Advanced Music Content Analysis
|
|
|
- Arlene Wilkerson
- 5 years ago
- Views:
Transcription
1 RuSSIR 2013: Content- and Context-based Music Similarity and Retrieval Titelmasterformat durch Klicken bearbeiten Advanced Music Content Analysis Markus Schedl Peter Knees {markus.schedl, Department of Computational Perception Johannes Kepler University (JKU) Linz, Austria
2 Mid-level feature extraction and similarity calculation Pitch Class Profiles: related to Western music tone scale, melodic retrieval MFCCs: related to timbral properties Block-Level Features Outline - Fluctuation Patterns: related to rhythmic/periodic properties - Correlation Patterns: temporal relation of frequencies - Spectral Contrast Patterns: related to tone-ness Throughout: Examples and Applications
: mimics human listening process (not linear, but logarithmic!")
 Frame-level (short time windows, e.g., 25 ms) needs feature distribution model")
3 Mid-level Feature Processing Overview Block Frames Convert signal to frequency domain, e.g., using an FFT (Psycho)acoustic transformation (Mel-scale, Bark-scale, Cent-scale,...): mimics human listening process (not linear, but logarithmic!), removes aspects not perceived by humans, emphasizes low frequencies Extract features Block-level (large time windows, e.g., 6 sec) Frame-level (short time windows, e.g., 25 ms) needs feature distribution model
4 Acoustic Scales Comparison of acoustic scales normalized scales Bark Mel Cent ERB Linear Frequency [Hz] x 10 4
5 Pitch Class Profiles (aka chroma vectors) Transforming the frequency activations into well known musical system/representation/notation Mapping to the equal-tempered scale (each semitone equal to one twelfth of an octave) For each frame, get intensity of each of the 12 semitone (pitch) classes (Fujishima; 1999)


6 Mapping Frequencies to Semitones

7 Semitone Scale Map data to semitone scale to represent (western) music Frequency doubles for each octave e.g. pitch of A3 is 220 Hz, compared to 440 Hz of A4 Mapping, e.g., using filter bank with triangular filters centered on pitches width given by neighboring pitches normalized by area under filter Octave The note C in different octaves vs. frequency Frequency
8 Pitch Class Features Sum up activations that belong to the same class of pitch (e.g., all A, all C, all F#) + Results in a 12-dimensional feature vector for each frame PCP feature vectors describe tonality Robust to noise (including percussive sounds) Independent of timbre (~ played instruments) Independent of loudness

9 Pitch Class Profiles in Action Sonic Visualizer by QMUL, C4DM;
 to match recorded live performance with dead-pan synthesized")
10 Real-Time Score Following (Arzt, Widmer; 2010) Tracks the position of a piano player in the score while playing Uses a combination of spectral flux and PCPs as features Dynamic Time Warping (DTW) to match recorded live performance with dead-pan synthesized version
")
11 Application: Automatic Page Turner (Arzt, Widmer; 2010)
12 Music Retrieval Scenarios PCPs used in classification, key/chord estimation, melody retrieval, and cover song retrieval, i.e., finding songs that are based on the same melody/tune, independent of instrumentation (timbre) Another scenario is to find different songs that nevertheless sound similar This is most often and predominantly related to timbre aspects (although it is more complex than that see Lecture I) MFCCs have shown to be better descriptors for this task
13 MFCCs Mel Frequency Cepstral Coefficients (MFCCs) have their roots in speech recognition and are a way to represent the envelope of the power spectrum of an audio frame the spectral envelope captures perceptually important information about the corresponding sound excerpt (timbral aspects) most important for music similarity: sounds with similar spectral envelopes are generally perceived as similar.
14 The Mel Scale Frequency [Mel] Mel Perceptual scale of pitches judged by listeners to be equal in distance from one another Given Frequency f in Hertz, the corresponding pitch in Mel can be computed by Frequency [Hz] Normally around 40 bins equally spaced on the Mel scale are used
15 Waveform Convert to Frames Take discrete Fourier transform Take Log of amplitude spectrum Mel-scaling and smoothing Discrete cosine transform MFCCs MFCCs are computed per frame 1. STFT: short-time Fourier transform 2. the logarithm of the amplitude spectrum is taken (motivated by the way we humans perceive loudness) 3. mapping of the amplitude spectrum to the Mel scale 4. quantize (e.g., 40 bins) and make linear (DCT doesn t operate on log scale) MFCC Features

16 Waveform Convert to Frames Take discrete Fourier transform Take Log of amplitude spectrum 5. perform Discrete Cosine Transform to de-correlate the Mel-spectral vectors similar to FFT; only real-valued components describes a sequence of finitely many data points as sum of cosine functions oscillating at different frequencies results in n coefficients (e.g., n = 20) Mel-scaling and smoothing Discrete cosine transform MFCC Features NB: performing (inverse) FT or similar on log representation of spectrum => cepstrum (anagram!)


17 MFCC Examples Metal Choir
18 Bag-of-frames Modeling Full music piece is now a set of MFCC vectors; number of frames depends on length of piece Need summary/aggregation/modeling of this set Average over all frames? Sum? Most common approach: Statistically model the distribution of all these local features memory requirements, runtime and also the recommendation quality depend on this step Learn model that explains the data best State-of-the-art until 2005: learn a Gaussian Mixture Model (GMM) a GMM estimates a probability density as the weighted sum of M simpler Gaussian densities, called components of the mixture each song is modeled with a GMM the parameters of the GMM are learned with the classic Expectation- Maximization (EM) algorithm this can be considered a shortcoming of this approach as this step is very time consuming
 State-of-the-Art since 2005: Single Gaussian Model p(x)log p(x) q(x)")
19 Bag-of-frames Modeling Comparing two GMMs is non-trivial and expensive The Kullback-Leibler divergence can be used (approximated) D KL (P Q) = Basically, this requires to (Monte-Carlo) sample one GMM and calculate the likelihood of these observations under the other model and vice versa (non-deterministic, slow) State-of-the-Art since 2005: Single Gaussian Model p(x)log p(x) q(x) dx
20 Single Gaussian Bag-of-frames model Describe the frames using the mean vector and a full covariance matrix For single Gaussian distributions, a closed form of the KLdivergence exists (not a metric!) µ... mean, Σ... cov. mat., tr... trace, k... dimensionality asymmetric, symmetrize by averaging Alternatively, calculate Jenson-Shannon Divergence symmetric, square root is a metric! Efficient (instantaneous retrieval of 10Ks of pieces) (D = D KL )
 played song model compared to all whenever played no caching necessary http://fm4.orf.")
21 Query-by-Example in the Real World Single Gaussian MFCC music similarity measure used in FM4 Soundpark Player For each played song, 5 similar sounding songs are recommended Retrieval in real-time full database ~20K songs (?) played song model compared to all whenever played no caching necessary
22 Limitations of Bag-of-Frames Approaches Loss of Temporal Information: temporal ordering of the MFCC vectors is completely lost because of the distribution model (bag-of-frames) possible approach: calculate delta-mfccs to preserve difference between subsequent frames Hub Problem ( Always Similar Problem ) depending on the used features and similarity measure, some songs will yield high similarities with many other songs without actually sounding similar (requires post-processing to prevent, e.g., recommendation for too many songs) general problem in high-dimensional feature spaces
23 Wrapping up MFCCs and BoF Similarity model applicable to real-world tasks Satisfactory results ( world s best similarity measure for several years) Extensions make it applicable to search within millions of songs in real-time approximate searching in lower-dimensional projection Possible Alternatives to BoF: Hidden Markov Models Vector Quantization Models ( Codebook )
24 Instead of processing single frames, compute features on larger blocks of frames blocks are defined as consecutive sequences of audio frames thus features are (to some extent) able to capture local temporal information Afterwards the blocks are summarized to form a generalized description of the piece of music Features considered in the following: Fluctuation Patterns (Pampalk; 2001) From Block Level Framework (BLF) (Seyerlehner; 2010) Correlation Pattern Spectral Contrast Pattern Block-Level Features

 Main advantage of")
25 block = b H,1 b H,W..... b 1,1 b 1,W Block Processing The whole spectrum is processed in terms of blocks Each block consists of a fixed number of frames (block size W) Number of rows H is defined by the frequency resolution Blocks may overlap (hop size) Main advantage of processing in blocks: blocks allow to perform some (local) temporal processing

26 Generalization To come up with a global feature vector per song, the local feature vectors must be combined into a single representation This is done by a summarization function (e.g., mean, median, certain percentiles, variance, ) The features in the upcoming slides will be matrices, however in these cases the summarization function simply is applied component by component
27 Fluctuation Patterns (FPs) Idea: measure how strong and fast beats are played within certain perceptually adjusted frequency bands Aims at capturing periodicities in the signal ( rhythmic properties ) Incorporates several psychoacoustic transformations Logarithmic perception of frequencies (Bark scale) Loudness Periodicities Results in a vector description for each music piece Vector Space Model Favorable for subsequent processing steps and applications: classification, clustering, etc.
28 Fluctuation Patterns Extract 6 sec blocks discard beginning and end In each block: FFT on Hanning-windowed frames (256 samples) Convert spectrum to 20 critical bands according to Bark scale Calculate Spectral Masking effects (i.e. occlusion of a quiet sound when a loud sound is played simultaneously) Several loudness transformations: 1. to db (sound intensity) 2. to phon (human sensation: log) 3. to sone (back to linear)
29 Fluctuation Patterns Second FFT reveals information about amplitude modulation, called fluctuations. - Fluctuations show how often frequencies reoccur at certain intervals within the 6-sec-segment - frequencies of the frequencies Psychoacoustic model of fluctuation strength - perception of fluctuations depends on their periodicities - reoccurring beats at 4Hz perceived most intensely - 60 levels of modulation (per band) (ranging from 0 to 600bpm) Emphasize distinctive beats
30 Fluctuation Patterns Each block is now respresented as a matrix of fluctuation strengths with 1,200 entries (20 critical bands x 60 levels of modulation) Aggregation of all blocks by taking median of each component This results in a 1,200 dimensional feature vector for each music piece Comparison of two music pieces is done by calculating the Euclidean distance between their feature vectors
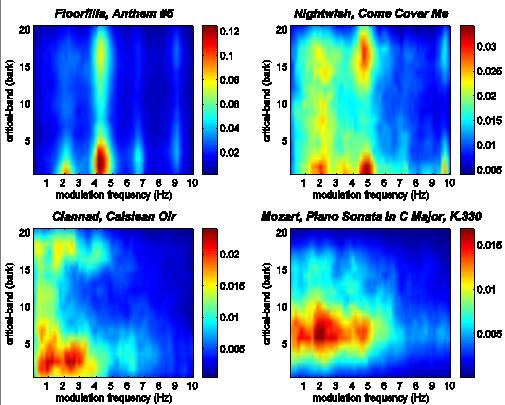
31 Examples
32 Wrapping up FPs and VSM (Some) temporal dependencies are modeled within segments of 6 second length Properties: + Vector Space Model: The whole mathematical toolbox of vector spaces is available. + easy to use in classification + song models can be visualized - high dimensional feature space (often a PCA is applied to reduce dim.) More comprehensive block-level features by (Seyerlehner; 2010) currently best performing similarity measure according to MIREX: Spectral Pattern (SP): frequency content Delta-Spectral Pattern (DSP): SP on delta frames Variance Delta-Spectral Pattern (VDSP): variance used to aggregate DSP Logarithmic Fluctuation Pattern (LFP): more tempo invariant Correlation Pattern (CP): temporal relation of frequency bands Spectral Contrast Pattern (SCP): estimate tone-ness Block aggregation via percentiles; similarity via Manhattan distance


33 Correlation Pattern (CP) Reduce the Cent spectrum to 52 frequency bands Captures the temporal relation of the frequency bands Compute the pair-wise linear correlation between each frequency band. CP r xy for all pairs The 0.5-percentile is used as aggregation function.
34 Spectral Contrast Pattern (SCP) Compute the spectral contrast per frame to estimate the tone-ness This is performed separately for 20 frequency bands of the Cent spectrum. Sort the spectral contrast values of each frequency band along the whole block. The aggregation function is the 0.1-percentile.
35 Spectral Contrast Pattern (SCP) Compute the spectral contrast per frame to estimate the tone-ness This is performed separately for 20 frequency bands of the Cent spectrum. Sort the spectral contrast values of each frequency band along the whole block. The aggregation function is the 0.1-percentile.
36 Spectral Contrast Pattern (SCP) Compute the spectral contrast per frame to estimate the tone-ness This is performed separately for 20 frequency bands of the Cent spectrum. Sort the spectral contrast values of each frequency band along the whole block. The aggregation function is the 0.1-percentile.
37 Spectral Contrast Pattern (SCP) Compute the spectral contrast per frame to estimate the tone-ness This is performed separately for 20 frequency bands of the Cent spectrum. Sort the spectral contrast values of each frequency band along the whole block. The aggregation function is the 0.1-percentile.
38 Spectral Contrast Pattern (SCP) Compute the spectral contrast per frame to estimate the tone-ness This is performed separately for 20 frequency bands of the Cent spectrum. Sort the spectral contrast values of each frequency band along the whole block. The aggregation function is the 0.1-percentile.

39 Spectral Contrast Pattern (SCP) Compute the spectral contrast per frame to estimate the tone-ness This is performed separately for 20 frequency bands of the Cent spectrum. Sort the spectral contrast values of each frequency band along the whole block. The aggregation function is the 0.1-percentile.

40 Defining Similarity in the BLF Estimate song similarities for multiple block-level features Calculate song similarities separately for each pattern (by computing Manhattan distance) Fusion: Combine the similarity estimates of the individual patterns into a single result Naïve approach: linearly weighted combination of BLFs Problem: similarity estimates of the different patterns (block-level features) have different scales. special normalization strategy is used: Distance Space Normalization Estimate DM 1 Combine DM N-1 DM N

41 Distance Space Normalization (DSN) Operates on the distance matrix Each distance D n,m is normalized using Gaussian normalization. Mean and standard deviation are computed over both column and row of the distance matrix. Each distance has its own normalization parameters. Observation: The operation itself can improve the nearest neighbor classification accuracy.

42 Demo: Content-Based Music Browsing

 space Self-organizing")
 is projected")

43 neptune Structuring the Music Space Clustering of music pieces Each song corresponds to point in feature (similarity) space Self-organizing Map High-dimensional data (content-based features) is projected to 2-dim. plane Number of pieces per cluster landscape height profile (Knees et al.; MM 2006)




")
 Music")
44 neptune Web-based Augmentation Automatic description of landscape via Web term extraction (Knees et al.; MM 2006) artist names (ID3) Music dictionary Term goodness
Audio Similarity. Mark Zadel MUMT 611 March 8, Audio Similarity p.1/23
 Audio Similarity Mark Zadel MUMT 611 March 8, 2004 Audio Similarity p.1/23 Overview MFCCs Foote Content-Based Retrieval of Music and Audio (1997) Logan, Salomon A Music Similarity Function Based On Signal
Audio Similarity Mark Zadel MUMT 611 March 8, 2004 Audio Similarity p.1/23 Overview MFCCs Foote Content-Based Retrieval of Music and Audio (1997) Logan, Salomon A Music Similarity Function Based On Signal
Rhythmic Similarity -- a quick paper review. Presented by: Shi Yong March 15, 2007 Music Technology, McGill University
 Rhythmic Similarity -- a quick paper review Presented by: Shi Yong March 15, 2007 Music Technology, McGill University Contents Introduction Three examples J. Foote 2001, 2002 J. Paulus 2002 S. Dixon 2004
Rhythmic Similarity -- a quick paper review Presented by: Shi Yong March 15, 2007 Music Technology, McGill University Contents Introduction Three examples J. Foote 2001, 2002 J. Paulus 2002 S. Dixon 2004
Advanced audio analysis. Martin Gasser
 Advanced audio analysis Martin Gasser Motivation Which methods are common in MIR research? How can we parameterize audio signals? Interesting dimensions of audio: Spectral/ time/melody structure, high
Advanced audio analysis Martin Gasser Motivation Which methods are common in MIR research? How can we parameterize audio signals? Interesting dimensions of audio: Spectral/ time/melody structure, high
Lecture 5: Pitch and Chord (1) Chord Recognition. Li Su
 Chord Recognition. Li Su") Lecture 5: Pitch and Chord (1) Chord Recognition Li Su Recap: short-time Fourier transform Given a discrete-time signal x(t) sampled at a rate f s. Let window size N samples, hop size H samples, then the
Lecture 5: Pitch and Chord (1) Chord Recognition Li Su Recap: short-time Fourier transform Given a discrete-time signal x(t) sampled at a rate f s. Let window size N samples, hop size H samples, then the
A CONSTRUCTION OF COMPACT MFCC-TYPE FEATURES USING SHORT-TIME STATISTICS FOR APPLICATIONS IN AUDIO SEGMENTATION
 17th European Signal Processing Conference (EUSIPCO 2009) Glasgow, Scotland, August 24-28, 2009 A CONSTRUCTION OF COMPACT MFCC-TYPE FEATURES USING SHORT-TIME STATISTICS FOR APPLICATIONS IN AUDIO SEGMENTATION
17th European Signal Processing Conference (EUSIPCO 2009) Glasgow, Scotland, August 24-28, 2009 A CONSTRUCTION OF COMPACT MFCC-TYPE FEATURES USING SHORT-TIME STATISTICS FOR APPLICATIONS IN AUDIO SEGMENTATION
Mel Spectrum Analysis of Speech Recognition using Single Microphone
 International Journal of Engineering Research in Electronics and Communication Mel Spectrum Analysis of Speech Recognition using Single Microphone [1] Lakshmi S.A, [2] Cholavendan M [1] PG Scholar, Sree
International Journal of Engineering Research in Electronics and Communication Mel Spectrum Analysis of Speech Recognition using Single Microphone [1] Lakshmi S.A, [2] Cholavendan M [1] PG Scholar, Sree
Speech and Music Discrimination based on Signal Modulation Spectrum.
 Speech and Music Discrimination based on Signal Modulation Spectrum. Pavel Balabko June 24, 1999 1 Introduction. This work is devoted to the problem of automatic speech and music discrimination. As we
Speech and Music Discrimination based on Signal Modulation Spectrum. Pavel Balabko June 24, 1999 1 Introduction. This work is devoted to the problem of automatic speech and music discrimination. As we
Topic. Spectrogram Chromagram Cesptrogram. Bryan Pardo, 2008, Northwestern University EECS 352: Machine Perception of Music and Audio
 Topic Spectrogram Chromagram Cesptrogram Short time Fourier Transform Break signal into windows Calculate DFT of each window The Spectrogram spectrogram(y,1024,512,1024,fs,'yaxis'); A series of short term
Topic Spectrogram Chromagram Cesptrogram Short time Fourier Transform Break signal into windows Calculate DFT of each window The Spectrogram spectrogram(y,1024,512,1024,fs,'yaxis'); A series of short term
BEAT DETECTION BY DYNAMIC PROGRAMMING. Racquel Ivy Awuor
 BEAT DETECTION BY DYNAMIC PROGRAMMING Racquel Ivy Awuor University of Rochester Department of Electrical and Computer Engineering Rochester, NY 14627 rawuor@ur.rochester.edu ABSTRACT A beat is a salient
BEAT DETECTION BY DYNAMIC PROGRAMMING Racquel Ivy Awuor University of Rochester Department of Electrical and Computer Engineering Rochester, NY 14627 rawuor@ur.rochester.edu ABSTRACT A beat is a salient
Applications of Music Processing
 Lecture Music Processing Applications of Music Processing Christian Dittmar International Audio Laboratories Erlangen christian.dittmar@audiolabs-erlangen.de Singing Voice Detection Important pre-requisite
Lecture Music Processing Applications of Music Processing Christian Dittmar International Audio Laboratories Erlangen christian.dittmar@audiolabs-erlangen.de Singing Voice Detection Important pre-requisite
Speech Signal Analysis
 Speech Signal Analysis Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 2&3 14,18 January 216 ASR Lectures 2&3 Speech Signal Analysis 1 Overview Speech Signal Analysis for
Speech Signal Analysis Hiroshi Shimodaira and Steve Renals Automatic Speech Recognition ASR Lectures 2&3 14,18 January 216 ASR Lectures 2&3 Speech Signal Analysis 1 Overview Speech Signal Analysis for
SOUND SOURCE RECOGNITION AND MODELING
 SOUND SOURCE RECOGNITION AND MODELING CASA seminar, summer 2000 Antti Eronen antti.eronen@tut.fi Contents: Basics of human sound source recognition Timbre Voice recognition Recognition of environmental
SOUND SOURCE RECOGNITION AND MODELING CASA seminar, summer 2000 Antti Eronen antti.eronen@tut.fi Contents: Basics of human sound source recognition Timbre Voice recognition Recognition of environmental
SONG RETRIEVAL SYSTEM USING HIDDEN MARKOV MODELS
 SONG RETRIEVAL SYSTEM USING HIDDEN MARKOV MODELS AKSHAY CHANDRASHEKARAN ANOOP RAMAKRISHNA akshayc@cmu.edu anoopr@andrew.cmu.edu ABHISHEK JAIN GE YANG ajain2@andrew.cmu.edu younger@cmu.edu NIDHI KOHLI R
SONG RETRIEVAL SYSTEM USING HIDDEN MARKOV MODELS AKSHAY CHANDRASHEKARAN ANOOP RAMAKRISHNA akshayc@cmu.edu anoopr@andrew.cmu.edu ABHISHEK JAIN GE YANG ajain2@andrew.cmu.edu younger@cmu.edu NIDHI KOHLI R
PLAYLIST GENERATION USING START AND END SONGS
 PLAYLIST GENERATION USING START AND END SONGS Arthur Flexer 1, Dominik Schnitzer 1,2, Martin Gasser 1, Gerhard Widmer 1,2 1 Austrian Research Institute for Artificial Intelligence (OFAI), Vienna, Austria
PLAYLIST GENERATION USING START AND END SONGS Arthur Flexer 1, Dominik Schnitzer 1,2, Martin Gasser 1, Gerhard Widmer 1,2 1 Austrian Research Institute for Artificial Intelligence (OFAI), Vienna, Austria
University of Colorado at Boulder ECEN 4/5532. Lab 1 Lab report due on February 2, 2015
 University of Colorado at Boulder ECEN 4/5532 Lab 1 Lab report due on February 2, 2015 This is a MATLAB only lab, and therefore each student needs to turn in her/his own lab report and own programs. 1
University of Colorado at Boulder ECEN 4/5532 Lab 1 Lab report due on February 2, 2015 This is a MATLAB only lab, and therefore each student needs to turn in her/his own lab report and own programs. 1
Cepstrum alanysis of speech signals
 Cepstrum alanysis of speech signals ELEC-E5520 Speech and language processing methods Spring 2016 Mikko Kurimo 1 /48 Contents Literature and other material Idea and history of cepstrum Cepstrum and LP
Cepstrum alanysis of speech signals ELEC-E5520 Speech and language processing methods Spring 2016 Mikko Kurimo 1 /48 Contents Literature and other material Idea and history of cepstrum Cepstrum and LP
Speech/Music Change Point Detection using Sonogram and AANN
 International Journal of Information & Computation Technology. ISSN 0974-2239 Volume 6, Number 1 (2016), pp. 45-49 International Research Publications House http://www. irphouse.com Speech/Music Change
International Journal of Information & Computation Technology. ISSN 0974-2239 Volume 6, Number 1 (2016), pp. 45-49 International Research Publications House http://www. irphouse.com Speech/Music Change
Signal Processing for Speech Applications - Part 2-1. Signal Processing For Speech Applications - Part 2
 Signal Processing for Speech Applications - Part 2-1 Signal Processing For Speech Applications - Part 2 May 14, 2013 Signal Processing for Speech Applications - Part 2-2 References Huang et al., Chapter
Signal Processing for Speech Applications - Part 2-1 Signal Processing For Speech Applications - Part 2 May 14, 2013 Signal Processing for Speech Applications - Part 2-2 References Huang et al., Chapter
Preeti Rao 2 nd CompMusicWorkshop, Istanbul 2012
 Preeti Rao 2 nd CompMusicWorkshop, Istanbul 2012 o Music signal characteristics o Perceptual attributes and acoustic properties o Signal representations for pitch detection o STFT o Sinusoidal model o
Preeti Rao 2 nd CompMusicWorkshop, Istanbul 2012 o Music signal characteristics o Perceptual attributes and acoustic properties o Signal representations for pitch detection o STFT o Sinusoidal model o
Evaluation of MFCC Estimation Techniques for Music Similarity Jensen, Jesper Højvang; Christensen, Mads Græsbøll; Murthi, Manohar; Jensen, Søren Holdt
 Aalborg Universitet Evaluation of MFCC Estimation Techniques for Music Similarity Jensen, Jesper Højvang; Christensen, Mads Græsbøll; Murthi, Manohar; Jensen, Søren Holdt Published in: Proceedings of the
Aalborg Universitet Evaluation of MFCC Estimation Techniques for Music Similarity Jensen, Jesper Højvang; Christensen, Mads Græsbøll; Murthi, Manohar; Jensen, Søren Holdt Published in: Proceedings of the
Sound Synthesis Methods
 Sound Synthesis Methods Matti Vihola, mvihola@cs.tut.fi 23rd August 2001 1 Objectives The objective of sound synthesis is to create sounds that are Musically interesting Preferably realistic (sounds like
Sound Synthesis Methods Matti Vihola, mvihola@cs.tut.fi 23rd August 2001 1 Objectives The objective of sound synthesis is to create sounds that are Musically interesting Preferably realistic (sounds like
Classification of ships using autocorrelation technique for feature extraction of the underwater acoustic noise
 Classification of ships using autocorrelation technique for feature extraction of the underwater acoustic noise Noha KORANY 1 Alexandria University, Egypt ABSTRACT The paper applies spectral analysis to
Classification of ships using autocorrelation technique for feature extraction of the underwater acoustic noise Noha KORANY 1 Alexandria University, Egypt ABSTRACT The paper applies spectral analysis to
CP-JKU SUBMISSIONS FOR DCASE-2016: A HYBRID APPROACH USING BINAURAL I-VECTORS AND DEEP CONVOLUTIONAL NEURAL NETWORKS
 CP-JKU SUBMISSIONS FOR DCASE-2016: A HYBRID APPROACH USING BINAURAL I-VECTORS AND DEEP CONVOLUTIONAL NEURAL NETWORKS Hamid Eghbal-Zadeh Bernhard Lehner Matthias Dorfer Gerhard Widmer Department of Computational
CP-JKU SUBMISSIONS FOR DCASE-2016: A HYBRID APPROACH USING BINAURAL I-VECTORS AND DEEP CONVOLUTIONAL NEURAL NETWORKS Hamid Eghbal-Zadeh Bernhard Lehner Matthias Dorfer Gerhard Widmer Department of Computational
Performance Analysis of MFCC and LPCC Techniques in Automatic Speech Recognition
 www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume - 3 Issue - 8 August, 2014 Page No. 7727-7732 Performance Analysis of MFCC and LPCC Techniques in Automatic
www.ijecs.in International Journal Of Engineering And Computer Science ISSN:2319-7242 Volume - 3 Issue - 8 August, 2014 Page No. 7727-7732 Performance Analysis of MFCC and LPCC Techniques in Automatic
EVALUATION OF MFCC ESTIMATION TECHNIQUES FOR MUSIC SIMILARITY
 EVALUATION OF MFCC ESTIMATION TECHNIQUES FOR MUSIC SIMILARITY Jesper Højvang Jensen 1, Mads Græsbøll Christensen 1, Manohar N. Murthi, and Søren Holdt Jensen 1 1 Department of Communication Technology,
EVALUATION OF MFCC ESTIMATION TECHNIQUES FOR MUSIC SIMILARITY Jesper Højvang Jensen 1, Mads Græsbøll Christensen 1, Manohar N. Murthi, and Søren Holdt Jensen 1 1 Department of Communication Technology,
Drum Transcription Based on Independent Subspace Analysis
 Report for EE 391 Special Studies and Reports for Electrical Engineering Drum Transcription Based on Independent Subspace Analysis Yinyi Guo Center for Computer Research in Music and Acoustics, Stanford,
Report for EE 391 Special Studies and Reports for Electrical Engineering Drum Transcription Based on Independent Subspace Analysis Yinyi Guo Center for Computer Research in Music and Acoustics, Stanford,
MFCC AND GMM BASED TAMIL LANGUAGE SPEAKER IDENTIFICATION SYSTEM
 www.advancejournals.org Open Access Scientific Publisher MFCC AND GMM BASED TAMIL LANGUAGE SPEAKER IDENTIFICATION SYSTEM ABSTRACT- P. Santhiya 1, T. Jayasankar 1 1 AUT (BIT campus), Tiruchirappalli, India
www.advancejournals.org Open Access Scientific Publisher MFCC AND GMM BASED TAMIL LANGUAGE SPEAKER IDENTIFICATION SYSTEM ABSTRACT- P. Santhiya 1, T. Jayasankar 1 1 AUT (BIT campus), Tiruchirappalli, India
A Parametric Model for Spectral Sound Synthesis of Musical Sounds
 A Parametric Model for Spectral Sound Synthesis of Musical Sounds Cornelia Kreutzer University of Limerick ECE Department Limerick, Ireland cornelia.kreutzer@ul.ie Jacqueline Walker University of Limerick
A Parametric Model for Spectral Sound Synthesis of Musical Sounds Cornelia Kreutzer University of Limerick ECE Department Limerick, Ireland cornelia.kreutzer@ul.ie Jacqueline Walker University of Limerick
Signal segmentation and waveform characterization. Biosignal processing, S Autumn 2012
 Signal segmentation and waveform characterization Biosignal processing, 5173S Autumn 01 Short-time analysis of signals Signal statistics may vary in time: nonstationary how to compute signal characterizations?
Signal segmentation and waveform characterization Biosignal processing, 5173S Autumn 01 Short-time analysis of signals Signal statistics may vary in time: nonstationary how to compute signal characterizations?
CONCURRENT ESTIMATION OF CHORDS AND KEYS FROM AUDIO
 CONCURRENT ESTIMATION OF CHORDS AND KEYS FROM AUDIO Thomas Rocher, Matthias Robine, Pierre Hanna LaBRI, University of Bordeaux 351 cours de la Libration 33405 Talence Cedex, France {rocher,robine,hanna}@labri.fr
CONCURRENT ESTIMATION OF CHORDS AND KEYS FROM AUDIO Thomas Rocher, Matthias Robine, Pierre Hanna LaBRI, University of Bordeaux 351 cours de la Libration 33405 Talence Cedex, France {rocher,robine,hanna}@labri.fr
Performance study of Text-independent Speaker identification system using MFCC & IMFCC for Telephone and Microphone Speeches
 Performance study of Text-independent Speaker identification system using & I for Telephone and Microphone Speeches Ruchi Chaudhary, National Technical Research Organization Abstract: A state-of-the-art
Performance study of Text-independent Speaker identification system using & I for Telephone and Microphone Speeches Ruchi Chaudhary, National Technical Research Organization Abstract: A state-of-the-art
Dimension Reduction of the Modulation Spectrogram for Speaker Verification
 Dimension Reduction of the Modulation Spectrogram for Speaker Verification Tomi Kinnunen Speech and Image Processing Unit Department of Computer Science University of Joensuu, Finland Kong Aik Lee and
Dimension Reduction of the Modulation Spectrogram for Speaker Verification Tomi Kinnunen Speech and Image Processing Unit Department of Computer Science University of Joensuu, Finland Kong Aik Lee and
Complex Sounds. Reading: Yost Ch. 4
 Complex Sounds Reading: Yost Ch. 4 Natural Sounds Most sounds in our everyday lives are not simple sinusoidal sounds, but are complex sounds, consisting of a sum of many sinusoids. The amplitude and frequency
Complex Sounds Reading: Yost Ch. 4 Natural Sounds Most sounds in our everyday lives are not simple sinusoidal sounds, but are complex sounds, consisting of a sum of many sinusoids. The amplitude and frequency
Sound Recognition. ~ CSE 352 Team 3 ~ Jason Park Evan Glover. Kevin Lui Aman Rawat. Prof. Anita Wasilewska
 Sound Recognition ~ CSE 352 Team 3 ~ Jason Park Evan Glover Kevin Lui Aman Rawat Prof. Anita Wasilewska What is Sound? Sound is a vibration that propagates as a typically audible mechanical wave of pressure
Sound Recognition ~ CSE 352 Team 3 ~ Jason Park Evan Glover Kevin Lui Aman Rawat Prof. Anita Wasilewska What is Sound? Sound is a vibration that propagates as a typically audible mechanical wave of pressure
SPEECH ENHANCEMENT USING PITCH DETECTION APPROACH FOR NOISY ENVIRONMENT
 SPEECH ENHANCEMENT USING PITCH DETECTION APPROACH FOR NOISY ENVIRONMENT RASHMI MAKHIJANI Department of CSE, G. H. R.C.E., Near CRPF Campus,Hingna Road, Nagpur, Maharashtra, India rashmi.makhijani2002@gmail.com
SPEECH ENHANCEMENT USING PITCH DETECTION APPROACH FOR NOISY ENVIRONMENT RASHMI MAKHIJANI Department of CSE, G. H. R.C.E., Near CRPF Campus,Hingna Road, Nagpur, Maharashtra, India rashmi.makhijani2002@gmail.com
Voice Activity Detection
 Voice Activity Detection Speech Processing Tom Bäckström Aalto University October 2015 Introduction Voice activity detection (VAD) (or speech activity detection, or speech detection) refers to a class
Voice Activity Detection Speech Processing Tom Bäckström Aalto University October 2015 Introduction Voice activity detection (VAD) (or speech activity detection, or speech detection) refers to a class
Adaptive Filters Application of Linear Prediction
 Adaptive Filters Application of Linear Prediction Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Electrical Engineering and Information Technology Digital Signal Processing
Adaptive Filters Application of Linear Prediction Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Electrical Engineering and Information Technology Digital Signal Processing
DSP First. Laboratory Exercise #11. Extracting Frequencies of Musical Tones
 DSP First Laboratory Exercise #11 Extracting Frequencies of Musical Tones This lab is built around a single project that involves the implementation of a system for automatically writing a musical score
DSP First Laboratory Exercise #11 Extracting Frequencies of Musical Tones This lab is built around a single project that involves the implementation of a system for automatically writing a musical score
Introduction of Audio and Music
 1 Introduction of Audio and Music Wei-Ta Chu 2009/12/3 Outline 2 Introduction of Audio Signals Introduction of Music 3 Introduction of Audio Signals Wei-Ta Chu 2009/12/3 Li and Drew, Fundamentals of Multimedia,
1 Introduction of Audio and Music Wei-Ta Chu 2009/12/3 Outline 2 Introduction of Audio Signals Introduction of Music 3 Introduction of Audio Signals Wei-Ta Chu 2009/12/3 Li and Drew, Fundamentals of Multimedia,
Singing Voice Detection. Applications of Music Processing. Singing Voice Detection. Singing Voice Detection. Singing Voice Detection
 Detection Lecture usic Processing Applications of usic Processing Christian Dittmar International Audio Laboratories Erlangen christian.dittmar@audiolabs-erlangen.de Important pre-requisite for: usic segmentation
Detection Lecture usic Processing Applications of usic Processing Christian Dittmar International Audio Laboratories Erlangen christian.dittmar@audiolabs-erlangen.de Important pre-requisite for: usic segmentation
Timbral Distortion in Inverse FFT Synthesis
 Timbral Distortion in Inverse FFT Synthesis Mark Zadel Introduction Inverse FFT synthesis (FFT ) is a computationally efficient technique for performing additive synthesis []. Instead of summing partials
Timbral Distortion in Inverse FFT Synthesis Mark Zadel Introduction Inverse FFT synthesis (FFT ) is a computationally efficient technique for performing additive synthesis []. Instead of summing partials
Isolated Digit Recognition Using MFCC AND DTW
 MarutiLimkar a, RamaRao b & VidyaSagvekar c a Terna collegeof Engineering, Department of Electronics Engineering, Mumbai University, India b Vidyalankar Institute of Technology, Department ofelectronics
MarutiLimkar a, RamaRao b & VidyaSagvekar c a Terna collegeof Engineering, Department of Electronics Engineering, Mumbai University, India b Vidyalankar Institute of Technology, Department ofelectronics
Separating Voiced Segments from Music File using MFCC, ZCR and GMM
 Separating Voiced Segments from Music File using MFCC, ZCR and GMM Mr. Prashant P. Zirmite 1, Mr. Mahesh K. Patil 2, Mr. Santosh P. Salgar 3,Mr. Veeresh M. Metigoudar 4 1,2,3,4Assistant Professor, Dept.
Separating Voiced Segments from Music File using MFCC, ZCR and GMM Mr. Prashant P. Zirmite 1, Mr. Mahesh K. Patil 2, Mr. Santosh P. Salgar 3,Mr. Veeresh M. Metigoudar 4 1,2,3,4Assistant Professor, Dept.
Mel- frequency cepstral coefficients (MFCCs) and gammatone filter banks
 and gammatone filter banks") SGN- 14006 Audio and Speech Processing Pasi PerQlä SGN- 14006 2015 Mel- frequency cepstral coefficients (MFCCs) and gammatone filter banks Slides for this lecture are based on those created by Katariina
SGN- 14006 Audio and Speech Processing Pasi PerQlä SGN- 14006 2015 Mel- frequency cepstral coefficients (MFCCs) and gammatone filter banks Slides for this lecture are based on those created by Katariina
Structure of Speech. Physical acoustics Time-domain representation Frequency domain representation Sound shaping
 Structure of Speech Physical acoustics Time-domain representation Frequency domain representation Sound shaping Speech acoustics Source-Filter Theory Speech Source characteristics Speech Filter characteristics
Structure of Speech Physical acoustics Time-domain representation Frequency domain representation Sound shaping Speech acoustics Source-Filter Theory Speech Source characteristics Speech Filter characteristics
Tempo and Beat Tracking
 Lecture Music Processing Tempo and Beat Tracking Meinard Müller International Audio Laboratories Erlangen meinard.mueller@audiolabs-erlangen.de Introduction Basic beat tracking task: Given an audio recording
Lecture Music Processing Tempo and Beat Tracking Meinard Müller International Audio Laboratories Erlangen meinard.mueller@audiolabs-erlangen.de Introduction Basic beat tracking task: Given an audio recording
Audio Imputation Using the Non-negative Hidden Markov Model
 Audio Imputation Using the Non-negative Hidden Markov Model Jinyu Han 1,, Gautham J. Mysore 2, and Bryan Pardo 1 1 EECS Department, Northwestern University 2 Advanced Technology Labs, Adobe Systems Inc.
Audio Imputation Using the Non-negative Hidden Markov Model Jinyu Han 1,, Gautham J. Mysore 2, and Bryan Pardo 1 1 EECS Department, Northwestern University 2 Advanced Technology Labs, Adobe Systems Inc.
Music Signal Processing
 Tutorial Music Signal Processing Meinard Müller Saarland University and MPI Informatik meinard@mpi-inf.mpg.de Anssi Klapuri Queen Mary University of London anssi.klapuri@elec.qmul.ac.uk Overview Part I:
Tutorial Music Signal Processing Meinard Müller Saarland University and MPI Informatik meinard@mpi-inf.mpg.de Anssi Klapuri Queen Mary University of London anssi.klapuri@elec.qmul.ac.uk Overview Part I:
Signals, Sound, and Sensation
 Signals, Sound, and Sensation William M. Hartmann Department of Physics and Astronomy Michigan State University East Lansing, Michigan Л1Р Contents Preface xv Chapter 1: Pure Tones 1 Mathematics of the
Signals, Sound, and Sensation William M. Hartmann Department of Physics and Astronomy Michigan State University East Lansing, Michigan Л1Р Contents Preface xv Chapter 1: Pure Tones 1 Mathematics of the
Signal Processing First Lab 20: Extracting Frequencies of Musical Tones
 Signal Processing First Lab 20: Extracting Frequencies of Musical Tones Pre-Lab and Warm-Up: You should read at least the Pre-Lab and Warm-up sections of this lab assignment and go over all exercises in
Signal Processing First Lab 20: Extracting Frequencies of Musical Tones Pre-Lab and Warm-Up: You should read at least the Pre-Lab and Warm-up sections of this lab assignment and go over all exercises in
University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005
 University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005 Lecture 5 Slides Jan 26 th, 2005 Outline of Today s Lecture Announcements Filter-bank analysis
University of Washington Department of Electrical Engineering Computer Speech Processing EE516 Winter 2005 Lecture 5 Slides Jan 26 th, 2005 Outline of Today s Lecture Announcements Filter-bank analysis
Perception of pitch. Definitions. Why is pitch important? BSc Audiology/MSc SHS Psychoacoustics wk 5: 12 Feb A. Faulkner.
 Perception of pitch BSc Audiology/MSc SHS Psychoacoustics wk 5: 12 Feb 2009. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence
Perception of pitch BSc Audiology/MSc SHS Psychoacoustics wk 5: 12 Feb 2009. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence
8.3 Basic Parameters for Audio
 8.3 Basic Parameters for Audio Analysis Physical audio signal: simple one-dimensional amplitude = loudness frequency = pitch Psycho-acoustic features: complex A real-life tone arises from a complex superposition
8.3 Basic Parameters for Audio Analysis Physical audio signal: simple one-dimensional amplitude = loudness frequency = pitch Psycho-acoustic features: complex A real-life tone arises from a complex superposition
An Improved Voice Activity Detection Based on Deep Belief Networks
 e-issn 2455 1392 Volume 2 Issue 4, April 2016 pp. 676-683 Scientific Journal Impact Factor : 3.468 http://www.ijcter.com An Improved Voice Activity Detection Based on Deep Belief Networks Shabeeba T. K.
e-issn 2455 1392 Volume 2 Issue 4, April 2016 pp. 676-683 Scientific Journal Impact Factor : 3.468 http://www.ijcter.com An Improved Voice Activity Detection Based on Deep Belief Networks Shabeeba T. K.
AUTOMATED MUSIC TRACK GENERATION
 AUTOMATED MUSIC TRACK GENERATION LOUIS EUGENE Stanford University leugene@stanford.edu GUILLAUME ROSTAING Stanford University rostaing@stanford.edu Abstract: This paper aims at presenting our method to
AUTOMATED MUSIC TRACK GENERATION LOUIS EUGENE Stanford University leugene@stanford.edu GUILLAUME ROSTAING Stanford University rostaing@stanford.edu Abstract: This paper aims at presenting our method to
Auditory Based Feature Vectors for Speech Recognition Systems
 Auditory Based Feature Vectors for Speech Recognition Systems Dr. Waleed H. Abdulla Electrical & Computer Engineering Department The University of Auckland, New Zealand [w.abdulla@auckland.ac.nz] 1 Outlines
Auditory Based Feature Vectors for Speech Recognition Systems Dr. Waleed H. Abdulla Electrical & Computer Engineering Department The University of Auckland, New Zealand [w.abdulla@auckland.ac.nz] 1 Outlines
FFT 1 /n octave analysis wavelet
 06/16 For most acoustic examinations, a simple sound level analysis is insufficient, as not only the overall sound pressure level, but also the frequency-dependent distribution of the level has a significant
06/16 For most acoustic examinations, a simple sound level analysis is insufficient, as not only the overall sound pressure level, but also the frequency-dependent distribution of the level has a significant
VQ Source Models: Perceptual & Phase Issues
 VQ Source Models: Perceptual & Phase Issues Dan Ellis & Ron Weiss Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA {dpwe,ronw}@ee.columbia.edu
VQ Source Models: Perceptual & Phase Issues Dan Ellis & Ron Weiss Laboratory for Recognition and Organization of Speech and Audio Dept. Electrical Eng., Columbia Univ., NY USA {dpwe,ronw}@ee.columbia.edu
Tempo and Beat Tracking
 Lecture Music Processing Tempo and Beat Tracking Meinard Müller International Audio Laboratories Erlangen meinard.mueller@audiolabs-erlangen.de Book: Fundamentals of Music Processing Meinard Müller Fundamentals
Lecture Music Processing Tempo and Beat Tracking Meinard Müller International Audio Laboratories Erlangen meinard.mueller@audiolabs-erlangen.de Book: Fundamentals of Music Processing Meinard Müller Fundamentals
What is Sound? Part II
 What is Sound? Part II Timbre & Noise 1 Prayouandi (2010) - OneOhtrix Point Never PSYCHOACOUSTICS ACOUSTICS LOUDNESS AMPLITUDE PITCH FREQUENCY QUALITY TIMBRE 2 Timbre / Quality everything that is not frequency
What is Sound? Part II Timbre & Noise 1 Prayouandi (2010) - OneOhtrix Point Never PSYCHOACOUSTICS ACOUSTICS LOUDNESS AMPLITUDE PITCH FREQUENCY QUALITY TIMBRE 2 Timbre / Quality everything that is not frequency
Real-time beat estimation using feature extraction
 Real-time beat estimation using feature extraction Kristoffer Jensen and Tue Haste Andersen Department of Computer Science, University of Copenhagen Universitetsparken 1 DK-2100 Copenhagen, Denmark, {krist,haste}@diku.dk,
Real-time beat estimation using feature extraction Kristoffer Jensen and Tue Haste Andersen Department of Computer Science, University of Copenhagen Universitetsparken 1 DK-2100 Copenhagen, Denmark, {krist,haste}@diku.dk,
Gammatone Cepstral Coefficient for Speaker Identification
 Gammatone Cepstral Coefficient for Speaker Identification Rahana Fathima 1, Raseena P E 2 M. Tech Student, Ilahia college of Engineering and Technology, Muvattupuzha, Kerala, India 1 Asst. Professor, Ilahia
Gammatone Cepstral Coefficient for Speaker Identification Rahana Fathima 1, Raseena P E 2 M. Tech Student, Ilahia college of Engineering and Technology, Muvattupuzha, Kerala, India 1 Asst. Professor, Ilahia
Change Point Determination in Audio Data Using Auditory Features
 INTL JOURNAL OF ELECTRONICS AND TELECOMMUNICATIONS, 0, VOL., NO., PP. 8 90 Manuscript received April, 0; revised June, 0. DOI: /eletel-0-00 Change Point Determination in Audio Data Using Auditory Features
INTL JOURNAL OF ELECTRONICS AND TELECOMMUNICATIONS, 0, VOL., NO., PP. 8 90 Manuscript received April, 0; revised June, 0. DOI: /eletel-0-00 Change Point Determination in Audio Data Using Auditory Features
SUB-BAND INDEPENDENT SUBSPACE ANALYSIS FOR DRUM TRANSCRIPTION. Derry FitzGerald, Eugene Coyle
 SUB-BAND INDEPENDEN SUBSPACE ANALYSIS FOR DRUM RANSCRIPION Derry FitzGerald, Eugene Coyle D.I.., Rathmines Rd, Dublin, Ireland derryfitzgerald@dit.ie eugene.coyle@dit.ie Bob Lawlor Department of Electronic
SUB-BAND INDEPENDEN SUBSPACE ANALYSIS FOR DRUM RANSCRIPION Derry FitzGerald, Eugene Coyle D.I.., Rathmines Rd, Dublin, Ireland derryfitzgerald@dit.ie eugene.coyle@dit.ie Bob Lawlor Department of Electronic
Speech Synthesis; Pitch Detection and Vocoders
 Speech Synthesis; Pitch Detection and Vocoders Tai-Shih Chi ( 冀泰石 ) Department of Communication Engineering National Chiao Tung University May. 29, 2008 Speech Synthesis Basic components of the text-to-speech
Speech Synthesis; Pitch Detection and Vocoders Tai-Shih Chi ( 冀泰石 ) Department of Communication Engineering National Chiao Tung University May. 29, 2008 Speech Synthesis Basic components of the text-to-speech
The psychoacoustics of reverberation
 The psychoacoustics of reverberation Steven van de Par Steven.van.de.Par@uni-oldenburg.de July 19, 2016 Thanks to Julian Grosse and Andreas Häußler 2016 AES International Conference on Sound Field Control
The psychoacoustics of reverberation Steven van de Par Steven.van.de.Par@uni-oldenburg.de July 19, 2016 Thanks to Julian Grosse and Andreas Häußler 2016 AES International Conference on Sound Field Control
Comparison of Spectral Analysis Methods for Automatic Speech Recognition
 INTERSPEECH 2013 Comparison of Spectral Analysis Methods for Automatic Speech Recognition Venkata Neelima Parinam, Chandra Vootkuri, Stephen A. Zahorian Department of Electrical and Computer Engineering
INTERSPEECH 2013 Comparison of Spectral Analysis Methods for Automatic Speech Recognition Venkata Neelima Parinam, Chandra Vootkuri, Stephen A. Zahorian Department of Electrical and Computer Engineering
AN ANALYSIS OF SPEECH RECOGNITION PERFORMANCE BASED UPON NETWORK LAYERS AND TRANSFER FUNCTIONS
 AN ANALYSIS OF SPEECH RECOGNITION PERFORMANCE BASED UPON NETWORK LAYERS AND TRANSFER FUNCTIONS Kuldeep Kumar 1, R. K. Aggarwal 1 and Ankita Jain 2 1 Department of Computer Engineering, National Institute
AN ANALYSIS OF SPEECH RECOGNITION PERFORMANCE BASED UPON NETWORK LAYERS AND TRANSFER FUNCTIONS Kuldeep Kumar 1, R. K. Aggarwal 1 and Ankita Jain 2 1 Department of Computer Engineering, National Institute
Audio Fingerprinting using Fractional Fourier Transform
 Audio Fingerprinting using Fractional Fourier Transform Swati V. Sutar 1, D. G. Bhalke 2 1 (Department of Electronics & Telecommunication, JSPM s RSCOE college of Engineering Pune, India) 2 (Department,
Audio Fingerprinting using Fractional Fourier Transform Swati V. Sutar 1, D. G. Bhalke 2 1 (Department of Electronics & Telecommunication, JSPM s RSCOE college of Engineering Pune, India) 2 (Department,
A SEGMENTATION-BASED TEMPO INDUCTION METHOD
 A SEGMENTATION-BASED TEMPO INDUCTION METHOD Maxime Le Coz, Helene Lachambre, Lionel Koenig and Regine Andre-Obrecht IRIT, Universite Paul Sabatier, 118 Route de Narbonne, F-31062 TOULOUSE CEDEX 9 {lecoz,lachambre,koenig,obrecht}@irit.fr
A SEGMENTATION-BASED TEMPO INDUCTION METHOD Maxime Le Coz, Helene Lachambre, Lionel Koenig and Regine Andre-Obrecht IRIT, Universite Paul Sabatier, 118 Route de Narbonne, F-31062 TOULOUSE CEDEX 9 {lecoz,lachambre,koenig,obrecht}@irit.fr
Nonlinear Audio Recurrence Analysis with Application to Music Genre Classification.
 Nonlinear Audio Recurrence Analysis with Application to Music Genre Classification. Carlos A. de los Santos Guadarrama MASTER THESIS UPF / 21 Master in Sound and Music Computing Master thesis supervisors:
Nonlinear Audio Recurrence Analysis with Application to Music Genre Classification. Carlos A. de los Santos Guadarrama MASTER THESIS UPF / 21 Master in Sound and Music Computing Master thesis supervisors:
Chapter 4. Digital Audio Representation CS 3570
 Chapter 4. Digital Audio Representation CS 3570 1 Objectives Be able to apply the Nyquist theorem to understand digital audio aliasing. Understand how dithering and noise shaping are done. Understand the
Chapter 4. Digital Audio Representation CS 3570 1 Objectives Be able to apply the Nyquist theorem to understand digital audio aliasing. Understand how dithering and noise shaping are done. Understand the
International Journal of Engineering and Techniques - Volume 1 Issue 6, Nov Dec 2015
 RESEARCH ARTICLE OPEN ACCESS A Comparative Study on Feature Extraction Technique for Isolated Word Speech Recognition Easwari.N 1, Ponmuthuramalingam.P 2 1,2 (PG & Research Department of Computer Science,
RESEARCH ARTICLE OPEN ACCESS A Comparative Study on Feature Extraction Technique for Isolated Word Speech Recognition Easwari.N 1, Ponmuthuramalingam.P 2 1,2 (PG & Research Department of Computer Science,
Lecture 6. Rhythm Analysis. (some slides are adapted from Zafar Rafii and some figures are from Meinard Mueller)
") Lecture 6 Rhythm Analysis (some slides are adapted from Zafar Rafii and some figures are from Meinard Mueller) Definitions for Rhythm Analysis Rhythm: movement marked by the regulated succession of strong
Lecture 6 Rhythm Analysis (some slides are adapted from Zafar Rafii and some figures are from Meinard Mueller) Definitions for Rhythm Analysis Rhythm: movement marked by the regulated succession of strong
IMPROVING ACCURACY OF POLYPHONIC MUSIC-TO-SCORE ALIGNMENT
 10th International Society for Music Information Retrieval Conference (ISMIR 2009) IMPROVING ACCURACY OF POLYPHONIC MUSIC-TO-SCORE ALIGNMENT Bernhard Niedermayer Department for Computational Perception
10th International Society for Music Information Retrieval Conference (ISMIR 2009) IMPROVING ACCURACY OF POLYPHONIC MUSIC-TO-SCORE ALIGNMENT Bernhard Niedermayer Department for Computational Perception
SIGNAL PROCESSING FOR ROBUST SPEECH RECOGNITION MOTIVATED BY AUDITORY PROCESSING CHANWOO KIM
 SIGNAL PROCESSING FOR ROBUST SPEECH RECOGNITION MOTIVATED BY AUDITORY PROCESSING CHANWOO KIM MAY 21 ABSTRACT Although automatic speech recognition systems have dramatically improved in recent decades,
SIGNAL PROCESSING FOR ROBUST SPEECH RECOGNITION MOTIVATED BY AUDITORY PROCESSING CHANWOO KIM MAY 21 ABSTRACT Although automatic speech recognition systems have dramatically improved in recent decades,
Multimedia Signal Processing: Theory and Applications in Speech, Music and Communications
 Brochure More information from http://www.researchandmarkets.com/reports/569388/ Multimedia Signal Processing: Theory and Applications in Speech, Music and Communications Description: Multimedia Signal
Brochure More information from http://www.researchandmarkets.com/reports/569388/ Multimedia Signal Processing: Theory and Applications in Speech, Music and Communications Description: Multimedia Signal
Speech Coding in the Frequency Domain
 Speech Coding in the Frequency Domain Speech Processing Advanced Topics Tom Bäckström Aalto University October 215 Introduction The speech production model can be used to efficiently encode speech signals.
Speech Coding in the Frequency Domain Speech Processing Advanced Topics Tom Bäckström Aalto University October 215 Introduction The speech production model can be used to efficiently encode speech signals.
Automatic Text-Independent. Speaker. Recognition Approaches Using Binaural Inputs
 Automatic Text-Independent Speaker Recognition Approaches Using Binaural Inputs Karim Youssef, Sylvain Argentieri and Jean-Luc Zarader 1 Outline Automatic speaker recognition: introduction Designed systems
Automatic Text-Independent Speaker Recognition Approaches Using Binaural Inputs Karim Youssef, Sylvain Argentieri and Jean-Luc Zarader 1 Outline Automatic speaker recognition: introduction Designed systems
Long Range Acoustic Classification
 Approved for public release; distribution is unlimited. Long Range Acoustic Classification Authors: Ned B. Thammakhoune, Stephen W. Lang Sanders a Lockheed Martin Company P. O. Box 868 Nashua, New Hampshire
Approved for public release; distribution is unlimited. Long Range Acoustic Classification Authors: Ned B. Thammakhoune, Stephen W. Lang Sanders a Lockheed Martin Company P. O. Box 868 Nashua, New Hampshire
ECE 556 BASICS OF DIGITAL SPEECH PROCESSING. Assıst.Prof.Dr. Selma ÖZAYDIN Spring Term-2017 Lecture 2
 ECE 556 BASICS OF DIGITAL SPEECH PROCESSING Assıst.Prof.Dr. Selma ÖZAYDIN Spring Term-2017 Lecture 2 Analog Sound to Digital Sound Characteristics of Sound Amplitude Wavelength (w) Frequency ( ) Timbre
ECE 556 BASICS OF DIGITAL SPEECH PROCESSING Assıst.Prof.Dr. Selma ÖZAYDIN Spring Term-2017 Lecture 2 Analog Sound to Digital Sound Characteristics of Sound Amplitude Wavelength (w) Frequency ( ) Timbre
Rhythm Analysis in Music
 Rhythm Analysis in Music EECS 352: Machine Perception of Music & Audio Zafar Rafii, Winter 24 Some Definitions Rhythm movement marked by the regulated succession of strong and weak elements, or of opposite
Rhythm Analysis in Music EECS 352: Machine Perception of Music & Audio Zafar Rafii, Winter 24 Some Definitions Rhythm movement marked by the regulated succession of strong and weak elements, or of opposite
Survey Paper on Music Beat Tracking
 Survey Paper on Music Beat Tracking Vedshree Panchwadkar, Shravani Pande, Prof.Mr.Makarand Velankar Cummins College of Engg, Pune, India vedshreepd@gmail.com, shravni.pande@gmail.com, makarand_v@rediffmail.com
Survey Paper on Music Beat Tracking Vedshree Panchwadkar, Shravani Pande, Prof.Mr.Makarand Velankar Cummins College of Engg, Pune, India vedshreepd@gmail.com, shravni.pande@gmail.com, makarand_v@rediffmail.com
Enhanced Waveform Interpolative Coding at 4 kbps
 Enhanced Waveform Interpolative Coding at 4 kbps Oded Gottesman, and Allen Gersho Signal Compression Lab. University of California, Santa Barbara E-mail: [oded, gersho]@scl.ece.ucsb.edu Signal Compression
Enhanced Waveform Interpolative Coding at 4 kbps Oded Gottesman, and Allen Gersho Signal Compression Lab. University of California, Santa Barbara E-mail: [oded, gersho]@scl.ece.ucsb.edu Signal Compression
Perception of pitch. Definitions. Why is pitch important? BSc Audiology/MSc SHS Psychoacoustics wk 4: 7 Feb A. Faulkner.
 Perception of pitch BSc Audiology/MSc SHS Psychoacoustics wk 4: 7 Feb 2008. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence Erlbaum,
Perception of pitch BSc Audiology/MSc SHS Psychoacoustics wk 4: 7 Feb 2008. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence Erlbaum,
MUSICAL GENRE CLASSIFICATION OF AUDIO DATA USING SOURCE SEPARATION TECHNIQUES. P.S. Lampropoulou, A.S. Lampropoulos and G.A.
 MUSICAL GENRE CLASSIFICATION OF AUDIO DATA USING SOURCE SEPARATION TECHNIQUES P.S. Lampropoulou, A.S. Lampropoulos and G.A. Tsihrintzis Department of Informatics, University of Piraeus 80 Karaoli & Dimitriou
MUSICAL GENRE CLASSIFICATION OF AUDIO DATA USING SOURCE SEPARATION TECHNIQUES P.S. Lampropoulou, A.S. Lampropoulos and G.A. Tsihrintzis Department of Informatics, University of Piraeus 80 Karaoli & Dimitriou
Dimension Reduction of the Modulation Spectrogram for Speaker Verification
 Dimension Reduction of the Modulation Spectrogram for Speaker Verification Tomi Kinnunen Speech and Image Processing Unit Department of Computer Science University of Joensuu, Finland tkinnu@cs.joensuu.fi
Dimension Reduction of the Modulation Spectrogram for Speaker Verification Tomi Kinnunen Speech and Image Processing Unit Department of Computer Science University of Joensuu, Finland tkinnu@cs.joensuu.fi
Automatic Guitar Chord Recognition
 Registration number 100018849 2015 Automatic Guitar Chord Recognition Supervised by Professor Stephen Cox University of East Anglia Faculty of Science School of Computing Sciences Abstract Chord recognition
Registration number 100018849 2015 Automatic Guitar Chord Recognition Supervised by Professor Stephen Cox University of East Anglia Faculty of Science School of Computing Sciences Abstract Chord recognition
Transcription of Piano Music
 Transcription of Piano Music Rudolf BRISUDA Slovak University of Technology in Bratislava Faculty of Informatics and Information Technologies Ilkovičova 2, 842 16 Bratislava, Slovakia xbrisuda@is.stuba.sk
Transcription of Piano Music Rudolf BRISUDA Slovak University of Technology in Bratislava Faculty of Informatics and Information Technologies Ilkovičova 2, 842 16 Bratislava, Slovakia xbrisuda@is.stuba.sk
UNSUPERVISED SPEAKER CHANGE DETECTION FOR BROADCAST NEWS SEGMENTATION
 4th European Signal Processing Conference (EUSIPCO 26), Florence, Italy, September 4-8, 26, copyright by EURASIP UNSUPERVISED SPEAKER CHANGE DETECTION FOR BROADCAST NEWS SEGMENTATION Kasper Jørgensen,
4th European Signal Processing Conference (EUSIPCO 26), Florence, Italy, September 4-8, 26, copyright by EURASIP UNSUPERVISED SPEAKER CHANGE DETECTION FOR BROADCAST NEWS SEGMENTATION Kasper Jørgensen,
Biomedical Signals. Signals and Images in Medicine Dr Nabeel Anwar
 Biomedical Signals Signals and Images in Medicine Dr Nabeel Anwar Noise Removal: Time Domain Techniques 1. Synchronized Averaging (covered in lecture 1) 2. Moving Average Filters (today s topic) 3. Derivative
Biomedical Signals Signals and Images in Medicine Dr Nabeel Anwar Noise Removal: Time Domain Techniques 1. Synchronized Averaging (covered in lecture 1) 2. Moving Average Filters (today s topic) 3. Derivative
A Correlation-Maximization Denoising Filter Used as An Enhancement Frontend for Noise Robust Bird Call Classification
 A Correlation-Maximization Denoising Filter Used as An Enhancement Frontend for Noise Robust Bird Call Classification Wei Chu and Abeer Alwan Speech Processing and Auditory Perception Laboratory Department
A Correlation-Maximization Denoising Filter Used as An Enhancement Frontend for Noise Robust Bird Call Classification Wei Chu and Abeer Alwan Speech Processing and Auditory Perception Laboratory Department
TIME DOMAIN ATTACK AND RELEASE MODELING Applied to Spectral Domain Sound Synthesis
 TIME DOMAIN ATTACK AND RELEASE MODELING Applied to Spectral Domain Sound Synthesis Cornelia Kreutzer, Jacqueline Walker Department of Electronic and Computer Engineering, University of Limerick, Limerick,
TIME DOMAIN ATTACK AND RELEASE MODELING Applied to Spectral Domain Sound Synthesis Cornelia Kreutzer, Jacqueline Walker Department of Electronic and Computer Engineering, University of Limerick, Limerick,
Perception of pitch. Importance of pitch: 2. mother hemp horse. scold. Definitions. Why is pitch important? AUDL4007: 11 Feb A. Faulkner.
 Perception of pitch AUDL4007: 11 Feb 2010. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence Erlbaum, 2005 Chapter 7 1 Definitions
Perception of pitch AUDL4007: 11 Feb 2010. A. Faulkner. See Moore, BCJ Introduction to the Psychology of Hearing, Chapter 5. Or Plack CJ The Sense of Hearing Lawrence Erlbaum, 2005 Chapter 7 1 Definitions
Bag-of-Features Acoustic Event Detection for Sensor Networks
 Bag-of-Features Acoustic Event Detection for Sensor Networks Julian Kürby, René Grzeszick, Axel Plinge, and Gernot A. Fink Pattern Recognition, Computer Science XII, TU Dortmund University September 3,
Bag-of-Features Acoustic Event Detection for Sensor Networks Julian Kürby, René Grzeszick, Axel Plinge, and Gernot A. Fink Pattern Recognition, Computer Science XII, TU Dortmund University September 3,
Pattern Recognition. Part 6: Bandwidth Extension. Gerhard Schmidt
 Pattern Recognition Part 6: Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Institute of Electrical and Information Engineering Digital Signal Processing and System Theory
Pattern Recognition Part 6: Gerhard Schmidt Christian-Albrechts-Universität zu Kiel Faculty of Engineering Institute of Electrical and Information Engineering Digital Signal Processing and System Theory
Aberehe Niguse Gebru ABSTRACT. Keywords Autocorrelation, MATLAB, Music education, Pitch Detection, Wavelet
 Master of Industrial Sciences 2015-2016 Faculty of Engineering Technology, Campus Group T Leuven This paper is written by (a) student(s) in the framework of a Master s Thesis ABC Research Alert VIRTUAL
Master of Industrial Sciences 2015-2016 Faculty of Engineering Technology, Campus Group T Leuven This paper is written by (a) student(s) in the framework of a Master s Thesis ABC Research Alert VIRTUAL
Mikko Myllymäki and Tuomas Virtanen
 NON-STATIONARY NOISE MODEL COMPENSATION IN VOICE ACTIVITY DETECTION Mikko Myllymäki and Tuomas Virtanen Department of Signal Processing, Tampere University of Technology Korkeakoulunkatu 1, 3370, Tampere,
NON-STATIONARY NOISE MODEL COMPENSATION IN VOICE ACTIVITY DETECTION Mikko Myllymäki and Tuomas Virtanen Department of Signal Processing, Tampere University of Technology Korkeakoulunkatu 1, 3370, Tampere,
Music 171: Amplitude Modulation
 Music 7: Amplitude Modulation Tamara Smyth, trsmyth@ucsd.edu Department of Music, University of California, San Diego (UCSD) February 7, 9 Adding Sinusoids Recall that adding sinusoids of the same frequency
Music 7: Amplitude Modulation Tamara Smyth, trsmyth@ucsd.edu Department of Music, University of California, San Diego (UCSD) February 7, 9 Adding Sinusoids Recall that adding sinusoids of the same frequency
Calibration of Microphone Arrays for Improved Speech Recognition
 MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Calibration of Microphone Arrays for Improved Speech Recognition Michael L. Seltzer, Bhiksha Raj TR-2001-43 December 2001 Abstract We present
MITSUBISHI ELECTRIC RESEARCH LABORATORIES http://www.merl.com Calibration of Microphone Arrays for Improved Speech Recognition Michael L. Seltzer, Bhiksha Raj TR-2001-43 December 2001 Abstract We present