By David Anderson SZTAKI (Budapest, Hungary) WPI D2009
|
|
|
- Peregrine McBride
- 6 years ago
- Views:
Transcription
 WPI")
1 By David Anderson SZTAKI (Budapest, Hungary) WPI D2009

2 1997, Deep Blue won against Kasparov Average workstation can defeat best Chess players Computer Chess no longer interesting Go is much harder for computers to play Branching factor is ~ versus ~35 in Chess Positional evaluation inaccurate, expensive Game cannot be scored until the end Beginners can defeat best Go programs

3 Two player, total information Players take turns placing black and white stones on grid Board is 19x19 (13x13 or 9x9 for beginners) Object is to surround empty space as territory Pieces can be captured, but not moved Winner determined by most points (territory plus captured pieces)

4 Image from

5 Minimax/α β algorithms require huge trees Tree depth cannot be cut easily
6 Monte Carlo now more popular Simulate random games from the game tree Use results to pick best move Two areas of optimization Discovery of good paths in the game tree Intelligence of random simulations Random games are usually bogus
7 Need to balance between exploration Discovering and simulating new paths And exploitation Simulating the most optimal path Best method is currently UCT given by Levente Kocsis and Csaba Szepesvári.

8 Say you have a slot machine with a probability of giving you money. You can infer this probability through experimentation.
9 What if there are three slot machines, and each has a different probability?
10 You need to choose between experimenting (exploration) and getting the best reward (exploitation).
11 UCB algorithm balances these problems to minimize loss of reward.
12 UCT applies UCB to games like Go, deciding which move to explore next by treating it like the bandit problem.
13 Starts with one level tree of legal board moves
14 Picks best move according to UCB algorithm
15 Runs Monte Carlo simulation, update node s win/loss. This is one iteration of the UCT process.

16 If node gets visited enough times, start looking at its child moves
17 UCT dives deeper, each time picking the most interesting move.

18 Eventually, UCT has built a large tree of simulation information
19 UCT is now in most major competitive programs MoGo used UCT to defeat a professional Used 800 node grid and a 9 stone handicap Much research now focused on improving simulation intelligence
20 Policy decides which move to play next in a random game simulation High stochasticity makes UCT less accurate Takes longer to converge to correct move Too much determinism makes UCT less effective Defeats purpose of Monte Carlo search Might introduce harmful selection bias
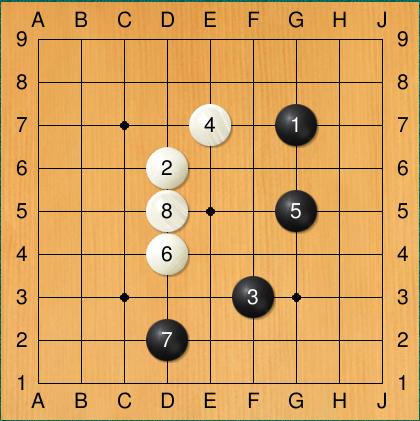
21 Certain shapes in Go are good Hane here is a strong attack on B Others are quite bad! B s empty triangle is too dense and wasteful
22 MoGo uses pattern knowledge with UCT Hand crafted database of 3x3 interesting patterns Doubled simulation win rate according to authors Can pattern knowledge be trained automatically via machine learning?
23 Paper Monte Carlo Simulation Balancing (by David Silver and Gerald Tesauro) Policies accumulate error with each move Strong policies minimize this error, but not the whole game error Proposes algorithms for minimizing whole game error with each move Authors tested on 5x5 Go using 2x2 patterns Found that balancing was more effective over raw strength

24 Implemented pattern learning algorithms in Monte Carlo Simulation Balancing Strength: Apprenticeship Strength: Policy Gradient Reinforcement Balance: Policy Gradient Simulation Balancing Balance: Two Step Simulation Balancing Used 9x9 Go with 3x3 patterns

25 Used amateur database of 9x9 games for training Mention worthy metrics: Simulation winrate against purely random UCT winrate against UCT purely random UCT winrate against GNU Go
26 Simplest algorithm Looks at every move of every game in the training set High preference for chosen moves Low preference for unchosen moves Strongly favored good patterns Over training; poor error compensation Values converge to infinity
27 80 Apprenticeship vs Pure Random Winrate (%) Pure Random Apprenticeship Playout UCT vs libego UCT vs GNU Go Game Type
28 Plays random games from the training set If the simulation matches the original game result, patterns get higher preference Otherwise, lower preference Results were promising
29 70 Reinforcement vs Pure Random Winrate (%) Pure Random Reinforcement Playout UCT vs libego UCT vs GNU Go Game Type
30 For each training game Plays random games to estimate win rate Plays more random games to determine which patterns win and lose Gives preferences to patterns based on error between actual game result and observed winrate
31 Usually, strong local moves Seemed to learn good pattern distribution Aggressively played useless moves hoping for an opponent mistake Poor consideration of the whole board
32

33 60 Simulation Balancing versus Pure Random Winrate (%) Pure Random Simulation Balancing 10 0 Playout UCT vs libego UCT vs GNU Go Game Type
34 Picks random game states Computes score estimate of every move at 2 ply depth Updates pattern preferences based on these results, using actual game result to compensate for error
35 Game score is hard to estimate, usually inaccurate Extremely expensive; sec to estimate score Game score doesn t change meaningfully for many moves Probably does not scale as board size grows
36 70 Two Step Balancing vs Pure Random Winrate (%) Pure Random Two Step Balancing Playout UCT vs libego UCT vs GNU Go Game Type

37

38 80 Algorithm Results Winrate (%) Pure Random Apprenticeship Reinforcement Simulation Balancing Two Step Balancing 10 0 Playout UCT vs libego UCT vs GNU Go Game Type

39 Reinforcement strongest All algorithms capable of very deterministic policies Higher playout winrates were too deterministic and thus usually bad with UCT Go may be too complex for these algorithms Optimizing self play doesn t guarantee good moves
40 Levente Kocsis SZTAKI Professors Sárközy and Selkow
41
42 Algorithm generates list of patterns Each pattern has a weight/value Policy looks at open positions on the board Gets the pattern at each open position Uses weights as a probability distribution
Adversarial Reasoning: Sampling-Based Search with the UCT algorithm. Joint work with Raghuram Ramanujan and Ashish Sabharwal
 Adversarial Reasoning: Sampling-Based Search with the UCT algorithm Joint work with Raghuram Ramanujan and Ashish Sabharwal Upper Confidence bounds for Trees (UCT) n The UCT algorithm (Kocsis and Szepesvari,
Adversarial Reasoning: Sampling-Based Search with the UCT algorithm Joint work with Raghuram Ramanujan and Ashish Sabharwal Upper Confidence bounds for Trees (UCT) n The UCT algorithm (Kocsis and Szepesvari,
CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH. Santiago Ontañón
 CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH Santiago Ontañón so367@drexel.edu Recall: Adversarial Search Idea: When there is only one agent in the world, we can solve problems using DFS, BFS, ID,
CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH Santiago Ontañón so367@drexel.edu Recall: Adversarial Search Idea: When there is only one agent in the world, we can solve problems using DFS, BFS, ID,
A Bandit Approach for Tree Search
 A An Example in Computer-Go Department of Statistics, University of Michigan March 27th, 2008 A 1 Bandit Problem K-Armed Bandit UCB Algorithms for K-Armed Bandit Problem 2 Classical Tree Search UCT Algorithm
A An Example in Computer-Go Department of Statistics, University of Michigan March 27th, 2008 A 1 Bandit Problem K-Armed Bandit UCB Algorithms for K-Armed Bandit Problem 2 Classical Tree Search UCT Algorithm
Monte Carlo Search in Games
 Project Number: CS-GXS-0901 Monte Carlo Search in Games a Major Qualifying Project Report submitted to the Faculty of the WORCESTER POLYTECHNIC INSTITUTE in partial fulfillment of the requirements for
Project Number: CS-GXS-0901 Monte Carlo Search in Games a Major Qualifying Project Report submitted to the Faculty of the WORCESTER POLYTECHNIC INSTITUTE in partial fulfillment of the requirements for
CS 387: GAME AI BOARD GAMES
 CS 387: GAME AI BOARD GAMES 5/28/2015 Instructor: Santiago Ontañón santi@cs.drexel.edu Class website: https://www.cs.drexel.edu/~santi/teaching/2015/cs387/intro.html Reminders Check BBVista site for the
CS 387: GAME AI BOARD GAMES 5/28/2015 Instructor: Santiago Ontañón santi@cs.drexel.edu Class website: https://www.cs.drexel.edu/~santi/teaching/2015/cs387/intro.html Reminders Check BBVista site for the
More on games (Ch )
") More on games (Ch. 5.4-5.6) Alpha-beta pruning Previously on CSci 4511... We talked about how to modify the minimax algorithm to prune only bad searches (i.e. alpha-beta pruning) This rule of checking
More on games (Ch. 5.4-5.6) Alpha-beta pruning Previously on CSci 4511... We talked about how to modify the minimax algorithm to prune only bad searches (i.e. alpha-beta pruning) This rule of checking
Computer Go: from the Beginnings to AlphaGo. Martin Müller, University of Alberta
 Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk Game of Go Short history - Computer Go from the beginnings to AlphaGo The science behind AlphaGo
Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk Game of Go Short history - Computer Go from the beginnings to AlphaGo The science behind AlphaGo
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Adversarial Search Instructor: Stuart Russell University of California, Berkeley Game Playing State-of-the-Art Checkers: 1950: First computer player. 1959: Samuel s self-taught
CS 188: Artificial Intelligence Adversarial Search Instructor: Stuart Russell University of California, Berkeley Game Playing State-of-the-Art Checkers: 1950: First computer player. 1959: Samuel s self-taught
More on games (Ch )
") More on games (Ch. 5.4-5.6) Announcements Midterm next Tuesday: covers weeks 1-4 (Chapters 1-4) Take the full class period Open book/notes (can use ebook) ^^ No programing/code, internet searches or friends
More on games (Ch. 5.4-5.6) Announcements Midterm next Tuesday: covers weeks 1-4 (Chapters 1-4) Take the full class period Open book/notes (can use ebook) ^^ No programing/code, internet searches or friends
Set 4: Game-Playing. ICS 271 Fall 2017 Kalev Kask
 Set 4: Game-Playing ICS 271 Fall 2017 Kalev Kask Overview Computer programs that play 2-player games game-playing as search with the complication of an opponent General principles of game-playing and search
Set 4: Game-Playing ICS 271 Fall 2017 Kalev Kask Overview Computer programs that play 2-player games game-playing as search with the complication of an opponent General principles of game-playing and search
Monte Carlo Tree Search and AlphaGo. Suraj Nair, Peter Kundzicz, Kevin An, Vansh Kumar
 Monte Carlo Tree Search and AlphaGo Suraj Nair, Peter Kundzicz, Kevin An, Vansh Kumar Zero-Sum Games and AI A player s utility gain or loss is exactly balanced by the combined gain or loss of opponents:
Monte Carlo Tree Search and AlphaGo Suraj Nair, Peter Kundzicz, Kevin An, Vansh Kumar Zero-Sum Games and AI A player s utility gain or loss is exactly balanced by the combined gain or loss of opponents:
Andrei Behel AC-43И 1
 Andrei Behel AC-43И 1 History The game of Go originated in China more than 2,500 years ago. The rules of the game are simple: Players take turns to place black or white stones on a board, trying to capture
Andrei Behel AC-43И 1 History The game of Go originated in China more than 2,500 years ago. The rules of the game are simple: Players take turns to place black or white stones on a board, trying to capture
Comparison of Monte Carlo Tree Search Methods in the Imperfect Information Card Game Cribbage
 Comparison of Monte Carlo Tree Search Methods in the Imperfect Information Card Game Cribbage Richard Kelly and David Churchill Computer Science Faculty of Science Memorial University {richard.kelly, dchurchill}@mun.ca
Comparison of Monte Carlo Tree Search Methods in the Imperfect Information Card Game Cribbage Richard Kelly and David Churchill Computer Science Faculty of Science Memorial University {richard.kelly, dchurchill}@mun.ca
Game-playing: DeepBlue and AlphaGo
 Game-playing: DeepBlue and AlphaGo Brief history of gameplaying frontiers 1990s: Othello world champions refuse to play computers 1994: Chinook defeats Checkers world champion 1997: DeepBlue defeats world
Game-playing: DeepBlue and AlphaGo Brief history of gameplaying frontiers 1990s: Othello world champions refuse to play computers 1994: Chinook defeats Checkers world champion 1997: DeepBlue defeats world
ARTIFICIAL INTELLIGENCE (CS 370D)
") Princess Nora University Faculty of Computer & Information Systems ARTIFICIAL INTELLIGENCE (CS 370D) (CHAPTER-5) ADVERSARIAL SEARCH ADVERSARIAL SEARCH Optimal decisions Min algorithm α-β pruning Imperfect,
Princess Nora University Faculty of Computer & Information Systems ARTIFICIAL INTELLIGENCE (CS 370D) (CHAPTER-5) ADVERSARIAL SEARCH ADVERSARIAL SEARCH Optimal decisions Min algorithm α-β pruning Imperfect,
Unit-III Chap-II Adversarial Search. Created by: Ashish Shah 1
 Unit-III Chap-II Adversarial Search Created by: Ashish Shah 1 Alpha beta Pruning In case of standard ALPHA BETA PRUNING minimax tree, it returns the same move as minimax would, but prunes away branches
Unit-III Chap-II Adversarial Search Created by: Ashish Shah 1 Alpha beta Pruning In case of standard ALPHA BETA PRUNING minimax tree, it returns the same move as minimax would, but prunes away branches
Programming Project 1: Pacman (Due )
") Programming Project 1: Pacman (Due 8.2.18) Registration to the exams 521495A: Artificial Intelligence Adversarial Search (Min-Max) Lectured by Abdenour Hadid Adjunct Professor, CMVS, University of Oulu
Programming Project 1: Pacman (Due 8.2.18) Registration to the exams 521495A: Artificial Intelligence Adversarial Search (Min-Max) Lectured by Abdenour Hadid Adjunct Professor, CMVS, University of Oulu
Playing Othello Using Monte Carlo
 June 22, 2007 Abstract This paper deals with the construction of an AI player to play the game Othello. A lot of techniques are already known to let AI players play the game Othello. Some of these techniques
June 22, 2007 Abstract This paper deals with the construction of an AI player to play the game Othello. A lot of techniques are already known to let AI players play the game Othello. Some of these techniques
CS 5522: Artificial Intelligence II
 CS 5522: Artificial Intelligence II Adversarial Search Instructor: Alan Ritter Ohio State University [These slides were adapted from CS188 Intro to AI at UC Berkeley. All materials available at http://ai.berkeley.edu.]
CS 5522: Artificial Intelligence II Adversarial Search Instructor: Alan Ritter Ohio State University [These slides were adapted from CS188 Intro to AI at UC Berkeley. All materials available at http://ai.berkeley.edu.]
Adversarial Search. CS 486/686: Introduction to Artificial Intelligence
 Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 Introduction So far we have only been concerned with a single agent Today, we introduce an adversary! 2 Outline Games Minimax search
Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 Introduction So far we have only been concerned with a single agent Today, we introduce an adversary! 2 Outline Games Minimax search
Improving MCTS and Neural Network Communication in Computer Go
 Improving MCTS and Neural Network Communication in Computer Go Joshua Keller Oscar Perez Worcester Polytechnic Institute a Major Qualifying Project Report submitted to the faculty of Worcester Polytechnic
Improving MCTS and Neural Network Communication in Computer Go Joshua Keller Oscar Perez Worcester Polytechnic Institute a Major Qualifying Project Report submitted to the faculty of Worcester Polytechnic
Implementation of Upper Confidence Bounds for Trees (UCT) on Gomoku
 on Gomoku") Implementation of Upper Confidence Bounds for Trees (UCT) on Gomoku Guanlin Zhou (gz2250), Nan Yu (ny2263), Yanqing Dai (yd2369), Yingtao Zhong (yz3276) 1. Introduction: Reinforcement Learning for Gomoku
Implementation of Upper Confidence Bounds for Trees (UCT) on Gomoku Guanlin Zhou (gz2250), Nan Yu (ny2263), Yanqing Dai (yd2369), Yingtao Zhong (yz3276) 1. Introduction: Reinforcement Learning for Gomoku
Lecture 33: How can computation Win games against you? Chess: Mechanical Turk
 4/2/0 CS 202 Introduction to Computation " UNIVERSITY of WISCONSIN-MADISON Computer Sciences Department Lecture 33: How can computation Win games against you? Professor Andrea Arpaci-Dusseau Spring 200
4/2/0 CS 202 Introduction to Computation " UNIVERSITY of WISCONSIN-MADISON Computer Sciences Department Lecture 33: How can computation Win games against you? Professor Andrea Arpaci-Dusseau Spring 200
Challenges in Monte Carlo Tree Search. Martin Müller University of Alberta
 Challenges in Monte Carlo Tree Search Martin Müller University of Alberta Contents State of the Fuego project (brief) Two Problems with simulations and search Examples from Fuego games Some recent and
Challenges in Monte Carlo Tree Search Martin Müller University of Alberta Contents State of the Fuego project (brief) Two Problems with simulations and search Examples from Fuego games Some recent and
TTIC 31230, Fundamentals of Deep Learning David McAllester, April AlphaZero
 TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 AlphaZero 1 AlphaGo Fan (October 2015) AlphaGo Defeats Fan Hui, European Go Champion. 2 AlphaGo Lee (March 2016) 3 AlphaGo Zero vs.
TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 AlphaZero 1 AlphaGo Fan (October 2015) AlphaGo Defeats Fan Hui, European Go Champion. 2 AlphaGo Lee (March 2016) 3 AlphaGo Zero vs.
Adversarial Search. Human-aware Robotics. 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: Slides for this lecture are here:
 Adversarial Search 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: q Slides for this lecture are here: http://www.public.asu.edu/~yzhan442/teaching/cse471/lectures/adversarial.pdf Slides are largely based
Adversarial Search 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: q Slides for this lecture are here: http://www.public.asu.edu/~yzhan442/teaching/cse471/lectures/adversarial.pdf Slides are largely based
Game Playing State-of-the-Art. CS 188: Artificial Intelligence. Behavior from Computation. Video of Demo Mystery Pacman. Adversarial Search
 CS 188: Artificial Intelligence Adversarial Search Instructor: Marco Alvarez University of Rhode Island (These slides were created/modified by Dan Klein, Pieter Abbeel, Anca Dragan for CS188 at UC Berkeley)
CS 188: Artificial Intelligence Adversarial Search Instructor: Marco Alvarez University of Rhode Island (These slides were created/modified by Dan Klein, Pieter Abbeel, Anca Dragan for CS188 at UC Berkeley)
Recent Progress in Computer Go. Martin Müller University of Alberta Edmonton, Canada
 Recent Progress in Computer Go Martin Müller University of Alberta Edmonton, Canada 40 Years of Computer Go 1960 s: initial ideas 1970 s: first serious program - Reitman & Wilcox 1980 s: first PC programs,
Recent Progress in Computer Go Martin Müller University of Alberta Edmonton, Canada 40 Years of Computer Go 1960 s: initial ideas 1970 s: first serious program - Reitman & Wilcox 1980 s: first PC programs,
Game Playing State-of-the-Art
 Adversarial Search [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188 materials are available at http://ai.berkeley.edu.] Game Playing State-of-the-Art
Adversarial Search [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188 materials are available at http://ai.berkeley.edu.] Game Playing State-of-the-Art
Game-Playing & Adversarial Search
 Game-Playing & Adversarial Search This lecture topic: Game-Playing & Adversarial Search (two lectures) Chapter 5.1-5.5 Next lecture topic: Constraint Satisfaction Problems (two lectures) Chapter 6.1-6.4,
Game-Playing & Adversarial Search This lecture topic: Game-Playing & Adversarial Search (two lectures) Chapter 5.1-5.5 Next lecture topic: Constraint Satisfaction Problems (two lectures) Chapter 6.1-6.4,
CS-E4800 Artificial Intelligence
 CS-E4800 Artificial Intelligence Jussi Rintanen Department of Computer Science Aalto University March 9, 2017 Difficulties in Rational Collective Behavior Individual utility in conflict with collective
CS-E4800 Artificial Intelligence Jussi Rintanen Department of Computer Science Aalto University March 9, 2017 Difficulties in Rational Collective Behavior Individual utility in conflict with collective
CS 771 Artificial Intelligence. Adversarial Search
 CS 771 Artificial Intelligence Adversarial Search Typical assumptions Two agents whose actions alternate Utility values for each agent are the opposite of the other This creates the adversarial situation
CS 771 Artificial Intelligence Adversarial Search Typical assumptions Two agents whose actions alternate Utility values for each agent are the opposite of the other This creates the adversarial situation
An AI for Dominion Based on Monte-Carlo Methods
 An AI for Dominion Based on Monte-Carlo Methods by Jon Vegard Jansen and Robin Tollisen Supervisors: Morten Goodwin, Associate Professor, Ph.D Sondre Glimsdal, Ph.D Fellow June 2, 2014 Abstract To the
An AI for Dominion Based on Monte-Carlo Methods by Jon Vegard Jansen and Robin Tollisen Supervisors: Morten Goodwin, Associate Professor, Ph.D Sondre Glimsdal, Ph.D Fellow June 2, 2014 Abstract To the
Adversarial Search. CS 486/686: Introduction to Artificial Intelligence
 Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 AccessAbility Services Volunteer Notetaker Required Interested? Complete an online application using your WATIAM: https://york.accessiblelearning.com/uwaterloo/
Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 AccessAbility Services Volunteer Notetaker Required Interested? Complete an online application using your WATIAM: https://york.accessiblelearning.com/uwaterloo/
Artificial Intelligence
 Artificial Intelligence Adversarial Search Instructors: David Suter and Qince Li Course Delivered @ Harbin Institute of Technology [Many slides adapted from those created by Dan Klein and Pieter Abbeel
Artificial Intelligence Adversarial Search Instructors: David Suter and Qince Li Course Delivered @ Harbin Institute of Technology [Many slides adapted from those created by Dan Klein and Pieter Abbeel
Pengju
 Introduction to AI Chapter05 Adversarial Search: Game Playing Pengju Ren@IAIR Outline Types of Games Formulation of games Perfect-Information Games Minimax and Negamax search α-β Pruning Pruning more Imperfect
Introduction to AI Chapter05 Adversarial Search: Game Playing Pengju Ren@IAIR Outline Types of Games Formulation of games Perfect-Information Games Minimax and Negamax search α-β Pruning Pruning more Imperfect
Game Playing State of the Art
 Game Playing State of the Art Checkers: Chinook ended 40 year reign of human world champion Marion Tinsley in 1994. Used an endgame database defining perfect play for all positions involving 8 or fewer
Game Playing State of the Art Checkers: Chinook ended 40 year reign of human world champion Marion Tinsley in 1994. Used an endgame database defining perfect play for all positions involving 8 or fewer
Computing Science (CMPUT) 496
 496") Computing Science (CMPUT) 496 Search, Knowledge, and Simulations Martin Müller Department of Computing Science University of Alberta mmueller@ualberta.ca Winter 2017 Part IV Knowledge 496 Today - Mar 9
Computing Science (CMPUT) 496 Search, Knowledge, and Simulations Martin Müller Department of Computing Science University of Alberta mmueller@ualberta.ca Winter 2017 Part IV Knowledge 496 Today - Mar 9
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Adversarial Search Prof. Scott Niekum The University of Texas at Austin [These slides are based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
CS 188: Artificial Intelligence Adversarial Search Prof. Scott Niekum The University of Texas at Austin [These slides are based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
CS 387/680: GAME AI BOARD GAMES
 CS 387/680: GAME AI BOARD GAMES 6/2/2014 Instructor: Santiago Ontañón santi@cs.drexel.edu TA: Alberto Uriarte office hours: Tuesday 4-6pm, Cyber Learning Center Class website: https://www.cs.drexel.edu/~santi/teaching/2014/cs387-680/intro.html
CS 387/680: GAME AI BOARD GAMES 6/2/2014 Instructor: Santiago Ontañón santi@cs.drexel.edu TA: Alberto Uriarte office hours: Tuesday 4-6pm, Cyber Learning Center Class website: https://www.cs.drexel.edu/~santi/teaching/2014/cs387-680/intro.html
CSC321 Lecture 23: Go
 CSC321 Lecture 23: Go Roger Grosse Roger Grosse CSC321 Lecture 23: Go 1 / 21 Final Exam Friday, April 20, 9am-noon Last names A Y: Clara Benson Building (BN) 2N Last names Z: Clara Benson Building (BN)
CSC321 Lecture 23: Go Roger Grosse Roger Grosse CSC321 Lecture 23: Go 1 / 21 Final Exam Friday, April 20, 9am-noon Last names A Y: Clara Benson Building (BN) 2N Last names Z: Clara Benson Building (BN)
Feature Learning Using State Differences
 Feature Learning Using State Differences Mesut Kirci and Jonathan Schaeffer and Nathan Sturtevant Department of Computing Science University of Alberta Edmonton, Alberta, Canada {kirci,nathanst,jonathan}@cs.ualberta.ca
Feature Learning Using State Differences Mesut Kirci and Jonathan Schaeffer and Nathan Sturtevant Department of Computing Science University of Alberta Edmonton, Alberta, Canada {kirci,nathanst,jonathan}@cs.ualberta.ca
Analyzing the Impact of Knowledge and Search in Monte Carlo Tree Search in Go
 Analyzing the Impact of Knowledge and Search in Monte Carlo Tree Search in Go Farhad Haqiqat and Martin Müller University of Alberta Edmonton, Canada Contents Motivation and research goals Feature Knowledge
Analyzing the Impact of Knowledge and Search in Monte Carlo Tree Search in Go Farhad Haqiqat and Martin Müller University of Alberta Edmonton, Canada Contents Motivation and research goals Feature Knowledge
Adversarial Search. Soleymani. Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5
 Adversarial Search CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2017 Soleymani Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5 Outline Game
Adversarial Search CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2017 Soleymani Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5 Outline Game
Adversarial Search. Read AIMA Chapter CIS 421/521 - Intro to AI 1
 Adversarial Search Read AIMA Chapter 5.2-5.5 CIS 421/521 - Intro to AI 1 Adversarial Search Instructors: Dan Klein and Pieter Abbeel University of California, Berkeley [These slides were created by Dan
Adversarial Search Read AIMA Chapter 5.2-5.5 CIS 421/521 - Intro to AI 1 Adversarial Search Instructors: Dan Klein and Pieter Abbeel University of California, Berkeley [These slides were created by Dan
COMP219: COMP219: Artificial Intelligence Artificial Intelligence Dr. Annabel Latham Lecture 12: Game Playing Overview Games and Search
 COMP19: Artificial Intelligence COMP19: Artificial Intelligence Dr. Annabel Latham Room.05 Ashton Building Department of Computer Science University of Liverpool Lecture 1: Game Playing 1 Overview Last
COMP19: Artificial Intelligence COMP19: Artificial Intelligence Dr. Annabel Latham Room.05 Ashton Building Department of Computer Science University of Liverpool Lecture 1: Game Playing 1 Overview Last
Exploration exploitation in Go: UCT for Monte-Carlo Go
 Exploration exploitation in Go: UCT for Monte-Carlo Go Sylvain Gelly(*) and Yizao Wang(*,**) (*)TAO (INRIA), LRI, UMR (CNRS - Univ. Paris-Sud) University of Paris-Sud, Orsay, France sylvain.gelly@lri.fr
Exploration exploitation in Go: UCT for Monte-Carlo Go Sylvain Gelly(*) and Yizao Wang(*,**) (*)TAO (INRIA), LRI, UMR (CNRS - Univ. Paris-Sud) University of Paris-Sud, Orsay, France sylvain.gelly@lri.fr
Game Playing State-of-the-Art CSE 473: Artificial Intelligence Fall Deterministic Games. Zero-Sum Games 10/13/17. Adversarial Search
 CSE 473: Artificial Intelligence Fall 2017 Adversarial Search Mini, pruning, Expecti Dieter Fox Based on slides adapted Luke Zettlemoyer, Dan Klein, Pieter Abbeel, Dan Weld, Stuart Russell or Andrew Moore
CSE 473: Artificial Intelligence Fall 2017 Adversarial Search Mini, pruning, Expecti Dieter Fox Based on slides adapted Luke Zettlemoyer, Dan Klein, Pieter Abbeel, Dan Weld, Stuart Russell or Andrew Moore
Google DeepMind s AlphaGo vs. world Go champion Lee Sedol
 Google DeepMind s AlphaGo vs. world Go champion Lee Sedol Review of Nature paper: Mastering the game of Go with Deep Neural Networks & Tree Search Tapani Raiko Thanks to Antti Tarvainen for some slides
Google DeepMind s AlphaGo vs. world Go champion Lee Sedol Review of Nature paper: Mastering the game of Go with Deep Neural Networks & Tree Search Tapani Raiko Thanks to Antti Tarvainen for some slides
AlphaGo and Artificial Intelligence GUEST LECTURE IN THE GAME OF GO AND SOCIETY
 AlphaGo and Artificial Intelligence HUCK BENNET T (NORTHWESTERN UNIVERSITY) GUEST LECTURE IN THE GAME OF GO AND SOCIETY AT OCCIDENTAL COLLEGE, 10/29/2018 The Game of Go A game for aliens, presidents, and
AlphaGo and Artificial Intelligence HUCK BENNET T (NORTHWESTERN UNIVERSITY) GUEST LECTURE IN THE GAME OF GO AND SOCIETY AT OCCIDENTAL COLLEGE, 10/29/2018 The Game of Go A game for aliens, presidents, and
Theory and Practice of Artificial Intelligence
 Theory and Practice of Artificial Intelligence Games Daniel Polani School of Computer Science University of Hertfordshire March 9, 2017 All rights reserved. Permission is granted to copy and distribute
Theory and Practice of Artificial Intelligence Games Daniel Polani School of Computer Science University of Hertfordshire March 9, 2017 All rights reserved. Permission is granted to copy and distribute
Adversarial Search and Game- Playing C H A P T E R 6 C M P T : S P R I N G H A S S A N K H O S R A V I
 Adversarial Search and Game- Playing C H A P T E R 6 C M P T 3 1 0 : S P R I N G 2 0 1 1 H A S S A N K H O S R A V I Adversarial Search Examine the problems that arise when we try to plan ahead in a world
Adversarial Search and Game- Playing C H A P T E R 6 C M P T 3 1 0 : S P R I N G 2 0 1 1 H A S S A N K H O S R A V I Adversarial Search Examine the problems that arise when we try to plan ahead in a world
TRIAL-BASED HEURISTIC TREE SEARCH FOR FINITE HORIZON MDPS. Thomas Keller and Malte Helmert Presented by: Ryan Berryhill
 TRIAL-BASED HEURISTIC TREE SEARCH FOR FINITE HORIZON MDPS Thomas Keller and Malte Helmert Presented by: Ryan Berryhill Outline Motivation Background THTS framework THTS algorithms Results Motivation Advances
TRIAL-BASED HEURISTIC TREE SEARCH FOR FINITE HORIZON MDPS Thomas Keller and Malte Helmert Presented by: Ryan Berryhill Outline Motivation Background THTS framework THTS algorithms Results Motivation Advances
Monte Carlo Tree Search
 Monte Carlo Tree Search 1 By the end, you will know Why we use Monte Carlo Search Trees The pros and cons of MCTS How it is applied to Super Mario Brothers and Alpha Go 2 Outline I. Pre-MCTS Algorithms
Monte Carlo Tree Search 1 By the end, you will know Why we use Monte Carlo Search Trees The pros and cons of MCTS How it is applied to Super Mario Brothers and Alpha Go 2 Outline I. Pre-MCTS Algorithms
CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions
 CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions Slides by Svetlana Lazebnik, 9/2016 Modified by Mark Hasegawa Johnson, 9/2017 Types of game environments Perfect
CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions Slides by Svetlana Lazebnik, 9/2016 Modified by Mark Hasegawa Johnson, 9/2017 Types of game environments Perfect
Outline. Game Playing. Game Problems. Game Problems. Types of games Playing a perfect game. Playing an imperfect game
 Outline Game Playing ECE457 Applied Artificial Intelligence Fall 2007 Lecture #5 Types of games Playing a perfect game Minimax search Alpha-beta pruning Playing an imperfect game Real-time Imperfect information
Outline Game Playing ECE457 Applied Artificial Intelligence Fall 2007 Lecture #5 Types of games Playing a perfect game Minimax search Alpha-beta pruning Playing an imperfect game Real-time Imperfect information
Application of UCT Search to the Connection Games of Hex, Y, *Star, and Renkula!
 Application of UCT Search to the Connection Games of Hex, Y, *Star, and Renkula! Tapani Raiko and Jaakko Peltonen Helsinki University of Technology, Adaptive Informatics Research Centre, P.O. Box 5400,
Application of UCT Search to the Connection Games of Hex, Y, *Star, and Renkula! Tapani Raiko and Jaakko Peltonen Helsinki University of Technology, Adaptive Informatics Research Centre, P.O. Box 5400,
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2011 Lecture 7: Minimax and Alpha-Beta Search 2/9/2011 Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein 1 Announcements W1 out and due Monday 4:59pm P2
CS 188: Artificial Intelligence Spring 2011 Lecture 7: Minimax and Alpha-Beta Search 2/9/2011 Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein 1 Announcements W1 out and due Monday 4:59pm P2
Announcements. CS 188: Artificial Intelligence Spring Game Playing State-of-the-Art. Overview. Game Playing. GamesCrafters
 CS 188: Artificial Intelligence Spring 2011 Announcements W1 out and due Monday 4:59pm P2 out and due next week Friday 4:59pm Lecture 7: Mini and Alpha-Beta Search 2/9/2011 Pieter Abbeel UC Berkeley Many
CS 188: Artificial Intelligence Spring 2011 Announcements W1 out and due Monday 4:59pm P2 out and due next week Friday 4:59pm Lecture 7: Mini and Alpha-Beta Search 2/9/2011 Pieter Abbeel UC Berkeley Many
Announcements. Homework 1. Project 1. Due tonight at 11:59pm. Due Friday 2/8 at 4:00pm. Electronic HW1 Written HW1
 Announcements Homework 1 Due tonight at 11:59pm Project 1 Electronic HW1 Written HW1 Due Friday 2/8 at 4:00pm CS 188: Artificial Intelligence Adversarial Search and Game Trees Instructors: Sergey Levine
Announcements Homework 1 Due tonight at 11:59pm Project 1 Electronic HW1 Written HW1 Due Friday 2/8 at 4:00pm CS 188: Artificial Intelligence Adversarial Search and Game Trees Instructors: Sergey Levine
CS 387: GAME AI BOARD GAMES. 5/24/2016 Instructor: Santiago Ontañón
 CS 387: GAME AI BOARD GAMES 5/24/2016 Instructor: Santiago Ontañón santi@cs.drexel.edu Class website: https://www.cs.drexel.edu/~santi/teaching/2016/cs387/intro.html Reminders Check BBVista site for the
CS 387: GAME AI BOARD GAMES 5/24/2016 Instructor: Santiago Ontañón santi@cs.drexel.edu Class website: https://www.cs.drexel.edu/~santi/teaching/2016/cs387/intro.html Reminders Check BBVista site for the
game tree complete all possible moves
 Game Trees Game Tree A game tree is a tree the nodes of which are positions in a game and edges are moves. The complete game tree for a game is the game tree starting at the initial position and containing
Game Trees Game Tree A game tree is a tree the nodes of which are positions in a game and edges are moves. The complete game tree for a game is the game tree starting at the initial position and containing
Foundations of AI. 6. Adversarial Search. Search Strategies for Games, Games with Chance, State of the Art. Wolfram Burgard & Bernhard Nebel
 Foundations of AI 6. Adversarial Search Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard & Bernhard Nebel Contents Game Theory Board Games Minimax Search Alpha-Beta Search
Foundations of AI 6. Adversarial Search Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard & Bernhard Nebel Contents Game Theory Board Games Minimax Search Alpha-Beta Search
Production of Various Strategies and Position Control for Monte-Carlo Go - Entertaining human players
 Production of Various Strategies and Position Control for Monte-Carlo Go - Entertaining human players Kokolo Ikeda and Simon Viennot Abstract Thanks to the continued development of tree search algorithms,
Production of Various Strategies and Position Control for Monte-Carlo Go - Entertaining human players Kokolo Ikeda and Simon Viennot Abstract Thanks to the continued development of tree search algorithms,
Local Search. Hill Climbing. Hill Climbing Diagram. Simulated Annealing. Simulated Annealing. Introduction to Artificial Intelligence
 Introduction to Artificial Intelligence V22.0472-001 Fall 2009 Lecture 6: Adversarial Search Local Search Queue-based algorithms keep fallback options (backtracking) Local search: improve what you have
Introduction to Artificial Intelligence V22.0472-001 Fall 2009 Lecture 6: Adversarial Search Local Search Queue-based algorithms keep fallback options (backtracking) Local search: improve what you have
Adversarial Search: Game Playing. Reading: Chapter
 Adversarial Search: Game Playing Reading: Chapter 6.5-6.8 1 Games and AI Easy to represent, abstract, precise rules One of the first tasks undertaken by AI (since 1950) Better than humans in Othello and
Adversarial Search: Game Playing Reading: Chapter 6.5-6.8 1 Games and AI Easy to represent, abstract, precise rules One of the first tasks undertaken by AI (since 1950) Better than humans in Othello and
Artificial Intelligence for Go. Kristen Ying Advisors: Dr. Maxim Likhachev & Dr. Norm Badler
 Artificial Intelligence for Go Kristen Ying Advisors: Dr. Maxim Likhachev & Dr. Norm Badler 1 Introduction 2 Algorithms 3 Implementation 4 Results 1 Introduction 2 Algorithms 3 Implementation 4 Results
Artificial Intelligence for Go Kristen Ying Advisors: Dr. Maxim Likhachev & Dr. Norm Badler 1 Introduction 2 Algorithms 3 Implementation 4 Results 1 Introduction 2 Algorithms 3 Implementation 4 Results
A Complex Systems Introduction to Go
 A Complex Systems Introduction to Go Eric Jankowski CSAAW 10-22-2007 Background image by Juha Nieminen Wei Chi, Go, Baduk... Oldest board game in the world (maybe) Developed by Chinese monks Spread to
A Complex Systems Introduction to Go Eric Jankowski CSAAW 10-22-2007 Background image by Juha Nieminen Wei Chi, Go, Baduk... Oldest board game in the world (maybe) Developed by Chinese monks Spread to
Programming an Othello AI Michael An (man4), Evan Liang (liange)
, Evan Liang (liange)") Programming an Othello AI Michael An (man4), Evan Liang (liange) 1 Introduction Othello is a two player board game played on an 8 8 grid. Players take turns placing stones with their assigned color (black
Programming an Othello AI Michael An (man4), Evan Liang (liange) 1 Introduction Othello is a two player board game played on an 8 8 grid. Players take turns placing stones with their assigned color (black
Training a Back-Propagation Network with Temporal Difference Learning and a database for the board game Pente
 Training a Back-Propagation Network with Temporal Difference Learning and a database for the board game Pente Valentijn Muijrers 3275183 Valentijn.Muijrers@phil.uu.nl Supervisor: Gerard Vreeswijk 7,5 ECTS
Training a Back-Propagation Network with Temporal Difference Learning and a database for the board game Pente Valentijn Muijrers 3275183 Valentijn.Muijrers@phil.uu.nl Supervisor: Gerard Vreeswijk 7,5 ECTS
Game-playing AIs: Games and Adversarial Search FINAL SET (w/ pruning study examples) AIMA
 AIMA") Game-playing AIs: Games and Adversarial Search FINAL SET (w/ pruning study examples) AIMA 5.1-5.2 Games: Outline of Unit Part I: Games as Search Motivation Game-playing AI successes Game Trees Evaluation
Game-playing AIs: Games and Adversarial Search FINAL SET (w/ pruning study examples) AIMA 5.1-5.2 Games: Outline of Unit Part I: Games as Search Motivation Game-playing AI successes Game Trees Evaluation
Foundations of AI. 6. Board Games. Search Strategies for Games, Games with Chance, State of the Art
 Foundations of AI 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Andreas Karwath, Bernhard Nebel, and Martin Riedmiller SA-1 Contents Board Games Minimax
Foundations of AI 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Andreas Karwath, Bernhard Nebel, and Martin Riedmiller SA-1 Contents Board Games Minimax
A Parallel Monte-Carlo Tree Search Algorithm
 A Parallel Monte-Carlo Tree Search Algorithm Tristan Cazenave and Nicolas Jouandeau LIASD, Université Paris 8, 93526, Saint-Denis, France cazenave@ai.univ-paris8.fr n@ai.univ-paris8.fr Abstract. Monte-Carlo
A Parallel Monte-Carlo Tree Search Algorithm Tristan Cazenave and Nicolas Jouandeau LIASD, Université Paris 8, 93526, Saint-Denis, France cazenave@ai.univ-paris8.fr n@ai.univ-paris8.fr Abstract. Monte-Carlo
Adversarial Search. Hal Daumé III. Computer Science University of Maryland CS 421: Introduction to Artificial Intelligence 9 Feb 2012
 1 Hal Daumé III (me@hal3.name) Adversarial Search Hal Daumé III Computer Science University of Maryland me@hal3.name CS 421: Introduction to Artificial Intelligence 9 Feb 2012 Many slides courtesy of Dan
1 Hal Daumé III (me@hal3.name) Adversarial Search Hal Daumé III Computer Science University of Maryland me@hal3.name CS 421: Introduction to Artificial Intelligence 9 Feb 2012 Many slides courtesy of Dan
Artificial Intelligence
 Artificial Intelligence Adversarial Search Vibhav Gogate The University of Texas at Dallas Some material courtesy of Rina Dechter, Alex Ihler and Stuart Russell, Luke Zettlemoyer, Dan Weld Adversarial
Artificial Intelligence Adversarial Search Vibhav Gogate The University of Texas at Dallas Some material courtesy of Rina Dechter, Alex Ihler and Stuart Russell, Luke Zettlemoyer, Dan Weld Adversarial
Contents. Foundations of Artificial Intelligence. Problems. Why Board Games?
 Contents Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Bernhard Nebel, and Martin Riedmiller Albert-Ludwigs-Universität
Contents Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Bernhard Nebel, and Martin Riedmiller Albert-Ludwigs-Universität
MONTE-CARLO TWIXT. Janik Steinhauer. Master Thesis 10-08
 MONTE-CARLO TWIXT Janik Steinhauer Master Thesis 10-08 Thesis submitted in partial fulfilment of the requirements for the degree of Master of Science of Artificial Intelligence at the Faculty of Humanities
MONTE-CARLO TWIXT Janik Steinhauer Master Thesis 10-08 Thesis submitted in partial fulfilment of the requirements for the degree of Master of Science of Artificial Intelligence at the Faculty of Humanities
Combining Final Score with Winning Percentage by Sigmoid Function in Monte-Carlo Simulations
 Combining Final Score with Winning Percentage by Sigmoid Function in Monte-Carlo Simulations Kazutomo SHIBAHARA Yoshiyuki KOTANI Abstract Monte-Carlo method recently has produced good results in Go. Monte-Carlo
Combining Final Score with Winning Percentage by Sigmoid Function in Monte-Carlo Simulations Kazutomo SHIBAHARA Yoshiyuki KOTANI Abstract Monte-Carlo method recently has produced good results in Go. Monte-Carlo
Artificial Intelligence Adversarial Search
 Artificial Intelligence Adversarial Search Adversarial Search Adversarial search problems games They occur in multiagent competitive environments There is an opponent we can t control planning again us!
Artificial Intelligence Adversarial Search Adversarial Search Adversarial search problems games They occur in multiagent competitive environments There is an opponent we can t control planning again us!
Using Neural Network and Monte-Carlo Tree Search to Play the Game TEN
 Using Neural Network and Monte-Carlo Tree Search to Play the Game TEN Weijie Chen Fall 2017 Weijie Chen Page 1 of 7 1. INTRODUCTION Game TEN The traditional game Tic-Tac-Toe enjoys people s favor. Moreover,
Using Neural Network and Monte-Carlo Tree Search to Play the Game TEN Weijie Chen Fall 2017 Weijie Chen Page 1 of 7 1. INTRODUCTION Game TEN The traditional game Tic-Tac-Toe enjoys people s favor. Moreover,
Mastering Chess and Shogi by Self- Play with a General Reinforcement Learning Algorithm
 Mastering Chess and Shogi by Self- Play with a General Reinforcement Learning Algorithm by Silver et al Published by Google Deepmind Presented by Kira Selby Background u In March 2016, Deepmind s AlphaGo
Mastering Chess and Shogi by Self- Play with a General Reinforcement Learning Algorithm by Silver et al Published by Google Deepmind Presented by Kira Selby Background u In March 2016, Deepmind s AlphaGo
Adversarial Search (Game Playing)
") Artificial Intelligence Adversarial Search (Game Playing) Chapter 5 Adapted from materials by Tim Finin, Marie desjardins, and Charles R. Dyer Outline Game playing State of the art and resources Framework
Artificial Intelligence Adversarial Search (Game Playing) Chapter 5 Adapted from materials by Tim Finin, Marie desjardins, and Charles R. Dyer Outline Game playing State of the art and resources Framework
COMP3211 Project. Artificial Intelligence for Tron game. Group 7. Chiu Ka Wa ( ) Chun Wai Wong ( ) Ku Chun Kit ( )
 Chun Wai Wong ( ) Ku Chun Kit ( )") COMP3211 Project Artificial Intelligence for Tron game Group 7 Chiu Ka Wa (20369737) Chun Wai Wong (20265022) Ku Chun Kit (20123470) Abstract Tron is an old and popular game based on a movie of the same
COMP3211 Project Artificial Intelligence for Tron game Group 7 Chiu Ka Wa (20369737) Chun Wai Wong (20265022) Ku Chun Kit (20123470) Abstract Tron is an old and popular game based on a movie of the same
Game Playing AI. Dr. Baldassano Yu s Elite Education
 Game Playing AI Dr. Baldassano chrisb@princeton.edu Yu s Elite Education Last 2 weeks recap: Graphs Graphs represent pairwise relationships Directed/undirected, weighted/unweights Common algorithms: Shortest
Game Playing AI Dr. Baldassano chrisb@princeton.edu Yu s Elite Education Last 2 weeks recap: Graphs Graphs represent pairwise relationships Directed/undirected, weighted/unweights Common algorithms: Shortest
Announcements. CS 188: Artificial Intelligence Fall Local Search. Hill Climbing. Simulated Annealing. Hill Climbing Diagram
 CS 188: Artificial Intelligence Fall 2008 Lecture 6: Adversarial Search 9/16/2008 Dan Klein UC Berkeley Many slides over the course adapted from either Stuart Russell or Andrew Moore 1 Announcements Project
CS 188: Artificial Intelligence Fall 2008 Lecture 6: Adversarial Search 9/16/2008 Dan Klein UC Berkeley Many slides over the course adapted from either Stuart Russell or Andrew Moore 1 Announcements Project
COMP219: Artificial Intelligence. Lecture 13: Game Playing
 CMP219: Artificial Intelligence Lecture 13: Game Playing 1 verview Last time Search with partial/no observations Belief states Incremental belief state search Determinism vs non-determinism Today We will
CMP219: Artificial Intelligence Lecture 13: Game Playing 1 verview Last time Search with partial/no observations Belief states Incremental belief state search Determinism vs non-determinism Today We will
CMSC 671 Project Report- Google AI Challenge: Planet Wars
 1. Introduction Purpose The purpose of the project is to apply relevant AI techniques learned during the course with a view to develop an intelligent game playing bot for the game of Planet Wars. Planet
1. Introduction Purpose The purpose of the project is to apply relevant AI techniques learned during the course with a view to develop an intelligent game playing bot for the game of Planet Wars. Planet
Games and Adversarial Search
 1 Games and Adversarial Search BBM 405 Fundamentals of Artificial Intelligence Pinar Duygulu Hacettepe University Slides are mostly adapted from AIMA, MIT Open Courseware and Svetlana Lazebnik (UIUC) Spring
1 Games and Adversarial Search BBM 405 Fundamentals of Artificial Intelligence Pinar Duygulu Hacettepe University Slides are mostly adapted from AIMA, MIT Open Courseware and Svetlana Lazebnik (UIUC) Spring
Foundations of Artificial Intelligence
 Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Frank Hutter and Bernhard Nebel Albert-Ludwigs-Universität
Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Frank Hutter and Bernhard Nebel Albert-Ludwigs-Universität
Poker AI: Equilibrium, Online Resolving, Deep Learning and Reinforcement Learning
 Poker AI: Equilibrium, Online Resolving, Deep Learning and Reinforcement Learning Nikolai Yakovenko NVidia ADLR Group -- Santa Clara CA Columbia University Deep Learning Seminar April 2017 Poker is a Turn-Based
Poker AI: Equilibrium, Online Resolving, Deep Learning and Reinforcement Learning Nikolai Yakovenko NVidia ADLR Group -- Santa Clara CA Columbia University Deep Learning Seminar April 2017 Poker is a Turn-Based
Artificial Intelligence. Minimax and alpha-beta pruning
 Artificial Intelligence Minimax and alpha-beta pruning In which we examine the problems that arise when we try to plan ahead to get the best result in a world that includes a hostile agent (other agent
Artificial Intelligence Minimax and alpha-beta pruning In which we examine the problems that arise when we try to plan ahead to get the best result in a world that includes a hostile agent (other agent
Foundations of Artificial Intelligence Introduction State of the Art Summary. classification: Board Games: Overview
 Foundations of Artificial Intelligence May 14, 2018 40. Board Games: Introduction and State of the Art Foundations of Artificial Intelligence 40. Board Games: Introduction and State of the Art 40.1 Introduction
Foundations of Artificial Intelligence May 14, 2018 40. Board Games: Introduction and State of the Art Foundations of Artificial Intelligence 40. Board Games: Introduction and State of the Art 40.1 Introduction
CS 188: Artificial Intelligence Spring 2007
 CS 188: Artificial Intelligence Spring 2007 Lecture 7: CSP-II and Adversarial Search 2/6/2007 Srini Narayanan ICSI and UC Berkeley Many slides over the course adapted from Dan Klein, Stuart Russell or
CS 188: Artificial Intelligence Spring 2007 Lecture 7: CSP-II and Adversarial Search 2/6/2007 Srini Narayanan ICSI and UC Berkeley Many slides over the course adapted from Dan Klein, Stuart Russell or
Igo Math Natural and Artificial Intelligence
 Attila Egri-Nagy Igo Math Natural and Artificial Intelligence and the Game of Go V 2 0 1 9.0 2.1 4 These preliminary notes are being written for the MAT230 course at Akita International University in Japan.
Attila Egri-Nagy Igo Math Natural and Artificial Intelligence and the Game of Go V 2 0 1 9.0 2.1 4 These preliminary notes are being written for the MAT230 course at Akita International University in Japan.
Adversarial Search. CMPSCI 383 September 29, 2011
 Adversarial Search CMPSCI 383 September 29, 2011 1 Why are games interesting to AI? Simple to represent and reason about Must consider the moves of an adversary Time constraints Russell & Norvig say: Games,
Adversarial Search CMPSCI 383 September 29, 2011 1 Why are games interesting to AI? Simple to represent and reason about Must consider the moves of an adversary Time constraints Russell & Norvig say: Games,
How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997)
") How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997) Alan Fern School of Electrical Engineering and Computer Science Oregon State University Deep Mind s vs. Lee Sedol (2016) Watson vs. Ken
How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997) Alan Fern School of Electrical Engineering and Computer Science Oregon State University Deep Mind s vs. Lee Sedol (2016) Watson vs. Ken
Intuition Mini-Max 2
 Games Today Saying Deep Blue doesn t really think about chess is like saying an airplane doesn t really fly because it doesn t flap its wings. Drew McDermott I could feel I could smell a new kind of intelligence
Games Today Saying Deep Blue doesn t really think about chess is like saying an airplane doesn t really fly because it doesn t flap its wings. Drew McDermott I could feel I could smell a new kind of intelligence
Chess Algorithms Theory and Practice. Rune Djurhuus Chess Grandmaster / September 23, 2013
 Chess Algorithms Theory and Practice Rune Djurhuus Chess Grandmaster runed@ifi.uio.no / runedj@microsoft.com September 23, 2013 1 Content Complexity of a chess game History of computer chess Search trees
Chess Algorithms Theory and Practice Rune Djurhuus Chess Grandmaster runed@ifi.uio.no / runedj@microsoft.com September 23, 2013 1 Content Complexity of a chess game History of computer chess Search trees
43.1 Introduction. Foundations of Artificial Intelligence Introduction Monte-Carlo Methods Monte-Carlo Tree Search. 43.
 May 6, 20 3. : Introduction 3. : Introduction Malte Helmert University of Basel May 6, 20 3. Introduction 3.2 3.3 3. Summary May 6, 20 / 27 May 6, 20 2 / 27 Board Games: Overview 3. : Introduction Introduction
May 6, 20 3. : Introduction 3. : Introduction Malte Helmert University of Basel May 6, 20 3. Introduction 3.2 3.3 3. Summary May 6, 20 / 27 May 6, 20 2 / 27 Board Games: Overview 3. : Introduction Introduction
Examples for Ikeda Territory I Scoring - Part 3
 Examples for Ikeda Territory I - Part 3 by Robert Jasiek One-sided Plays A general formal definition of "one-sided play" is not available yet. In the discussed examples, the following types occur: 1) one-sided
Examples for Ikeda Territory I - Part 3 by Robert Jasiek One-sided Plays A general formal definition of "one-sided play" is not available yet. In the discussed examples, the following types occur: 1) one-sided