Cepstrum alanysis of speech signals
|
|
|
- Shon Lucas
- 5 years ago
- Views:
Transcription
1 Cepstrum alanysis of speech signals ELEC-E5520 Speech and language processing methods Spring 2016 Mikko Kurimo 1 /48
2 Contents Literature and other material Idea and history of cepstrum Cepstrum and LP model Mel cepstrum Pitch detection, formant tracking Phoneme recognition Temporal (a.k.a. delta) features 2 /48
3 Books 1. Cepstrum chapter in John R. Deller, John G. Proakis, and John H. L. Hansen: Discrete-Time Processing of Speech Signals 2. Homomorphic Speech Analysis chapter (5) in L. R. Rabiner and R. W. Schafer: Introduction to Digital Speech Processing (2007). 3 /48
4 Slides 1. This course (modified from Unto K. Laine, 2015) 2. Homomorphic Speech Analysis, lecture (12) in L. R. Rabiner's Digital Speech Processing Course (2015) 4 /48
5 Introduction In linear systems the useful information can easily be separated from additive noise by filtering, if we know in which frequency range each occur. For example: x[n] = x 1 [n]+w[n], where n is index of time x 1 [n] is the useful signal and w [n] high frequency noise lin. operator I [.] is a low-pass filter I [x[n]] = I [x 1 [n]+w[n]] = I [x 1 [n]]+ I [w[n]] x 1 [n] 5 /48
6 But this is much harder, if the signal and noise are convoluted (*). For example the source-filter model of speech production: s[n] = e[n]*h[n] e[n] is the flowing air (source) and h[n] vocal tract (filter) I [s[n]] = I [e[n]*h[n]] will not help, so => We need a new operator that could separate convoluted components! H [s[n]] = H [e[n]*h[n]] = H [e[n]]+h [h[n]] [The complex cepstrum operator transforms convolution into addition.] 6 /48
7 Cepstrum was developed to separate convoluted signals: e[n]*h[n] Fourier: F [e*h ] = E[k] H[k], where k is index of frequency Log[ E H ] = Log[ E ] + Log[ H ] Linear combination may be separated by linear bandpass filtering (called liftering in cepstral domain) 7 /48
8 History Bogert, Healy, and Tukey, The quefrency analysis of time series for echoes: Cepstrum, pseudoautocovariance, cross-cepstrum and saphe cracking In M. Rosenblatt, ed., Proceedings of the Symposium on Time Series Analysisı. J. Wiley & Sons, pp , NY, Tukey = The FFT man spectrum <-> cepstrum "quefrency," "gamnitude," lifter, alanysis, saphe 8 /48
9 Noll A. M., Cepstrum pitch determination, JASA (Journal of Acoustical Society of America) vol. 41, pp , Feb Homomorphic signal processing Oppenheim (1967, 1969) Shafer (1968) Homomorphic same shape + <-> * ; linear domain <-> convolution domain 9 /48
10 Homomorphic System H[s[n]] = H [e[n]*h[n]] = H [e[n]]+h [h[n]] Typically, used to separate noise i.e. impulse e[n] from system response h[n] using operator H, hoping that: H [e[n]] δ[n] ja H [h[n]] h[n]. Cepstrum operator is not an ideal separator, but can approximate a homomorphic system. 10 /48
11 How to recognize speech sounds? A simple procedure: Measure some characteristic features of the signal and train statistical models for them Good features should be: 1.Compact 2.Discriminative for speech sounds 3.Fast to compute 4.Robust for noise 11 /48
12 Frequency analysis Calculate the short-time spectrum in short intervals 12 /48
13 Frequency analysis Calculate the short-time spectrum in short intervals 13 /48
14 Frequency analysis Calculate the short-time spectrum in short intervals 14 /48
15 Computation of MFCC 15 /48 Picture by B.Pellom

16 Approximation of human perception of speech Divide the frequency scale into perceptually equal intervals : Linear below 1 khz, logarithmic above 1 khz Mel scale 16 /48
17 Mel-Cepstrum 17 /48
18 Cepstrum Short-time analysis in frequency scale (vertical direction) MFCC = Mel-Frequency Cepstral Coefficients /48
19 Computation of MFCC 19 /48 Picture by B.Pellom
20 Speech sample Frames: Frames: short short 10ms 10ms windows windows FFT: FFT: power power spectrum spectrum spectrogram spectrogram Filtering: Filtering: mel mel filter filter motivated motivated by by human human ear ear essential essential data data 20 / Features: Features: DCT DCT transform transform mel mel cepstrum cepstrum MFCC MFCC -less -less features features -less correlation



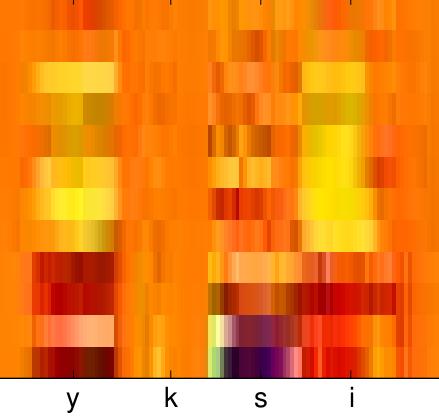
21 5 speech samples Very difficult to recognize speech from this picture /48



22 Power spectrogram Speech recognition possible Lot of data Lot of redundancy Lot of noise 22 /48
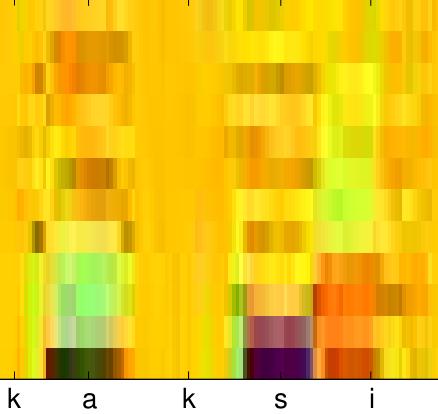
23 Mel spectrogram Speech recognition maybe easier? 10 x less data Less redundancy Less noise 23 /48
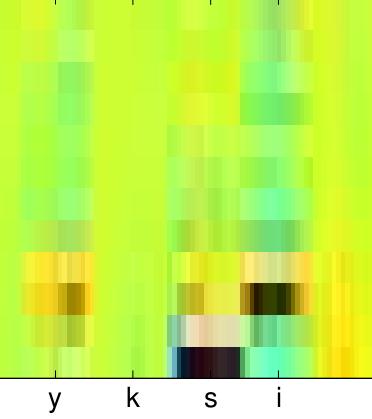
24 Mel spectrogram 24 /48
25 Mel spectrogram 25 /48
26 Mel spectrogram 26 /48
27 Mel spectrogram 27 /48
28 Mel spectrogram 28 /48
29 Mel spectrogram 29 /48

30 Mel-frequency cepstral coefficients (MFCC) 30 /48
31 Background noise? 31 /48
32 Background noise? 32 /48
33 Background noise? 33 /48
34 Background noise? 34 /48
35 Background noise? 35 /48
36 Background noise? 36 /48
37 Background noise? 37 /48
38 Background noise? 38 /48
39 To classify speech sounds by features? Training 1. Extract MFCC from samples of each sound (e.g. phoneme) 2. Train a statistical model (mean and variance) Testing 1. Record new samples and extract MFCC 2. Choose the best-matching model to be the class 39 /48
40 Real and complex cepstrum Classic: Real Cepstrum (RC) symmetric Generalization: Complex Cepstrum (CC) CC saves the phase information of the signal shape Has also an anti-symmetric component CC coefficients are still always real 40 /48
41 Definitions Real Cepstrum: (x[n] infinite sequence in time) c[m] = F -1 [Log[ X[k] ]] [m] = F -1 [Log[ F [x[n]] ]] [m] Complex Cepstrum: y[m] = F -1 [Log[X[k]]] [m] = F -1 [Log[ F [x[n]]]] [m] Note that we take the Magnitude spectrum! 41 /48
42 Linear prediction LP LP-model: G/ (1-a 1 z -1 -a 2 z a p z -p ) = Η [z] x[n] causal and minimum phase (impulse response) y[0] = c[0] = Log[G] (Markel & Gray) LP coefficients can be transformed to cepstral coefficients by: y[0] = Log[G], y[1] = a[1], y[m] = a[m] + t=1, m-1 [(t/m) y[t] a[m-t]] 1 < m p, where a[m] is m's LP coefficient Real cepstrum c[m] can be computed from y[m]: c[0] = y[0], c[m] = y[m]/2, 0 < m p 42 /48
43 Intuition Source-Filter Theory: X(w) = S(w) H(w) Real cepstrum: Log[ X(w) ] = Log[ S(w) ] + Log[ H(w) ] The effects of source and filter in logarithmic spectrum are additive => can be separated by linear transformation, if they occur at different bands Voiced source produces a comb structure (fast variation in frequency), filter adjusts its envelope (slow variation in frequency) Fast and slow variations in frequency can be separated by a new Fourier transform (IFT)! 43 /48
44 Peak Regular comb structure No peak Random variation 44 /48 Picture by L.R.Rabiner

45 Formant tracking: F1,F2,F3 Voiced with pitch Unvoiced no pitch 45 Picture /48 by L.R.Rabiner
46 All have peaks at formant frequencies 46 /48 Picture by L.R.Rabiner

47 Speech sample Frames: Frames: short short 10ms 10ms windows windows FFT: FFT: power power spectrum spectrum spectrogram spectrogram Filtering: Filtering: mel mel filter filter motivated motivated by by human human ear ear essential essential data data 47 / Features: Features: DCT DCT transform transform mel mel cepstrum cepstrum MFCC MFCC -less -less features features -less correlation
48 Delta cepstrum Speech is dynamic, one way to capture that is taking the time derivatives of the short-time cepstrum First derivative = delta cepstrum Second derivative = delta-delta cepstrum The simplest way of computing the derivative is just the difference of two neighboring cepstral vectors: c[t] - c[t-1] The simple difference is very noisy, rather make a least-squares approximation to the local slope (smoothed difference including several neighbors with suitable weights) 48 /48
Signal Processing for Speech Applications - Part 2-1. Signal Processing For Speech Applications - Part 2
 Signal Processing for Speech Applications - Part 2-1 Signal Processing For Speech Applications - Part 2 May 14, 2013 Signal Processing for Speech Applications - Part 2-2 References Huang et al., Chapter
Signal Processing for Speech Applications - Part 2-1 Signal Processing For Speech Applications - Part 2 May 14, 2013 Signal Processing for Speech Applications - Part 2-2 References Huang et al., Chapter
Speech Signal Analysis
 Speech Signal Analysis Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 2&3 14,18 January 216 ASR Lectures 2&3 Speech Signal Analysis 1 Overview Speech Signal Analysis for
Speech Signal Analysis Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 2&3 14,18 January 216 ASR Lectures 2&3 Speech Signal Analysis 1 Overview Speech Signal Analysis for
Mel Spectrum Analysis of Speech Recognition using Single Microphone
 International Journal of Engineering Research in Electronics and Communication Mel Spectrum Analysis of Speech Recognition using Single Microphone [1] Lakshmi S.A, [2] Cholavendan M [1] PG Scholar, Sree
International Journal of Engineering Research in Electronics and Communication Mel Spectrum Analysis of Speech Recognition using Single Microphone [1] Lakshmi S.A, [2] Cholavendan M [1] PG Scholar, Sree
Topic. Spectrogram Chromagram Cesptrogram. Bryan Pardo, 2008, Northwestern University EECS 352: Machine Perception of Music and Audio
 Topic Spectrogram Chromagram Cesptrogram Short time Fourier Transform Break signal into windows Calculate DFT of each window The Spectrogram spectrogram(y,1024,512,1024,fs,'yaxis'); A series of short term
Topic Spectrogram Chromagram Cesptrogram Short time Fourier Transform Break signal into windows Calculate DFT of each window The Spectrogram spectrogram(y,1024,512,1024,fs,'yaxis'); A series of short term
speech signal S(n). This involves a transformation of S(n) into another signal or a set of signals
. This involves a transformation of S(n) into another signal or a set of signals") 16 3. SPEECH ANALYSIS 3.1 INTRODUCTION TO SPEECH ANALYSIS Many speech processing [22] applications exploits speech production and perception to accomplish speech analysis. By speech analysis we extract
16 3. SPEECH ANALYSIS 3.1 INTRODUCTION TO SPEECH ANALYSIS Many speech processing [22] applications exploits speech production and perception to accomplish speech analysis. By speech analysis we extract
I D I A P. On Factorizing Spectral Dynamics for Robust Speech Recognition R E S E A R C H R E P O R T. Iain McCowan a Hemant Misra a,b
 R E S E A R C H R E P O R T I D I A P On Factorizing Spectral Dynamics for Robust Speech Recognition a Vivek Tyagi Hervé Bourlard a,b IDIAP RR 3-33 June 23 Iain McCowan a Hemant Misra a,b to appear in
R E S E A R C H R E P O R T I D I A P On Factorizing Spectral Dynamics for Robust Speech Recognition a Vivek Tyagi Hervé Bourlard a,b IDIAP RR 3-33 June 23 Iain McCowan a Hemant Misra a,b to appear in
Speech Synthesis using Mel-Cepstral Coefficient Feature
 Speech Synthesis using Mel-Cepstral Coefficient Feature By Lu Wang Senior Thesis in Electrical Engineering University of Illinois at Urbana-Champaign Advisor: Professor Mark Hasegawa-Johnson May 2018 Abstract
Speech Synthesis using Mel-Cepstral Coefficient Feature By Lu Wang Senior Thesis in Electrical Engineering University of Illinois at Urbana-Champaign Advisor: Professor Mark Hasegawa-Johnson May 2018 Abstract
E : Lecture 8 Source-Filter Processing. E : Lecture 8 Source-Filter Processing / 21
 E85.267: Lecture 8 Source-Filter Processing E85.267: Lecture 8 Source-Filter Processing 21-4-1 1 / 21 Source-filter analysis/synthesis n f Spectral envelope Spectral envelope Analysis Source signal n 1
E85.267: Lecture 8 Source-Filter Processing E85.267: Lecture 8 Source-Filter Processing 21-4-1 1 / 21 Source-filter analysis/synthesis n f Spectral envelope Spectral envelope Analysis Source signal n 1
Speech Synthesis; Pitch Detection and Vocoders
 Speech Synthesis; Pitch Detection and Vocoders Tai-Shih Chi ( 冀泰石 ) Department of Communication Engineering National Chiao Tung University May. 29, 2008 Speech Synthesis Basic components of the text-to-speech
Speech Synthesis; Pitch Detection and Vocoders Tai-Shih Chi ( 冀泰石 ) Department of Communication Engineering National Chiao Tung University May. 29, 2008 Speech Synthesis Basic components of the text-to-speech
Speech Production. Automatic Speech Recognition handout (1) Jan - Mar 2009 Revision : 1.1. Speech Communication. Spectrogram. Waveform.
 Jan - Mar 2009 Revision : 1.1. Speech Communication. Spectrogram. Waveform.") Speech Production Automatic Speech Recognition handout () Jan - Mar 29 Revision :. Speech Signal Processing and Feature Extraction lips teeth nasal cavity oral cavity tongue lang S( Ω) pharynx larynx vocal
Speech Production Automatic Speech Recognition handout () Jan - Mar 29 Revision :. Speech Signal Processing and Feature Extraction lips teeth nasal cavity oral cavity tongue lang S( Ω) pharynx larynx vocal
International Journal of Engineering and Techniques - Volume 1 Issue 6, Nov Dec 2015
 RESEARCH ARTICLE OPEN ACCESS A Comparative Study on Feature Extraction Technique for Isolated Word Speech Recognition Easwari.N 1, Ponmuthuramalingam.P 2 1,2 (PG & Research Department of Computer Science,
RESEARCH ARTICLE OPEN ACCESS A Comparative Study on Feature Extraction Technique for Isolated Word Speech Recognition Easwari.N 1, Ponmuthuramalingam.P 2 1,2 (PG & Research Department of Computer Science,
Isolated Digit Recognition Using MFCC AND DTW
 MarutiLimkar a, RamaRao b & VidyaSagvekar c a Terna collegeof Engineering, Department of Electronics Engineering, Mumbai University, India b Vidyalankar Institute of Technology, Department ofelectronics
MarutiLimkar a, RamaRao b & VidyaSagvekar c a Terna collegeof Engineering, Department of Electronics Engineering, Mumbai University, India b Vidyalankar Institute of Technology, Department ofelectronics
An Improved Voice Activity Detection Based on Deep Belief Networks
 e-issn 2455 1392 Volume 2 Issue 4, April 2016 pp. 676-683 Scientific Journal Impact Factor : 3.468 http://www.ijcter.com An Improved Voice Activity Detection Based on Deep Belief Networks Shabeeba T. K.
e-issn 2455 1392 Volume 2 Issue 4, April 2016 pp. 676-683 Scientific Journal Impact Factor : 3.468 http://www.ijcter.com An Improved Voice Activity Detection Based on Deep Belief Networks Shabeeba T. K.
NCCF ACF. cepstrum coef. error signal > samples
 ESTIMATION OF FUNDAMENTAL FREQUENCY IN SPEECH Petr Motl»cek 1 Abstract This paper presents an application of one method for improving fundamental frequency detection from the speech. The method is based
ESTIMATION OF FUNDAMENTAL FREQUENCY IN SPEECH Petr Motl»cek 1 Abstract This paper presents an application of one method for improving fundamental frequency detection from the speech. The method is based
Advanced audio analysis. Martin Gasser
 Advanced audio analysis Martin Gasser Motivation Which methods are common in MIR research? How can we parameterize audio signals? Interesting dimensions of audio: Spectral/ time/melody structure, high
Advanced audio analysis Martin Gasser Motivation Which methods are common in MIR research? How can we parameterize audio signals? Interesting dimensions of audio: Spectral/ time/melody structure, high
Automatic Speech Recognition handout (1)
") Automatic Speech Recognition handout (1) Jan - Mar 2012 Revision : 1.1 Speech Signal Processing and Feature Extraction Hiroshi Shimodaira (h.shimodaira@ed.ac.uk) Speech Communication Intention Language
Automatic Speech Recognition handout (1) Jan - Mar 2012 Revision : 1.1 Speech Signal Processing and Feature Extraction Hiroshi Shimodaira (h.shimodaira@ed.ac.uk) Speech Communication Intention Language
I D I A P. Mel-Cepstrum Modulation Spectrum (MCMS) Features for Robust ASR R E S E A R C H R E P O R T. Iain McCowan a Hemant Misra a,b
 Features for Robust ASR R E S E A R C H R E P O R T. Iain McCowan a Hemant Misra a,b") R E S E A R C H R E P O R T I D I A P Mel-Cepstrum Modulation Spectrum (MCMS) Features for Robust ASR a Vivek Tyagi Hervé Bourlard a,b IDIAP RR 3-47 September 23 Iain McCowan a Hemant Misra a,b to appear
R E S E A R C H R E P O R T I D I A P Mel-Cepstrum Modulation Spectrum (MCMS) Features for Robust ASR a Vivek Tyagi Hervé Bourlard a,b IDIAP RR 3-47 September 23 Iain McCowan a Hemant Misra a,b to appear
Quantification of glottal and voiced speech harmonicsto-noise ratios using cepstral-based estimation
 Quantification of glottal and voiced speech harmonicsto-noise ratios using cepstral-based estimation Peter J. Murphy and Olatunji O. Akande, Department of Electronic and Computer Engineering University
Quantification of glottal and voiced speech harmonicsto-noise ratios using cepstral-based estimation Peter J. Murphy and Olatunji O. Akande, Department of Electronic and Computer Engineering University
Performance Analysis of MFCC and LPCC Techniques in Automatic Speech Recognition
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume - 3 Issue - 8 August, 2014 Page No. 7727-7732 Performance Analysis of MFCC and LPCC Techniques in Automatic
www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume - 3 Issue - 8 August, 2014 Page No. 7727-7732 Performance Analysis of MFCC and LPCC Techniques in Automatic
Lecture 6: Speech modeling and synthesis
 EE E682: Speech & Audio Processing & Recognition Lecture 6: Speech modeling and synthesis 1 2 3 4 5 Modeling speech signals Spectral and cepstral models Linear Predictive models (LPC) Other signal models
EE E682: Speech & Audio Processing & Recognition Lecture 6: Speech modeling and synthesis 1 2 3 4 5 Modeling speech signals Spectral and cepstral models Linear Predictive models (LPC) Other signal models
University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005
 University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005 Lecture 5 Slides Jan 26 th, 2005 Outline of Today s Lecture Announcements Filter-bank analysis
University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005 Lecture 5 Slides Jan 26 th, 2005 Outline of Today s Lecture Announcements Filter-bank analysis
Lecture 5: Speech modeling. The speech signal
 EE E68: Speech & Audio Processing & Recognition Lecture 5: Speech modeling 1 3 4 5 Modeling speech signals Spectral and cepstral models Linear Predictive models (LPC) Other signal models Speech synthesis
EE E68: Speech & Audio Processing & Recognition Lecture 5: Speech modeling 1 3 4 5 Modeling speech signals Spectral and cepstral models Linear Predictive models (LPC) Other signal models Speech synthesis
CS 188: Artificial Intelligence Spring Speech in an Hour
 CS 188: Artificial Intelligence Spring 2006 Lecture 19: Speech Recognition 3/23/2006 Dan Klein UC Berkeley Many slides from Dan Jurafsky Speech in an Hour Speech input is an acoustic wave form s p ee ch
CS 188: Artificial Intelligence Spring 2006 Lecture 19: Speech Recognition 3/23/2006 Dan Klein UC Berkeley Many slides from Dan Jurafsky Speech in an Hour Speech input is an acoustic wave form s p ee ch
MFCC AND GMM BASED TAMIL LANGUAGE SPEAKER IDENTIFICATION SYSTEM
 www.advancejournals.org Open Access Scientific Publisher MFCC AND GMM BASED TAMIL LANGUAGE SPEAKER IDENTIFICATION SYSTEM ABSTRACT- P. Santhiya 1, T. Jayasankar 1 1 AUT (BIT campus), Tiruchirappalli, India
www.advancejournals.org Open Access Scientific Publisher MFCC AND GMM BASED TAMIL LANGUAGE SPEAKER IDENTIFICATION SYSTEM ABSTRACT- P. Santhiya 1, T. Jayasankar 1 1 AUT (BIT campus), Tiruchirappalli, India
Adaptive Filters Linear Prediction
 Adaptive Filters Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Institute of Electrical and Information Engineering Digital Signal Processing and System Theory Slide 1 Contents
Adaptive Filters Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Institute of Electrical and Information Engineering Digital Signal Processing and System Theory Slide 1 Contents
SPEECH ENHANCEMENT USING PITCH DETECTION APPROACH FOR NOISY ENVIRONMENT
 SPEECH ENHANCEMENT USING PITCH DETECTION APPROACH FOR NOISY ENVIRONMENT RASHMI MAKHIJANI Department of CSE, G. H. R.C.E., Near CRPF Campus,Hingna Road, Nagpur, Maharashtra, India rashmi.makhijani2002@gmail.com
SPEECH ENHANCEMENT USING PITCH DETECTION APPROACH FOR NOISY ENVIRONMENT RASHMI MAKHIJANI Department of CSE, G. H. R.C.E., Near CRPF Campus,Hingna Road, Nagpur, Maharashtra, India rashmi.makhijani2002@gmail.com
AN ANALYSIS OF SPEECH RECOGNITION PERFORMANCE BASED UPON NETWORK LAYERS AND TRANSFER FUNCTIONS
 AN ANALYSIS OF SPEECH RECOGNITION PERFORMANCE BASED UPON NETWORK LAYERS AND TRANSFER FUNCTIONS Kuldeep Kumar 1, R. K. Aggarwal 1 and Ankita Jain 2 1 Department of Computer Engineering, National Institute
AN ANALYSIS OF SPEECH RECOGNITION PERFORMANCE BASED UPON NETWORK LAYERS AND TRANSFER FUNCTIONS Kuldeep Kumar 1, R. K. Aggarwal 1 and Ankita Jain 2 1 Department of Computer Engineering, National Institute
Learning to Unlearn and Relearn Speech Signal Processing using Neural Networks: current and future perspectives
 Learning to Unlearn and Relearn Speech Signal Processing using Neural Networks: current and future perspectives Mathew Magimai Doss Collaborators: Vinayak Abrol, Selen Hande Kabil, Hannah Muckenhirn, Dimitri
Learning to Unlearn and Relearn Speech Signal Processing using Neural Networks: current and future perspectives Mathew Magimai Doss Collaborators: Vinayak Abrol, Selen Hande Kabil, Hannah Muckenhirn, Dimitri
Speech Coding using Linear Prediction
 Speech Coding using Linear Prediction Jesper Kjær Nielsen Aalborg University and Bang & Olufsen jkn@es.aau.dk September 10, 2015 1 Background Speech is generated when air is pushed from the lungs through
Speech Coding using Linear Prediction Jesper Kjær Nielsen Aalborg University and Bang & Olufsen jkn@es.aau.dk September 10, 2015 1 Background Speech is generated when air is pushed from the lungs through
EVALUATION OF MFCC ESTIMATION TECHNIQUES FOR MUSIC SIMILARITY
 EVALUATION OF MFCC ESTIMATION TECHNIQUES FOR MUSIC SIMILARITY Jesper Højvang Jensen 1, Mads Græsbøll Christensen 1, Manohar N. Murthi, and Søren Holdt Jensen 1 1 Department of Communication Technology,
EVALUATION OF MFCC ESTIMATION TECHNIQUES FOR MUSIC SIMILARITY Jesper Højvang Jensen 1, Mads Græsbøll Christensen 1, Manohar N. Murthi, and Søren Holdt Jensen 1 1 Department of Communication Technology,
International Journal of Modern Trends in Engineering and Research e-issn No.: , Date: 2-4 July, 2015
 International Journal of Modern Trends in Engineering and Research www.ijmter.com e-issn No.:2349-9745, Date: 2-4 July, 2015 Analysis of Speech Signal Using Graphic User Interface Solly Joy 1, Savitha
International Journal of Modern Trends in Engineering and Research www.ijmter.com e-issn No.:2349-9745, Date: 2-4 July, 2015 Analysis of Speech Signal Using Graphic User Interface Solly Joy 1, Savitha
Speech and Music Discrimination based on Signal Modulation Spectrum.
 Speech and Music Discrimination based on Signal Modulation Spectrum. Pavel Balabko June 24, 1999 1 Introduction. This work is devoted to the problem of automatic speech and music discrimination. As we
Speech and Music Discrimination based on Signal Modulation Spectrum. Pavel Balabko June 24, 1999 1 Introduction. This work is devoted to the problem of automatic speech and music discrimination. As we
Effect of parameters setting on performance of discrete component removal (DCR) methods for bearing faults detection
 methods for bearing faults detection") Effect of parameters setting on performance of discrete component removal (DCR) methods for bearing faults detection Bovic Kilundu, Agusmian Partogi Ompusunggu 2, Faris Elasha 3, and David Mba 4,2 Flanders
Effect of parameters setting on performance of discrete component removal (DCR) methods for bearing faults detection Bovic Kilundu, Agusmian Partogi Ompusunggu 2, Faris Elasha 3, and David Mba 4,2 Flanders
Mel- frequency cepstral coefficients (MFCCs) and gammatone filter banks
 and gammatone filter banks") SGN- 14006 Audio and Speech Processing Pasi PerQlä SGN- 14006 2015 Mel- frequency cepstral coefficients (MFCCs) and gammatone filter banks Slides for this lecture are based on those created by Katariina
SGN- 14006 Audio and Speech Processing Pasi PerQlä SGN- 14006 2015 Mel- frequency cepstral coefficients (MFCCs) and gammatone filter banks Slides for this lecture are based on those created by Katariina
Applications of Music Processing
 Lecture Music Processing Applications of Music Processing Christian Dittmar International Audio Laboratories Erlangen christian.dittmar@audiolabs-erlangen.de Singing Voice Detection Important pre-requisite
Lecture Music Processing Applications of Music Processing Christian Dittmar International Audio Laboratories Erlangen christian.dittmar@audiolabs-erlangen.de Singing Voice Detection Important pre-requisite
SYNTHETIC SPEECH DETECTION USING TEMPORAL MODULATION FEATURE
 SYNTHETIC SPEECH DETECTION USING TEMPORAL MODULATION FEATURE Zhizheng Wu 1,2, Xiong Xiao 2, Eng Siong Chng 1,2, Haizhou Li 1,2,3 1 School of Computer Engineering, Nanyang Technological University (NTU),
SYNTHETIC SPEECH DETECTION USING TEMPORAL MODULATION FEATURE Zhizheng Wu 1,2, Xiong Xiao 2, Eng Siong Chng 1,2, Haizhou Li 1,2,3 1 School of Computer Engineering, Nanyang Technological University (NTU),
Spectral estimation using higher-lag autocorrelation coefficients with applications to speech recognition
 Spectral estimation using higher-lag autocorrelation coefficients with applications to speech recognition Author Shannon, Ben, Paliwal, Kuldip Published 25 Conference Title The 8th International Symposium
Spectral estimation using higher-lag autocorrelation coefficients with applications to speech recognition Author Shannon, Ben, Paliwal, Kuldip Published 25 Conference Title The 8th International Symposium
Evaluation of MFCC Estimation Techniques for Music Similarity Jensen, Jesper Højvang; Christensen, Mads Græsbøll; Murthi, Manohar; Jensen, Søren Holdt
 Aalborg Universitet Evaluation of MFCC Estimation Techniques for Music Similarity Jensen, Jesper Højvang; Christensen, Mads Græsbøll; Murthi, Manohar; Jensen, Søren Holdt Published in: Proceedings of the
Aalborg Universitet Evaluation of MFCC Estimation Techniques for Music Similarity Jensen, Jesper Højvang; Christensen, Mads Græsbøll; Murthi, Manohar; Jensen, Søren Holdt Published in: Proceedings of the
Digital Signal Processing
 COMP ENG 4TL4: Digital Signal Processing Notes for Lecture #27 Tuesday, November 11, 23 6. SPECTRAL ANALYSIS AND ESTIMATION 6.1 Introduction to Spectral Analysis and Estimation The discrete-time Fourier
COMP ENG 4TL4: Digital Signal Processing Notes for Lecture #27 Tuesday, November 11, 23 6. SPECTRAL ANALYSIS AND ESTIMATION 6.1 Introduction to Spectral Analysis and Estimation The discrete-time Fourier
Project 0: Part 2 A second hands-on lab on Speech Processing Frequency-domain processing
 Project : Part 2 A second hands-on lab on Speech Processing Frequency-domain processing February 24, 217 During this lab, you will have a first contact on frequency domain analysis of speech signals. You
Project : Part 2 A second hands-on lab on Speech Processing Frequency-domain processing February 24, 217 During this lab, you will have a first contact on frequency domain analysis of speech signals. You
Adaptive Filters Application of Linear Prediction
 Adaptive Filters Application of Linear Prediction Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Electrical Engineering and Information Technology Digital Signal Processing
Adaptive Filters Application of Linear Prediction Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Electrical Engineering and Information Technology Digital Signal Processing
Auditory Based Feature Vectors for Speech Recognition Systems
 Auditory Based Feature Vectors for Speech Recognition Systems Dr. Waleed H. Abdulla Electrical & Computer Engineering Department The University of Auckland, New Zealand [w.abdulla@auckland.ac.nz] 1 Outlines
Auditory Based Feature Vectors for Speech Recognition Systems Dr. Waleed H. Abdulla Electrical & Computer Engineering Department The University of Auckland, New Zealand [w.abdulla@auckland.ac.nz] 1 Outlines
GLOTTAL EXCITATION EXTRACTION OF VOICED SPEECH - JOINTLY PARAMETRIC AND NONPARAMETRIC APPROACHES
 Clemson University TigerPrints All Dissertations Dissertations 5-2012 GLOTTAL EXCITATION EXTRACTION OF VOICED SPEECH - JOINTLY PARAMETRIC AND NONPARAMETRIC APPROACHES Yiqiao Chen Clemson University, rls_lms@yahoo.com
Clemson University TigerPrints All Dissertations Dissertations 5-2012 GLOTTAL EXCITATION EXTRACTION OF VOICED SPEECH - JOINTLY PARAMETRIC AND NONPARAMETRIC APPROACHES Yiqiao Chen Clemson University, rls_lms@yahoo.com
A History of Cepstrum Analysis and its Application to Mechanical Problems
 A History of Cepstrum Analysis and its Application to Mechanical Problems Robert B Randall 1 1 School of Mechanical and Manufacturing Engineering University of New South Wales, Sydney 252, Australia {b.randall@unsw.edu.au}
A History of Cepstrum Analysis and its Application to Mechanical Problems Robert B Randall 1 1 School of Mechanical and Manufacturing Engineering University of New South Wales, Sydney 252, Australia {b.randall@unsw.edu.au}
Lecture 5: Speech modeling
 CSC 836: Speech & Audio Understanding Lecture 5: Speech modeling Dan Ellis CUNY Graduate Center, Computer Science Program http://mr-pc.org/t/csc836 With much content from Dan Ellis
CSC 836: Speech & Audio Understanding Lecture 5: Speech modeling Dan Ellis CUNY Graduate Center, Computer Science Program http://mr-pc.org/t/csc836 With much content from Dan Ellis
Speech Recognition using FIR Wiener Filter
 Speech Recognition using FIR Wiener Filter Deepak 1, Vikas Mittal 2 1 Department of Electronics & Communication Engineering, Maharishi Markandeshwar University, Mullana (Ambala), INDIA 2 Department of
Speech Recognition using FIR Wiener Filter Deepak 1, Vikas Mittal 2 1 Department of Electronics & Communication Engineering, Maharishi Markandeshwar University, Mullana (Ambala), INDIA 2 Department of
Text and Language Independent Speaker Identification By Using Short-Time Low Quality Signals
 Text and Language Independent Speaker Identification By Using Short-Time Low Quality Signals Maurizio Bocca*, Reino Virrankoski**, Heikki Koivo* * Control Engineering Group Faculty of Electronics, Communications
Text and Language Independent Speaker Identification By Using Short-Time Low Quality Signals Maurizio Bocca*, Reino Virrankoski**, Heikki Koivo* * Control Engineering Group Faculty of Electronics, Communications
SOUND SOURCE RECOGNITION AND MODELING
 SOUND SOURCE RECOGNITION AND MODELING CASA seminar, summer 2000 Antti Eronen antti.eronen@tut.fi Contents: Basics of human sound source recognition Timbre Voice recognition Recognition of environmental
SOUND SOURCE RECOGNITION AND MODELING CASA seminar, summer 2000 Antti Eronen antti.eronen@tut.fi Contents: Basics of human sound source recognition Timbre Voice recognition Recognition of environmental
T Automatic Speech Recognition: From Theory to Practice
 Automatic Speech Recognition: From Theory to Practice http://www.cis.hut.fi/opinnot// September 27, 2004 Prof. Bryan Pellom Department of Computer Science Center for Spoken Language Research University
Automatic Speech Recognition: From Theory to Practice http://www.cis.hut.fi/opinnot// September 27, 2004 Prof. Bryan Pellom Department of Computer Science Center for Spoken Language Research University
Design and Implementation of Speech Recognition Systems
 Design and Implementation of Speech Recognition Systems Spring 2013 Class 3: Feature Computation 30 Jan 2013 1 First Step: Feature Extraction Speech recognition is a type of pattern recognition problem
Design and Implementation of Speech Recognition Systems Spring 2013 Class 3: Feature Computation 30 Jan 2013 1 First Step: Feature Extraction Speech recognition is a type of pattern recognition problem
Automatic Text-Independent. Speaker. Recognition Approaches Using Binaural Inputs
 Automatic Text-Independent Speaker Recognition Approaches Using Binaural Inputs Karim Youssef, Sylvain Argentieri and Jean-Luc Zarader 1 Outline Automatic speaker recognition: introduction Designed systems
Automatic Text-Independent Speaker Recognition Approaches Using Binaural Inputs Karim Youssef, Sylvain Argentieri and Jean-Luc Zarader 1 Outline Automatic speaker recognition: introduction Designed systems
Performance analysis of voice activity detection algorithm for robust speech recognition system under different noisy environment
 BABU et al: VOICE ACTIVITY DETECTION ALGORITHM FOR ROBUST SPEECH RECOGNITION SYSTEM Journal of Scientific & Industrial Research Vol. 69, July 2010, pp. 515-522 515 Performance analysis of voice activity
BABU et al: VOICE ACTIVITY DETECTION ALGORITHM FOR ROBUST SPEECH RECOGNITION SYSTEM Journal of Scientific & Industrial Research Vol. 69, July 2010, pp. 515-522 515 Performance analysis of voice activity
VOICE COMMAND RECOGNITION SYSTEM BASED ON MFCC AND DTW
 VOICE COMMAND RECOGNITION SYSTEM BASED ON MFCC AND DTW ANJALI BALA * Kurukshetra University, Department of Instrumentation & Control Engineering., H.E.C* Jagadhri, Haryana, 135003, India sachdevaanjali26@gmail.com
VOICE COMMAND RECOGNITION SYSTEM BASED ON MFCC AND DTW ANJALI BALA * Kurukshetra University, Department of Instrumentation & Control Engineering., H.E.C* Jagadhri, Haryana, 135003, India sachdevaanjali26@gmail.com
Speech Enhancement using Wiener filtering
 Speech Enhancement using Wiener filtering S. Chirtmay and M. Tahernezhadi Department of Electrical Engineering Northern Illinois University DeKalb, IL 60115 ABSTRACT The problem of reducing the disturbing
Speech Enhancement using Wiener filtering S. Chirtmay and M. Tahernezhadi Department of Electrical Engineering Northern Illinois University DeKalb, IL 60115 ABSTRACT The problem of reducing the disturbing
Perceptive Speech Filters for Speech Signal Noise Reduction
 International Journal of Computer Applications (975 8887) Volume 55 - No. *, October 22 Perceptive Speech Filters for Speech Signal Noise Reduction E.S. Kasthuri and A.P. James School of Computer Science
International Journal of Computer Applications (975 8887) Volume 55 - No. *, October 22 Perceptive Speech Filters for Speech Signal Noise Reduction E.S. Kasthuri and A.P. James School of Computer Science
Electronic disguised voice identification based on Mel- Frequency Cepstral Coefficient analysis
 International Journal of Scientific and Research Publications, Volume 5, Issue 11, November 2015 412 Electronic disguised voice identification based on Mel- Frequency Cepstral Coefficient analysis Shalate
International Journal of Scientific and Research Publications, Volume 5, Issue 11, November 2015 412 Electronic disguised voice identification based on Mel- Frequency Cepstral Coefficient analysis Shalate
A Comparative Performance of Various Speech Analysis-Synthesis Techniques
 International Journal of Signal Processing Systems Vol. 2, No. 1 June 2014 A Comparative Performance of Various Speech Analysis-Synthesis Techniques Ankita N. Chadha, Jagannath H. Nirmal, and Pramod Kachare
International Journal of Signal Processing Systems Vol. 2, No. 1 June 2014 A Comparative Performance of Various Speech Analysis-Synthesis Techniques Ankita N. Chadha, Jagannath H. Nirmal, and Pramod Kachare
Singing Voice Detection. Applications of Music Processing. Singing Voice Detection. Singing Voice Detection. Singing Voice Detection
 Detection Lecture usic Processing Applications of usic Processing Christian Dittmar International Audio Laboratories Erlangen christian.dittmar@audiolabs-erlangen.de Important pre-requisite for: usic segmentation
Detection Lecture usic Processing Applications of usic Processing Christian Dittmar International Audio Laboratories Erlangen christian.dittmar@audiolabs-erlangen.de Important pre-requisite for: usic segmentation
A Comparative Study of Formant Frequencies Estimation Techniques
 A Comparative Study of Formant Frequencies Estimation Techniques DORRA GARGOURI, Med ALI KAMMOUN and AHMED BEN HAMIDA Unité de traitement de l information et électronique médicale, ENIS University of Sfax
A Comparative Study of Formant Frequencies Estimation Techniques DORRA GARGOURI, Med ALI KAMMOUN and AHMED BEN HAMIDA Unité de traitement de l information et électronique médicale, ENIS University of Sfax
Robust Algorithms For Speech Reconstruction On Mobile Devices
 Robust Algorithms For Speech Reconstruction On Mobile Devices XU SHAO A Thesis presented for the degree of Doctor of Philosophy Speech Group School of Computing Sciences University of East Anglia England
Robust Algorithms For Speech Reconstruction On Mobile Devices XU SHAO A Thesis presented for the degree of Doctor of Philosophy Speech Group School of Computing Sciences University of East Anglia England
PR No. 119 DIGITAL SIGNAL PROCESSING XVIII. Academic Research Staff. Prof. Alan V. Oppenheim Prof. James H. McClellan.
 XVIII. DIGITAL SIGNAL PROCESSING Academic Research Staff Prof. Alan V. Oppenheim Prof. James H. McClellan Graduate Students Bir Bhanu Gary E. Kopec Thomas F. Quatieri, Jr. Patrick W. Bosshart Jae S. Lim
XVIII. DIGITAL SIGNAL PROCESSING Academic Research Staff Prof. Alan V. Oppenheim Prof. James H. McClellan Graduate Students Bir Bhanu Gary E. Kopec Thomas F. Quatieri, Jr. Patrick W. Bosshart Jae S. Lim
Dimension Reduction of the Modulation Spectrogram for Speaker Verification
 Dimension Reduction of the Modulation Spectrogram for Speaker Verification Tomi Kinnunen Speech and Image Processing Unit Department of Computer Science University of Joensuu, Finland Kong Aik Lee and
Dimension Reduction of the Modulation Spectrogram for Speaker Verification Tomi Kinnunen Speech and Image Processing Unit Department of Computer Science University of Joensuu, Finland Kong Aik Lee and
IMPLEMENTATION OF SPEECH RECOGNITION SYSTEM USING DSP PROCESSOR ADSP2181
 IMPLEMENTATION OF SPEECH RECOGNITION SYSTEM USING DSP PROCESSOR ADSP2181 1 KALPANA JOSHI, 2 NILIMA KOLHARE & 3 V.M.PANDHARIPANDE 1&2 Dept.of Electronics and Telecommunication Engg, Government College of
IMPLEMENTATION OF SPEECH RECOGNITION SYSTEM USING DSP PROCESSOR ADSP2181 1 KALPANA JOSHI, 2 NILIMA KOLHARE & 3 V.M.PANDHARIPANDE 1&2 Dept.of Electronics and Telecommunication Engg, Government College of
A CONSTRUCTION OF COMPACT MFCC-TYPE FEATURES USING SHORT-TIME STATISTICS FOR APPLICATIONS IN AUDIO SEGMENTATION
 17th European Signal Processing Conference (EUSIPCO 2009) Glasgow, Scotland, August 24-28, 2009 A CONSTRUCTION OF COMPACT MFCC-TYPE FEATURES USING SHORT-TIME STATISTICS FOR APPLICATIONS IN AUDIO SEGMENTATION
17th European Signal Processing Conference (EUSIPCO 2009) Glasgow, Scotland, August 24-28, 2009 A CONSTRUCTION OF COMPACT MFCC-TYPE FEATURES USING SHORT-TIME STATISTICS FOR APPLICATIONS IN AUDIO SEGMENTATION
APPLICATIONS OF DSP OBJECTIVES
 APPLICATIONS OF DSP OBJECTIVES This lecture will discuss the following: Introduce analog and digital waveform coding Introduce Pulse Coded Modulation Consider speech-coding principles Introduce the channel
APPLICATIONS OF DSP OBJECTIVES This lecture will discuss the following: Introduce analog and digital waveform coding Introduce Pulse Coded Modulation Consider speech-coding principles Introduce the channel
EE482: Digital Signal Processing Applications
 Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 14 Quiz 04 Review 14/04/07 http://www.ee.unlv.edu/~b1morris/ee482/
Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 14 Quiz 04 Review 14/04/07 http://www.ee.unlv.edu/~b1morris/ee482/
Introducing COVAREP: A collaborative voice analysis repository for speech technologies
 Introducing COVAREP: A collaborative voice analysis repository for speech technologies John Kane Wednesday November 27th, 2013 SIGMEDIA-group TCD COVAREP - Open-source speech processing repository 1 Introduction
Introducing COVAREP: A collaborative voice analysis repository for speech technologies John Kane Wednesday November 27th, 2013 SIGMEDIA-group TCD COVAREP - Open-source speech processing repository 1 Introduction
Linguistic Phonetics. Spectral Analysis
 24.963 Linguistic Phonetics Spectral Analysis 4 4 Frequency (Hz) 1 Reading for next week: Liljencrants & Lindblom 1972. Assignment: Lip-rounding assignment, due 1/15. 2 Spectral analysis techniques There
24.963 Linguistic Phonetics Spectral Analysis 4 4 Frequency (Hz) 1 Reading for next week: Liljencrants & Lindblom 1972. Assignment: Lip-rounding assignment, due 1/15. 2 Spectral analysis techniques There
SGN Audio and Speech Processing
 Introduction 1 Course goals Introduction 2 SGN 14006 Audio and Speech Processing Lectures, Fall 2014 Anssi Klapuri Tampere University of Technology! Learn basics of audio signal processing Basic operations
Introduction 1 Course goals Introduction 2 SGN 14006 Audio and Speech Processing Lectures, Fall 2014 Anssi Klapuri Tampere University of Technology! Learn basics of audio signal processing Basic operations
CHAPTER 2 FIR ARCHITECTURE FOR THE FILTER BANK OF SPEECH PROCESSOR
 22 CHAPTER 2 FIR ARCHITECTURE FOR THE FILTER BANK OF SPEECH PROCESSOR 2.1 INTRODUCTION A CI is a device that can provide a sense of sound to people who are deaf or profoundly hearing-impaired. Filters
22 CHAPTER 2 FIR ARCHITECTURE FOR THE FILTER BANK OF SPEECH PROCESSOR 2.1 INTRODUCTION A CI is a device that can provide a sense of sound to people who are deaf or profoundly hearing-impaired. Filters
Implementing Speaker Recognition
 Implementing Speaker Recognition Chase Zhou Physics 406-11 May 2015 Introduction Machinery has come to replace much of human labor. They are faster, stronger, and more consistent than any human. They ve
Implementing Speaker Recognition Chase Zhou Physics 406-11 May 2015 Introduction Machinery has come to replace much of human labor. They are faster, stronger, and more consistent than any human. They ve
University of Colorado at Boulder ECEN 4/5532. Lab 1 Lab report due on February 2, 2015
 University of Colorado at Boulder ECEN 4/5532 Lab 1 Lab report due on February 2, 2015 This is a MATLAB only lab, and therefore each student needs to turn in her/his own lab report and own programs. 1
University of Colorado at Boulder ECEN 4/5532 Lab 1 Lab report due on February 2, 2015 This is a MATLAB only lab, and therefore each student needs to turn in her/his own lab report and own programs. 1
Speech Enhancement Based On Noise Reduction
 Speech Enhancement Based On Noise Reduction Kundan Kumar Singh Electrical Engineering Department University Of Rochester ksingh11@z.rochester.edu ABSTRACT This paper addresses the problem of signal distortion
Speech Enhancement Based On Noise Reduction Kundan Kumar Singh Electrical Engineering Department University Of Rochester ksingh11@z.rochester.edu ABSTRACT This paper addresses the problem of signal distortion
Multimedia Signal Processing: Theory and Applications in Speech, Music and Communications
 Brochure More information from http://www.researchandmarkets.com/reports/569388/ Multimedia Signal Processing: Theory and Applications in Speech, Music and Communications Description: Multimedia Signal
Brochure More information from http://www.researchandmarkets.com/reports/569388/ Multimedia Signal Processing: Theory and Applications in Speech, Music and Communications Description: Multimedia Signal
Gammatone Cepstral Coefficient for Speaker Identification
 Gammatone Cepstral Coefficient for Speaker Identification Rahana Fathima 1, Raseena P E 2 M. Tech Student, Ilahia college of Engineering and Technology, Muvattupuzha, Kerala, India 1 Asst. Professor, Ilahia
Gammatone Cepstral Coefficient for Speaker Identification Rahana Fathima 1, Raseena P E 2 M. Tech Student, Ilahia college of Engineering and Technology, Muvattupuzha, Kerala, India 1 Asst. Professor, Ilahia
SGN Audio and Speech Processing
 SGN 14006 Audio and Speech Processing Introduction 1 Course goals Introduction 2! Learn basics of audio signal processing Basic operations and their underlying ideas and principles Give basic skills although
SGN 14006 Audio and Speech Processing Introduction 1 Course goals Introduction 2! Learn basics of audio signal processing Basic operations and their underlying ideas and principles Give basic skills although
Performance study of Text-independent Speaker identification system using MFCC & IMFCC for Telephone and Microphone Speeches
 Performance study of Text-independent Speaker identification system using & I for Telephone and Microphone Speeches Ruchi Chaudhary, National Technical Research Organization Abstract: A state-of-the-art
Performance study of Text-independent Speaker identification system using & I for Telephone and Microphone Speeches Ruchi Chaudhary, National Technical Research Organization Abstract: A state-of-the-art
Introduction of Audio and Music
 1 Introduction of Audio and Music Wei-Ta Chu 2009/12/3 Outline 2 Introduction of Audio Signals Introduction of Music 3 Introduction of Audio Signals Wei-Ta Chu 2009/12/3 Li and Drew, Fundamentals of Multimedia,
1 Introduction of Audio and Music Wei-Ta Chu 2009/12/3 Outline 2 Introduction of Audio Signals Introduction of Music 3 Introduction of Audio Signals Wei-Ta Chu 2009/12/3 Li and Drew, Fundamentals of Multimedia,
EE482: Digital Signal Processing Applications
 Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 12 Speech Signal Processing 14/03/25 http://www.ee.unlv.edu/~b1morris/ee482/
Professor Brendan Morris, SEB 3216, brendan.morris@unlv.edu EE482: Digital Signal Processing Applications Spring 2014 TTh 14:30-15:45 CBC C222 Lecture 12 Speech Signal Processing 14/03/25 http://www.ee.unlv.edu/~b1morris/ee482/
Digital Signal Processing
 Digital Signal Processing Fourth Edition John G. Proakis Department of Electrical and Computer Engineering Northeastern University Boston, Massachusetts Dimitris G. Manolakis MIT Lincoln Laboratory Lexington,
Digital Signal Processing Fourth Edition John G. Proakis Department of Electrical and Computer Engineering Northeastern University Boston, Massachusetts Dimitris G. Manolakis MIT Lincoln Laboratory Lexington,
Chapter 7. Frequency-Domain Representations 语音信号的频域表征
 Chapter 7 Frequency-Domain Representations 语音信号的频域表征 1 General Discrete-Time Model of Speech Production Voiced Speech: A V P(z)G(z)V(z)R(z) Unvoiced Speech: A N N(z)V(z)R(z) 2 DTFT and DFT of Speech The
Chapter 7 Frequency-Domain Representations 语音信号的频域表征 1 General Discrete-Time Model of Speech Production Voiced Speech: A V P(z)G(z)V(z)R(z) Unvoiced Speech: A N N(z)V(z)R(z) 2 DTFT and DFT of Speech The
Signal Analysis Using Autoregressive Models of Amplitude Modulation. Sriram Ganapathy
 Signal Analysis Using Autoregressive Models of Amplitude Modulation Sriram Ganapathy Advisor - Hynek Hermansky Johns Hopkins University 11-18-2011 Overview Introduction AR Model of Hilbert Envelopes FDLP
Signal Analysis Using Autoregressive Models of Amplitude Modulation Sriram Ganapathy Advisor - Hynek Hermansky Johns Hopkins University 11-18-2011 Overview Introduction AR Model of Hilbert Envelopes FDLP
Pattern Recognition. Part 6: Bandwidth Extension. Gerhard Schmidt
 Pattern Recognition Part 6: Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Institute of Electrical and Information Engineering Digital Signal Processing and System Theory
Pattern Recognition Part 6: Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Institute of Electrical and Information Engineering Digital Signal Processing and System Theory
Determination of instants of significant excitation in speech using Hilbert envelope and group delay function
 Determination of instants of significant excitation in speech using Hilbert envelope and group delay function by K. Sreenivasa Rao, S. R. M. Prasanna, B.Yegnanarayana in IEEE Signal Processing Letters,
Determination of instants of significant excitation in speech using Hilbert envelope and group delay function by K. Sreenivasa Rao, S. R. M. Prasanna, B.Yegnanarayana in IEEE Signal Processing Letters,
Digital Speech Processing and Coding
 ENEE408G Spring 2006 Lecture-2 Digital Speech Processing and Coding Spring 06 Instructor: Shihab Shamma Electrical & Computer Engineering University of Maryland, College Park http://www.ece.umd.edu/class/enee408g/
ENEE408G Spring 2006 Lecture-2 Digital Speech Processing and Coding Spring 06 Instructor: Shihab Shamma Electrical & Computer Engineering University of Maryland, College Park http://www.ece.umd.edu/class/enee408g/
Variation in Noise Parameter Estimates for Background Noise Classification
 Variation in Noise Parameter Estimates for Background Noise Classification Md. Danish Nadeem Greater Noida Institute of Technology, Gr. Noida Mr. B. P. Mishra Greater Noida Institute of Technology, Gr.
Variation in Noise Parameter Estimates for Background Noise Classification Md. Danish Nadeem Greater Noida Institute of Technology, Gr. Noida Mr. B. P. Mishra Greater Noida Institute of Technology, Gr.
HIGH RESOLUTION SIGNAL RECONSTRUCTION
 HIGH RESOLUTION SIGNAL RECONSTRUCTION Trausti Kristjansson Machine Learning and Applied Statistics Microsoft Research traustik@microsoft.com John Hershey University of California, San Diego Machine Perception
HIGH RESOLUTION SIGNAL RECONSTRUCTION Trausti Kristjansson Machine Learning and Applied Statistics Microsoft Research traustik@microsoft.com John Hershey University of California, San Diego Machine Perception
Audio processing methods on marine mammal vocalizations
 Audio processing methods on marine mammal vocalizations Xanadu Halkias Laboratory for the Recognition and Organization of Speech and Audio http://labrosa.ee.columbia.edu Sound to Signal sound is pressure
Audio processing methods on marine mammal vocalizations Xanadu Halkias Laboratory for the Recognition and Organization of Speech and Audio http://labrosa.ee.columbia.edu Sound to Signal sound is pressure
Speech Enhancement Using Spectral Flatness Measure Based Spectral Subtraction
 IOSR Journal of VLSI and Signal Processing (IOSR-JVSP) Volume 7, Issue, Ver. I (Mar. - Apr. 7), PP 4-46 e-issn: 9 4, p-issn No. : 9 497 www.iosrjournals.org Speech Enhancement Using Spectral Flatness Measure
IOSR Journal of VLSI and Signal Processing (IOSR-JVSP) Volume 7, Issue, Ver. I (Mar. - Apr. 7), PP 4-46 e-issn: 9 4, p-issn No. : 9 497 www.iosrjournals.org Speech Enhancement Using Spectral Flatness Measure
arxiv: v1 [cs.sd] 12 Dec 2016
![arxiv: v1 [cs.sd] 12 Dec 2016](/thumbs/92/108438711.jpg "arxiv: v1 [cs.sd] 12 Dec 2016") CONVOLUTIONAL NEURAL NETWORKS FOR PASSIVE MONITORING OF A SHALLOW WATER ENVIRONMENT USING A SINGLE SENSOR arxiv:1612.355v1 [cs.sd] 12 Dec 216 Eric L. Ferguson, Rishi Ramakrishnan, Stefan B. Williams Australian
CONVOLUTIONAL NEURAL NETWORKS FOR PASSIVE MONITORING OF A SHALLOW WATER ENVIRONMENT USING A SINGLE SENSOR arxiv:1612.355v1 [cs.sd] 12 Dec 216 Eric L. Ferguson, Rishi Ramakrishnan, Stefan B. Williams Australian
Feasibility of Vocal Emotion Conversion on Modulation Spectrogram for Simulated Cochlear Implants
 Feasibility of Vocal Emotion Conversion on Modulation Spectrogram for Simulated Cochlear Implants Zhi Zhu, Ryota Miyauchi, Yukiko Araki, and Masashi Unoki School of Information Science, Japan Advanced
Feasibility of Vocal Emotion Conversion on Modulation Spectrogram for Simulated Cochlear Implants Zhi Zhu, Ryota Miyauchi, Yukiko Araki, and Masashi Unoki School of Information Science, Japan Advanced
Research Article Linear Prediction Using Refined Autocorrelation Function
 Hindawi Publishing Corporation EURASIP Journal on Audio, Speech, and Music Processing Volume 27, Article ID 45962, 9 pages doi:.55/27/45962 Research Article Linear Prediction Using Refined Autocorrelation
Hindawi Publishing Corporation EURASIP Journal on Audio, Speech, and Music Processing Volume 27, Article ID 45962, 9 pages doi:.55/27/45962 Research Article Linear Prediction Using Refined Autocorrelation
Signal segmentation and waveform characterization. Biosignal processing, S Autumn 2012
 Signal segmentation and waveform characterization Biosignal processing, 5173S Autumn 01 Short-time analysis of signals Signal statistics may vary in time: nonstationary how to compute signal characterizations?
Signal segmentation and waveform characterization Biosignal processing, 5173S Autumn 01 Short-time analysis of signals Signal statistics may vary in time: nonstationary how to compute signal characterizations?
Fundamental frequency estimation of speech signals using MUSIC algorithm
 Acoust. Sci. & Tech. 22, 4 (2) TECHNICAL REPORT Fundamental frequency estimation of speech signals using MUSIC algorithm Takahiro Murakami and Yoshihisa Ishida School of Science and Technology, Meiji University,,
Acoust. Sci. & Tech. 22, 4 (2) TECHNICAL REPORT Fundamental frequency estimation of speech signals using MUSIC algorithm Takahiro Murakami and Yoshihisa Ishida School of Science and Technology, Meiji University,,
SPEech Feature Toolbox (SPEFT) Design and Emotional Speech Feature Extraction
 Design and Emotional Speech Feature Extraction") SPEech Feature Toolbox (SPEFT) Design and Emotional Speech Feature Extraction by Xi Li A thesis submitted to the Faculty of Graduate School, Marquette University, in Partial Fulfillment of the Requirements
SPEech Feature Toolbox (SPEFT) Design and Emotional Speech Feature Extraction by Xi Li A thesis submitted to the Faculty of Graduate School, Marquette University, in Partial Fulfillment of the Requirements
Announcements. Today. Speech and Language. State Path Trellis. HMMs: MLE Queries. Introduction to Artificial Intelligence. V22.
 Introduction to Artificial Intelligence Announcements V22.0472-001 Fall 2009 Lecture 19: Speech Recognition & Viterbi Decoding Rob Fergus Dept of Computer Science, Courant Institute, NYU Slides from John
Introduction to Artificial Intelligence Announcements V22.0472-001 Fall 2009 Lecture 19: Speech Recognition & Viterbi Decoding Rob Fergus Dept of Computer Science, Courant Institute, NYU Slides from John
DERIVATION OF TRAPS IN AUDITORY DOMAIN
 DERIVATION OF TRAPS IN AUDITORY DOMAIN Petr Motlíček, Doctoral Degree Programme (4) Dept. of Computer Graphics and Multimedia, FIT, BUT E-mail: motlicek@fit.vutbr.cz Supervised by: Dr. Jan Černocký, Prof.
DERIVATION OF TRAPS IN AUDITORY DOMAIN Petr Motlíček, Doctoral Degree Programme (4) Dept. of Computer Graphics and Multimedia, FIT, BUT E-mail: motlicek@fit.vutbr.cz Supervised by: Dr. Jan Černocký, Prof.
Identification of disguised voices using feature extraction and classification
 Identification of disguised voices using feature extraction and classification Lini T Lal, Avani Nath N.J, Dept. of Electronics and Communication, TKMIT, Kollam, Kerala, India linithyvila23@gmail.com,
Identification of disguised voices using feature extraction and classification Lini T Lal, Avani Nath N.J, Dept. of Electronics and Communication, TKMIT, Kollam, Kerala, India linithyvila23@gmail.com,
Signal Analysis. Peak Detection. Envelope Follower (Amplitude detection) Music 270a: Signal Analysis
 Music 270a: Signal Analysis") Signal Analysis Music 27a: Signal Analysis Tamara Smyth, trsmyth@ucsd.edu Department of Music, University of California, San Diego (UCSD November 23, 215 Some tools we may want to use to automate analysis
Signal Analysis Music 27a: Signal Analysis Tamara Smyth, trsmyth@ucsd.edu Department of Music, University of California, San Diego (UCSD November 23, 215 Some tools we may want to use to automate analysis
Machine recognition of speech trained on data from New Jersey Labs
 Machine recognition of speech trained on data from New Jersey Labs Frequency response (peak around 5 Hz) Impulse response (effective length around 200 ms) 41 RASTA filter 10 attenuation [db] 40 1 10 modulation
Machine recognition of speech trained on data from New Jersey Labs Frequency response (peak around 5 Hz) Impulse response (effective length around 200 ms) 41 RASTA filter 10 attenuation [db] 40 1 10 modulation