Extracting meaning from audio signals - a machine learning approach
|
|
|
- Vernon Thomas
- 5 years ago
- Views:
Transcription



1 Extracting meaning from audio signals - a machine learning approach Jan Larsen isp.imm.dtu.dk 1 Extracting meaning from audio signals

2 Informatics and Mathematical the largest ICT department in Denmark image processing and computer graphics intelligent signal processing safe and secure IT systems operations research languages and verification numerical analysis system on-chips geoinformatics ontologies and databases mathematical statistics design methodologies mathematical physics embedded/distributed systems information and communication technology 2006 figures students signed in to courses 900 full time students 170 final projects at MSc 90 final projects at IT-diplom 75 faculty members 25 externally funded 70 PhD students 40 staff members DTU budget: 90 mill DKK External sources: 28 mill DKK 2 Extracting meaning from audio signals





3 ISP Group Multimedia Humanitarian Demining Machine Monitor Biomedical Systems Neuroinformatics from processing to understanding extraction of meaningful learning information by learning 3+1 faculty 3 3 postdocs 20 Ph.D. students 10 M.Sc. students 3 Extracting meaning from audio signals
4 The potential of learning machines Most real world problems are too complex to be handled by classical physical models and systems engineering approach In most real world situations there is access to data describing properties of the problem Learning machines can offer Learning of optimal prediction/decision/action Adaptation to the usage environment Explorative analysis and new insights into the problem and suggestions for improvement 4 Extracting meaning from audio signals
5 Issues and trends in machine learning Data quantity stationarity quality structure Features representation selection extraction integration sparse models Models Evaluation structure performance type robustness learning complexity high-level context selection information and interpretation integration and visualization semisupevised HCI user modeling 5 Extracting meaning from audio signals
6 Outline Take home? Machine learning framework for sound search New ways of using semisupervised learning Genre classification algorithms Involves all issues of machine learning and user modeling Involves feature selection, projection and integration Linear and New nonlinear ways classifiers of incorporating Music and audio high-level separation information and users Involves combination machine learning signal processing NMF and ICA algorithms New application domains Wind noise suppression Semi-supervised NMF algorithms 6 Extracting meaning from audio signals
7 The digital music market Wired, April 27, 2005: "With the new Rhapsody, millions of people can now experience and share digital music legally and with no strings attached," Rob Glaser, RealNetworks chairman and CEO, said in a statement. "We believe that once consumers experience Rhapsody and share it with their friends, many people will upgrade to one of our premium Rhapsody tiers." Financial Times (ft.com) 12:46 p.m. ET Dec. 28, 2005: LONDON - Visits to music downloading Web sites saw a 50 percent rise on Christmas Day as hundreds of thousands of people began loading songs on to the ipods they received as presents. Wired, January 17, 2006: Google said today it has offered to acquire digital radio advertising provider dmarc Broadcasting for $102 million in cash. 7 Extracting meaning from audio signals
8 Huge demand for tools Organization, search and retrieval Recommender systems ( taste prediction ) Playlist generation Finding similarity in music (e.g., genre classification, instrument classification, etc.) Hit prediction Newscast transcription/search Music transcription/search Machine learning is going to play a key role in future systems 8 Extracting meaning from audio signals
9 Aspects of search Specificity standard search engines indexing of deep content Similarity more like this similarity metrics Objective: high retrieval performance Objective: high generalization and user acceptance 9 Extracting meaning from audio signals




10 Specialized search and music organization Using social network analysis Explore by Genre, mood, theme, country, instrument Query by humming The NGSW is creating an online fully-searchable digital library of spoken word collections spanning the 20th century Organize songs according to tempo, genre, mood search for related songs using the 400 genes of music 10 Extracting meaning from audio signals
11 Sound information data audio data Meta data ID3 tags context User networks co-play data playlist communities user groups high ontology Description level low 11 Extracting meaning from audio signals



12 Machine learning in sound information processing audio data User networks co-play data playlist communities user groups Meta data ID3 tags context machine learning model Tasks Grouping Classification Mapping to a structure Prediction e.g. answer to query 12 Extracting meaning from audio signals
13 Machine learning for high level interpretations feature extraction feature and extraction feature selection and extraction feature selection and extraction feature selection and extraction feature selection and data extraction feature selection and extraction selection and selection Similarity functions Euclidian, Weighted Euclidian, Cosine, Nearest Feature Line, earth Mover Distance, Self-organized Maps, Distance From Boundary, Crosssampling, Bregman, unsupervised KL, Manhattan, Adaptive time integration time integration time integration time integration time integration time integration time integration machine learning model 13 Extracting meaning from audio signals
14 Frequency domain Similarity structures Time MFCC domian Low level loudness features Gamma tone filterbank zero-crossing energy pitch High log-energy level features brightness down sampling MoHMM bandwidth Metrics autocorrelation harmonicity peak detection spectrum power delta-log-loudness subband power centroid roll-off Ad hoc from time-domain, Ad hoc from spectrum, MFCC, RCC, Bark/Sone, Wavelets, Gamma-tone-filterbank low-pass filtering spectral flatness Basic statistics, Histograms, Selected subsets, GMM, Kmeans, Neural Network, SVM, QDA, SVD, AR-model, spectral tilt sharpness Euclidian, Weighted Euclidian, Cosine, Nearest Feature Line, earth Mover Distance, Self-organized roughness Maps, Distance From Boundary, Cross-sampling, Bregman, Manhattan 14 Extracting meaning from audio signals
15 Predicting the answer from query : index for answer song : index for query song : user (group index) : hidden cluster index of similarity 15 Extracting meaning from audio signals
16 Search and similarity integration d 1 d 2 d n Integration Projection onto latent space Clustering perceptual resolution user List of songs, metadata and content 16 Extracting meaning from audio signals
17 Similarity fusion Latent by variables mixture can modeling k th high-level descriptor quantized in to groups satisfactorily explain all observed similarities and provides a very convenient representation for song retrieval Synergy latent between (hidden) two descriptors variables was advatageous common to all analogy high-level between documents descriptors and songs opens new lines for investigating music structure using the elaborated machinery for web-mining J. Arenas-García, A. Meng, K. Brandt Petersen, T. Lehn-Schiøler, L.K. Hansen, J. Larsen: Unveiling music structure via PLSA similarity fusion, Extracting meaning from audio signals user specified weights

18 18 Extracting meaning from audio signals

19 Demo of WINAMP plugin Lehn-Schiøler, T., Arenas-García, J., Petersen, K. B., Hansen, L. K., A Genre Classification Plug-in for Data Collection, ISMIR, Extracting meaning from audio signals
20 Genre classification Prototypical example of predicting meta and highlevel data The problem of interpretation of genres Can be used for other applications e.g. context detection in hearing aids 20 Extracting meaning from audio signals
21 Model Making the computer classify a sound piece into musical genres such as jazz, techno and blues. Sound Signal Feature vector Probabilities Decision Pre-processing Feature extraction Statistical model Postprocessing 21 Extracting meaning from audio signals
22 How do humans do? Sounds loudness, pitch, duration and timbre Music mixed streams of sounds Recognizing musical genre physical and perceptual: instrument recognition, rhythm, roughness, vocal sound and content cultural effects 22 Extracting meaning from audio signals
23 How well do humans do? Data set with 11 genres 25 people assessing 33 random 30s clips accuracy % Baseline: 9.1% 23 Extracting meaning from audio signals
24 What s the problem? Technical problem: Hierarchical, multi-labels Real problems: Musical genre is not an intrinsic property of music A subjective measure Historical and sociological context is important No Ground-Truth 24 Extracting meaning from audio signals
25 Music genres form a hierarchy Music Jazz New Age Latin Swing Cool New Orleans Classic BB Vintage BB Contemp. BB Quincy Jones: Stuff like that (according to Amazon.com) 25 Extracting meaning from audio signals

26 Wikipedia 26 Extracting meaning from audio signals
27 Music Genre Classification Systems Sound Signal Feature vector Probabilities Decision Pre-processing Feature extraction Statistical model Postprocessing 27 Extracting meaning from audio signals
28 Features Short time features (10-30 ms) MFCC and LPC Zero-Crossing Rate (ZCR), Short-time Energy (STE) MPEG-7 Features (Spread, Centroid and Flatness Measure) Medium time features (around 1000 ms) Mean and Variance of short-time features Multivariate Autoregressive features (DAR and MAR) Long time features (several seconds) Beat Histogram 28 Extracting meaning from audio signals
29 On MFCC Discrete Fourier transform Log amplitude spectrum Mel scaling and smoothing Discrete Cosine transform MFCC represents a mel-weighted spectral envelope. The mel-scale models human auditory perception. Are believed to encode music timbre Sigurdsson, S., Petersen, K. B., Mel Frequency Cepstral Coefficients: An Evaluation of Robustness of MP3 Encoded Music, Proceedings of the Seventh International Conference on Music Information Retrieval (ISMIR), Extracting meaning from audio signals
30 Features for genre classification 30s sound clip from the center of the song 6 MFCCs, 30ms frame 6 MFCCs, 30ms frame 6 MFCCs, 30ms frame 3 ARCs per MFCC, 760ms frame 30-dimensional AR features, x r,r=1,..,80 30 Extracting meaning from audio signals


31 31 Extracting meaning from audio signals
32 Statistical models Desired: (genre class and song ) Used models Intregration of MFCCs using MAR models Linear and non-linear neural networks Gaussian classifier Gaussian Mixture Model Co-occurrence models 32 Extracting meaning from audio signals
33 Example of MFCC s Cross correlation Temporal correlation 33 Extracting meaning from audio signals
34 Results reported in Meng, A., Ahrendt, P., Larsen, J., Hansen, L. K., Temporal Feature Integration for Music Genre Classification, IEEE Transactions on Speech and Audio Processing, A. Meng, P. Ahrendt, J. Larsen, Improving Music Genre Classification by Short-Time Feature Integration, IEEE International Conference on Acoustics, Speech, and Signal Processing, vol. V, pp , Ahrendt, P., Goutte, C., Larsen, J., Co-occurrence Models in Music Genre Classification, IEEE International workshop on Machine Learning for Signal Processing, pp , Ahrendt, P., Meng, A., Larsen, J., Decision Time Horizon for Music Genre Classification using Short Time Features, EUSIPCO, pp , Meng, A., Shawe-Taylor, J., An Investigation of Feature Models for Music Genre Classification using the Support Vector Classifier, International Conference on Music Information Retrieval, pp , Extracting meaning from audio signals
35 Best results 5-genre problem (with little class overlap) : 2% error Comparable to human classification on this database Amazon.com 6-genre problem (some overlap) : 30% error 11-genre problem (some overlap) : 50% error human error about 43% 35 Extracting meaning from audio signals

36 Best 11-genre confusion matrix 36 Extracting meaning from audio signals

37 11-genre human evaluation 37 Extracting meaning from audio signals
38 Supervised Filter Design in Temporal Feature Integration Model the dynamics of MFCCs: Obtaining periodograms for each frame of 768ms MFCC Bank-filter these new features to obtain discriminative data J. Arenas-Gacía, J. Larsen, L.H. Hansen, A. Meng: Optimal filtering of dynamics in short-time features for music organization, ISMIR Extracting meaning from audio signals


39 MFCC3 frequency Periodograms contain information about how fast MFCCs change A bank with 4 constant-amplitude was proposed for genre classification - 0 Hz : DC Value Hz : Beat rates Hz : Modulation energy (e.g., vibrato) - 20 Fs/2 Hz : Perceptual Roughness Orthonormalized PLS can be used for a better design of this bank filter. Additional constraint U>0: Positive Constrained OPLS (POPLS) 39 Extracting meaning from audio signals
40 Illustrative example: vibrato detection 64 (32/32) AltoSax music snippets in Db3-Ab5 Only the first MFCC was used Vib NonVib Leave-one-out CV error: 9,4 % (n f = 25); 20 % (n f = 2) (Fixed filter bank: 48,3 %) 40 Extracting meaning from audio signals
41 POPLS for genre classification 1317 music snippets (30 s) evenly distributed among 11 genres 7 MFCCs, but an unique filter bank POPLS 2% better on average compared to a fixed filter bank of four filter 10-fold cross-validation error falls to 61 % for n f = Extracting meaning from audio signals
42 Interpretation of filters Filter 1: modulation frequencies of instruments Filter 2: lower modulation frequency + beat-scale Filter 4: perceptual roughness Consistent filters across 10- fold cross-validation robustness to noise relevant features for genre 42 Extracting meaning from audio signals
43 Music separation A possible front end component for the music search framework Noise reduction Semi-supervised learning methods Music transcription Instrument detection and separation Vocalist identification Pedersen, M. S., Larsen, J., Kjems, U., Parra, L. C., A Survey of Convolutive Blind Source Separation Methods, Springer Handbook of Speech, Springer Press, Extracting meaning from audio signals


44 Nonnegative matrix factor 2D deconvolution φ time 3200 pitch Frequency [Hz] τ Time [s] M. N. Schmidt, M. Mørup Nonnegative Matrix Factor 2-D Deconvolution for Blind Single Channel Source Separation, ICA2006, Demo also available. 44 Extracting meaning from audio signals 200

45 Demonstration of the 2D convolutive NMF model φ Frequency [Hz] τ Time [s] Extracting meaning from audio signals






46 Separating music into basic components 46 Extracting meaning from audio signals
47 Separating music into basic components Combined ICA and masking Pedersen, M. S., Wang, D., Larsen, J., Kjems, U., Two-microphone Separation of Speech Mixtures, IEEE Transactions on Neural Networks, 2007 Pedersen, M. S., Lehn-Schiøler, T., Larsen, J., BLUES from Music: BLind Underdetermined Extraction of Sources from Music, ICA2006, vol. 3889, pp , Springer Berlin / Heidelberg, 2006 Pedersen, M. S., Wang, D., Larsen, J., Kjems, U., Separating Underdetermined Convolutive Speech Mixtures, ICA 2006, vol. 3889, pp , Springer Berlin / Heidelberg, 2006 Pedersen, M. S., Wang, D., Larsen, J., Kjems, U., Overcomplete Blind Source Separation by Combining ICA and Binary Time- Frequency Masking, IEEE International workshop on Machine Learning for Signal Processing, pp , Extracting meaning from audio signals
48 Assumptions Stereo recording of the music piece is available. The instruments are separated to some extent in time and in frequency, i.e., the instruments are sparse in the time-frequency (T-F) domain. The different instruments originate from spatially different directions. 48 Extracting meaning from audio signals





49 Separation principle: ideal T-F masking 49 Extracting meaning from audio signals



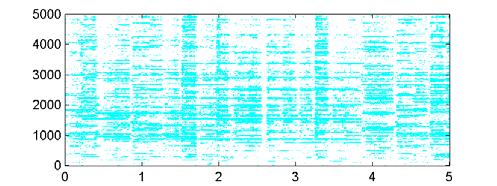
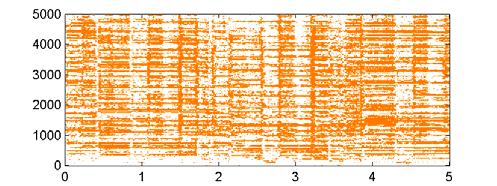


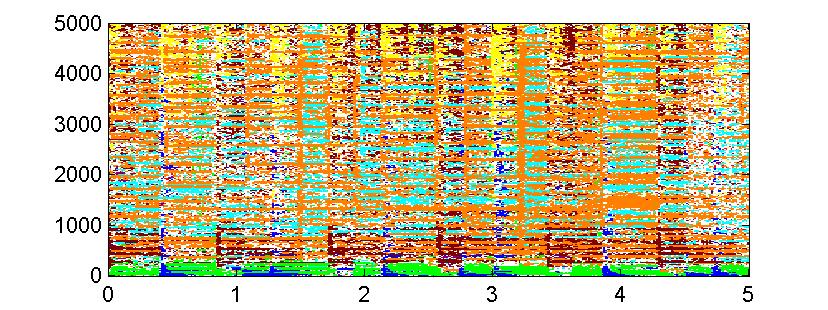


50 Stereo channel 1 Gain difference between channels Stereo channel 2 50 Extracting meaning from audio signals
51 Separation principle 2: ICA mixing separation sources x = As mixed signals ICA y = Wx recovered source signals What happens if a 2-by-2 separation matrix W is applied to a 2-by-N mixing system? 51 Extracting meaning from audio signals
52 ICA on stereo signals We assume that the mixture can be modeled as an instantaneous mixture, i.e., x= A( θ,..., θ ) s 1 N A( θ ) r( θ ) r( θ ) N = r2( θ1) r2( θn ) The ratio between the gains in each column in the mixing matrix corresponds to a certain direction 52 Extracting meaning from audio signals


53 Direction dependent gain r( θ) = 20log WA( θ) When W is applied, the two separated channels each contain a group of sources, which is as independent as possible from the other channel. 53 Extracting meaning from audio signals
54 Combining ICA and T-F masking x 1 x 2 separator STFT ICA y 1 y 2 STFT Y 1 (t, f) Y 2 (t, f) BM 1 1 when Y 1 / Y 2 > c 1 when Y 2 / Y 1 > c = BM 2 = 0 otherwise 0 otherwise BM 1 BM 2 X 1 (t,f) X 2 (t,f) X 1 (t,f) X 2 (t,f) ISTFT ISTFT ISTFT ISTFT ^ x 1 (1) ^ x 2 (1) ^ x 1 (2) ^ x 2 (2) 54 Extracting meaning from audio signals
55 Method applied iteratively x 1 x 2 55 Extracting meaning from audio signals
56 Intelligent Signal Processing Group, IMM, DTU / Jan Larsen Improved method The assumption of instantaneous mixing may not always hold Assumption can be relaxed Separation procedure is continued until very sparse masks are obtained Masks that mainly contain the same source are afterwards merged 56 Extracting meaning from audio signals




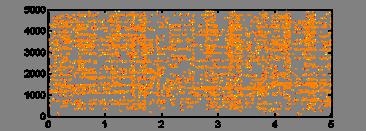





57 Mask merging If the signals are correlated (envelope), their corresponding masks are merged. + The resulting signal from the merged mask is of higher quality. 57 Extracting meaning from audio signals
58 Results Evaluation on real stereo music recordings, with the stereo recording of each instrument available, before mixing. We find the correlation between the obtained sources and the by the ideal binary mask obtained sources. Other segregated music examples and code are available online via 58 Extracting meaning from audio signals



59 Results The segregated outputs are dominated by individual instruments Some instruments cannot be segregated by this method, because they are not spatially different. 59 Extracting meaning from audio signals
60 Conclusion on combined ICA T-F separation An unsupervised method for segregation of single instruments or vocal sound from stereo music. The segregated signals are maintained in stereo. Only spatially different signals can be segregated from each other. The proposed framework may be improved by combining the method with single channel separation methods. 60 Extracting meaning from audio signals


61 Wind noise reduction M.N Schmidt, J. Larsen, F.T. Hsiao: Wind noise reduction using non-negative sparse coding, Extracting meaning from audio signals
62 Sparse NMF decomposition Code-book (dictionary) of noise spectra is learned Can be interpreted as an advanced spectral subtraction technique original cleaned alternative method (qualcom) 62 Extracting meaning from audio signals
63 Objective performance 63 Extracting meaning from audio signals
64 Summary Machine learning is, and will become, an important component in most real world applications Semi-supervised learning Sparse models and automatic model and featutre selection Incorporation of high-level context description User modeling Searching in massive amounts of heterogeneous enhances productivity simply important to.quality of life Machine learning is essential for search in particular mapping low level data to high description levels enabling human interpretation Music and audio separation combines unsupervised methods ICA/MNF with other SP and supervised techniques 64 Extracting meaning from audio signals
Extracting Meaning from Sound Signals a machine learning approach
 Extracting Meaning from Sound Signals a machine learning approach, Associate Professor PhD Cognitive Systems Section Dept. of Informatics and Mathematical Modelling Technical University of Denmark jl@imm.dtu.dk,
Extracting Meaning from Sound Signals a machine learning approach, Associate Professor PhD Cognitive Systems Section Dept. of Informatics and Mathematical Modelling Technical University of Denmark jl@imm.dtu.dk,
Applications of Music Processing
 Lecture Music Processing Applications of Music Processing Christian Dittmar International Audio Laboratories Erlangen christian.dittmar@audiolabs-erlangen.de Singing Voice Detection Important pre-requisite
Lecture Music Processing Applications of Music Processing Christian Dittmar International Audio Laboratories Erlangen christian.dittmar@audiolabs-erlangen.de Singing Voice Detection Important pre-requisite
Singing Voice Detection. Applications of Music Processing. Singing Voice Detection. Singing Voice Detection. Singing Voice Detection
 Detection Lecture usic Processing Applications of usic Processing Christian Dittmar International Audio Laboratories Erlangen christian.dittmar@audiolabs-erlangen.de Important pre-requisite for: usic segmentation
Detection Lecture usic Processing Applications of usic Processing Christian Dittmar International Audio Laboratories Erlangen christian.dittmar@audiolabs-erlangen.de Important pre-requisite for: usic segmentation
MUSICAL GENRE CLASSIFICATION OF AUDIO DATA USING SOURCE SEPARATION TECHNIQUES. P.S. Lampropoulou, A.S. Lampropoulos and G.A.
 MUSICAL GENRE CLASSIFICATION OF AUDIO DATA USING SOURCE SEPARATION TECHNIQUES P.S. Lampropoulou, A.S. Lampropoulos and G.A. Tsihrintzis Department of Informatics, University of Piraeus 80 Karaoli & Dimitriou
MUSICAL GENRE CLASSIFICATION OF AUDIO DATA USING SOURCE SEPARATION TECHNIQUES P.S. Lampropoulou, A.S. Lampropoulos and G.A. Tsihrintzis Department of Informatics, University of Piraeus 80 Karaoli & Dimitriou
Drum Transcription Based on Independent Subspace Analysis
 Report for EE 391 Special Studies and Reports for Electrical Engineering Drum Transcription Based on Independent Subspace Analysis Yinyi Guo Center for Computer Research in Music and Acoustics, Stanford,
Report for EE 391 Special Studies and Reports for Electrical Engineering Drum Transcription Based on Independent Subspace Analysis Yinyi Guo Center for Computer Research in Music and Acoustics, Stanford,
Rhythmic Similarity -- a quick paper review. Presented by: Shi Yong March 15, 2007 Music Technology, McGill University
 Rhythmic Similarity -- a quick paper review Presented by: Shi Yong March 15, 2007 Music Technology, McGill University Contents Introduction Three examples J. Foote 2001, 2002 J. Paulus 2002 S. Dixon 2004
Rhythmic Similarity -- a quick paper review Presented by: Shi Yong March 15, 2007 Music Technology, McGill University Contents Introduction Three examples J. Foote 2001, 2002 J. Paulus 2002 S. Dixon 2004
Sound Recognition. ~ CSE 352 Team 3 ~ Jason Park Evan Glover. Kevin Lui Aman Rawat. Prof. Anita Wasilewska
 Sound Recognition ~ CSE 352 Team 3 ~ Jason Park Evan Glover Kevin Lui Aman Rawat Prof. Anita Wasilewska What is Sound? Sound is a vibration that propagates as a typically audible mechanical wave of pressure
Sound Recognition ~ CSE 352 Team 3 ~ Jason Park Evan Glover Kevin Lui Aman Rawat Prof. Anita Wasilewska What is Sound? Sound is a vibration that propagates as a typically audible mechanical wave of pressure
Audio Similarity. Mark Zadel MUMT 611 March 8, Audio Similarity p.1/23
 Audio Similarity Mark Zadel MUMT 611 March 8, 2004 Audio Similarity p.1/23 Overview MFCCs Foote Content-Based Retrieval of Music and Audio (1997) Logan, Salomon A Music Similarity Function Based On Signal
Audio Similarity Mark Zadel MUMT 611 March 8, 2004 Audio Similarity p.1/23 Overview MFCCs Foote Content-Based Retrieval of Music and Audio (1997) Logan, Salomon A Music Similarity Function Based On Signal
Advanced audio analysis. Martin Gasser
 Advanced audio analysis Martin Gasser Motivation Which methods are common in MIR research? How can we parameterize audio signals? Interesting dimensions of audio: Spectral/ time/melody structure, high
Advanced audio analysis Martin Gasser Motivation Which methods are common in MIR research? How can we parameterize audio signals? Interesting dimensions of audio: Spectral/ time/melody structure, high
An Optimization of Audio Classification and Segmentation using GASOM Algorithm
 An Optimization of Audio Classification and Segmentation using GASOM Algorithm Dabbabi Karim, Cherif Adnen Research Unity of Processing and Analysis of Electrical and Energetic Systems Faculty of Sciences
An Optimization of Audio Classification and Segmentation using GASOM Algorithm Dabbabi Karim, Cherif Adnen Research Unity of Processing and Analysis of Electrical and Energetic Systems Faculty of Sciences
Audio Fingerprinting using Fractional Fourier Transform
 Audio Fingerprinting using Fractional Fourier Transform Swati V. Sutar 1, D. G. Bhalke 2 1 (Department of Electronics & Telecommunication, JSPM s RSCOE college of Engineering Pune, India) 2 (Department,
Audio Fingerprinting using Fractional Fourier Transform Swati V. Sutar 1, D. G. Bhalke 2 1 (Department of Electronics & Telecommunication, JSPM s RSCOE college of Engineering Pune, India) 2 (Department,
SONG RETRIEVAL SYSTEM USING HIDDEN MARKOV MODELS
 SONG RETRIEVAL SYSTEM USING HIDDEN MARKOV MODELS AKSHAY CHANDRASHEKARAN ANOOP RAMAKRISHNA akshayc@cmu.edu anoopr@andrew.cmu.edu ABHISHEK JAIN GE YANG ajain2@andrew.cmu.edu younger@cmu.edu NIDHI KOHLI R
SONG RETRIEVAL SYSTEM USING HIDDEN MARKOV MODELS AKSHAY CHANDRASHEKARAN ANOOP RAMAKRISHNA akshayc@cmu.edu anoopr@andrew.cmu.edu ABHISHEK JAIN GE YANG ajain2@andrew.cmu.edu younger@cmu.edu NIDHI KOHLI R
Design and Implementation of an Audio Classification System Based on SVM
 Available online at www.sciencedirect.com Procedia ngineering 15 (011) 4031 4035 Advanced in Control ngineering and Information Science Design and Implementation of an Audio Classification System Based
Available online at www.sciencedirect.com Procedia ngineering 15 (011) 4031 4035 Advanced in Control ngineering and Information Science Design and Implementation of an Audio Classification System Based
Classification of ships using autocorrelation technique for feature extraction of the underwater acoustic noise
 Classification of ships using autocorrelation technique for feature extraction of the underwater acoustic noise Noha KORANY 1 Alexandria University, Egypt ABSTRACT The paper applies spectral analysis to
Classification of ships using autocorrelation technique for feature extraction of the underwater acoustic noise Noha KORANY 1 Alexandria University, Egypt ABSTRACT The paper applies spectral analysis to
A CONSTRUCTION OF COMPACT MFCC-TYPE FEATURES USING SHORT-TIME STATISTICS FOR APPLICATIONS IN AUDIO SEGMENTATION
 17th European Signal Processing Conference (EUSIPCO 2009) Glasgow, Scotland, August 24-28, 2009 A CONSTRUCTION OF COMPACT MFCC-TYPE FEATURES USING SHORT-TIME STATISTICS FOR APPLICATIONS IN AUDIO SEGMENTATION
17th European Signal Processing Conference (EUSIPCO 2009) Glasgow, Scotland, August 24-28, 2009 A CONSTRUCTION OF COMPACT MFCC-TYPE FEATURES USING SHORT-TIME STATISTICS FOR APPLICATIONS IN AUDIO SEGMENTATION
Performance study of Text-independent Speaker identification system using MFCC & IMFCC for Telephone and Microphone Speeches
 Performance study of Text-independent Speaker identification system using & I for Telephone and Microphone Speeches Ruchi Chaudhary, National Technical Research Organization Abstract: A state-of-the-art
Performance study of Text-independent Speaker identification system using & I for Telephone and Microphone Speeches Ruchi Chaudhary, National Technical Research Organization Abstract: A state-of-the-art
A multi-class method for detecting audio events in news broadcasts
 A multi-class method for detecting audio events in news broadcasts Sergios Petridis, Theodoros Giannakopoulos, and Stavros Perantonis Computational Intelligence Laboratory, Institute of Informatics and
A multi-class method for detecting audio events in news broadcasts Sergios Petridis, Theodoros Giannakopoulos, and Stavros Perantonis Computational Intelligence Laboratory, Institute of Informatics and
Environmental Sound Recognition using MP-based Features
 Environmental Sound Recognition using MP-based Features Selina Chu, Shri Narayanan *, and C.-C. Jay Kuo * Speech Analysis and Interpretation Lab Signal & Image Processing Institute Department of Computer
Environmental Sound Recognition using MP-based Features Selina Chu, Shri Narayanan *, and C.-C. Jay Kuo * Speech Analysis and Interpretation Lab Signal & Image Processing Institute Department of Computer
Speech/Music Change Point Detection using Sonogram and AANN
 International Journal of Information & Computation Technology. ISSN 0974-2239 Volume 6, Number 1 (2016), pp. 45-49 International Research Publications House http://www. irphouse.com Speech/Music Change
International Journal of Information & Computation Technology. ISSN 0974-2239 Volume 6, Number 1 (2016), pp. 45-49 International Research Publications House http://www. irphouse.com Speech/Music Change
An Efficient Extraction of Vocal Portion from Music Accompaniment Using Trend Estimation
 An Efficient Extraction of Vocal Portion from Music Accompaniment Using Trend Estimation Aisvarya V 1, Suganthy M 2 PG Student [Comm. Systems], Dept. of ECE, Sree Sastha Institute of Engg. & Tech., Chennai,
An Efficient Extraction of Vocal Portion from Music Accompaniment Using Trend Estimation Aisvarya V 1, Suganthy M 2 PG Student [Comm. Systems], Dept. of ECE, Sree Sastha Institute of Engg. & Tech., Chennai,
SOUND SOURCE RECOGNITION AND MODELING
 SOUND SOURCE RECOGNITION AND MODELING CASA seminar, summer 2000 Antti Eronen antti.eronen@tut.fi Contents: Basics of human sound source recognition Timbre Voice recognition Recognition of environmental
SOUND SOURCE RECOGNITION AND MODELING CASA seminar, summer 2000 Antti Eronen antti.eronen@tut.fi Contents: Basics of human sound source recognition Timbre Voice recognition Recognition of environmental
Introduction of Audio and Music
 1 Introduction of Audio and Music Wei-Ta Chu 2009/12/3 Outline 2 Introduction of Audio Signals Introduction of Music 3 Introduction of Audio Signals Wei-Ta Chu 2009/12/3 Li and Drew, Fundamentals of Multimedia,
1 Introduction of Audio and Music Wei-Ta Chu 2009/12/3 Outline 2 Introduction of Audio Signals Introduction of Music 3 Introduction of Audio Signals Wei-Ta Chu 2009/12/3 Li and Drew, Fundamentals of Multimedia,
Preeti Rao 2 nd CompMusicWorkshop, Istanbul 2012
 Preeti Rao 2 nd CompMusicWorkshop, Istanbul 2012 o Music signal characteristics o Perceptual attributes and acoustic properties o Signal representations for pitch detection o STFT o Sinusoidal model o
Preeti Rao 2 nd CompMusicWorkshop, Istanbul 2012 o Music signal characteristics o Perceptual attributes and acoustic properties o Signal representations for pitch detection o STFT o Sinusoidal model o
Data processing framework for decision making
 Data processing framework for decision making Jan Larsen Intelligent Signal Processing Group Department of Informatics and Mathematical Modelling Technical University of Denmark jl@imm.dtu.dk, www.imm.dtu.dk/~jl
Data processing framework for decision making Jan Larsen Intelligent Signal Processing Group Department of Informatics and Mathematical Modelling Technical University of Denmark jl@imm.dtu.dk, www.imm.dtu.dk/~jl
DERIVATION OF TRAPS IN AUDITORY DOMAIN
 DERIVATION OF TRAPS IN AUDITORY DOMAIN Petr Motlíček, Doctoral Degree Programme (4) Dept. of Computer Graphics and Multimedia, FIT, BUT E-mail: motlicek@fit.vutbr.cz Supervised by: Dr. Jan Černocký, Prof.
DERIVATION OF TRAPS IN AUDITORY DOMAIN Petr Motlíček, Doctoral Degree Programme (4) Dept. of Computer Graphics and Multimedia, FIT, BUT E-mail: motlicek@fit.vutbr.cz Supervised by: Dr. Jan Černocký, Prof.
Audio Imputation Using the Non-negative Hidden Markov Model
 Audio Imputation Using the Non-negative Hidden Markov Model Jinyu Han 1,, Gautham J. Mysore 2, and Bryan Pardo 1 1 EECS Department, Northwestern University 2 Advanced Technology Labs, Adobe Systems Inc.
Audio Imputation Using the Non-negative Hidden Markov Model Jinyu Han 1,, Gautham J. Mysore 2, and Bryan Pardo 1 1 EECS Department, Northwestern University 2 Advanced Technology Labs, Adobe Systems Inc.
Performance Analysis of MFCC and LPCC Techniques in Automatic Speech Recognition
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume - 3 Issue - 8 August, 2014 Page No. 7727-7732 Performance Analysis of MFCC and LPCC Techniques in Automatic
www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume - 3 Issue - 8 August, 2014 Page No. 7727-7732 Performance Analysis of MFCC and LPCC Techniques in Automatic
University of Colorado at Boulder ECEN 4/5532. Lab 1 Lab report due on February 2, 2015
 University of Colorado at Boulder ECEN 4/5532 Lab 1 Lab report due on February 2, 2015 This is a MATLAB only lab, and therefore each student needs to turn in her/his own lab report and own programs. 1
University of Colorado at Boulder ECEN 4/5532 Lab 1 Lab report due on February 2, 2015 This is a MATLAB only lab, and therefore each student needs to turn in her/his own lab report and own programs. 1
An Improved Voice Activity Detection Based on Deep Belief Networks
 e-issn 2455 1392 Volume 2 Issue 4, April 2016 pp. 676-683 Scientific Journal Impact Factor : 3.468 http://www.ijcter.com An Improved Voice Activity Detection Based on Deep Belief Networks Shabeeba T. K.
e-issn 2455 1392 Volume 2 Issue 4, April 2016 pp. 676-683 Scientific Journal Impact Factor : 3.468 http://www.ijcter.com An Improved Voice Activity Detection Based on Deep Belief Networks Shabeeba T. K.
Mel Spectrum Analysis of Speech Recognition using Single Microphone
 International Journal of Engineering Research in Electronics and Communication Mel Spectrum Analysis of Speech Recognition using Single Microphone [1] Lakshmi S.A, [2] Cholavendan M [1] PG Scholar, Sree
International Journal of Engineering Research in Electronics and Communication Mel Spectrum Analysis of Speech Recognition using Single Microphone [1] Lakshmi S.A, [2] Cholavendan M [1] PG Scholar, Sree
An Adaptive Algorithm for Speech Source Separation in Overcomplete Cases Using Wavelet Packets
 Proceedings of the th WSEAS International Conference on Signal Processing, Istanbul, Turkey, May 7-9, 6 (pp4-44) An Adaptive Algorithm for Speech Source Separation in Overcomplete Cases Using Wavelet Packets
Proceedings of the th WSEAS International Conference on Signal Processing, Istanbul, Turkey, May 7-9, 6 (pp4-44) An Adaptive Algorithm for Speech Source Separation in Overcomplete Cases Using Wavelet Packets
Advanced Music Content Analysis
 RuSSIR 2013: Content- and Context-based Music Similarity and Retrieval Titelmasterformat durch Klicken bearbeiten Advanced Music Content Analysis Markus Schedl Peter Knees {markus.schedl, peter.knees}@jku.at
RuSSIR 2013: Content- and Context-based Music Similarity and Retrieval Titelmasterformat durch Klicken bearbeiten Advanced Music Content Analysis Markus Schedl Peter Knees {markus.schedl, peter.knees}@jku.at
Dimension Reduction of the Modulation Spectrogram for Speaker Verification
 Dimension Reduction of the Modulation Spectrogram for Speaker Verification Tomi Kinnunen Speech and Image Processing Unit Department of Computer Science University of Joensuu, Finland Kong Aik Lee and
Dimension Reduction of the Modulation Spectrogram for Speaker Verification Tomi Kinnunen Speech and Image Processing Unit Department of Computer Science University of Joensuu, Finland Kong Aik Lee and
Single-channel Mixture Decomposition using Bayesian Harmonic Models
 Single-channel Mixture Decomposition using Bayesian Harmonic Models Emmanuel Vincent and Mark D. Plumbley Electronic Engineering Department, Queen Mary, University of London Mile End Road, London E1 4NS,
Single-channel Mixture Decomposition using Bayesian Harmonic Models Emmanuel Vincent and Mark D. Plumbley Electronic Engineering Department, Queen Mary, University of London Mile End Road, London E1 4NS,
1 DTU Informatics, Technical University of Denmark
 1 DTU Informatics, Technical University of Denmark is the average general attention span. Continuous attention span is only 8 secs. 2 DTU Informatics, Technical University of Denmark is the average general
1 DTU Informatics, Technical University of Denmark is the average general attention span. Continuous attention span is only 8 secs. 2 DTU Informatics, Technical University of Denmark is the average general
ANALYSIS OF ACOUSTIC FEATURES FOR AUTOMATED MULTI-TRACK MIXING
 th International Society for Music Information Retrieval Conference (ISMIR ) ANALYSIS OF ACOUSTIC FEATURES FOR AUTOMATED MULTI-TRACK MIXING Jeffrey Scott, Youngmoo E. Kim Music and Entertainment Technology
th International Society for Music Information Retrieval Conference (ISMIR ) ANALYSIS OF ACOUSTIC FEATURES FOR AUTOMATED MULTI-TRACK MIXING Jeffrey Scott, Youngmoo E. Kim Music and Entertainment Technology
AUTOMATED MUSIC TRACK GENERATION
 AUTOMATED MUSIC TRACK GENERATION LOUIS EUGENE Stanford University leugene@stanford.edu GUILLAUME ROSTAING Stanford University rostaing@stanford.edu Abstract: This paper aims at presenting our method to
AUTOMATED MUSIC TRACK GENERATION LOUIS EUGENE Stanford University leugene@stanford.edu GUILLAUME ROSTAING Stanford University rostaing@stanford.edu Abstract: This paper aims at presenting our method to
Long Range Acoustic Classification
 Approved for public release; distribution is unlimited. Long Range Acoustic Classification Authors: Ned B. Thammakhoune, Stephen W. Lang Sanders a Lockheed Martin Company P. O. Box 868 Nashua, New Hampshire
Approved for public release; distribution is unlimited. Long Range Acoustic Classification Authors: Ned B. Thammakhoune, Stephen W. Lang Sanders a Lockheed Martin Company P. O. Box 868 Nashua, New Hampshire
UNSUPERVISED SPEAKER CHANGE DETECTION FOR BROADCAST NEWS SEGMENTATION
 4th European Signal Processing Conference (EUSIPCO 26), Florence, Italy, September 4-8, 26, copyright by EURASIP UNSUPERVISED SPEAKER CHANGE DETECTION FOR BROADCAST NEWS SEGMENTATION Kasper Jørgensen,
4th European Signal Processing Conference (EUSIPCO 26), Florence, Italy, September 4-8, 26, copyright by EURASIP UNSUPERVISED SPEAKER CHANGE DETECTION FOR BROADCAST NEWS SEGMENTATION Kasper Jørgensen,
Speech Synthesis using Mel-Cepstral Coefficient Feature
 Speech Synthesis using Mel-Cepstral Coefficient Feature By Lu Wang Senior Thesis in Electrical Engineering University of Illinois at Urbana-Champaign Advisor: Professor Mark Hasegawa-Johnson May 2018 Abstract
Speech Synthesis using Mel-Cepstral Coefficient Feature By Lu Wang Senior Thesis in Electrical Engineering University of Illinois at Urbana-Champaign Advisor: Professor Mark Hasegawa-Johnson May 2018 Abstract
Voice Activity Detection
 Voice Activity Detection Speech Processing Tom Bäckström Aalto University October 2015 Introduction Voice activity detection (VAD) (or speech activity detection, or speech detection) refers to a class
Voice Activity Detection Speech Processing Tom Bäckström Aalto University October 2015 Introduction Voice activity detection (VAD) (or speech activity detection, or speech detection) refers to a class
An Audio Fingerprint Algorithm Based on Statistical Characteristics of db4 Wavelet
 Journal of Information & Computational Science 8: 14 (2011) 3027 3034 Available at http://www.joics.com An Audio Fingerprint Algorithm Based on Statistical Characteristics of db4 Wavelet Jianguo JIANG
Journal of Information & Computational Science 8: 14 (2011) 3027 3034 Available at http://www.joics.com An Audio Fingerprint Algorithm Based on Statistical Characteristics of db4 Wavelet Jianguo JIANG
Reduction of Musical Residual Noise Using Harmonic- Adapted-Median Filter
 Reduction of Musical Residual Noise Using Harmonic- Adapted-Median Filter Ching-Ta Lu, Kun-Fu Tseng 2, Chih-Tsung Chen 2 Department of Information Communication, Asia University, Taichung, Taiwan, ROC
Reduction of Musical Residual Noise Using Harmonic- Adapted-Median Filter Ching-Ta Lu, Kun-Fu Tseng 2, Chih-Tsung Chen 2 Department of Information Communication, Asia University, Taichung, Taiwan, ROC
Change Point Determination in Audio Data Using Auditory Features
 INTL JOURNAL OF ELECTRONICS AND TELECOMMUNICATIONS, 0, VOL., NO., PP. 8 90 Manuscript received April, 0; revised June, 0. DOI: /eletel-0-00 Change Point Determination in Audio Data Using Auditory Features
INTL JOURNAL OF ELECTRONICS AND TELECOMMUNICATIONS, 0, VOL., NO., PP. 8 90 Manuscript received April, 0; revised June, 0. DOI: /eletel-0-00 Change Point Determination in Audio Data Using Auditory Features
Enhancement of Speech Signal Based on Improved Minima Controlled Recursive Averaging and Independent Component Analysis
 Enhancement of Speech Signal Based on Improved Minima Controlled Recursive Averaging and Independent Component Analysis Mohini Avatade & S.L. Sahare Electronics & Telecommunication Department, Cummins
Enhancement of Speech Signal Based on Improved Minima Controlled Recursive Averaging and Independent Component Analysis Mohini Avatade & S.L. Sahare Electronics & Telecommunication Department, Cummins
ON THE RELATIONSHIP BETWEEN INSTANTANEOUS FREQUENCY AND PITCH IN. 1 Introduction. Zied Mnasri 1, Hamid Amiri 1
 ON THE RELATIONSHIP BETWEEN INSTANTANEOUS FREQUENCY AND PITCH IN SPEECH SIGNALS Zied Mnasri 1, Hamid Amiri 1 1 Electrical engineering dept, National School of Engineering in Tunis, University Tunis El
ON THE RELATIONSHIP BETWEEN INSTANTANEOUS FREQUENCY AND PITCH IN SPEECH SIGNALS Zied Mnasri 1, Hamid Amiri 1 1 Electrical engineering dept, National School of Engineering in Tunis, University Tunis El
Single Channel Speaker Segregation using Sinusoidal Residual Modeling
 NCC 2009, January 16-18, IIT Guwahati 294 Single Channel Speaker Segregation using Sinusoidal Residual Modeling Rajesh M Hegde and A. Srinivas Dept. of Electrical Engineering Indian Institute of Technology
NCC 2009, January 16-18, IIT Guwahati 294 Single Channel Speaker Segregation using Sinusoidal Residual Modeling Rajesh M Hegde and A. Srinivas Dept. of Electrical Engineering Indian Institute of Technology
Speech Signal Analysis
 Speech Signal Analysis Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 2&3 14,18 January 216 ASR Lectures 2&3 Speech Signal Analysis 1 Overview Speech Signal Analysis for
Speech Signal Analysis Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 2&3 14,18 January 216 ASR Lectures 2&3 Speech Signal Analysis 1 Overview Speech Signal Analysis for
IDENTIFICATION OF SIGNATURES TRANSMITTED OVER RAYLEIGH FADING CHANNEL BY USING HMM AND RLE
 International Journal of Technology (2011) 1: 56 64 ISSN 2086 9614 IJTech 2011 IDENTIFICATION OF SIGNATURES TRANSMITTED OVER RAYLEIGH FADING CHANNEL BY USING HMM AND RLE Djamhari Sirat 1, Arman D. Diponegoro
International Journal of Technology (2011) 1: 56 64 ISSN 2086 9614 IJTech 2011 IDENTIFICATION OF SIGNATURES TRANSMITTED OVER RAYLEIGH FADING CHANNEL BY USING HMM AND RLE Djamhari Sirat 1, Arman D. Diponegoro
Monaural and Binaural Speech Separation
 Monaural and Binaural Speech Separation DeLiang Wang Perception & Neurodynamics Lab The Ohio State University Outline of presentation Introduction CASA approach to sound separation Ideal binary mask as
Monaural and Binaural Speech Separation DeLiang Wang Perception & Neurodynamics Lab The Ohio State University Outline of presentation Introduction CASA approach to sound separation Ideal binary mask as
Auditory Based Feature Vectors for Speech Recognition Systems
 Auditory Based Feature Vectors for Speech Recognition Systems Dr. Waleed H. Abdulla Electrical & Computer Engineering Department The University of Auckland, New Zealand [w.abdulla@auckland.ac.nz] 1 Outlines
Auditory Based Feature Vectors for Speech Recognition Systems Dr. Waleed H. Abdulla Electrical & Computer Engineering Department The University of Auckland, New Zealand [w.abdulla@auckland.ac.nz] 1 Outlines
Comparison of Spectral Analysis Methods for Automatic Speech Recognition
 INTERSPEECH 2013 Comparison of Spectral Analysis Methods for Automatic Speech Recognition Venkata Neelima Parinam, Chandra Vootkuri, Stephen A. Zahorian Department of Electrical and Computer Engineering
INTERSPEECH 2013 Comparison of Spectral Analysis Methods for Automatic Speech Recognition Venkata Neelima Parinam, Chandra Vootkuri, Stephen A. Zahorian Department of Electrical and Computer Engineering
Effects of Reverberation on Pitch, Onset/Offset, and Binaural Cues
 Effects of Reverberation on Pitch, Onset/Offset, and Binaural Cues DeLiang Wang Perception & Neurodynamics Lab The Ohio State University Outline of presentation Introduction Human performance Reverberation
Effects of Reverberation on Pitch, Onset/Offset, and Binaural Cues DeLiang Wang Perception & Neurodynamics Lab The Ohio State University Outline of presentation Introduction Human performance Reverberation
Automatic Text-Independent. Speaker. Recognition Approaches Using Binaural Inputs
 Automatic Text-Independent Speaker Recognition Approaches Using Binaural Inputs Karim Youssef, Sylvain Argentieri and Jean-Luc Zarader 1 Outline Automatic speaker recognition: introduction Designed systems
Automatic Text-Independent Speaker Recognition Approaches Using Binaural Inputs Karim Youssef, Sylvain Argentieri and Jean-Luc Zarader 1 Outline Automatic speaker recognition: introduction Designed systems
ROBUST ISOLATED SPEECH RECOGNITION USING BINARY MASKS
 ROBUST ISOLATED SPEECH RECOGNITION USING BINARY MASKS Seliz Gülsen Karado gan 1, Jan Larsen 1, Michael Syskind Pedersen 2, Jesper Bünsow Boldt 2 1) Informatics and Mathematical Modelling, Technical University
ROBUST ISOLATED SPEECH RECOGNITION USING BINARY MASKS Seliz Gülsen Karado gan 1, Jan Larsen 1, Michael Syskind Pedersen 2, Jesper Bünsow Boldt 2 1) Informatics and Mathematical Modelling, Technical University
Roberto Togneri (Signal Processing and Recognition Lab)
") Signal Processing and Machine Learning for Power Quality Disturbance Detection and Classification Roberto Togneri (Signal Processing and Recognition Lab) Power Quality (PQ) disturbances are broadly classified
Signal Processing and Machine Learning for Power Quality Disturbance Detection and Classification Roberto Togneri (Signal Processing and Recognition Lab) Power Quality (PQ) disturbances are broadly classified
Pattern Recognition. Part 6: Bandwidth Extension. Gerhard Schmidt
 Pattern Recognition Part 6: Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Institute of Electrical and Information Engineering Digital Signal Processing and System Theory
Pattern Recognition Part 6: Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Institute of Electrical and Information Engineering Digital Signal Processing and System Theory
An Automatic Audio Segmentation System for Radio Newscast. Final Project
 An Automatic Audio Segmentation System for Radio Newscast Final Project ADVISOR Professor Ignasi Esquerra STUDENT Vincenzo Dimattia March 2008 Preface The work presented in this thesis has been carried
An Automatic Audio Segmentation System for Radio Newscast Final Project ADVISOR Professor Ignasi Esquerra STUDENT Vincenzo Dimattia March 2008 Preface The work presented in this thesis has been carried
EVALUATION OF MFCC ESTIMATION TECHNIQUES FOR MUSIC SIMILARITY
 EVALUATION OF MFCC ESTIMATION TECHNIQUES FOR MUSIC SIMILARITY Jesper Højvang Jensen 1, Mads Græsbøll Christensen 1, Manohar N. Murthi, and Søren Holdt Jensen 1 1 Department of Communication Technology,
EVALUATION OF MFCC ESTIMATION TECHNIQUES FOR MUSIC SIMILARITY Jesper Højvang Jensen 1, Mads Græsbøll Christensen 1, Manohar N. Murthi, and Søren Holdt Jensen 1 1 Department of Communication Technology,
SPEECH ENHANCEMENT USING PITCH DETECTION APPROACH FOR NOISY ENVIRONMENT
 SPEECH ENHANCEMENT USING PITCH DETECTION APPROACH FOR NOISY ENVIRONMENT RASHMI MAKHIJANI Department of CSE, G. H. R.C.E., Near CRPF Campus,Hingna Road, Nagpur, Maharashtra, India rashmi.makhijani2002@gmail.com
SPEECH ENHANCEMENT USING PITCH DETECTION APPROACH FOR NOISY ENVIRONMENT RASHMI MAKHIJANI Department of CSE, G. H. R.C.E., Near CRPF Campus,Hingna Road, Nagpur, Maharashtra, India rashmi.makhijani2002@gmail.com
Perception of pitch. Definitions. Why is pitch important? BSc Audiology/MSc SHS Psychoacoustics wk 5: 12 Feb A. Faulkner.
 Perception of pitch BSc Audiology/MSc SHS Psychoacoustics wk 5: 12 Feb 2009. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence
Perception of pitch BSc Audiology/MSc SHS Psychoacoustics wk 5: 12 Feb 2009. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence
Separating Voiced Segments from Music File using MFCC, ZCR and GMM
 Separating Voiced Segments from Music File using MFCC, ZCR and GMM Mr. Prashant P. Zirmite 1, Mr. Mahesh K. Patil 2, Mr. Santosh P. Salgar 3,Mr. Veeresh M. Metigoudar 4 1,2,3,4Assistant Professor, Dept.
Separating Voiced Segments from Music File using MFCC, ZCR and GMM Mr. Prashant P. Zirmite 1, Mr. Mahesh K. Patil 2, Mr. Santosh P. Salgar 3,Mr. Veeresh M. Metigoudar 4 1,2,3,4Assistant Professor, Dept.
Signal Processing for Speech Applications - Part 2-1. Signal Processing For Speech Applications - Part 2
 Signal Processing for Speech Applications - Part 2-1 Signal Processing For Speech Applications - Part 2 May 14, 2013 Signal Processing for Speech Applications - Part 2-2 References Huang et al., Chapter
Signal Processing for Speech Applications - Part 2-1 Signal Processing For Speech Applications - Part 2 May 14, 2013 Signal Processing for Speech Applications - Part 2-2 References Huang et al., Chapter
Synchronous Overlap and Add of Spectra for Enhancement of Excitation in Artificial Bandwidth Extension of Speech
 INTERSPEECH 5 Synchronous Overlap and Add of Spectra for Enhancement of Excitation in Artificial Bandwidth Extension of Speech M. A. Tuğtekin Turan and Engin Erzin Multimedia, Vision and Graphics Laboratory,
INTERSPEECH 5 Synchronous Overlap and Add of Spectra for Enhancement of Excitation in Artificial Bandwidth Extension of Speech M. A. Tuğtekin Turan and Engin Erzin Multimedia, Vision and Graphics Laboratory,
A Parametric Model for Spectral Sound Synthesis of Musical Sounds
 A Parametric Model for Spectral Sound Synthesis of Musical Sounds Cornelia Kreutzer University of Limerick ECE Department Limerick, Ireland cornelia.kreutzer@ul.ie Jacqueline Walker University of Limerick
A Parametric Model for Spectral Sound Synthesis of Musical Sounds Cornelia Kreutzer University of Limerick ECE Department Limerick, Ireland cornelia.kreutzer@ul.ie Jacqueline Walker University of Limerick
JOURNAL OF OBJECT TECHNOLOGY
 JOURNAL OF OBJECT TECHNOLOGY Online at http://www.jot.fm. Published by ETH Zurich, Chair of Software Engineering JOT, 2009 Vol. 9, No. 1, January-February 2010 The Discrete Fourier Transform, Part 5: Spectrogram
JOURNAL OF OBJECT TECHNOLOGY Online at http://www.jot.fm. Published by ETH Zurich, Chair of Software Engineering JOT, 2009 Vol. 9, No. 1, January-February 2010 The Discrete Fourier Transform, Part 5: Spectrogram
Survey Paper on Music Beat Tracking
 Survey Paper on Music Beat Tracking Vedshree Panchwadkar, Shravani Pande, Prof.Mr.Makarand Velankar Cummins College of Engg, Pune, India vedshreepd@gmail.com, shravni.pande@gmail.com, makarand_v@rediffmail.com
Survey Paper on Music Beat Tracking Vedshree Panchwadkar, Shravani Pande, Prof.Mr.Makarand Velankar Cummins College of Engg, Pune, India vedshreepd@gmail.com, shravni.pande@gmail.com, makarand_v@rediffmail.com
Feature Analysis for Audio Classification
 Feature Analysis for Audio Classification Gaston Bengolea 1, Daniel Acevedo 1,Martín Rais 2,,andMartaMejail 1 1 Departamento de Computación, Facultad de Ciencias Exactas y Naturales, Universidad de Buenos
Feature Analysis for Audio Classification Gaston Bengolea 1, Daniel Acevedo 1,Martín Rais 2,,andMartaMejail 1 1 Departamento de Computación, Facultad de Ciencias Exactas y Naturales, Universidad de Buenos
Introducing COVAREP: A collaborative voice analysis repository for speech technologies
 Introducing COVAREP: A collaborative voice analysis repository for speech technologies John Kane Wednesday November 27th, 2013 SIGMEDIA-group TCD COVAREP - Open-source speech processing repository 1 Introduction
Introducing COVAREP: A collaborative voice analysis repository for speech technologies John Kane Wednesday November 27th, 2013 SIGMEDIA-group TCD COVAREP - Open-source speech processing repository 1 Introduction
REpeating Pattern Extraction Technique (REPET)
") REpeating Pattern Extraction Technique (REPET) EECS 32: Machine Perception of Music & Audio Zafar RAFII, Spring 22 Repetition Repetition is a fundamental element in generating and perceiving structure
REpeating Pattern Extraction Technique (REPET) EECS 32: Machine Perception of Music & Audio Zafar RAFII, Spring 22 Repetition Repetition is a fundamental element in generating and perceiving structure
Perception of pitch. Importance of pitch: 2. mother hemp horse. scold. Definitions. Why is pitch important? AUDL4007: 11 Feb A. Faulkner.
 Perception of pitch AUDL4007: 11 Feb 2010. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence Erlbaum, 2005 Chapter 7 1 Definitions
Perception of pitch AUDL4007: 11 Feb 2010. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence Erlbaum, 2005 Chapter 7 1 Definitions
Electronic disguised voice identification based on Mel- Frequency Cepstral Coefficient analysis
 International Journal of Scientific and Research Publications, Volume 5, Issue 11, November 2015 412 Electronic disguised voice identification based on Mel- Frequency Cepstral Coefficient analysis Shalate
International Journal of Scientific and Research Publications, Volume 5, Issue 11, November 2015 412 Electronic disguised voice identification based on Mel- Frequency Cepstral Coefficient analysis Shalate
Sound Synthesis Methods
 Sound Synthesis Methods Matti Vihola, mvihola@cs.tut.fi 23rd August 2001 1 Objectives The objective of sound synthesis is to create sounds that are Musically interesting Preferably realistic (sounds like
Sound Synthesis Methods Matti Vihola, mvihola@cs.tut.fi 23rd August 2001 1 Objectives The objective of sound synthesis is to create sounds that are Musically interesting Preferably realistic (sounds like
Lecture 14: Source Separation
 ELEN E896 MUSIC SIGNAL PROCESSING Lecture 1: Source Separation 1. Sources, Mixtures, & Perception. Spatial Filtering 3. Time-Frequency Masking. Model-Based Separation Dan Ellis Dept. Electrical Engineering,
ELEN E896 MUSIC SIGNAL PROCESSING Lecture 1: Source Separation 1. Sources, Mixtures, & Perception. Spatial Filtering 3. Time-Frequency Masking. Model-Based Separation Dan Ellis Dept. Electrical Engineering,
Infrasound Source Identification Based on Spectral Moment Features
 International Journal of Intelligent Information Systems 2016; 5(3): 37-41 http://www.sciencepublishinggroup.com/j/ijiis doi: 10.11648/j.ijiis.20160503.11 ISSN: 2328-7675 (Print); ISSN: 2328-7683 (Online)
International Journal of Intelligent Information Systems 2016; 5(3): 37-41 http://www.sciencepublishinggroup.com/j/ijiis doi: 10.11648/j.ijiis.20160503.11 ISSN: 2328-7675 (Print); ISSN: 2328-7683 (Online)
AN ANALYSIS OF SPEECH RECOGNITION PERFORMANCE BASED UPON NETWORK LAYERS AND TRANSFER FUNCTIONS
 AN ANALYSIS OF SPEECH RECOGNITION PERFORMANCE BASED UPON NETWORK LAYERS AND TRANSFER FUNCTIONS Kuldeep Kumar 1, R. K. Aggarwal 1 and Ankita Jain 2 1 Department of Computer Engineering, National Institute
AN ANALYSIS OF SPEECH RECOGNITION PERFORMANCE BASED UPON NETWORK LAYERS AND TRANSFER FUNCTIONS Kuldeep Kumar 1, R. K. Aggarwal 1 and Ankita Jain 2 1 Department of Computer Engineering, National Institute
Perception of pitch. Definitions. Why is pitch important? BSc Audiology/MSc SHS Psychoacoustics wk 4: 7 Feb A. Faulkner.
 Perception of pitch BSc Audiology/MSc SHS Psychoacoustics wk 4: 7 Feb 2008. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence Erlbaum,
Perception of pitch BSc Audiology/MSc SHS Psychoacoustics wk 4: 7 Feb 2008. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence Erlbaum,
University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005
 University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005 Lecture 5 Slides Jan 26 th, 2005 Outline of Today s Lecture Announcements Filter-bank analysis
University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005 Lecture 5 Slides Jan 26 th, 2005 Outline of Today s Lecture Announcements Filter-bank analysis
WIND NOISE REDUCTION USING NON-NEGATIVE SPARSE CODING
 WIND NOISE REDUCTION USING NON-NEGATIVE SPARSE CODING Mikkel N. Schmidt, Jan Larsen Technical University of Denmark Informatics and Mathematical Modelling Richard Petersens Plads, Building 31 Kgs. Lyngby
WIND NOISE REDUCTION USING NON-NEGATIVE SPARSE CODING Mikkel N. Schmidt, Jan Larsen Technical University of Denmark Informatics and Mathematical Modelling Richard Petersens Plads, Building 31 Kgs. Lyngby
SPEECH ENHANCEMENT USING A ROBUST KALMAN FILTER POST-PROCESSOR IN THE MODULATION DOMAIN. Yu Wang and Mike Brookes
 SPEECH ENHANCEMENT USING A ROBUST KALMAN FILTER POST-PROCESSOR IN THE MODULATION DOMAIN Yu Wang and Mike Brookes Department of Electrical and Electronic Engineering, Exhibition Road, Imperial College London,
SPEECH ENHANCEMENT USING A ROBUST KALMAN FILTER POST-PROCESSOR IN THE MODULATION DOMAIN Yu Wang and Mike Brookes Department of Electrical and Electronic Engineering, Exhibition Road, Imperial College London,
Evaluation of MFCC Estimation Techniques for Music Similarity Jensen, Jesper Højvang; Christensen, Mads Græsbøll; Murthi, Manohar; Jensen, Søren Holdt
 Aalborg Universitet Evaluation of MFCC Estimation Techniques for Music Similarity Jensen, Jesper Højvang; Christensen, Mads Græsbøll; Murthi, Manohar; Jensen, Søren Holdt Published in: Proceedings of the
Aalborg Universitet Evaluation of MFCC Estimation Techniques for Music Similarity Jensen, Jesper Højvang; Christensen, Mads Græsbøll; Murthi, Manohar; Jensen, Søren Holdt Published in: Proceedings of the
Multimedia Signal Processing: Theory and Applications in Speech, Music and Communications
 Brochure More information from http://www.researchandmarkets.com/reports/569388/ Multimedia Signal Processing: Theory and Applications in Speech, Music and Communications Description: Multimedia Signal
Brochure More information from http://www.researchandmarkets.com/reports/569388/ Multimedia Signal Processing: Theory and Applications in Speech, Music and Communications Description: Multimedia Signal
The psychoacoustics of reverberation
 The psychoacoustics of reverberation Steven van de Par Steven.van.de.Par@uni-oldenburg.de July 19, 2016 Thanks to Julian Grosse and Andreas Häußler 2016 AES International Conference on Sound Field Control
The psychoacoustics of reverberation Steven van de Par Steven.van.de.Par@uni-oldenburg.de July 19, 2016 Thanks to Julian Grosse and Andreas Häußler 2016 AES International Conference on Sound Field Control
Learning to Unlearn and Relearn Speech Signal Processing using Neural Networks: current and future perspectives
 Learning to Unlearn and Relearn Speech Signal Processing using Neural Networks: current and future perspectives Mathew Magimai Doss Collaborators: Vinayak Abrol, Selen Hande Kabil, Hannah Muckenhirn, Dimitri
Learning to Unlearn and Relearn Speech Signal Processing using Neural Networks: current and future perspectives Mathew Magimai Doss Collaborators: Vinayak Abrol, Selen Hande Kabil, Hannah Muckenhirn, Dimitri
Signal segmentation and waveform characterization. Biosignal processing, S Autumn 2012
 Signal segmentation and waveform characterization Biosignal processing, 5173S Autumn 01 Short-time analysis of signals Signal statistics may vary in time: nonstationary how to compute signal characterizations?
Signal segmentation and waveform characterization Biosignal processing, 5173S Autumn 01 Short-time analysis of signals Signal statistics may vary in time: nonstationary how to compute signal characterizations?
RASTA-PLP SPEECH ANALYSIS. Aruna Bayya. Phil Kohn y TR December 1991
 RASTA-PLP SPEECH ANALYSIS Hynek Hermansky Nelson Morgan y Aruna Bayya Phil Kohn y TR-91-069 December 1991 Abstract Most speech parameter estimation techniques are easily inuenced by the frequency response
RASTA-PLP SPEECH ANALYSIS Hynek Hermansky Nelson Morgan y Aruna Bayya Phil Kohn y TR-91-069 December 1991 Abstract Most speech parameter estimation techniques are easily inuenced by the frequency response
Speech/Music Discrimination via Energy Density Analysis
 Speech/Music Discrimination via Energy Density Analysis Stanis law Kacprzak and Mariusz Zió lko Department of Electronics, AGH University of Science and Technology al. Mickiewicza 30, Kraków, Poland {skacprza,
Speech/Music Discrimination via Energy Density Analysis Stanis law Kacprzak and Mariusz Zió lko Department of Electronics, AGH University of Science and Technology al. Mickiewicza 30, Kraków, Poland {skacprza,
Automatic Morse Code Recognition Under Low SNR
 2nd International Conference on Mechanical, Electronic, Control and Automation Engineering (MECAE 2018) Automatic Morse Code Recognition Under Low SNR Xianyu Wanga, Qi Zhaob, Cheng Mac, * and Jianping
2nd International Conference on Mechanical, Electronic, Control and Automation Engineering (MECAE 2018) Automatic Morse Code Recognition Under Low SNR Xianyu Wanga, Qi Zhaob, Cheng Mac, * and Jianping
Deep learning architectures for music audio classification: a personal (re)view
view") Deep learning architectures for music audio classification: a personal (re)view Jordi Pons jordipons.me @jordiponsdotme Music Technology Group Universitat Pompeu Fabra, Barcelona Acronyms MLP: multi layer
Deep learning architectures for music audio classification: a personal (re)view Jordi Pons jordipons.me @jordiponsdotme Music Technology Group Universitat Pompeu Fabra, Barcelona Acronyms MLP: multi layer
Dominant Voiced Speech Segregation Using Onset Offset Detection and IBM Based Segmentation
 Dominant Voiced Speech Segregation Using Onset Offset Detection and IBM Based Segmentation Shibani.H 1, Lekshmi M S 2 M. Tech Student, Ilahia college of Engineering and Technology, Muvattupuzha, Kerala,
Dominant Voiced Speech Segregation Using Onset Offset Detection and IBM Based Segmentation Shibani.H 1, Lekshmi M S 2 M. Tech Student, Ilahia college of Engineering and Technology, Muvattupuzha, Kerala,
Combining Pitch-Based Inference and Non-Negative Spectrogram Factorization in Separating Vocals from Polyphonic Music
 Combining Pitch-Based Inference and Non-Negative Spectrogram Factorization in Separating Vocals from Polyphonic Music Tuomas Virtanen, Annamaria Mesaros, Matti Ryynänen Department of Signal Processing,
Combining Pitch-Based Inference and Non-Negative Spectrogram Factorization in Separating Vocals from Polyphonic Music Tuomas Virtanen, Annamaria Mesaros, Matti Ryynänen Department of Signal Processing,
High-speed Noise Cancellation with Microphone Array
 Noise Cancellation a Posteriori Probability, Maximum Criteria Independent Component Analysis High-speed Noise Cancellation with Microphone Array We propose the use of a microphone array based on independent
Noise Cancellation a Posteriori Probability, Maximum Criteria Independent Component Analysis High-speed Noise Cancellation with Microphone Array We propose the use of a microphone array based on independent
SUPERVISED SIGNAL PROCESSING FOR SEPARATION AND INDEPENDENT GAIN CONTROL OF DIFFERENT PERCUSSION INSTRUMENTS USING A LIMITED NUMBER OF MICROPHONES
 SUPERVISED SIGNAL PROCESSING FOR SEPARATION AND INDEPENDENT GAIN CONTROL OF DIFFERENT PERCUSSION INSTRUMENTS USING A LIMITED NUMBER OF MICROPHONES SF Minhas A Barton P Gaydecki School of Electrical and
SUPERVISED SIGNAL PROCESSING FOR SEPARATION AND INDEPENDENT GAIN CONTROL OF DIFFERENT PERCUSSION INSTRUMENTS USING A LIMITED NUMBER OF MICROPHONES SF Minhas A Barton P Gaydecki School of Electrical and
Enhanced Waveform Interpolative Coding at 4 kbps
 Enhanced Waveform Interpolative Coding at 4 kbps Oded Gottesman, and Allen Gersho Signal Compression Lab. University of California, Santa Barbara E-mail: [oded, gersho]@scl.ece.ucsb.edu Signal Compression
Enhanced Waveform Interpolative Coding at 4 kbps Oded Gottesman, and Allen Gersho Signal Compression Lab. University of California, Santa Barbara E-mail: [oded, gersho]@scl.ece.ucsb.edu Signal Compression
Automatic classification of traffic noise
 Automatic classification of traffic noise M.A. Sobreira-Seoane, A. Rodríguez Molares and J.L. Alba Castro University of Vigo, E.T.S.I de Telecomunicación, Rúa Maxwell s/n, 36310 Vigo, Spain msobre@gts.tsc.uvigo.es
Automatic classification of traffic noise M.A. Sobreira-Seoane, A. Rodríguez Molares and J.L. Alba Castro University of Vigo, E.T.S.I de Telecomunicación, Rúa Maxwell s/n, 36310 Vigo, Spain msobre@gts.tsc.uvigo.es
Chapter 4 SPEECH ENHANCEMENT
 44 Chapter 4 SPEECH ENHANCEMENT 4.1 INTRODUCTION: Enhancement is defined as improvement in the value or Quality of something. Speech enhancement is defined as the improvement in intelligibility and/or
44 Chapter 4 SPEECH ENHANCEMENT 4.1 INTRODUCTION: Enhancement is defined as improvement in the value or Quality of something. Speech enhancement is defined as the improvement in intelligibility and/or
Improving Meetings with Microphone Array Algorithms. Ivan Tashev Microsoft Research
 Improving Meetings with Microphone Array Algorithms Ivan Tashev Microsoft Research Why microphone arrays? They ensure better sound quality: less noises and reverberation Provide speaker position using
Improving Meetings with Microphone Array Algorithms Ivan Tashev Microsoft Research Why microphone arrays? They ensure better sound quality: less noises and reverberation Provide speaker position using
Speech Enhancement in Presence of Noise using Spectral Subtraction and Wiener Filter
 Speech Enhancement in Presence of Noise using Spectral Subtraction and Wiener Filter 1 Gupteswar Sahu, 2 D. Arun Kumar, 3 M. Bala Krishna and 4 Jami Venkata Suman Assistant Professor, Department of ECE,
Speech Enhancement in Presence of Noise using Spectral Subtraction and Wiener Filter 1 Gupteswar Sahu, 2 D. Arun Kumar, 3 M. Bala Krishna and 4 Jami Venkata Suman Assistant Professor, Department of ECE,
Power Normalized Cepstral Coefficient for Speaker Diarization and Acoustic Echo Cancellation
 Power Normalized Cepstral Coefficient for Speaker Diarization and Acoustic Echo Cancellation Sherbin Kanattil Kassim P.G Scholar, Department of ECE, Engineering College, Edathala, Ernakulam, India sherbin_kassim@yahoo.co.in
Power Normalized Cepstral Coefficient for Speaker Diarization and Acoustic Echo Cancellation Sherbin Kanattil Kassim P.G Scholar, Department of ECE, Engineering College, Edathala, Ernakulam, India sherbin_kassim@yahoo.co.in
PRACTICAL IMAGE AND VIDEO PROCESSING USING MATLAB
 PRACTICAL IMAGE AND VIDEO PROCESSING USING MATLAB OGE MARQUES Florida Atlantic University *IEEE IEEE PRESS WWILEY A JOHN WILEY & SONS, INC., PUBLICATION CONTENTS LIST OF FIGURES LIST OF TABLES FOREWORD
PRACTICAL IMAGE AND VIDEO PROCESSING USING MATLAB OGE MARQUES Florida Atlantic University *IEEE IEEE PRESS WWILEY A JOHN WILEY & SONS, INC., PUBLICATION CONTENTS LIST OF FIGURES LIST OF TABLES FOREWORD