Advanced audio analysis. Martin Gasser
|
|
|
- Florence Barrett
- 5 years ago
- Views:
Transcription
1 Advanced audio analysis Martin Gasser
2 Motivation Which methods are common in MIR research? How can we parameterize audio signals? Interesting dimensions of audio: Spectral/ time/melody structure, high level descriptions Which properties of the signals are captured by the features?
3 Topics STFT, Phase Vocoder ConstantQ transform Source-filter analysis (LPC, Cepstrum, MFCC) Spectral modeling synthesis Beat tracking Pitch estimation Chord/key recognition
4 STFT Short time fourier transform Take DFT s of (overlapping) frames of audio data Before DFT, multiply data with window function Efficiently implemented via FFT (e.g., FFTW) Resolution of STFT limited by samplerate/number of bins by window type (spectrum is convolved with DFT of window function)

5 Phase vocoder Analysis/resynthesis method based on STFT Independent modification of magnitude and phase values in STFT bins High-quality pitch shifting/ time stretching/other effects
6 Problems of STFT Window size/type has to be manually adjusted to the data Equal time/frequency resolution for all freq. bands Human auditory perception has good frequency resolution in lower bands, good time resolution in upper bands Ratio of center frequency to bandwidth of auditory filters (``filter Q ) is approximately constant
7 Constant Q transform Window length of basis sinusoids is inversely related to center frequencies Center frequencies are logarithmically spaced ( no 0 frequency!) Basis matrix is not invertible there is no unique inversion (yet?) Efficient implementation: Leverages sparsity of basis functions in frequency domain
 DFT X")
![cq [k cq ]= N 1 n=0 x[n]k [n, k](/docs-images/92/108438876/images/8-2.jpg "cq ] = 1 N N 1 k=0 X[k]K [k, k cq")
8 Fast CQT Time kernel: K (dense) Spectral kernel: K (sparse) DFT X cq [k cq ]= N 1 n=0 x[n]k [n, k cq ] = 1 N N 1 k=0 X[k]K [k, k cq ]

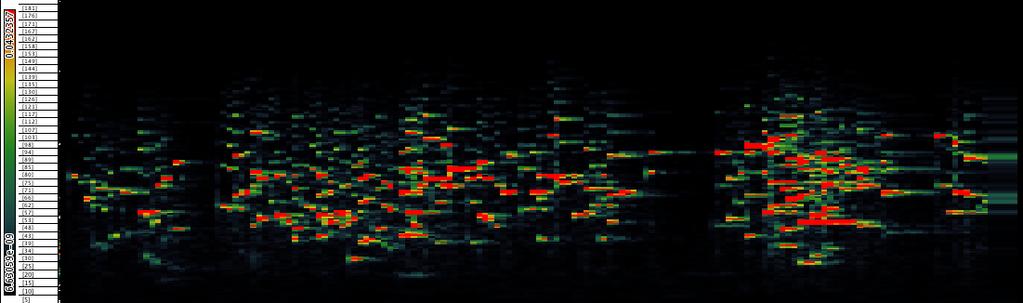
9 STFT vs. CQT
10 SMS Spectral modeling synthesis Enhancement of tracking phase vocoder Tries to separate signal into sinusoidal and residual (filtered white noise) parts Store sinusoidal tracks and filter coefficients Mixed bottom-up/top-down approach Usage: transcription, high quality time stretching/pitch shifting
11 Algorithm
12 Deterministic part (a) Peak picking (b) Peak interpolation to increase accuracy
13 (c) Peak tracking Deterministic part
14 Stochastic part Spectral subtraction can be done in frequency or time domain Frequency domain: Synthesize spectral shape of sinusoid (main lobe of window function) and resynthesize Time domain: Use phase matched additive synthesis Ideal residual is stochastic
15 Stochastic part Perform amplitude rescaling in order to reduce smearing artifacts Compare residual to original signal Whenever residual > original, reduce amplitude of residual Model spectral envelope of resulting signal (smoothed DFT, LPC, Cepstrum)
16 Critical steps Spectral analysis: Currently, STFT - can we improve? Additive resynthesis Smearing at transients!
17 Source-filter analysis Idea: signal excitation resonance Models human speech production and many musical instruments Excitation broadband pitched source signal (e.g., glottal pulse train) Resonance slowly varying filter (e.g., vocal tract) formants
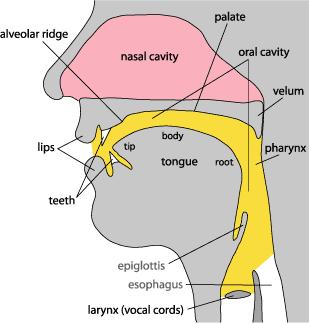

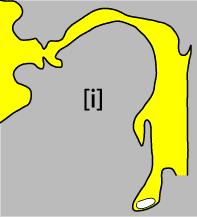
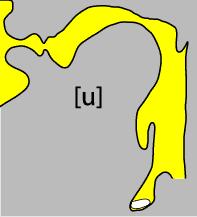
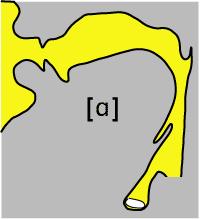
18 Source-filter analysis
19 Source-filter analysis Source signal is convolved with time-varying filter How to deconvolve the resulting signal? How to calculate coefficients of the filter? Applications: Pitch tracking, speech recognition/synthesis, music similarity,...
20 Linear Predictive Coding Analysis: Optimize coefficients in a predictive model (FIR filter), such that prediction error is minimized Difference between input signal and prediction: Residual Inverse filter: All pole (IIR) filter Resynthesis: Use (compressed) residual as input to inverse filter
21 LPC maths e(n) =x(n) p k=1 a k x(n k) E{e 2 (n)} a i = 2E{e(n) e(n) a i } = 2E{e(n)x(n i)} p = 2E{[x(n) a k x(n k)]x(n i)} =0 p k=1 Normal equations: Toeplitz matrix k=1 a k E{x(n k)x(n i)} = E{x(n)x(n i)} p a k r xx (i k) =r xx (i),i=1,...,p k=1 Efficient solution: Levinson-Durbin recursion
22 Cepstral techniques ``Cepstrum : Spectrum of a log(abs (spectrum)) Spectrum of signal: Spectrum of source spectrum of filter ``quefrency : Abscissa of cepstrum plot, unit of quefrency: Time (!) ``Cepstrogram : Plot of time intervals vs. spectral periodicities ``Liftering : Filtering in the cepstral domain
23 Cepstrum Inverse transform (DFT) of (liftered) Cepstrum spectral envelope
24 MFCC MFCC(x) =DCT(Mel(log DFT(x) )) Logarithm: Transforms product spectrum to sum Mel: Perceptual scale of pitches judged by listeners to be equal in distance to one another DCT: Decorrelates signal (DCT-II) spectral envelope (timbre) low coeffs.
25 Music similarity Model timbre as Gaussian distribution Σ = E(XX T ) µµ T µ = 1 n Σ(x i) E(XX T ) = 1 n Σx ix T i Compute similarity between distributions (KL divergence, earth movers distance,...) Simple genre classification Training : Labeled reference samples Nearest neighbor classification
26 High-level music analysis Beat tracking: Track locations of downbeats Tempo estimation: Find the (perceptual) tempo of a musical piece Pitch estimation Chord/key estimation
27 Beat tracking First step: Onset detection Can be done in spectral or time domain Causal/ real time methods: Model beat as dynamically excited oscillator Offline methods: Cluster inter-onset-intervals and find most plausible beat hypothesis
28 Scheirer s algorithm Subband decomposition (6 bands) Input half-wave rectified envelopes to resonator filterbank (150 bands ~ bpm) Choose resonator with max. output over all bands ( Tempo)
29 Scheirer s algo cont d Beat phase determination can be done by inspecting output or internal state of winning oscillator Pros: Predicts what is happening NOW (in contrast to simple autocorrelation, which performs calculation after the fact ) Cons: Discretizes tempo
30 Non-causal IOI clustering Multiple agents Dixon s algorithm
31 Dixon s algo cont d Onset detection: Surfboard method Calculate amplitude envelope of signal Linear regression of envelope Use IOI clusters as input to agents which predict beat times
32 Pitch estimation Task: Find the fundamental frequency in a signal Problems: Lowest peak is not always the fundamental frequency Perceived fundamental may not even be physically present
33 Pitch estimation Time-domain Zero-crossing rate Maxima in autocorrelation φ(τ) = 1 N Minima in magnitude difference Frequency-domain Cepstrum Maximum likelihood, HPS N 1 n=0 ψ(τ) = 1 N x(n)x(n + τ) N 1 n=0 x(n) x(n + τ)
34 Cepstrum pitch detection Real Cepstrum: C(x) =IFFT(log( DFT(x) )) log scales values into usable range Regular partials appear as peaks in cepstrum Unit of quefrency is ms (period)
35 HPS, ML Harmonic Product spectrum Y (ω) = R r=1 X(ωr) Ŷ = max ω i Y (ω i ) Maximum likelihood Correlate ideal spectra with input Ideal spectrum: Pulse train starting at ω, convolved with analysis window function Select spectral template with max. corr.

36 Key/Chord recognition Chroma: Fold down spectral representation to 12 bins, one bin covers one pitch class Correlate Chroma vectors with pitch-class distribution templates
37 Thank you!
E : Lecture 8 Source-Filter Processing. E : Lecture 8 Source-Filter Processing / 21
 E85.267: Lecture 8 Source-Filter Processing E85.267: Lecture 8 Source-Filter Processing 21-4-1 1 / 21 Source-filter analysis/synthesis n f Spectral envelope Spectral envelope Analysis Source signal n 1
E85.267: Lecture 8 Source-Filter Processing E85.267: Lecture 8 Source-Filter Processing 21-4-1 1 / 21 Source-filter analysis/synthesis n f Spectral envelope Spectral envelope Analysis Source signal n 1
University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005
 University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005 Lecture 5 Slides Jan 26 th, 2005 Outline of Today s Lecture Announcements Filter-bank analysis
University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005 Lecture 5 Slides Jan 26 th, 2005 Outline of Today s Lecture Announcements Filter-bank analysis
Topic. Spectrogram Chromagram Cesptrogram. Bryan Pardo, 2008, Northwestern University EECS 352: Machine Perception of Music and Audio
 Topic Spectrogram Chromagram Cesptrogram Short time Fourier Transform Break signal into windows Calculate DFT of each window The Spectrogram spectrogram(y,1024,512,1024,fs,'yaxis'); A series of short term
Topic Spectrogram Chromagram Cesptrogram Short time Fourier Transform Break signal into windows Calculate DFT of each window The Spectrogram spectrogram(y,1024,512,1024,fs,'yaxis'); A series of short term
Sound Synthesis Methods
 Sound Synthesis Methods Matti Vihola, mvihola@cs.tut.fi 23rd August 2001 1 Objectives The objective of sound synthesis is to create sounds that are Musically interesting Preferably realistic (sounds like
Sound Synthesis Methods Matti Vihola, mvihola@cs.tut.fi 23rd August 2001 1 Objectives The objective of sound synthesis is to create sounds that are Musically interesting Preferably realistic (sounds like
Lecture 6: Speech modeling and synthesis
 EE E682: Speech & Audio Processing & Recognition Lecture 6: Speech modeling and synthesis 1 2 3 4 5 Modeling speech signals Spectral and cepstral models Linear Predictive models (LPC) Other signal models
EE E682: Speech & Audio Processing & Recognition Lecture 6: Speech modeling and synthesis 1 2 3 4 5 Modeling speech signals Spectral and cepstral models Linear Predictive models (LPC) Other signal models
Speech Signal Analysis
 Speech Signal Analysis Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 2&3 14,18 January 216 ASR Lectures 2&3 Speech Signal Analysis 1 Overview Speech Signal Analysis for
Speech Signal Analysis Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 2&3 14,18 January 216 ASR Lectures 2&3 Speech Signal Analysis 1 Overview Speech Signal Analysis for
Speech Synthesis; Pitch Detection and Vocoders
 Speech Synthesis; Pitch Detection and Vocoders Tai-Shih Chi ( 冀泰石 ) Department of Communication Engineering National Chiao Tung University May. 29, 2008 Speech Synthesis Basic components of the text-to-speech
Speech Synthesis; Pitch Detection and Vocoders Tai-Shih Chi ( 冀泰石 ) Department of Communication Engineering National Chiao Tung University May. 29, 2008 Speech Synthesis Basic components of the text-to-speech
Lecture 5: Speech modeling. The speech signal
 EE E68: Speech & Audio Processing & Recognition Lecture 5: Speech modeling 1 3 4 5 Modeling speech signals Spectral and cepstral models Linear Predictive models (LPC) Other signal models Speech synthesis
EE E68: Speech & Audio Processing & Recognition Lecture 5: Speech modeling 1 3 4 5 Modeling speech signals Spectral and cepstral models Linear Predictive models (LPC) Other signal models Speech synthesis
EE482: Digital Signal Processing Applications
 Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 12 Speech Signal Processing 14/03/25 http://www.ee.unlv.edu/~b1morris/ee482/
Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 12 Speech Signal Processing 14/03/25 http://www.ee.unlv.edu/~b1morris/ee482/
Signal Analysis. Peak Detection. Envelope Follower (Amplitude detection) Music 270a: Signal Analysis
 Music 270a: Signal Analysis") Signal Analysis Music 27a: Signal Analysis Tamara Smyth, trsmyth@ucsd.edu Department of Music, University of California, San Diego (UCSD November 23, 215 Some tools we may want to use to automate analysis
Signal Analysis Music 27a: Signal Analysis Tamara Smyth, trsmyth@ucsd.edu Department of Music, University of California, San Diego (UCSD November 23, 215 Some tools we may want to use to automate analysis
Performance Analysis of MFCC and LPCC Techniques in Automatic Speech Recognition
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume - 3 Issue - 8 August, 2014 Page No. 7727-7732 Performance Analysis of MFCC and LPCC Techniques in Automatic
www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume - 3 Issue - 8 August, 2014 Page No. 7727-7732 Performance Analysis of MFCC and LPCC Techniques in Automatic
Speech Synthesis using Mel-Cepstral Coefficient Feature
 Speech Synthesis using Mel-Cepstral Coefficient Feature By Lu Wang Senior Thesis in Electrical Engineering University of Illinois at Urbana-Champaign Advisor: Professor Mark Hasegawa-Johnson May 2018 Abstract
Speech Synthesis using Mel-Cepstral Coefficient Feature By Lu Wang Senior Thesis in Electrical Engineering University of Illinois at Urbana-Champaign Advisor: Professor Mark Hasegawa-Johnson May 2018 Abstract
Signal Processing for Speech Applications - Part 2-1. Signal Processing For Speech Applications - Part 2
 Signal Processing for Speech Applications - Part 2-1 Signal Processing For Speech Applications - Part 2 May 14, 2013 Signal Processing for Speech Applications - Part 2-2 References Huang et al., Chapter
Signal Processing for Speech Applications - Part 2-1 Signal Processing For Speech Applications - Part 2 May 14, 2013 Signal Processing for Speech Applications - Part 2-2 References Huang et al., Chapter
Applications of Music Processing
 Lecture Music Processing Applications of Music Processing Christian Dittmar International Audio Laboratories Erlangen christian.dittmar@audiolabs-erlangen.de Singing Voice Detection Important pre-requisite
Lecture Music Processing Applications of Music Processing Christian Dittmar International Audio Laboratories Erlangen christian.dittmar@audiolabs-erlangen.de Singing Voice Detection Important pre-requisite
Mel Spectrum Analysis of Speech Recognition using Single Microphone
 International Journal of Engineering Research in Electronics and Communication Mel Spectrum Analysis of Speech Recognition using Single Microphone [1] Lakshmi S.A, [2] Cholavendan M [1] PG Scholar, Sree
International Journal of Engineering Research in Electronics and Communication Mel Spectrum Analysis of Speech Recognition using Single Microphone [1] Lakshmi S.A, [2] Cholavendan M [1] PG Scholar, Sree
Quantification of glottal and voiced speech harmonicsto-noise ratios using cepstral-based estimation
 Quantification of glottal and voiced speech harmonicsto-noise ratios using cepstral-based estimation Peter J. Murphy and Olatunji O. Akande, Department of Electronic and Computer Engineering University
Quantification of glottal and voiced speech harmonicsto-noise ratios using cepstral-based estimation Peter J. Murphy and Olatunji O. Akande, Department of Electronic and Computer Engineering University
L19: Prosodic modification of speech
 L19: Prosodic modification of speech Time-domain pitch synchronous overlap add (TD-PSOLA) Linear-prediction PSOLA Frequency-domain PSOLA Sinusoidal models Harmonic + noise models STRAIGHT This lecture
L19: Prosodic modification of speech Time-domain pitch synchronous overlap add (TD-PSOLA) Linear-prediction PSOLA Frequency-domain PSOLA Sinusoidal models Harmonic + noise models STRAIGHT This lecture
A Parametric Model for Spectral Sound Synthesis of Musical Sounds
 A Parametric Model for Spectral Sound Synthesis of Musical Sounds Cornelia Kreutzer University of Limerick ECE Department Limerick, Ireland cornelia.kreutzer@ul.ie Jacqueline Walker University of Limerick
A Parametric Model for Spectral Sound Synthesis of Musical Sounds Cornelia Kreutzer University of Limerick ECE Department Limerick, Ireland cornelia.kreutzer@ul.ie Jacqueline Walker University of Limerick
Lecture 5: Sinusoidal Modeling
 ELEN E4896 MUSIC SIGNAL PROCESSING Lecture 5: Sinusoidal Modeling 1. Sinusoidal Modeling 2. Sinusoidal Analysis 3. Sinusoidal Synthesis & Modification 4. Noise Residual Dan Ellis Dept. Electrical Engineering,
ELEN E4896 MUSIC SIGNAL PROCESSING Lecture 5: Sinusoidal Modeling 1. Sinusoidal Modeling 2. Sinusoidal Analysis 3. Sinusoidal Synthesis & Modification 4. Noise Residual Dan Ellis Dept. Electrical Engineering,
Signal segmentation and waveform characterization. Biosignal processing, S Autumn 2012
 Signal segmentation and waveform characterization Biosignal processing, 5173S Autumn 01 Short-time analysis of signals Signal statistics may vary in time: nonstationary how to compute signal characterizations?
Signal segmentation and waveform characterization Biosignal processing, 5173S Autumn 01 Short-time analysis of signals Signal statistics may vary in time: nonstationary how to compute signal characterizations?
Audio Similarity. Mark Zadel MUMT 611 March 8, Audio Similarity p.1/23
 Audio Similarity Mark Zadel MUMT 611 March 8, 2004 Audio Similarity p.1/23 Overview MFCCs Foote Content-Based Retrieval of Music and Audio (1997) Logan, Salomon A Music Similarity Function Based On Signal
Audio Similarity Mark Zadel MUMT 611 March 8, 2004 Audio Similarity p.1/23 Overview MFCCs Foote Content-Based Retrieval of Music and Audio (1997) Logan, Salomon A Music Similarity Function Based On Signal
Singing Voice Detection. Applications of Music Processing. Singing Voice Detection. Singing Voice Detection. Singing Voice Detection
 Detection Lecture usic Processing Applications of usic Processing Christian Dittmar International Audio Laboratories Erlangen christian.dittmar@audiolabs-erlangen.de Important pre-requisite for: usic segmentation
Detection Lecture usic Processing Applications of usic Processing Christian Dittmar International Audio Laboratories Erlangen christian.dittmar@audiolabs-erlangen.de Important pre-requisite for: usic segmentation
Cepstrum alanysis of speech signals
 Cepstrum alanysis of speech signals ELEC-E5520 Speech and language processing methods Spring 2016 Mikko Kurimo 1 /48 Contents Literature and other material Idea and history of cepstrum Cepstrum and LP
Cepstrum alanysis of speech signals ELEC-E5520 Speech and language processing methods Spring 2016 Mikko Kurimo 1 /48 Contents Literature and other material Idea and history of cepstrum Cepstrum and LP
Adaptive Filters Application of Linear Prediction
 Adaptive Filters Application of Linear Prediction Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Electrical Engineering and Information Technology Digital Signal Processing
Adaptive Filters Application of Linear Prediction Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Electrical Engineering and Information Technology Digital Signal Processing
MULTIPLE F0 ESTIMATION IN THE TRANSFORM DOMAIN
 10th International Society for Music Information Retrieval Conference (ISMIR 2009 MULTIPLE F0 ESTIMATION IN THE TRANSFORM DOMAIN Christopher A. Santoro +* Corey I. Cheng *# + LSB Audio Tampa, FL 33610
10th International Society for Music Information Retrieval Conference (ISMIR 2009 MULTIPLE F0 ESTIMATION IN THE TRANSFORM DOMAIN Christopher A. Santoro +* Corey I. Cheng *# + LSB Audio Tampa, FL 33610
Digital Signal Processing
 Digital Signal Processing Fourth Edition John G. Proakis Department of Electrical and Computer Engineering Northeastern University Boston, Massachusetts Dimitris G. Manolakis MIT Lincoln Laboratory Lexington,
Digital Signal Processing Fourth Edition John G. Proakis Department of Electrical and Computer Engineering Northeastern University Boston, Massachusetts Dimitris G. Manolakis MIT Lincoln Laboratory Lexington,
Converting Speaking Voice into Singing Voice
 Converting Speaking Voice into Singing Voice 1 st place of the Synthesis of Singing Challenge 2007: Vocal Conversion from Speaking to Singing Voice using STRAIGHT by Takeshi Saitou et al. 1 STRAIGHT Speech
Converting Speaking Voice into Singing Voice 1 st place of the Synthesis of Singing Challenge 2007: Vocal Conversion from Speaking to Singing Voice using STRAIGHT by Takeshi Saitou et al. 1 STRAIGHT Speech
Synthesis Techniques. Juan P Bello
 Synthesis Techniques Juan P Bello Synthesis It implies the artificial construction of a complex body by combining its elements. Complex body: acoustic signal (sound) Elements: parameters and/or basic signals
Synthesis Techniques Juan P Bello Synthesis It implies the artificial construction of a complex body by combining its elements. Complex body: acoustic signal (sound) Elements: parameters and/or basic signals
Audio Signal Compression using DCT and LPC Techniques
 Audio Signal Compression using DCT and LPC Techniques P. Sandhya Rani#1, D.Nanaji#2, V.Ramesh#3,K.V.S. Kiran#4 #Student, Department of ECE, Lendi Institute Of Engineering And Technology, Vizianagaram,
Audio Signal Compression using DCT and LPC Techniques P. Sandhya Rani#1, D.Nanaji#2, V.Ramesh#3,K.V.S. Kiran#4 #Student, Department of ECE, Lendi Institute Of Engineering And Technology, Vizianagaram,
Overview of Code Excited Linear Predictive Coder
 Overview of Code Excited Linear Predictive Coder Minal Mulye 1, Sonal Jagtap 2 1 PG Student, 2 Assistant Professor, Department of E&TC, Smt. Kashibai Navale College of Engg, Pune, India Abstract Advances
Overview of Code Excited Linear Predictive Coder Minal Mulye 1, Sonal Jagtap 2 1 PG Student, 2 Assistant Professor, Department of E&TC, Smt. Kashibai Navale College of Engg, Pune, India Abstract Advances
Rhythmic Similarity -- a quick paper review. Presented by: Shi Yong March 15, 2007 Music Technology, McGill University
 Rhythmic Similarity -- a quick paper review Presented by: Shi Yong March 15, 2007 Music Technology, McGill University Contents Introduction Three examples J. Foote 2001, 2002 J. Paulus 2002 S. Dixon 2004
Rhythmic Similarity -- a quick paper review Presented by: Shi Yong March 15, 2007 Music Technology, McGill University Contents Introduction Three examples J. Foote 2001, 2002 J. Paulus 2002 S. Dixon 2004
speech signal S(n). This involves a transformation of S(n) into another signal or a set of signals
. This involves a transformation of S(n) into another signal or a set of signals") 16 3. SPEECH ANALYSIS 3.1 INTRODUCTION TO SPEECH ANALYSIS Many speech processing [22] applications exploits speech production and perception to accomplish speech analysis. By speech analysis we extract
16 3. SPEECH ANALYSIS 3.1 INTRODUCTION TO SPEECH ANALYSIS Many speech processing [22] applications exploits speech production and perception to accomplish speech analysis. By speech analysis we extract
Preeti Rao 2 nd CompMusicWorkshop, Istanbul 2012
 Preeti Rao 2 nd CompMusicWorkshop, Istanbul 2012 o Music signal characteristics o Perceptual attributes and acoustic properties o Signal representations for pitch detection o STFT o Sinusoidal model o
Preeti Rao 2 nd CompMusicWorkshop, Istanbul 2012 o Music signal characteristics o Perceptual attributes and acoustic properties o Signal representations for pitch detection o STFT o Sinusoidal model o
Lecture 5: Speech modeling
 CSC 836: Speech & Audio Understanding Lecture 5: Speech modeling Dan Ellis CUNY Graduate Center, Computer Science Program http://mr-pc.org/t/csc836 With much content from Dan Ellis
CSC 836: Speech & Audio Understanding Lecture 5: Speech modeling Dan Ellis CUNY Graduate Center, Computer Science Program http://mr-pc.org/t/csc836 With much content from Dan Ellis
Enhanced Waveform Interpolative Coding at 4 kbps
 Enhanced Waveform Interpolative Coding at 4 kbps Oded Gottesman, and Allen Gersho Signal Compression Lab. University of California, Santa Barbara E-mail: [oded, gersho]@scl.ece.ucsb.edu Signal Compression
Enhanced Waveform Interpolative Coding at 4 kbps Oded Gottesman, and Allen Gersho Signal Compression Lab. University of California, Santa Barbara E-mail: [oded, gersho]@scl.ece.ucsb.edu Signal Compression
EE482: Digital Signal Processing Applications
 Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 14 Quiz 04 Review 14/04/07 http://www.ee.unlv.edu/~b1morris/ee482/
Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 14 Quiz 04 Review 14/04/07 http://www.ee.unlv.edu/~b1morris/ee482/
Synthesis Algorithms and Validation
 Chapter 5 Synthesis Algorithms and Validation An essential step in the study of pathological voices is re-synthesis; clear and immediate evidence of the success and accuracy of modeling efforts is provided
Chapter 5 Synthesis Algorithms and Validation An essential step in the study of pathological voices is re-synthesis; clear and immediate evidence of the success and accuracy of modeling efforts is provided
Digital Speech Processing and Coding
 ENEE408G Spring 2006 Lecture-2 Digital Speech Processing and Coding Spring 06 Instructor: Shihab Shamma Electrical & Computer Engineering University of Maryland, College Park http://www.ece.umd.edu/class/enee408g/
ENEE408G Spring 2006 Lecture-2 Digital Speech Processing and Coding Spring 06 Instructor: Shihab Shamma Electrical & Computer Engineering University of Maryland, College Park http://www.ece.umd.edu/class/enee408g/
Project 0: Part 2 A second hands-on lab on Speech Processing Frequency-domain processing
 Project : Part 2 A second hands-on lab on Speech Processing Frequency-domain processing February 24, 217 During this lab, you will have a first contact on frequency domain analysis of speech signals. You
Project : Part 2 A second hands-on lab on Speech Processing Frequency-domain processing February 24, 217 During this lab, you will have a first contact on frequency domain analysis of speech signals. You
EVALUATION OF MFCC ESTIMATION TECHNIQUES FOR MUSIC SIMILARITY
 EVALUATION OF MFCC ESTIMATION TECHNIQUES FOR MUSIC SIMILARITY Jesper Højvang Jensen 1, Mads Græsbøll Christensen 1, Manohar N. Murthi, and Søren Holdt Jensen 1 1 Department of Communication Technology,
EVALUATION OF MFCC ESTIMATION TECHNIQUES FOR MUSIC SIMILARITY Jesper Højvang Jensen 1, Mads Græsbøll Christensen 1, Manohar N. Murthi, and Søren Holdt Jensen 1 1 Department of Communication Technology,
Advanced Music Content Analysis
 RuSSIR 2013: Content- and Context-based Music Similarity and Retrieval Titelmasterformat durch Klicken bearbeiten Advanced Music Content Analysis Markus Schedl Peter Knees {markus.schedl, peter.knees}@jku.at
RuSSIR 2013: Content- and Context-based Music Similarity and Retrieval Titelmasterformat durch Klicken bearbeiten Advanced Music Content Analysis Markus Schedl Peter Knees {markus.schedl, peter.knees}@jku.at
Introducing COVAREP: A collaborative voice analysis repository for speech technologies
 Introducing COVAREP: A collaborative voice analysis repository for speech technologies John Kane Wednesday November 27th, 2013 SIGMEDIA-group TCD COVAREP - Open-source speech processing repository 1 Introduction
Introducing COVAREP: A collaborative voice analysis repository for speech technologies John Kane Wednesday November 27th, 2013 SIGMEDIA-group TCD COVAREP - Open-source speech processing repository 1 Introduction
BEAT DETECTION BY DYNAMIC PROGRAMMING. Racquel Ivy Awuor
 BEAT DETECTION BY DYNAMIC PROGRAMMING Racquel Ivy Awuor University of Rochester Department of Electrical and Computer Engineering Rochester, NY 14627 rawuor@ur.rochester.edu ABSTRACT A beat is a salient
BEAT DETECTION BY DYNAMIC PROGRAMMING Racquel Ivy Awuor University of Rochester Department of Electrical and Computer Engineering Rochester, NY 14627 rawuor@ur.rochester.edu ABSTRACT A beat is a salient
ADAPTIVE NOISE LEVEL ESTIMATION
 Proc. of the 9 th Int. Conference on Digital Audio Effects (DAFx-6), Montreal, Canada, September 18-2, 26 ADAPTIVE NOISE LEVEL ESTIMATION Chunghsin Yeh Analysis/Synthesis team IRCAM/CNRS-STMS, Paris, France
Proc. of the 9 th Int. Conference on Digital Audio Effects (DAFx-6), Montreal, Canada, September 18-2, 26 ADAPTIVE NOISE LEVEL ESTIMATION Chunghsin Yeh Analysis/Synthesis team IRCAM/CNRS-STMS, Paris, France
Formant Synthesis of Haegeum: A Sound Analysis/Synthesis System using Cpestral Envelope
 Formant Synthesis of Haegeum: A Sound Analysis/Synthesis System using Cpestral Envelope Myeongsu Kang School of Computer Engineering and Information Technology Ulsan, South Korea ilmareboy@ulsan.ac.kr
Formant Synthesis of Haegeum: A Sound Analysis/Synthesis System using Cpestral Envelope Myeongsu Kang School of Computer Engineering and Information Technology Ulsan, South Korea ilmareboy@ulsan.ac.kr
Linguistic Phonetics. Spectral Analysis
 24.963 Linguistic Phonetics Spectral Analysis 4 4 Frequency (Hz) 1 Reading for next week: Liljencrants & Lindblom 1972. Assignment: Lip-rounding assignment, due 1/15. 2 Spectral analysis techniques There
24.963 Linguistic Phonetics Spectral Analysis 4 4 Frequency (Hz) 1 Reading for next week: Liljencrants & Lindblom 1972. Assignment: Lip-rounding assignment, due 1/15. 2 Spectral analysis techniques There
SOUND SOURCE RECOGNITION AND MODELING
 SOUND SOURCE RECOGNITION AND MODELING CASA seminar, summer 2000 Antti Eronen antti.eronen@tut.fi Contents: Basics of human sound source recognition Timbre Voice recognition Recognition of environmental
SOUND SOURCE RECOGNITION AND MODELING CASA seminar, summer 2000 Antti Eronen antti.eronen@tut.fi Contents: Basics of human sound source recognition Timbre Voice recognition Recognition of environmental
High-Pitch Formant Estimation by Exploiting Temporal Change of Pitch
 High-Pitch Formant Estimation by Exploiting Temporal Change of Pitch The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation As Published
High-Pitch Formant Estimation by Exploiting Temporal Change of Pitch The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation As Published
Communications Theory and Engineering
 Communications Theory and Engineering Master's Degree in Electronic Engineering Sapienza University of Rome A.A. 2018-2019 Speech and telephone speech Based on a voice production model Parametric representation
Communications Theory and Engineering Master's Degree in Electronic Engineering Sapienza University of Rome A.A. 2018-2019 Speech and telephone speech Based on a voice production model Parametric representation
B.Tech III Year II Semester (R13) Regular & Supplementary Examinations May/June 2017 DIGITAL SIGNAL PROCESSING (Common to ECE and EIE)
 Regular & Supplementary Examinations May/June 2017 DIGITAL SIGNAL PROCESSING (Common to ECE and EIE)") Code: 13A04602 R13 B.Tech III Year II Semester (R13) Regular & Supplementary Examinations May/June 2017 (Common to ECE and EIE) PART A (Compulsory Question) 1 Answer the following: (10 X 02 = 20 Marks)
Code: 13A04602 R13 B.Tech III Year II Semester (R13) Regular & Supplementary Examinations May/June 2017 (Common to ECE and EIE) PART A (Compulsory Question) 1 Answer the following: (10 X 02 = 20 Marks)
Mel- frequency cepstral coefficients (MFCCs) and gammatone filter banks
 and gammatone filter banks") SGN- 14006 Audio and Speech Processing Pasi PerQlä SGN- 14006 2015 Mel- frequency cepstral coefficients (MFCCs) and gammatone filter banks Slides for this lecture are based on those created by Katariina
SGN- 14006 Audio and Speech Processing Pasi PerQlä SGN- 14006 2015 Mel- frequency cepstral coefficients (MFCCs) and gammatone filter banks Slides for this lecture are based on those created by Katariina
Between physics and perception signal models for high level audio processing. Axel Röbel. Analysis / synthesis team, IRCAM. DAFx 2010 iem Graz
 Between physics and perception signal models for high level audio processing Axel Röbel Analysis / synthesis team, IRCAM DAFx 2010 iem Graz Overview Introduction High level control of signal transformation
Between physics and perception signal models for high level audio processing Axel Röbel Analysis / synthesis team, IRCAM DAFx 2010 iem Graz Overview Introduction High level control of signal transformation
EC 6501 DIGITAL COMMUNICATION UNIT - II PART A
 EC 6501 DIGITAL COMMUNICATION 1.What is the need of prediction filtering? UNIT - II PART A [N/D-16] Prediction filtering is used mostly in audio signal processing and speech processing for representing
EC 6501 DIGITAL COMMUNICATION 1.What is the need of prediction filtering? UNIT - II PART A [N/D-16] Prediction filtering is used mostly in audio signal processing and speech processing for representing
FFT analysis in practice
 FFT analysis in practice Perception & Multimedia Computing Lecture 13 Rebecca Fiebrink Lecturer, Department of Computing Goldsmiths, University of London 1 Last Week Review of complex numbers: rectangular
FFT analysis in practice Perception & Multimedia Computing Lecture 13 Rebecca Fiebrink Lecturer, Department of Computing Goldsmiths, University of London 1 Last Week Review of complex numbers: rectangular
Drum Transcription Based on Independent Subspace Analysis
 Report for EE 391 Special Studies and Reports for Electrical Engineering Drum Transcription Based on Independent Subspace Analysis Yinyi Guo Center for Computer Research in Music and Acoustics, Stanford,
Report for EE 391 Special Studies and Reports for Electrical Engineering Drum Transcription Based on Independent Subspace Analysis Yinyi Guo Center for Computer Research in Music and Acoustics, Stanford,
COMPUTATIONAL RHYTHM AND BEAT ANALYSIS Nicholas Berkner. University of Rochester
 COMPUTATIONAL RHYTHM AND BEAT ANALYSIS Nicholas Berkner University of Rochester ABSTRACT One of the most important applications in the field of music information processing is beat finding. Humans have
COMPUTATIONAL RHYTHM AND BEAT ANALYSIS Nicholas Berkner University of Rochester ABSTRACT One of the most important applications in the field of music information processing is beat finding. Humans have
Complex Sounds. Reading: Yost Ch. 4
 Complex Sounds Reading: Yost Ch. 4 Natural Sounds Most sounds in our everyday lives are not simple sinusoidal sounds, but are complex sounds, consisting of a sum of many sinusoids. The amplitude and frequency
Complex Sounds Reading: Yost Ch. 4 Natural Sounds Most sounds in our everyday lives are not simple sinusoidal sounds, but are complex sounds, consisting of a sum of many sinusoids. The amplitude and frequency
TIME DOMAIN ATTACK AND RELEASE MODELING Applied to Spectral Domain Sound Synthesis
 TIME DOMAIN ATTACK AND RELEASE MODELING Applied to Spectral Domain Sound Synthesis Cornelia Kreutzer, Jacqueline Walker Department of Electronic and Computer Engineering, University of Limerick, Limerick,
TIME DOMAIN ATTACK AND RELEASE MODELING Applied to Spectral Domain Sound Synthesis Cornelia Kreutzer, Jacqueline Walker Department of Electronic and Computer Engineering, University of Limerick, Limerick,
Pattern Recognition. Part 6: Bandwidth Extension. Gerhard Schmidt
 Pattern Recognition Part 6: Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Institute of Electrical and Information Engineering Digital Signal Processing and System Theory
Pattern Recognition Part 6: Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Institute of Electrical and Information Engineering Digital Signal Processing and System Theory
Isolated Digit Recognition Using MFCC AND DTW
 MarutiLimkar a, RamaRao b & VidyaSagvekar c a Terna collegeof Engineering, Department of Electronics Engineering, Mumbai University, India b Vidyalankar Institute of Technology, Department ofelectronics
MarutiLimkar a, RamaRao b & VidyaSagvekar c a Terna collegeof Engineering, Department of Electronics Engineering, Mumbai University, India b Vidyalankar Institute of Technology, Department ofelectronics
ADDITIVE SYNTHESIS BASED ON THE CONTINUOUS WAVELET TRANSFORM: A SINUSOIDAL PLUS TRANSIENT MODEL
 ADDITIVE SYNTHESIS BASED ON THE CONTINUOUS WAVELET TRANSFORM: A SINUSOIDAL PLUS TRANSIENT MODEL José R. Beltrán and Fernando Beltrán Department of Electronic Engineering and Communications University of
ADDITIVE SYNTHESIS BASED ON THE CONTINUOUS WAVELET TRANSFORM: A SINUSOIDAL PLUS TRANSIENT MODEL José R. Beltrán and Fernando Beltrán Department of Electronic Engineering and Communications University of
Reading: Johnson Ch , Ch.5.5 (today); Liljencrants & Lindblom; Stevens (Tues) reminder: no class on Thursday.
; Liljencrants & Lindblom; Stevens (Tues) reminder: no class on Thursday.") L105/205 Phonetics Scarborough Handout 7 10/18/05 Reading: Johnson Ch.2.3.3-2.3.6, Ch.5.5 (today); Liljencrants & Lindblom; Stevens (Tues) reminder: no class on Thursday Spectral Analysis 1. There are
L105/205 Phonetics Scarborough Handout 7 10/18/05 Reading: Johnson Ch.2.3.3-2.3.6, Ch.5.5 (today); Liljencrants & Lindblom; Stevens (Tues) reminder: no class on Thursday Spectral Analysis 1. There are
Evaluation of MFCC Estimation Techniques for Music Similarity Jensen, Jesper Højvang; Christensen, Mads Græsbøll; Murthi, Manohar; Jensen, Søren Holdt
 Aalborg Universitet Evaluation of MFCC Estimation Techniques for Music Similarity Jensen, Jesper Højvang; Christensen, Mads Græsbøll; Murthi, Manohar; Jensen, Søren Holdt Published in: Proceedings of the
Aalborg Universitet Evaluation of MFCC Estimation Techniques for Music Similarity Jensen, Jesper Højvang; Christensen, Mads Græsbøll; Murthi, Manohar; Jensen, Søren Holdt Published in: Proceedings of the
HIGH ACCURACY FRAME-BY-FRAME NON-STATIONARY SINUSOIDAL MODELLING
 HIGH ACCURACY FRAME-BY-FRAME NON-STATIONARY SINUSOIDAL MODELLING Jeremy J. Wells, Damian T. Murphy Audio Lab, Intelligent Systems Group, Department of Electronics University of York, YO10 5DD, UK {jjw100
HIGH ACCURACY FRAME-BY-FRAME NON-STATIONARY SINUSOIDAL MODELLING Jeremy J. Wells, Damian T. Murphy Audio Lab, Intelligent Systems Group, Department of Electronics University of York, YO10 5DD, UK {jjw100
Comparison of CELP speech coder with a wavelet method
 University of Kentucky UKnowledge University of Kentucky Master's Theses Graduate School 2006 Comparison of CELP speech coder with a wavelet method Sriram Nagaswamy University of Kentucky, sriramn@gmail.com
University of Kentucky UKnowledge University of Kentucky Master's Theses Graduate School 2006 Comparison of CELP speech coder with a wavelet method Sriram Nagaswamy University of Kentucky, sriramn@gmail.com
Auditory modelling for speech processing in the perceptual domain
 ANZIAM J. 45 (E) ppc964 C980, 2004 C964 Auditory modelling for speech processing in the perceptual domain L. Lin E. Ambikairajah W. H. Holmes (Received 8 August 2003; revised 28 January 2004) Abstract
ANZIAM J. 45 (E) ppc964 C980, 2004 C964 Auditory modelling for speech processing in the perceptual domain L. Lin E. Ambikairajah W. H. Holmes (Received 8 August 2003; revised 28 January 2004) Abstract
Aberehe Niguse Gebru ABSTRACT. Keywords Autocorrelation, MATLAB, Music education, Pitch Detection, Wavelet
 Master of Industrial Sciences 2015-2016 Faculty of Engineering Technology, Campus Group T Leuven This paper is written by (a) student(s) in the framework of a Master s Thesis ABC Research Alert VIRTUAL
Master of Industrial Sciences 2015-2016 Faculty of Engineering Technology, Campus Group T Leuven This paper is written by (a) student(s) in the framework of a Master s Thesis ABC Research Alert VIRTUAL
International Journal of Modern Trends in Engineering and Research e-issn No.: , Date: 2-4 July, 2015
 International Journal of Modern Trends in Engineering and Research www.ijmter.com e-issn No.:2349-9745, Date: 2-4 July, 2015 Analysis of Speech Signal Using Graphic User Interface Solly Joy 1, Savitha
International Journal of Modern Trends in Engineering and Research www.ijmter.com e-issn No.:2349-9745, Date: 2-4 July, 2015 Analysis of Speech Signal Using Graphic User Interface Solly Joy 1, Savitha
-voiced. +voiced. /z/ /s/ Last Lecture. Digital Speech Processing. Overview of Speech Processing. Example on Sound Source Feature
 ENEE408G Lecture-6 Digital Speech rocessing URL: http://www.ece.umd.edu/class/enee408g/ Slides included here are based on Spring 005 offering in the order of introduction, image, video, speech, and audio.
ENEE408G Lecture-6 Digital Speech rocessing URL: http://www.ece.umd.edu/class/enee408g/ Slides included here are based on Spring 005 offering in the order of introduction, image, video, speech, and audio.
MUS421/EE367B Applications Lecture 9C: Time Scale Modification (TSM) and Frequency Scaling/Shifting
 and Frequency Scaling/Shifting") MUS421/EE367B Applications Lecture 9C: Time Scale Modification (TSM) and Frequency Scaling/Shifting Julius O. Smith III (jos@ccrma.stanford.edu) Center for Computer Research in Music and Acoustics (CCRMA)
MUS421/EE367B Applications Lecture 9C: Time Scale Modification (TSM) and Frequency Scaling/Shifting Julius O. Smith III (jos@ccrma.stanford.edu) Center for Computer Research in Music and Acoustics (CCRMA)
Speech Production. Automatic Speech Recognition handout (1) Jan - Mar 2009 Revision : 1.1. Speech Communication. Spectrogram. Waveform.
 Jan - Mar 2009 Revision : 1.1. Speech Communication. Spectrogram. Waveform.") Speech Production Automatic Speech Recognition handout () Jan - Mar 29 Revision :. Speech Signal Processing and Feature Extraction lips teeth nasal cavity oral cavity tongue lang S( Ω) pharynx larynx vocal
Speech Production Automatic Speech Recognition handout () Jan - Mar 29 Revision :. Speech Signal Processing and Feature Extraction lips teeth nasal cavity oral cavity tongue lang S( Ω) pharynx larynx vocal
Linear Predictive Coding *
 OpenStax-CNX module: m45345 1 Linear Predictive Coding * Kiefer Forseth This work is produced by OpenStax-CNX and licensed under the Creative Commons Attribution License 3.0 1 LPC Implementation Linear
OpenStax-CNX module: m45345 1 Linear Predictive Coding * Kiefer Forseth This work is produced by OpenStax-CNX and licensed under the Creative Commons Attribution License 3.0 1 LPC Implementation Linear
An Improved Voice Activity Detection Based on Deep Belief Networks
 e-issn 2455 1392 Volume 2 Issue 4, April 2016 pp. 676-683 Scientific Journal Impact Factor : 3.468 http://www.ijcter.com An Improved Voice Activity Detection Based on Deep Belief Networks Shabeeba T. K.
e-issn 2455 1392 Volume 2 Issue 4, April 2016 pp. 676-683 Scientific Journal Impact Factor : 3.468 http://www.ijcter.com An Improved Voice Activity Detection Based on Deep Belief Networks Shabeeba T. K.
VU Signal and Image Processing. Torsten Möller + Hrvoje Bogunović + Raphael Sahann
 052600 VU Signal and Image Processing Torsten Möller + Hrvoje Bogunović + Raphael Sahann torsten.moeller@univie.ac.at hrvoje.bogunovic@meduniwien.ac.at raphael.sahann@univie.ac.at vda.cs.univie.ac.at/teaching/sip/17s/
052600 VU Signal and Image Processing Torsten Möller + Hrvoje Bogunović + Raphael Sahann torsten.moeller@univie.ac.at hrvoje.bogunovic@meduniwien.ac.at raphael.sahann@univie.ac.at vda.cs.univie.ac.at/teaching/sip/17s/
Speech synthesizer. W. Tidelund S. Andersson R. Andersson. March 11, 2015
 Speech synthesizer W. Tidelund S. Andersson R. Andersson March 11, 2015 1 1 Introduction A real time speech synthesizer is created by modifying a recorded signal on a DSP by using a prediction filter.
Speech synthesizer W. Tidelund S. Andersson R. Andersson March 11, 2015 1 1 Introduction A real time speech synthesizer is created by modifying a recorded signal on a DSP by using a prediction filter.
Speech Compression Using Voice Excited Linear Predictive Coding
 Speech Compression Using Voice Excited Linear Predictive Coding Ms.Tosha Sen, Ms.Kruti Jay Pancholi PG Student, Asst. Professor, L J I E T, Ahmedabad Abstract : The aim of the thesis is design good quality
Speech Compression Using Voice Excited Linear Predictive Coding Ms.Tosha Sen, Ms.Kruti Jay Pancholi PG Student, Asst. Professor, L J I E T, Ahmedabad Abstract : The aim of the thesis is design good quality
Lecture 6: Nonspeech and Music
 EE E682: Speech & Audio Processing & Recognition Lecture 6: Nonspeech and Music 1 Music & nonspeech Dan Ellis Michael Mandel 2 Environmental Sounds Columbia
EE E682: Speech & Audio Processing & Recognition Lecture 6: Nonspeech and Music 1 Music & nonspeech Dan Ellis Michael Mandel 2 Environmental Sounds Columbia
University of Colorado at Boulder ECEN 4/5532. Lab 1 Lab report due on February 2, 2015
 University of Colorado at Boulder ECEN 4/5532 Lab 1 Lab report due on February 2, 2015 This is a MATLAB only lab, and therefore each student needs to turn in her/his own lab report and own programs. 1
University of Colorado at Boulder ECEN 4/5532 Lab 1 Lab report due on February 2, 2015 This is a MATLAB only lab, and therefore each student needs to turn in her/his own lab report and own programs. 1
Signal Processing Toolbox
 Signal Processing Toolbox Perform signal processing, analysis, and algorithm development Signal Processing Toolbox provides industry-standard algorithms for analog and digital signal processing (DSP).
Signal Processing Toolbox Perform signal processing, analysis, and algorithm development Signal Processing Toolbox provides industry-standard algorithms for analog and digital signal processing (DSP).
Tempo and Beat Tracking
 Lecture Music Processing Tempo and Beat Tracking Meinard Müller International Audio Laboratories Erlangen meinard.mueller@audiolabs-erlangen.de Introduction Basic beat tracking task: Given an audio recording
Lecture Music Processing Tempo and Beat Tracking Meinard Müller International Audio Laboratories Erlangen meinard.mueller@audiolabs-erlangen.de Introduction Basic beat tracking task: Given an audio recording
The Channel Vocoder (analyzer):
:") Vocoders 1 The Channel Vocoder (analyzer): The channel vocoder employs a bank of bandpass filters, Each having a bandwidth between 100 Hz and 300 Hz. Typically, 16-20 linear phase FIR filter are used.
Vocoders 1 The Channel Vocoder (analyzer): The channel vocoder employs a bank of bandpass filters, Each having a bandwidth between 100 Hz and 300 Hz. Typically, 16-20 linear phase FIR filter are used.
Audio processing methods on marine mammal vocalizations
 Audio processing methods on marine mammal vocalizations Xanadu Halkias Laboratory for the Recognition and Organization of Speech and Audio http://labrosa.ee.columbia.edu Sound to Signal sound is pressure
Audio processing methods on marine mammal vocalizations Xanadu Halkias Laboratory for the Recognition and Organization of Speech and Audio http://labrosa.ee.columbia.edu Sound to Signal sound is pressure
MFCC AND GMM BASED TAMIL LANGUAGE SPEAKER IDENTIFICATION SYSTEM
 www.advancejournals.org Open Access Scientific Publisher MFCC AND GMM BASED TAMIL LANGUAGE SPEAKER IDENTIFICATION SYSTEM ABSTRACT- P. Santhiya 1, T. Jayasankar 1 1 AUT (BIT campus), Tiruchirappalli, India
www.advancejournals.org Open Access Scientific Publisher MFCC AND GMM BASED TAMIL LANGUAGE SPEAKER IDENTIFICATION SYSTEM ABSTRACT- P. Santhiya 1, T. Jayasankar 1 1 AUT (BIT campus), Tiruchirappalli, India
Music Signal Processing
 Tutorial Music Signal Processing Meinard Müller Saarland University and MPI Informatik meinard@mpi-inf.mpg.de Anssi Klapuri Queen Mary University of London anssi.klapuri@elec.qmul.ac.uk Overview Part I:
Tutorial Music Signal Processing Meinard Müller Saarland University and MPI Informatik meinard@mpi-inf.mpg.de Anssi Klapuri Queen Mary University of London anssi.klapuri@elec.qmul.ac.uk Overview Part I:
SINUSOIDAL MODELING. EE6641 Analysis and Synthesis of Audio Signals. Yi-Wen Liu Nov 3, 2015
 1 SINUSOIDAL MODELING EE6641 Analysis and Synthesis of Audio Signals Yi-Wen Liu Nov 3, 2015 2 Last time: Spectral Estimation Resolution Scenario: multiple peaks in the spectrum Choice of window type and
1 SINUSOIDAL MODELING EE6641 Analysis and Synthesis of Audio Signals Yi-Wen Liu Nov 3, 2015 2 Last time: Spectral Estimation Resolution Scenario: multiple peaks in the spectrum Choice of window type and
Speech and Music Discrimination based on Signal Modulation Spectrum.
 Speech and Music Discrimination based on Signal Modulation Spectrum. Pavel Balabko June 24, 1999 1 Introduction. This work is devoted to the problem of automatic speech and music discrimination. As we
Speech and Music Discrimination based on Signal Modulation Spectrum. Pavel Balabko June 24, 1999 1 Introduction. This work is devoted to the problem of automatic speech and music discrimination. As we
SINOLA: A New Analysis/Synthesis Method using Spectrum Peak Shape Distortion, Phase and Reassigned Spectrum
 SINOLA: A New Analysis/Synthesis Method using Spectrum Peak Shape Distortion, Phase Reassigned Spectrum Geoffroy Peeters, Xavier Rodet Ircam - Centre Georges-Pompidou Analysis/Synthesis Team, 1, pl. Igor
SINOLA: A New Analysis/Synthesis Method using Spectrum Peak Shape Distortion, Phase Reassigned Spectrum Geoffroy Peeters, Xavier Rodet Ircam - Centre Georges-Pompidou Analysis/Synthesis Team, 1, pl. Igor
SPEECH ENHANCEMENT USING PITCH DETECTION APPROACH FOR NOISY ENVIRONMENT
 SPEECH ENHANCEMENT USING PITCH DETECTION APPROACH FOR NOISY ENVIRONMENT RASHMI MAKHIJANI Department of CSE, G. H. R.C.E., Near CRPF Campus,Hingna Road, Nagpur, Maharashtra, India rashmi.makhijani2002@gmail.com
SPEECH ENHANCEMENT USING PITCH DETECTION APPROACH FOR NOISY ENVIRONMENT RASHMI MAKHIJANI Department of CSE, G. H. R.C.E., Near CRPF Campus,Hingna Road, Nagpur, Maharashtra, India rashmi.makhijani2002@gmail.com
Robust Algorithms For Speech Reconstruction On Mobile Devices
 Robust Algorithms For Speech Reconstruction On Mobile Devices XU SHAO A Thesis presented for the degree of Doctor of Philosophy Speech Group School of Computing Sciences University of East Anglia England
Robust Algorithms For Speech Reconstruction On Mobile Devices XU SHAO A Thesis presented for the degree of Doctor of Philosophy Speech Group School of Computing Sciences University of East Anglia England
SPEECH ANALYSIS-SYNTHESIS FOR SPEAKER CHARACTERISTIC MODIFICATION
 M.Tech. Credit Seminar Report, Electronic Systems Group, EE Dept, IIT Bombay, submitted November 04 SPEECH ANALYSIS-SYNTHESIS FOR SPEAKER CHARACTERISTIC MODIFICATION G. Gidda Reddy (Roll no. 04307046)
M.Tech. Credit Seminar Report, Electronic Systems Group, EE Dept, IIT Bombay, submitted November 04 SPEECH ANALYSIS-SYNTHESIS FOR SPEAKER CHARACTERISTIC MODIFICATION G. Gidda Reddy (Roll no. 04307046)
Sound Recognition. ~ CSE 352 Team 3 ~ Jason Park Evan Glover. Kevin Lui Aman Rawat. Prof. Anita Wasilewska
 Sound Recognition ~ CSE 352 Team 3 ~ Jason Park Evan Glover Kevin Lui Aman Rawat Prof. Anita Wasilewska What is Sound? Sound is a vibration that propagates as a typically audible mechanical wave of pressure
Sound Recognition ~ CSE 352 Team 3 ~ Jason Park Evan Glover Kevin Lui Aman Rawat Prof. Anita Wasilewska What is Sound? Sound is a vibration that propagates as a typically audible mechanical wave of pressure
DISCRETE FOURIER TRANSFORM AND FILTER DESIGN
 DISCRETE FOURIER TRANSFORM AND FILTER DESIGN N. C. State University CSC557 Multimedia Computing and Networking Fall 2001 Lecture # 03 Spectrum of a Square Wave 2 Results of Some Filters 3 Notation 4 x[n]
DISCRETE FOURIER TRANSFORM AND FILTER DESIGN N. C. State University CSC557 Multimedia Computing and Networking Fall 2001 Lecture # 03 Spectrum of a Square Wave 2 Results of Some Filters 3 Notation 4 x[n]
Lecture 9: Time & Pitch Scaling
 ELEN E4896 MUSIC SIGNAL PROCESSING Lecture 9: Time & Pitch Scaling 1. Time Scale Modification (TSM) 2. Time-Domain Approaches 3. The Phase Vocoder 4. Sinusoidal Approach Dan Ellis Dept. Electrical Engineering,
ELEN E4896 MUSIC SIGNAL PROCESSING Lecture 9: Time & Pitch Scaling 1. Time Scale Modification (TSM) 2. Time-Domain Approaches 3. The Phase Vocoder 4. Sinusoidal Approach Dan Ellis Dept. Electrical Engineering,
Tempo and Beat Tracking
 Lecture Music Processing Tempo and Beat Tracking Meinard Müller International Audio Laboratories Erlangen meinard.mueller@audiolabs-erlangen.de Book: Fundamentals of Music Processing Meinard Müller Fundamentals
Lecture Music Processing Tempo and Beat Tracking Meinard Müller International Audio Laboratories Erlangen meinard.mueller@audiolabs-erlangen.de Book: Fundamentals of Music Processing Meinard Müller Fundamentals
MUSICAL GENRE CLASSIFICATION OF AUDIO DATA USING SOURCE SEPARATION TECHNIQUES. P.S. Lampropoulou, A.S. Lampropoulos and G.A.
 MUSICAL GENRE CLASSIFICATION OF AUDIO DATA USING SOURCE SEPARATION TECHNIQUES P.S. Lampropoulou, A.S. Lampropoulos and G.A. Tsihrintzis Department of Informatics, University of Piraeus 80 Karaoli & Dimitriou
MUSICAL GENRE CLASSIFICATION OF AUDIO DATA USING SOURCE SEPARATION TECHNIQUES P.S. Lampropoulou, A.S. Lampropoulos and G.A. Tsihrintzis Department of Informatics, University of Piraeus 80 Karaoli & Dimitriou
A Comparative Study of Formant Frequencies Estimation Techniques
 A Comparative Study of Formant Frequencies Estimation Techniques DORRA GARGOURI, Med ALI KAMMOUN and AHMED BEN HAMIDA Unité de traitement de l information et électronique médicale, ENIS University of Sfax
A Comparative Study of Formant Frequencies Estimation Techniques DORRA GARGOURI, Med ALI KAMMOUN and AHMED BEN HAMIDA Unité de traitement de l information et électronique médicale, ENIS University of Sfax
Discrete Fourier Transform (DFT)
") Amplitude Amplitude Discrete Fourier Transform (DFT) DFT transforms the time domain signal samples to the frequency domain components. DFT Signal Spectrum Time Frequency DFT is often used to do frequency
Amplitude Amplitude Discrete Fourier Transform (DFT) DFT transforms the time domain signal samples to the frequency domain components. DFT Signal Spectrum Time Frequency DFT is often used to do frequency
Using Noise Substitution for Backwards-Compatible Audio Codec Improvement
 Using Noise Substitution for Backwards-Compatible Audio Codec Improvement Colin Raffel Experimentalists Anonymous craffel@gmail.com April 11, 2011 Abstract A method for representing error in perceptual
Using Noise Substitution for Backwards-Compatible Audio Codec Improvement Colin Raffel Experimentalists Anonymous craffel@gmail.com April 11, 2011 Abstract A method for representing error in perceptual
Multimedia Signal Processing: Theory and Applications in Speech, Music and Communications
 Brochure More information from http://www.researchandmarkets.com/reports/569388/ Multimedia Signal Processing: Theory and Applications in Speech, Music and Communications Description: Multimedia Signal
Brochure More information from http://www.researchandmarkets.com/reports/569388/ Multimedia Signal Processing: Theory and Applications in Speech, Music and Communications Description: Multimedia Signal
Speech/Non-speech detection Rule-based method using log energy and zero crossing rate
 Digital Speech Processing- Lecture 14A Algorithms for Speech Processing Speech Processing Algorithms Speech/Non-speech detection Rule-based method using log energy and zero crossing rate Single speech
Digital Speech Processing- Lecture 14A Algorithms for Speech Processing Speech Processing Algorithms Speech/Non-speech detection Rule-based method using log energy and zero crossing rate Single speech