Auditory Based Feature Vectors for Speech Recognition Systems
|
|
|
- Joella Benson
- 5 years ago
- Views:
Transcription
1 Auditory Based Feature Vectors for Speech Recognition Systems Dr. Waleed H. Abdulla Electrical & Computer Engineering Department The University of Auckland, New Zealand 1
2 Outlines Introduction ASR Systems and Signal Modelling The Human Ears Equivalent rectangular band (ERB) The Gammatone Filterbank (GTF) Speech Signal Analysis based on GTF Classification Evaluation Conclusions 2
3 Introduction Automatic speech recognition (ASR) is the process of converting an incoming acoustic signal to its corresponding stream of words. ASR systems can be: Speaker Dependent OR Speaker Independent Isolated Words OR Continuous Limited vocabulary OR Large vocabulary Resticted Domain OR Unrestricted Domain 3


4 Introduction The general paradigm of speech recognition systems comprises two main parts: front-end and back-end Signal Processing Part Statistical Modeling Part 4
5 Block diagram of the ASR systems ASR systems comprises: Speech Dataset Training Recognition s n Feature Extraction Recognition Phase O t Recognition W O t Training HMM Initial Training set Trainin, q t q t Training Phase 5
6 Speech Signal Processing Speech Signal Digital Filterbank Wavelets Fourier Transform Linear Prediction Power Estimation Mel Filterbank Fourier Transform Cepstrum Cepstrum PLP Coding Reflection Coefficients 6


7 MFCC & PLP Filterbanks MFCC Filterbank PLP Filterbank 7
8 Signal Modelling Feature Extraction Speech Signal s n Sampling Frequency Hz Preemphasis H(z)= z -1 Sampling at 9 ms rate Hanning Window 23 ms Time Domain Frequency Domain Power & 12 MFCC Normalised MFCC 12 Coefficients 36 & 72 ms Delta MFCC Delta-Delta MFCC Normalised Power 72 ms Delta Power Delta-Delta Power Feature Vectors Concatenation OR Streaming O t 8

9 The Structure of the Human Ears 9
10 Human Basilar Membrane 10
.")
11 Cochlea characteristic frequency for different species In 1961, Don Greenwood developed a mathematical function relating the characteristic frequency, fc, at any location along the length of the cochlea to the distance, x, from the apex (Greenwood 1961). The function is: f c A(10 ax / L K) Where: A is a high frequency control constant L is the cochlea length in (mm) a is the slop factor K is the low frequency control constant 11
.")
12 Reverse Correlation (Revcor) technique Revcore technique states that, for a linear system, it is possible to extract the system parameters by operations on stochastic input and output signals (de-boer and H. R. de Jongh 1978). The revcore function can be represented mathematically by the equation: g(t) t m e t cos( t) (a) (b) Amplitude e ff(t) Time (samples) Frequency 12
13 Critical band and equivalent rectangular bandwidth Critical band (CB) is the bandwidth of the human auditory filter at different characteristic frequencies positioned along the cochlea path. The bandwidth of the human auditory filter can be measured psycho-acoustically in masking experiments using a sine wave signal (single tone) and a broadband noise as a masker. Experiments show that sounds can be distinguished by ear only if they fall into different critical bands, and they practice the masking process on each other when they fall into the same critical band. H(f) 2 actual filter frequency 13
14 Equivalent rectangular bandwidth (ERB) The bandwidth of the actual auditory filter can be related to an equivalent rectangular bandwidth (ERB) filter that has a unit height and a bandwidth ERB. It passes the same power as the real filter does when subjected to a white noise input. ERB 0 H(f ) 2 df 14
15 Formulae for the ERB Various formulas have been derived for the ERB values: Zwicker 1961 ERB (1 1.4f c ) Glasberg and Moore 1990 ERB2 24.7(1 4.37f c ) Moore and Glasberg 1983 ERB3 6.23f c 93.39f c

16 Comparison of Different ERB Functions 16
17 General Formula for ERB ERB é m æ f c ö = + BW Q ê çè ø ë m min 1/ m ù úû Where f c is the centre frequency, Q is the ear quality factor, which is the ratio between the centre frequency and its corresponding filter bandwidth, BW min is the minimum bandwidth allowed, and m is the order. Lyon recommended the following parameters (Slaney 1988): Q = 8, BW min = 125 Hz, and m = 2 to produce ERB Ly ERB Ly é 2 æ f ö c = ç çè 8 ê ø ë 2 ù úû 17
18 General Formula for ERB Greenwood recommended: Q = 7.24, BW min = 22.85, m = 1 to form ERB Gr fc ERB Gr = Glassberg and Moore (Glasberg and Moore 1990) recommended Q = 9.26, BW min = 24.7, m = 1 to get ERB GM ERB GM fc = = 24.7( fc) 9.26 ERB GM is used in our approach as it approximates most of the other estimates. 18

19 Comparison Between Three ERB Definitions ERB ERB ERB Ly Gr GM 2 f c f c ( fc ) 19
20 Critical Band Number For a certain frequency, it represents the number of critical bands required until reaching that frequency. Let us consider the change in the critical-band number, z, as the frequency changes by df is given by: Dz 1 1 dz = df = df = df Df Df / Dz ERB( f ) z f c = ò 0 1 df ERB( f ) For ERB( f ) = 24.7( f ) fc 1 z= ò df = ln(4.37 f c + 1) 24.7( f ) 0 20
 = g(, ) cos( + f)")
21 Gammatone Filters The impulse response of these filters ht nbt e wt ut n-1 -bt () = g(, ) cos( + f) () 21
22 ERB of Gammatone Filters 2 ERB = ò H ( f ) df 0 ( n -1)! 1 H( f) =. 2 é êë b + 4 p ( f - f ) c ù úû n /2-2( n-1) 2 ERB = 2 p( n -1)! b 2 ( 1)! [ n - ] For n = 4, ERB = b b = ERB 22
23 Number of Channels and the Overlapping Spacing z f f H = ò L 1 df ERB( f ) ERB f = + BWmin For m = 1, Q f H Q fh + QB z= ò df = Qln f + BQ f + QB f L L where B = BW min If the overlapping factor between the contiguous filters is then the number of channels, N, is related to z, as follows: z = N. v Q fh + QB 9.26 fh N =.ln = ln v f + QB v f L L For Q = 9.26 and B =
24 Gammatone Filterbank For a certain band f L f H with overlapping between filters N = 9.26 f H ln v f L For 1 n N f c ( n ) ( f H ) e vn 9.26 ERB ( n ) f ( n c ) 24
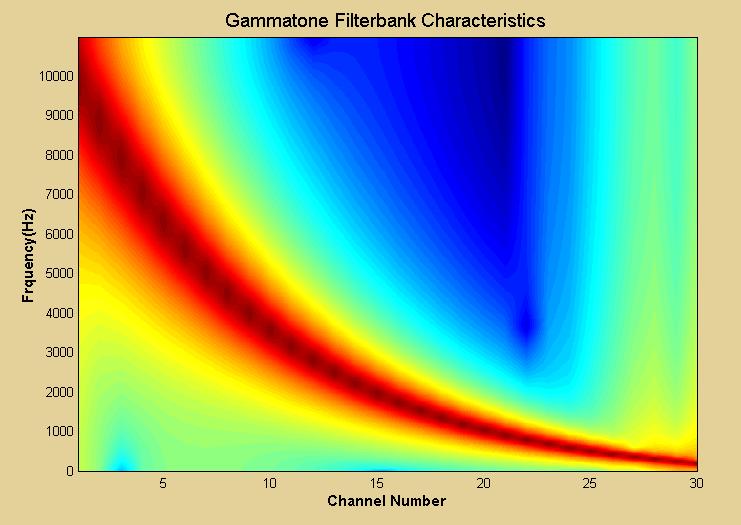
25 Characteristics of the GTF 25
26 Gammatone Filterbank Frequency response of a 30-channel filterbank, covering Hz band 26

27 Gammatone Filterbank Amplitude Time in samples Filter number is on the lower right corner Impulse responses of a 20-filters Gammatone filterbank. 27


28 Equal Loudness Contours This graph shows that the ear is not equally sensitive to all frequencies ISO recommendation R226 of equal loudness contours for pure tones and normal threshold of hearing for persons aged years. 28
 ( ) 2 6 2 2 9 6 ( 6.310 ).( 0.3810 ).( 9.")
29 Equal Loudness Preemphasis Filter The non-uniformity of the loudness sensing can be compensated for by a filter with the following transfer function E ( ) ( ) ( ).( ).( ) 29

30 Gammatone Filterbank Toward filter 20 Toward filter 1 Amplitude frequency responses of a 20-filters Gammatone filterbank after subjecting the filters to the equal loudness pre-emphasis filter. 30
 Spectra of the speech signal, (b) Log spectra of the speech signal.")
31 Speech Signal GTF Frequency Analysis Speech Signal Frames Speech signal analysis of a spoken digit 9 using 30 Gammatone filters. (a) Spectra of the speech signal, (b) Log spectra of the speech signal. 31
32 Feature Extraction Paradigms Speech Signal Speech Signal Gammatone Filterbank Gammatone Filterbank Equal Loudness Pre-emphasis Equal Loudness Pre-emphasis (a) Intensity - Loudness Power Law LOG{ } (b) Inverse Discrete Fourier Transform Inverse Discrete Cosine Transform Auto Regressive Mod elling Smoothing Gamma-PLP Coefficients Gamma-Cepst Coefficients Block diagrams of two feature extraction paradigms. 32
33 Feature Evaluation Based on F-Ratio F-ratio is a measure of the feature effectiveness. It is the ratio of the between class variance (B) to the within class variance (W). For the i th feature in the j th class of K classes: F B i i Bi W i 1 K K j1 ( ij ) i 2 W i 1 K K j1 W ij 33
34 F-Ratio Based on HMM HMM satisfies the F-ratio conditions Features have Gaussian distribution. Diagonal covariance implies uncorrelated features For K states in each model and for H models we have: F ave 1 H H i1 F i 34

35 F-Ratio Characteristics F-ratio Mean F-ratio Q static delta delta-delta F-ratio of the between states procedure. The thick red line indicates the mean of the between states F-ratio. 35

36 Performance Evaluation F-ratio static delta delta-delta Q Classification properties based on F-ratio calculations of different feature extraction paradigms. 36
37 Feature Rank F-ratio MFCC Rank F-ratio GTCC Rank F-ratio GTPLP Rank F-ratio PLP Mean F- ratio
 Model MFCC13 is constructed from 13 static mel scale coefficients.")
 Model GTCC13 is constructed from 13 static Gammatone cepstral coefficients.")
38 a MFCC13 b PLP13 c GTCC13 d GTPLP13 e Shows the states of the word three as detected by its four static features based CDHMMs. (a) Model MFCC13 is constructed from 13 static mel scale coefficients. (b) Model PLP13 is constructed from 13 static perceptual linear prediction coefficients. (c) Model GTCC13 is constructed from 13 static Gammatone cepstral coefficients. (d) Model GTPLP13 is constructed from 13 static Gammatone PLP coefficients. (e) The spectrogram of the input signal to envisage the frequency content of each state. 38

39 Classification Performance Absolute threshold recognition Margin Spoken words other than zero zero MFCC PLP GTPLP GTCC
40 Recognition Rate Performance DATASET-I DATASET-II Mel-cespt PLP Gamma-PLP Gamma-cepst DATASET-I : 10 digits DATASET-II : 31 words S/N ratio = 20 db 40
41 Conclusions Efficient auditory motivated technique is introduced. It is mainly based on Gammatone filterbank (GTF). GTF composed of non uniform bandpass filters imitating the frequency resolution of the cochlea. Two paradigms: Gamma-cepst and Gamma-PLP are investigated. Classification performance based on the F-ratio figure of merit has been investigated as it is a strong cue to the recognition performance. Gamma-cepst feature set outperforms the other feature sets. 41
42 42
Comparison of Spectral Analysis Methods for Automatic Speech Recognition
 INTERSPEECH 2013 Comparison of Spectral Analysis Methods for Automatic Speech Recognition Venkata Neelima Parinam, Chandra Vootkuri, Stephen A. Zahorian Department of Electrical and Computer Engineering
INTERSPEECH 2013 Comparison of Spectral Analysis Methods for Automatic Speech Recognition Venkata Neelima Parinam, Chandra Vootkuri, Stephen A. Zahorian Department of Electrical and Computer Engineering
Speech Signal Analysis
 Speech Signal Analysis Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 2&3 14,18 January 216 ASR Lectures 2&3 Speech Signal Analysis 1 Overview Speech Signal Analysis for
Speech Signal Analysis Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 2&3 14,18 January 216 ASR Lectures 2&3 Speech Signal Analysis 1 Overview Speech Signal Analysis for
Gammatone Cepstral Coefficient for Speaker Identification
 Gammatone Cepstral Coefficient for Speaker Identification Rahana Fathima 1, Raseena P E 2 M. Tech Student, Ilahia college of Engineering and Technology, Muvattupuzha, Kerala, India 1 Asst. Professor, Ilahia
Gammatone Cepstral Coefficient for Speaker Identification Rahana Fathima 1, Raseena P E 2 M. Tech Student, Ilahia college of Engineering and Technology, Muvattupuzha, Kerala, India 1 Asst. Professor, Ilahia
Signals & Systems for Speech & Hearing. Week 6. Practical spectral analysis. Bandpass filters & filterbanks. Try this out on an old friend
 Signals & Systems for Speech & Hearing Week 6 Bandpass filters & filterbanks Practical spectral analysis Most analogue signals of interest are not easily mathematically specified so applying a Fourier
Signals & Systems for Speech & Hearing Week 6 Bandpass filters & filterbanks Practical spectral analysis Most analogue signals of interest are not easily mathematically specified so applying a Fourier
AN AUDITORILY MOTIVATED ANALYSIS METHOD FOR ROOM IMPULSE RESPONSES
 Proceedings of the COST G-6 Conference on Digital Audio Effects (DAFX-), Verona, Italy, December 7-9,2 AN AUDITORILY MOTIVATED ANALYSIS METHOD FOR ROOM IMPULSE RESPONSES Tapio Lokki Telecommunications
Proceedings of the COST G-6 Conference on Digital Audio Effects (DAFX-), Verona, Italy, December 7-9,2 AN AUDITORILY MOTIVATED ANALYSIS METHOD FOR ROOM IMPULSE RESPONSES Tapio Lokki Telecommunications
Mel- frequency cepstral coefficients (MFCCs) and gammatone filter banks
 and gammatone filter banks") SGN- 14006 Audio and Speech Processing Pasi PerQlä SGN- 14006 2015 Mel- frequency cepstral coefficients (MFCCs) and gammatone filter banks Slides for this lecture are based on those created by Katariina
SGN- 14006 Audio and Speech Processing Pasi PerQlä SGN- 14006 2015 Mel- frequency cepstral coefficients (MFCCs) and gammatone filter banks Slides for this lecture are based on those created by Katariina
Hearing and Deafness 2. Ear as a frequency analyzer. Chris Darwin
 Hearing and Deafness 2. Ear as a analyzer Chris Darwin Frequency: -Hz Sine Wave. Spectrum Amplitude against -..5 Time (s) Waveform Amplitude against time amp Hz Frequency: 5-Hz Sine Wave. Spectrum Amplitude
Hearing and Deafness 2. Ear as a analyzer Chris Darwin Frequency: -Hz Sine Wave. Spectrum Amplitude against -..5 Time (s) Waveform Amplitude against time amp Hz Frequency: 5-Hz Sine Wave. Spectrum Amplitude
Speech Synthesis using Mel-Cepstral Coefficient Feature
 Speech Synthesis using Mel-Cepstral Coefficient Feature By Lu Wang Senior Thesis in Electrical Engineering University of Illinois at Urbana-Champaign Advisor: Professor Mark Hasegawa-Johnson May 2018 Abstract
Speech Synthesis using Mel-Cepstral Coefficient Feature By Lu Wang Senior Thesis in Electrical Engineering University of Illinois at Urbana-Champaign Advisor: Professor Mark Hasegawa-Johnson May 2018 Abstract
Using the Gammachirp Filter for Auditory Analysis of Speech
 Using the Gammachirp Filter for Auditory Analysis of Speech 18.327: Wavelets and Filterbanks Alex Park malex@sls.lcs.mit.edu May 14, 2003 Abstract Modern automatic speech recognition (ASR) systems typically
Using the Gammachirp Filter for Auditory Analysis of Speech 18.327: Wavelets and Filterbanks Alex Park malex@sls.lcs.mit.edu May 14, 2003 Abstract Modern automatic speech recognition (ASR) systems typically
HCS 7367 Speech Perception
 HCS 7367 Speech Perception Dr. Peter Assmann Fall 212 Power spectrum model of masking Assumptions: Only frequencies within the passband of the auditory filter contribute to masking. Detection is based
HCS 7367 Speech Perception Dr. Peter Assmann Fall 212 Power spectrum model of masking Assumptions: Only frequencies within the passband of the auditory filter contribute to masking. Detection is based
T Automatic Speech Recognition: From Theory to Practice
 Automatic Speech Recognition: From Theory to Practice http://www.cis.hut.fi/opinnot// September 27, 2004 Prof. Bryan Pellom Department of Computer Science Center for Spoken Language Research University
Automatic Speech Recognition: From Theory to Practice http://www.cis.hut.fi/opinnot// September 27, 2004 Prof. Bryan Pellom Department of Computer Science Center for Spoken Language Research University
Acoustics, signals & systems for audiology. Week 4. Signals through Systems
 Acoustics, signals & systems for audiology Week 4 Signals through Systems Crucial ideas Any signal can be constructed as a sum of sine waves In a linear time-invariant (LTI) system, the response to a sinusoid
Acoustics, signals & systems for audiology Week 4 Signals through Systems Crucial ideas Any signal can be constructed as a sum of sine waves In a linear time-invariant (LTI) system, the response to a sinusoid
Signal Processing for Speech Applications - Part 2-1. Signal Processing For Speech Applications - Part 2
 Signal Processing for Speech Applications - Part 2-1 Signal Processing For Speech Applications - Part 2 May 14, 2013 Signal Processing for Speech Applications - Part 2-2 References Huang et al., Chapter
Signal Processing for Speech Applications - Part 2-1 Signal Processing For Speech Applications - Part 2 May 14, 2013 Signal Processing for Speech Applications - Part 2-2 References Huang et al., Chapter
Auditory modelling for speech processing in the perceptual domain
 ANZIAM J. 45 (E) ppc964 C980, 2004 C964 Auditory modelling for speech processing in the perceptual domain L. Lin E. Ambikairajah W. H. Holmes (Received 8 August 2003; revised 28 January 2004) Abstract
ANZIAM J. 45 (E) ppc964 C980, 2004 C964 Auditory modelling for speech processing in the perceptual domain L. Lin E. Ambikairajah W. H. Holmes (Received 8 August 2003; revised 28 January 2004) Abstract
AN ANALYSIS OF SPEECH RECOGNITION PERFORMANCE BASED UPON NETWORK LAYERS AND TRANSFER FUNCTIONS
 AN ANALYSIS OF SPEECH RECOGNITION PERFORMANCE BASED UPON NETWORK LAYERS AND TRANSFER FUNCTIONS Kuldeep Kumar 1, R. K. Aggarwal 1 and Ankita Jain 2 1 Department of Computer Engineering, National Institute
AN ANALYSIS OF SPEECH RECOGNITION PERFORMANCE BASED UPON NETWORK LAYERS AND TRANSFER FUNCTIONS Kuldeep Kumar 1, R. K. Aggarwal 1 and Ankita Jain 2 1 Department of Computer Engineering, National Institute
Psycho-acoustics (Sound characteristics, Masking, and Loudness)
") Psycho-acoustics (Sound characteristics, Masking, and Loudness) Tai-Shih Chi ( 冀泰石 ) Department of Communication Engineering National Chiao Tung University Mar. 20, 2008 Pure tones Mathematics of the pure
Psycho-acoustics (Sound characteristics, Masking, and Loudness) Tai-Shih Chi ( 冀泰石 ) Department of Communication Engineering National Chiao Tung University Mar. 20, 2008 Pure tones Mathematics of the pure
Applying Models of Auditory Processing to Automatic Speech Recognition: Promise and Progress!
 Applying Models of Auditory Processing to Automatic Speech Recognition: Promise and Progress! Richard Stern (with Chanwoo Kim, Yu-Hsiang Chiu, and others) Department of Electrical and Computer Engineering
Applying Models of Auditory Processing to Automatic Speech Recognition: Promise and Progress! Richard Stern (with Chanwoo Kim, Yu-Hsiang Chiu, and others) Department of Electrical and Computer Engineering
Feasibility of Vocal Emotion Conversion on Modulation Spectrogram for Simulated Cochlear Implants
 Feasibility of Vocal Emotion Conversion on Modulation Spectrogram for Simulated Cochlear Implants Zhi Zhu, Ryota Miyauchi, Yukiko Araki, and Masashi Unoki School of Information Science, Japan Advanced
Feasibility of Vocal Emotion Conversion on Modulation Spectrogram for Simulated Cochlear Implants Zhi Zhu, Ryota Miyauchi, Yukiko Araki, and Masashi Unoki School of Information Science, Japan Advanced
Signals, Sound, and Sensation
 Signals, Sound, and Sensation William M. Hartmann Department of Physics and Astronomy Michigan State University East Lansing, Michigan Л1Р Contents Preface xv Chapter 1: Pure Tones 1 Mathematics of the
Signals, Sound, and Sensation William M. Hartmann Department of Physics and Astronomy Michigan State University East Lansing, Michigan Л1Р Contents Preface xv Chapter 1: Pure Tones 1 Mathematics of the
International Journal of Engineering and Techniques - Volume 1 Issue 6, Nov Dec 2015
 RESEARCH ARTICLE OPEN ACCESS A Comparative Study on Feature Extraction Technique for Isolated Word Speech Recognition Easwari.N 1, Ponmuthuramalingam.P 2 1,2 (PG & Research Department of Computer Science,
RESEARCH ARTICLE OPEN ACCESS A Comparative Study on Feature Extraction Technique for Isolated Word Speech Recognition Easwari.N 1, Ponmuthuramalingam.P 2 1,2 (PG & Research Department of Computer Science,
SPEech Feature Toolbox (SPEFT) Design and Emotional Speech Feature Extraction
 Design and Emotional Speech Feature Extraction") SPEech Feature Toolbox (SPEFT) Design and Emotional Speech Feature Extraction by Xi Li A thesis submitted to the Faculty of Graduate School, Marquette University, in Partial Fulfillment of the Requirements
SPEech Feature Toolbox (SPEFT) Design and Emotional Speech Feature Extraction by Xi Li A thesis submitted to the Faculty of Graduate School, Marquette University, in Partial Fulfillment of the Requirements
Perception of pitch. Importance of pitch: 2. mother hemp horse. scold. Definitions. Why is pitch important? AUDL4007: 11 Feb A. Faulkner.
 Perception of pitch AUDL4007: 11 Feb 2010. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence Erlbaum, 2005 Chapter 7 1 Definitions
Perception of pitch AUDL4007: 11 Feb 2010. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence Erlbaum, 2005 Chapter 7 1 Definitions
I D I A P. On Factorizing Spectral Dynamics for Robust Speech Recognition R E S E A R C H R E P O R T. Iain McCowan a Hemant Misra a,b
 R E S E A R C H R E P O R T I D I A P On Factorizing Spectral Dynamics for Robust Speech Recognition a Vivek Tyagi Hervé Bourlard a,b IDIAP RR 3-33 June 23 Iain McCowan a Hemant Misra a,b to appear in
R E S E A R C H R E P O R T I D I A P On Factorizing Spectral Dynamics for Robust Speech Recognition a Vivek Tyagi Hervé Bourlard a,b IDIAP RR 3-33 June 23 Iain McCowan a Hemant Misra a,b to appear in
SIGNAL PROCESSING FOR ROBUST SPEECH RECOGNITION MOTIVATED BY AUDITORY PROCESSING CHANWOO KIM
 SIGNAL PROCESSING FOR ROBUST SPEECH RECOGNITION MOTIVATED BY AUDITORY PROCESSING CHANWOO KIM MAY 21 ABSTRACT Although automatic speech recognition systems have dramatically improved in recent decades,
SIGNAL PROCESSING FOR ROBUST SPEECH RECOGNITION MOTIVATED BY AUDITORY PROCESSING CHANWOO KIM MAY 21 ABSTRACT Although automatic speech recognition systems have dramatically improved in recent decades,
Phase and Feedback in the Nonlinear Brain. Malcolm Slaney (IBM and Stanford) Hiroko Shiraiwa-Terasawa (Stanford) Regaip Sen (Stanford)
 Hiroko Shiraiwa-Terasawa (Stanford) Regaip Sen (Stanford)") Phase and Feedback in the Nonlinear Brain Malcolm Slaney (IBM and Stanford) Hiroko Shiraiwa-Terasawa (Stanford) Regaip Sen (Stanford) Auditory processing pre-cosyne workshop March 23, 2004 Simplistic Models
Phase and Feedback in the Nonlinear Brain Malcolm Slaney (IBM and Stanford) Hiroko Shiraiwa-Terasawa (Stanford) Regaip Sen (Stanford) Auditory processing pre-cosyne workshop March 23, 2004 Simplistic Models
An Improved Voice Activity Detection Based on Deep Belief Networks
 e-issn 2455 1392 Volume 2 Issue 4, April 2016 pp. 676-683 Scientific Journal Impact Factor : 3.468 http://www.ijcter.com An Improved Voice Activity Detection Based on Deep Belief Networks Shabeeba T. K.
e-issn 2455 1392 Volume 2 Issue 4, April 2016 pp. 676-683 Scientific Journal Impact Factor : 3.468 http://www.ijcter.com An Improved Voice Activity Detection Based on Deep Belief Networks Shabeeba T. K.
Cepstrum alanysis of speech signals
 Cepstrum alanysis of speech signals ELEC-E5520 Speech and language processing methods Spring 2016 Mikko Kurimo 1 /48 Contents Literature and other material Idea and history of cepstrum Cepstrum and LP
Cepstrum alanysis of speech signals ELEC-E5520 Speech and language processing methods Spring 2016 Mikko Kurimo 1 /48 Contents Literature and other material Idea and history of cepstrum Cepstrum and LP
19 th INTERNATIONAL CONGRESS ON ACOUSTICS MADRID, 2-7 SEPTEMBER 2007
 19 th INTERNATIONAL CONGRESS ON ACOUSTICS MADRID, 2-7 SEPTEMBER 2007 MODELING SPECTRAL AND TEMPORAL MASKING IN THE HUMAN AUDITORY SYSTEM PACS: 43.66.Ba, 43.66.Dc Dau, Torsten; Jepsen, Morten L.; Ewert,
19 th INTERNATIONAL CONGRESS ON ACOUSTICS MADRID, 2-7 SEPTEMBER 2007 MODELING SPECTRAL AND TEMPORAL MASKING IN THE HUMAN AUDITORY SYSTEM PACS: 43.66.Ba, 43.66.Dc Dau, Torsten; Jepsen, Morten L.; Ewert,
A Pole Zero Filter Cascade Provides Good Fits to Human Masking Data and to Basilar Membrane and Neural Data
 A Pole Zero Filter Cascade Provides Good Fits to Human Masking Data and to Basilar Membrane and Neural Data Richard F. Lyon Google, Inc. Abstract. A cascade of two-pole two-zero filters with level-dependent
A Pole Zero Filter Cascade Provides Good Fits to Human Masking Data and to Basilar Membrane and Neural Data Richard F. Lyon Google, Inc. Abstract. A cascade of two-pole two-zero filters with level-dependent
Perception of pitch. Definitions. Why is pitch important? BSc Audiology/MSc SHS Psychoacoustics wk 4: 7 Feb A. Faulkner.
 Perception of pitch BSc Audiology/MSc SHS Psychoacoustics wk 4: 7 Feb 2008. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence Erlbaum,
Perception of pitch BSc Audiology/MSc SHS Psychoacoustics wk 4: 7 Feb 2008. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence Erlbaum,
Mel Spectrum Analysis of Speech Recognition using Single Microphone
 International Journal of Engineering Research in Electronics and Communication Mel Spectrum Analysis of Speech Recognition using Single Microphone [1] Lakshmi S.A, [2] Cholavendan M [1] PG Scholar, Sree
International Journal of Engineering Research in Electronics and Communication Mel Spectrum Analysis of Speech Recognition using Single Microphone [1] Lakshmi S.A, [2] Cholavendan M [1] PG Scholar, Sree
Perception of pitch. Definitions. Why is pitch important? BSc Audiology/MSc SHS Psychoacoustics wk 5: 12 Feb A. Faulkner.
 Perception of pitch BSc Audiology/MSc SHS Psychoacoustics wk 5: 12 Feb 2009. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence
Perception of pitch BSc Audiology/MSc SHS Psychoacoustics wk 5: 12 Feb 2009. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence
Quantification of glottal and voiced speech harmonicsto-noise ratios using cepstral-based estimation
 Quantification of glottal and voiced speech harmonicsto-noise ratios using cepstral-based estimation Peter J. Murphy and Olatunji O. Akande, Department of Electronic and Computer Engineering University
Quantification of glottal and voiced speech harmonicsto-noise ratios using cepstral-based estimation Peter J. Murphy and Olatunji O. Akande, Department of Electronic and Computer Engineering University
MOST MODERN automatic speech recognition (ASR)
") IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING, VOL. 5, NO. 5, SEPTEMBER 1997 451 A Model of Dynamic Auditory Perception and Its Application to Robust Word Recognition Brian Strope and Abeer Alwan, Member,
IEEE TRANSACTIONS ON SPEECH AND AUDIO PROCESSING, VOL. 5, NO. 5, SEPTEMBER 1997 451 A Model of Dynamic Auditory Perception and Its Application to Robust Word Recognition Brian Strope and Abeer Alwan, Member,
RASTA-PLP SPEECH ANALYSIS. Aruna Bayya. Phil Kohn y TR December 1991
 RASTA-PLP SPEECH ANALYSIS Hynek Hermansky Nelson Morgan y Aruna Bayya Phil Kohn y TR-91-069 December 1991 Abstract Most speech parameter estimation techniques are easily inuenced by the frequency response
RASTA-PLP SPEECH ANALYSIS Hynek Hermansky Nelson Morgan y Aruna Bayya Phil Kohn y TR-91-069 December 1991 Abstract Most speech parameter estimation techniques are easily inuenced by the frequency response
DERIVATION OF TRAPS IN AUDITORY DOMAIN
 DERIVATION OF TRAPS IN AUDITORY DOMAIN Petr Motlíček, Doctoral Degree Programme (4) Dept. of Computer Graphics and Multimedia, FIT, BUT E-mail: motlicek@fit.vutbr.cz Supervised by: Dr. Jan Černocký, Prof.
DERIVATION OF TRAPS IN AUDITORY DOMAIN Petr Motlíček, Doctoral Degree Programme (4) Dept. of Computer Graphics and Multimedia, FIT, BUT E-mail: motlicek@fit.vutbr.cz Supervised by: Dr. Jan Černocký, Prof.
You know about adding up waves, e.g. from two loudspeakers. AUDL 4007 Auditory Perception. Week 2½. Mathematical prelude: Adding up levels
 AUDL 47 Auditory Perception You know about adding up waves, e.g. from two loudspeakers Week 2½ Mathematical prelude: Adding up levels 2 But how do you get the total rms from the rms values of two signals
AUDL 47 Auditory Perception You know about adding up waves, e.g. from two loudspeakers Week 2½ Mathematical prelude: Adding up levels 2 But how do you get the total rms from the rms values of two signals
Linguistic Phonetics. Spectral Analysis
 24.963 Linguistic Phonetics Spectral Analysis 4 4 Frequency (Hz) 1 Reading for next week: Liljencrants & Lindblom 1972. Assignment: Lip-rounding assignment, due 1/15. 2 Spectral analysis techniques There
24.963 Linguistic Phonetics Spectral Analysis 4 4 Frequency (Hz) 1 Reading for next week: Liljencrants & Lindblom 1972. Assignment: Lip-rounding assignment, due 1/15. 2 Spectral analysis techniques There
Machine recognition of speech trained on data from New Jersey Labs
 Machine recognition of speech trained on data from New Jersey Labs Frequency response (peak around 5 Hz) Impulse response (effective length around 200 ms) 41 RASTA filter 10 attenuation [db] 40 1 10 modulation
Machine recognition of speech trained on data from New Jersey Labs Frequency response (peak around 5 Hz) Impulse response (effective length around 200 ms) 41 RASTA filter 10 attenuation [db] 40 1 10 modulation
I D I A P. Mel-Cepstrum Modulation Spectrum (MCMS) Features for Robust ASR R E S E A R C H R E P O R T. Iain McCowan a Hemant Misra a,b
 Features for Robust ASR R E S E A R C H R E P O R T. Iain McCowan a Hemant Misra a,b") R E S E A R C H R E P O R T I D I A P Mel-Cepstrum Modulation Spectrum (MCMS) Features for Robust ASR a Vivek Tyagi Hervé Bourlard a,b IDIAP RR 3-47 September 23 Iain McCowan a Hemant Misra a,b to appear
R E S E A R C H R E P O R T I D I A P Mel-Cepstrum Modulation Spectrum (MCMS) Features for Robust ASR a Vivek Tyagi Hervé Bourlard a,b IDIAP RR 3-47 September 23 Iain McCowan a Hemant Misra a,b to appear
University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005
 University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005 Lecture 5 Slides Jan 26 th, 2005 Outline of Today s Lecture Announcements Filter-bank analysis
University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005 Lecture 5 Slides Jan 26 th, 2005 Outline of Today s Lecture Announcements Filter-bank analysis
Performance Analysis of MFCC and LPCC Techniques in Automatic Speech Recognition
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume - 3 Issue - 8 August, 2014 Page No. 7727-7732 Performance Analysis of MFCC and LPCC Techniques in Automatic
www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume - 3 Issue - 8 August, 2014 Page No. 7727-7732 Performance Analysis of MFCC and LPCC Techniques in Automatic
Rhythmic Similarity -- a quick paper review. Presented by: Shi Yong March 15, 2007 Music Technology, McGill University
 Rhythmic Similarity -- a quick paper review Presented by: Shi Yong March 15, 2007 Music Technology, McGill University Contents Introduction Three examples J. Foote 2001, 2002 J. Paulus 2002 S. Dixon 2004
Rhythmic Similarity -- a quick paper review Presented by: Shi Yong March 15, 2007 Music Technology, McGill University Contents Introduction Three examples J. Foote 2001, 2002 J. Paulus 2002 S. Dixon 2004
Robust Speech Recognition Based on Binaural Auditory Processing
 INTERSPEECH 2017 August 20 24, 2017, Stockholm, Sweden Robust Speech Recognition Based on Binaural Auditory Processing Anjali Menon 1, Chanwoo Kim 2, Richard M. Stern 1 1 Department of Electrical and Computer
INTERSPEECH 2017 August 20 24, 2017, Stockholm, Sweden Robust Speech Recognition Based on Binaural Auditory Processing Anjali Menon 1, Chanwoo Kim 2, Richard M. Stern 1 1 Department of Electrical and Computer
Robust Speech Recognition Based on Binaural Auditory Processing
 Robust Speech Recognition Based on Binaural Auditory Processing Anjali Menon 1, Chanwoo Kim 2, Richard M. Stern 1 1 Department of Electrical and Computer Engineering, Carnegie Mellon University, Pittsburgh,
Robust Speech Recognition Based on Binaural Auditory Processing Anjali Menon 1, Chanwoo Kim 2, Richard M. Stern 1 1 Department of Electrical and Computer Engineering, Carnegie Mellon University, Pittsburgh,
Human Auditory Periphery (HAP)
") Human Auditory Periphery (HAP) Ray Meddis Department of Human Sciences, University of Essex Colchester, CO4 3SQ, UK. rmeddis@essex.ac.uk A demonstrator for a human auditory modelling approach. 23/11/2003
Human Auditory Periphery (HAP) Ray Meddis Department of Human Sciences, University of Essex Colchester, CO4 3SQ, UK. rmeddis@essex.ac.uk A demonstrator for a human auditory modelling approach. 23/11/2003
SPEECH ENHANCEMENT USING PITCH DETECTION APPROACH FOR NOISY ENVIRONMENT
 SPEECH ENHANCEMENT USING PITCH DETECTION APPROACH FOR NOISY ENVIRONMENT RASHMI MAKHIJANI Department of CSE, G. H. R.C.E., Near CRPF Campus,Hingna Road, Nagpur, Maharashtra, India rashmi.makhijani2002@gmail.com
SPEECH ENHANCEMENT USING PITCH DETECTION APPROACH FOR NOISY ENVIRONMENT RASHMI MAKHIJANI Department of CSE, G. H. R.C.E., Near CRPF Campus,Hingna Road, Nagpur, Maharashtra, India rashmi.makhijani2002@gmail.com
Can binary masks improve intelligibility?
 Can binary masks improve intelligibility? Mike Brookes (Imperial College London) & Mark Huckvale (University College London) Apparently so... 2 How does it work? 3 Time-frequency grid of local SNR + +
Can binary masks improve intelligibility? Mike Brookes (Imperial College London) & Mark Huckvale (University College London) Apparently so... 2 How does it work? 3 Time-frequency grid of local SNR + +
Dimension Reduction of the Modulation Spectrogram for Speaker Verification
 Dimension Reduction of the Modulation Spectrogram for Speaker Verification Tomi Kinnunen Speech and Image Processing Unit Department of Computer Science University of Joensuu, Finland tkinnu@cs.joensuu.fi
Dimension Reduction of the Modulation Spectrogram for Speaker Verification Tomi Kinnunen Speech and Image Processing Unit Department of Computer Science University of Joensuu, Finland tkinnu@cs.joensuu.fi
Signals A Preliminary Discussion EE442 Analog & Digital Communication Systems Lecture 2
 Signals A Preliminary Discussion EE442 Analog & Digital Communication Systems Lecture 2 The Fourier transform of single pulse is the sinc function. EE 442 Signal Preliminaries 1 Communication Systems and
Signals A Preliminary Discussion EE442 Analog & Digital Communication Systems Lecture 2 The Fourier transform of single pulse is the sinc function. EE 442 Signal Preliminaries 1 Communication Systems and
Complex Sounds. Reading: Yost Ch. 4
 Complex Sounds Reading: Yost Ch. 4 Natural Sounds Most sounds in our everyday lives are not simple sinusoidal sounds, but are complex sounds, consisting of a sum of many sinusoids. The amplitude and frequency
Complex Sounds Reading: Yost Ch. 4 Natural Sounds Most sounds in our everyday lives are not simple sinusoidal sounds, but are complex sounds, consisting of a sum of many sinusoids. The amplitude and frequency
Speech Synthesis; Pitch Detection and Vocoders
 Speech Synthesis; Pitch Detection and Vocoders Tai-Shih Chi ( 冀泰石 ) Department of Communication Engineering National Chiao Tung University May. 29, 2008 Speech Synthesis Basic components of the text-to-speech
Speech Synthesis; Pitch Detection and Vocoders Tai-Shih Chi ( 冀泰石 ) Department of Communication Engineering National Chiao Tung University May. 29, 2008 Speech Synthesis Basic components of the text-to-speech
Robust Speech Feature Extraction using RSF/DRA and Burst Noise Skipping
 100 ECTI TRANSACTIONS ON ELECTRICAL ENG., ELECTRONICS, AND COMMUNICATIONS VOL.3, NO.2 AUGUST 2005 Robust Speech Feature Extraction using RSF/DRA and Burst Noise Skipping Naoya Wada, Shingo Yoshizawa, Noboru
100 ECTI TRANSACTIONS ON ELECTRICAL ENG., ELECTRONICS, AND COMMUNICATIONS VOL.3, NO.2 AUGUST 2005 Robust Speech Feature Extraction using RSF/DRA and Burst Noise Skipping Naoya Wada, Shingo Yoshizawa, Noboru
Monaural and binaural processing of fluctuating sounds in the auditory system
 Monaural and binaural processing of fluctuating sounds in the auditory system Eric R. Thompson September 23, 2005 MSc Thesis Acoustic Technology Ørsted DTU Technical University of Denmark Supervisor: Torsten
Monaural and binaural processing of fluctuating sounds in the auditory system Eric R. Thompson September 23, 2005 MSc Thesis Acoustic Technology Ørsted DTU Technical University of Denmark Supervisor: Torsten
CS 188: Artificial Intelligence Spring Speech in an Hour
 CS 188: Artificial Intelligence Spring 2006 Lecture 19: Speech Recognition 3/23/2006 Dan Klein UC Berkeley Many slides from Dan Jurafsky Speech in an Hour Speech input is an acoustic wave form s p ee ch
CS 188: Artificial Intelligence Spring 2006 Lecture 19: Speech Recognition 3/23/2006 Dan Klein UC Berkeley Many slides from Dan Jurafsky Speech in an Hour Speech input is an acoustic wave form s p ee ch
Tones in HVAC Systems (Update from 2006 Seminar, Quebec City) Jerry G. Lilly, P.E. JGL Acoustics, Inc. Issaquah, WA
 Jerry G. Lilly, P.E. JGL Acoustics, Inc. Issaquah, WA") Tones in HVAC Systems (Update from 2006 Seminar, Quebec City) Jerry G. Lilly, P.E. JGL Acoustics, Inc. Issaquah, WA Outline Review Fundamentals Frequency Spectra Tone Characteristics Tone Detection Methods
Tones in HVAC Systems (Update from 2006 Seminar, Quebec City) Jerry G. Lilly, P.E. JGL Acoustics, Inc. Issaquah, WA Outline Review Fundamentals Frequency Spectra Tone Characteristics Tone Detection Methods
Multichannel level alignment, part I: Signals and methods
 Suokuisma, Zacharov & Bech AES 5th Convention - San Francisco Multichannel level alignment, part I: Signals and methods Pekka Suokuisma Nokia Research Center, Speech and Audio Systems Laboratory, Tampere,
Suokuisma, Zacharov & Bech AES 5th Convention - San Francisco Multichannel level alignment, part I: Signals and methods Pekka Suokuisma Nokia Research Center, Speech and Audio Systems Laboratory, Tampere,
Speech Production. Automatic Speech Recognition handout (1) Jan - Mar 2009 Revision : 1.1. Speech Communication. Spectrogram. Waveform.
 Jan - Mar 2009 Revision : 1.1. Speech Communication. Spectrogram. Waveform.") Speech Production Automatic Speech Recognition handout () Jan - Mar 29 Revision :. Speech Signal Processing and Feature Extraction lips teeth nasal cavity oral cavity tongue lang S( Ω) pharynx larynx vocal
Speech Production Automatic Speech Recognition handout () Jan - Mar 29 Revision :. Speech Signal Processing and Feature Extraction lips teeth nasal cavity oral cavity tongue lang S( Ω) pharynx larynx vocal
EE482: Digital Signal Processing Applications
 Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 14 Quiz 04 Review 14/04/07 http://www.ee.unlv.edu/~b1morris/ee482/
Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 14 Quiz 04 Review 14/04/07 http://www.ee.unlv.edu/~b1morris/ee482/
Performance study of Text-independent Speaker identification system using MFCC & IMFCC for Telephone and Microphone Speeches
 Performance study of Text-independent Speaker identification system using & I for Telephone and Microphone Speeches Ruchi Chaudhary, National Technical Research Organization Abstract: A state-of-the-art
Performance study of Text-independent Speaker identification system using & I for Telephone and Microphone Speeches Ruchi Chaudhary, National Technical Research Organization Abstract: A state-of-the-art
Isolated Digit Recognition Using MFCC AND DTW
 MarutiLimkar a, RamaRao b & VidyaSagvekar c a Terna collegeof Engineering, Department of Electronics Engineering, Mumbai University, India b Vidyalankar Institute of Technology, Department ofelectronics
MarutiLimkar a, RamaRao b & VidyaSagvekar c a Terna collegeof Engineering, Department of Electronics Engineering, Mumbai University, India b Vidyalankar Institute of Technology, Department ofelectronics
REAL-TIME BROADBAND NOISE REDUCTION
 REAL-TIME BROADBAND NOISE REDUCTION Robert Hoeldrich and Markus Lorber Institute of Electronic Music Graz Jakoministrasse 3-5, A-8010 Graz, Austria email: robert.hoeldrich@mhsg.ac.at Abstract A real-time
REAL-TIME BROADBAND NOISE REDUCTION Robert Hoeldrich and Markus Lorber Institute of Electronic Music Graz Jakoministrasse 3-5, A-8010 Graz, Austria email: robert.hoeldrich@mhsg.ac.at Abstract A real-time
A comparative study on feature extraction techniques in speech recognition
 A comparative study on feature techniques in speech recognition Smita B. Magre Department of C. S. and I.T., Dr. Babasaheb Ambedkar Marathwada University, Aurangabad smit.magre@gmail.com ABSTRACT Automatic
A comparative study on feature techniques in speech recognition Smita B. Magre Department of C. S. and I.T., Dr. Babasaheb Ambedkar Marathwada University, Aurangabad smit.magre@gmail.com ABSTRACT Automatic
Chapter 4 SPEECH ENHANCEMENT
 44 Chapter 4 SPEECH ENHANCEMENT 4.1 INTRODUCTION: Enhancement is defined as improvement in the value or Quality of something. Speech enhancement is defined as the improvement in intelligibility and/or
44 Chapter 4 SPEECH ENHANCEMENT 4.1 INTRODUCTION: Enhancement is defined as improvement in the value or Quality of something. Speech enhancement is defined as the improvement in intelligibility and/or
FFT 1 /n octave analysis wavelet
 06/16 For most acoustic examinations, a simple sound level analysis is insufficient, as not only the overall sound pressure level, but also the frequency-dependent distribution of the level has a significant
06/16 For most acoustic examinations, a simple sound level analysis is insufficient, as not only the overall sound pressure level, but also the frequency-dependent distribution of the level has a significant
Testing of Objective Audio Quality Assessment Models on Archive Recordings Artifacts
 POSTER 25, PRAGUE MAY 4 Testing of Objective Audio Quality Assessment Models on Archive Recordings Artifacts Bc. Martin Zalabák Department of Radioelectronics, Czech Technical University in Prague, Technická
POSTER 25, PRAGUE MAY 4 Testing of Objective Audio Quality Assessment Models on Archive Recordings Artifacts Bc. Martin Zalabák Department of Radioelectronics, Czech Technical University in Prague, Technická
Topic. Spectrogram Chromagram Cesptrogram. Bryan Pardo, 2008, Northwestern University EECS 352: Machine Perception of Music and Audio
 Topic Spectrogram Chromagram Cesptrogram Short time Fourier Transform Break signal into windows Calculate DFT of each window The Spectrogram spectrogram(y,1024,512,1024,fs,'yaxis'); A series of short term
Topic Spectrogram Chromagram Cesptrogram Short time Fourier Transform Break signal into windows Calculate DFT of each window The Spectrogram spectrogram(y,1024,512,1024,fs,'yaxis'); A series of short term
SOUND QUALITY EVALUATION OF FAN NOISE BASED ON HEARING-RELATED PARAMETERS SUMMARY INTRODUCTION
 SOUND QUALITY EVALUATION OF FAN NOISE BASED ON HEARING-RELATED PARAMETERS Roland SOTTEK, Klaus GENUIT HEAD acoustics GmbH, Ebertstr. 30a 52134 Herzogenrath, GERMANY SUMMARY Sound quality evaluation of
SOUND QUALITY EVALUATION OF FAN NOISE BASED ON HEARING-RELATED PARAMETERS Roland SOTTEK, Klaus GENUIT HEAD acoustics GmbH, Ebertstr. 30a 52134 Herzogenrath, GERMANY SUMMARY Sound quality evaluation of
Speech and Music Discrimination based on Signal Modulation Spectrum.
 Speech and Music Discrimination based on Signal Modulation Spectrum. Pavel Balabko June 24, 1999 1 Introduction. This work is devoted to the problem of automatic speech and music discrimination. As we
Speech and Music Discrimination based on Signal Modulation Spectrum. Pavel Balabko June 24, 1999 1 Introduction. This work is devoted to the problem of automatic speech and music discrimination. As we
A CONSTRUCTION OF COMPACT MFCC-TYPE FEATURES USING SHORT-TIME STATISTICS FOR APPLICATIONS IN AUDIO SEGMENTATION
 17th European Signal Processing Conference (EUSIPCO 2009) Glasgow, Scotland, August 24-28, 2009 A CONSTRUCTION OF COMPACT MFCC-TYPE FEATURES USING SHORT-TIME STATISTICS FOR APPLICATIONS IN AUDIO SEGMENTATION
17th European Signal Processing Conference (EUSIPCO 2009) Glasgow, Scotland, August 24-28, 2009 A CONSTRUCTION OF COMPACT MFCC-TYPE FEATURES USING SHORT-TIME STATISTICS FOR APPLICATIONS IN AUDIO SEGMENTATION
Advanced audio analysis. Martin Gasser
 Advanced audio analysis Martin Gasser Motivation Which methods are common in MIR research? How can we parameterize audio signals? Interesting dimensions of audio: Spectral/ time/melody structure, high
Advanced audio analysis Martin Gasser Motivation Which methods are common in MIR research? How can we parameterize audio signals? Interesting dimensions of audio: Spectral/ time/melody structure, high
Electronic disguised voice identification based on Mel- Frequency Cepstral Coefficient analysis
 International Journal of Scientific and Research Publications, Volume 5, Issue 11, November 2015 412 Electronic disguised voice identification based on Mel- Frequency Cepstral Coefficient analysis Shalate
International Journal of Scientific and Research Publications, Volume 5, Issue 11, November 2015 412 Electronic disguised voice identification based on Mel- Frequency Cepstral Coefficient analysis Shalate
Automatic Speech Recognition handout (1)
") Automatic Speech Recognition handout (1) Jan - Mar 2012 Revision : 1.1 Speech Signal Processing and Feature Extraction Hiroshi Shimodaira (h.shimodaira@ed.ac.uk) Speech Communication Intention Language
Automatic Speech Recognition handout (1) Jan - Mar 2012 Revision : 1.1 Speech Signal Processing and Feature Extraction Hiroshi Shimodaira (h.shimodaira@ed.ac.uk) Speech Communication Intention Language
Auditory filters at low frequencies: ERB and filter shape
 Auditory filters at low frequencies: ERB and filter shape Spring - 2007 Acoustics - 07gr1061 Carlos Jurado David Robledano Spring 2007 AALBORG UNIVERSITY 2 Preface The report contains all relevant information
Auditory filters at low frequencies: ERB and filter shape Spring - 2007 Acoustics - 07gr1061 Carlos Jurado David Robledano Spring 2007 AALBORG UNIVERSITY 2 Preface The report contains all relevant information
Objectives. Presentation Outline. Digital Modulation Lecture 03
 Digital Modulation Lecture 03 Inter-Symbol Interference Power Spectral Density Richard Harris Objectives To be able to discuss Inter-Symbol Interference (ISI), its causes and possible remedies. To be able
Digital Modulation Lecture 03 Inter-Symbol Interference Power Spectral Density Richard Harris Objectives To be able to discuss Inter-Symbol Interference (ISI), its causes and possible remedies. To be able
Signal Processing for Robust Speech Recognition Motivated by Auditory Processing
 Signal Processing for Robust Speech Recognition Motivated by Auditory Processing Chanwoo Kim CMU-LTI-1-17 Language Technologies Institute School of Computer Science Carnegie Mellon University 5 Forbes
Signal Processing for Robust Speech Recognition Motivated by Auditory Processing Chanwoo Kim CMU-LTI-1-17 Language Technologies Institute School of Computer Science Carnegie Mellon University 5 Forbes
arxiv: v1 [eess.as] 30 Dec 2017
![arxiv: v1 [eess.as] 30 Dec 2017](/thumbs/92/109672651.jpg "arxiv: v1 [eess.as] 30 Dec 2017") LOGARITHMI FREQUEY SALIG AD OSISTET FREQUEY OVERAGE FOR THE SELETIO OF AUDITORY FILTERAK ETER FREQUEIES Shoufeng Lin arxiv:8.75v [eess.as] 3 Dec 27 Department of Electrical and omputer Engineering, urtin
LOGARITHMI FREQUEY SALIG AD OSISTET FREQUEY OVERAGE FOR THE SELETIO OF AUDITORY FILTERAK ETER FREQUEIES Shoufeng Lin arxiv:8.75v [eess.as] 3 Dec 27 Department of Electrical and omputer Engineering, urtin
Classification of ships using autocorrelation technique for feature extraction of the underwater acoustic noise
 Classification of ships using autocorrelation technique for feature extraction of the underwater acoustic noise Noha KORANY 1 Alexandria University, Egypt ABSTRACT The paper applies spectral analysis to
Classification of ships using autocorrelation technique for feature extraction of the underwater acoustic noise Noha KORANY 1 Alexandria University, Egypt ABSTRACT The paper applies spectral analysis to
Harmonic Analysis. Purpose of Time Series Analysis. What Does Each Harmonic Mean? Part 3: Time Series I
 Part 3: Time Series I Harmonic Analysis Spectrum Analysis Autocorrelation Function Degree of Freedom Data Window (Figure from Panofsky and Brier 1968) Significance Tests Harmonic Analysis Harmonic analysis
Part 3: Time Series I Harmonic Analysis Spectrum Analysis Autocorrelation Function Degree of Freedom Data Window (Figure from Panofsky and Brier 1968) Significance Tests Harmonic Analysis Harmonic analysis
Effective post-processing for single-channel frequency-domain speech enhancement Weifeng Li a
 R E S E A R C H R E P O R T I D I A P Effective post-processing for single-channel frequency-domain speech enhancement Weifeng Li a IDIAP RR 7-7 January 8 submitted for publication a IDIAP Research Institute,
R E S E A R C H R E P O R T I D I A P Effective post-processing for single-channel frequency-domain speech enhancement Weifeng Li a IDIAP RR 7-7 January 8 submitted for publication a IDIAP Research Institute,
Enhancement of Speech Signal by Adaptation of Scales and Thresholds of Bionic Wavelet Transform Coefficients
 ISSN (Print) : 232 3765 An ISO 3297: 27 Certified Organization Vol. 3, Special Issue 3, April 214 Paiyanoor-63 14, Tamil Nadu, India Enhancement of Speech Signal by Adaptation of Scales and Thresholds
ISSN (Print) : 232 3765 An ISO 3297: 27 Certified Organization Vol. 3, Special Issue 3, April 214 Paiyanoor-63 14, Tamil Nadu, India Enhancement of Speech Signal by Adaptation of Scales and Thresholds
An Efficient Extraction of Vocal Portion from Music Accompaniment Using Trend Estimation
 An Efficient Extraction of Vocal Portion from Music Accompaniment Using Trend Estimation Aisvarya V 1, Suganthy M 2 PG Student [Comm. Systems], Dept. of ECE, Sree Sastha Institute of Engg. & Tech., Chennai,
An Efficient Extraction of Vocal Portion from Music Accompaniment Using Trend Estimation Aisvarya V 1, Suganthy M 2 PG Student [Comm. Systems], Dept. of ECE, Sree Sastha Institute of Engg. & Tech., Chennai,
I M P L I C AT I O N S O F M O D U L AT I O N F I LT E R B A N K P R O C E S S I N G F O R A U T O M AT I C S P E E C H R E C O G N I T I O N
 Giuliano Bernardi I M P L I C AT I O N S O F M O D U L AT I O N F I LT E R B A N K P R O C E S S I N G F O R A U T O M AT I C S P E E C H R E C O G N I T I O N Master s Thesis, July 211 this report was
Giuliano Bernardi I M P L I C AT I O N S O F M O D U L AT I O N F I LT E R B A N K P R O C E S S I N G F O R A U T O M AT I C S P E E C H R E C O G N I T I O N Master s Thesis, July 211 this report was
CHAPTER 2 FIR ARCHITECTURE FOR THE FILTER BANK OF SPEECH PROCESSOR
 22 CHAPTER 2 FIR ARCHITECTURE FOR THE FILTER BANK OF SPEECH PROCESSOR 2.1 INTRODUCTION A CI is a device that can provide a sense of sound to people who are deaf or profoundly hearing-impaired. Filters
22 CHAPTER 2 FIR ARCHITECTURE FOR THE FILTER BANK OF SPEECH PROCESSOR 2.1 INTRODUCTION A CI is a device that can provide a sense of sound to people who are deaf or profoundly hearing-impaired. Filters
Dimension Reduction of the Modulation Spectrogram for Speaker Verification
 Dimension Reduction of the Modulation Spectrogram for Speaker Verification Tomi Kinnunen Speech and Image Processing Unit Department of Computer Science University of Joensuu, Finland Kong Aik Lee and
Dimension Reduction of the Modulation Spectrogram for Speaker Verification Tomi Kinnunen Speech and Image Processing Unit Department of Computer Science University of Joensuu, Finland Kong Aik Lee and
2920 J. Acoust. Soc. Am. 102 (5), Pt. 1, November /97/102(5)/2920/5/$ Acoustical Society of America 2920
, Pt. 1, November /97/102(5)/2920/5/$ Acoustical Society of America 2920") Detection and discrimination of frequency glides as a function of direction, duration, frequency span, and center frequency John P. Madden and Kevin M. Fire Department of Communication Sciences and Disorders,
Detection and discrimination of frequency glides as a function of direction, duration, frequency span, and center frequency John P. Madden and Kevin M. Fire Department of Communication Sciences and Disorders,
Problem Sheet 1 Probability, random processes, and noise
 Problem Sheet 1 Probability, random processes, and noise 1. If F X (x) is the distribution function of a random variable X and x 1 x 2, show that F X (x 1 ) F X (x 2 ). 2. Use the definition of the cumulative
Problem Sheet 1 Probability, random processes, and noise 1. If F X (x) is the distribution function of a random variable X and x 1 x 2, show that F X (x 1 ) F X (x 2 ). 2. Use the definition of the cumulative
Speech Enhancement and Noise-Robust Automatic Speech Recognition
 Speech Enhancement and Noise-Robust Automatic Speech Recognition - Harvesting the Best of Two Worlds Dennis A. L. Thomsen & Carina E. Andersen Group: 15gr1071 Signal Processing and Computing June 3, 2015
Speech Enhancement and Noise-Robust Automatic Speech Recognition - Harvesting the Best of Two Worlds Dennis A. L. Thomsen & Carina E. Andersen Group: 15gr1071 Signal Processing and Computing June 3, 2015
JOURNAL OF OBJECT TECHNOLOGY
 JOURNAL OF OBJECT TECHNOLOGY Online at http://www.jot.fm. Published by ETH Zurich, Chair of Software Engineering JOT, 2009 Vol. 9, No. 1, January-February 2010 The Discrete Fourier Transform, Part 5: Spectrogram
JOURNAL OF OBJECT TECHNOLOGY Online at http://www.jot.fm. Published by ETH Zurich, Chair of Software Engineering JOT, 2009 Vol. 9, No. 1, January-February 2010 The Discrete Fourier Transform, Part 5: Spectrogram
IMPROVING MICROPHONE ARRAY SPEECH RECOGNITION WITH COCHLEAR IMPLANT-LIKE SPECTRALLY REDUCED SPEECH
 RESEARCH REPORT IDIAP IMPROVING MICROPHONE ARRAY SPEECH RECOGNITION WITH COCHLEAR IMPLANT-LIKE SPECTRALLY REDUCED SPEECH Cong-Thanh Do Mohammad J. Taghizadeh Philip N. Garner Idiap-RR-40-2011 DECEMBER
RESEARCH REPORT IDIAP IMPROVING MICROPHONE ARRAY SPEECH RECOGNITION WITH COCHLEAR IMPLANT-LIKE SPECTRALLY REDUCED SPEECH Cong-Thanh Do Mohammad J. Taghizadeh Philip N. Garner Idiap-RR-40-2011 DECEMBER
Automatic Text-Independent. Speaker. Recognition Approaches Using Binaural Inputs
 Automatic Text-Independent Speaker Recognition Approaches Using Binaural Inputs Karim Youssef, Sylvain Argentieri and Jean-Luc Zarader 1 Outline Automatic speaker recognition: introduction Designed systems
Automatic Text-Independent Speaker Recognition Approaches Using Binaural Inputs Karim Youssef, Sylvain Argentieri and Jean-Luc Zarader 1 Outline Automatic speaker recognition: introduction Designed systems
MFCC AND GMM BASED TAMIL LANGUAGE SPEAKER IDENTIFICATION SYSTEM
 www.advancejournals.org Open Access Scientific Publisher MFCC AND GMM BASED TAMIL LANGUAGE SPEAKER IDENTIFICATION SYSTEM ABSTRACT- P. Santhiya 1, T. Jayasankar 1 1 AUT (BIT campus), Tiruchirappalli, India
www.advancejournals.org Open Access Scientific Publisher MFCC AND GMM BASED TAMIL LANGUAGE SPEAKER IDENTIFICATION SYSTEM ABSTRACT- P. Santhiya 1, T. Jayasankar 1 1 AUT (BIT campus), Tiruchirappalli, India
Tone-in-noise detection: Observed discrepancies in spectral integration. Nicolas Le Goff a) Technische Universiteit Eindhoven, P.O.
 Technische Universiteit Eindhoven, P.O.") Tone-in-noise detection: Observed discrepancies in spectral integration Nicolas Le Goff a) Technische Universiteit Eindhoven, P.O. Box 513, NL-5600 MB Eindhoven, The Netherlands Armin Kohlrausch b) and
Tone-in-noise detection: Observed discrepancies in spectral integration Nicolas Le Goff a) Technische Universiteit Eindhoven, P.O. Box 513, NL-5600 MB Eindhoven, The Netherlands Armin Kohlrausch b) and
PDF hosted at the Radboud Repository of the Radboud University Nijmegen
 PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is an author's version which may differ from the publisher's version. For additional information about this
PDF hosted at the Radboud Repository of the Radboud University Nijmegen The following full text is an author's version which may differ from the publisher's version. For additional information about this
Separating Voiced Segments from Music File using MFCC, ZCR and GMM
 Separating Voiced Segments from Music File using MFCC, ZCR and GMM Mr. Prashant P. Zirmite 1, Mr. Mahesh K. Patil 2, Mr. Santosh P. Salgar 3,Mr. Veeresh M. Metigoudar 4 1,2,3,4Assistant Professor, Dept.
Separating Voiced Segments from Music File using MFCC, ZCR and GMM Mr. Prashant P. Zirmite 1, Mr. Mahesh K. Patil 2, Mr. Santosh P. Salgar 3,Mr. Veeresh M. Metigoudar 4 1,2,3,4Assistant Professor, Dept.
Investigating Modulation Spectrogram Features for Deep Neural Network-based Automatic Speech Recognition
 Investigating Modulation Spectrogram Features for Deep Neural Network-based Automatic Speech Recognition DeepakBabyand HugoVanhamme Department ESAT, KU Leuven, Belgium {Deepak.Baby, Hugo.Vanhamme}@esat.kuleuven.be
Investigating Modulation Spectrogram Features for Deep Neural Network-based Automatic Speech Recognition DeepakBabyand HugoVanhamme Department ESAT, KU Leuven, Belgium {Deepak.Baby, Hugo.Vanhamme}@esat.kuleuven.be
2.1 BASIC CONCEPTS Basic Operations on Signals Time Shifting. Figure 2.2 Time shifting of a signal. Time Reversal.
 1 2.1 BASIC CONCEPTS 2.1.1 Basic Operations on Signals Time Shifting. Figure 2.2 Time shifting of a signal. Time Reversal. 2 Time Scaling. Figure 2.4 Time scaling of a signal. 2.1.2 Classification of Signals
1 2.1 BASIC CONCEPTS 2.1.1 Basic Operations on Signals Time Shifting. Figure 2.2 Time shifting of a signal. Time Reversal. 2 Time Scaling. Figure 2.4 Time scaling of a signal. 2.1.2 Classification of Signals
Spectro-Temporal Methods in Primary Auditory Cortex David Klein Didier Depireux Jonathan Simon Shihab Shamma
 Spectro-Temporal Methods in Primary Auditory Cortex David Klein Didier Depireux Jonathan Simon Shihab Shamma & Department of Electrical Engineering Supported in part by a MURI grant from the Office of
Spectro-Temporal Methods in Primary Auditory Cortex David Klein Didier Depireux Jonathan Simon Shihab Shamma & Department of Electrical Engineering Supported in part by a MURI grant from the Office of
A102 Signals and Systems for Hearing and Speech: Final exam answers
 A12 Signals and Systems for Hearing and Speech: Final exam answers 1) Take two sinusoids of 4 khz, both with a phase of. One has a peak level of.8 Pa while the other has a peak level of. Pa. Draw the spectrum
A12 Signals and Systems for Hearing and Speech: Final exam answers 1) Take two sinusoids of 4 khz, both with a phase of. One has a peak level of.8 Pa while the other has a peak level of. Pa. Draw the spectrum
AUDL GS08/GAV1 Signals, systems, acoustics and the ear. Loudness & Temporal resolution
 AUDL GS08/GAV1 Signals, systems, acoustics and the ear Loudness & Temporal resolution Absolute thresholds & Loudness Name some ways these concepts are crucial to audiologists Sivian & White (1933) JASA
AUDL GS08/GAV1 Signals, systems, acoustics and the ear Loudness & Temporal resolution Absolute thresholds & Loudness Name some ways these concepts are crucial to audiologists Sivian & White (1933) JASA