Introduction of Audio and Music
|
|
|
- Darrell Ramsey
- 5 years ago
- Views:
Transcription
1 1 Introduction of Audio and Music Wei-Ta Chu 2009/12/3
2 Outline 2 Introduction of Audio Signals Introduction of Music
3 3 Introduction of Audio Signals Wei-Ta Chu 2009/12/3 Li and Drew, Fundamentals of Multimedia, Prentice Hall, 2004
4 Sound 4 Sound is a wave phenomenon like light, but is macroscopic and involves molecules of air being compressed and expanded under the action of some physical device. Since sound is a pressure wave, it takes on continuous values, as opposed to digitized ones.
5 Digitization 5 Digitization means conversion to a stream of numbers, and preferably these numbers should be integers for efficiency. Sampling and Quantization
6 Digitization 6 The first kind of sampling, using measurements only at evenly spaced time intervals, is simply called, sampling. The rate at which it is performed is called the sampling frequency. For audio, typical sampling rates are from 8 khz (8,000 samples per second) to 48 khz. This range is determined by Nyquist theorem discussed later. Typical uniform quantization rates are 8-bit and 16-bit. 8-bit quantization divides the vertical axis into 256 levels, and 16- bit divides it into levels.
7 Sinusoids 7
8 Nyquist Theorem 8 The Nyquist theorem states how frequently we must sample in time to be able to recover the original sound. If sampling rate just equals the actual frequency, this figure shows that a false signal is detected: it is simply a constant, with zero frequency.
9 Nyquist Theorem 9 If sample at 1.5 times the actual frequency, this figure shows that we obtain an incorrect (alias) frequency that is lower than the correct one. For correct sampling we must use a sampling rate equal to at least twice the maximum frequency content in the signal. This rate is called the Nyquist rate.
10 Nyquist Theorem 10 Nyquist Theorem: The sampling rate has to be at least twice the maximum frequency content in the signal. Nyquist frequency: half of the Nyquist rate. Since it would be impossible to recover frequencies higher than Nyquist frequency, most systems have an antialiasing filter that restricts the frequency content to a range at or below Nyquist frequency.
11 Signal-to-Noise Ratio (SNR) 11 The ratio of the power of the correct signal and the noise is called the signal to noise ratio (SNR) - a measure of the quality of the signal. The SNR is usually measured in decibels (db), where 1 db is a tenth of a bel. The SNR value, in units of db, is defined in terms of base-10 logarithms of squared voltages, as follows: If the signal voltage V signal is 10 times the noise, the SNR is
12 12 Signal-to-Quantization-Noise Ratio (SQNR) Aside from any noise that may have been present in the original analog signal, there is also an additional error that results from quantization. This introduces a roundoff error. It is not really noise. Nevertheles it is caled quantization noise (or quantization error). The quality of the quantization is characterized by the Signal to Quantization Noise Ratio (SQNR).
13 13 Signal-to-Quantization-Noise Ratio (SQNR) For a quantization accuracy of N bits per sample, the range of the digital signal is -2 N-1 to 2 N-1-1. If the actual analog signal is in the range from V max to +V max, each quantization level represents a voltage of 2V max /2 N, or V N-1 max /2 Peak SQNR
14 14 Signal-to-Quantization-Noise Ratio (SQNR)
15 15 Signal-to-Quantization-Noise Ratio (SQNR) 6.02N is the worst case. If the input signal is sinusoidal, the quantization error is statistically independent, and its magnitude is uniformly distributed between 0 and half of the interval, then it can be shown that the expression for the SQNR becomes Typical digital audio sample precision is either 8 bits per sample, equivalent to about telephone quality, or 16 bits, for CD quality.
16 Linear and Nonlinear Quantization 16 Non-uniform quantization: set up more finely-spaced levels where humans hear with the most acuity. We are quantizing magnitude, or amplitude how loud the signal is. Weber s Law stated formaly says that equaly perceived differences have values proportional to absolute levels: If we can feel an increase in weight from 10 to 11 pounds, then if instead we start at 20 pounds, it would take 22 pounds for us to feel an increase in weight.
17 Linear and Nonlinear Quantization 17
18 Linear and Nonlinear Quantization 18 For steps near the low end of the signal, quantization steps are effectively more concentrated on the s axis, whereas for large values of s, one quantization step in r encompasses a wide range of s values.
19 Linear and Nonlinear Quantization 19 s p is the peak signal value and s is the current signal value
20 Linear and Nonlinear Quantization 20
21 Audio Filtering 21 Prior to sampling and AD conversion, the audio signal is also usually filtered to remove unwanted frequencies. For speech, typically from 50Hz to 10kHz is retained, and other frequencies are blocked by the use of a band-pass filter that screens out lower and higher frequencies. An audio music signal will typically contain from about 20Hz up to 20kHz.
22 Audio Quality vs. Data Rate 22 The uncompressed data rate increases as more bits are used for quantization. Stereo: double the bandwidth
23 Processing in Frequency Domain 23 It s hard to infer much from the time-domain waveform. Human hearing is based on frequency analysis. Use of frequency analysis often facilitates understanding. Part of slides are from Prof. Hsu, NTU
24 Problems in Using Fourier Transform 24 Fourier transformation contains only frequency information No Time information is retained Works fine for stationary signals Non-stationary or changing signals cause problems Fourier transformation shows frequencies occurring at all times instead of specific times
25 Short-Time Fourier Transform (STFT) 25 How can we still use FT, but handle nonstationary signals? How can we include time? Idea: Break up the signal into discrete windows Each signal within a window is a stationary signal Take FT over each part

26 STFT Example 26 Window function
27 Short-Time Fourier Analysis 27 Problem: Conventional Fourier analysis does not capture time-varying nature of audio signals Solution: Multiply signals by finite-duration window function, then compute DTFT:
28 Window Functions 28 Rectangular window: Hamming window:

29 Window Functions 29
30 30 Break Up Original Audio Signals into Frames Using Hamming Window
31 31 Introduction of Audio Features Wei-Ta Chu 2009/12/3
32 Introduction of Audio Features 32 Short-term frame level vs. long-term clip level A frame is defined as a group of neighboring samples which last about 10 to 40 ms For audio clips with sampling frequency 16kHz, how many samples are in a 20ms audio frame? Within an audio frame we can assume that the audio signal is stationary. A clip consists of a sequence of frames, and clip-level features usually characterize how frame-level features change over a clip. Y. Wang, Z. Liu, and J.-C. Huang, Multimedia content analysis using both audio and visual clues, IEEE Signal Processing Magazine, Nov., 2000, pp
33 Frames and Clips 33 Fixed length clips (1 to 2 seconds) or vary-length clips Both frames and clips may overlap with their previous ones
34 Frame-Level Features 34 Most of the frame-level features are inherited from speech signal processing. Time-domain features Frequency-domain features We use N to denote the fame length, and s n (i) to denote the ith sample in the nth audio frame.
35 Volume (Loudness, Energy) 35 Volume is a reliable indicator for silence detection, which may help to segment an audio sequence and to determine clip boundaries. It is approximated by the root mean square of the signal magnitude within each frame Volume of an audio signal depends on the gain value of the recording and digitizing devices. We may normalize the volume for a frame by the maximum volume of some previous frames.
36 Zero Crossing Rate 36 Count the number of times that the audio waveform crosses the zero axis. ZCR = the number of zero crossings per second ZCR is one of the most indicative and robust measures to discern unvoiced speech. Typically, unvoiced speech has a low volume but a high ZCR. Using ZCR and volume together, one can prevent low energy unvoiced speech frames from being classified as silent.
37 Pitch 37 Pitch is the fundamental frequency ( 基頻 ) of an audio waveform. Normally only voiced speech and harmonic ( 泛音 ) music have well-defined pitch. Temporal estimation methods rely on computation of the short time autocorrelation function or AMDF AMDF: average magnitude difference function

38 Pitch 38 Valleys exist in voiced and music frames and vanish in noise and unvoiced frames.
39 Spectral Features 39 Spectrum: the Fourier transform of the samples in this frames The difference among these three clips is more noticeable in the frequency domain than in the waveform domain Spectrogram
40 Spectral Features 40 Let denote the power spectrum (i.e. magnitude square of the spectrum) of frame n. If we think of as a random variable and normalized by the total power as the probability density function of, we can define mean and standard deviation of. Frequency centroid, brightness Bandwidth
41 Subband Energy Ratio 41 The ratio of the energy in a frequency subband to the total energy When the sampling rate is Hz, the frequency ranges for the four subbands are Hz, Hz, Hz, and Hz. Z. Liu, Y. Wang, and T. Chen, Audio feature extraction and analysis for scene segmentation and clasification, Journal of VLSI Signal Processing, vol. 20, 1998, pp
42 Spectral Flux 42 Spectrum flux (SF) is defined as the average variation value of spectrum between the adjacent two frames. The SF values of speech are higher than those of music. The environment sound is among the highest and changes more dramatically than the other two types of signal. L. Lu, H.-J. Zhang, H. Jiang, Content analysis for audio clasification and segmentation, IEEE Trans. on Speech and Audio Processing, vol. 10, no. 7, 2002, pp
43 Spectral Rolloff 43 The 95th percentile of the power spectral distribution. This measure distinguishes voiced from unvoiced speech. The value is higher for right-skewed distributions. Unvoiced speech has a high proportion of energy contained in the high-frequency range of the spectrum This is a measure of the skewness of the spectral shape E. Scheirerand M. Slaney, Construction and evaluation of a robust multifeaturesspeech/music discriminator, Proc. of ICASSP, vol. 2, 1997, pp
44 44 MFCC (Mel-Frequency Cepstral Coefficients) The most popular features in speech/audio/music processing. Segment incoming waveform into frames Compute frequency response for each frame using DFTs Group magnitude of frequency response into channels using triangular weighting functions Compute log of weighted magnitudes for each channel Take inverse DCT/DFT of weighted magnitudes for each channel, producing ~14 cepstral coefficients for each frame Par of slides are from Prof. Hsu, NTU

45 The Mel Weighting Functions 45 Human pitch perception is most accurate between 100Hz and 1000Hz. Linear in this range Logarithmic above 1000Hz A mel is a unit of pitch defined so that pairs of sounds which are perceptually equidistant in pitch are separated by an equal number of mels
46 Clip-Level Features 46 To extract the semantic content, we need to observe the temporal variation of frame features on a longer time scale. Volume-based features: VSTD (volume standard deviation) VDR (volume dynamic range) Percentage of low-energy frames: proportion of frames with rms volume less than 50% of the mean volume within one clip NSR (nonsilence ratio): the ratio of the number of nonsilent frames
47 Clip-Level Features 47 ZCR-based features: With a speech signal, low and high ZCR periods interlaced. ZSTD (standard deviation of ZCR) Standard deviation of first order difference Third central moment about the mean Total number of zero crossing exceeding a threshold Difference between the number of zero crossings above and below the mean values J. Saunders, Real-time discrimination of broadcast speech/music, Proc. of ICASSP, vol. 2, 1996, pp
48 Clip-Level Features 48 Pitch-based features: PSTD (standard deviation of pitch) SPR (smooth pitch ratio): the percentage of frames in a clip that have similar pitch as the previous frames Measure the percentage of voiced or music frames within a clip NPR (nonpitch ratio): percentage of frames without pitch. Measure how many frames are unvoiced speech or noise within a clip
49 49 Audio Segmentation and Classification Wei-Ta Chu 2009/12/3 T. Zhang and C.-C. J. Kuo, Audio content analysis for online audiovisual data segmentation and clasification, IEEE Trans. on Speech and Audio Procesing, vol. 9, no. 4, 2001, pp
50 Overview 50
51 Characteristics Taking into account hybrid types of sound which contain more than one kind of audio component. 2. Put more emphasis on the distinction of environmental sounds Essential in many applications such as the post-processing of films 3. Integrated features are exploited for audio classification 4. Low complexity 5. The proposed method is generic and model-free. Used as the tool for segmentation and indexing of radio and TV programs
52 Features ZCR 52
53 Features Fundamental Frequency 53 Distinguish between harmonic from nonharmonic sounds. Sounds from most musical instruments are harmonic. Speech signal is a harmonic and nonharmonic mixed sound. Most environmental sounds are nonharmonic.
54 Features Fundamental Frequency 54 All maxima in the spectrum are detected as potential harmonic peaks. Check among locations of peaks whether they have sharpness, amplitude, and width values satisfying certain criteria. If all conditions are met, the SFuF (short-time fundamental frequency) value is estimated as the frequency corresponding to the greatest common divider of locations of harmonic peaks; otherwise, SFuF is set to zero.
55 Features Fundamental Frequency 55
56 Audio Segmentation 56 Two adjoining sliding windows installed with the average feature value computed within each window
57 Audio Segmentation 57
58 Audio Classification Detecting silence: If the short-time energy is continuously lower than a threshold, or if most short-time average ZCR is lower than a threshold 2. Separating sounds with/without music components By detecting continuous and stable frequency peaks from the power spectrum Based on a threshold for the zero ratio at about 0.7 > 0.7: pure speech or nonharmonic environmental sound <0.7: otherwise
59 Audio Classification Detecting harmonic environmental sounds: If the fundamental frequency of a sound clip changes over time but only with several values 4. Distinguishing pure music Based on statistical analysis of the ZCR and SFuF curves Degree of being harmonic, degree of fundamental frequency s concentration on certain values during a period of time, the variance of the average zerocrossing rate, and range of amplitude of the average zero-crossing rate
60 Audio Classification Distinguishing songs 6. Separating speech/environmental sound with music background 7. Distinguish pure speech 8. Classifying Nonharmonic environmental sounds
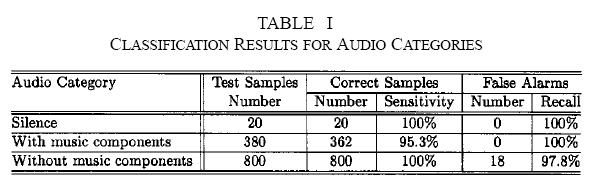
61 Evaluation 61
62 References 62 Y. Wang, Z. Liu, and J.-C. Huang, Multimedia content analysis using both audio and visual clues, IEEE Signal Processing Magazine, Nov., 2000, pp (must read) Z. Liu, Y. Wang, and T. Chen, Audio feature extraction and analysis for scene segmentation and clasification, Journal of VLSI Signal Processing, vol. 20, 1998, pp T. Zhang and C.-C. J. Kuo, Audio content analysis for online audiovisual data segmentation and clasification, IEEE Trans. on Speech and Audio Processing, vol. 9, no. 4, 2001, pp
63 Next Week 63 Project proposal
Digital Audio. Lecture-6
 Digital Audio Lecture-6 Topics today Digitization of sound PCM Lossless predictive coding 2 Sound Sound is a pressure wave, taking continuous values Increase / decrease in pressure can be measured in amplitude,
Digital Audio Lecture-6 Topics today Digitization of sound PCM Lossless predictive coding 2 Sound Sound is a pressure wave, taking continuous values Increase / decrease in pressure can be measured in amplitude,
Chapter 2: Digitization of Sound
 Chapter 2: Digitization of Sound Acoustics pressure waves are converted to electrical signals by use of a microphone. The output signal from the microphone is an analog signal, i.e., a continuous-valued
Chapter 2: Digitization of Sound Acoustics pressure waves are converted to electrical signals by use of a microphone. The output signal from the microphone is an analog signal, i.e., a continuous-valued
Signal segmentation and waveform characterization. Biosignal processing, S Autumn 2012
 Signal segmentation and waveform characterization Biosignal processing, 5173S Autumn 01 Short-time analysis of signals Signal statistics may vary in time: nonstationary how to compute signal characterizations?
Signal segmentation and waveform characterization Biosignal processing, 5173S Autumn 01 Short-time analysis of signals Signal statistics may vary in time: nonstationary how to compute signal characterizations?
Speech/Music Discrimination via Energy Density Analysis
 Speech/Music Discrimination via Energy Density Analysis Stanis law Kacprzak and Mariusz Zió lko Department of Electronics, AGH University of Science and Technology al. Mickiewicza 30, Kraków, Poland {skacprza,
Speech/Music Discrimination via Energy Density Analysis Stanis law Kacprzak and Mariusz Zió lko Department of Electronics, AGH University of Science and Technology al. Mickiewicza 30, Kraków, Poland {skacprza,
speech signal S(n). This involves a transformation of S(n) into another signal or a set of signals
. This involves a transformation of S(n) into another signal or a set of signals") 16 3. SPEECH ANALYSIS 3.1 INTRODUCTION TO SPEECH ANALYSIS Many speech processing [22] applications exploits speech production and perception to accomplish speech analysis. By speech analysis we extract
16 3. SPEECH ANALYSIS 3.1 INTRODUCTION TO SPEECH ANALYSIS Many speech processing [22] applications exploits speech production and perception to accomplish speech analysis. By speech analysis we extract
Rhythmic Similarity -- a quick paper review. Presented by: Shi Yong March 15, 2007 Music Technology, McGill University
 Rhythmic Similarity -- a quick paper review Presented by: Shi Yong March 15, 2007 Music Technology, McGill University Contents Introduction Three examples J. Foote 2001, 2002 J. Paulus 2002 S. Dixon 2004
Rhythmic Similarity -- a quick paper review Presented by: Shi Yong March 15, 2007 Music Technology, McGill University Contents Introduction Three examples J. Foote 2001, 2002 J. Paulus 2002 S. Dixon 2004
Topic. Spectrogram Chromagram Cesptrogram. Bryan Pardo, 2008, Northwestern University EECS 352: Machine Perception of Music and Audio
 Topic Spectrogram Chromagram Cesptrogram Short time Fourier Transform Break signal into windows Calculate DFT of each window The Spectrogram spectrogram(y,1024,512,1024,fs,'yaxis'); A series of short term
Topic Spectrogram Chromagram Cesptrogram Short time Fourier Transform Break signal into windows Calculate DFT of each window The Spectrogram spectrogram(y,1024,512,1024,fs,'yaxis'); A series of short term
ECE 556 BASICS OF DIGITAL SPEECH PROCESSING. Assıst.Prof.Dr. Selma ÖZAYDIN Spring Term-2017 Lecture 2
 ECE 556 BASICS OF DIGITAL SPEECH PROCESSING Assıst.Prof.Dr. Selma ÖZAYDIN Spring Term-2017 Lecture 2 Analog Sound to Digital Sound Characteristics of Sound Amplitude Wavelength (w) Frequency ( ) Timbre
ECE 556 BASICS OF DIGITAL SPEECH PROCESSING Assıst.Prof.Dr. Selma ÖZAYDIN Spring Term-2017 Lecture 2 Analog Sound to Digital Sound Characteristics of Sound Amplitude Wavelength (w) Frequency ( ) Timbre
Signal Processing for Speech Applications - Part 2-1. Signal Processing For Speech Applications - Part 2
 Signal Processing for Speech Applications - Part 2-1 Signal Processing For Speech Applications - Part 2 May 14, 2013 Signal Processing for Speech Applications - Part 2-2 References Huang et al., Chapter
Signal Processing for Speech Applications - Part 2-1 Signal Processing For Speech Applications - Part 2 May 14, 2013 Signal Processing for Speech Applications - Part 2-2 References Huang et al., Chapter
EE 464 Short-Time Fourier Transform Fall and Spectrogram. Many signals of importance have spectral content that
 EE 464 Short-Time Fourier Transform Fall 2018 Read Text, Chapter 4.9. and Spectrogram Many signals of importance have spectral content that changes with time. Let xx(nn), nn = 0, 1,, NN 1 1 be a discrete-time
EE 464 Short-Time Fourier Transform Fall 2018 Read Text, Chapter 4.9. and Spectrogram Many signals of importance have spectral content that changes with time. Let xx(nn), nn = 0, 1,, NN 1 1 be a discrete-time
Heuristic Approach for Generic Audio Data Segmentation and Annotation
 Heuristic Approach for Generic Audio Data Segmentation and Annotation Tong Zhang and C.-C. Jay Kuo Integrated Media Systems Center and Department of Electrical Engineering-Systems University of Southern
Heuristic Approach for Generic Audio Data Segmentation and Annotation Tong Zhang and C.-C. Jay Kuo Integrated Media Systems Center and Department of Electrical Engineering-Systems University of Southern
Mel Spectrum Analysis of Speech Recognition using Single Microphone
 International Journal of Engineering Research in Electronics and Communication Mel Spectrum Analysis of Speech Recognition using Single Microphone [1] Lakshmi S.A, [2] Cholavendan M [1] PG Scholar, Sree
International Journal of Engineering Research in Electronics and Communication Mel Spectrum Analysis of Speech Recognition using Single Microphone [1] Lakshmi S.A, [2] Cholavendan M [1] PG Scholar, Sree
Music 270a: Fundamentals of Digital Audio and Discrete-Time Signals
 Music 270a: Fundamentals of Digital Audio and Discrete-Time Signals Tamara Smyth, trsmyth@ucsd.edu Department of Music, University of California, San Diego October 3, 2016 1 Continuous vs. Discrete signals
Music 270a: Fundamentals of Digital Audio and Discrete-Time Signals Tamara Smyth, trsmyth@ucsd.edu Department of Music, University of California, San Diego October 3, 2016 1 Continuous vs. Discrete signals
International Journal of Modern Trends in Engineering and Research e-issn No.: , Date: 2-4 July, 2015
 International Journal of Modern Trends in Engineering and Research www.ijmter.com e-issn No.:2349-9745, Date: 2-4 July, 2015 Analysis of Speech Signal Using Graphic User Interface Solly Joy 1, Savitha
International Journal of Modern Trends in Engineering and Research www.ijmter.com e-issn No.:2349-9745, Date: 2-4 July, 2015 Analysis of Speech Signal Using Graphic User Interface Solly Joy 1, Savitha
8.3 Basic Parameters for Audio
 8.3 Basic Parameters for Audio Analysis Physical audio signal: simple one-dimensional amplitude = loudness frequency = pitch Psycho-acoustic features: complex A real-life tone arises from a complex superposition
8.3 Basic Parameters for Audio Analysis Physical audio signal: simple one-dimensional amplitude = loudness frequency = pitch Psycho-acoustic features: complex A real-life tone arises from a complex superposition
Measuring the complexity of sound
 PRAMANA c Indian Academy of Sciences Vol. 77, No. 5 journal of November 2011 physics pp. 811 816 Measuring the complexity of sound NANDINI CHATTERJEE SINGH National Brain Research Centre, NH-8, Nainwal
PRAMANA c Indian Academy of Sciences Vol. 77, No. 5 journal of November 2011 physics pp. 811 816 Measuring the complexity of sound NANDINI CHATTERJEE SINGH National Brain Research Centre, NH-8, Nainwal
A multi-class method for detecting audio events in news broadcasts
 A multi-class method for detecting audio events in news broadcasts Sergios Petridis, Theodoros Giannakopoulos, and Stavros Perantonis Computational Intelligence Laboratory, Institute of Informatics and
A multi-class method for detecting audio events in news broadcasts Sergios Petridis, Theodoros Giannakopoulos, and Stavros Perantonis Computational Intelligence Laboratory, Institute of Informatics and
Speech Synthesis using Mel-Cepstral Coefficient Feature
 Speech Synthesis using Mel-Cepstral Coefficient Feature By Lu Wang Senior Thesis in Electrical Engineering University of Illinois at Urbana-Champaign Advisor: Professor Mark Hasegawa-Johnson May 2018 Abstract
Speech Synthesis using Mel-Cepstral Coefficient Feature By Lu Wang Senior Thesis in Electrical Engineering University of Illinois at Urbana-Champaign Advisor: Professor Mark Hasegawa-Johnson May 2018 Abstract
Speech Enhancement Using Spectral Flatness Measure Based Spectral Subtraction
 IOSR Journal of VLSI and Signal Processing (IOSR-JVSP) Volume 7, Issue, Ver. I (Mar. - Apr. 7), PP 4-46 e-issn: 9 4, p-issn No. : 9 497 www.iosrjournals.org Speech Enhancement Using Spectral Flatness Measure
IOSR Journal of VLSI and Signal Processing (IOSR-JVSP) Volume 7, Issue, Ver. I (Mar. - Apr. 7), PP 4-46 e-issn: 9 4, p-issn No. : 9 497 www.iosrjournals.org Speech Enhancement Using Spectral Flatness Measure
Topic 2. Signal Processing Review. (Some slides are adapted from Bryan Pardo s course slides on Machine Perception of Music)
") Topic 2 Signal Processing Review (Some slides are adapted from Bryan Pardo s course slides on Machine Perception of Music) Recording Sound Mechanical Vibration Pressure Waves Motion->Voltage Transducer
Topic 2 Signal Processing Review (Some slides are adapted from Bryan Pardo s course slides on Machine Perception of Music) Recording Sound Mechanical Vibration Pressure Waves Motion->Voltage Transducer
Short Time Energy Amplitude. Audio Waveform Amplitude. 2 x x Time Index
 Content-Based Classication and Retrieval of Audio Tong Zhang and C.-C. Jay Kuo Integrated Media Systems Center and Department of Electrical Engineering-Systems University of Southern California, Los Angeles,
Content-Based Classication and Retrieval of Audio Tong Zhang and C.-C. Jay Kuo Integrated Media Systems Center and Department of Electrical Engineering-Systems University of Southern California, Los Angeles,
!"!#"#$% Lecture 2: Media Creation. Some materials taken from Prof. Yao Wang s slides RECAP
 Lecture 2: Media Creation Some materials taken from Prof. Yao Wang s slides RECAP #% A Big Umbrella Content Creation: produce the media, compress it to a format that is portable/ deliverable Distribution:
Lecture 2: Media Creation Some materials taken from Prof. Yao Wang s slides RECAP #% A Big Umbrella Content Creation: produce the media, compress it to a format that is portable/ deliverable Distribution:
Structure of Speech. Physical acoustics Time-domain representation Frequency domain representation Sound shaping
 Structure of Speech Physical acoustics Time-domain representation Frequency domain representation Sound shaping Speech acoustics Source-Filter Theory Speech Source characteristics Speech Filter characteristics
Structure of Speech Physical acoustics Time-domain representation Frequency domain representation Sound shaping Speech acoustics Source-Filter Theory Speech Source characteristics Speech Filter characteristics
Reduction of Musical Residual Noise Using Harmonic- Adapted-Median Filter
 Reduction of Musical Residual Noise Using Harmonic- Adapted-Median Filter Ching-Ta Lu, Kun-Fu Tseng 2, Chih-Tsung Chen 2 Department of Information Communication, Asia University, Taichung, Taiwan, ROC
Reduction of Musical Residual Noise Using Harmonic- Adapted-Median Filter Ching-Ta Lu, Kun-Fu Tseng 2, Chih-Tsung Chen 2 Department of Information Communication, Asia University, Taichung, Taiwan, ROC
Advanced Digital Signal Processing Part 2: Digital Processing of Continuous-Time Signals
 Advanced Digital Signal Processing Part 2: Digital Processing of Continuous-Time Signals Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Institute of Electrical Engineering
Advanced Digital Signal Processing Part 2: Digital Processing of Continuous-Time Signals Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Institute of Electrical Engineering
Fundamentals of Digital Audio *
 Digital Media The material in this handout is excerpted from Digital Media Curriculum Primer a work written by Dr. Yue-Ling Wong (ylwong@wfu.edu), Department of Computer Science and Department of Art,
Digital Media The material in this handout is excerpted from Digital Media Curriculum Primer a work written by Dr. Yue-Ling Wong (ylwong@wfu.edu), Department of Computer Science and Department of Art,
Performance Analysis of MFCC and LPCC Techniques in Automatic Speech Recognition
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume - 3 Issue - 8 August, 2014 Page No. 7727-7732 Performance Analysis of MFCC and LPCC Techniques in Automatic
www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume - 3 Issue - 8 August, 2014 Page No. 7727-7732 Performance Analysis of MFCC and LPCC Techniques in Automatic
Lecture 7 Frequency Modulation
 Lecture 7 Frequency Modulation Fundamentals of Digital Signal Processing Spring, 2012 Wei-Ta Chu 2012/3/15 1 Time-Frequency Spectrum We have seen that a wide range of interesting waveforms can be synthesized
Lecture 7 Frequency Modulation Fundamentals of Digital Signal Processing Spring, 2012 Wei-Ta Chu 2012/3/15 1 Time-Frequency Spectrum We have seen that a wide range of interesting waveforms can be synthesized
Time division multiplexing The block diagram for TDM is illustrated as shown in the figure
 CHAPTER 2 Syllabus: 1) Pulse amplitude modulation 2) TDM 3) Wave form coding techniques 4) PCM 5) Quantization noise and SNR 6) Robust quantization Pulse amplitude modulation In pulse amplitude modulation,
CHAPTER 2 Syllabus: 1) Pulse amplitude modulation 2) TDM 3) Wave form coding techniques 4) PCM 5) Quantization noise and SNR 6) Robust quantization Pulse amplitude modulation In pulse amplitude modulation,
Robust Voice Activity Detection Based on Discrete Wavelet. Transform
 Robust Voice Activity Detection Based on Discrete Wavelet Transform Kun-Ching Wang Department of Information Technology & Communication Shin Chien University kunching@mail.kh.usc.edu.tw Abstract This paper
Robust Voice Activity Detection Based on Discrete Wavelet Transform Kun-Ching Wang Department of Information Technology & Communication Shin Chien University kunching@mail.kh.usc.edu.tw Abstract This paper
CHAPTER 4. PULSE MODULATION Part 2
 CHAPTER 4 PULSE MODULATION Part 2 Pulse Modulation Analog pulse modulation: Sampling, i.e., information is transmitted only at discrete time instants. e.g. PAM, PPM and PDM Digital pulse modulation: Sampling
CHAPTER 4 PULSE MODULATION Part 2 Pulse Modulation Analog pulse modulation: Sampling, i.e., information is transmitted only at discrete time instants. e.g. PAM, PPM and PDM Digital pulse modulation: Sampling
Chapter 4. Digital Audio Representation CS 3570
 Chapter 4. Digital Audio Representation CS 3570 1 Objectives Be able to apply the Nyquist theorem to understand digital audio aliasing. Understand how dithering and noise shaping are done. Understand the
Chapter 4. Digital Audio Representation CS 3570 1 Objectives Be able to apply the Nyquist theorem to understand digital audio aliasing. Understand how dithering and noise shaping are done. Understand the
Speech Enhancement Based On Spectral Subtraction For Speech Recognition System With Dpcm
 International OPEN ACCESS Journal Of Modern Engineering Research (IJMER) Speech Enhancement Based On Spectral Subtraction For Speech Recognition System With Dpcm A.T. Rajamanickam, N.P.Subiramaniyam, A.Balamurugan*,
International OPEN ACCESS Journal Of Modern Engineering Research (IJMER) Speech Enhancement Based On Spectral Subtraction For Speech Recognition System With Dpcm A.T. Rajamanickam, N.P.Subiramaniyam, A.Balamurugan*,
SAMPLING THEORY. Representing continuous signals with discrete numbers
 SAMPLING THEORY Representing continuous signals with discrete numbers Roger B. Dannenberg Professor of Computer Science, Art, and Music Carnegie Mellon University ICM Week 3 Copyright 2002-2013 by Roger
SAMPLING THEORY Representing continuous signals with discrete numbers Roger B. Dannenberg Professor of Computer Science, Art, and Music Carnegie Mellon University ICM Week 3 Copyright 2002-2013 by Roger
Continuous vs. Discrete signals. Sampling. Analog to Digital Conversion. CMPT 368: Lecture 4 Fundamentals of Digital Audio, Discrete-Time Signals
 Continuous vs. Discrete signals CMPT 368: Lecture 4 Fundamentals of Digital Audio, Discrete-Time Signals Tamara Smyth, tamaras@cs.sfu.ca School of Computing Science, Simon Fraser University January 22,
Continuous vs. Discrete signals CMPT 368: Lecture 4 Fundamentals of Digital Audio, Discrete-Time Signals Tamara Smyth, tamaras@cs.sfu.ca School of Computing Science, Simon Fraser University January 22,
Sound is the human ear s perceived effect of pressure changes in the ambient air. Sound can be modeled as a function of time.
 2. Physical sound 2.1 What is sound? Sound is the human ear s perceived effect of pressure changes in the ambient air. Sound can be modeled as a function of time. Figure 2.1: A 0.56-second audio clip of
2. Physical sound 2.1 What is sound? Sound is the human ear s perceived effect of pressure changes in the ambient air. Sound can be modeled as a function of time. Figure 2.1: A 0.56-second audio clip of
Preeti Rao 2 nd CompMusicWorkshop, Istanbul 2012
 Preeti Rao 2 nd CompMusicWorkshop, Istanbul 2012 o Music signal characteristics o Perceptual attributes and acoustic properties o Signal representations for pitch detection o STFT o Sinusoidal model o
Preeti Rao 2 nd CompMusicWorkshop, Istanbul 2012 o Music signal characteristics o Perceptual attributes and acoustic properties o Signal representations for pitch detection o STFT o Sinusoidal model o
Audio Fingerprinting using Fractional Fourier Transform
 Audio Fingerprinting using Fractional Fourier Transform Swati V. Sutar 1, D. G. Bhalke 2 1 (Department of Electronics & Telecommunication, JSPM s RSCOE college of Engineering Pune, India) 2 (Department,
Audio Fingerprinting using Fractional Fourier Transform Swati V. Sutar 1, D. G. Bhalke 2 1 (Department of Electronics & Telecommunication, JSPM s RSCOE college of Engineering Pune, India) 2 (Department,
ON THE VALIDITY OF THE NOISE MODEL OF QUANTIZATION FOR THE FREQUENCY-DOMAIN AMPLITUDE ESTIMATION OF LOW-LEVEL SINE WAVES
 Metrol. Meas. Syst., Vol. XXII (215), No. 1, pp. 89 1. METROLOGY AND MEASUREMENT SYSTEMS Index 3393, ISSN 86-8229 www.metrology.pg.gda.pl ON THE VALIDITY OF THE NOISE MODEL OF QUANTIZATION FOR THE FREQUENCY-DOMAIN
Metrol. Meas. Syst., Vol. XXII (215), No. 1, pp. 89 1. METROLOGY AND MEASUREMENT SYSTEMS Index 3393, ISSN 86-8229 www.metrology.pg.gda.pl ON THE VALIDITY OF THE NOISE MODEL OF QUANTIZATION FOR THE FREQUENCY-DOMAIN
Speech Signal Analysis
 Speech Signal Analysis Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 2&3 14,18 January 216 ASR Lectures 2&3 Speech Signal Analysis 1 Overview Speech Signal Analysis for
Speech Signal Analysis Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 2&3 14,18 January 216 ASR Lectures 2&3 Speech Signal Analysis 1 Overview Speech Signal Analysis for
A CONSTRUCTION OF COMPACT MFCC-TYPE FEATURES USING SHORT-TIME STATISTICS FOR APPLICATIONS IN AUDIO SEGMENTATION
 17th European Signal Processing Conference (EUSIPCO 2009) Glasgow, Scotland, August 24-28, 2009 A CONSTRUCTION OF COMPACT MFCC-TYPE FEATURES USING SHORT-TIME STATISTICS FOR APPLICATIONS IN AUDIO SEGMENTATION
17th European Signal Processing Conference (EUSIPCO 2009) Glasgow, Scotland, August 24-28, 2009 A CONSTRUCTION OF COMPACT MFCC-TYPE FEATURES USING SHORT-TIME STATISTICS FOR APPLICATIONS IN AUDIO SEGMENTATION
Signals A Preliminary Discussion EE442 Analog & Digital Communication Systems Lecture 2
 Signals A Preliminary Discussion EE442 Analog & Digital Communication Systems Lecture 2 The Fourier transform of single pulse is the sinc function. EE 442 Signal Preliminaries 1 Communication Systems and
Signals A Preliminary Discussion EE442 Analog & Digital Communication Systems Lecture 2 The Fourier transform of single pulse is the sinc function. EE 442 Signal Preliminaries 1 Communication Systems and
Introduction to Digital Signal Processing (Discrete-time Signal Processing)
") Introduction to Digital Signal Processing (Discrete-time Signal Processing) Prof. Chu-Song Chen Research Center for Info. Tech. Innovation, Academia Sinica, Taiwan Dept. CSIE & GINM National Taiwan University
Introduction to Digital Signal Processing (Discrete-time Signal Processing) Prof. Chu-Song Chen Research Center for Info. Tech. Innovation, Academia Sinica, Taiwan Dept. CSIE & GINM National Taiwan University
CO-CHANNEL SPEECH DETECTION APPROACHES USING CYCLOSTATIONARITY OR WAVELET TRANSFORM
 CO-CHANNEL SPEECH DETECTION APPROACHES USING CYCLOSTATIONARITY OR WAVELET TRANSFORM Arvind Raman Kizhanatham, Nishant Chandra, Robert E. Yantorno Temple University/ECE Dept. 2 th & Norris Streets, Philadelphia,
CO-CHANNEL SPEECH DETECTION APPROACHES USING CYCLOSTATIONARITY OR WAVELET TRANSFORM Arvind Raman Kizhanatham, Nishant Chandra, Robert E. Yantorno Temple University/ECE Dept. 2 th & Norris Streets, Philadelphia,
CMPT 318: Lecture 4 Fundamentals of Digital Audio, Discrete-Time Signals
 CMPT 318: Lecture 4 Fundamentals of Digital Audio, Discrete-Time Signals Tamara Smyth, tamaras@cs.sfu.ca School of Computing Science, Simon Fraser University January 16, 2006 1 Continuous vs. Discrete
CMPT 318: Lecture 4 Fundamentals of Digital Audio, Discrete-Time Signals Tamara Smyth, tamaras@cs.sfu.ca School of Computing Science, Simon Fraser University January 16, 2006 1 Continuous vs. Discrete
Speech/Music Change Point Detection using Sonogram and AANN
 International Journal of Information & Computation Technology. ISSN 0974-2239 Volume 6, Number 1 (2016), pp. 45-49 International Research Publications House http://www. irphouse.com Speech/Music Change
International Journal of Information & Computation Technology. ISSN 0974-2239 Volume 6, Number 1 (2016), pp. 45-49 International Research Publications House http://www. irphouse.com Speech/Music Change
Feature Analysis for Audio Classification
 Feature Analysis for Audio Classification Gaston Bengolea 1, Daniel Acevedo 1,Martín Rais 2,,andMartaMejail 1 1 Departamento de Computación, Facultad de Ciencias Exactas y Naturales, Universidad de Buenos
Feature Analysis for Audio Classification Gaston Bengolea 1, Daniel Acevedo 1,Martín Rais 2,,andMartaMejail 1 1 Departamento de Computación, Facultad de Ciencias Exactas y Naturales, Universidad de Buenos
New Features of IEEE Std Digitizing Waveform Recorders
 New Features of IEEE Std 1057-2007 Digitizing Waveform Recorders William B. Boyer 1, Thomas E. Linnenbrink 2, Jerome Blair 3, 1 Chair, Subcommittee on Digital Waveform Recorders Sandia National Laboratories
New Features of IEEE Std 1057-2007 Digitizing Waveform Recorders William B. Boyer 1, Thomas E. Linnenbrink 2, Jerome Blair 3, 1 Chair, Subcommittee on Digital Waveform Recorders Sandia National Laboratories
Signal processing preliminaries
 Signal processing preliminaries ISMIR Graduate School, October 4th-9th, 2004 Contents: Digital audio signals Fourier transform Spectrum estimation Filters Signal Proc. 2 1 Digital signals Advantages of
Signal processing preliminaries ISMIR Graduate School, October 4th-9th, 2004 Contents: Digital audio signals Fourier transform Spectrum estimation Filters Signal Proc. 2 1 Digital signals Advantages of
Chapter 4 SPEECH ENHANCEMENT
 44 Chapter 4 SPEECH ENHANCEMENT 4.1 INTRODUCTION: Enhancement is defined as improvement in the value or Quality of something. Speech enhancement is defined as the improvement in intelligibility and/or
44 Chapter 4 SPEECH ENHANCEMENT 4.1 INTRODUCTION: Enhancement is defined as improvement in the value or Quality of something. Speech enhancement is defined as the improvement in intelligibility and/or
Outline. Communications Engineering 1
 Outline Introduction Signal, random variable, random process and spectra Analog modulation Analog to digital conversion Digital transmission through baseband channels Signal space representation Optimal
Outline Introduction Signal, random variable, random process and spectra Analog modulation Analog to digital conversion Digital transmission through baseband channels Signal space representation Optimal
Communications I (ELCN 306)
") Communications I (ELCN 306) c Samy S. Soliman Electronics and Electrical Communications Engineering Department Cairo University, Egypt Email: samy.soliman@cu.edu.eg Website: http://scholar.cu.edu.eg/samysoliman
Communications I (ELCN 306) c Samy S. Soliman Electronics and Electrical Communications Engineering Department Cairo University, Egypt Email: samy.soliman@cu.edu.eg Website: http://scholar.cu.edu.eg/samysoliman
Signal Processing for Digitizers
 Signal Processing for Digitizers Modular digitizers allow accurate, high resolution data acquisition that can be quickly transferred to a host computer. Signal processing functions, applied in the digitizer
Signal Processing for Digitizers Modular digitizers allow accurate, high resolution data acquisition that can be quickly transferred to a host computer. Signal processing functions, applied in the digitizer
(i) Understanding the basic concepts of signal modeling, correlation, maximum likelihood estimation, least squares and iterative numerical methods
 Understanding the basic concepts of signal modeling, correlation, maximum likelihood estimation, least squares and iterative numerical methods") Tools and Applications Chapter Intended Learning Outcomes: (i) Understanding the basic concepts of signal modeling, correlation, maximum likelihood estimation, least squares and iterative numerical methods
Tools and Applications Chapter Intended Learning Outcomes: (i) Understanding the basic concepts of signal modeling, correlation, maximum likelihood estimation, least squares and iterative numerical methods
Lecture Schedule: Week Date Lecture Title
 http://elec3004.org Sampling & More 2014 School of Information Technology and Electrical Engineering at The University of Queensland Lecture Schedule: Week Date Lecture Title 1 2-Mar Introduction 3-Mar
http://elec3004.org Sampling & More 2014 School of Information Technology and Electrical Engineering at The University of Queensland Lecture Schedule: Week Date Lecture Title 1 2-Mar Introduction 3-Mar
EXPERIMENTAL INVESTIGATION INTO THE OPTIMAL USE OF DITHER
 EXPERIMENTAL INVESTIGATION INTO THE OPTIMAL USE OF DITHER PACS: 43.60.Cg Preben Kvist 1, Karsten Bo Rasmussen 2, Torben Poulsen 1 1 Acoustic Technology, Ørsted DTU, Technical University of Denmark DK-2800
EXPERIMENTAL INVESTIGATION INTO THE OPTIMAL USE OF DITHER PACS: 43.60.Cg Preben Kvist 1, Karsten Bo Rasmussen 2, Torben Poulsen 1 1 Acoustic Technology, Ørsted DTU, Technical University of Denmark DK-2800
Isolated Digit Recognition Using MFCC AND DTW
 MarutiLimkar a, RamaRao b & VidyaSagvekar c a Terna collegeof Engineering, Department of Electronics Engineering, Mumbai University, India b Vidyalankar Institute of Technology, Department ofelectronics
MarutiLimkar a, RamaRao b & VidyaSagvekar c a Terna collegeof Engineering, Department of Electronics Engineering, Mumbai University, India b Vidyalankar Institute of Technology, Department ofelectronics
Speech Synthesis; Pitch Detection and Vocoders
 Speech Synthesis; Pitch Detection and Vocoders Tai-Shih Chi ( 冀泰石 ) Department of Communication Engineering National Chiao Tung University May. 29, 2008 Speech Synthesis Basic components of the text-to-speech
Speech Synthesis; Pitch Detection and Vocoders Tai-Shih Chi ( 冀泰石 ) Department of Communication Engineering National Chiao Tung University May. 29, 2008 Speech Synthesis Basic components of the text-to-speech
Different Approaches of Spectral Subtraction Method for Speech Enhancement
 ISSN 2249 5460 Available online at www.internationalejournals.com International ejournals International Journal of Mathematical Sciences, Technology and Humanities 95 (2013 1056 1062 Different Approaches
ISSN 2249 5460 Available online at www.internationalejournals.com International ejournals International Journal of Mathematical Sciences, Technology and Humanities 95 (2013 1056 1062 Different Approaches
Speech and Music Discrimination based on Signal Modulation Spectrum.
 Speech and Music Discrimination based on Signal Modulation Spectrum. Pavel Balabko June 24, 1999 1 Introduction. This work is devoted to the problem of automatic speech and music discrimination. As we
Speech and Music Discrimination based on Signal Modulation Spectrum. Pavel Balabko June 24, 1999 1 Introduction. This work is devoted to the problem of automatic speech and music discrimination. As we
Keywords: spectral centroid, MPEG-7, sum of sine waves, band limited impulse train, STFT, peak detection.
 Global Journal of Researches in Engineering: J General Engineering Volume 15 Issue 4 Version 1.0 Year 2015 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global Journals Inc.
Global Journal of Researches in Engineering: J General Engineering Volume 15 Issue 4 Version 1.0 Year 2015 Type: Double Blind Peer Reviewed International Research Journal Publisher: Global Journals Inc.
Chapter 5 Window Functions. periodic with a period of N (number of samples). This is observed in table (3.1).
. This is observed in table (3.1).") Chapter 5 Window Functions 5.1 Introduction As discussed in section (3.7.5), the DTFS assumes that the input waveform is periodic with a period of N (number of samples). This is observed in table (3.1).
Chapter 5 Window Functions 5.1 Introduction As discussed in section (3.7.5), the DTFS assumes that the input waveform is periodic with a period of N (number of samples). This is observed in table (3.1).
Chapter Two. Fundamentals of Data and Signals. Data Communications and Computer Networks: A Business User's Approach Seventh Edition
 Chapter Two Fundamentals of Data and Signals Data Communications and Computer Networks: A Business User's Approach Seventh Edition After reading this chapter, you should be able to: Distinguish between
Chapter Two Fundamentals of Data and Signals Data Communications and Computer Networks: A Business User's Approach Seventh Edition After reading this chapter, you should be able to: Distinguish between
Pulse Code Modulation
 Pulse Code Modulation EE 44 Spring Semester Lecture 9 Analog signal Pulse Amplitude Modulation Pulse Width Modulation Pulse Position Modulation Pulse Code Modulation (3-bit coding) 1 Advantages of Digital
Pulse Code Modulation EE 44 Spring Semester Lecture 9 Analog signal Pulse Amplitude Modulation Pulse Width Modulation Pulse Position Modulation Pulse Code Modulation (3-bit coding) 1 Advantages of Digital
REAL-TIME BROADBAND NOISE REDUCTION
 REAL-TIME BROADBAND NOISE REDUCTION Robert Hoeldrich and Markus Lorber Institute of Electronic Music Graz Jakoministrasse 3-5, A-8010 Graz, Austria email: robert.hoeldrich@mhsg.ac.at Abstract A real-time
REAL-TIME BROADBAND NOISE REDUCTION Robert Hoeldrich and Markus Lorber Institute of Electronic Music Graz Jakoministrasse 3-5, A-8010 Graz, Austria email: robert.hoeldrich@mhsg.ac.at Abstract A real-time
Psycho-acoustics (Sound characteristics, Masking, and Loudness)
") Psycho-acoustics (Sound characteristics, Masking, and Loudness) Tai-Shih Chi ( 冀泰石 ) Department of Communication Engineering National Chiao Tung University Mar. 20, 2008 Pure tones Mathematics of the pure
Psycho-acoustics (Sound characteristics, Masking, and Loudness) Tai-Shih Chi ( 冀泰石 ) Department of Communication Engineering National Chiao Tung University Mar. 20, 2008 Pure tones Mathematics of the pure
Spectral estimation using higher-lag autocorrelation coefficients with applications to speech recognition
 Spectral estimation using higher-lag autocorrelation coefficients with applications to speech recognition Author Shannon, Ben, Paliwal, Kuldip Published 25 Conference Title The 8th International Symposium
Spectral estimation using higher-lag autocorrelation coefficients with applications to speech recognition Author Shannon, Ben, Paliwal, Kuldip Published 25 Conference Title The 8th International Symposium
ADAPTIVE NOISE LEVEL ESTIMATION
 Proc. of the 9 th Int. Conference on Digital Audio Effects (DAFx-6), Montreal, Canada, September 18-2, 26 ADAPTIVE NOISE LEVEL ESTIMATION Chunghsin Yeh Analysis/Synthesis team IRCAM/CNRS-STMS, Paris, France
Proc. of the 9 th Int. Conference on Digital Audio Effects (DAFx-6), Montreal, Canada, September 18-2, 26 ADAPTIVE NOISE LEVEL ESTIMATION Chunghsin Yeh Analysis/Synthesis team IRCAM/CNRS-STMS, Paris, France
University of Colorado at Boulder ECEN 4/5532. Lab 1 Lab report due on February 2, 2015
 University of Colorado at Boulder ECEN 4/5532 Lab 1 Lab report due on February 2, 2015 This is a MATLAB only lab, and therefore each student needs to turn in her/his own lab report and own programs. 1
University of Colorado at Boulder ECEN 4/5532 Lab 1 Lab report due on February 2, 2015 This is a MATLAB only lab, and therefore each student needs to turn in her/his own lab report and own programs. 1
An Audio Fingerprint Algorithm Based on Statistical Characteristics of db4 Wavelet
 Journal of Information & Computational Science 8: 14 (2011) 3027 3034 Available at http://www.joics.com An Audio Fingerprint Algorithm Based on Statistical Characteristics of db4 Wavelet Jianguo JIANG
Journal of Information & Computational Science 8: 14 (2011) 3027 3034 Available at http://www.joics.com An Audio Fingerprint Algorithm Based on Statistical Characteristics of db4 Wavelet Jianguo JIANG
DIGITAL COMMUNICATION
 DEPARTMENT OF ELECTRICAL &ELECTRONICS ENGINEERING DIGITAL COMMUNICATION Spring 00 Yrd. Doç. Dr. Burak Kelleci OUTLINE Quantization Pulse-Code Modulation THE QUANTIZATION PROCESS A continuous signal has
DEPARTMENT OF ELECTRICAL &ELECTRONICS ENGINEERING DIGITAL COMMUNICATION Spring 00 Yrd. Doç. Dr. Burak Kelleci OUTLINE Quantization Pulse-Code Modulation THE QUANTIZATION PROCESS A continuous signal has
Chapter 3 Data Transmission COSC 3213 Summer 2003
 Chapter 3 Data Transmission COSC 3213 Summer 2003 Courtesy of Prof. Amir Asif Definitions 1. Recall that the lowest layer in OSI is the physical layer. The physical layer deals with the transfer of raw
Chapter 3 Data Transmission COSC 3213 Summer 2003 Courtesy of Prof. Amir Asif Definitions 1. Recall that the lowest layer in OSI is the physical layer. The physical layer deals with the transfer of raw
FFT analysis in practice
 FFT analysis in practice Perception & Multimedia Computing Lecture 13 Rebecca Fiebrink Lecturer, Department of Computing Goldsmiths, University of London 1 Last Week Review of complex numbers: rectangular
FFT analysis in practice Perception & Multimedia Computing Lecture 13 Rebecca Fiebrink Lecturer, Department of Computing Goldsmiths, University of London 1 Last Week Review of complex numbers: rectangular
Mel- frequency cepstral coefficients (MFCCs) and gammatone filter banks
 and gammatone filter banks") SGN- 14006 Audio and Speech Processing Pasi PerQlä SGN- 14006 2015 Mel- frequency cepstral coefficients (MFCCs) and gammatone filter banks Slides for this lecture are based on those created by Katariina
SGN- 14006 Audio and Speech Processing Pasi PerQlä SGN- 14006 2015 Mel- frequency cepstral coefficients (MFCCs) and gammatone filter banks Slides for this lecture are based on those created by Katariina
Sampling and Reconstruction of Analog Signals
 Sampling and Reconstruction of Analog Signals Chapter Intended Learning Outcomes: (i) Ability to convert an analog signal to a discrete-time sequence via sampling (ii) Ability to construct an analog signal
Sampling and Reconstruction of Analog Signals Chapter Intended Learning Outcomes: (i) Ability to convert an analog signal to a discrete-time sequence via sampling (ii) Ability to construct an analog signal
Introduction. Chapter Time-Varying Signals
 Chapter 1 1.1 Time-Varying Signals Time-varying signals are commonly observed in the laboratory as well as many other applied settings. Consider, for example, the voltage level that is present at a specific
Chapter 1 1.1 Time-Varying Signals Time-varying signals are commonly observed in the laboratory as well as many other applied settings. Consider, for example, the voltage level that is present at a specific
Digital Processing of Continuous-Time Signals
 Chapter 4 Digital Processing of Continuous-Time Signals 清大電機系林嘉文 cwlin@ee.nthu.edu.tw 03-5731152 Original PowerPoint slides prepared by S. K. Mitra 4-1-1 Digital Processing of Continuous-Time Signals Digital
Chapter 4 Digital Processing of Continuous-Time Signals 清大電機系林嘉文 cwlin@ee.nthu.edu.tw 03-5731152 Original PowerPoint slides prepared by S. K. Mitra 4-1-1 Digital Processing of Continuous-Time Signals Digital
Design and Implementation of an Audio Classification System Based on SVM
 Available online at www.sciencedirect.com Procedia ngineering 15 (011) 4031 4035 Advanced in Control ngineering and Information Science Design and Implementation of an Audio Classification System Based
Available online at www.sciencedirect.com Procedia ngineering 15 (011) 4031 4035 Advanced in Control ngineering and Information Science Design and Implementation of an Audio Classification System Based
Monaural and Binaural Speech Separation
 Monaural and Binaural Speech Separation DeLiang Wang Perception & Neurodynamics Lab The Ohio State University Outline of presentation Introduction CASA approach to sound separation Ideal binary mask as
Monaural and Binaural Speech Separation DeLiang Wang Perception & Neurodynamics Lab The Ohio State University Outline of presentation Introduction CASA approach to sound separation Ideal binary mask as
6.2 MIDI: Musical Instrument Digital Interface. 6.4 Further Exploration
 Chapter 6 Basics of Digital Audio 6.1 Digitization of Sound 6.2 MIDI: Musical Instrument Digital Interface 63 6.3 Quantization and Transmission of Audio 6.4 Further Exploration 6.1 Digitization of Sound
Chapter 6 Basics of Digital Audio 6.1 Digitization of Sound 6.2 MIDI: Musical Instrument Digital Interface 63 6.3 Quantization and Transmission of Audio 6.4 Further Exploration 6.1 Digitization of Sound
(i) Understanding of the characteristics of linear-phase finite impulse response (FIR) filters
 Understanding of the characteristics of linear-phase finite impulse response (FIR) filters") FIR Filter Design Chapter Intended Learning Outcomes: (i) Understanding of the characteristics of linear-phase finite impulse response (FIR) filters (ii) Ability to design linear-phase FIR filters according
FIR Filter Design Chapter Intended Learning Outcomes: (i) Understanding of the characteristics of linear-phase finite impulse response (FIR) filters (ii) Ability to design linear-phase FIR filters according
Digital Processing of
 Chapter 4 Digital Processing of Continuous-Time Signals 清大電機系林嘉文 cwlin@ee.nthu.edu.tw 03-5731152 Original PowerPoint slides prepared by S. K. Mitra 4-1-1 Digital Processing of Continuous-Time Signals Digital
Chapter 4 Digital Processing of Continuous-Time Signals 清大電機系林嘉文 cwlin@ee.nthu.edu.tw 03-5731152 Original PowerPoint slides prepared by S. K. Mitra 4-1-1 Digital Processing of Continuous-Time Signals Digital
A Method for Voiced/Unvoiced Classification of Noisy Speech by Analyzing Time-Domain Features of Spectrogram Image
 Science Journal of Circuits, Systems and Signal Processing 2017; 6(2): 11-17 http://www.sciencepublishinggroup.com/j/cssp doi: 10.11648/j.cssp.20170602.12 ISSN: 2326-9065 (Print); ISSN: 2326-9073 (Online)
Science Journal of Circuits, Systems and Signal Processing 2017; 6(2): 11-17 http://www.sciencepublishinggroup.com/j/cssp doi: 10.11648/j.cssp.20170602.12 ISSN: 2326-9065 (Print); ISSN: 2326-9073 (Online)
Communications IB Paper 6 Handout 3: Digitisation and Digital Signals
 Communications IB Paper 6 Handout 3: Digitisation and Digital Signals Jossy Sayir Signal Processing and Communications Lab Department of Engineering University of Cambridge jossy.sayir@eng.cam.ac.uk Lent
Communications IB Paper 6 Handout 3: Digitisation and Digital Signals Jossy Sayir Signal Processing and Communications Lab Department of Engineering University of Cambridge jossy.sayir@eng.cam.ac.uk Lent
Comparison of Spectral Analysis Methods for Automatic Speech Recognition
 INTERSPEECH 2013 Comparison of Spectral Analysis Methods for Automatic Speech Recognition Venkata Neelima Parinam, Chandra Vootkuri, Stephen A. Zahorian Department of Electrical and Computer Engineering
INTERSPEECH 2013 Comparison of Spectral Analysis Methods for Automatic Speech Recognition Venkata Neelima Parinam, Chandra Vootkuri, Stephen A. Zahorian Department of Electrical and Computer Engineering
Data Communication. Chapter 3 Data Transmission
 Data Communication Chapter 3 Data Transmission ١ Terminology (1) Transmitter Receiver Medium Guided medium e.g. twisted pair, coaxial cable, optical fiber Unguided medium e.g. air, water, vacuum ٢ Terminology
Data Communication Chapter 3 Data Transmission ١ Terminology (1) Transmitter Receiver Medium Guided medium e.g. twisted pair, coaxial cable, optical fiber Unguided medium e.g. air, water, vacuum ٢ Terminology
THE CITADEL THE MILITARY COLLEGE OF SOUTH CAROLINA. Department of Electrical and Computer Engineering. ELEC 423 Digital Signal Processing
 THE CITADEL THE MILITARY COLLEGE OF SOUTH CAROLINA Department of Electrical and Computer Engineering ELEC 423 Digital Signal Processing Project 2 Due date: November 12 th, 2013 I) Introduction In ELEC
THE CITADEL THE MILITARY COLLEGE OF SOUTH CAROLINA Department of Electrical and Computer Engineering ELEC 423 Digital Signal Processing Project 2 Due date: November 12 th, 2013 I) Introduction In ELEC
2.1 BASIC CONCEPTS Basic Operations on Signals Time Shifting. Figure 2.2 Time shifting of a signal. Time Reversal.
 1 2.1 BASIC CONCEPTS 2.1.1 Basic Operations on Signals Time Shifting. Figure 2.2 Time shifting of a signal. Time Reversal. 2 Time Scaling. Figure 2.4 Time scaling of a signal. 2.1.2 Classification of Signals
1 2.1 BASIC CONCEPTS 2.1.1 Basic Operations on Signals Time Shifting. Figure 2.2 Time shifting of a signal. Time Reversal. 2 Time Scaling. Figure 2.4 Time scaling of a signal. 2.1.2 Classification of Signals
Digital Speech Processing and Coding
 ENEE408G Spring 2006 Lecture-2 Digital Speech Processing and Coding Spring 06 Instructor: Shihab Shamma Electrical & Computer Engineering University of Maryland, College Park http://www.ece.umd.edu/class/enee408g/
ENEE408G Spring 2006 Lecture-2 Digital Speech Processing and Coding Spring 06 Instructor: Shihab Shamma Electrical & Computer Engineering University of Maryland, College Park http://www.ece.umd.edu/class/enee408g/
EEE482F: Problem Set 1
 EEE482F: Problem Set 1 1. A digital source emits 1.0 and 0.0V levels with a probability of 0.2 each, and +3.0 and +4.0V levels with a probability of 0.3 each. Evaluate the average information of the source.
EEE482F: Problem Set 1 1. A digital source emits 1.0 and 0.0V levels with a probability of 0.2 each, and +3.0 and +4.0V levels with a probability of 0.3 each. Evaluate the average information of the source.
SGN Audio and Speech Processing
 Introduction 1 Course goals Introduction 2 SGN 14006 Audio and Speech Processing Lectures, Fall 2014 Anssi Klapuri Tampere University of Technology! Learn basics of audio signal processing Basic operations
Introduction 1 Course goals Introduction 2 SGN 14006 Audio and Speech Processing Lectures, Fall 2014 Anssi Klapuri Tampere University of Technology! Learn basics of audio signal processing Basic operations
MULTIMEDIA SYSTEMS
 1 Department of Computer Engineering, Faculty of Engineering King Mongkut s Institute of Technology Ladkrabang 01076531 MULTIMEDIA SYSTEMS Pk Pakorn Watanachaturaporn, Wt ht Ph.D. PhD pakorn@live.kmitl.ac.th,
1 Department of Computer Engineering, Faculty of Engineering King Mongkut s Institute of Technology Ladkrabang 01076531 MULTIMEDIA SYSTEMS Pk Pakorn Watanachaturaporn, Wt ht Ph.D. PhD pakorn@live.kmitl.ac.th,
Digital Signal Processing
 COMP ENG 4TL4: Digital Signal Processing Notes for Lecture #27 Tuesday, November 11, 23 6. SPECTRAL ANALYSIS AND ESTIMATION 6.1 Introduction to Spectral Analysis and Estimation The discrete-time Fourier
COMP ENG 4TL4: Digital Signal Processing Notes for Lecture #27 Tuesday, November 11, 23 6. SPECTRAL ANALYSIS AND ESTIMATION 6.1 Introduction to Spectral Analysis and Estimation The discrete-time Fourier
(i) Understanding of the characteristics of linear-phase finite impulse response (FIR) filters
 Understanding of the characteristics of linear-phase finite impulse response (FIR) filters") FIR Filter Design Chapter Intended Learning Outcomes: (i) Understanding of the characteristics of linear-phase finite impulse response (FIR) filters (ii) Ability to design linear-phase FIR filters according
FIR Filter Design Chapter Intended Learning Outcomes: (i) Understanding of the characteristics of linear-phase finite impulse response (FIR) filters (ii) Ability to design linear-phase FIR filters according
Sound waves. septembre 2014 Audio signals and systems 1
 Sound waves Sound is created by elastic vibrations or oscillations of particles in a particular medium. The vibrations are transmitted from particles to (neighbouring) particles: sound wave. Sound waves
Sound waves Sound is created by elastic vibrations or oscillations of particles in a particular medium. The vibrations are transmitted from particles to (neighbouring) particles: sound wave. Sound waves
Adaptive noise level estimation
 Adaptive noise level estimation Chunghsin Yeh, Axel Roebel To cite this version: Chunghsin Yeh, Axel Roebel. Adaptive noise level estimation. Workshop on Computer Music and Audio Technology (WOCMAT 6),
Adaptive noise level estimation Chunghsin Yeh, Axel Roebel To cite this version: Chunghsin Yeh, Axel Roebel. Adaptive noise level estimation. Workshop on Computer Music and Audio Technology (WOCMAT 6),
Complex Sounds. Reading: Yost Ch. 4
 Complex Sounds Reading: Yost Ch. 4 Natural Sounds Most sounds in our everyday lives are not simple sinusoidal sounds, but are complex sounds, consisting of a sum of many sinusoids. The amplitude and frequency
Complex Sounds Reading: Yost Ch. 4 Natural Sounds Most sounds in our everyday lives are not simple sinusoidal sounds, but are complex sounds, consisting of a sum of many sinusoids. The amplitude and frequency
CG401 Advanced Signal Processing. Dr Stuart Lawson Room A330 Tel: January 2003
 CG40 Advanced Dr Stuart Lawson Room A330 Tel: 23780 e-mail: ssl@eng.warwick.ac.uk 03 January 2003 Lecture : Overview INTRODUCTION What is a signal? An information-bearing quantity. Examples of -D and 2-D
CG40 Advanced Dr Stuart Lawson Room A330 Tel: 23780 e-mail: ssl@eng.warwick.ac.uk 03 January 2003 Lecture : Overview INTRODUCTION What is a signal? An information-bearing quantity. Examples of -D and 2-D
Speech Enhancement using Wiener filtering
 Speech Enhancement using Wiener filtering S. Chirtmay and M. Tahernezhadi Department of Electrical Engineering Northern Illinois University DeKalb, IL 60115 ABSTRACT The problem of reducing the disturbing
Speech Enhancement using Wiener filtering S. Chirtmay and M. Tahernezhadi Department of Electrical Engineering Northern Illinois University DeKalb, IL 60115 ABSTRACT The problem of reducing the disturbing
EEE508 GÜÇ SİSTEMLERİNDE SİNYAL İŞLEME
 EEE508 GÜÇ SİSTEMLERİNDE SİNYAL İŞLEME Signal Processing for Power System Applications Triggering, Segmentation and Characterization of the Events (Week-12) Gazi Üniversitesi, Elektrik ve Elektronik Müh.
EEE508 GÜÇ SİSTEMLERİNDE SİNYAL İŞLEME Signal Processing for Power System Applications Triggering, Segmentation and Characterization of the Events (Week-12) Gazi Üniversitesi, Elektrik ve Elektronik Müh.