Hacking Reinforcement Learning
|
|
|
- Kelly McCoy
- 5 years ago
- Views:
Transcription



1 Hacking Reinforcement Learning Guillem Duran Ballester
2 A tale about hacking AI-Corp
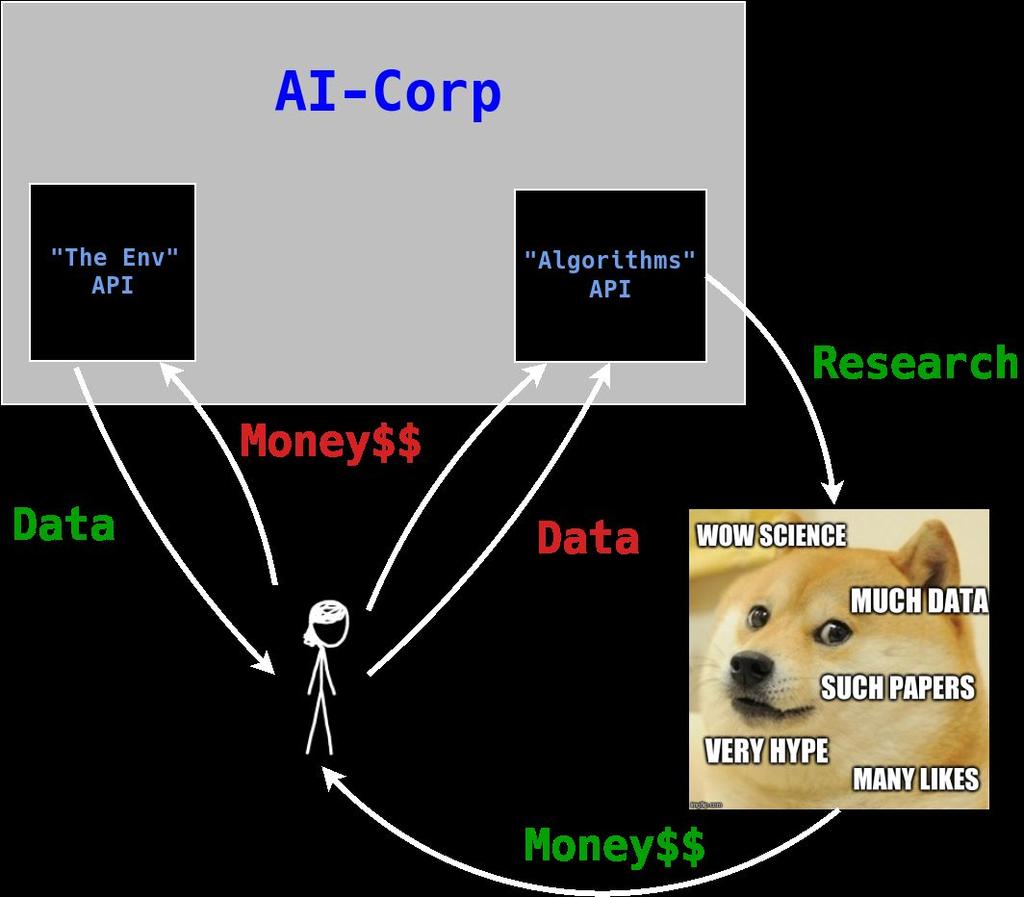

3
4
5 Hacking RL 1. Information gathering 2. Scanning 3. Exploitation & privilege escalation 4. Maintaining access & covering tracks
6 What is RL?, end, info
7 Our Hobby: Developing FractalAI "Study hard what interests you the most in the most undisciplined, irreverent and original manner possible. R. P. Feynman Sergio Guillem
8 Causal entropic forces - Paper by Alex. Wissner-Gross (2013) - Intelligence is a thermodynamic process - No neural networks Equations
9 Intelligent decision Direction of maximum Number of future possible outcomes Given your current state
10 Until you reach the time horizon Count all the paths that exist Map them to a score

11 Cone: Space of future possible outcomes Sample random walks Zero score Present Move away from the wall so fewer walks get 0 score

12

13

14 Nobody likes entropic forces Paper Released - All rewards equal 1 - NP hard!
15 FractalAI Finds low probability points and paths Constrained resources Total control of exploration process Linear time
16 FractalAI A set of rules for: 1. Defining a cloud of points (Swarm) 2. Moving a Swarm in any Cone 3. Measuring and comparing Swarms 4. Analyzing the history of a Swarm
17 Hacking RL 1. Information gathering 2. Finding vulnerabilities & Scanning 3. Exploitation & privilege escalation 4. Covering tracks & Maintaining access



18 RL, end, info


19 Finding an attack vector
20 Swarms are cool - They move in linear time. Pixels/RAM + Reward. They guess density distributions They follow useful paths

21

22 Cunningham's Law "The best way to get the right answer on the Internet is not to ask a question; it's to post the wrong answer." FractalAI SW FMC
23 Using a Swarm to generate data Swarm Wave (SW) - Move a Swarm Sample state space - Cone Tree of visited states - Efficient Only one tree

24
25 Using a Swarm to generate data Swarm Wave (SW) - Move a Swarm Sample state space - Cone Tree of visited states - Efficient Only one tree Fractal Monte Carlo (FMC) - 1 Cone per action - Robust Stochastic/difficult envs - Distribution of action utility

26 Hardcore Lunar Lander HP Fuel Rubber band 2 Continuous DoF FIRE Hook

27 The Gameplay Catch rock outside this circle Reward - Health + Fuel level - Closer to target Reach target +100 Bring rock here Don t crash!
 Catch Rock Drop Rock Rock")
28 FMC Cone - Grey lines: Rocket Paths - Colored lines: Hook s Path - Colored change: New target (Pick up/drop rock) Catch Rock Drop Rock Rock attached

29
30 Hacking RL 1. Information gathering 2. Scanning 3. Exploitation & privilege escalation 4. Maintaining access & covering tracks
31 Demo time!
32 Hacking RL 1. Information gathering 2. Scanning 3. Exploitation & privilege escalation 4. Maintaining access & managing tracks


33 Performance of the Swarm Wave

34 Robust to sparse rewards



35 Solving Atari games is easy


36 SW is useful in virtually all environments

37 Fractal Monte Carlo
38

39


40 Control swarms of agents


41 Multi objective environments
42 Hacking OpenAI Baselines Run_atary.py inject hacked env. A2c.py recover action
43



44
45 Guillem Duran Ballester Guillemdb Let s coauthor papers or hire me! - PyData Mallorca co organizer - Save tons of money! - Telecomm. Engineer - SW & FMC are simple - My hobby: hacking AI stuff - I learn stuff super fast - RL Researcher Wannabe - I like teaching & sharing
46 Thank You! Please Hack us: 1. Talk repo: 2. Code: FragileTheory/FractalAI 3. More than 100 videos 4. PDFs on
47 Additional Material How the algorithm works An overview of the FractalAI repository Reinforcement Learning as a supervised problem Hacking OpenAI baselines Papers that need some love Improving AlphaZero Combining FractalAI with neural networks
48 The Algorithm 1. Random perturbation of the walkers 2. Calculate the virtual reward of each walker a. Distance to 1 random walker b. Reward of current state 3. Clone the walkers Balance the Swarm

49 Random perturbation


50 Walkers & Reward density

51 Cloning Process

52 Cloning balances both densities

53 Choose the action that most walkers share
54 RL is training a DNN model ML without labels Environment Sample the environment Dataset of games Map states to scores Predict good actions
55 Which Envs are compromised? Atari games Solved 32 Games! Sega games Good performance dm_control x1000+ with tricks I hope soon in DoTA 2 & challenging environments
56 If you run it on your laptop in 50 games - Pwns planning SoTA - Cheaper than a human (No Pitfall) games with max scores (1M Bug) - Beats human record 56.36% games
57 RL as a supervised task Train autoencoder with a SW Generate 1M Games and overfit on them Use a GAN to mimic a fractal Use FMC to calculate Q-vals/Advantages Trained model as a prior
58 Give love to papers! Reproducing world models Playing Atari from demonstrations (OpenAI) Playing Atari from YouTube Videos (Deepmind) RUDDER
59 Efficiency on MsPacman An example run: walkers samples / action Scored points Game len samples 1min 38s. Runtime fps SW vs. UCT & p-iw (Assuming 2 x M4.16xlarge) UCT 150k p-iw 150k p-iw 0.5s p-iw 32s Score x1.25 x0.91 x1.85 x1.21 Sampling Efficiency x1260 x1260 x1848 x29581 When UCT(AlphaZero) finishes ⅔ of its first step, SW has already beaten by 25% its final score
60 Improving Alphazero Change UTC for SW sample x faster Stones as reward SW jumps local optima Embedding of conv. layers for distance Use FMC to get better Q-values Heuristics only valid in Go
61 SW: Presenting an unfair benchmark A fair benchmark requires sampling 1M score at 150k samples / step - 10 min play: steps - One step: 400 µs - 1 core game: 4.8s x 150k x 50 rounds -> 416 days - Ideal M4.16xlarge: $3.20 / Hour 500$ per game running 1 instance for 6.5 days - 26,500$ on 53 games Sponsors are welcome
62 Counting Paths vs. Trees Samples / step: confusing Tree of games Traditional Planning Swarm Wave
Adversarial Examples and Adversarial Training. Ian Goodfellow, OpenAI Research Scientist Presentation at Quora,
 Adversarial Examples and Adversarial Training Ian Goodfellow, OpenAI Research Scientist Presentation at Quora, 2016-08-04 In this presentation Intriguing Properties of Neural Networks Szegedy et al, 2013
Adversarial Examples and Adversarial Training Ian Goodfellow, OpenAI Research Scientist Presentation at Quora, 2016-08-04 In this presentation Intriguing Properties of Neural Networks Szegedy et al, 2013
Poker AI: Equilibrium, Online Resolving, Deep Learning and Reinforcement Learning
 Poker AI: Equilibrium, Online Resolving, Deep Learning and Reinforcement Learning Nikolai Yakovenko NVidia ADLR Group -- Santa Clara CA Columbia University Deep Learning Seminar April 2017 Poker is a Turn-Based
Poker AI: Equilibrium, Online Resolving, Deep Learning and Reinforcement Learning Nikolai Yakovenko NVidia ADLR Group -- Santa Clara CA Columbia University Deep Learning Seminar April 2017 Poker is a Turn-Based
Applying Modern Reinforcement Learning to Play Video Games. Computer Science & Engineering Leung Man Ho Supervisor: Prof. LYU Rung Tsong Michael
 Applying Modern Reinforcement Learning to Play Video Games Computer Science & Engineering Leung Man Ho Supervisor: Prof. LYU Rung Tsong Michael Outline Term 1 Review Term 2 Objectives Experiments & Results
Applying Modern Reinforcement Learning to Play Video Games Computer Science & Engineering Leung Man Ho Supervisor: Prof. LYU Rung Tsong Michael Outline Term 1 Review Term 2 Objectives Experiments & Results
Adversarial Examples and Adversarial Training. Ian Goodfellow, OpenAI Research Scientist Presentation at HORSE 2016 London,
 Adversarial Examples and Adversarial Training Ian Goodfellow, OpenAI Research Scientist Presentation at HORSE 2016 London, 2016-09-19 In this presentation Intriguing Properties of Neural Networks Szegedy
Adversarial Examples and Adversarial Training Ian Goodfellow, OpenAI Research Scientist Presentation at HORSE 2016 London, 2016-09-19 In this presentation Intriguing Properties of Neural Networks Szegedy
ConvNets and Forward Modeling for StarCraft AI
 ConvNets and Forward Modeling for StarCraft AI Alex Auvolat September 15, 2016 ConvNets and Forward Modeling for StarCraft AI 1 / 20 Overview ConvNets and Forward Modeling for StarCraft AI 2 / 20 Section
ConvNets and Forward Modeling for StarCraft AI Alex Auvolat September 15, 2016 ConvNets and Forward Modeling for StarCraft AI 1 / 20 Overview ConvNets and Forward Modeling for StarCraft AI 2 / 20 Section
46.1 Introduction. Foundations of Artificial Intelligence Introduction MCTS in AlphaGo Neural Networks. 46.
 Foundations of Artificial Intelligence May 30, 2016 46. AlphaGo and Outlook Foundations of Artificial Intelligence 46. AlphaGo and Outlook Thomas Keller Universität Basel May 30, 2016 46.1 Introduction
Foundations of Artificial Intelligence May 30, 2016 46. AlphaGo and Outlook Foundations of Artificial Intelligence 46. AlphaGo and Outlook Thomas Keller Universität Basel May 30, 2016 46.1 Introduction
Artificial Intelligence. Cameron Jett, William Kentris, Arthur Mo, Juan Roman
 Artificial Intelligence Cameron Jett, William Kentris, Arthur Mo, Juan Roman AI Outline Handicap for AI Machine Learning Monte Carlo Methods Group Intelligence Incorporating stupidity into game AI overview
Artificial Intelligence Cameron Jett, William Kentris, Arthur Mo, Juan Roman AI Outline Handicap for AI Machine Learning Monte Carlo Methods Group Intelligence Incorporating stupidity into game AI overview
Mastering Chess and Shogi by Self- Play with a General Reinforcement Learning Algorithm
 Mastering Chess and Shogi by Self- Play with a General Reinforcement Learning Algorithm by Silver et al Published by Google Deepmind Presented by Kira Selby Background u In March 2016, Deepmind s AlphaGo
Mastering Chess and Shogi by Self- Play with a General Reinforcement Learning Algorithm by Silver et al Published by Google Deepmind Presented by Kira Selby Background u In March 2016, Deepmind s AlphaGo
The Principles Of A.I Alphago
 The Principles Of A.I Alphago YinChen Wu Dr. Hubert Bray Duke Summer Session 20 july 2017 Introduction Go, a traditional Chinese board game, is a remarkable work of art which has been invented for more
The Principles Of A.I Alphago YinChen Wu Dr. Hubert Bray Duke Summer Session 20 july 2017 Introduction Go, a traditional Chinese board game, is a remarkable work of art which has been invented for more
CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions
 CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions Slides by Svetlana Lazebnik, 9/2016 Modified by Mark Hasegawa Johnson, 9/2017 Types of game environments Perfect
CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions Slides by Svetlana Lazebnik, 9/2016 Modified by Mark Hasegawa Johnson, 9/2017 Types of game environments Perfect
DeepMind Self-Learning Atari Agent
 DeepMind Self-Learning Atari Agent Human-level control through deep reinforcement learning Nature Vol 518, Feb 26, 2015 The Deep Mind of Demis Hassabis Backchannel / Medium.com interview with David Levy
DeepMind Self-Learning Atari Agent Human-level control through deep reinforcement learning Nature Vol 518, Feb 26, 2015 The Deep Mind of Demis Hassabis Backchannel / Medium.com interview with David Levy
Swing Copters AI. Monisha White and Nolan Walsh Fall 2015, CS229, Stanford University
 Swing Copters AI Monisha White and Nolan Walsh mewhite@stanford.edu njwalsh@stanford.edu Fall 2015, CS229, Stanford University 1. Introduction For our project we created an autonomous player for the game
Swing Copters AI Monisha White and Nolan Walsh mewhite@stanford.edu njwalsh@stanford.edu Fall 2015, CS229, Stanford University 1. Introduction For our project we created an autonomous player for the game
CSC321 Lecture 23: Go
 CSC321 Lecture 23: Go Roger Grosse Roger Grosse CSC321 Lecture 23: Go 1 / 21 Final Exam Friday, April 20, 9am-noon Last names A Y: Clara Benson Building (BN) 2N Last names Z: Clara Benson Building (BN)
CSC321 Lecture 23: Go Roger Grosse Roger Grosse CSC321 Lecture 23: Go 1 / 21 Final Exam Friday, April 20, 9am-noon Last names A Y: Clara Benson Building (BN) 2N Last names Z: Clara Benson Building (BN)
CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH. Santiago Ontañón
 CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH Santiago Ontañón so367@drexel.edu Recall: Adversarial Search Idea: When there is only one agent in the world, we can solve problems using DFS, BFS, ID,
CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH Santiago Ontañón so367@drexel.edu Recall: Adversarial Search Idea: When there is only one agent in the world, we can solve problems using DFS, BFS, ID,
Monte Carlo Tree Search
 Monte Carlo Tree Search 1 By the end, you will know Why we use Monte Carlo Search Trees The pros and cons of MCTS How it is applied to Super Mario Brothers and Alpha Go 2 Outline I. Pre-MCTS Algorithms
Monte Carlo Tree Search 1 By the end, you will know Why we use Monte Carlo Search Trees The pros and cons of MCTS How it is applied to Super Mario Brothers and Alpha Go 2 Outline I. Pre-MCTS Algorithms
Game-playing: DeepBlue and AlphaGo
 Game-playing: DeepBlue and AlphaGo Brief history of gameplaying frontiers 1990s: Othello world champions refuse to play computers 1994: Chinook defeats Checkers world champion 1997: DeepBlue defeats world
Game-playing: DeepBlue and AlphaGo Brief history of gameplaying frontiers 1990s: Othello world champions refuse to play computers 1994: Chinook defeats Checkers world champion 1997: DeepBlue defeats world
Google DeepMind s AlphaGo vs. world Go champion Lee Sedol
 Google DeepMind s AlphaGo vs. world Go champion Lee Sedol Review of Nature paper: Mastering the game of Go with Deep Neural Networks & Tree Search Tapani Raiko Thanks to Antti Tarvainen for some slides
Google DeepMind s AlphaGo vs. world Go champion Lee Sedol Review of Nature paper: Mastering the game of Go with Deep Neural Networks & Tree Search Tapani Raiko Thanks to Antti Tarvainen for some slides
Prof. Sameer Singh CS 175: PROJECTS IN AI (IN MINECRAFT) WINTER April 6, 2017
 WINTER April 6, 2017") Prof. Sameer Singh CS 175: PROJECTS IN AI (IN MINECRAFT) WINTER 2017 April 6, 2017 Upcoming Misc. Check out course webpage and schedule Check out Canvas, especially for deadlines Do the survey by tomorrow,
Prof. Sameer Singh CS 175: PROJECTS IN AI (IN MINECRAFT) WINTER 2017 April 6, 2017 Upcoming Misc. Check out course webpage and schedule Check out Canvas, especially for deadlines Do the survey by tomorrow,
Andrei Behel AC-43И 1
 Andrei Behel AC-43И 1 History The game of Go originated in China more than 2,500 years ago. The rules of the game are simple: Players take turns to place black or white stones on a board, trying to capture
Andrei Behel AC-43И 1 History The game of Go originated in China more than 2,500 years ago. The rules of the game are simple: Players take turns to place black or white stones on a board, trying to capture
Artificial Intelligence and Deep Learning
 Artificial Intelligence and Deep Learning Cars are now driving themselves (far from perfectly, though) Speaking to a Bot is No Longer Unusual March 2016: World Go Champion Beaten by Machine AI: The Upcoming
Artificial Intelligence and Deep Learning Cars are now driving themselves (far from perfectly, though) Speaking to a Bot is No Longer Unusual March 2016: World Go Champion Beaten by Machine AI: The Upcoming
Success Stories of Deep RL. David Silver
 Success Stories of Deep RL David Silver Reinforcement Learning (RL) RL is a general-purpose framework for decision-making An agent selects actions Its actions influence its future observations Success
Success Stories of Deep RL David Silver Reinforcement Learning (RL) RL is a general-purpose framework for decision-making An agent selects actions Its actions influence its future observations Success
Creating an Agent of Doom: A Visual Reinforcement Learning Approach
 Creating an Agent of Doom: A Visual Reinforcement Learning Approach Michael Lowney Department of Electrical Engineering Stanford University mlowney@stanford.edu Robert Mahieu Department of Electrical Engineering
Creating an Agent of Doom: A Visual Reinforcement Learning Approach Michael Lowney Department of Electrical Engineering Stanford University mlowney@stanford.edu Robert Mahieu Department of Electrical Engineering
Designing AI for Competitive Games. Bruce Hayles & Derek Neal
 Designing AI for Competitive Games Bruce Hayles & Derek Neal Introduction Meet the Speakers Derek Neal Bruce Hayles @brucehayles Director of Production Software Engineer The Problem Same Old Song New User
Designing AI for Competitive Games Bruce Hayles & Derek Neal Introduction Meet the Speakers Derek Neal Bruce Hayles @brucehayles Director of Production Software Engineer The Problem Same Old Song New User
Reinforcement Learning for CPS Safety Engineering. Sam Green, Çetin Kaya Koç, Jieliang Luo University of California, Santa Barbara
 Reinforcement Learning for CPS Safety Engineering Sam Green, Çetin Kaya Koç, Jieliang Luo University of California, Santa Barbara Motivations Safety-critical duties desired by CPS? Autonomous vehicle control:
Reinforcement Learning for CPS Safety Engineering Sam Green, Çetin Kaya Koç, Jieliang Luo University of California, Santa Barbara Motivations Safety-critical duties desired by CPS? Autonomous vehicle control:
Computer Go: from the Beginnings to AlphaGo. Martin Müller, University of Alberta
 Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk Game of Go Short history - Computer Go from the beginnings to AlphaGo The science behind AlphaGo
Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk Game of Go Short history - Computer Go from the beginnings to AlphaGo The science behind AlphaGo
Building a Computer Mahjong Player Based on Monte Carlo Simulation and Opponent Models
 Building a Computer Mahjong Player Based on Monte Carlo Simulation and Opponent Models Naoki Mizukami 1 and Yoshimasa Tsuruoka 1 1 The University of Tokyo 1 Introduction Imperfect information games are
Building a Computer Mahjong Player Based on Monte Carlo Simulation and Opponent Models Naoki Mizukami 1 and Yoshimasa Tsuruoka 1 1 The University of Tokyo 1 Introduction Imperfect information games are
CS221 Project Final Report Deep Q-Learning on Arcade Game Assault
 CS221 Project Final Report Deep Q-Learning on Arcade Game Assault Fabian Chan (fabianc), Xueyuan Mei (xmei9), You Guan (you17) Joint-project with CS229 1 Introduction Atari 2600 Assault is a game environment
CS221 Project Final Report Deep Q-Learning on Arcade Game Assault Fabian Chan (fabianc), Xueyuan Mei (xmei9), You Guan (you17) Joint-project with CS229 1 Introduction Atari 2600 Assault is a game environment
Experiments with Tensor Flow Roman Weber (Geschäftsführer) Richard Schmid (Senior Consultant)
 Richard Schmid (Senior Consultant)") Experiments with Tensor Flow 23.05.2017 Roman Weber (Geschäftsführer) Richard Schmid (Senior Consultant) WEBGATE CONSULTING Gegründet Mitarbeiter CH Inhaber geführt IT Anbieter Partner 2001 Ex 29 Beratung
Experiments with Tensor Flow 23.05.2017 Roman Weber (Geschäftsführer) Richard Schmid (Senior Consultant) WEBGATE CONSULTING Gegründet Mitarbeiter CH Inhaber geführt IT Anbieter Partner 2001 Ex 29 Beratung
CandyCrush.ai: An AI Agent for Candy Crush
 CandyCrush.ai: An AI Agent for Candy Crush Jiwoo Lee, Niranjan Balachandar, Karan Singhal December 16, 2016 1 Introduction Candy Crush, a mobile puzzle game, has become very popular in the past few years.
CandyCrush.ai: An AI Agent for Candy Crush Jiwoo Lee, Niranjan Balachandar, Karan Singhal December 16, 2016 1 Introduction Candy Crush, a mobile puzzle game, has become very popular in the past few years.
Population Initialization Techniques for RHEA in GVGP
 Population Initialization Techniques for RHEA in GVGP Raluca D. Gaina, Simon M. Lucas, Diego Perez-Liebana Introduction Rolling Horizon Evolutionary Algorithms (RHEA) show promise in General Video Game
Population Initialization Techniques for RHEA in GVGP Raluca D. Gaina, Simon M. Lucas, Diego Perez-Liebana Introduction Rolling Horizon Evolutionary Algorithms (RHEA) show promise in General Video Game
TTIC 31230, Fundamentals of Deep Learning David McAllester, April AlphaZero
 TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 AlphaZero 1 AlphaGo Fan (October 2015) AlphaGo Defeats Fan Hui, European Go Champion. 2 AlphaGo Lee (March 2016) 3 AlphaGo Zero vs.
TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 AlphaZero 1 AlphaGo Fan (October 2015) AlphaGo Defeats Fan Hui, European Go Champion. 2 AlphaGo Lee (March 2016) 3 AlphaGo Zero vs.
Game AI Challenges: Past, Present, and Future
 Game AI Challenges: Past, Present, and Future Professor Michael Buro Computing Science, University of Alberta, Edmonton, Canada www.skatgame.net/cpcc2018.pdf 1/ 35 AI / ML Group @ University of Alberta
Game AI Challenges: Past, Present, and Future Professor Michael Buro Computing Science, University of Alberta, Edmonton, Canada www.skatgame.net/cpcc2018.pdf 1/ 35 AI / ML Group @ University of Alberta
TRIAL-BASED HEURISTIC TREE SEARCH FOR FINITE HORIZON MDPS. Thomas Keller and Malte Helmert Presented by: Ryan Berryhill
 TRIAL-BASED HEURISTIC TREE SEARCH FOR FINITE HORIZON MDPS Thomas Keller and Malte Helmert Presented by: Ryan Berryhill Outline Motivation Background THTS framework THTS algorithms Results Motivation Advances
TRIAL-BASED HEURISTIC TREE SEARCH FOR FINITE HORIZON MDPS Thomas Keller and Malte Helmert Presented by: Ryan Berryhill Outline Motivation Background THTS framework THTS algorithms Results Motivation Advances
Adversarial Robustness for Aligned AI
 Adversarial Robustness for Aligned AI Ian Goodfellow, Staff Research NIPS 2017 Workshop on Aligned Artificial Intelligence Many thanks to Catherine Olsson for feedback on drafts The Alignment Problem (This
Adversarial Robustness for Aligned AI Ian Goodfellow, Staff Research NIPS 2017 Workshop on Aligned Artificial Intelligence Many thanks to Catherine Olsson for feedback on drafts The Alignment Problem (This
Principles of Computer Game Design and Implementation. Lecture 20
 Principles of Computer Game Design and Implementation Lecture 20 utline for today Sense-Think-Act Cycle: Thinking Acting 2 Agents and Virtual Player Agents, no virtual player Shooters, racing, Virtual
Principles of Computer Game Design and Implementation Lecture 20 utline for today Sense-Think-Act Cycle: Thinking Acting 2 Agents and Virtual Player Agents, no virtual player Shooters, racing, Virtual
Monte Carlo Tree Search and AlphaGo. Suraj Nair, Peter Kundzicz, Kevin An, Vansh Kumar
 Monte Carlo Tree Search and AlphaGo Suraj Nair, Peter Kundzicz, Kevin An, Vansh Kumar Zero-Sum Games and AI A player s utility gain or loss is exactly balanced by the combined gain or loss of opponents:
Monte Carlo Tree Search and AlphaGo Suraj Nair, Peter Kundzicz, Kevin An, Vansh Kumar Zero-Sum Games and AI A player s utility gain or loss is exactly balanced by the combined gain or loss of opponents:
Using Neural Network and Monte-Carlo Tree Search to Play the Game TEN
 Using Neural Network and Monte-Carlo Tree Search to Play the Game TEN Weijie Chen Fall 2017 Weijie Chen Page 1 of 7 1. INTRODUCTION Game TEN The traditional game Tic-Tac-Toe enjoys people s favor. Moreover,
Using Neural Network and Monte-Carlo Tree Search to Play the Game TEN Weijie Chen Fall 2017 Weijie Chen Page 1 of 7 1. INTRODUCTION Game TEN The traditional game Tic-Tac-Toe enjoys people s favor. Moreover,
Learning from Hints: AI for Playing Threes
 Learning from Hints: AI for Playing Threes Hao Sheng (haosheng), Chen Guo (cguo2) December 17, 2016 1 Introduction The highly addictive stochastic puzzle game Threes by Sirvo LLC. is Apple Game of the
Learning from Hints: AI for Playing Threes Hao Sheng (haosheng), Chen Guo (cguo2) December 17, 2016 1 Introduction The highly addictive stochastic puzzle game Threes by Sirvo LLC. is Apple Game of the
Playing CHIP-8 Games with Reinforcement Learning
 Playing CHIP-8 Games with Reinforcement Learning Niven Achenjang, Patrick DeMichele, Sam Rogers Stanford University Abstract We begin with some background in the history of CHIP-8 games and the use of
Playing CHIP-8 Games with Reinforcement Learning Niven Achenjang, Patrick DeMichele, Sam Rogers Stanford University Abstract We begin with some background in the history of CHIP-8 games and the use of
Department of Computer Science and Engineering. The Chinese University of Hong Kong. Final Year Project Report LYU1601
 Department of Computer Science and Engineering The Chinese University of Hong Kong 2016 2017 LYU1601 Intelligent Non-Player Character with Deep Learning Prepared by ZHANG Haoze Supervised by Prof. Michael
Department of Computer Science and Engineering The Chinese University of Hong Kong 2016 2017 LYU1601 Intelligent Non-Player Character with Deep Learning Prepared by ZHANG Haoze Supervised by Prof. Michael
More on games (Ch )
") More on games (Ch. 5.4-5.6) Announcements Midterm next Tuesday: covers weeks 1-4 (Chapters 1-4) Take the full class period Open book/notes (can use ebook) ^^ No programing/code, internet searches or friends
More on games (Ch. 5.4-5.6) Announcements Midterm next Tuesday: covers weeks 1-4 (Chapters 1-4) Take the full class period Open book/notes (can use ebook) ^^ No programing/code, internet searches or friends
Reinforcement Learning Agent for Scrolling Shooter Game
 Reinforcement Learning Agent for Scrolling Shooter Game Peng Yuan (pengy@stanford.edu) Yangxin Zhong (yangxin@stanford.edu) Zibo Gong (zibo@stanford.edu) 1 Introduction and Task Definition 1.1 Game Agent
Reinforcement Learning Agent for Scrolling Shooter Game Peng Yuan (pengy@stanford.edu) Yangxin Zhong (yangxin@stanford.edu) Zibo Gong (zibo@stanford.edu) 1 Introduction and Task Definition 1.1 Game Agent
How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997)
") How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997) Alan Fern School of Electrical Engineering and Computer Science Oregon State University Deep Mind s vs. Lee Sedol (2016) Watson vs. Ken
How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997) Alan Fern School of Electrical Engineering and Computer Science Oregon State University Deep Mind s vs. Lee Sedol (2016) Watson vs. Ken
Artificial Intelligence ( CS 365 ) IMPLEMENTATION OF AI SCRIPT GENERATOR USING DYNAMIC SCRIPTING FOR AOE2 GAME
 IMPLEMENTATION OF AI SCRIPT GENERATOR USING DYNAMIC SCRIPTING FOR AOE2 GAME") Artificial Intelligence ( CS 365 ) IMPLEMENTATION OF AI SCRIPT GENERATOR USING DYNAMIC SCRIPTING FOR AOE2 GAME Author: Saurabh Chatterjee Guided by: Dr. Amitabha Mukherjee Abstract: I have implemented
Artificial Intelligence ( CS 365 ) IMPLEMENTATION OF AI SCRIPT GENERATOR USING DYNAMIC SCRIPTING FOR AOE2 GAME Author: Saurabh Chatterjee Guided by: Dr. Amitabha Mukherjee Abstract: I have implemented
Dependable AI Systems
 Dependable AI Systems Homa Alemzadeh University of Virginia In collaboration with: Kush Varshney, IBM Research 2 Artificial Intelligence An intelligent agent or system that perceives its environment and
Dependable AI Systems Homa Alemzadeh University of Virginia In collaboration with: Kush Varshney, IBM Research 2 Artificial Intelligence An intelligent agent or system that perceives its environment and
Adversarial Search. CS 486/686: Introduction to Artificial Intelligence
 Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 Introduction So far we have only been concerned with a single agent Today, we introduce an adversary! 2 Outline Games Minimax search
Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 Introduction So far we have only been concerned with a single agent Today, we introduce an adversary! 2 Outline Games Minimax search
By David Anderson SZTAKI (Budapest, Hungary) WPI D2009
 WPI D2009") By David Anderson SZTAKI (Budapest, Hungary) WPI D2009 1997, Deep Blue won against Kasparov Average workstation can defeat best Chess players Computer Chess no longer interesting Go is much harder for
By David Anderson SZTAKI (Budapest, Hungary) WPI D2009 1997, Deep Blue won against Kasparov Average workstation can defeat best Chess players Computer Chess no longer interesting Go is much harder for
CS221 Final Project Report Learn to Play Texas hold em
 CS221 Final Project Report Learn to Play Texas hold em Yixin Tang(yixint), Ruoyu Wang(rwang28), Chang Yue(changyue) 1 Introduction Texas hold em, one of the most popular poker games in casinos, is a variation
CS221 Final Project Report Learn to Play Texas hold em Yixin Tang(yixint), Ruoyu Wang(rwang28), Chang Yue(changyue) 1 Introduction Texas hold em, one of the most popular poker games in casinos, is a variation
Analyzing the Impact of Knowledge and Search in Monte Carlo Tree Search in Go
 Analyzing the Impact of Knowledge and Search in Monte Carlo Tree Search in Go Farhad Haqiqat and Martin Müller University of Alberta Edmonton, Canada Contents Motivation and research goals Feature Knowledge
Analyzing the Impact of Knowledge and Search in Monte Carlo Tree Search in Go Farhad Haqiqat and Martin Müller University of Alberta Edmonton, Canada Contents Motivation and research goals Feature Knowledge
Master Thesis. Enhancing Monte Carlo Tree Search by Using Deep Learning Techniques in Video Games
 Master Thesis Enhancing Monte Carlo Tree Search by Using Deep Learning Techniques in Video Games M. Dienstknecht Master Thesis DKE 18-13 Thesis submitted in partial fulfillment of the requirements for
Master Thesis Enhancing Monte Carlo Tree Search by Using Deep Learning Techniques in Video Games M. Dienstknecht Master Thesis DKE 18-13 Thesis submitted in partial fulfillment of the requirements for
Creating a Dominion AI Using Genetic Algorithms
 Creating a Dominion AI Using Genetic Algorithms Abstract Mok Ming Foong Dominion is a deck-building card game. It allows for complex strategies, has an aspect of randomness in card drawing, and no obvious
Creating a Dominion AI Using Genetic Algorithms Abstract Mok Ming Foong Dominion is a deck-building card game. It allows for complex strategies, has an aspect of randomness in card drawing, and no obvious
VISUAL ANALOGIES BETWEEN ATARI GAMES FOR STUDYING TRANSFER LEARNING IN RL
 VISUAL ANALOGIES BETWEEN ATARI GAMES FOR STUDYING TRANSFER LEARNING IN RL Doron Sobol 1, Lior Wolf 1,2 & Yaniv Taigman 2 1 School of Computer Science, Tel-Aviv University 2 Facebook AI Research ABSTRACT
VISUAL ANALOGIES BETWEEN ATARI GAMES FOR STUDYING TRANSFER LEARNING IN RL Doron Sobol 1, Lior Wolf 1,2 & Yaniv Taigman 2 1 School of Computer Science, Tel-Aviv University 2 Facebook AI Research ABSTRACT
Learning to Play Love Letter with Deep Reinforcement Learning
 Learning to Play Love Letter with Deep Reinforcement Learning Madeleine D. Dawson* MIT mdd@mit.edu Robert X. Liang* MIT xbliang@mit.edu Alexander M. Turner* MIT turneram@mit.edu Abstract Recent advancements
Learning to Play Love Letter with Deep Reinforcement Learning Madeleine D. Dawson* MIT mdd@mit.edu Robert X. Liang* MIT xbliang@mit.edu Alexander M. Turner* MIT turneram@mit.edu Abstract Recent advancements
Heads-up Limit Texas Hold em Poker Agent
 Heads-up Limit Texas Hold em Poker Agent Nattapoom Asavareongchai and Pin Pin Tea-mangkornpan CS221 Final Project Report Abstract Our project aims to create an agent that is able to play heads-up limit
Heads-up Limit Texas Hold em Poker Agent Nattapoom Asavareongchai and Pin Pin Tea-mangkornpan CS221 Final Project Report Abstract Our project aims to create an agent that is able to play heads-up limit
Opleiding Informatica
 Opleiding Informatica Agents for the card game of Hearts Joris Teunisse Supervisors: Walter Kosters, Jeanette de Graaf BACHELOR THESIS Leiden Institute of Advanced Computer Science (LIACS) www.liacs.leidenuniv.nl
Opleiding Informatica Agents for the card game of Hearts Joris Teunisse Supervisors: Walter Kosters, Jeanette de Graaf BACHELOR THESIS Leiden Institute of Advanced Computer Science (LIACS) www.liacs.leidenuniv.nl
Analysis of Vanilla Rolling Horizon Evolution Parameters in General Video Game Playing
 Analysis of Vanilla Rolling Horizon Evolution Parameters in General Video Game Playing Raluca D. Gaina, Jialin Liu, Simon M. Lucas, Diego Perez-Liebana Introduction One of the most promising techniques
Analysis of Vanilla Rolling Horizon Evolution Parameters in General Video Game Playing Raluca D. Gaina, Jialin Liu, Simon M. Lucas, Diego Perez-Liebana Introduction One of the most promising techniques
AI & Machine Learning. By Jan Øye Lindroos
 AI & Machine Learning By Jan Øye Lindroos About This Talk Brief introduction to AI: Definition and Characteristics Machine Learning: Types of ML, example algorithms Historical Overview: 1940-Present Present
AI & Machine Learning By Jan Øye Lindroos About This Talk Brief introduction to AI: Definition and Characteristics Machine Learning: Types of ML, example algorithms Historical Overview: 1940-Present Present
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Adversarial Search Prof. Scott Niekum The University of Texas at Austin [These slides are based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
CS 188: Artificial Intelligence Adversarial Search Prof. Scott Niekum The University of Texas at Austin [These slides are based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
An Introduction to Machine Learning for Social Scientists
 An Introduction to Machine Learning for Social Scientists Tyler Ransom University of Oklahoma, Dept. of Economics November 10, 2017 Outline 1. Intro 2. Examples 3. Conclusion Tyler Ransom (OU Econ) An
An Introduction to Machine Learning for Social Scientists Tyler Ransom University of Oklahoma, Dept. of Economics November 10, 2017 Outline 1. Intro 2. Examples 3. Conclusion Tyler Ransom (OU Econ) An
Adversarial Search. CS 486/686: Introduction to Artificial Intelligence
 Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 AccessAbility Services Volunteer Notetaker Required Interested? Complete an online application using your WATIAM: https://york.accessiblelearning.com/uwaterloo/
Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 AccessAbility Services Volunteer Notetaker Required Interested? Complete an online application using your WATIAM: https://york.accessiblelearning.com/uwaterloo/
Dota2 is a very popular video game currently.
 Dota2 Outcome Prediction Zhengyao Li 1, Dingyue Cui 2 and Chen Li 3 1 ID: A53210709, Email: zhl380@eng.ucsd.edu 2 ID: A53211051, Email: dicui@eng.ucsd.edu 3 ID: A53218665, Email: lic055@eng.ucsd.edu March
Dota2 Outcome Prediction Zhengyao Li 1, Dingyue Cui 2 and Chen Li 3 1 ID: A53210709, Email: zhl380@eng.ucsd.edu 2 ID: A53211051, Email: dicui@eng.ucsd.edu 3 ID: A53218665, Email: lic055@eng.ucsd.edu March
Improving MCTS and Neural Network Communication in Computer Go
 Improving MCTS and Neural Network Communication in Computer Go Joshua Keller Oscar Perez Worcester Polytechnic Institute a Major Qualifying Project Report submitted to the faculty of Worcester Polytechnic
Improving MCTS and Neural Network Communication in Computer Go Joshua Keller Oscar Perez Worcester Polytechnic Institute a Major Qualifying Project Report submitted to the faculty of Worcester Polytechnic
Robotics at OpenAI. May 1, 2017 By Wojciech Zaremba
 Robotics at OpenAI May 1, 2017 By Wojciech Zaremba Why OpenAI? OpenAI s mission is to build safe AGI, and ensure AGI's benefits are as widely and evenly distributed as possible. Why OpenAI? OpenAI s mission
Robotics at OpenAI May 1, 2017 By Wojciech Zaremba Why OpenAI? OpenAI s mission is to build safe AGI, and ensure AGI's benefits are as widely and evenly distributed as possible. Why OpenAI? OpenAI s mission
Stanford Center for AI Safety
 Stanford Center for AI Safety Clark Barrett, David L. Dill, Mykel J. Kochenderfer, Dorsa Sadigh 1 Introduction Software-based systems play important roles in many areas of modern life, including manufacturing,
Stanford Center for AI Safety Clark Barrett, David L. Dill, Mykel J. Kochenderfer, Dorsa Sadigh 1 Introduction Software-based systems play important roles in many areas of modern life, including manufacturing,
Aja Huang Cho Chikun David Silver Demis Hassabis. Fan Hui Geoff Hinton Lee Sedol Michael Redmond
 CMPUT 396 3 hr closedbook 6 pages, 7 marks/page page 1 1. [3 marks] For each person or program, give the label of its description. Aja Huang Cho Chikun David Silver Demis Hassabis Fan Hui Geoff Hinton
CMPUT 396 3 hr closedbook 6 pages, 7 marks/page page 1 1. [3 marks] For each person or program, give the label of its description. Aja Huang Cho Chikun David Silver Demis Hassabis Fan Hui Geoff Hinton
Pushing the rule engine to its limits with Drools Planner. Geoffrey De Smet
 Pushing the rule engine to its limits with Drools Planner Geoffrey De Smet Agenda Drools Platform overview Use cases Bin packaging What is NP complete? Employee shift rostering Hard and soft constraints
Pushing the rule engine to its limits with Drools Planner Geoffrey De Smet Agenda Drools Platform overview Use cases Bin packaging What is NP complete? Employee shift rostering Hard and soft constraints
COMP3211 Project. Artificial Intelligence for Tron game. Group 7. Chiu Ka Wa ( ) Chun Wai Wong ( ) Ku Chun Kit ( )
 Chun Wai Wong ( ) Ku Chun Kit ( )") COMP3211 Project Artificial Intelligence for Tron game Group 7 Chiu Ka Wa (20369737) Chun Wai Wong (20265022) Ku Chun Kit (20123470) Abstract Tron is an old and popular game based on a movie of the same
COMP3211 Project Artificial Intelligence for Tron game Group 7 Chiu Ka Wa (20369737) Chun Wai Wong (20265022) Ku Chun Kit (20123470) Abstract Tron is an old and popular game based on a movie of the same
UNIT 13A AI: Games & Search Strategies
 UNIT 13A AI: Games & Search Strategies 1 Artificial Intelligence Branch of computer science that studies the use of computers to perform computational processes normally associated with human intellect
UNIT 13A AI: Games & Search Strategies 1 Artificial Intelligence Branch of computer science that studies the use of computers to perform computational processes normally associated with human intellect
AI Fairness 360. Kush R. Varshney
 IBM Research AI AI Fairness 360 Kush R. Varshney krvarshn@us.ibm.com http://krvarshney.github.io @krvarshney http://aif360.mybluemix.net https://github.com/ibm/aif360 https://pypi.org/project/aif360 2018
IBM Research AI AI Fairness 360 Kush R. Varshney krvarshn@us.ibm.com http://krvarshney.github.io @krvarshney http://aif360.mybluemix.net https://github.com/ibm/aif360 https://pypi.org/project/aif360 2018
Augmenting Self-Learning In Chess Through Expert Imitation
 Augmenting Self-Learning In Chess Through Expert Imitation Michael Xie Department of Computer Science Stanford University Stanford, CA 94305 xie@cs.stanford.edu Gene Lewis Department of Computer Science
Augmenting Self-Learning In Chess Through Expert Imitation Michael Xie Department of Computer Science Stanford University Stanford, CA 94305 xie@cs.stanford.edu Gene Lewis Department of Computer Science
Monte Carlo tree search techniques in the game of Kriegspiel
 Monte Carlo tree search techniques in the game of Kriegspiel Paolo Ciancarini and Gian Piero Favini University of Bologna, Italy 22 IJCAI, Pasadena, July 2009 Agenda Kriegspiel as a partial information
Monte Carlo tree search techniques in the game of Kriegspiel Paolo Ciancarini and Gian Piero Favini University of Bologna, Italy 22 IJCAI, Pasadena, July 2009 Agenda Kriegspiel as a partial information
CS-E4800 Artificial Intelligence
 CS-E4800 Artificial Intelligence Jussi Rintanen Department of Computer Science Aalto University March 9, 2017 Difficulties in Rational Collective Behavior Individual utility in conflict with collective
CS-E4800 Artificial Intelligence Jussi Rintanen Department of Computer Science Aalto University March 9, 2017 Difficulties in Rational Collective Behavior Individual utility in conflict with collective
AI for Autonomous Ships Challenges in Design and Validation
 VTT TECHNICAL RESEARCH CENTRE OF FINLAND LTD AI for Autonomous Ships Challenges in Design and Validation ISSAV 2018 Eetu Heikkilä Autonomous ships - activities in VTT Autonomous ship systems Unmanned engine
VTT TECHNICAL RESEARCH CENTRE OF FINLAND LTD AI for Autonomous Ships Challenges in Design and Validation ISSAV 2018 Eetu Heikkilä Autonomous ships - activities in VTT Autonomous ship systems Unmanned engine
Navigating the AI Adoption Minefield Pitfalls, best practices, and developing your own AI roadmap April 11
 Navigating the AI Adoption Minefield Pitfalls, best practices, and developing your own AI roadmap April 11 Presenter: Cosmin Laslau, Director of Research Products, Lux Research Agenda 1 2 3 Why you yes,
Navigating the AI Adoption Minefield Pitfalls, best practices, and developing your own AI roadmap April 11 Presenter: Cosmin Laslau, Director of Research Products, Lux Research Agenda 1 2 3 Why you yes,
Artificial Intelligence for Games
 Artificial Intelligence for Games CSC404: Video Game Design Elias Adum Let s talk about AI Artificial Intelligence AI is the field of creating intelligent behaviour in machines. Intelligence understood
Artificial Intelligence for Games CSC404: Video Game Design Elias Adum Let s talk about AI Artificial Intelligence AI is the field of creating intelligent behaviour in machines. Intelligence understood
Learning via Delayed Knowledge A Case of Jamming. SaiDhiraj Amuru and R. Michael Buehrer
 Learning via Delayed Knowledge A Case of Jamming SaiDhiraj Amuru and R. Michael Buehrer 1 Why do we need an Intelligent Jammer? Dynamic environment conditions in electronic warfare scenarios failure of
Learning via Delayed Knowledge A Case of Jamming SaiDhiraj Amuru and R. Michael Buehrer 1 Why do we need an Intelligent Jammer? Dynamic environment conditions in electronic warfare scenarios failure of
CS221 Project Final Report Gomoku Game Agent
 CS221 Project Final Report Gomoku Game Agent Qiao Tan qtan@stanford.edu Xiaoti Hu xiaotihu@stanford.edu 1 Introduction Gomoku, also know as five-in-a-row, is a strategy board game which is traditionally
CS221 Project Final Report Gomoku Game Agent Qiao Tan qtan@stanford.edu Xiaoti Hu xiaotihu@stanford.edu 1 Introduction Gomoku, also know as five-in-a-row, is a strategy board game which is traditionally
Ar#ficial)Intelligence!!
Intelligence!!") Introduc*on! Ar#ficial)Intelligence!! Roman Barták Department of Theoretical Computer Science and Mathematical Logic So far we assumed a single-agent environment, but what if there are more agents and
Introduc*on! Ar#ficial)Intelligence!! Roman Barták Department of Theoretical Computer Science and Mathematical Logic So far we assumed a single-agent environment, but what if there are more agents and
The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand).
.") http://waikato.researchgateway.ac.nz/ Research Commons at the University of Waikato Copyright Statement: The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand). The thesis
http://waikato.researchgateway.ac.nz/ Research Commons at the University of Waikato Copyright Statement: The digital copy of this thesis is protected by the Copyright Act 1994 (New Zealand). The thesis
Tutorial of Reinforcement: A Special Focus on Q-Learning
 Tutorial of Reinforcement: A Special Focus on Q-Learning TINGWU WANG, MACHINE LEARNING GROUP, UNIVERSITY OF TORONTO Contents 1. Introduction 1. Discrete Domain vs. Continous Domain 2. Model Based vs. Model
Tutorial of Reinforcement: A Special Focus on Q-Learning TINGWU WANG, MACHINE LEARNING GROUP, UNIVERSITY OF TORONTO Contents 1. Introduction 1. Discrete Domain vs. Continous Domain 2. Model Based vs. Model
It s Over 400: Cooperative reinforcement learning through self-play
 CIS 520 Spring 2018, Project Report It s Over 400: Cooperative reinforcement learning through self-play Team Members: Hadi Elzayn (PennKey: hads; Email: hads@sas.upenn.edu) Mohammad Fereydounian (PennKey:
CIS 520 Spring 2018, Project Report It s Over 400: Cooperative reinforcement learning through self-play Team Members: Hadi Elzayn (PennKey: hads; Email: hads@sas.upenn.edu) Mohammad Fereydounian (PennKey:
Event:
 Raluca D. Gaina @b_gum22 rdgain.github.io Usually people talk about AI as AI bots playing games, and getting very good at it and at dealing with difficult situations us evil researchers put in their ways.
Raluca D. Gaina @b_gum22 rdgain.github.io Usually people talk about AI as AI bots playing games, and getting very good at it and at dealing with difficult situations us evil researchers put in their ways.
SDS PODCAST EPISODE 71 WITH HADELIN DE PONTEVES
 SDS PODCAST EPISODE 71 WITH HADELIN DE PONTEVES This is episode number 71 with your favourite Hadelin de Ponteves. (background music plays) Welcome to the SuperDataScience podcast. My name is Kirill Eremenko,
SDS PODCAST EPISODE 71 WITH HADELIN DE PONTEVES This is episode number 71 with your favourite Hadelin de Ponteves. (background music plays) Welcome to the SuperDataScience podcast. My name is Kirill Eremenko,
School of EECS Washington State University. Artificial Intelligence
 School of EECS Washington State University Artificial Intelligence 1 } Classic AI challenge Easy to represent Difficult to solve } Zero-sum games Total final reward to all players is constant } Perfect
School of EECS Washington State University Artificial Intelligence 1 } Classic AI challenge Easy to represent Difficult to solve } Zero-sum games Total final reward to all players is constant } Perfect
Bootstrapping from Game Tree Search
 Joel Veness David Silver Will Uther Alan Blair University of New South Wales NICTA University of Alberta December 9, 2009 Presentation Overview Introduction Overview Game Tree Search Evaluation Functions
Joel Veness David Silver Will Uther Alan Blair University of New South Wales NICTA University of Alberta December 9, 2009 Presentation Overview Introduction Overview Game Tree Search Evaluation Functions
Artificial Intelligence
 Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory AI Challenge One 140 Challenge 1 grades 120 100 80 60 AI Challenge One Transform to graph Explore the
Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory AI Challenge One 140 Challenge 1 grades 120 100 80 60 AI Challenge One Transform to graph Explore the
Artificial Intelligence and Games Playing Games
 Artificial Intelligence and Games Playing Games Georgios N. Yannakakis @yannakakis Julian Togelius @togelius Your readings from gameaibook.org Chapter: 3 Reminder: Artificial Intelligence and Games Making
Artificial Intelligence and Games Playing Games Georgios N. Yannakakis @yannakakis Julian Togelius @togelius Your readings from gameaibook.org Chapter: 3 Reminder: Artificial Intelligence and Games Making
Decision Making in Multiplayer Environments Application in Backgammon Variants
 Decision Making in Multiplayer Environments Application in Backgammon Variants PhD Thesis by Nikolaos Papahristou AI researcher Department of Applied Informatics Thessaloniki, Greece Contributions Expert
Decision Making in Multiplayer Environments Application in Backgammon Variants PhD Thesis by Nikolaos Papahristou AI researcher Department of Applied Informatics Thessaloniki, Greece Contributions Expert
CS 4700: Foundations of Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence selman@cs.cornell.edu Module: Adversarial Search R&N: Chapter 5 Part II 1 Outline Game Playing Optimal decisions Minimax α-β pruning Case study: Deep Blue
CS 4700: Foundations of Artificial Intelligence selman@cs.cornell.edu Module: Adversarial Search R&N: Chapter 5 Part II 1 Outline Game Playing Optimal decisions Minimax α-β pruning Case study: Deep Blue
Set 4: Game-Playing. ICS 271 Fall 2017 Kalev Kask
 Set 4: Game-Playing ICS 271 Fall 2017 Kalev Kask Overview Computer programs that play 2-player games game-playing as search with the complication of an opponent General principles of game-playing and search
Set 4: Game-Playing ICS 271 Fall 2017 Kalev Kask Overview Computer programs that play 2-player games game-playing as search with the complication of an opponent General principles of game-playing and search
Artificial Intelligence. Minimax and alpha-beta pruning
 Artificial Intelligence Minimax and alpha-beta pruning In which we examine the problems that arise when we try to plan ahead to get the best result in a world that includes a hostile agent (other agent
Artificial Intelligence Minimax and alpha-beta pruning In which we examine the problems that arise when we try to plan ahead to get the best result in a world that includes a hostile agent (other agent
AI Learning Agent for the Game of Battleship
 CS 221 Fall 2016 AI Learning Agent for the Game of Battleship Jordan Ebel (jebel) Kai Yee Wan (kaiw) Abstract This project implements a Battleship-playing agent that uses reinforcement learning to become
CS 221 Fall 2016 AI Learning Agent for the Game of Battleship Jordan Ebel (jebel) Kai Yee Wan (kaiw) Abstract This project implements a Battleship-playing agent that uses reinforcement learning to become
Outcome Forecasting in Sports. Ondřej Hubáček
 Outcome Forecasting in Sports Ondřej Hubáček Motivation & Challenges Motivation exploiting betting markets performance optimization Challenges no available datasets difficulties with establishing the state-of-the-art
Outcome Forecasting in Sports Ondřej Hubáček Motivation & Challenges Motivation exploiting betting markets performance optimization Challenges no available datasets difficulties with establishing the state-of-the-art
MyPawns OppPawns MyKings OppKings MyThreatened OppThreatened MyWins OppWins Draws
 The Role of Opponent Skill Level in Automated Game Learning Ying Ge and Michael Hash Advisor: Dr. Mark Burge Armstrong Atlantic State University Savannah, Geogia USA 31419-1997 geying@drake.armstrong.edu
The Role of Opponent Skill Level in Automated Game Learning Ying Ge and Michael Hash Advisor: Dr. Mark Burge Armstrong Atlantic State University Savannah, Geogia USA 31419-1997 geying@drake.armstrong.edu
Game Playing State of the Art
 Game Playing State of the Art Checkers: Chinook ended 40 year reign of human world champion Marion Tinsley in 1994. Used an endgame database defining perfect play for all positions involving 8 or fewer
Game Playing State of the Art Checkers: Chinook ended 40 year reign of human world champion Marion Tinsley in 1994. Used an endgame database defining perfect play for all positions involving 8 or fewer
CS 5522: Artificial Intelligence II
 CS 5522: Artificial Intelligence II Adversarial Search Instructor: Alan Ritter Ohio State University [These slides were adapted from CS188 Intro to AI at UC Berkeley. All materials available at http://ai.berkeley.edu.]
CS 5522: Artificial Intelligence II Adversarial Search Instructor: Alan Ritter Ohio State University [These slides were adapted from CS188 Intro to AI at UC Berkeley. All materials available at http://ai.berkeley.edu.]
Intro to AI & AI DAOs: Nature 2.0 Edition. Trent Ocean BigchainDB
 Intro to AI & AI DAOs: Nature 2.0 Edition Trent McConaghy @trentmc0 Ocean BigchainDB Trucking 3.5M jobs Retail 4.6M jobs Creative jobs? In an age of AI, How to feed our families? Achieve abundance? Ways
Intro to AI & AI DAOs: Nature 2.0 Edition Trent McConaghy @trentmc0 Ocean BigchainDB Trucking 3.5M jobs Retail 4.6M jobs Creative jobs? In an age of AI, How to feed our families? Achieve abundance? Ways
An Intelligent Agent for Connect-6
 An Intelligent Agent for Connect-6 Sagar Vare, Sherrie Wang, Andrea Zanette {svare, sherwang, zanette}@stanford.edu Institute for Computational and Mathematical Engineering Huang Building 475 Via Ortega
An Intelligent Agent for Connect-6 Sagar Vare, Sherrie Wang, Andrea Zanette {svare, sherwang, zanette}@stanford.edu Institute for Computational and Mathematical Engineering Huang Building 475 Via Ortega
Evolutionary Computation for Creativity and Intelligence. By Darwin Johnson, Alice Quintanilla, and Isabel Tweraser
 Evolutionary Computation for Creativity and Intelligence By Darwin Johnson, Alice Quintanilla, and Isabel Tweraser Introduction to NEAT Stands for NeuroEvolution of Augmenting Topologies (NEAT) Evolves
Evolutionary Computation for Creativity and Intelligence By Darwin Johnson, Alice Quintanilla, and Isabel Tweraser Introduction to NEAT Stands for NeuroEvolution of Augmenting Topologies (NEAT) Evolves
1) Complexity, Emergence & CA (sb) 2) Fractals and L-systems (sb) 3) Multi-agent systems (vg) 4) Swarm intelligence (vg) 5) Artificial evolution (vg)
 Complexity, Emergence & CA (sb) 2) Fractals and L-systems (sb) 3) Multi-agent systems (vg) 4) Swarm intelligence (vg) 5) Artificial evolution (vg)") 1) Complexity, Emergence & CA (sb) 2) Fractals and L-systems (sb) 3) Multi-agent systems (vg) 4) Swarm intelligence (vg) 5) Artificial evolution (vg) 6) Virtual Ecosystems & Perspectives (sb) Inspired
1) Complexity, Emergence & CA (sb) 2) Fractals and L-systems (sb) 3) Multi-agent systems (vg) 4) Swarm intelligence (vg) 5) Artificial evolution (vg) 6) Virtual Ecosystems & Perspectives (sb) Inspired