Reinforcement Learning
|
|
|
- Asher Ferguson
- 6 years ago
- Views:
Transcription
1 Reinforcement Learning
2 Reinforcement Learning Assumptions we made so far: Known state space S Known transition model T(s, a, s ) Known reward function R(s) not realistic for many real agents Reinforcement Learning: Learn optimal policy with a priori unknown environment Assume fully observable state(i.e. agent can tell its state) Agent needs to explore environment (i.e. experimentation)
3 Passive Reinforcement Learning Task: Given a policy π, what is the utility function U π? Similar to Policy Evaluation, but unknown T(s, a, s ) and R(s) Approach: Agent experiments in the environment Trials: execute policy from start state until in terminal state. (1,1) (1,2) (1,3) (1,2) (1,3) (2,3) (3,3) (4,3) 1.0 (1,1) (1,2) (1,3) (2,3) (3,3) (3,2) (3,3) (4,3) 1.0 (1,1) (2,1) (3,1) (3,2) (4,2) -1.0
4 Direct Utility Estimation Data: Trials of the form (1,1) (1,2) (1,3) (1,2) (1,3) (2,3) (3,3) (4,3) 1.0 (1,1) (1,2) (1,3) (2,3) (3,3) (3,2) (3,3) (4,3) 1.0 (1,1) (2,1) (3,1) (3,2) (4,2) -1.0 Idea: Average reward over all trials for each state independently From data above, estimate U(1,1) A=0.72 B= C=0.28 D=0.55
5 Direct Utility Estimation Data: Trials of the form (1,1) (1,2) (1,3) (1,2) (1,3) (2,3) (3,3) (4,3) 1.0 (1,1) (1,2) (1,3) (2,3) (3,3) (3,2) (3,3) (4,3) 1.0 (1,1) (2,1) (3,1) (3,2) (4,2) -1.0 Idea: Average reward over all trials for each state independently From data above, estimate U(1,2) A=0.76 B= 0.77 C=0.78 D=0.79
6 Direct Utility Estimation Why is this less efficient than necessary? Ignores dependencies between states U π (s) = R(s) + γ Σ s T(s, π(s), s ) U π (s )
7 Adaptive Dynamic Programming (ADP) Idea: Run trials to learn model of environment (i.e. T and R) Memorize R(s) for all visited states Estimate fraction of times action a from state s leads to s Use PolicyEvaluation Algorithm on estimated model Data: Trials of the form (1,1) (1,2) (1,3) (1,2) (1,3) (2,3) (3,3) (4,3) 1.0 (1,1) (1,2) (1,3) (2,3) (3,3) (3,2) (3,3) (4,3) 1.0 (1,1) (2,1) (3,1) (3,2) (4,2) -1.0
8 ADP (1,1) (1,2) (1,3) (1,2) (1,3) (2,3) (3,3) (4,3) 1.0 (1,1) (1,2) (1,3) (2,3) (3,3) (3,2) (3,3) (4,3) 1.0 (1,1) (2,1) (3,1) (3,2) (4,2) -1.0 Estimate T[(1,3), right, (2,3)] A=0 B=0.333 C=0.666 D=1.0
9 Problem? Can be quite costly for large state spaces For example, Backgammon has states Learn and store all transition probabilities and rewards PolicyEvaluation needs to solve linear program with equations and variables.
10 Temporal Difference (TD) Learning If policy led U(1,3) to U(2,3) all the time, we would expect that U π (1,3) = U π (2,3) R(s) should be equal U π (s) - γ U π (s ), so U π (s) = U π (s) + α [R(s) + γ U π (s ) - U π (s)] α is learning rate. α should decrease slowly over time, so that estimates stabilize eventually.
11 From observation, U(1,3)=0.84 U(2,3)=0.92 And R = Is U(1,3) too low or too high? A=Too Low B=Too high
12 Temporal Difference (TD) Learning Idea: Do not learn explicit model of environment! Use update rule that implicitly reflects transition probabilities. Method: Init U π (s) with R(s) when first visited After each transition, update with U π (s) = U π (s) + α [R(s) + γ U π (s ) - U π (s)] α is learning rate. α should decrease slowly over time, so that estimates stabilize eventually. Properties: No need to store model Only one update for each action (not full PolicyEvaluation)
13 Active Reinforcement Learning Task: In an a priori unknown environment, find the optimal policy. unknown T(s, a, s ) and R(s) Agent must experiment with the environment. Naïve Approach: Naïve Active PolicyIteration Start with some random policy Follow policy to learn model of environment and use ADP to estimate utilities. Update policy using π(s) argmax a Σ s T(s, a, s ) U π (s ) Problem: Can converge to sub-optimal policy! By following policy, agent might never learn T and R everywhere. Need for exploration!
14 Exploration vs. Exploitation Exploration: Take actions that explore the environment Hope: possibly find areas in the state space of higher reward Problem: possibly take suboptimal steps Exploitation: Follow current policy Guaranteed to get certain? expected reward Approach:? Sometimes take rand steps Bonus reward for states that have not been visited often yet
15 Q-Learning Problem: Agent needs model of environment to select action via argmax a Σ s T(s, a, s ) U π (s ) Solution: Learn action utility function Q(a,s), not state utility function U(s). Define Q(a,s) as U(s) = max a Q(a,s) Bellman equation with Q(a,s) instead of U(s) Q(a,s) = R(s) + γ Σ s T(s, a, s ) max a Q(a,s ) TD-Update with Q(a,s) instead of U(s) Q(a,s) Q(a,s) + α [R(s) + γ max a Q(a,s ) - Q(a,s)] Result: With Q-function, agent can select action without model of environment argmax a Q(a,s)
16 Q-Learning Illustration Q(up,(1,2)) Q(right,(1,2)) Q(down,(1,2)) Q(left,(1,2)) Q(up,(1,1)) Q(right,(1,1)) Q(down,(1,1)) Q(left,(1,1)) Q(up,(2,1)) Q(right,(2,1)) Q(down,(2,1)) Q(left,(2,1))
17 Function Approximation Problem: Storing Q or U,T,R for each state in a table is too expensive, if number of states is large Does not exploit similarity of states (i.e. agent has to learn separate behavior for each state, even if states are similar) Solution: Approximate function using parametric representation For example: Ф(s) is feature vector describing the state Material values of board Is the queen threatened?

18 Tilt Sensors Servo Actuators
19

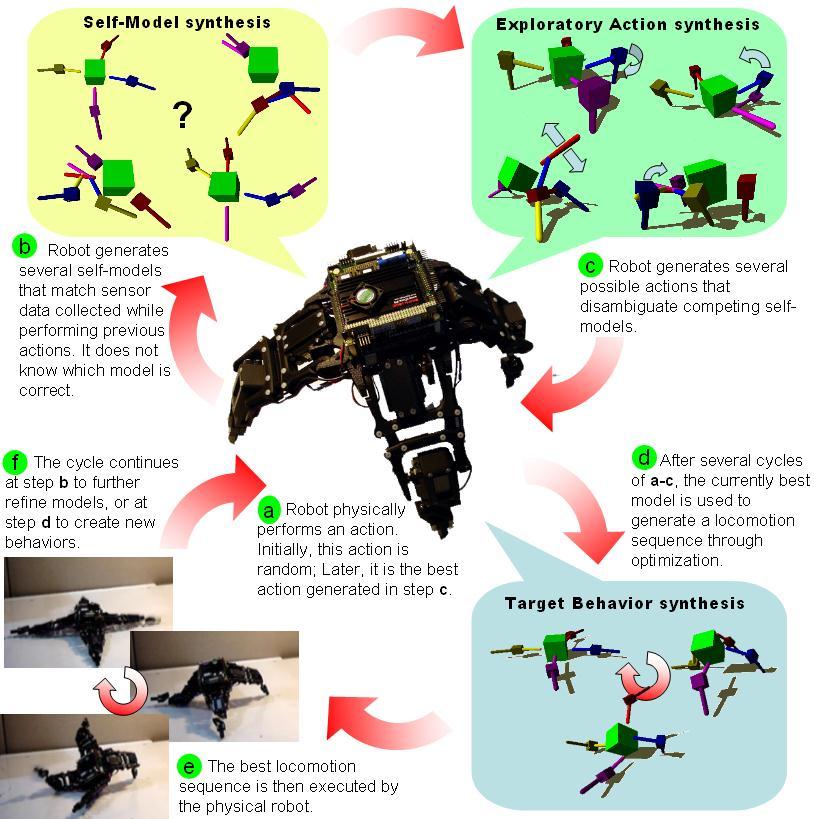
20 Morphological Estimation

21 Emergent Self-Model With Josh Bongard and Victor Zykov, Science 2006

22 Damage Recovery With Josh Bongard and Victor Zykov, Science 2006
23 Random Predicted Physical
CSCI 4150 Introduction to Artificial Intelligence, Fall 2004 Assignment 7 (135 points), out Monday November 22, due Thursday December 9
, out Monday November 22, due Thursday December 9") CSCI 4150 Introduction to Artificial Intelligence, Fall 2004 Assignment 7 (135 points), out Monday November 22, due Thursday December 9 Learning to play blackjack In this assignment, you will implement
CSCI 4150 Introduction to Artificial Intelligence, Fall 2004 Assignment 7 (135 points), out Monday November 22, due Thursday December 9 Learning to play blackjack In this assignment, you will implement
TUD Poker Challenge Reinforcement Learning with Imperfect Information
 TUD Poker Challenge 2008 Reinforcement Learning with Imperfect Information Outline Reinforcement Learning Perfect Information Imperfect Information Lagging Anchor Algorithm Matrix Form Extensive Form Poker
TUD Poker Challenge 2008 Reinforcement Learning with Imperfect Information Outline Reinforcement Learning Perfect Information Imperfect Information Lagging Anchor Algorithm Matrix Form Extensive Form Poker
A. Rules of blackjack, representations, and playing blackjack
 CSCI 4150 Introduction to Artificial Intelligence, Fall 2005 Assignment 7 (140 points), out Monday November 21, due Thursday December 8 Learning to play blackjack In this assignment, you will implement
CSCI 4150 Introduction to Artificial Intelligence, Fall 2005 Assignment 7 (140 points), out Monday November 21, due Thursday December 8 Learning to play blackjack In this assignment, you will implement
Learning via Delayed Knowledge A Case of Jamming. SaiDhiraj Amuru and R. Michael Buehrer
 Learning via Delayed Knowledge A Case of Jamming SaiDhiraj Amuru and R. Michael Buehrer 1 Why do we need an Intelligent Jammer? Dynamic environment conditions in electronic warfare scenarios failure of
Learning via Delayed Knowledge A Case of Jamming SaiDhiraj Amuru and R. Michael Buehrer 1 Why do we need an Intelligent Jammer? Dynamic environment conditions in electronic warfare scenarios failure of
CS188: Artificial Intelligence, Fall 2011 Written 2: Games and MDP s
 CS88: Artificial Intelligence, Fall 20 Written 2: Games and MDP s Due: 0/5 submitted electronically by :59pm (no slip days) Policy: Can be solved in groups (acknowledge collaborators) but must be written
CS88: Artificial Intelligence, Fall 20 Written 2: Games and MDP s Due: 0/5 submitted electronically by :59pm (no slip days) Policy: Can be solved in groups (acknowledge collaborators) but must be written
Reinforcement Learning in Games Autonomous Learning Systems Seminar
 Reinforcement Learning in Games Autonomous Learning Systems Seminar Matthias Zöllner Intelligent Autonomous Systems TU-Darmstadt zoellner@rbg.informatik.tu-darmstadt.de Betreuer: Gerhard Neumann Abstract
Reinforcement Learning in Games Autonomous Learning Systems Seminar Matthias Zöllner Intelligent Autonomous Systems TU-Darmstadt zoellner@rbg.informatik.tu-darmstadt.de Betreuer: Gerhard Neumann Abstract
10703 Deep Reinforcement Learning and Control
 10703 Deep Reinforcement Learning and Control Russ Salakhutdinov Slides borrowed from Katerina Fragkiadaki Solving known MDPs: Dynamic Programming Markov Decision Process (MDP)! A Markov Decision Process
10703 Deep Reinforcement Learning and Control Russ Salakhutdinov Slides borrowed from Katerina Fragkiadaki Solving known MDPs: Dynamic Programming Markov Decision Process (MDP)! A Markov Decision Process
Policy Teaching. Through Reward Function Learning. Haoqi Zhang, David Parkes, and Yiling Chen
 Policy Teaching Through Reward Function Learning Haoqi Zhang, David Parkes, and Yiling Chen School of Engineering and Applied Sciences Harvard University ACM EC 2009 Haoqi Zhang (Harvard University) Policy
Policy Teaching Through Reward Function Learning Haoqi Zhang, David Parkes, and Yiling Chen School of Engineering and Applied Sciences Harvard University ACM EC 2009 Haoqi Zhang (Harvard University) Policy
Resource Management in QoS-Aware Wireless Cellular Networks
 Resource Management in QoS-Aware Wireless Cellular Networks Zhi Zhang Dept. of Electrical and Computer Engineering Colorado State University April 24, 2009 Zhi Zhang (ECE CSU) Resource Management in Wireless
Resource Management in QoS-Aware Wireless Cellular Networks Zhi Zhang Dept. of Electrical and Computer Engineering Colorado State University April 24, 2009 Zhi Zhang (ECE CSU) Resource Management in Wireless
Morphology Independent Learning in Modular Robots
 Morphology Independent Learning in Modular Robots David Johan Christensen, Mirko Bordignon, Ulrik Pagh Schultz, Danish Shaikh, and Kasper Stoy Abstract Hand-coding locomotion controllers for modular robots
Morphology Independent Learning in Modular Robots David Johan Christensen, Mirko Bordignon, Ulrik Pagh Schultz, Danish Shaikh, and Kasper Stoy Abstract Hand-coding locomotion controllers for modular robots
Temporal-Difference Learning in Self-Play Training
 Temporal-Difference Learning in Self-Play Training Clifford Kotnik Jugal Kalita University of Colorado at Colorado Springs, Colorado Springs, Colorado 80918 CLKOTNIK@ATT.NET KALITA@EAS.UCCS.EDU Abstract
Temporal-Difference Learning in Self-Play Training Clifford Kotnik Jugal Kalita University of Colorado at Colorado Springs, Colorado Springs, Colorado 80918 CLKOTNIK@ATT.NET KALITA@EAS.UCCS.EDU Abstract
An Artificially Intelligent Ludo Player
 An Artificially Intelligent Ludo Player Andres Calderon Jaramillo and Deepak Aravindakshan Colorado State University {andrescj, deepakar}@cs.colostate.edu Abstract This project replicates results reported
An Artificially Intelligent Ludo Player Andres Calderon Jaramillo and Deepak Aravindakshan Colorado State University {andrescj, deepakar}@cs.colostate.edu Abstract This project replicates results reported
Tutorial of Reinforcement: A Special Focus on Q-Learning
 Tutorial of Reinforcement: A Special Focus on Q-Learning TINGWU WANG, MACHINE LEARNING GROUP, UNIVERSITY OF TORONTO Contents 1. Introduction 1. Discrete Domain vs. Continous Domain 2. Model Based vs. Model
Tutorial of Reinforcement: A Special Focus on Q-Learning TINGWU WANG, MACHINE LEARNING GROUP, UNIVERSITY OF TORONTO Contents 1. Introduction 1. Discrete Domain vs. Continous Domain 2. Model Based vs. Model
Reinforcement Learning-Based Dynamic Power Management of a Battery-Powered System Supplying Multiple Active Modes
 Reinforcement Learning-Based Dynamic Power Management of a Battery-Powered System Supplying Multiple Active Modes Maryam Triki 1,Ahmed C. Ammari 1,2 1 MMA Laboratory, INSAT Carthage University, Tunis,
Reinforcement Learning-Based Dynamic Power Management of a Battery-Powered System Supplying Multiple Active Modes Maryam Triki 1,Ahmed C. Ammari 1,2 1 MMA Laboratory, INSAT Carthage University, Tunis,
Reinforcement Learning Simulations and Robotics
 Reinforcement Learning Simulations and Robotics Models Partially observable noise in sensors Policy search methods rather than value functionbased approaches Isolate key parameters by choosing an appropriate
Reinforcement Learning Simulations and Robotics Models Partially observable noise in sensors Policy search methods rather than value functionbased approaches Isolate key parameters by choosing an appropriate
Reinforcement Learning and its Application to Othello
 Reinforcement Learning and its Application to Othello Nees Jan van Eck, Michiel van Wezel Econometric Institute, Faculty of Economics, Erasmus University Rotterdam, P.O. Box 1738, 3000 DR, Rotterdam, The
Reinforcement Learning and its Application to Othello Nees Jan van Eck, Michiel van Wezel Econometric Institute, Faculty of Economics, Erasmus University Rotterdam, P.O. Box 1738, 3000 DR, Rotterdam, The
Optimization Techniques for Alphabet-Constrained Signal Design
 Optimization Techniques for Alphabet-Constrained Signal Design Mojtaba Soltanalian Department of Electrical Engineering California Institute of Technology Stanford EE- ISL Mar. 2015 Optimization Techniques
Optimization Techniques for Alphabet-Constrained Signal Design Mojtaba Soltanalian Department of Electrical Engineering California Institute of Technology Stanford EE- ISL Mar. 2015 Optimization Techniques
Classifier-Based Approximate Policy Iteration. Alan Fern
 Classifier-Based Approximate Policy Iteration Alan Fern 1 Uniform Policy Rollout Algorithm Rollout[π,h,w](s) 1. For each a i run SimQ(s,a i,π,h) w times 2. Return action with best average of SimQ results
Classifier-Based Approximate Policy Iteration Alan Fern 1 Uniform Policy Rollout Algorithm Rollout[π,h,w](s) 1. For each a i run SimQ(s,a i,π,h) w times 2. Return action with best average of SimQ results
Frugal Sensing Spectral Analysis from Power Inequalities
 Frugal Sensing Spectral Analysis from Power Inequalities Nikos Sidiropoulos Joint work with Omar Mehanna IEEE SPAWC 2013 Plenary, June 17, 2013, Darmstadt, Germany Wideband Spectrum Sensing (for CR/DSM)
Frugal Sensing Spectral Analysis from Power Inequalities Nikos Sidiropoulos Joint work with Omar Mehanna IEEE SPAWC 2013 Plenary, June 17, 2013, Darmstadt, Germany Wideband Spectrum Sensing (for CR/DSM)
DeepMind Self-Learning Atari Agent
 DeepMind Self-Learning Atari Agent Human-level control through deep reinforcement learning Nature Vol 518, Feb 26, 2015 The Deep Mind of Demis Hassabis Backchannel / Medium.com interview with David Levy
DeepMind Self-Learning Atari Agent Human-level control through deep reinforcement learning Nature Vol 518, Feb 26, 2015 The Deep Mind of Demis Hassabis Backchannel / Medium.com interview with David Levy
ROBOCODE PROJECT AIBOT - MARKOV MODEL DRIVEN AIMING COMBINED WITH Q LEARNING FOR MOVEMENT
 ROBOCODE PROJECT AIBOT - MARKOV MODEL DRIVEN AIMING COMBINED WITH Q LEARNING FOR MOVEMENT PATRICK HALUPTZOK, XU MIAO Abstract. In this paper the development of a robot controller for Robocode is discussed.
ROBOCODE PROJECT AIBOT - MARKOV MODEL DRIVEN AIMING COMBINED WITH Q LEARNING FOR MOVEMENT PATRICK HALUPTZOK, XU MIAO Abstract. In this paper the development of a robot controller for Robocode is discussed.
Introduction to Neuro-Dynamic Programming (Or, how to count cards in blackjack and do other fun things too.)
") Introduction to Neuro-Dynamic Programming (Or, how to count cards in blackjack and do other fun things too.) Eric B. Laber February 12, 2008 Eric B. Laber () Introduction to Neuro-Dynamic Programming (Or,
Introduction to Neuro-Dynamic Programming (Or, how to count cards in blackjack and do other fun things too.) Eric B. Laber February 12, 2008 Eric B. Laber () Introduction to Neuro-Dynamic Programming (Or,
REINFORCEMENT LEARNING (DD3359) O-03 END-TO-END LEARNING
 O-03 END-TO-END LEARNING") REINFORCEMENT LEARNING (DD3359) O-03 END-TO-END LEARNING RIKA ANTONOVA ANTONOVA@KTH.SE ALI GHADIRZADEH ALGH@KTH.SE RL: What We Know So Far Formulate the problem as an MDP (or POMDP) State space captures
REINFORCEMENT LEARNING (DD3359) O-03 END-TO-END LEARNING RIKA ANTONOVA ANTONOVA@KTH.SE ALI GHADIRZADEH ALGH@KTH.SE RL: What We Know So Far Formulate the problem as an MDP (or POMDP) State space captures
Iteration. Many thanks to Alan Fern for the majority of the LSPI slides.
 Approximate Click to edit Master titlepolicy style Iteration Click to edit Emma Master Brunskill subtitle style Many thanks to Alan Fern for the majority of the LSPI slides. https://web.engr.oregonstate.edu/~afern/classes/cs533/notes/lspi.pdf
Approximate Click to edit Master titlepolicy style Iteration Click to edit Emma Master Brunskill subtitle style Many thanks to Alan Fern for the majority of the LSPI slides. https://web.engr.oregonstate.edu/~afern/classes/cs533/notes/lspi.pdf
1 Introuction 1.1 Robots 1.2. Error recovery Self healing or self modelling robots 2.1 Researchers 2.2 The starfish robot 2.2.
 SELF HEALING ROBOTS A SEMINAR REPORT Submitted by AKHIL in partial fulfillment for the award of the degree of BACHELOR OF TECHNOLOGY in COMPUTER SCIENCE & ENGINEERING SCHOOL OF ENGINEERING COCHIN UNIVERSITY
SELF HEALING ROBOTS A SEMINAR REPORT Submitted by AKHIL in partial fulfillment for the award of the degree of BACHELOR OF TECHNOLOGY in COMPUTER SCIENCE & ENGINEERING SCHOOL OF ENGINEERING COCHIN UNIVERSITY
TJHSST Senior Research Project Evolving Motor Techniques for Artificial Life
 TJHSST Senior Research Project Evolving Motor Techniques for Artificial Life 2007-2008 Kelley Hecker November 2, 2007 Abstract This project simulates evolving virtual creatures in a 3D environment, based
TJHSST Senior Research Project Evolving Motor Techniques for Artificial Life 2007-2008 Kelley Hecker November 2, 2007 Abstract This project simulates evolving virtual creatures in a 3D environment, based
Soar-RL A Year of Learning
 Soar-RL A Year of Learning Nate Derbinsky University of Michigan Outline The Big Picture Developing Soar-RL Agents Controlling the Soar-RL Algorithm Debugging Soar-RL Soar-RL Performance Nuggets & Coal
Soar-RL A Year of Learning Nate Derbinsky University of Michigan Outline The Big Picture Developing Soar-RL Agents Controlling the Soar-RL Algorithm Debugging Soar-RL Soar-RL Performance Nuggets & Coal
Applying Modern Reinforcement Learning to Play Video Games. Computer Science & Engineering Leung Man Ho Supervisor: Prof. LYU Rung Tsong Michael
 Applying Modern Reinforcement Learning to Play Video Games Computer Science & Engineering Leung Man Ho Supervisor: Prof. LYU Rung Tsong Michael Outline Term 1 Review Term 2 Objectives Experiments & Results
Applying Modern Reinforcement Learning to Play Video Games Computer Science & Engineering Leung Man Ho Supervisor: Prof. LYU Rung Tsong Michael Outline Term 1 Review Term 2 Objectives Experiments & Results
Learning to Play Love Letter with Deep Reinforcement Learning
 Learning to Play Love Letter with Deep Reinforcement Learning Madeleine D. Dawson* MIT mdd@mit.edu Robert X. Liang* MIT xbliang@mit.edu Alexander M. Turner* MIT turneram@mit.edu Abstract Recent advancements
Learning to Play Love Letter with Deep Reinforcement Learning Madeleine D. Dawson* MIT mdd@mit.edu Robert X. Liang* MIT xbliang@mit.edu Alexander M. Turner* MIT turneram@mit.edu Abstract Recent advancements
A Reinforcement Learning Scheme for Adaptive Link Allocation in ATM Networks
 A Reinforcement Learning Scheme for Adaptive Link Allocation in ATM Networks Ernst Nordström, Jakob Carlström Department of Computer Systems, Uppsala University, Box 325, S 751 05 Uppsala, Sweden Fax:
A Reinforcement Learning Scheme for Adaptive Link Allocation in ATM Networks Ernst Nordström, Jakob Carlström Department of Computer Systems, Uppsala University, Box 325, S 751 05 Uppsala, Sweden Fax:
Temporal Difference Learning for the Game Tic-Tac-Toe 3D: Applying Structure to Neural Networks
 2015 IEEE Symposium Series on Computational Intelligence Temporal Difference Learning for the Game Tic-Tac-Toe 3D: Applying Structure to Neural Networks Michiel van de Steeg Institute of Artificial Intelligence
2015 IEEE Symposium Series on Computational Intelligence Temporal Difference Learning for the Game Tic-Tac-Toe 3D: Applying Structure to Neural Networks Michiel van de Steeg Institute of Artificial Intelligence
TEMPORAL DIFFERENCE LEARNING IN CHINESE CHESS
 TEMPORAL DIFFERENCE LEARNING IN CHINESE CHESS Thong B. Trinh, Anwer S. Bashi, Nikhil Deshpande Department of Electrical Engineering University of New Orleans New Orleans, LA 70148 Tel: (504) 280-7383 Fax:
TEMPORAL DIFFERENCE LEARNING IN CHINESE CHESS Thong B. Trinh, Anwer S. Bashi, Nikhil Deshpande Department of Electrical Engineering University of New Orleans New Orleans, LA 70148 Tel: (504) 280-7383 Fax:
Distributed Online Learning of Central Pattern Generators in Modular Robots
 Distributed Online Learning of Central Pattern Generators in Modular Robots David Johan Christensen 1, Alexander Spröwitz 2, and Auke Jan Ijspeert 2 1 The Maersk Mc-Kinney Moller Institute, University
Distributed Online Learning of Central Pattern Generators in Modular Robots David Johan Christensen 1, Alexander Spröwitz 2, and Auke Jan Ijspeert 2 1 The Maersk Mc-Kinney Moller Institute, University
CS188 Spring 2014 Section 3: Games
 CS188 Spring 2014 Section 3: Games 1 Nearly Zero Sum Games The standard Minimax algorithm calculates worst-case values in a zero-sum two player game, i.e. a game in which for all terminal states s, the
CS188 Spring 2014 Section 3: Games 1 Nearly Zero Sum Games The standard Minimax algorithm calculates worst-case values in a zero-sum two player game, i.e. a game in which for all terminal states s, the
TD-Leaf(λ) Giraffe: Using Deep Reinforcement Learning to Play Chess. Stefan Lüttgen
 Giraffe: Using Deep Reinforcement Learning to Play Chess. Stefan Lüttgen") TD-Leaf(λ) Giraffe: Using Deep Reinforcement Learning to Play Chess Stefan Lüttgen Motivation Learn to play chess Computer approach different than human one Humans search more selective: Kasparov (3-5
TD-Leaf(λ) Giraffe: Using Deep Reinforcement Learning to Play Chess Stefan Lüttgen Motivation Learn to play chess Computer approach different than human one Humans search more selective: Kasparov (3-5
Jamming mitigation in cognitive radio networks using a modified Q-learning algorithm
 Jamming mitigation in cognitive radio networks using a modified Q-learning algorithm Feten Slimeni, Bart Scheers, Zied Chtourou and Vincent Le Nir VRIT Lab - Military Academy of Tunisia, Nabeul, Tunisia
Jamming mitigation in cognitive radio networks using a modified Q-learning algorithm Feten Slimeni, Bart Scheers, Zied Chtourou and Vincent Le Nir VRIT Lab - Military Academy of Tunisia, Nabeul, Tunisia
Reinforcement Learning to Train Ms. Pac-Man Using Higher-order Action-relative Inputs
 Reinforcement Learning to Train Ms. Pac-Man Using Higher-order Action-relative Inputs Luuk Bom, Ruud Henken and Marco Wiering (IEEE Member) Institute of Artificial Intelligence and Cognitive Engineering
Reinforcement Learning to Train Ms. Pac-Man Using Higher-order Action-relative Inputs Luuk Bom, Ruud Henken and Marco Wiering (IEEE Member) Institute of Artificial Intelligence and Cognitive Engineering
Closing the loop around Sensor Networks
 Closing the loop around Sensor Networks Bruno Sinopoli Shankar Sastry Dept of Electrical Engineering, UC Berkeley Chess Review May 11, 2005 Berkeley, CA Conceptual Issues Given a certain wireless sensor
Closing the loop around Sensor Networks Bruno Sinopoli Shankar Sastry Dept of Electrical Engineering, UC Berkeley Chess Review May 11, 2005 Berkeley, CA Conceptual Issues Given a certain wireless sensor
Reinforcement Learning Agent for Scrolling Shooter Game
 Reinforcement Learning Agent for Scrolling Shooter Game Peng Yuan (pengy@stanford.edu) Yangxin Zhong (yangxin@stanford.edu) Zibo Gong (zibo@stanford.edu) 1 Introduction and Task Definition 1.1 Game Agent
Reinforcement Learning Agent for Scrolling Shooter Game Peng Yuan (pengy@stanford.edu) Yangxin Zhong (yangxin@stanford.edu) Zibo Gong (zibo@stanford.edu) 1 Introduction and Task Definition 1.1 Game Agent
Energy-aware Task Scheduling in Wireless Sensor Networks based on Cooperative Reinforcement Learning
 Energy-aware Task Scheduling in Wireless Sensor Networks based on Cooperative Reinforcement Learning Muhidul Islam Khan, Bernhard Rinner Institute of Networked and Embedded Systems Alpen-Adria Universität
Energy-aware Task Scheduling in Wireless Sensor Networks based on Cooperative Reinforcement Learning Muhidul Islam Khan, Bernhard Rinner Institute of Networked and Embedded Systems Alpen-Adria Universität
Human-Swarm Interaction
 Human-Swarm Interaction a brief primer Andreas Kolling irobot Corp. Pasadena, CA Swarm Properties - simple and distributed - from the operator s perspective - distributed algorithms and information processing
Human-Swarm Interaction a brief primer Andreas Kolling irobot Corp. Pasadena, CA Swarm Properties - simple and distributed - from the operator s perspective - distributed algorithms and information processing
Transport Capacity and Spectral Efficiency of Large Wireless CDMA Ad Hoc Networks
 Transport Capacity and Spectral Efficiency of Large Wireless CDMA Ad Hoc Networks Yi Sun Department of Electrical Engineering The City College of City University of New York Acknowledgement: supported
Transport Capacity and Spectral Efficiency of Large Wireless CDMA Ad Hoc Networks Yi Sun Department of Electrical Engineering The City College of City University of New York Acknowledgement: supported
A Survey on Machine-Learning Techniques in Cognitive Radios
 1 A Survey on Machine-Learning Techniques in Cognitive Radios Mario Bkassiny, Student Member, IEEE, Yang Li, Student Member, IEEE and Sudharman K. Jayaweera, Senior Member, IEEE Department of Electrical
1 A Survey on Machine-Learning Techniques in Cognitive Radios Mario Bkassiny, Student Member, IEEE, Yang Li, Student Member, IEEE and Sudharman K. Jayaweera, Senior Member, IEEE Department of Electrical
Decision Making in Multiplayer Environments Application in Backgammon Variants
 Decision Making in Multiplayer Environments Application in Backgammon Variants PhD Thesis by Nikolaos Papahristou AI researcher Department of Applied Informatics Thessaloniki, Greece Contributions Expert
Decision Making in Multiplayer Environments Application in Backgammon Variants PhD Thesis by Nikolaos Papahristou AI researcher Department of Applied Informatics Thessaloniki, Greece Contributions Expert
Q-Learning Algorithms for Constrained Markov Decision Processes with Randomized Monotone Policies: Application to MIMO Transmission Control
 Q-Learning Algorithms for Constrained Markov Decision Processes with Randomized Monotone Policies: Application to MIMO Transmission Control Dejan V. Djonin, Vikram Krishnamurthy, Fellow, IEEE Abstract
Q-Learning Algorithms for Constrained Markov Decision Processes with Randomized Monotone Policies: Application to MIMO Transmission Control Dejan V. Djonin, Vikram Krishnamurthy, Fellow, IEEE Abstract
Towards Strategic Kriegspiel Play with Opponent Modeling
 Towards Strategic Kriegspiel Play with Opponent Modeling Antonio Del Giudice and Piotr Gmytrasiewicz Department of Computer Science, University of Illinois at Chicago Chicago, IL, 60607-7053, USA E-mail:
Towards Strategic Kriegspiel Play with Opponent Modeling Antonio Del Giudice and Piotr Gmytrasiewicz Department of Computer Science, University of Illinois at Chicago Chicago, IL, 60607-7053, USA E-mail:
Ilab METIS Optimization of Energy Policies
 Ilab METIS Optimization of Energy Policies Olivier Teytaud + Inria-Tao + Artelys TAO project-team INRIA Saclay Île-de-France O. Teytaud, Research Fellow, olivier.teytaud@inria.fr http://www.lri.fr/~teytaud/
Ilab METIS Optimization of Energy Policies Olivier Teytaud + Inria-Tao + Artelys TAO project-team INRIA Saclay Île-de-France O. Teytaud, Research Fellow, olivier.teytaud@inria.fr http://www.lri.fr/~teytaud/
CSE 473 Midterm Exam Feb 8, 2018
 CSE 473 Midterm Exam Feb 8, 2018 Name: This exam is take home and is due on Wed Feb 14 at 1:30 pm. You can submit it online (see the message board for instructions) or hand it in at the beginning of class.
CSE 473 Midterm Exam Feb 8, 2018 Name: This exam is take home and is due on Wed Feb 14 at 1:30 pm. You can submit it online (see the message board for instructions) or hand it in at the beginning of class.
Some results on optimal estimation and control for lossy NCS. Luca Schenato
 Some results on optimal estimation and control for lossy NCS Luca Schenato Networked Control Systems Drive-by-wire systems Swarm robotics Smart structures: adaptive space telescope Wireless Sensor Networks
Some results on optimal estimation and control for lossy NCS Luca Schenato Networked Control Systems Drive-by-wire systems Swarm robotics Smart structures: adaptive space telescope Wireless Sensor Networks
Learning Artificial Intelligence in Large-Scale Video Games
 Learning Artificial Intelligence in Large-Scale Video Games A First Case Study with Hearthstone: Heroes of WarCraft Master Thesis Submitted for the Degree of MSc in Computer Science & Engineering Author
Learning Artificial Intelligence in Large-Scale Video Games A First Case Study with Hearthstone: Heroes of WarCraft Master Thesis Submitted for the Degree of MSc in Computer Science & Engineering Author
International Journal of Modern Engineering and Research Technology
 Volume 5, Issue 1, January 2018 ISSN: 2348-8565 (Online) International Journal of Modern Engineering and Research Technology Website: http://www.ijmert.org Email: editor.ijmert@gmail.com Experimental Analysis
Volume 5, Issue 1, January 2018 ISSN: 2348-8565 (Online) International Journal of Modern Engineering and Research Technology Website: http://www.ijmert.org Email: editor.ijmert@gmail.com Experimental Analysis
Real-World Reinforcement Learning for Autonomous Humanoid Robot Charging in a Home Environment
 Real-World Reinforcement Learning for Autonomous Humanoid Robot Charging in a Home Environment Nicolás Navarro, Cornelius Weber, and Stefan Wermter University of Hamburg, Department of Computer Science,
Real-World Reinforcement Learning for Autonomous Humanoid Robot Charging in a Home Environment Nicolás Navarro, Cornelius Weber, and Stefan Wermter University of Hamburg, Department of Computer Science,
CS188 Spring 2011 Written 2: Minimax, Expectimax, MDPs
 Last name: First name: SID: Class account login: Collaborators: CS188 Spring 2011 Written 2: Minimax, Expectimax, MDPs Due: Monday 2/28 at 5:29pm either in lecture or in 283 Soda Drop Box (no slip days).
Last name: First name: SID: Class account login: Collaborators: CS188 Spring 2011 Written 2: Minimax, Expectimax, MDPs Due: Monday 2/28 at 5:29pm either in lecture or in 283 Soda Drop Box (no slip days).
CS221 Project Final Report Gomoku Game Agent
 CS221 Project Final Report Gomoku Game Agent Qiao Tan qtan@stanford.edu Xiaoti Hu xiaotihu@stanford.edu 1 Introduction Gomoku, also know as five-in-a-row, is a strategy board game which is traditionally
CS221 Project Final Report Gomoku Game Agent Qiao Tan qtan@stanford.edu Xiaoti Hu xiaotihu@stanford.edu 1 Introduction Gomoku, also know as five-in-a-row, is a strategy board game which is traditionally
Learning and Using Models of Kicking Motions for Legged Robots
 Learning and Using Models of Kicking Motions for Legged Robots Sonia Chernova and Manuela Veloso Computer Science Department Carnegie Mellon University Pittsburgh, PA 15213 {soniac, mmv}@cs.cmu.edu Abstract
Learning and Using Models of Kicking Motions for Legged Robots Sonia Chernova and Manuela Veloso Computer Science Department Carnegie Mellon University Pittsburgh, PA 15213 {soniac, mmv}@cs.cmu.edu Abstract
Learning Reactive Neurocontrollers using Simulated Annealing for Mobile Robots
 Learning Reactive Neurocontrollers using Simulated Annealing for Mobile Robots Philippe Lucidarme, Alain Liégeois LIRMM, University Montpellier II, France, lucidarm@lirmm.fr Abstract This paper presents
Learning Reactive Neurocontrollers using Simulated Annealing for Mobile Robots Philippe Lucidarme, Alain Liégeois LIRMM, University Montpellier II, France, lucidarm@lirmm.fr Abstract This paper presents
Automated Suicide: An Antichess Engine
 Automated Suicide: An Antichess Engine Jim Andress and Prasanna Ramakrishnan 1 Introduction Antichess (also known as Suicide Chess or Loser s Chess) is a popular variant of chess where the objective of
Automated Suicide: An Antichess Engine Jim Andress and Prasanna Ramakrishnan 1 Introduction Antichess (also known as Suicide Chess or Loser s Chess) is a popular variant of chess where the objective of
Dynamic Fair Channel Allocation for Wideband Systems
 Outlines Introduction and Motivation Dynamic Fair Channel Allocation for Wideband Systems Department of Mobile Communications Eurecom Institute Sophia Antipolis 19/10/2006 Outline of Part I Outlines Introduction
Outlines Introduction and Motivation Dynamic Fair Channel Allocation for Wideband Systems Department of Mobile Communications Eurecom Institute Sophia Antipolis 19/10/2006 Outline of Part I Outlines Introduction
Announcements. Homework 1. Project 1. Due tonight at 11:59pm. Due Friday 2/8 at 4:00pm. Electronic HW1 Written HW1
 Announcements Homework 1 Due tonight at 11:59pm Project 1 Electronic HW1 Written HW1 Due Friday 2/8 at 4:00pm CS 188: Artificial Intelligence Adversarial Search and Game Trees Instructors: Sergey Levine
Announcements Homework 1 Due tonight at 11:59pm Project 1 Electronic HW1 Written HW1 Due Friday 2/8 at 4:00pm CS 188: Artificial Intelligence Adversarial Search and Game Trees Instructors: Sergey Levine
Q Learning Behavior on Autonomous Navigation of Physical Robot
 The 8th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI 211) Nov. 23-26, 211 in Songdo ConventiA, Incheon, Korea Q Learning Behavior on Autonomous Navigation of Physical Robot
The 8th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI 211) Nov. 23-26, 211 in Songdo ConventiA, Incheon, Korea Q Learning Behavior on Autonomous Navigation of Physical Robot
Booklet of teaching units
 International Master Program in Mechatronic Systems for Rehabilitation Booklet of teaching units Third semester (M2 S1) Master Sciences de l Ingénieur Université Pierre et Marie Curie Paris 6 Boite 164,
International Master Program in Mechatronic Systems for Rehabilitation Booklet of teaching units Third semester (M2 S1) Master Sciences de l Ingénieur Université Pierre et Marie Curie Paris 6 Boite 164,
Cooperative Behavior Acquisition in A Multiple Mobile Robot Environment by Co-evolution
 Cooperative Behavior Acquisition in A Multiple Mobile Robot Environment by Co-evolution Eiji Uchibe, Masateru Nakamura, Minoru Asada Dept. of Adaptive Machine Systems, Graduate School of Eng., Osaka University,
Cooperative Behavior Acquisition in A Multiple Mobile Robot Environment by Co-evolution Eiji Uchibe, Masateru Nakamura, Minoru Asada Dept. of Adaptive Machine Systems, Graduate School of Eng., Osaka University,
Cooperative Tracking using Mobile Robots and Environment-Embedded, Networked Sensors
 In the 2001 International Symposium on Computational Intelligence in Robotics and Automation pp. 206-211, Banff, Alberta, Canada, July 29 - August 1, 2001. Cooperative Tracking using Mobile Robots and
In the 2001 International Symposium on Computational Intelligence in Robotics and Automation pp. 206-211, Banff, Alberta, Canada, July 29 - August 1, 2001. Cooperative Tracking using Mobile Robots and
Applying Modern Reinforcement Learning to Play Video Games
 THE CHINESE UNIVERSITY OF HONG KONG FINAL YEAR PROJECT REPORT (TERM 1) Applying Modern Reinforcement Learning to Play Video Games Author: Man Ho LEUNG Supervisor: Prof. LYU Rung Tsong Michael LYU1701 Department
THE CHINESE UNIVERSITY OF HONG KONG FINAL YEAR PROJECT REPORT (TERM 1) Applying Modern Reinforcement Learning to Play Video Games Author: Man Ho LEUNG Supervisor: Prof. LYU Rung Tsong Michael LYU1701 Department
TRIAL-BASED HEURISTIC TREE SEARCH FOR FINITE HORIZON MDPS. Thomas Keller and Malte Helmert Presented by: Ryan Berryhill
 TRIAL-BASED HEURISTIC TREE SEARCH FOR FINITE HORIZON MDPS Thomas Keller and Malte Helmert Presented by: Ryan Berryhill Outline Motivation Background THTS framework THTS algorithms Results Motivation Advances
TRIAL-BASED HEURISTIC TREE SEARCH FOR FINITE HORIZON MDPS Thomas Keller and Malte Helmert Presented by: Ryan Berryhill Outline Motivation Background THTS framework THTS algorithms Results Motivation Advances
Reinforcement Learning for Penalty Avoiding Policy Making and its Extensions and an Application to the Othello Game
 Reinforcement Learning for Penalty Avoiding Policy Making and its Extensions and an Application to the Othello Game Kazuteru Miyazaki teru@niad.ac.jp National Institution for Academic Degrees, 3-29-1 Ootsuka
Reinforcement Learning for Penalty Avoiding Policy Making and its Extensions and an Application to the Othello Game Kazuteru Miyazaki teru@niad.ac.jp National Institution for Academic Degrees, 3-29-1 Ootsuka
Reinforcement Learning in Robotic Task Domains with Deictic Descriptor Representation
 Louisiana State University LSU Digital Commons LSU Doctoral Dissertations Graduate School 10-22-2018 Reinforcement Learning in Robotic Task Domains with Deictic Descriptor Representation Harry Paul Moore
Louisiana State University LSU Digital Commons LSU Doctoral Dissertations Graduate School 10-22-2018 Reinforcement Learning in Robotic Task Domains with Deictic Descriptor Representation Harry Paul Moore
Design of Instrumentation Systems for Monitoring Geo-Hazards in Transportation. By Barry R. Christopher Christopher Consultants Roswell, Ga.
 Design of Instrumentation Systems for Monitoring Geo-Hazards in Transportation By Barry R. Christopher Christopher Consultants Roswell, Ga. Systematic Approach to Planning Monitoring Programs Without a
Design of Instrumentation Systems for Monitoring Geo-Hazards in Transportation By Barry R. Christopher Christopher Consultants Roswell, Ga. Systematic Approach to Planning Monitoring Programs Without a
Name: Your EdX Login: SID: Name of person to left: Exam Room: Name of person to right: Primary TA:
 UC Berkeley Computer Science CS188: Introduction to Artificial Intelligence Josh Hug and Adam Janin Midterm I, Fall 2016 This test has 8 questions worth a total of 100 points, to be completed in 110 minutes.
UC Berkeley Computer Science CS188: Introduction to Artificial Intelligence Josh Hug and Adam Janin Midterm I, Fall 2016 This test has 8 questions worth a total of 100 points, to be completed in 110 minutes.
Artificial Neural Networks. Artificial Intelligence Santa Clara, 2016
 Artificial Neural Networks Artificial Intelligence Santa Clara, 2016 Simulate the functioning of the brain Can simulate actual neurons: Computational neuroscience Can introduce simplified neurons: Neural
Artificial Neural Networks Artificial Intelligence Santa Clara, 2016 Simulate the functioning of the brain Can simulate actual neurons: Computational neuroscience Can introduce simplified neurons: Neural
Learning Attentive-Depth Switching while Interacting with an Agent
 Learning Attentive-Depth Switching while Interacting with an Agent Chyon Hae Kim, Hiroshi Tsujino, and Hiroyuki Nakahara Abstract This paper addresses a learning system design for a robot based on an extended
Learning Attentive-Depth Switching while Interacting with an Agent Chyon Hae Kim, Hiroshi Tsujino, and Hiroyuki Nakahara Abstract This paper addresses a learning system design for a robot based on an extended
DECENTRALISED ACTIVE VIBRATION CONTROL USING A REMOTE SENSING STRATEGY
 DECENTRALISED ACTIVE VIBRATION CONTROL USING A REMOTE SENSING STRATEGY Joseph Milton University of Southampton, Faculty of Engineering and the Environment, Highfield, Southampton, UK email: jm3g13@soton.ac.uk
DECENTRALISED ACTIVE VIBRATION CONTROL USING A REMOTE SENSING STRATEGY Joseph Milton University of Southampton, Faculty of Engineering and the Environment, Highfield, Southampton, UK email: jm3g13@soton.ac.uk
Augmenting Self-Learning In Chess Through Expert Imitation
 Augmenting Self-Learning In Chess Through Expert Imitation Michael Xie Department of Computer Science Stanford University Stanford, CA 94305 xie@cs.stanford.edu Gene Lewis Department of Computer Science
Augmenting Self-Learning In Chess Through Expert Imitation Michael Xie Department of Computer Science Stanford University Stanford, CA 94305 xie@cs.stanford.edu Gene Lewis Department of Computer Science
Reinforcement Learning-based Cooperative Sensing in Cognitive Radio Ad Hoc Networks
 2st Annual IEEE International Symposium on Personal, Indoor and Mobile Radio Communications Reinforcement Learning-based Cooperative Sensing in Cognitive Radio Ad Hoc Networks Brandon F. Lo and Ian F.
2st Annual IEEE International Symposium on Personal, Indoor and Mobile Radio Communications Reinforcement Learning-based Cooperative Sensing in Cognitive Radio Ad Hoc Networks Brandon F. Lo and Ian F.
FreeCiv Learner: A Machine Learning Project Utilizing Genetic Algorithms
 FreeCiv Learner: A Machine Learning Project Utilizing Genetic Algorithms Felix Arnold, Bryan Horvat, Albert Sacks Department of Computer Science Georgia Institute of Technology Atlanta, GA 30318 farnold3@gatech.edu
FreeCiv Learner: A Machine Learning Project Utilizing Genetic Algorithms Felix Arnold, Bryan Horvat, Albert Sacks Department of Computer Science Georgia Institute of Technology Atlanta, GA 30318 farnold3@gatech.edu
Maximum Likelihood Time Delay Estimation and Cramér-Rao Bounds for Multipath Exploitation
 Maximum Likelihood Time Delay stimation and Cramér-Rao Bounds for Multipath xploitation Harun Taha Hayvaci, Pawan Setlur, Natasha Devroye, Danilo rricolo Department of lectrical and Computer ngineering
Maximum Likelihood Time Delay stimation and Cramér-Rao Bounds for Multipath xploitation Harun Taha Hayvaci, Pawan Setlur, Natasha Devroye, Danilo rricolo Department of lectrical and Computer ngineering
Multi-Robot Task-Allocation through Vacancy Chains
 In Proceedings of the 03 IEEE International Conference on Robotics and Automation (ICRA 03) pp2293-2298, Taipei, Taiwan, September 14-19, 03 Multi-Robot Task-Allocation through Vacancy Chains Torbjørn
In Proceedings of the 03 IEEE International Conference on Robotics and Automation (ICRA 03) pp2293-2298, Taipei, Taiwan, September 14-19, 03 Multi-Robot Task-Allocation through Vacancy Chains Torbjørn
Efficiency and detectability of random reactive jamming in wireless networks
 Efficiency and detectability of random reactive jamming in wireless networks Ni An, Steven Weber Modeling & Analysis of Networks Laboratory Drexel University Department of Electrical and Computer Engineering
Efficiency and detectability of random reactive jamming in wireless networks Ni An, Steven Weber Modeling & Analysis of Networks Laboratory Drexel University Department of Electrical and Computer Engineering
ECE 174 Computer Assignment #2 Due Thursday 12/6/2012 GLOBAL POSITIONING SYSTEM (GPS) ALGORITHM
 ALGORITHM") ECE 174 Computer Assignment #2 Due Thursday 12/6/2012 GLOBAL POSITIONING SYSTEM (GPS) ALGORITHM Overview By utilizing measurements of the so-called pseudorange between an object and each of several earth
ECE 174 Computer Assignment #2 Due Thursday 12/6/2012 GLOBAL POSITIONING SYSTEM (GPS) ALGORITHM Overview By utilizing measurements of the so-called pseudorange between an object and each of several earth
Random Administrivia. In CMC 306 on Monday for LISP lab
 Random Administrivia In CMC 306 on Monday for LISP lab Artificial Intelligence: Introduction What IS artificial intelligence? Examples of intelligent behavior: Definitions of AI There are as many definitions
Random Administrivia In CMC 306 on Monday for LISP lab Artificial Intelligence: Introduction What IS artificial intelligence? Examples of intelligent behavior: Definitions of AI There are as many definitions
Wright-Fisher Process. (as applied to costly signaling)
") Wright-Fisher Process (as applied to costly signaling) 1 Today: 1) new model of evolution/learning (Wright-Fisher) 2) evolution/learning costly signaling (We will come back to evidence for costly signaling
Wright-Fisher Process (as applied to costly signaling) 1 Today: 1) new model of evolution/learning (Wright-Fisher) 2) evolution/learning costly signaling (We will come back to evidence for costly signaling
EE 435/535: Error Correcting Codes Project 1, Fall 2009: Extended Hamming Code. 1 Introduction. 2 Extended Hamming Code: Encoding. 1.
 EE 435/535: Error Correcting Codes Project 1, Fall 2009: Extended Hamming Code Project #1 is due on Tuesday, October 6, 2009, in class. You may turn the project report in early. Late projects are accepted
EE 435/535: Error Correcting Codes Project 1, Fall 2009: Extended Hamming Code Project #1 is due on Tuesday, October 6, 2009, in class. You may turn the project report in early. Late projects are accepted
TD-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play
 NOTE Communicated by Richard Sutton TD-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play Gerald Tesauro IBM Thomas 1. Watson Research Center, I? 0. Box 704, Yorktozon Heights, NY 10598
NOTE Communicated by Richard Sutton TD-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play Gerald Tesauro IBM Thomas 1. Watson Research Center, I? 0. Box 704, Yorktozon Heights, NY 10598
POKER AGENTS LD Miller & Adam Eck April 14 & 19, 2011
 POKER AGENTS LD Miller & Adam Eck April 14 & 19, 2011 Motivation Classic environment properties of MAS Stochastic behavior (agents and environment) Incomplete information Uncertainty Application Examples
POKER AGENTS LD Miller & Adam Eck April 14 & 19, 2011 Motivation Classic environment properties of MAS Stochastic behavior (agents and environment) Incomplete information Uncertainty Application Examples
Traffic Control for a Swarm of Robots: Avoiding Group Conflicts
 Traffic Control for a Swarm of Robots: Avoiding Group Conflicts Leandro Soriano Marcolino and Luiz Chaimowicz Abstract A very common problem in the navigation of robotic swarms is when groups of robots
Traffic Control for a Swarm of Robots: Avoiding Group Conflicts Leandro Soriano Marcolino and Luiz Chaimowicz Abstract A very common problem in the navigation of robotic swarms is when groups of robots
Practice Session 2. HW 1 Review
 Practice Session 2 HW 1 Review Chapter 1 1.4 Suppose we extend Evans s Analogy program so that it can score 200 on a standard IQ test. Would we then have a program more intelligent than a human? Explain.
Practice Session 2 HW 1 Review Chapter 1 1.4 Suppose we extend Evans s Analogy program so that it can score 200 on a standard IQ test. Would we then have a program more intelligent than a human? Explain.
Learning in 3-Player Kuhn Poker
 University of Manchester Learning in 3-Player Kuhn Poker Author: Yifei Wang 3rd Year Project Final Report Supervisor: Dr. Jonathan Shapiro April 25, 2015 Abstract This report contains how an ɛ-nash Equilibrium
University of Manchester Learning in 3-Player Kuhn Poker Author: Yifei Wang 3rd Year Project Final Report Supervisor: Dr. Jonathan Shapiro April 25, 2015 Abstract This report contains how an ɛ-nash Equilibrium
On Kalman Filtering. The 1960s: A Decade to Remember
 On Kalman Filtering A study of A New Approach to Linear Filtering and Prediction Problems by R. E. Kalman Mehul Motani February, 000 The 960s: A Decade to Remember Rudolf E. Kalman in 960 Research Institute
On Kalman Filtering A study of A New Approach to Linear Filtering and Prediction Problems by R. E. Kalman Mehul Motani February, 000 The 960s: A Decade to Remember Rudolf E. Kalman in 960 Research Institute
Modeling and Control of Mold Oscillation
 ANNUAL REPORT UIUC, August 8, Modeling and Control of Mold Oscillation Vivek Natarajan (Ph.D. Student), Joseph Bentsman Department of Mechanical Science and Engineering University of Illinois at UrbanaChampaign
ANNUAL REPORT UIUC, August 8, Modeling and Control of Mold Oscillation Vivek Natarajan (Ph.D. Student), Joseph Bentsman Department of Mechanical Science and Engineering University of Illinois at UrbanaChampaign
CMSC 671 Project Report- Google AI Challenge: Planet Wars
 1. Introduction Purpose The purpose of the project is to apply relevant AI techniques learned during the course with a view to develop an intelligent game playing bot for the game of Planet Wars. Planet
1. Introduction Purpose The purpose of the project is to apply relevant AI techniques learned during the course with a view to develop an intelligent game playing bot for the game of Planet Wars. Planet
CAPIR: Collaborative Action Planning with Intention Recognition
 CAPIR: Collaborative Action Planning with Intention Recognition Truong-Huy Dinh Nguyen and David Hsu and Wee-Sun Lee and Tze-Yun Leong Department of Computer Science, National University of Singapore,
CAPIR: Collaborative Action Planning with Intention Recognition Truong-Huy Dinh Nguyen and David Hsu and Wee-Sun Lee and Tze-Yun Leong Department of Computer Science, National University of Singapore,
Learning and Using Models of Kicking Motions for Legged Robots
 Learning and Using Models of Kicking Motions for Legged Robots Sonia Chernova and Manuela Veloso Computer Science Department Carnegie Mellon University Pittsburgh, PA 15213 {soniac, mmv}@cs.cmu.edu Abstract
Learning and Using Models of Kicking Motions for Legged Robots Sonia Chernova and Manuela Veloso Computer Science Department Carnegie Mellon University Pittsburgh, PA 15213 {soniac, mmv}@cs.cmu.edu Abstract
University of Tennessee at. Chattanooga
 University of Tennessee at Chattanooga Step Response Engineering 329 By Gold Team: Jason Price Jered Swartz Simon Ionashku 2-3- 2 INTRODUCTION: The purpose of the experiments was to investigate and understand
University of Tennessee at Chattanooga Step Response Engineering 329 By Gold Team: Jason Price Jered Swartz Simon Ionashku 2-3- 2 INTRODUCTION: The purpose of the experiments was to investigate and understand
COMPACT FUZZY Q LEARNING FOR AUTONOMOUS MOBILE ROBOT NAVIGATION
 COMPACT FUZZY Q LEARNING FOR AUTONOMOUS MOBILE ROBOT NAVIGATION Handy Wicaksono, Khairul Anam 2, Prihastono 3, Indra Adjie Sulistijono 4, Son Kuswadi 5 Department of Electrical Engineering, Petra Christian
COMPACT FUZZY Q LEARNING FOR AUTONOMOUS MOBILE ROBOT NAVIGATION Handy Wicaksono, Khairul Anam 2, Prihastono 3, Indra Adjie Sulistijono 4, Son Kuswadi 5 Department of Electrical Engineering, Petra Christian
A Toolbox of Hamilton-Jacobi Solvers for Analysis of Nondeterministic Continuous and Hybrid Systems
 A Toolbox of Hamilton-Jacobi Solvers for Analysis of Nondeterministic Continuous and Hybrid Systems Ian Mitchell Department of Computer Science University of British Columbia Jeremy Templeton Department
A Toolbox of Hamilton-Jacobi Solvers for Analysis of Nondeterministic Continuous and Hybrid Systems Ian Mitchell Department of Computer Science University of British Columbia Jeremy Templeton Department
COMP219: Artificial Intelligence. Lecture 13: Game Playing
 CMP219: Artificial Intelligence Lecture 13: Game Playing 1 verview Last time Search with partial/no observations Belief states Incremental belief state search Determinism vs non-determinism Today We will
CMP219: Artificial Intelligence Lecture 13: Game Playing 1 verview Last time Search with partial/no observations Belief states Incremental belief state search Determinism vs non-determinism Today We will
Chapter 4 Investigation of OFDM Synchronization Techniques
 Chapter 4 Investigation of OFDM Synchronization Techniques In this chapter, basic function blocs of OFDM-based synchronous receiver such as: integral and fractional frequency offset detection, symbol timing
Chapter 4 Investigation of OFDM Synchronization Techniques In this chapter, basic function blocs of OFDM-based synchronous receiver such as: integral and fractional frequency offset detection, symbol timing
Computational Sensors
 Computational Sensors Suren Jayasuriya Postdoctoral Fellow, The Robotics Institute, Carnegie Mellon University Class Announcements 1) Vote on this poll about project checkpoint date on Piazza: https://piazza.com/class/j6dobp76al46ao?cid=126
Computational Sensors Suren Jayasuriya Postdoctoral Fellow, The Robotics Institute, Carnegie Mellon University Class Announcements 1) Vote on this poll about project checkpoint date on Piazza: https://piazza.com/class/j6dobp76al46ao?cid=126
Signal Recovery from Random Measurements
 Signal Recovery from Random Measurements Joel A. Tropp Anna C. Gilbert {jtropp annacg}@umich.edu Department of Mathematics The University of Michigan 1 The Signal Recovery Problem Let s be an m-sparse
Signal Recovery from Random Measurements Joel A. Tropp Anna C. Gilbert {jtropp annacg}@umich.edu Department of Mathematics The University of Michigan 1 The Signal Recovery Problem Let s be an m-sparse
Chapter 5. Tracking system with MEMS mirror
 Chapter 5 Tracking system with MEMS mirror Up to now, this project has dealt with the theoretical optimization of the tracking servo with MEMS mirror through the use of simulation models. For these models
Chapter 5 Tracking system with MEMS mirror Up to now, this project has dealt with the theoretical optimization of the tracking servo with MEMS mirror through the use of simulation models. For these models