Success Stories of Deep RL. David Silver
|
|
|
- Jeffrey Hubbard
- 5 years ago
- Views:
Transcription
1 Success Stories of Deep RL David Silver

2 Reinforcement Learning (RL) RL is a general-purpose framework for decision-making An agent selects actions Its actions influence its future observations Success is measured by a scalar reward signal Goal: select actions to maximise future rewards

3 Deep Learning (DL) Deep learning is a general-purpose framework for representation learning Given an objective Learn a representation that achieves objective Directly from raw inputs Using minimal domain knowledge
4 Deep Reinforcement Learning We seek an agent that can solve any human-level task Reinforcement learning defines the objective Deep learning gives the mechanism Conjecture: RL + DL = artificial general intelligence
5 Deep RL in Practice Use neural networks to represent: Value function Policy Model Optimise loss function end-to-end e.g. by stochastic gradient descent
6 Tesauro 1992 TD Gammon Success Story #1

7 Deep RL in Backgammon Randomly initialised weights Trained by games of self-play Using temporal-difference learning Greedy action selection (using lookahead)

8 In 1992, TD Gammon defeated world champion Luigi Villa 7-2 It was trained by self-play Expert features were used Later results showed they could be removed
9 Mnih et al DQN in Atari Success Story #2


10 Deep Reinforcement Learning on Atari Mnih et al. 2015
11
12


13 Learning to Play Atari 2600 Games Computer has never seen the game before and does not know the rules It learns by deep reinforcement learning to maximise its score Given only the pixels and game score as input Separately for 57 different games
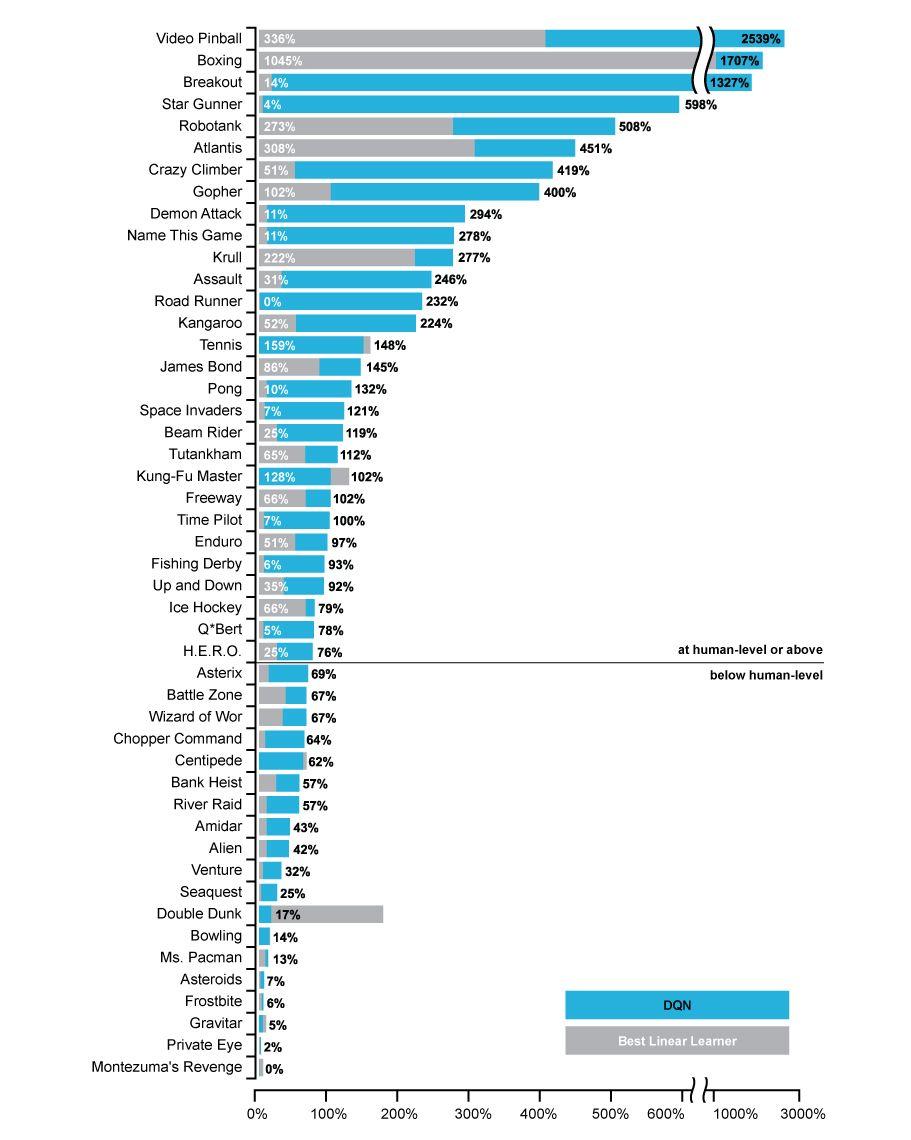
14
15
16
17 News Recommendation using DQN Zhang et al. 2018
18 Deep RL in Robotics Success Story #3
19 Actor-Critic Deep RL Actor π = Policy Critic Q = Value Fn Update critic by TD learning Update actor in direction of critic


20 Deep RL by Diverse Simulation Heess et al Andrychowicz 2018


21 Augmenting Data Kalshnikov et al Riedmiller et al. 2018
22 Silver et al AlphaGo Success Story #4a
23
24 Policy network P Move probabilities Position

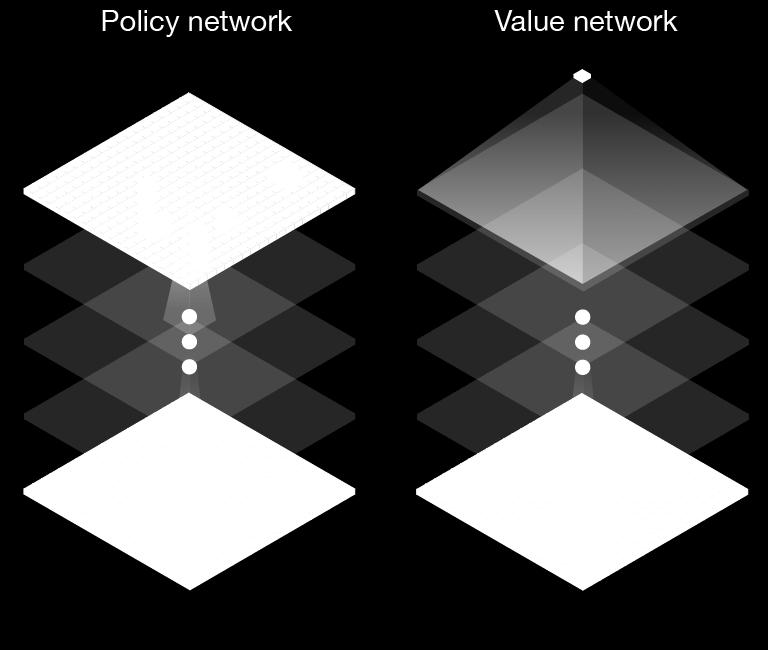
25 Value network V Evaluation Position

26 Training AlphaGo Human expert positions Supervised Learning P V Policy network Value network Reinforcement Learning
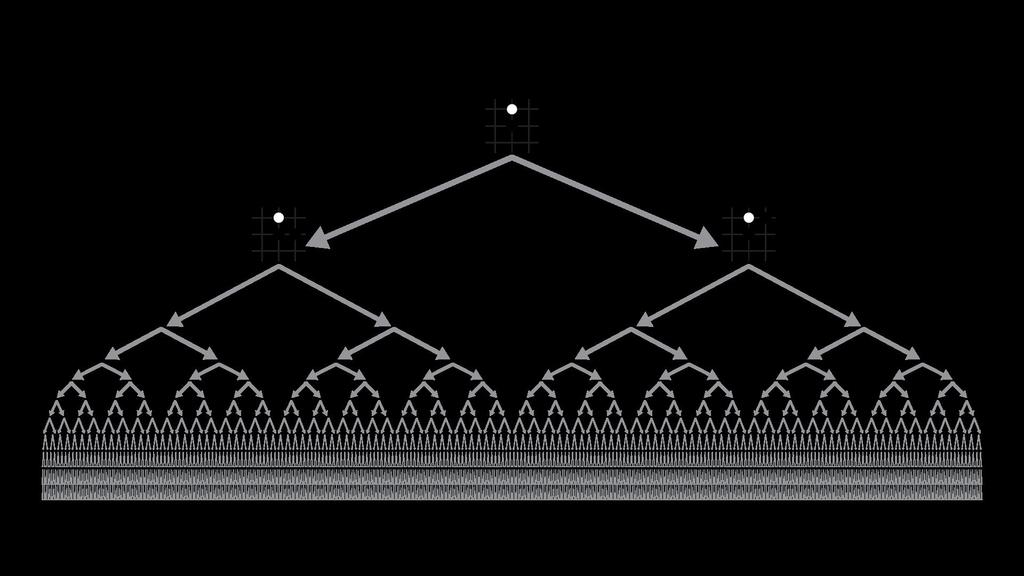
27 Exhaustive search
28 Reducing breadth with policy network P P P P P P P

29 Reducing depth with value network VV VV VV VV VV VV VV VV VV VV VV VV VV VV VV VV

30 AlphaGo vs Lee Sedol Lee Sedol (9p): winner of 18 world titles Match was played in Seoul, March 2016 AlphaGo won the match 4-1

31 AlphaGo vs. Human World Champion Lee Sedol
32 Silver et al AlphaZero Success Story #4b
33 AlphaZero: learning from first principles No human data No human features Only takes raw board as an input Single neural network Learns solely by self-play reinforcement learning, starting from random Policy and value networks are combined into one neural network (resnet) Fully general Applicable to many domains, no special treatment for Go (symmetry etc.)
34 Reinforcement Learning in AlphaZero Position P,V P,V P,V Move AlphaZero plays games against itself
35 Reinforcement Learning in AlphaZero Move Policy Position New policy network P is trained to predict AlphaZero s moves

36 Reinforcement Learning in AlphaZero Winner Value Position New value network V is trained to predict winner
37 Reinforcement Learning in AlphaZero Position P,V P,V P,V Move New policy/value network is used in next iteration of AlphaZero
38 Search-Based Policy Iteration Search-Based Policy Improvement Run MCTS search using current network Actions selected by MCTS > actions selected by raw network Search-Based Policy Evaluation Play self-play games using MCTS to select actions Evaluate improved policy by the average outcome See also: Lagoudakis 03, Scherrer 15
39 AlphaZero in Go 8 hours - AlphaZero surpasses AlphaGo Lee


40 Discovering and Discarding Human Go Knowledge Known opening patterns (joseki) are discovered as training proceeds... But discarded if deemed inferior
41 Computer Chess Most studied domain in history of artificial intelligence Highly specialised systems have been successful in chess Deep Blue defeated Kasparov in 1997 State-of-the-art now indisputably superhuman Shogi (Japanese chess) is more complex than chess Studied by Babbage, Turing, Shannon, von Neumann Drosophila of artificial intelligence for several decades Larger board, larger action space (captured pieces dropped back into play) Only recently achieved human world champion level State-of-the-art engines are based on alpha-beta search Handcrafted evaluation functions optimised by human grandmasters Search extensions that are highly optimised using game-specific heuristics
42 Anatomy of a World Champion Chess Engine Domain knowledge, extensions, heuristics in 2016 TCEC world champion Stockfish: Board Representation: Bitboards with Little-Endian Rank-File Mapping (LERF), Magic Bitboards, BMI2 - PEXT Bitboards, Piece-Lists, Search: Iterative Deepening, Aspiration Windows, Parallel Search using Threads, YBWC, Lazy SMP, Principal Variation Search. Transposition Table: Shared Hash Table, Depth-preferred Replacement Strategy, No PV-Node probing, Prefetch Move Ordering: Countermove Heuristic, Counter Moves History, History Heuristic, Internal Iterative Deepening, Killer Heuristic, MVV/LVA, SEE, Selectivity: Check Extensions if SEE >= 0, Restricted Singular Extensions, Futility Pruning, Move Count Based Pruning, Null Move Pruning, Dynamic Depth Reduction based on depth and value, Static Null Move Pruning, Verification search at high depths, ProbCut, SEE Pruning, Late Move Reductions, Razoring, Quiescence Search, Evaluation: Tapered Eval, Score Grain, Point Values Midgame: 198, 817, 836, 1270, 2521, Endgame: 258, 846, 857, 1278, 2558, Bishop Pair, Imbalance Tables, Material Hash Table, Piece-Square Tables, Trapped Pieces, Rooks on (Semi) Open Files, Outposts, Pawn Hash Table, Backward Pawn, Doubled Pawn, Isolated Pawn, Phalanx, Passed Pawn, Attacking King Zone, Pawn Shelter, Pawn Storm, Square Control, Evaluation Patterns, Endgame Tablebases: Syzygy TableBases
43 Anatomy of AlphaZero Self-play reinforcement learning + self-play Monte-Carlo search Board Representation: Bitboards with Little-Endian Rank-File Mapping (LERF), Magic Bitboards, BMI2 - PEXT Bitboards, Piece-Lists, Search: Iterative Deepening, Aspiration Windows, Parallel Search using Threads, YBWC, Lazy SMP, Principal Variation Search. Transposition Table: Shared Hash Table, Depth-preferred Replacement Strategy, No PV-Node probing, Prefetch Move Ordering: Countermove Heuristic, Counter Moves History, History Heuristic, Internal Iterative Deepening, Killer Heuristic, MVV/LVA, SEE, Selectivity: Check Extensions if SEE >= 0, Restricted Singular Extensions, Futility Pruning, Move Count Based Pruning, Null Move Pruning, Dynamic Depth Reduction based on depth and value, Static Null Move Pruning, Verification search at high depths, ProbCut, SEE Pruning, Late Move Reductions, Razoring, Quiescence Search, Evaluation: Tapered Eval, Score Grain, Point Values Midgame: 198, 817, 836, 1270, 2521, Endgame: 258, 846, 857, 1278, 2558, Bishop Pair, Imbalance Tables, Material Hash Table, Piece-Square Tables, Trapped Pieces, Rooks on (Semi) Open Files, Outposts, Pawn Hash Table, Backward Pawn, Doubled Pawn, Isolated Pawn, Phalanx, Passed Pawn, Attacking King Zone, Pawn Shelter, Pawn Storm, Square Control, Evaluation Patterns, Endgame Tablebases: Syzygy TableBases
44 2 hours - AlphaZero surpasses Elmo 4 hours - AlphaZero surpasses Stockfish
45 AlphaChem Other Go programs (FineArt, LeelaZero, ELF, ) Hex (Anthony 2017) Bin packing (Laterre et al. 2018) Segler et al., 2018
46 OpenAI 2018 (unpublished) Dota 2 Success Story #5a
 20,000 observations summarise information available to")
47 Dota 2 5v5 multi-player game with rich strategies 20,000 time-steps per game 170,000 discrete actions (~1,000 legal) 20,000 observations summarise information available to human
48 OpenAI Five Self-play training starting from random weights Actor-critic algorithm (PPO) LSTM network represents policy and value 20% of games played against old weights Handcrafted reward shaping based on expert domain knowledge Exploits domain randomisations Simplified game rules (e.g. drafting) 1v1: defeated professional human (2017) 5v5: narrowly lost to professional human team (2018)
49 Jaderberg et al Capture the Flag Success Story #5b

50 MULTI-AGENT RL: CAPTURE THE FLAG Multi-Agent Learning Tutorial
.")

51 ENVIRONMENTS Based on DMLab (Quake III Arena). Train agents on two style of maps, outdoor and indoor. These are procedurally generated every game. Multi-Agent Learning Tutorial

52 TRAINING ALGORITHM Internal reward is adapted by population-based training to maximise win rate Policies/values are trained by actor-critic to maximise internal rewards Multi-Agent Learning Tutorial

53 NETWORK ARCHITECTURE Differentiable memory reads and writes latent variables Temporal hierarchy: fast and slow timescales learn to work together Multi-Agent Learning Tutorial

54 RESULTS Multi-Agent Learning Tutorial
Mastering Chess and Shogi by Self- Play with a General Reinforcement Learning Algorithm
 Mastering Chess and Shogi by Self- Play with a General Reinforcement Learning Algorithm by Silver et al Published by Google Deepmind Presented by Kira Selby Background u In March 2016, Deepmind s AlphaGo
Mastering Chess and Shogi by Self- Play with a General Reinforcement Learning Algorithm by Silver et al Published by Google Deepmind Presented by Kira Selby Background u In March 2016, Deepmind s AlphaGo
CS 331: Artificial Intelligence Adversarial Search II. Outline
 CS 331: Artificial Intelligence Adversarial Search II 1 Outline 1. Evaluation Functions 2. State-of-the-art game playing programs 3. 2 player zero-sum finite stochastic games of perfect information 2 1
CS 331: Artificial Intelligence Adversarial Search II 1 Outline 1. Evaluation Functions 2. State-of-the-art game playing programs 3. 2 player zero-sum finite stochastic games of perfect information 2 1
Google DeepMind s AlphaGo vs. world Go champion Lee Sedol
 Google DeepMind s AlphaGo vs. world Go champion Lee Sedol Review of Nature paper: Mastering the game of Go with Deep Neural Networks & Tree Search Tapani Raiko Thanks to Antti Tarvainen for some slides
Google DeepMind s AlphaGo vs. world Go champion Lee Sedol Review of Nature paper: Mastering the game of Go with Deep Neural Networks & Tree Search Tapani Raiko Thanks to Antti Tarvainen for some slides
Artificial Intelligence Search III
 Artificial Intelligence Search III Lecture 5 Content: Search III Quick Review on Lecture 4 Why Study Games? Game Playing as Search Special Characteristics of Game Playing Search Ingredients of 2-Person
Artificial Intelligence Search III Lecture 5 Content: Search III Quick Review on Lecture 4 Why Study Games? Game Playing as Search Special Characteristics of Game Playing Search Ingredients of 2-Person
Monte Carlo Tree Search
 Monte Carlo Tree Search 1 By the end, you will know Why we use Monte Carlo Search Trees The pros and cons of MCTS How it is applied to Super Mario Brothers and Alpha Go 2 Outline I. Pre-MCTS Algorithms
Monte Carlo Tree Search 1 By the end, you will know Why we use Monte Carlo Search Trees The pros and cons of MCTS How it is applied to Super Mario Brothers and Alpha Go 2 Outline I. Pre-MCTS Algorithms
TTIC 31230, Fundamentals of Deep Learning David McAllester, April AlphaZero
 TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 AlphaZero 1 AlphaGo Fan (October 2015) AlphaGo Defeats Fan Hui, European Go Champion. 2 AlphaGo Lee (March 2016) 3 AlphaGo Zero vs.
TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 AlphaZero 1 AlphaGo Fan (October 2015) AlphaGo Defeats Fan Hui, European Go Champion. 2 AlphaGo Lee (March 2016) 3 AlphaGo Zero vs.
School of EECS Washington State University. Artificial Intelligence
 School of EECS Washington State University Artificial Intelligence 1 } Classic AI challenge Easy to represent Difficult to solve } Zero-sum games Total final reward to all players is constant } Perfect
School of EECS Washington State University Artificial Intelligence 1 } Classic AI challenge Easy to represent Difficult to solve } Zero-sum games Total final reward to all players is constant } Perfect
TD-Leaf(λ) Giraffe: Using Deep Reinforcement Learning to Play Chess. Stefan Lüttgen
 Giraffe: Using Deep Reinforcement Learning to Play Chess. Stefan Lüttgen") TD-Leaf(λ) Giraffe: Using Deep Reinforcement Learning to Play Chess Stefan Lüttgen Motivation Learn to play chess Computer approach different than human one Humans search more selective: Kasparov (3-5
TD-Leaf(λ) Giraffe: Using Deep Reinforcement Learning to Play Chess Stefan Lüttgen Motivation Learn to play chess Computer approach different than human one Humans search more selective: Kasparov (3-5
How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997)
") How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997) Alan Fern School of Electrical Engineering and Computer Science Oregon State University Deep Mind s vs. Lee Sedol (2016) Watson vs. Ken
How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997) Alan Fern School of Electrical Engineering and Computer Science Oregon State University Deep Mind s vs. Lee Sedol (2016) Watson vs. Ken
Game AI Challenges: Past, Present, and Future
 Game AI Challenges: Past, Present, and Future Professor Michael Buro Computing Science, University of Alberta, Edmonton, Canada www.skatgame.net/cpcc2018.pdf 1/ 35 AI / ML Group @ University of Alberta
Game AI Challenges: Past, Present, and Future Professor Michael Buro Computing Science, University of Alberta, Edmonton, Canada www.skatgame.net/cpcc2018.pdf 1/ 35 AI / ML Group @ University of Alberta
Game-playing: DeepBlue and AlphaGo
 Game-playing: DeepBlue and AlphaGo Brief history of gameplaying frontiers 1990s: Othello world champions refuse to play computers 1994: Chinook defeats Checkers world champion 1997: DeepBlue defeats world
Game-playing: DeepBlue and AlphaGo Brief history of gameplaying frontiers 1990s: Othello world champions refuse to play computers 1994: Chinook defeats Checkers world champion 1997: DeepBlue defeats world
CSC321 Lecture 23: Go
 CSC321 Lecture 23: Go Roger Grosse Roger Grosse CSC321 Lecture 23: Go 1 / 21 Final Exam Friday, April 20, 9am-noon Last names A Y: Clara Benson Building (BN) 2N Last names Z: Clara Benson Building (BN)
CSC321 Lecture 23: Go Roger Grosse Roger Grosse CSC321 Lecture 23: Go 1 / 21 Final Exam Friday, April 20, 9am-noon Last names A Y: Clara Benson Building (BN) 2N Last names Z: Clara Benson Building (BN)
Game Playing: Adversarial Search. Chapter 5
 Game Playing: Adversarial Search Chapter 5 Outline Games Perfect play minimax search α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information Games vs. Search
Game Playing: Adversarial Search Chapter 5 Outline Games Perfect play minimax search α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information Games vs. Search
Set 4: Game-Playing. ICS 271 Fall 2017 Kalev Kask
 Set 4: Game-Playing ICS 271 Fall 2017 Kalev Kask Overview Computer programs that play 2-player games game-playing as search with the complication of an opponent General principles of game-playing and search
Set 4: Game-Playing ICS 271 Fall 2017 Kalev Kask Overview Computer programs that play 2-player games game-playing as search with the complication of an opponent General principles of game-playing and search
CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH. Santiago Ontañón
 CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH Santiago Ontañón so367@drexel.edu Recall: Adversarial Search Idea: When there is only one agent in the world, we can solve problems using DFS, BFS, ID,
CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH Santiago Ontañón so367@drexel.edu Recall: Adversarial Search Idea: When there is only one agent in the world, we can solve problems using DFS, BFS, ID,
Lecture 14. Questions? Friday, February 10 CS 430 Artificial Intelligence - Lecture 14 1
 Lecture 14 Questions? Friday, February 10 CS 430 Artificial Intelligence - Lecture 14 1 Outline Chapter 5 - Adversarial Search Alpha-Beta Pruning Imperfect Real-Time Decisions Stochastic Games Friday,
Lecture 14 Questions? Friday, February 10 CS 430 Artificial Intelligence - Lecture 14 1 Outline Chapter 5 - Adversarial Search Alpha-Beta Pruning Imperfect Real-Time Decisions Stochastic Games Friday,
AlphaGo and Artificial Intelligence GUEST LECTURE IN THE GAME OF GO AND SOCIETY
 AlphaGo and Artificial Intelligence HUCK BENNET T (NORTHWESTERN UNIVERSITY) GUEST LECTURE IN THE GAME OF GO AND SOCIETY AT OCCIDENTAL COLLEGE, 10/29/2018 The Game of Go A game for aliens, presidents, and
AlphaGo and Artificial Intelligence HUCK BENNET T (NORTHWESTERN UNIVERSITY) GUEST LECTURE IN THE GAME OF GO AND SOCIETY AT OCCIDENTAL COLLEGE, 10/29/2018 The Game of Go A game for aliens, presidents, and
Game Playing. Philipp Koehn. 29 September 2015
 Game Playing Philipp Koehn 29 September 2015 Outline 1 Games Perfect play minimax decisions α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information 2 games
Game Playing Philipp Koehn 29 September 2015 Outline 1 Games Perfect play minimax decisions α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information 2 games
Artificial Intelligence Adversarial Search
 Artificial Intelligence Adversarial Search Adversarial Search Adversarial search problems games They occur in multiagent competitive environments There is an opponent we can t control planning again us!
Artificial Intelligence Adversarial Search Adversarial Search Adversarial search problems games They occur in multiagent competitive environments There is an opponent we can t control planning again us!
6. Games. COMP9414/ 9814/ 3411: Artificial Intelligence. Outline. Mechanical Turk. Origins. origins. motivation. minimax search
 COMP9414/9814/3411 16s1 Games 1 COMP9414/ 9814/ 3411: Artificial Intelligence 6. Games Outline origins motivation Russell & Norvig, Chapter 5. minimax search resource limits and heuristic evaluation α-β
COMP9414/9814/3411 16s1 Games 1 COMP9414/ 9814/ 3411: Artificial Intelligence 6. Games Outline origins motivation Russell & Norvig, Chapter 5. minimax search resource limits and heuristic evaluation α-β
Tutorial of Reinforcement: A Special Focus on Q-Learning
 Tutorial of Reinforcement: A Special Focus on Q-Learning TINGWU WANG, MACHINE LEARNING GROUP, UNIVERSITY OF TORONTO Contents 1. Introduction 1. Discrete Domain vs. Continous Domain 2. Model Based vs. Model
Tutorial of Reinforcement: A Special Focus on Q-Learning TINGWU WANG, MACHINE LEARNING GROUP, UNIVERSITY OF TORONTO Contents 1. Introduction 1. Discrete Domain vs. Continous Domain 2. Model Based vs. Model
Games and Adversarial Search
 1 Games and Adversarial Search BBM 405 Fundamentals of Artificial Intelligence Pinar Duygulu Hacettepe University Slides are mostly adapted from AIMA, MIT Open Courseware and Svetlana Lazebnik (UIUC) Spring
1 Games and Adversarial Search BBM 405 Fundamentals of Artificial Intelligence Pinar Duygulu Hacettepe University Slides are mostly adapted from AIMA, MIT Open Courseware and Svetlana Lazebnik (UIUC) Spring
Artificial Intelligence. Topic 5. Game playing
 Artificial Intelligence Topic 5 Game playing broadening our world view dealing with incompleteness why play games? perfect decisions the Minimax algorithm dealing with resource limits evaluation functions
Artificial Intelligence Topic 5 Game playing broadening our world view dealing with incompleteness why play games? perfect decisions the Minimax algorithm dealing with resource limits evaluation functions
Foundations of Artificial Intelligence
 Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Bernhard Nebel Albert-Ludwigs-Universität
Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Bernhard Nebel Albert-Ludwigs-Universität
Adversarial Search Aka Games
 Adversarial Search Aka Games Chapter 5 Some material adopted from notes by Charles R. Dyer, U of Wisconsin-Madison Overview Game playing State of the art and resources Framework Game trees Minimax Alpha-beta
Adversarial Search Aka Games Chapter 5 Some material adopted from notes by Charles R. Dyer, U of Wisconsin-Madison Overview Game playing State of the art and resources Framework Game trees Minimax Alpha-beta
Adversarial Search. Human-aware Robotics. 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: Slides for this lecture are here:
 Adversarial Search 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: q Slides for this lecture are here: http://www.public.asu.edu/~yzhan442/teaching/cse471/lectures/adversarial.pdf Slides are largely based
Adversarial Search 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: q Slides for this lecture are here: http://www.public.asu.edu/~yzhan442/teaching/cse471/lectures/adversarial.pdf Slides are largely based
Augmenting Self-Learning In Chess Through Expert Imitation
 Augmenting Self-Learning In Chess Through Expert Imitation Michael Xie Department of Computer Science Stanford University Stanford, CA 94305 xie@cs.stanford.edu Gene Lewis Department of Computer Science
Augmenting Self-Learning In Chess Through Expert Imitation Michael Xie Department of Computer Science Stanford University Stanford, CA 94305 xie@cs.stanford.edu Gene Lewis Department of Computer Science
Andrei Behel AC-43И 1
 Andrei Behel AC-43И 1 History The game of Go originated in China more than 2,500 years ago. The rules of the game are simple: Players take turns to place black or white stones on a board, trying to capture
Andrei Behel AC-43И 1 History The game of Go originated in China more than 2,500 years ago. The rules of the game are simple: Players take turns to place black or white stones on a board, trying to capture
Foundations of Artificial Intelligence
 Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Frank Hutter and Bernhard Nebel Albert-Ludwigs-Universität
Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Frank Hutter and Bernhard Nebel Albert-Ludwigs-Universität
Foundations of AI. 6. Adversarial Search. Search Strategies for Games, Games with Chance, State of the Art. Wolfram Burgard & Bernhard Nebel
 Foundations of AI 6. Adversarial Search Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard & Bernhard Nebel Contents Game Theory Board Games Minimax Search Alpha-Beta Search
Foundations of AI 6. Adversarial Search Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard & Bernhard Nebel Contents Game Theory Board Games Minimax Search Alpha-Beta Search
CITS3001. Algorithms, Agents and Artificial Intelligence. Semester 2, 2016 Tim French
 CITS3001 Algorithms, Agents and Artificial Intelligence Semester 2, 2016 Tim French School of Computer Science & Software Eng. The University of Western Australia 8. Game-playing AIMA, Ch. 5 Objectives
CITS3001 Algorithms, Agents and Artificial Intelligence Semester 2, 2016 Tim French School of Computer Science & Software Eng. The University of Western Australia 8. Game-playing AIMA, Ch. 5 Objectives
46.1 Introduction. Foundations of Artificial Intelligence Introduction MCTS in AlphaGo Neural Networks. 46.
 Foundations of Artificial Intelligence May 30, 2016 46. AlphaGo and Outlook Foundations of Artificial Intelligence 46. AlphaGo and Outlook Thomas Keller Universität Basel May 30, 2016 46.1 Introduction
Foundations of Artificial Intelligence May 30, 2016 46. AlphaGo and Outlook Foundations of Artificial Intelligence 46. AlphaGo and Outlook Thomas Keller Universität Basel May 30, 2016 46.1 Introduction
Adversarial Search. CS 486/686: Introduction to Artificial Intelligence
 Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 Introduction So far we have only been concerned with a single agent Today, we introduce an adversary! 2 Outline Games Minimax search
Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 Introduction So far we have only been concerned with a single agent Today, we introduce an adversary! 2 Outline Games Minimax search
Automated Suicide: An Antichess Engine
 Automated Suicide: An Antichess Engine Jim Andress and Prasanna Ramakrishnan 1 Introduction Antichess (also known as Suicide Chess or Loser s Chess) is a popular variant of chess where the objective of
Automated Suicide: An Antichess Engine Jim Andress and Prasanna Ramakrishnan 1 Introduction Antichess (also known as Suicide Chess or Loser s Chess) is a popular variant of chess where the objective of
Adversarial Search. Soleymani. Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5
 Adversarial Search CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2017 Soleymani Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5 Outline Game
Adversarial Search CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2017 Soleymani Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5 Outline Game
CPS 570: Artificial Intelligence Two-player, zero-sum, perfect-information Games
 CPS 57: Artificial Intelligence Two-player, zero-sum, perfect-information Games Instructor: Vincent Conitzer Game playing Rich tradition of creating game-playing programs in AI Many similarities to search
CPS 57: Artificial Intelligence Two-player, zero-sum, perfect-information Games Instructor: Vincent Conitzer Game playing Rich tradition of creating game-playing programs in AI Many similarities to search
CS 4700: Foundations of Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence selman@cs.cornell.edu Module: Adversarial Search R&N: Chapter 5 1 Outline Adversarial Search Optimal decisions Minimax α-β pruning Case study: Deep Blue
CS 4700: Foundations of Artificial Intelligence selman@cs.cornell.edu Module: Adversarial Search R&N: Chapter 5 1 Outline Adversarial Search Optimal decisions Minimax α-β pruning Case study: Deep Blue
Applications of Artificial Intelligence and Machine Learning in Othello TJHSST Computer Systems Lab
 Applications of Artificial Intelligence and Machine Learning in Othello TJHSST Computer Systems Lab 2009-2010 Jack Chen January 22, 2010 Abstract The purpose of this project is to explore Artificial Intelligence
Applications of Artificial Intelligence and Machine Learning in Othello TJHSST Computer Systems Lab 2009-2010 Jack Chen January 22, 2010 Abstract The purpose of this project is to explore Artificial Intelligence
Lecture 5: Game Playing (Adversarial Search)
") Lecture 5: Game Playing (Adversarial Search) CS 580 (001) - Spring 2018 Amarda Shehu Department of Computer Science George Mason University, Fairfax, VA, USA February 21, 2018 Amarda Shehu (580) 1 1 Outline
Lecture 5: Game Playing (Adversarial Search) CS 580 (001) - Spring 2018 Amarda Shehu Department of Computer Science George Mason University, Fairfax, VA, USA February 21, 2018 Amarda Shehu (580) 1 1 Outline
Bootstrapping from Game Tree Search
 Joel Veness David Silver Will Uther Alan Blair University of New South Wales NICTA University of Alberta December 9, 2009 Presentation Overview Introduction Overview Game Tree Search Evaluation Functions
Joel Veness David Silver Will Uther Alan Blair University of New South Wales NICTA University of Alberta December 9, 2009 Presentation Overview Introduction Overview Game Tree Search Evaluation Functions
COMP219: Artificial Intelligence. Lecture 13: Game Playing
 CMP219: Artificial Intelligence Lecture 13: Game Playing 1 verview Last time Search with partial/no observations Belief states Incremental belief state search Determinism vs non-determinism Today We will
CMP219: Artificial Intelligence Lecture 13: Game Playing 1 verview Last time Search with partial/no observations Belief states Incremental belief state search Determinism vs non-determinism Today We will
COMP219: COMP219: Artificial Intelligence Artificial Intelligence Dr. Annabel Latham Lecture 12: Game Playing Overview Games and Search
 COMP19: Artificial Intelligence COMP19: Artificial Intelligence Dr. Annabel Latham Room.05 Ashton Building Department of Computer Science University of Liverpool Lecture 1: Game Playing 1 Overview Last
COMP19: Artificial Intelligence COMP19: Artificial Intelligence Dr. Annabel Latham Room.05 Ashton Building Department of Computer Science University of Liverpool Lecture 1: Game Playing 1 Overview Last
CS 4700: Foundations of Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence selman@cs.cornell.edu Module: Adversarial Search R&N: Chapter 5 Part II 1 Outline Game Playing Optimal decisions Minimax α-β pruning Case study: Deep Blue
CS 4700: Foundations of Artificial Intelligence selman@cs.cornell.edu Module: Adversarial Search R&N: Chapter 5 Part II 1 Outline Game Playing Optimal decisions Minimax α-β pruning Case study: Deep Blue
Adversarial Search. CS 486/686: Introduction to Artificial Intelligence
 Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 AccessAbility Services Volunteer Notetaker Required Interested? Complete an online application using your WATIAM: https://york.accessiblelearning.com/uwaterloo/
Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 AccessAbility Services Volunteer Notetaker Required Interested? Complete an online application using your WATIAM: https://york.accessiblelearning.com/uwaterloo/
CS2212 PROGRAMMING CHALLENGE II EVALUATION FUNCTIONS N. H. N. D. DE SILVA
 CS2212 PROGRAMMING CHALLENGE II EVALUATION FUNCTIONS N. H. N. D. DE SILVA Game playing was one of the first tasks undertaken in AI as soon as computers became programmable. (e.g., Turing, Shannon, and
CS2212 PROGRAMMING CHALLENGE II EVALUATION FUNCTIONS N. H. N. D. DE SILVA Game playing was one of the first tasks undertaken in AI as soon as computers became programmable. (e.g., Turing, Shannon, and
Algorithms for solving sequential (zero-sum) games. Main case in these slides: chess! Slide pack by " Tuomas Sandholm"
 games. Main case in these slides: chess! Slide pack by Tuomas Sandholm") Algorithms for solving sequential (zero-sum) games Main case in these slides: chess! Slide pack by " Tuomas Sandholm" Rich history of cumulative ideas Game-theoretic perspective" Game of perfect information"
Algorithms for solving sequential (zero-sum) games Main case in these slides: chess! Slide pack by " Tuomas Sandholm" Rich history of cumulative ideas Game-theoretic perspective" Game of perfect information"
Presentation Overview. Bootstrapping from Game Tree Search. Game Tree Search. Heuristic Evaluation Function
 Presentation Bootstrapping from Joel Veness David Silver Will Uther Alan Blair University of New South Wales NICTA University of Alberta A new algorithm will be presented for learning heuristic evaluation
Presentation Bootstrapping from Joel Veness David Silver Will Uther Alan Blair University of New South Wales NICTA University of Alberta A new algorithm will be presented for learning heuristic evaluation
Contents. Foundations of Artificial Intelligence. Problems. Why Board Games?
 Contents Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Bernhard Nebel, and Martin Riedmiller Albert-Ludwigs-Universität
Contents Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Bernhard Nebel, and Martin Riedmiller Albert-Ludwigs-Universität
TD-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play
 NOTE Communicated by Richard Sutton TD-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play Gerald Tesauro IBM Thomas 1. Watson Research Center, I? 0. Box 704, Yorktozon Heights, NY 10598
NOTE Communicated by Richard Sutton TD-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play Gerald Tesauro IBM Thomas 1. Watson Research Center, I? 0. Box 704, Yorktozon Heights, NY 10598
GC Gadgets in the Rush Hour. Game Complexity Gadgets in the Rush Hour. Walter Kosters, Universiteit Leiden
 GC Gadgets in the Rush Hour Game Complexity Gadgets in the Rush Hour Walter Kosters, Universiteit Leiden www.liacs.leidenuniv.nl/ kosterswa/ IPA, Eindhoven; Friday, January 25, 209 link link link mystery
GC Gadgets in the Rush Hour Game Complexity Gadgets in the Rush Hour Walter Kosters, Universiteit Leiden www.liacs.leidenuniv.nl/ kosterswa/ IPA, Eindhoven; Friday, January 25, 209 link link link mystery
CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions
 CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions Slides by Svetlana Lazebnik, 9/2016 Modified by Mark Hasegawa Johnson, 9/2017 Types of game environments Perfect
CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions Slides by Svetlana Lazebnik, 9/2016 Modified by Mark Hasegawa Johnson, 9/2017 Types of game environments Perfect
Game Playing State-of-the-Art CSE 473: Artificial Intelligence Fall Deterministic Games. Zero-Sum Games 10/13/17. Adversarial Search
 CSE 473: Artificial Intelligence Fall 2017 Adversarial Search Mini, pruning, Expecti Dieter Fox Based on slides adapted Luke Zettlemoyer, Dan Klein, Pieter Abbeel, Dan Weld, Stuart Russell or Andrew Moore
CSE 473: Artificial Intelligence Fall 2017 Adversarial Search Mini, pruning, Expecti Dieter Fox Based on slides adapted Luke Zettlemoyer, Dan Klein, Pieter Abbeel, Dan Weld, Stuart Russell or Andrew Moore
Game Design Verification using Reinforcement Learning
 Game Design Verification using Reinforcement Learning Eirini Ntoutsi Dimitris Kalles AHEAD Relationship Mediators S.A., 65 Othonos-Amalias St, 262 21 Patras, Greece and Department of Computer Engineering
Game Design Verification using Reinforcement Learning Eirini Ntoutsi Dimitris Kalles AHEAD Relationship Mediators S.A., 65 Othonos-Amalias St, 262 21 Patras, Greece and Department of Computer Engineering
Algorithms for solving sequential (zero-sum) games. Main case in these slides: chess. Slide pack by Tuomas Sandholm
 games. Main case in these slides: chess. Slide pack by Tuomas Sandholm") Algorithms for solving sequential (zero-sum) games Main case in these slides: chess Slide pack by Tuomas Sandholm Rich history of cumulative ideas Game-theoretic perspective Game of perfect information
Algorithms for solving sequential (zero-sum) games Main case in these slides: chess Slide pack by Tuomas Sandholm Rich history of cumulative ideas Game-theoretic perspective Game of perfect information
CS-E4800 Artificial Intelligence
 CS-E4800 Artificial Intelligence Jussi Rintanen Department of Computer Science Aalto University March 9, 2017 Difficulties in Rational Collective Behavior Individual utility in conflict with collective
CS-E4800 Artificial Intelligence Jussi Rintanen Department of Computer Science Aalto University March 9, 2017 Difficulties in Rational Collective Behavior Individual utility in conflict with collective
Foundations of AI. 6. Board Games. Search Strategies for Games, Games with Chance, State of the Art
 Foundations of AI 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Andreas Karwath, Bernhard Nebel, and Martin Riedmiller SA-1 Contents Board Games Minimax
Foundations of AI 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Andreas Karwath, Bernhard Nebel, and Martin Riedmiller SA-1 Contents Board Games Minimax
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Adversarial Search Instructor: Stuart Russell University of California, Berkeley Game Playing State-of-the-Art Checkers: 1950: First computer player. 1959: Samuel s self-taught
CS 188: Artificial Intelligence Adversarial Search Instructor: Stuart Russell University of California, Berkeley Game Playing State-of-the-Art Checkers: 1950: First computer player. 1959: Samuel s self-taught
Adversarial Search and Game- Playing C H A P T E R 6 C M P T : S P R I N G H A S S A N K H O S R A V I
 Adversarial Search and Game- Playing C H A P T E R 6 C M P T 3 1 0 : S P R I N G 2 0 1 1 H A S S A N K H O S R A V I Adversarial Search Examine the problems that arise when we try to plan ahead in a world
Adversarial Search and Game- Playing C H A P T E R 6 C M P T 3 1 0 : S P R I N G 2 0 1 1 H A S S A N K H O S R A V I Adversarial Search Examine the problems that arise when we try to plan ahead in a world
Artificial Intelligence. Minimax and alpha-beta pruning
 Artificial Intelligence Minimax and alpha-beta pruning In which we examine the problems that arise when we try to plan ahead to get the best result in a world that includes a hostile agent (other agent
Artificial Intelligence Minimax and alpha-beta pruning In which we examine the problems that arise when we try to plan ahead to get the best result in a world that includes a hostile agent (other agent
More on games (Ch )
") More on games (Ch. 5.4-5.6) Alpha-beta pruning Previously on CSci 4511... We talked about how to modify the minimax algorithm to prune only bad searches (i.e. alpha-beta pruning) This rule of checking
More on games (Ch. 5.4-5.6) Alpha-beta pruning Previously on CSci 4511... We talked about how to modify the minimax algorithm to prune only bad searches (i.e. alpha-beta pruning) This rule of checking
Decision Making in Multiplayer Environments Application in Backgammon Variants
 Decision Making in Multiplayer Environments Application in Backgammon Variants PhD Thesis by Nikolaos Papahristou AI researcher Department of Applied Informatics Thessaloniki, Greece Contributions Expert
Decision Making in Multiplayer Environments Application in Backgammon Variants PhD Thesis by Nikolaos Papahristou AI researcher Department of Applied Informatics Thessaloniki, Greece Contributions Expert
A general reinforcement learning algorithm that masters chess, shogi and Go through self-play
 A general reinforcement learning algorithm that masters chess, shogi and Go through self-play David Silver, 1,2 Thomas Hubert, 1 Julian Schrittwieser, 1 Ioannis Antonoglou, 1,2 Matthew Lai, 1 Arthur Guez,
A general reinforcement learning algorithm that masters chess, shogi and Go through self-play David Silver, 1,2 Thomas Hubert, 1 Julian Schrittwieser, 1 Ioannis Antonoglou, 1,2 Matthew Lai, 1 Arthur Guez,
Adversarial Search. CMPSCI 383 September 29, 2011
 Adversarial Search CMPSCI 383 September 29, 2011 1 Why are games interesting to AI? Simple to represent and reason about Must consider the moves of an adversary Time constraints Russell & Norvig say: Games,
Adversarial Search CMPSCI 383 September 29, 2011 1 Why are games interesting to AI? Simple to represent and reason about Must consider the moves of an adversary Time constraints Russell & Norvig say: Games,
Foundations of Artificial Intelligence Introduction State of the Art Summary. classification: Board Games: Overview
 Foundations of Artificial Intelligence May 14, 2018 40. Board Games: Introduction and State of the Art Foundations of Artificial Intelligence 40. Board Games: Introduction and State of the Art 40.1 Introduction
Foundations of Artificial Intelligence May 14, 2018 40. Board Games: Introduction and State of the Art Foundations of Artificial Intelligence 40. Board Games: Introduction and State of the Art 40.1 Introduction
Adversarial Search: Game Playing. Reading: Chapter
 Adversarial Search: Game Playing Reading: Chapter 6.5-6.8 1 Games and AI Easy to represent, abstract, precise rules One of the first tasks undertaken by AI (since 1950) Better than humans in Othello and
Adversarial Search: Game Playing Reading: Chapter 6.5-6.8 1 Games and AI Easy to represent, abstract, precise rules One of the first tasks undertaken by AI (since 1950) Better than humans in Othello and
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Adversarial Search Prof. Scott Niekum The University of Texas at Austin [These slides are based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
CS 188: Artificial Intelligence Adversarial Search Prof. Scott Niekum The University of Texas at Austin [These slides are based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
AI in Tabletop Games. Team 13 Josh Charnetsky Zachary Koch CSE Professor Anita Wasilewska
 AI in Tabletop Games Team 13 Josh Charnetsky Zachary Koch CSE 352 - Professor Anita Wasilewska Works Cited Kurenkov, Andrey. a-brief-history-of-game-ai.png. 18 Apr. 2016, www.andreykurenkov.com/writing/a-brief-history-of-game-ai/
AI in Tabletop Games Team 13 Josh Charnetsky Zachary Koch CSE 352 - Professor Anita Wasilewska Works Cited Kurenkov, Andrey. a-brief-history-of-game-ai.png. 18 Apr. 2016, www.andreykurenkov.com/writing/a-brief-history-of-game-ai/
Outline. Game Playing. Game Problems. Game Problems. Types of games Playing a perfect game. Playing an imperfect game
 Outline Game Playing ECE457 Applied Artificial Intelligence Fall 2007 Lecture #5 Types of games Playing a perfect game Minimax search Alpha-beta pruning Playing an imperfect game Real-time Imperfect information
Outline Game Playing ECE457 Applied Artificial Intelligence Fall 2007 Lecture #5 Types of games Playing a perfect game Minimax search Alpha-beta pruning Playing an imperfect game Real-time Imperfect information
Artificial Intelligence
 Artificial Intelligence CS482, CS682, MW 1 2:15, SEM 201, MS 227 Prerequisites: 302, 365 Instructor: Sushil Louis, sushil@cse.unr.edu, http://www.cse.unr.edu/~sushil Games and game trees Multi-agent systems
Artificial Intelligence CS482, CS682, MW 1 2:15, SEM 201, MS 227 Prerequisites: 302, 365 Instructor: Sushil Louis, sushil@cse.unr.edu, http://www.cse.unr.edu/~sushil Games and game trees Multi-agent systems
Reinforcement Learning of Local Shape in the Game of Go
 Reinforcement Learning of Local Shape in the Game of Go David Silver, Richard Sutton, and Martin Müller Department of Computing Science University of Alberta Edmonton, Canada T6G 2E8 {silver, sutton, mmueller}@cs.ualberta.ca
Reinforcement Learning of Local Shape in the Game of Go David Silver, Richard Sutton, and Martin Müller Department of Computing Science University of Alberta Edmonton, Canada T6G 2E8 {silver, sutton, mmueller}@cs.ualberta.ca
Adversarial search (game playing)
") Adversarial search (game playing) References Russell and Norvig, Artificial Intelligence: A modern approach, 2nd ed. Prentice Hall, 2003 Nilsson, Artificial intelligence: A New synthesis. McGraw Hill,
Adversarial search (game playing) References Russell and Norvig, Artificial Intelligence: A modern approach, 2nd ed. Prentice Hall, 2003 Nilsson, Artificial intelligence: A New synthesis. McGraw Hill,
Last update: March 9, Game playing. CMSC 421, Chapter 6. CMSC 421, Chapter 6 1
 Last update: March 9, 2010 Game playing CMSC 421, Chapter 6 CMSC 421, Chapter 6 1 Finite perfect-information zero-sum games Finite: finitely many agents, actions, states Perfect information: every agent
Last update: March 9, 2010 Game playing CMSC 421, Chapter 6 CMSC 421, Chapter 6 1 Finite perfect-information zero-sum games Finite: finitely many agents, actions, states Perfect information: every agent
Today. Types of Game. Games and Search 1/18/2010. COMP210: Artificial Intelligence. Lecture 10. Game playing
 COMP10: Artificial Intelligence Lecture 10. Game playing Trevor Bench-Capon Room 15, Ashton Building Today We will look at how search can be applied to playing games Types of Games Perfect play minimax
COMP10: Artificial Intelligence Lecture 10. Game playing Trevor Bench-Capon Room 15, Ashton Building Today We will look at how search can be applied to playing games Types of Games Perfect play minimax
CS440/ECE448 Lecture 9: Minimax Search. Slides by Svetlana Lazebnik 9/2016 Modified by Mark Hasegawa-Johnson 9/2017
 CS440/ECE448 Lecture 9: Minimax Search Slides by Svetlana Lazebnik 9/2016 Modified by Mark Hasegawa-Johnson 9/2017 Why study games? Games are a traditional hallmark of intelligence Games are easy to formalize
CS440/ECE448 Lecture 9: Minimax Search Slides by Svetlana Lazebnik 9/2016 Modified by Mark Hasegawa-Johnson 9/2017 Why study games? Games are a traditional hallmark of intelligence Games are easy to formalize
DeepStack: Expert-Level AI in Heads-Up No-Limit Poker. Surya Prakash Chembrolu
 DeepStack: Expert-Level AI in Heads-Up No-Limit Poker Surya Prakash Chembrolu AI and Games AlphaGo Go Watson Jeopardy! DeepBlue -Chess Chinook -Checkers TD-Gammon -Backgammon Perfect Information Games
DeepStack: Expert-Level AI in Heads-Up No-Limit Poker Surya Prakash Chembrolu AI and Games AlphaGo Go Watson Jeopardy! DeepBlue -Chess Chinook -Checkers TD-Gammon -Backgammon Perfect Information Games
Programming an Othello AI Michael An (man4), Evan Liang (liange)
, Evan Liang (liange)") Programming an Othello AI Michael An (man4), Evan Liang (liange) 1 Introduction Othello is a two player board game played on an 8 8 grid. Players take turns placing stones with their assigned color (black
Programming an Othello AI Michael An (man4), Evan Liang (liange) 1 Introduction Othello is a two player board game played on an 8 8 grid. Players take turns placing stones with their assigned color (black
DIT411/TIN175, Artificial Intelligence. Peter Ljunglöf. 2 February, 2018
 DIT411/TIN175, Artificial Intelligence Chapters 4 5: Non-classical and adversarial search CHAPTERS 4 5: NON-CLASSICAL AND ADVERSARIAL SEARCH DIT411/TIN175, Artificial Intelligence Peter Ljunglöf 2 February,
DIT411/TIN175, Artificial Intelligence Chapters 4 5: Non-classical and adversarial search CHAPTERS 4 5: NON-CLASSICAL AND ADVERSARIAL SEARCH DIT411/TIN175, Artificial Intelligence Peter Ljunglöf 2 February,
CS 4700: Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence Fall 2017 Instructor: Prof. Haym Hirsh Lecture 10 Today Adversarial search (R&N Ch 5) Tuesday, March 7 Knowledge Representation and Reasoning (R&N Ch 7)
CS 4700: Foundations of Artificial Intelligence Fall 2017 Instructor: Prof. Haym Hirsh Lecture 10 Today Adversarial search (R&N Ch 5) Tuesday, March 7 Knowledge Representation and Reasoning (R&N Ch 7)
Computer Go: from the Beginnings to AlphaGo. Martin Müller, University of Alberta
 Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk Game of Go Short history - Computer Go from the beginnings to AlphaGo The science behind AlphaGo
Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk Game of Go Short history - Computer Go from the beginnings to AlphaGo The science behind AlphaGo
CS 380: ARTIFICIAL INTELLIGENCE ADVERSARIAL SEARCH. Santiago Ontañón
 CS 380: ARTIFICIAL INTELLIGENCE ADVERSARIAL SEARCH Santiago Ontañón so367@drexel.edu Recall: Problem Solving Idea: represent the problem we want to solve as: State space Actions Goal check Cost function
CS 380: ARTIFICIAL INTELLIGENCE ADVERSARIAL SEARCH Santiago Ontañón so367@drexel.edu Recall: Problem Solving Idea: represent the problem we want to solve as: State space Actions Goal check Cost function
Lecture 10: Games II. Question. Review: minimax. Review: depth-limited search
 Lecture 0: Games II cs22.stanford.edu/q Question For a simultaneous two-player zero-sum game (like rock-paper-scissors), can you still be optimal if you reveal your strategy? yes no CS22 / Autumn 208 /
Lecture 0: Games II cs22.stanford.edu/q Question For a simultaneous two-player zero-sum game (like rock-paper-scissors), can you still be optimal if you reveal your strategy? yes no CS22 / Autumn 208 /
MyPawns OppPawns MyKings OppKings MyThreatened OppThreatened MyWins OppWins Draws
 The Role of Opponent Skill Level in Automated Game Learning Ying Ge and Michael Hash Advisor: Dr. Mark Burge Armstrong Atlantic State University Savannah, Geogia USA 31419-1997 geying@drake.armstrong.edu
The Role of Opponent Skill Level in Automated Game Learning Ying Ge and Michael Hash Advisor: Dr. Mark Burge Armstrong Atlantic State University Savannah, Geogia USA 31419-1997 geying@drake.armstrong.edu
Announcements. Homework 1. Project 1. Due tonight at 11:59pm. Due Friday 2/8 at 4:00pm. Electronic HW1 Written HW1
 Announcements Homework 1 Due tonight at 11:59pm Project 1 Electronic HW1 Written HW1 Due Friday 2/8 at 4:00pm CS 188: Artificial Intelligence Adversarial Search and Game Trees Instructors: Sergey Levine
Announcements Homework 1 Due tonight at 11:59pm Project 1 Electronic HW1 Written HW1 Due Friday 2/8 at 4:00pm CS 188: Artificial Intelligence Adversarial Search and Game Trees Instructors: Sergey Levine
Learning from Hints: AI for Playing Threes
 Learning from Hints: AI for Playing Threes Hao Sheng (haosheng), Chen Guo (cguo2) December 17, 2016 1 Introduction The highly addictive stochastic puzzle game Threes by Sirvo LLC. is Apple Game of the
Learning from Hints: AI for Playing Threes Hao Sheng (haosheng), Chen Guo (cguo2) December 17, 2016 1 Introduction The highly addictive stochastic puzzle game Threes by Sirvo LLC. is Apple Game of the
Adversarial Search and Game Playing
 Games Adversarial Search and Game Playing Russell and Norvig, 3 rd edition, Ch. 5 Games: multi-agent environment q What do other agents do and how do they affect our success? q Cooperative vs. competitive
Games Adversarial Search and Game Playing Russell and Norvig, 3 rd edition, Ch. 5 Games: multi-agent environment q What do other agents do and how do they affect our success? q Cooperative vs. competitive
By David Anderson SZTAKI (Budapest, Hungary) WPI D2009
 WPI D2009") By David Anderson SZTAKI (Budapest, Hungary) WPI D2009 1997, Deep Blue won against Kasparov Average workstation can defeat best Chess players Computer Chess no longer interesting Go is much harder for
By David Anderson SZTAKI (Budapest, Hungary) WPI D2009 1997, Deep Blue won against Kasparov Average workstation can defeat best Chess players Computer Chess no longer interesting Go is much harder for
Programming Project 1: Pacman (Due )
") Programming Project 1: Pacman (Due 8.2.18) Registration to the exams 521495A: Artificial Intelligence Adversarial Search (Min-Max) Lectured by Abdenour Hadid Adjunct Professor, CMVS, University of Oulu
Programming Project 1: Pacman (Due 8.2.18) Registration to the exams 521495A: Artificial Intelligence Adversarial Search (Min-Max) Lectured by Abdenour Hadid Adjunct Professor, CMVS, University of Oulu
Pengju
 Introduction to AI Chapter05 Adversarial Search: Game Playing Pengju Ren@IAIR Outline Types of Games Formulation of games Perfect-Information Games Minimax and Negamax search α-β Pruning Pruning more Imperfect
Introduction to AI Chapter05 Adversarial Search: Game Playing Pengju Ren@IAIR Outline Types of Games Formulation of games Perfect-Information Games Minimax and Negamax search α-β Pruning Pruning more Imperfect
CS 771 Artificial Intelligence. Adversarial Search
 CS 771 Artificial Intelligence Adversarial Search Typical assumptions Two agents whose actions alternate Utility values for each agent are the opposite of the other This creates the adversarial situation
CS 771 Artificial Intelligence Adversarial Search Typical assumptions Two agents whose actions alternate Utility values for each agent are the opposite of the other This creates the adversarial situation
Aja Huang Cho Chikun David Silver Demis Hassabis. Fan Hui Geoff Hinton Lee Sedol Michael Redmond
 CMPUT 396 3 hr closedbook 6 pages, 7 marks/page page 1 1. [3 marks] For each person or program, give the label of its description. Aja Huang Cho Chikun David Silver Demis Hassabis Fan Hui Geoff Hinton
CMPUT 396 3 hr closedbook 6 pages, 7 marks/page page 1 1. [3 marks] For each person or program, give the label of its description. Aja Huang Cho Chikun David Silver Demis Hassabis Fan Hui Geoff Hinton
Computing Science (CMPUT) 496
 496") Computing Science (CMPUT) 496 Search, Knowledge, and Simulations Martin Müller Department of Computing Science University of Alberta mmueller@ualberta.ca Winter 2017 Part IV Knowledge 496 Today - Mar 9
Computing Science (CMPUT) 496 Search, Knowledge, and Simulations Martin Müller Department of Computing Science University of Alberta mmueller@ualberta.ca Winter 2017 Part IV Knowledge 496 Today - Mar 9
REINFORCEMENT LEARNING (DD3359) O-03 END-TO-END LEARNING
 O-03 END-TO-END LEARNING") REINFORCEMENT LEARNING (DD3359) O-03 END-TO-END LEARNING RIKA ANTONOVA ANTONOVA@KTH.SE ALI GHADIRZADEH ALGH@KTH.SE RL: What We Know So Far Formulate the problem as an MDP (or POMDP) State space captures
REINFORCEMENT LEARNING (DD3359) O-03 END-TO-END LEARNING RIKA ANTONOVA ANTONOVA@KTH.SE ALI GHADIRZADEH ALGH@KTH.SE RL: What We Know So Far Formulate the problem as an MDP (or POMDP) State space captures
Reinforcement Learning in Games Autonomous Learning Systems Seminar
 Reinforcement Learning in Games Autonomous Learning Systems Seminar Matthias Zöllner Intelligent Autonomous Systems TU-Darmstadt zoellner@rbg.informatik.tu-darmstadt.de Betreuer: Gerhard Neumann Abstract
Reinforcement Learning in Games Autonomous Learning Systems Seminar Matthias Zöllner Intelligent Autonomous Systems TU-Darmstadt zoellner@rbg.informatik.tu-darmstadt.de Betreuer: Gerhard Neumann Abstract
Foundations of Artificial Intelligence
 Foundations of Artificial Intelligence 42. Board Games: Alpha-Beta Search Malte Helmert University of Basel May 16, 2018 Board Games: Overview chapter overview: 40. Introduction and State of the Art 41.
Foundations of Artificial Intelligence 42. Board Games: Alpha-Beta Search Malte Helmert University of Basel May 16, 2018 Board Games: Overview chapter overview: 40. Introduction and State of the Art 41.
AI, AlphaGo and computer Hex
 a math and computing story computing.science university of alberta 2018 march thanks Computer Research Hex Group Michael Johanson, Yngvi Björnsson, Morgan Kan, Nathan Po, Jack van Rijswijck, Broderick
a math and computing story computing.science university of alberta 2018 march thanks Computer Research Hex Group Michael Johanson, Yngvi Björnsson, Morgan Kan, Nathan Po, Jack van Rijswijck, Broderick
CS 380: ARTIFICIAL INTELLIGENCE
 CS 380: ARTIFICIAL INTELLIGENCE ADVERSARIAL SEARCH 10/23/2013 Santiago Ontañón santi@cs.drexel.edu https://www.cs.drexel.edu/~santi/teaching/2013/cs380/intro.html Recall: Problem Solving Idea: represent
CS 380: ARTIFICIAL INTELLIGENCE ADVERSARIAL SEARCH 10/23/2013 Santiago Ontañón santi@cs.drexel.edu https://www.cs.drexel.edu/~santi/teaching/2013/cs380/intro.html Recall: Problem Solving Idea: represent
Learning to Play Love Letter with Deep Reinforcement Learning
 Learning to Play Love Letter with Deep Reinforcement Learning Madeleine D. Dawson* MIT mdd@mit.edu Robert X. Liang* MIT xbliang@mit.edu Alexander M. Turner* MIT turneram@mit.edu Abstract Recent advancements
Learning to Play Love Letter with Deep Reinforcement Learning Madeleine D. Dawson* MIT mdd@mit.edu Robert X. Liang* MIT xbliang@mit.edu Alexander M. Turner* MIT turneram@mit.edu Abstract Recent advancements
Chess Algorithms Theory and Practice. Rune Djurhuus Chess Grandmaster / September 23, 2013
 Chess Algorithms Theory and Practice Rune Djurhuus Chess Grandmaster runed@ifi.uio.no / runedj@microsoft.com September 23, 2013 1 Content Complexity of a chess game History of computer chess Search trees
Chess Algorithms Theory and Practice Rune Djurhuus Chess Grandmaster runed@ifi.uio.no / runedj@microsoft.com September 23, 2013 1 Content Complexity of a chess game History of computer chess Search trees
Theory and Practice of Artificial Intelligence
 Theory and Practice of Artificial Intelligence Games Daniel Polani School of Computer Science University of Hertfordshire March 9, 2017 All rights reserved. Permission is granted to copy and distribute
Theory and Practice of Artificial Intelligence Games Daniel Polani School of Computer Science University of Hertfordshire March 9, 2017 All rights reserved. Permission is granted to copy and distribute
Intelligent Non-Player Character with Deep Learning. Intelligent Non-Player Character with Deep Learning 1
 Intelligent Non-Player Character with Deep Learning Meng Zhixiang, Zhang Haoze Supervised by Prof. Michael Lyu CUHK CSE FYP Term 1 Intelligent Non-Player Character with Deep Learning 1 Intelligent Non-Player
Intelligent Non-Player Character with Deep Learning Meng Zhixiang, Zhang Haoze Supervised by Prof. Michael Lyu CUHK CSE FYP Term 1 Intelligent Non-Player Character with Deep Learning 1 Intelligent Non-Player