2016) 695 705 MYU Tokyo 695 S & M 1227 Artificial Beacons with RGB-D Environment Mapping for Indoor Mobile Robot Localization Chun-Chi Lai and Kuo-Lan Su * Department
Sensors and Materials, Vol. 28, No. 6 (2016) 695 705 MYU Tokyo 695 S & M 1227 Artificial Beacons with RGB-D Environment Mapping for Indoor Mobile Robot Localization Chun-Chi Lai and Kuo-Lan Su * Department
Fuzzy-Heuristic Robot Navigation in a Simulated Environment
 Fuzzy-Heuristic Robot Navigation in a Simulated Environment S. K. Deshpande, M. Blumenstein and B. Verma School of Information Technology, Griffith University-Gold Coast, PMB 50, GCMC, Bundall, QLD 9726,
Fuzzy-Heuristic Robot Navigation in a Simulated Environment S. K. Deshpande, M. Blumenstein and B. Verma School of Information Technology, Griffith University-Gold Coast, PMB 50, GCMC, Bundall, QLD 9726,
Reinforcement Learning Approach to Generate Goal-directed Locomotion of a Snake-Like Robot with Screw-Drive Units
 Reinforcement Learning Approach to Generate Goal-directed Locomotion of a Snake-Like Robot with Screw-Drive Units Sromona Chatterjee, Timo Nachstedt, Florentin Wörgötter, Minija Tamosiunaite, Poramate
Reinforcement Learning Approach to Generate Goal-directed Locomotion of a Snake-Like Robot with Screw-Drive Units Sromona Chatterjee, Timo Nachstedt, Florentin Wörgötter, Minija Tamosiunaite, Poramate
Term Paper: Robot Arm Modeling
 Term Paper: Robot Arm Modeling Akul Penugonda December 10, 2014 1 Abstract This project attempts to model and verify the motion of a robot arm. The two joints used in robot arms - prismatic and rotational.
Term Paper: Robot Arm Modeling Akul Penugonda December 10, 2014 1 Abstract This project attempts to model and verify the motion of a robot arm. The two joints used in robot arms - prismatic and rotational.
Using GPS to Synthesize A Large Antenna Aperture When The Elements Are Mobile
 Using GPS to Synthesize A Large Antenna Aperture When The Elements Are Mobile Shau-Shiun Jan, Per Enge Department of Aeronautics and Astronautics Stanford University BIOGRAPHY Shau-Shiun Jan is a Ph.D.
Using GPS to Synthesize A Large Antenna Aperture When The Elements Are Mobile Shau-Shiun Jan, Per Enge Department of Aeronautics and Astronautics Stanford University BIOGRAPHY Shau-Shiun Jan is a Ph.D.
Robots Learning from Robots: A proof of Concept Study for Co-Manipulation Tasks. Luka Peternel and Arash Ajoudani Presented by Halishia Chugani
 Robots Learning from Robots: A proof of Concept Study for Co-Manipulation Tasks Luka Peternel and Arash Ajoudani Presented by Halishia Chugani Robots learning from humans 1. Robots learn from humans 2.
Robots Learning from Robots: A proof of Concept Study for Co-Manipulation Tasks Luka Peternel and Arash Ajoudani Presented by Halishia Chugani Robots learning from humans 1. Robots learn from humans 2.
Graz University of Technology (Austria)
") Graz University of Technology (Austria) I am in charge of the Vision Based Measurement Group at Graz University of Technology. The research group is focused on two main areas: Object Category Recognition
Graz University of Technology (Austria) I am in charge of the Vision Based Measurement Group at Graz University of Technology. The research group is focused on two main areas: Object Category Recognition
Confidence-Based Multi-Robot Learning from Demonstration
 Int J Soc Robot (2010) 2: 195 215 DOI 10.1007/s12369-010-0060-0 Confidence-Based Multi-Robot Learning from Demonstration Sonia Chernova Manuela Veloso Accepted: 5 May 2010 / Published online: 19 May 2010
Int J Soc Robot (2010) 2: 195 215 DOI 10.1007/s12369-010-0060-0 Confidence-Based Multi-Robot Learning from Demonstration Sonia Chernova Manuela Veloso Accepted: 5 May 2010 / Published online: 19 May 2010
Reinforcement Learning in Games Autonomous Learning Systems Seminar
 Reinforcement Learning in Games Autonomous Learning Systems Seminar Matthias Zöllner Intelligent Autonomous Systems TU-Darmstadt zoellner@rbg.informatik.tu-darmstadt.de Betreuer: Gerhard Neumann Abstract
Reinforcement Learning in Games Autonomous Learning Systems Seminar Matthias Zöllner Intelligent Autonomous Systems TU-Darmstadt zoellner@rbg.informatik.tu-darmstadt.de Betreuer: Gerhard Neumann Abstract
BODILY NON-VERBAL INTERACTION WITH VIRTUAL CHARACTERS
 KEER2010, PARIS MARCH 2-4 2010 INTERNATIONAL CONFERENCE ON KANSEI ENGINEERING AND EMOTION RESEARCH 2010 BODILY NON-VERBAL INTERACTION WITH VIRTUAL CHARACTERS Marco GILLIES *a a Department of Computing,
KEER2010, PARIS MARCH 2-4 2010 INTERNATIONAL CONFERENCE ON KANSEI ENGINEERING AND EMOTION RESEARCH 2010 BODILY NON-VERBAL INTERACTION WITH VIRTUAL CHARACTERS Marco GILLIES *a a Department of Computing,
Segmentation using Saturation Thresholding and its Application in Content-Based Retrieval of Images
 Segmentation using Saturation Thresholding and its Application in Content-Based Retrieval of Images A. Vadivel 1, M. Mohan 1, Shamik Sural 2 and A.K.Majumdar 1 1 Department of Computer Science and Engineering,
Segmentation using Saturation Thresholding and its Application in Content-Based Retrieval of Images A. Vadivel 1, M. Mohan 1, Shamik Sural 2 and A.K.Majumdar 1 1 Department of Computer Science and Engineering,
Perception. Read: AIMA Chapter 24 & Chapter HW#8 due today. Vision
 11-25-2013 Perception Vision Read: AIMA Chapter 24 & Chapter 25.3 HW#8 due today visual aural haptic & tactile vestibular (balance: equilibrium, acceleration, and orientation wrt gravity) olfactory taste
11-25-2013 Perception Vision Read: AIMA Chapter 24 & Chapter 25.3 HW#8 due today visual aural haptic & tactile vestibular (balance: equilibrium, acceleration, and orientation wrt gravity) olfactory taste
Multi-Platform Soccer Robot Development System
 Multi-Platform Soccer Robot Development System Hui Wang, Han Wang, Chunmiao Wang, William Y. C. Soh Division of Control & Instrumentation, School of EEE Nanyang Technological University Nanyang Avenue,
Multi-Platform Soccer Robot Development System Hui Wang, Han Wang, Chunmiao Wang, William Y. C. Soh Division of Control & Instrumentation, School of EEE Nanyang Technological University Nanyang Avenue,
Randomized Motion Planning for Groups of Nonholonomic Robots
 Randomized Motion Planning for Groups of Nonholonomic Robots Christopher M Clark chrisc@sun-valleystanfordedu Stephen Rock rock@sun-valleystanfordedu Department of Aeronautics & Astronautics Stanford University
Randomized Motion Planning for Groups of Nonholonomic Robots Christopher M Clark chrisc@sun-valleystanfordedu Stephen Rock rock@sun-valleystanfordedu Department of Aeronautics & Astronautics Stanford University
AN ABSTRACT OF THE THESIS OF
 AN ABSTRACT OF THE THESIS OF Jason Aaron Greco for the degree of Honors Baccalaureate of Science in Computer Science presented on August 19, 2010. Title: Automatically Generating Solutions for Sokoban
AN ABSTRACT OF THE THESIS OF Jason Aaron Greco for the degree of Honors Baccalaureate of Science in Computer Science presented on August 19, 2010. Title: Automatically Generating Solutions for Sokoban
-f/d-b '') o, q&r{laniels, Advisor. 20rt. lmage Processing of Petrographic and SEM lmages. By James Gonsiewski. The Ohio State University
 o, q&r{laniels, Advisor. 20rt. lmage Processing of Petrographic and SEM lmages. By James Gonsiewski. The Ohio State University") lmage Processing of Petrographic and SEM lmages Senior Thesis Submitted in partial fulfillment of the requirements for the Bachelor of Science Degree At The Ohio State Universitv By By James Gonsiewski
lmage Processing of Petrographic and SEM lmages Senior Thesis Submitted in partial fulfillment of the requirements for the Bachelor of Science Degree At The Ohio State Universitv By By James Gonsiewski
City Research Online. Permanent City Research Online URL:
 Child, C. H. T. & Trusler, B. P. (2014). Implementing Racing AI using Q-Learning and Steering Behaviours. Paper presented at the GAMEON 2014 (15th annual European Conference on Simulation and AI in Computer
Child, C. H. T. & Trusler, B. P. (2014). Implementing Racing AI using Q-Learning and Steering Behaviours. Paper presented at the GAMEON 2014 (15th annual European Conference on Simulation and AI in Computer
Colour Profiling Using Multiple Colour Spaces
 Colour Profiling Using Multiple Colour Spaces Nicola Duffy and Gerard Lacey Computer Vision and Robotics Group, Trinity College, Dublin.Ireland duffynn@cs.tcd.ie Abstract This paper presents an original
Colour Profiling Using Multiple Colour Spaces Nicola Duffy and Gerard Lacey Computer Vision and Robotics Group, Trinity College, Dublin.Ireland duffynn@cs.tcd.ie Abstract This paper presents an original
Lab Design of FANUC Robot Operation for Engineering Technology Major Students
 Paper ID #21185 Lab Design of FANUC Robot Operation for Engineering Technology Major Students Dr. Maged Mikhail, Purdue University Northwest Dr. Maged B.Mikhail, Assistant Professor, Mechatronics Engineering
Paper ID #21185 Lab Design of FANUC Robot Operation for Engineering Technology Major Students Dr. Maged Mikhail, Purdue University Northwest Dr. Maged B.Mikhail, Assistant Professor, Mechatronics Engineering
Distributed Vision System: A Perceptual Information Infrastructure for Robot Navigation
 Distributed Vision System: A Perceptual Information Infrastructure for Robot Navigation Hiroshi Ishiguro Department of Information Science, Kyoto University Sakyo-ku, Kyoto 606-01, Japan E-mail: ishiguro@kuis.kyoto-u.ac.jp
Distributed Vision System: A Perceptual Information Infrastructure for Robot Navigation Hiroshi Ishiguro Department of Information Science, Kyoto University Sakyo-ku, Kyoto 606-01, Japan E-mail: ishiguro@kuis.kyoto-u.ac.jp
Affordance based Human Motion Synthesizing System
 Affordance based Human Motion Synthesizing System H. Ishii, N. Ichiguchi, D. Komaki, H. Shimoda and H. Yoshikawa Graduate School of Energy Science Kyoto University Uji-shi, Kyoto, 611-0011, Japan Abstract
Affordance based Human Motion Synthesizing System H. Ishii, N. Ichiguchi, D. Komaki, H. Shimoda and H. Yoshikawa Graduate School of Energy Science Kyoto University Uji-shi, Kyoto, 611-0011, Japan Abstract
Vision System for a Robot Guide System
 Vision System for a Robot Guide System Yu Wua Wong 1, Liqiong Tang 2, Donald Bailey 1 1 Institute of Information Sciences and Technology, 2 Institute of Technology and Engineering Massey University, Palmerston
Vision System for a Robot Guide System Yu Wua Wong 1, Liqiong Tang 2, Donald Bailey 1 1 Institute of Information Sciences and Technology, 2 Institute of Technology and Engineering Massey University, Palmerston
ROBOCODE PROJECT AIBOT - MARKOV MODEL DRIVEN AIMING COMBINED WITH Q LEARNING FOR MOVEMENT
 ROBOCODE PROJECT AIBOT - MARKOV MODEL DRIVEN AIMING COMBINED WITH Q LEARNING FOR MOVEMENT PATRICK HALUPTZOK, XU MIAO Abstract. In this paper the development of a robot controller for Robocode is discussed.
ROBOCODE PROJECT AIBOT - MARKOV MODEL DRIVEN AIMING COMBINED WITH Q LEARNING FOR MOVEMENT PATRICK HALUPTZOK, XU MIAO Abstract. In this paper the development of a robot controller for Robocode is discussed.
CHAPTER-4 FRUIT QUALITY GRADATION USING SHAPE, SIZE AND DEFECT ATTRIBUTES
 CHAPTER-4 FRUIT QUALITY GRADATION USING SHAPE, SIZE AND DEFECT ATTRIBUTES In addition to colour based estimation of apple quality, various models have been suggested to estimate external attribute based
CHAPTER-4 FRUIT QUALITY GRADATION USING SHAPE, SIZE AND DEFECT ATTRIBUTES In addition to colour based estimation of apple quality, various models have been suggested to estimate external attribute based
Classroom Konnect. Artificial Intelligence and Machine Learning
 Artificial Intelligence and Machine Learning 1. What is Machine Learning (ML)? The general idea about Machine Learning (ML) can be traced back to 1959 with the approach proposed by Arthur Samuel, one of
Artificial Intelligence and Machine Learning 1. What is Machine Learning (ML)? The general idea about Machine Learning (ML) can be traced back to 1959 with the approach proposed by Arthur Samuel, one of
Distributed Collaborative Path Planning in Sensor Networks with Multiple Mobile Sensor Nodes
 7th Mediterranean Conference on Control & Automation Makedonia Palace, Thessaloniki, Greece June 4-6, 009 Distributed Collaborative Path Planning in Sensor Networks with Multiple Mobile Sensor Nodes Theofanis
7th Mediterranean Conference on Control & Automation Makedonia Palace, Thessaloniki, Greece June 4-6, 009 Distributed Collaborative Path Planning in Sensor Networks with Multiple Mobile Sensor Nodes Theofanis
A Memory-Efficient Method for Fast Computation of Short 15-Puzzle Solutions
 A Memory-Efficient Method for Fast Computation of Short 15-Puzzle Solutions Ian Parberry Technical Report LARC-2014-02 Laboratory for Recreational Computing Department of Computer Science & Engineering
A Memory-Efficient Method for Fast Computation of Short 15-Puzzle Solutions Ian Parberry Technical Report LARC-2014-02 Laboratory for Recreational Computing Department of Computer Science & Engineering
I R UNDERGRADUATE REPORT. Hardware and Design Factors for the Implementation of Virtual Reality as a Training Tool. by Walter Miranda Advisor:
 UNDERGRADUATE REPORT Hardware and Design Factors for the Implementation of Virtual Reality as a Training Tool by Walter Miranda Advisor: UG 2006-10 I R INSTITUTE FOR SYSTEMS RESEARCH ISR develops, applies
UNDERGRADUATE REPORT Hardware and Design Factors for the Implementation of Virtual Reality as a Training Tool by Walter Miranda Advisor: UG 2006-10 I R INSTITUTE FOR SYSTEMS RESEARCH ISR develops, applies
More Info at Open Access Database by S. Dutta and T. Schmidt
 More Info at Open Access Database www.ndt.net/?id=17657 New concept for higher Robot position accuracy during thermography measurement to be implemented with the existing prototype automated thermography
More Info at Open Access Database www.ndt.net/?id=17657 New concept for higher Robot position accuracy during thermography measurement to be implemented with the existing prototype automated thermography
Sokoban: Reversed Solving
 Sokoban: Reversed Solving Frank Takes (ftakes@liacs.nl) Leiden Institute of Advanced Computer Science (LIACS), Leiden University June 20, 2008 Abstract This article describes a new method for attempting
Sokoban: Reversed Solving Frank Takes (ftakes@liacs.nl) Leiden Institute of Advanced Computer Science (LIACS), Leiden University June 20, 2008 Abstract This article describes a new method for attempting
Transactions on Information and Communications Technologies vol 6, 1994 WIT Press, ISSN
 Application of artificial neural networks to the robot path planning problem P. Martin & A.P. del Pobil Department of Computer Science, Jaume I University, Campus de Penyeta Roja, 207 Castellon, Spain
Application of artificial neural networks to the robot path planning problem P. Martin & A.P. del Pobil Department of Computer Science, Jaume I University, Campus de Penyeta Roja, 207 Castellon, Spain
A Novel Cognitive Anti-jamming Stochastic Game
 A Novel Cognitive Anti-jamming Stochastic Game Mohamed Aref and Sudharman K. Jayaweera Communication and Information Sciences Laboratory (CISL) ECE, University of New Mexico, Albuquerque, NM and Bluecom
A Novel Cognitive Anti-jamming Stochastic Game Mohamed Aref and Sudharman K. Jayaweera Communication and Information Sciences Laboratory (CISL) ECE, University of New Mexico, Albuquerque, NM and Bluecom
Image Extraction using Image Mining Technique
 IOSR Journal of Engineering (IOSRJEN) e-issn: 2250-3021, p-issn: 2278-8719 Vol. 3, Issue 9 (September. 2013), V2 PP 36-42 Image Extraction using Image Mining Technique Prof. Samir Kumar Bandyopadhyay,
IOSR Journal of Engineering (IOSRJEN) e-issn: 2250-3021, p-issn: 2278-8719 Vol. 3, Issue 9 (September. 2013), V2 PP 36-42 Image Extraction using Image Mining Technique Prof. Samir Kumar Bandyopadhyay,
MarineBlue: A Low-Cost Chess Robot
 MarineBlue: A Low-Cost Chess Robot David URTING and Yolande BERBERS {David.Urting, Yolande.Berbers}@cs.kuleuven.ac.be KULeuven, Department of Computer Science Celestijnenlaan 200A, B-3001 LEUVEN Belgium
MarineBlue: A Low-Cost Chess Robot David URTING and Yolande BERBERS {David.Urting, Yolande.Berbers}@cs.kuleuven.ac.be KULeuven, Department of Computer Science Celestijnenlaan 200A, B-3001 LEUVEN Belgium
Designing Toys That Come Alive: Curious Robots for Creative Play
 Designing Toys That Come Alive: Curious Robots for Creative Play Kathryn Merrick School of Information Technologies and Electrical Engineering University of New South Wales, Australian Defence Force Academy
Designing Toys That Come Alive: Curious Robots for Creative Play Kathryn Merrick School of Information Technologies and Electrical Engineering University of New South Wales, Australian Defence Force Academy
Evolving High-Dimensional, Adaptive Camera-Based Speed Sensors
 In: M.H. Hamza (ed.), Proceedings of the 21st IASTED Conference on Applied Informatics, pp. 1278-128. Held February, 1-1, 2, Insbruck, Austria Evolving High-Dimensional, Adaptive Camera-Based Speed Sensors
In: M.H. Hamza (ed.), Proceedings of the 21st IASTED Conference on Applied Informatics, pp. 1278-128. Held February, 1-1, 2, Insbruck, Austria Evolving High-Dimensional, Adaptive Camera-Based Speed Sensors
Using Reactive and Adaptive Behaviors to Play Soccer
 AI Magazine Volume 21 Number 3 (2000) ( AAAI) Articles Using Reactive and Adaptive Behaviors to Play Soccer Vincent Hugel, Patrick Bonnin, and Pierre Blazevic This work deals with designing simple behaviors
AI Magazine Volume 21 Number 3 (2000) ( AAAI) Articles Using Reactive and Adaptive Behaviors to Play Soccer Vincent Hugel, Patrick Bonnin, and Pierre Blazevic This work deals with designing simple behaviors
PHYSICAL ROBOTS PROGRAMMING BY IMITATION USING VIRTUAL ROBOT PROTOTYPES
 Bulletin of the Transilvania University of Braşov Series I: Engineering Sciences Vol. 6 (55) No. 2-2013 PHYSICAL ROBOTS PROGRAMMING BY IMITATION USING VIRTUAL ROBOT PROTOTYPES A. FRATU 1 M. FRATU 2 Abstract:
Bulletin of the Transilvania University of Braşov Series I: Engineering Sciences Vol. 6 (55) No. 2-2013 PHYSICAL ROBOTS PROGRAMMING BY IMITATION USING VIRTUAL ROBOT PROTOTYPES A. FRATU 1 M. FRATU 2 Abstract:
Learning Actions from Demonstration
 Learning Actions from Demonstration Michael Tirtowidjojo, Matthew Frierson, Benjamin Singer, Palak Hirpara October 2, 2016 Abstract The goal of our project is twofold. First, we will design a controller
Learning Actions from Demonstration Michael Tirtowidjojo, Matthew Frierson, Benjamin Singer, Palak Hirpara October 2, 2016 Abstract The goal of our project is twofold. First, we will design a controller
CHAPTER 5 INDUSTRIAL ROBOTICS
 CHAPTER 5 INDUSTRIAL ROBOTICS 5.1 Basic of Robotics 5.1.1 Introduction There are two widely used definitions of industrial robots : i) An industrial robot is a reprogrammable, multifunctional manipulator
CHAPTER 5 INDUSTRIAL ROBOTICS 5.1 Basic of Robotics 5.1.1 Introduction There are two widely used definitions of industrial robots : i) An industrial robot is a reprogrammable, multifunctional manipulator
JEPPIAAR ENGINEERING COLLEGE
 JEPPIAAR ENGINEERING COLLEGE Jeppiaar Nagar, Rajiv Gandhi Salai 600 119 DEPARTMENT OFMECHANICAL ENGINEERING QUESTION BANK VII SEMESTER ME6010 ROBOTICS Regulation 013 JEPPIAAR ENGINEERING COLLEGE Jeppiaar
JEPPIAAR ENGINEERING COLLEGE Jeppiaar Nagar, Rajiv Gandhi Salai 600 119 DEPARTMENT OFMECHANICAL ENGINEERING QUESTION BANK VII SEMESTER ME6010 ROBOTICS Regulation 013 JEPPIAAR ENGINEERING COLLEGE Jeppiaar
IMAGE INTENSIFICATION TECHNIQUE USING HORIZONTAL SITUATION INDICATOR
 IMAGE INTENSIFICATION TECHNIQUE USING HORIZONTAL SITUATION INDICATOR Naveen Kumar Mandadi 1, B.Praveen Kumar 2, M.Nagaraju 3, 1,2,3 Assistant Professor, Department of ECE, SRTIST, Nalgonda (India) ABSTRACT
IMAGE INTENSIFICATION TECHNIQUE USING HORIZONTAL SITUATION INDICATOR Naveen Kumar Mandadi 1, B.Praveen Kumar 2, M.Nagaraju 3, 1,2,3 Assistant Professor, Department of ECE, SRTIST, Nalgonda (India) ABSTRACT
Learning and Using Models of Kicking Motions for Legged Robots
 Learning and Using Models of Kicking Motions for Legged Robots Sonia Chernova and Manuela Veloso Computer Science Department Carnegie Mellon University Pittsburgh, PA 15213 {soniac, mmv}@cs.cmu.edu Abstract
Learning and Using Models of Kicking Motions for Legged Robots Sonia Chernova and Manuela Veloso Computer Science Department Carnegie Mellon University Pittsburgh, PA 15213 {soniac, mmv}@cs.cmu.edu Abstract
Digital Control of MS-150 Modular Position Servo System
 IEEE NECEC Nov. 8, 2007 St. John's NL 1 Digital Control of MS-150 Modular Position Servo System Farid Arvani, Syeda N. Ferdaus, M. Tariq Iqbal Faculty of Engineering, Memorial University of Newfoundland
IEEE NECEC Nov. 8, 2007 St. John's NL 1 Digital Control of MS-150 Modular Position Servo System Farid Arvani, Syeda N. Ferdaus, M. Tariq Iqbal Faculty of Engineering, Memorial University of Newfoundland
A Semi-Minimalistic Approach to Humanoid Design
 International Journal of Scientific and Research Publications, Volume 2, Issue 4, April 2012 1 A Semi-Minimalistic Approach to Humanoid Design Hari Krishnan R., Vallikannu A.L. Department of Electronics
International Journal of Scientific and Research Publications, Volume 2, Issue 4, April 2012 1 A Semi-Minimalistic Approach to Humanoid Design Hari Krishnan R., Vallikannu A.L. Department of Electronics
ISMCR2004. Abstract. 2. The mechanism of the master-slave arm of Telesar II. 1. Introduction. D21-Page 1
 Development of Multi-D.O.F. Master-Slave Arm with Bilateral Impedance Control for Telexistence Riichiro Tadakuma, Kiyohiro Sogen, Hiroyuki Kajimoto, Naoki Kawakami, and Susumu Tachi 7-3-1 Hongo, Bunkyo-ku,
Development of Multi-D.O.F. Master-Slave Arm with Bilateral Impedance Control for Telexistence Riichiro Tadakuma, Kiyohiro Sogen, Hiroyuki Kajimoto, Naoki Kawakami, and Susumu Tachi 7-3-1 Hongo, Bunkyo-ku,
Cognitive robots and emotional intelligence Cloud robotics Ethical, legal and social issues of robotic Construction robots Human activities in many
 Preface The jubilee 25th International Conference on Robotics in Alpe-Adria-Danube Region, RAAD 2016 was held in the conference centre of the Best Western Hotel M, Belgrade, Serbia, from 30 June to 2 July
Preface The jubilee 25th International Conference on Robotics in Alpe-Adria-Danube Region, RAAD 2016 was held in the conference centre of the Best Western Hotel M, Belgrade, Serbia, from 30 June to 2 July
Chapter 1 Introduction
 Chapter 1 Introduction It is appropriate to begin the textbook on robotics with the definition of the industrial robot manipulator as given by the ISO 8373 standard. An industrial robot manipulator is
Chapter 1 Introduction It is appropriate to begin the textbook on robotics with the definition of the industrial robot manipulator as given by the ISO 8373 standard. An industrial robot manipulator is
Diagnostics of Bearing Defects Using Vibration Signal
 Diagnostics of Bearing Defects Using Vibration Signal Kayode Oyeniyi Oyedoja Abstract Current trend toward industrial automation requires the replacement of supervision and monitoring roles traditionally
Diagnostics of Bearing Defects Using Vibration Signal Kayode Oyeniyi Oyedoja Abstract Current trend toward industrial automation requires the replacement of supervision and monitoring roles traditionally
Extended Kalman Filtering
 Extended Kalman Filtering Andre Cornman, Darren Mei Stanford EE 267, Virtual Reality, Course Report, Instructors: Gordon Wetzstein and Robert Konrad Abstract When working with virtual reality, one of the
Extended Kalman Filtering Andre Cornman, Darren Mei Stanford EE 267, Virtual Reality, Course Report, Instructors: Gordon Wetzstein and Robert Konrad Abstract When working with virtual reality, one of the
Game Mechanics Minesweeper is a game in which the player must correctly deduce the positions of
 Table of Contents Game Mechanics...2 Game Play...3 Game Strategy...4 Truth...4 Contrapositive... 5 Exhaustion...6 Burnout...8 Game Difficulty... 10 Experiment One... 12 Experiment Two...14 Experiment Three...16
Table of Contents Game Mechanics...2 Game Play...3 Game Strategy...4 Truth...4 Contrapositive... 5 Exhaustion...6 Burnout...8 Game Difficulty... 10 Experiment One... 12 Experiment Two...14 Experiment Three...16
Trajectory Generation for a Mobile Robot by Reinforcement Learning
 1 Trajectory Generation for a Mobile Robot by Reinforcement Learning Masaki Shimizu 1, Makoto Fujita 2, and Hiroyuki Miyamoto 3 1 Kyushu Institute of Technology, Kitakyushu, Japan shimizu-masaki@edu.brain.kyutech.ac.jp
1 Trajectory Generation for a Mobile Robot by Reinforcement Learning Masaki Shimizu 1, Makoto Fujita 2, and Hiroyuki Miyamoto 3 1 Kyushu Institute of Technology, Kitakyushu, Japan shimizu-masaki@edu.brain.kyutech.ac.jp
Artificial Intelligence: An overview
 Artificial Intelligence: An overview Thomas Trappenberg January 4, 2009 Based on the slides provided by Russell and Norvig, Chapter 1 & 2 What is AI? Systems that think like humans Systems that act like
Artificial Intelligence: An overview Thomas Trappenberg January 4, 2009 Based on the slides provided by Russell and Norvig, Chapter 1 & 2 What is AI? Systems that think like humans Systems that act like
Playing CHIP-8 Games with Reinforcement Learning
 Playing CHIP-8 Games with Reinforcement Learning Niven Achenjang, Patrick DeMichele, Sam Rogers Stanford University Abstract We begin with some background in the history of CHIP-8 games and the use of
Playing CHIP-8 Games with Reinforcement Learning Niven Achenjang, Patrick DeMichele, Sam Rogers Stanford University Abstract We begin with some background in the history of CHIP-8 games and the use of
Perception. Introduction to HRI Simmons & Nourbakhsh Spring 2015
 Perception Introduction to HRI Simmons & Nourbakhsh Spring 2015 Perception my goals What is the state of the art boundary? Where might we be in 5-10 years? The Perceptual Pipeline The classical approach:
Perception Introduction to HRI Simmons & Nourbakhsh Spring 2015 Perception my goals What is the state of the art boundary? Where might we be in 5-10 years? The Perceptual Pipeline The classical approach:
Introduction to Artificial Intelligence
 Introduction to Artificial Intelligence By Budditha Hettige Sources: Based on An Introduction to Multi-agent Systems by Michael Wooldridge, John Wiley & Sons, 2002 Artificial Intelligence A Modern Approach,
Introduction to Artificial Intelligence By Budditha Hettige Sources: Based on An Introduction to Multi-agent Systems by Michael Wooldridge, John Wiley & Sons, 2002 Artificial Intelligence A Modern Approach,
Dipartimento di Elettronica Informazione e Bioingegneria Robotics
 Dipartimento di Elettronica Informazione e Bioingegneria Robotics Behavioral robotics @ 2014 Behaviorism behave is what organisms do Behaviorism is built on this assumption, and its goal is to promote
Dipartimento di Elettronica Informazione e Bioingegneria Robotics Behavioral robotics @ 2014 Behaviorism behave is what organisms do Behaviorism is built on this assumption, and its goal is to promote
AGENT PLATFORM FOR ROBOT CONTROL IN REAL-TIME DYNAMIC ENVIRONMENTS. Nuno Sousa Eugénio Oliveira
 AGENT PLATFORM FOR ROBOT CONTROL IN REAL-TIME DYNAMIC ENVIRONMENTS Nuno Sousa Eugénio Oliveira Faculdade de Egenharia da Universidade do Porto, Portugal Abstract: This paper describes a platform that enables
AGENT PLATFORM FOR ROBOT CONTROL IN REAL-TIME DYNAMIC ENVIRONMENTS Nuno Sousa Eugénio Oliveira Faculdade de Egenharia da Universidade do Porto, Portugal Abstract: This paper describes a platform that enables
10703 Deep Reinforcement Learning and Control
 10703 Deep Reinforcement Learning and Control Russ Salakhutdinov Slides borrowed from Katerina Fragkiadaki Solving known MDPs: Dynamic Programming Markov Decision Process (MDP)! A Markov Decision Process
10703 Deep Reinforcement Learning and Control Russ Salakhutdinov Slides borrowed from Katerina Fragkiadaki Solving known MDPs: Dynamic Programming Markov Decision Process (MDP)! A Markov Decision Process
Recommended Text. Logistics. Course Logistics. Intelligent Robotic Systems
 Recommended Text Intelligent Robotic Systems CS 685 Jana Kosecka, 4444 Research II kosecka@gmu.edu, 3-1876 [1] S. LaValle: Planning Algorithms, Cambridge Press, http://planning.cs.uiuc.edu/ [2] S. Thrun,
Recommended Text Intelligent Robotic Systems CS 685 Jana Kosecka, 4444 Research II kosecka@gmu.edu, 3-1876 [1] S. LaValle: Planning Algorithms, Cambridge Press, http://planning.cs.uiuc.edu/ [2] S. Thrun,
Soar-RL A Year of Learning
 Soar-RL A Year of Learning Nate Derbinsky University of Michigan Outline The Big Picture Developing Soar-RL Agents Controlling the Soar-RL Algorithm Debugging Soar-RL Soar-RL Performance Nuggets & Coal
Soar-RL A Year of Learning Nate Derbinsky University of Michigan Outline The Big Picture Developing Soar-RL Agents Controlling the Soar-RL Algorithm Debugging Soar-RL Soar-RL Performance Nuggets & Coal
Q Learning Behavior on Autonomous Navigation of Physical Robot
 The 8th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI 211) Nov. 23-26, 211 in Songdo ConventiA, Incheon, Korea Q Learning Behavior on Autonomous Navigation of Physical Robot
The 8th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI 211) Nov. 23-26, 211 in Songdo ConventiA, Incheon, Korea Q Learning Behavior on Autonomous Navigation of Physical Robot
Supervisory Control for Cost-Effective Redistribution of Robotic Swarms
 Supervisory Control for Cost-Effective Redistribution of Robotic Swarms Ruikun Luo Department of Mechaincal Engineering College of Engineering Carnegie Mellon University Pittsburgh, Pennsylvania 11 Email:
Supervisory Control for Cost-Effective Redistribution of Robotic Swarms Ruikun Luo Department of Mechaincal Engineering College of Engineering Carnegie Mellon University Pittsburgh, Pennsylvania 11 Email:
NAVIGATION OF MOBILE ROBOT USING THE PSO PARTICLE SWARM OPTIMIZATION
 Journal of Academic and Applied Studies (JAAS) Vol. 2(1) Jan 2012, pp. 32-38 Available online @ www.academians.org ISSN1925-931X NAVIGATION OF MOBILE ROBOT USING THE PSO PARTICLE SWARM OPTIMIZATION Sedigheh
Journal of Academic and Applied Studies (JAAS) Vol. 2(1) Jan 2012, pp. 32-38 Available online @ www.academians.org ISSN1925-931X NAVIGATION OF MOBILE ROBOT USING THE PSO PARTICLE SWARM OPTIMIZATION Sedigheh
Moving Obstacle Avoidance for Mobile Robot Moving on Designated Path
 Moving Obstacle Avoidance for Mobile Robot Moving on Designated Path Taichi Yamada 1, Yeow Li Sa 1 and Akihisa Ohya 1 1 Graduate School of Systems and Information Engineering, University of Tsukuba, 1-1-1,
Moving Obstacle Avoidance for Mobile Robot Moving on Designated Path Taichi Yamada 1, Yeow Li Sa 1 and Akihisa Ohya 1 1 Graduate School of Systems and Information Engineering, University of Tsukuba, 1-1-1,
Auto-tagging The Facebook
 Auto-tagging The Facebook Jonathan Michelson and Jorge Ortiz Stanford University 2006 E-mail: JonMich@Stanford.edu, jorge.ortiz@stanford.com Introduction For those not familiar, The Facebook is an extremely
Auto-tagging The Facebook Jonathan Michelson and Jorge Ortiz Stanford University 2006 E-mail: JonMich@Stanford.edu, jorge.ortiz@stanford.com Introduction For those not familiar, The Facebook is an extremely
CS 188 Fall Introduction to Artificial Intelligence Midterm 1
 CS 188 Fall 2018 Introduction to Artificial Intelligence Midterm 1 You have 120 minutes. The time will be projected at the front of the room. You may not leave during the last 10 minutes of the exam. Do
CS 188 Fall 2018 Introduction to Artificial Intelligence Midterm 1 You have 120 minutes. The time will be projected at the front of the room. You may not leave during the last 10 minutes of the exam. Do
Creating a 3D environment map from 2D camera images in robotics
 Creating a 3D environment map from 2D camera images in robotics J.P. Niemantsverdriet jelle@niemantsverdriet.nl 4th June 2003 Timorstraat 6A 9715 LE Groningen student number: 0919462 internal advisor:
Creating a 3D environment map from 2D camera images in robotics J.P. Niemantsverdriet jelle@niemantsverdriet.nl 4th June 2003 Timorstraat 6A 9715 LE Groningen student number: 0919462 internal advisor:
The UPennalizers RoboCup Standard Platform League Team Description Paper 2017
 The UPennalizers RoboCup Standard Platform League Team Description Paper 2017 Yongbo Qian, Xiang Deng, Alex Baucom and Daniel D. Lee GRASP Lab, University of Pennsylvania, Philadelphia PA 19104, USA, https://www.grasp.upenn.edu/
The UPennalizers RoboCup Standard Platform League Team Description Paper 2017 Yongbo Qian, Xiang Deng, Alex Baucom and Daniel D. Lee GRASP Lab, University of Pennsylvania, Philadelphia PA 19104, USA, https://www.grasp.upenn.edu/
RISTO MIIKKULAINEN, SENTIENT (HTTP://VENTUREBEAT.COM/AUTHOR/RISTO-MIIKKULAINEN- SATIENT/) APRIL 3, :23 PM
 APRIL 3, :23 PM") 1,2 Guest Machines are becoming more creative than humans RISTO MIIKKULAINEN, SENTIENT (HTTP://VENTUREBEAT.COM/AUTHOR/RISTO-MIIKKULAINEN- SATIENT/) APRIL 3, 2016 12:23 PM TAGS: ARTIFICIAL INTELLIGENCE
1,2 Guest Machines are becoming more creative than humans RISTO MIIKKULAINEN, SENTIENT (HTTP://VENTUREBEAT.COM/AUTHOR/RISTO-MIIKKULAINEN- SATIENT/) APRIL 3, 2016 12:23 PM TAGS: ARTIFICIAL INTELLIGENCE
Assignment 1 IN5480: interaction with AI s
 Assignment 1 IN5480: interaction with AI s Artificial Intelligence definitions 1. Artificial intelligence (AI) is an area of computer science that emphasizes the creation of intelligent machines that work
Assignment 1 IN5480: interaction with AI s Artificial Intelligence definitions 1. Artificial intelligence (AI) is an area of computer science that emphasizes the creation of intelligent machines that work
4/9/2015. Simple Graphics and Image Processing. Simple Graphics. Overview of Turtle Graphics (continued) Overview of Turtle Graphics
 Overview of Turtle Graphics") Simple Graphics and Image Processing The Plan For Today Website Updates Intro to Python Quiz Corrections Missing Assignments Graphics and Images Simple Graphics Turtle Graphics Image Processing Assignment
Simple Graphics and Image Processing The Plan For Today Website Updates Intro to Python Quiz Corrections Missing Assignments Graphics and Images Simple Graphics Turtle Graphics Image Processing Assignment
The Effect of Opponent Noise on Image Quality
 The Effect of Opponent Noise on Image Quality Garrett M. Johnson * and Mark D. Fairchild Munsell Color Science Laboratory, Rochester Institute of Technology Rochester, NY 14623 ABSTRACT A psychophysical
The Effect of Opponent Noise on Image Quality Garrett M. Johnson * and Mark D. Fairchild Munsell Color Science Laboratory, Rochester Institute of Technology Rochester, NY 14623 ABSTRACT A psychophysical
Learning Attentive-Depth Switching while Interacting with an Agent
 Learning Attentive-Depth Switching while Interacting with an Agent Chyon Hae Kim, Hiroshi Tsujino, and Hiroyuki Nakahara Abstract This paper addresses a learning system design for a robot based on an extended
Learning Attentive-Depth Switching while Interacting with an Agent Chyon Hae Kim, Hiroshi Tsujino, and Hiroyuki Nakahara Abstract This paper addresses a learning system design for a robot based on an extended
Generating Personality Character in a Face Robot through Interaction with Human
 Generating Personality Character in a Face Robot through Interaction with Human F. Iida, M. Tabata and F. Hara Department of Mechanical Engineering Science University of Tokyo - Kagurazaka, Shinjuku-ku,
Generating Personality Character in a Face Robot through Interaction with Human F. Iida, M. Tabata and F. Hara Department of Mechanical Engineering Science University of Tokyo - Kagurazaka, Shinjuku-ku,
Proposers Day Workshop
 Proposers Day Workshop Monday, January 23, 2017 @srcjump, #JUMPpdw Cognitive Computing Vertical Research Center Mandy Pant Academic Research Director Intel Corporation Center Motivation Today s deep learning
Proposers Day Workshop Monday, January 23, 2017 @srcjump, #JUMPpdw Cognitive Computing Vertical Research Center Mandy Pant Academic Research Director Intel Corporation Center Motivation Today s deep learning
Reinforcement Learning
 Reinforcement Learning Reinforcement Learning Assumptions we made so far: Known state space S Known transition model T(s, a, s ) Known reward function R(s) not realistic for many real agents Reinforcement
Reinforcement Learning Reinforcement Learning Assumptions we made so far: Known state space S Known transition model T(s, a, s ) Known reward function R(s) not realistic for many real agents Reinforcement