Contents. List of Figures
|
|
|
- Suzan Ford
- 5 years ago
- Views:
Transcription
1 1
2 Contents 1 Introduction Rules of the game Complexity of the game History of self-learning backgammon AI Standard techniques Implementation details Usage of open source projects Framework First Try: Windows Framework Second Try: Heuristic Framework Algorithms MCMC TD(λ) Genetic Algorithm Results Intermediate Approaches Final Results MCMC TD Genetic Comparison Comparison Analysis and Conclusions Suggestions for further work A Installation and Running B The code structure List of Figures 3.1 Benchmark players results MCMC learning from gnubg MCMC learning from initial AI MCMC learning from random AI TD learning from random TD learning, changing alpha values TD learning, changing lambda values Genetic population Genetic generations Best Scores A.1 The main GUI
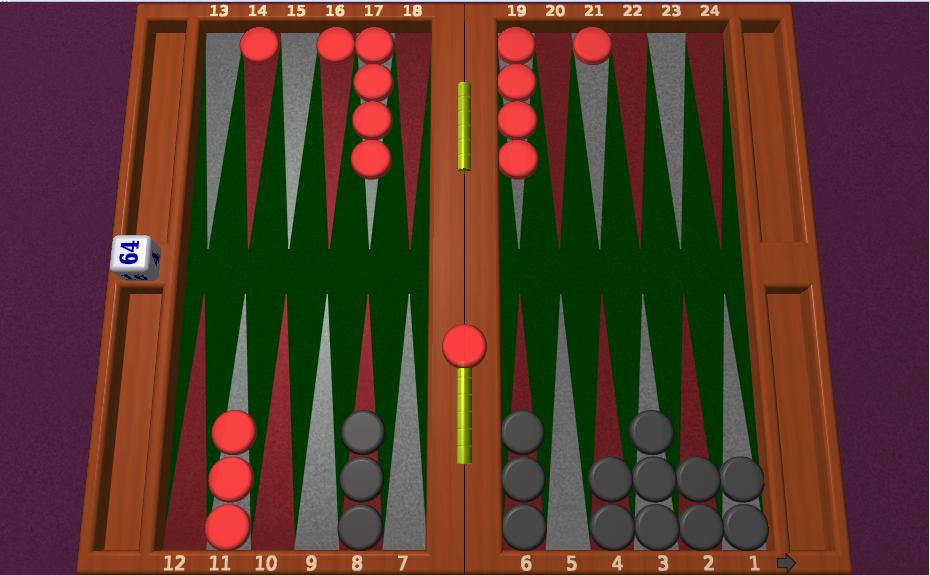
3 1 Introduction In this project we explored the ability of various reinforcement learning algorithms (including a genetic algorithm) in the game of backgammon. We implemented 3 different algorithms: MCMC, TD and Genetic Algorithm. 1.1 Rules of the game (quoted from [1]) Backgammon playing pieces are known variously as checkers, draughts, stones, men, counters, pawns, or chips. The objective is to remove (bear off) all of one s own checkers from the board before one s opponent can do the same. The checkers are scattered at first and may be blocked or hit by the opponent. As the playing time for each individual game is short, it is often played in matches, where victory is awarded to the first player to reach a certain number of points. Setup Each side of the board has a track of 12 long triangles, called points. The points are considered to be connected across one edge of the board, forming a continuous track in the shape of a horseshoe, and are numbered from 1 to 24. Players begin with two checkers on their 24-point, three checkers on their 8-point, and five checkers each on their 13-point and their 6-point. The two players move their checkers in opposing directions, from the 24-point towards the 1-point. Points 1 through 6 are called the home board or inner board, and points 7 through 12 are called the outer board. The 7-point is referred to as the bar point, and the 13-point as the mid point. Movement To start the game, each player rolls one die, and the player with the higher number moves first using both the numbers shown. If the players roll the same number, they must roll again as the first move can not be a double. Both dice must land completely flat on the right hand side of the gameboard. The players then alternate turns, rolling two dice at the beginning of each turn. After rolling the dice players must, if possible, move their checkers according to the number of pips shown on each die. For example, if the player rolls a 6 and a 3 (notated as 6-3 ), that player must move one checker six points forward, and another or the same checker three points forward. The same checker may be moved twice as long as the two moves are distinct: six and then three, or three and then six. If a player rolls two of the same number, called doubles, that player must play each die twice. For example, upon rolling a 5-5 that player may move up to four separate checkers forward five spaces each. For any roll, if a player can move both dice, that player is compelled to do so. If players cannot move either die in a roll, given the position of their checkers then that turn is over and the turn passes to the opponent. If it is possible to move either die, but not both, the higher number must be played. For example if a player rolls 6-3 and can only move a 6 or a 3, the 6 being the bigger number must be moved; if it is possible to move the 3 but not the 6 then the 3 is played. Further, if one die is unable to be moved, but such a move is made possible by the moving of the other die, that move is compulsory. In the course of a move, a checker may land on any point that is unoccupied or is occupied only by a player s own checkers. It may also land on a point occupied by exactly one opposing checker, or blot. In this case, the blot has been hit, and is placed in the middle of the board on the bar that divides the two sides of the playing surface. A checker may never land on a point occupied by two or more opposing checkers; thus, no point is ever occupied by checkers from both players simultaneously. Checkers placed on the bar re-enter the game through the opponent s home board. A roll of 2 allows the checker to enter on the 23-point, a roll of 3 on the 22-point, and so forth. A player may not move any other checkers until all checkers on the bar belonging to that player have re-entered the game. When all of a player s checkers are in that player s home board, that player may start removing them; this is called bearing off. A roll of 1 may be used to bear off a checker from the 1-point, a 2 from the 2-point, and so on. A die may not be used to bear off checkers from a lower-numbered point unless there are no checkers on any higher points. For example if a player rolls a 6 and a 3
4 5, but has no checkers on the 6-point, though 2 checkers remain on the 5-point, then the 6 and the 5 must be used to bear off the 2 checkers from the 5-point. When bearing off, a player may also move a lower die roll before the higher even if that means the full value of the higher die is not fully utilized. For example, if a player has exactly 1 checker remaining on the 6-point, and rolls a 6 and a 1, the player may move the 6-point checker 1 place to the 5-point with the lower die roll of 1, and then bear that checker off the 5-point using the die roll of 6; this is sometimes useful tactically. If one player has not borne off any checkers by the time that player s opponent has borne off all fifteen, then the player has lost a gammon, which counts for double a normal loss. If the losing player has not borne off any checkers and still has checkers on the bar or in the opponent s home board, then the player has lost a backgammon, which counts for triple a normal loss. Doubling The game also includes doubling - an action which (if taken) causes the score to be doubled. In order to simplify the game, we ignored doubling in the implementation of the game. 1.2 Complexity of the game The major difficulty in modelling an AI for backgammon, is the large number of possible states. The number is estimated[2] at which is far too large for any practical purpose. Moreover, the large branching factor (several hundred[2] for each move) is an obstacle for common game-tree approaches. 1.3 History of self-learning backgammon AI In 1992, Tesauro [2], using the TD(λ) algorithm, on a multilayered neural net structure, created TD-Gammon. Learning from self-play, it achieved a level of play comparable to human experts without explicit programming of heuristic function evaluation. It was further shown[3] that other algorithms that implement co-evolution, could achieve similar results - using a genetic algorithm, on a framework of neural networks Standard techniques Bearoff database Surprisingly, programmed AIs are better at the evaluation of normal game progress situations (which is a pattern evaluation problem), but are worse in the evaluation of the bearoff positions. It is standard to use a database for the ending positions. Lookahead For the evaluation of the board, one way is to look at the possibilities for the game tree in the immediate future of the position. Because of the large branching factor, this is generally limited to a small (1-3) number of moves. Rollouts One technique for the evaluation of a board position, is to sample several chains of rollouts (throws of dice) from the position, and have the AI play according to them. Then the position is scored according to the average score (or evaluation of resulting boards - if using partial rollouts). 4
5 2 Implementation details 2.1 Usage of open source projects The game details implementation (board position logic, board GUI), where adapted from JGammon[4]. JGammon is an open-source project, that gives you the option to play Backgammon games against different AIs and provides you with an interface to create new AIs. Since the AIs in JGammon are still in development, we added the Gnu Backgammon program (gnubg [5]) for benchmarking. As its name suggests gnubg is also an open-source project, that also give you the option to play against AIs, but in contrary to JGammon, gnubg uses neural network weight tables which were built in months of trainings. Gnubg gives you different difficulty levels (controlled by adding noise to the decisions and n-ply lookahead). Gnubg at its full power - no noise and 3-ply lookahead is considered as a human expert. That was confirmed by the members of this team :). The JGammon gui was heavily simplified to remove unneeded options, leaving a plain gameplay. 2.2 Framework One of the great challenges in this project was the evaluation function of the board. The target was to create an effective evaluation function mapping a board to a respective value, which should be an approximation of the expectation of the score achievable from the board position. Then when a move in needed in a game, we go all over the possible next move boards, and choose the one with the highest value. As the number of states is very large, we needed some abstraction of the board. The implementation of the function was using the naive approach of a lookup table (LUT), which was filled by the various algorithms. It should be noted, that since there is full observability of the game position, and the passage from a position (with dice), to the next (without dice) is deterministic, it is sufficient to evaluate the board positions, and there is no need to evaluate a separate value for actions. First we tried a simple relaxation, which proved to be not very successful even against random opponents, then we tried a different approach that proved itself to be better than the first. We called every evaluation function a framework First Try: Windows Framework The window framework is basically a relaxation of the board full description. The first abstraction we used is that the number of checkers at each point can be either 0, 1 or 2. That means that two boards are considered equal if they only differ in the actual number of checkers at points which aren t a blot. Furthermore we divide the board to different windows. A window is a series of continuous points on the board. We divide a board to a number of windows. Windows can overlap. Then we assign a value to every window in the board, and the value of the board is the average of all the windows values. After implementing this framework and testing it using the different algorithms (discussed later), we reached poor result in all the test cases, even against random opponent. The main reason for the poor performance of this framework is that the relaxation wasn t enough, and the number of states was still too large to be learnt well enough from a limited number of games. In addition, it might be that the averaging of values of windows did not create a good enough estimate of the overall board value. We have changed the framework to a different one which gave better results: the heuristic framework Second Try: Heuristic Framework The heuristic framework extracts a small set of features from each board. The function that uses the features to evaluate the board (using a LUT) is learnt by the RL algorithms. Those features are: 1. The number of houses (points with checkers, which aren t a blot). 2. The number of blots. 5
6 3. The number of checkers on the bar. 4. The number of checkers of the other player on the bar. 5. The number of houses in the last six points. 6. Whether separation of pieces has been achieved (all other player pieces are before all pieces). 2.3 Algorithms We have used the following algorithms, using as a utility function the score of the game, thereby trying to maximize the expected score of a game. We have considered implementing an on-policy algorithm (SARSA), but since the results from learning from self play were poor, we have deemed it a lost cause MCMC Monte Carlo Markov Chain sampling algorithm is a model-free off-policy algorithm for evaluating the value of positions. Using a given policy (AI), it runs a large number of simulation of the game. The algorithm samples every board in a simulation of a game and gives it a value according to the average score of games which pass through that board. In our implementation, we did not accumulate the results when moving to a new generation, that means each generation learns the entire database from scratch. Since the algorithm is trivially parallelizable, we implemented it using multi-threading, for speedup of computation TD(λ) Temporal Difference is a model-free off-policy algorithm for evaluating the value of positions. Using a given policy (AI) it runs a large number of games. The value given to the board is averaged using the approximation given to the next position generated in the markovian chain. λ is an interpolation parameter, for interpolating between the immediate estimation of the reward and the reward of later positions. The reward (of non-terminal states) is calculated as: R(p) = λv (p + ) + (1 λ)r(p + ) Where p + is the next position in the chain. Then the value is update as V (p) = (1 α)v (p) + αr(p) Where α is the averaging parameter. [6] Genetic Algorithm Genetic algorithm is a local search algorithm. A population of (intermediate) solutions is kept. Each solutions is given a score by a scoring function, and a selection function chooses, with a preference to higher scoring members, solutions to go on to the next generation. A crossover function is used to combine different solutions, and a mutation function to modify them randomly in a small manner. In our implementation, we used randomly generated LUTs as the initial population, the scoring function was done by evaluating the expected performance against a specified AI. The selection function selected randomly in proportion to the expectation of the score (after adding 3 in order to have positive results). The crossover function averaged the value given to each position between the two AIs. The mutation function added white noise to the value of each board. It is possible to score the population using games against one another, thereby implementing self play, without the need of a specific AI to score against. We have used an outside AI in order to check the effect of the scoring function on the results. 6
7 3 Results 3.1 Intermediate Approaches We have discovered that an addition of features to the framework, has in fact caused poorer results. This is a direct consequence of the naive implementation of the evaluation function as a LUT - with a too large state space, it is hard to learn to evaluate a function properly, without some sort of interpolation between neighboring states. We have found out that it is better (in the RL algorithms) to learn from a game between the AI we are learning from and the random player. This configuration gave better results than learning from a game between two better AIs, even when using ɛ-greedy exploration (choosing a random move with probability ɛ). The probable reason for this is that the naive implementation of the evaluation function as a LUT, causes the resulting AI to behave very close to a random one - since it has to see each framework value in order to evaluate it differently than the default. Although we have implemented rollouts to augment an existing AI, we have found that it is too computationally expensive, and did not give significantly better results. The AIs resulting from our imlementation are not stable enough to use as a reliable guide for the rollout game progress, and the evaluation function not good enough to give reliable results for partial rollouts. 3.2 Final Results Benchmarking was done by evaluating the expectation of the score of a game (measured on 1000 games) on 3 AIs: GnuBG - the gnubg AI (set on expert level, which although not the strongest setting, does play reasonably well). Random - an AI choosing the moves uniformly at random Initial - JGammon s initial AI - an AI using a linear evaluation function on a small set of heuristics. This AI is very weak, and has very peculiar behaviour. In our tests we measure the expected score of a game. A score is positive if our player won, and negative if the opponent won. A single game has a score from 1 to 3. 1 (or -1) for a regular win, 2 is a gammon (qxn) and 3 is a backgammon (iwxeh qxn). 7
8 Figure 3.1: Benchmark players results MCMC MCMC tests have three parameters: Number of games for each learning generations (varying from 10 to 10000, multiplied by 10). Number of generations (varying from 1 to 9, steps of 2). AI to learn from 8
9 Figure 3.2: MCMC learning from gnubg Figure 3.2 shows only one generation learning, as later generations produce poor results. It can be observed that the AI achieves good result against the random opponent, and a continued improvement against the initial AI opponent. Even though the AI did not show any improvement against the gnubg AI. It is important to remember that when you play more games, your database will be larger, but still not close to the number of states. 9
10 Figure 3.3: MCMC learning from initial AI Figure 3.3 shows again only one generation, for the same reasons. This figure and figure 3.1 show a surprising result, as learning from gnubg yields good results against initial AI and poor results against gnubg opponent, as this figure suggests, learning from initial AI produces poor results against the initial AI, and relatively good results against gnubg opponent (breaking the -2.0 barrier and showing an improvement against a much stronger opponent). 10
11 Figure 3.4: MCMC learning from random AI In figure 3.4 we can see very good results against the random opponent as expected, and a consistent dominance over initial AI. Results against gnubg does not break the -2.0 barrier. We can see from the various figures, that the performance does get better with more games TD TD tests have five parameters: Number of games for each learning generations (varying from 10 to 10000, powers of 10). Number of generations (varying from 1 to 9, steps of 2). Alpha factor (varying from 0.01 to 0.1, steps of 0.01) Lambda factor (varying from 0.1 to 1, steps of 0.1) AI to learn from. 11
12 Figure 3.5: TD learning from random Figure 3.5 shows the correlation between the average score and the number of games learned from (against random with lambda=0.1 alpha=0.01). As expected, in general the player improves as the number of games increases. However, it seems that against the better players the learning curve peaks around 1000 games, and from there on the results stay more or less the same. Figure 3.6: TD learning, changing alpha values 12
13 Figure 3.7: TD learning, changing lambda values When looking at figures 3.6 and 3.7, we can see no conclusive alpha or lambda values that yield the best results for all opponents. There is a small correlation between the good lambda values for random and initial AI (learned from), but the maximum for gnubg is different. Again, graphs with varying generations do not appear here, because beyond one generation the performance is deteriorating Genetic Genetic tests have three parameters: Size of population (varying from 10 to 1000, powers of 10). Number of generations (varying from 10 to 40, steps of 5). AI to learn from (for use in scoring). 13
14 Figure 3.8: Genetic population Figure 3.8 shows the correlation between the average score and the population (learned from random with 40 generations). There is no clear connection between these parameters. However, most of the tests show that the score in general declines as the population grows. 14
15 Figure 3.9: Genetic generations Figure 3.9 shows the correlation between the average score and the number of generations (learned from gnubg with a population of 10). In this case it is very hard to find a connection between the parameters, though it seems that for a low number of generations and for a high number the score is the highest. Note that generations in genetic algorithms is inherently different concept from generations in MCMC or TD algorithms Comparison These results suggest that the genetic algorithm framework is too noisy to give reliable results - a direct consequence from the large number of parameters of the framework (the LUT implementation), and the small number of generations run (since running a large number is computationally punitive). 15
16 3.2.5 Comparison Figure 3.10: Best Scores Figure 3.10 shows the comparison between the best results we got from all of the learning algorithms and opponents. It is clear that the genetic algorithm performs poorly in comparison to the RL algorithms. 16
17 4 Analysis and Conclusions The resulting AIs from the RL algorithms achieved quite good results against the random opponent - much better than InitialAI s performance - but performed only slightly better against InitialAI. Unsurprisingly the performance against gnubg is abysmal, it is better than random (expectation of losing with score 1.5 instead of 2.5) but generally worse than initialai (1.3). Playing against the resulting AIs, we have noticed that the initial game play was much more reasonable than the bearoff. This is expected since it is known that programming an evaluation of the bearoff states is particularly difficult (which is why a database is normally used), and the framework we used is totally unsuitable for such evaluation. The genetic algorithm resulting AIs have much worse results. The large number of parameters (since we used a LUT framework), and the small number of generations (it was computationally punitive) - which means that the number of games played during the learning process is quite small in comparison to the RL algorithms - caused poor performance of this algorithm. It is easily verified by noting that the size of the LUT in the AIs resulting from the genetic algorithm, are much smaller than the corresponding AIs resulting from the RL algorithms. The various parameters had small effect on the actual results. This suggests that saturation of the performance available from the specific framework we used, is already achieved. This would also explain why self-play did not cause noticeable improvement. The conclusion is that even with a simple set of features, and a simple framework (not using the flexibility achieved by using neural networks) reasonable performance could be achieved using reinforcement learning, however, expectedly, the performance is worse than those acheived with a flexible framework, and a long training period. 4.1 Suggestions for further work It would be interesting to see if using an interpolation scheme, and perhaps using a smaller set of parameters for the evaluation function, would improve the performance - especially with the genetic algorithm. It would be interesting to compare the performance of different feature sets and frameworks. It would be interesting to see the effect of different selection, crossover and mutation functions on the genetic algorithm performance. 17

18 A Installation and Running Warning: The compilation process takes a while as the makefile compiles gnubg, get a cup of coffee in the meantime. To install - make. To run - make run. Note: since gnubg runs on a separate process, if interrupted it continues to run on the computer, and interferes with running it again. running killall gnubg would clear it. Warning: The compilation process takes a while as the makefile compiles gnubg, get a cup of coffee in the meantime. The GUI We provide an interface to create a new AI player that learns from a given AI. One can create a player using any of the algorithms we implemented using any AI he choses. In the same interface we provide a way to play against any AI opponent, including one created from learning. We also provide the ability to save created AI to files and to load them from files. Figure A.1: The main GUI The GUI is divided into two sections, the upper section which focuses on playing or watching games. The lower part handles learning. When learning a new AI, the new AI is placed in memory and called the current learner. When learning a new AI, you can choose the algorithm you want to use, and AI to learn from, and the different parameters for each algorithm. In the directory AIs, there is a representative AIs from the various algorithms, which could be used to play against (by loading them from file). Warning: Learning with large parameters can lead to long computational time, so choose the parameters carefully. After learning you can view any game by choosing the preferred players and clicking Start Game. 18
19 B The code structure <AI> options are specified as -c classname for loading a class (e.g. -c jgam.ai.randomai) or as -o filename for loading an object (e.g. -o AIs/MCMC.ai), or as -ro..., -rc... for augmentation with rollouts. utils Miscellaneous utilities used for various jobs. Game - an implementation of a simulation of a game between 2 AIs Main: <AI1> <AI2> would run a match of 1000 games of one against the other, and print the expected score. Learner - an implementation of the learning process. Loader - a dynamic AI class loader. Logger - an interface for logging the board positions during the game simulation RolloutAI - an implementation of augmentation of an AI using rollouts. framework The implementation of the feature framework extracted from the board FrameworkAI - an implementation of the AI using the LUT. HeuristicFramework - the features extracted from the board position. gui MainGui - the gui rl RL - an interface for the learning algorithms MCMC - an implementation of the MCMC algorithm Main: <AI> <numberofgames> <filename> learns from the ai, running the specified number of simulations, and saves to the filename TD - an implementation of the TD algorithm Main: <AI> <gamesnumber> <lambda> <alpha> <filename> learns from the ai, using the specified parameters, and saves to the filename Exploration - an implementation of ɛ-greedy exploration genetic Genetic - an implementation of genetic algorithm Main: <population> <gamenumber> <AI> <filename> learns from the ai, using the specified parameters, and saves to the filename 19
20 References [1] Wikipedia - [2] Temporal Difference Learning and TD-Gammon / Gerald Tesauro / Communications of the ACM, March 1995, Vol. 38, No. 3 / Available at [3] Co-Evolution in the Successful Learning of Backgammon Strategy / Jordan B. Pollack & Alan D. Blair / Journal Machine Learning archive Volume 32 Issue 3, Sept [4] [5] [6] Reinforcement Learning: An Introduction / Richard S. Sutton and Andrew G. Barto / Available at sutton/book/ebook/index.html 20
TD-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play
 NOTE Communicated by Richard Sutton TD-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play Gerald Tesauro IBM Thomas 1. Watson Research Center, I? 0. Box 704, Yorktozon Heights, NY 10598
NOTE Communicated by Richard Sutton TD-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play Gerald Tesauro IBM Thomas 1. Watson Research Center, I? 0. Box 704, Yorktozon Heights, NY 10598
Reinforcement Learning in Games Autonomous Learning Systems Seminar
 Reinforcement Learning in Games Autonomous Learning Systems Seminar Matthias Zöllner Intelligent Autonomous Systems TU-Darmstadt zoellner@rbg.informatik.tu-darmstadt.de Betreuer: Gerhard Neumann Abstract
Reinforcement Learning in Games Autonomous Learning Systems Seminar Matthias Zöllner Intelligent Autonomous Systems TU-Darmstadt zoellner@rbg.informatik.tu-darmstadt.de Betreuer: Gerhard Neumann Abstract
An Artificially Intelligent Ludo Player
 An Artificially Intelligent Ludo Player Andres Calderon Jaramillo and Deepak Aravindakshan Colorado State University {andrescj, deepakar}@cs.colostate.edu Abstract This project replicates results reported
An Artificially Intelligent Ludo Player Andres Calderon Jaramillo and Deepak Aravindakshan Colorado State University {andrescj, deepakar}@cs.colostate.edu Abstract This project replicates results reported
Training a Back-Propagation Network with Temporal Difference Learning and a database for the board game Pente
 Training a Back-Propagation Network with Temporal Difference Learning and a database for the board game Pente Valentijn Muijrers 3275183 Valentijn.Muijrers@phil.uu.nl Supervisor: Gerard Vreeswijk 7,5 ECTS
Training a Back-Propagation Network with Temporal Difference Learning and a database for the board game Pente Valentijn Muijrers 3275183 Valentijn.Muijrers@phil.uu.nl Supervisor: Gerard Vreeswijk 7,5 ECTS
Game Design Verification using Reinforcement Learning
 Game Design Verification using Reinforcement Learning Eirini Ntoutsi Dimitris Kalles AHEAD Relationship Mediators S.A., 65 Othonos-Amalias St, 262 21 Patras, Greece and Department of Computer Engineering
Game Design Verification using Reinforcement Learning Eirini Ntoutsi Dimitris Kalles AHEAD Relationship Mediators S.A., 65 Othonos-Amalias St, 262 21 Patras, Greece and Department of Computer Engineering
CMSC 671 Project Report- Google AI Challenge: Planet Wars
 1. Introduction Purpose The purpose of the project is to apply relevant AI techniques learned during the course with a view to develop an intelligent game playing bot for the game of Planet Wars. Planet
1. Introduction Purpose The purpose of the project is to apply relevant AI techniques learned during the course with a view to develop an intelligent game playing bot for the game of Planet Wars. Planet
Backgammon Basics And How To Play
 Backgammon Basics And How To Play Backgammon is a game for two players, played on a board consisting of twenty-four narrow triangles called points. The triangles alternate in color and are grouped into
Backgammon Basics And How To Play Backgammon is a game for two players, played on a board consisting of twenty-four narrow triangles called points. The triangles alternate in color and are grouped into
Decision Making in Multiplayer Environments Application in Backgammon Variants
 Decision Making in Multiplayer Environments Application in Backgammon Variants PhD Thesis by Nikolaos Papahristou AI researcher Department of Applied Informatics Thessaloniki, Greece Contributions Expert
Decision Making in Multiplayer Environments Application in Backgammon Variants PhD Thesis by Nikolaos Papahristou AI researcher Department of Applied Informatics Thessaloniki, Greece Contributions Expert
Absolute Backgammon for the ipad Manual Version 2.0 Table of Contents
 Absolute Backgammon for the ipad Manual Version 2.0 Table of Contents Game Design Philosophy 2 Game Layout 2 How to Play a Game 3 How to get useful information 4 Preferences/Settings 5 Main menu 6 Actions
Absolute Backgammon for the ipad Manual Version 2.0 Table of Contents Game Design Philosophy 2 Game Layout 2 How to Play a Game 3 How to get useful information 4 Preferences/Settings 5 Main menu 6 Actions
CS 229 Final Project: Using Reinforcement Learning to Play Othello
 CS 229 Final Project: Using Reinforcement Learning to Play Othello Kevin Fry Frank Zheng Xianming Li ID: kfry ID: fzheng ID: xmli 16 December 2016 Abstract We built an AI that learned to play Othello.
CS 229 Final Project: Using Reinforcement Learning to Play Othello Kevin Fry Frank Zheng Xianming Li ID: kfry ID: fzheng ID: xmli 16 December 2016 Abstract We built an AI that learned to play Othello.
2048: An Autonomous Solver
 2048: An Autonomous Solver Final Project in Introduction to Artificial Intelligence ABSTRACT. Our goal in this project was to create an automatic solver for the wellknown game 2048 and to analyze how different
2048: An Autonomous Solver Final Project in Introduction to Artificial Intelligence ABSTRACT. Our goal in this project was to create an automatic solver for the wellknown game 2048 and to analyze how different
Automated Suicide: An Antichess Engine
 Automated Suicide: An Antichess Engine Jim Andress and Prasanna Ramakrishnan 1 Introduction Antichess (also known as Suicide Chess or Loser s Chess) is a popular variant of chess where the objective of
Automated Suicide: An Antichess Engine Jim Andress and Prasanna Ramakrishnan 1 Introduction Antichess (also known as Suicide Chess or Loser s Chess) is a popular variant of chess where the objective of
OCTAGON 5 IN 1 GAME SET
 OCTAGON 5 IN 1 GAME SET CHESS, CHECKERS, BACKGAMMON, DOMINOES AND POKER DICE Replacement Parts Order direct at or call our Customer Service department at (800) 225-7593 8 am to 4:30 pm Central Standard
OCTAGON 5 IN 1 GAME SET CHESS, CHECKERS, BACKGAMMON, DOMINOES AND POKER DICE Replacement Parts Order direct at or call our Customer Service department at (800) 225-7593 8 am to 4:30 pm Central Standard
U.S. TOURNAMENT BACKGAMMON RULES* (Honest, Fair Play And Sportsmanship Will Take Precedence Over Any Rule - Directors Discretion)
") U.S. TOURNAMENT BACKGAMMON RULES* (Honest, Fair Play And Sportsmanship Will Take Precedence Over Any Rule - Directors Discretion) 1.0 PROPRIETIES 1.1 TERMS. TD-Tournament Director, TS-Tournament Staff
U.S. TOURNAMENT BACKGAMMON RULES* (Honest, Fair Play And Sportsmanship Will Take Precedence Over Any Rule - Directors Discretion) 1.0 PROPRIETIES 1.1 TERMS. TD-Tournament Director, TS-Tournament Staff
Programming an Othello AI Michael An (man4), Evan Liang (liange)
, Evan Liang (liange)") Programming an Othello AI Michael An (man4), Evan Liang (liange) 1 Introduction Othello is a two player board game played on an 8 8 grid. Players take turns placing stones with their assigned color (black
Programming an Othello AI Michael An (man4), Evan Liang (liange) 1 Introduction Othello is a two player board game played on an 8 8 grid. Players take turns placing stones with their assigned color (black
For slightly more detailed instructions on how to play, visit:
 Introduction to Artificial Intelligence CS 151 Programming Assignment 2 Mancala!! The purpose of this assignment is to program some of the search algorithms and game playing strategies that we have learned
Introduction to Artificial Intelligence CS 151 Programming Assignment 2 Mancala!! The purpose of this assignment is to program some of the search algorithms and game playing strategies that we have learned
Plakoto. A Backgammon Board Game Variant Introduction, Rules and Basic Strategy. (by J.Mamoun - This primer is copyright-free, in the public domain)
") Plakoto A Backgammon Board Game Variant Introduction, Rules and Basic Strategy (by J.Mamoun - This primer is copyright-free, in the public domain) Introduction: Plakoto is a variation of the game of backgammon.
Plakoto A Backgammon Board Game Variant Introduction, Rules and Basic Strategy (by J.Mamoun - This primer is copyright-free, in the public domain) Introduction: Plakoto is a variation of the game of backgammon.
An Empirical Evaluation of Policy Rollout for Clue
 An Empirical Evaluation of Policy Rollout for Clue Eric Marshall Oregon State University M.S. Final Project marshaer@oregonstate.edu Adviser: Professor Alan Fern Abstract We model the popular board game
An Empirical Evaluation of Policy Rollout for Clue Eric Marshall Oregon State University M.S. Final Project marshaer@oregonstate.edu Adviser: Professor Alan Fern Abstract We model the popular board game
Bootstrapping from Game Tree Search
 Joel Veness David Silver Will Uther Alan Blair University of New South Wales NICTA University of Alberta December 9, 2009 Presentation Overview Introduction Overview Game Tree Search Evaluation Functions
Joel Veness David Silver Will Uther Alan Blair University of New South Wales NICTA University of Alberta December 9, 2009 Presentation Overview Introduction Overview Game Tree Search Evaluation Functions
Unit-III Chap-II Adversarial Search. Created by: Ashish Shah 1
 Unit-III Chap-II Adversarial Search Created by: Ashish Shah 1 Alpha beta Pruning In case of standard ALPHA BETA PRUNING minimax tree, it returns the same move as minimax would, but prunes away branches
Unit-III Chap-II Adversarial Search Created by: Ashish Shah 1 Alpha beta Pruning In case of standard ALPHA BETA PRUNING minimax tree, it returns the same move as minimax would, but prunes away branches
Artificial Intelligence Search III
 Artificial Intelligence Search III Lecture 5 Content: Search III Quick Review on Lecture 4 Why Study Games? Game Playing as Search Special Characteristics of Game Playing Search Ingredients of 2-Person
Artificial Intelligence Search III Lecture 5 Content: Search III Quick Review on Lecture 4 Why Study Games? Game Playing as Search Special Characteristics of Game Playing Search Ingredients of 2-Person
CSC321 Lecture 23: Go
 CSC321 Lecture 23: Go Roger Grosse Roger Grosse CSC321 Lecture 23: Go 1 / 21 Final Exam Friday, April 20, 9am-noon Last names A Y: Clara Benson Building (BN) 2N Last names Z: Clara Benson Building (BN)
CSC321 Lecture 23: Go Roger Grosse Roger Grosse CSC321 Lecture 23: Go 1 / 21 Final Exam Friday, April 20, 9am-noon Last names A Y: Clara Benson Building (BN) 2N Last names Z: Clara Benson Building (BN)
K-means separated neural networks training with application to backgammon evaluations
 K-means separated neural networks training with application to backgammon evaluations Øystein Johansen December 19, 2007 Abstract This study examines whether a k-means clustering method can be utilied
K-means separated neural networks training with application to backgammon evaluations Øystein Johansen December 19, 2007 Abstract This study examines whether a k-means clustering method can be utilied
CLASSIC 18'' BACKGAMMON SET
 CLASSIC 18'' BACKGAMMON SET August 2012 UPC Code 7-19265-51829-9 HOW TO PLAY BACKGAMMON Backgammon Includes: 15 Black Pieces 15 White Pieces 4 Dice 1 Doubling Cube Board How to Set Up the Board 1. Lay
CLASSIC 18'' BACKGAMMON SET August 2012 UPC Code 7-19265-51829-9 HOW TO PLAY BACKGAMMON Backgammon Includes: 15 Black Pieces 15 White Pieces 4 Dice 1 Doubling Cube Board How to Set Up the Board 1. Lay
ABPA Backgammon.txt. BACKGAMMON CARTRIDGE INSTRUCTIONS (For 1 or 2 Players)
") BACKGAMMON CARTRIDGE INSTRUCTIONS (For 1 or 2 Players) ABPA Backgammon.txt INTELLIVISION BACKGAMMON is identical with the board game. You can play against the built-in computer at two different skill levels,
BACKGAMMON CARTRIDGE INSTRUCTIONS (For 1 or 2 Players) ABPA Backgammon.txt INTELLIVISION BACKGAMMON is identical with the board game. You can play against the built-in computer at two different skill levels,
CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions
 CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions Slides by Svetlana Lazebnik, 9/2016 Modified by Mark Hasegawa Johnson, 9/2017 Types of game environments Perfect
CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions Slides by Svetlana Lazebnik, 9/2016 Modified by Mark Hasegawa Johnson, 9/2017 Types of game environments Perfect
Foundations of AI. 6. Adversarial Search. Search Strategies for Games, Games with Chance, State of the Art. Wolfram Burgard & Bernhard Nebel
 Foundations of AI 6. Adversarial Search Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard & Bernhard Nebel Contents Game Theory Board Games Minimax Search Alpha-Beta Search
Foundations of AI 6. Adversarial Search Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard & Bernhard Nebel Contents Game Theory Board Games Minimax Search Alpha-Beta Search
Ar#ficial)Intelligence!!
Intelligence!!") Introduc*on! Ar#ficial)Intelligence!! Roman Barták Department of Theoretical Computer Science and Mathematical Logic So far we assumed a single-agent environment, but what if there are more agents and
Introduc*on! Ar#ficial)Intelligence!! Roman Barták Department of Theoretical Computer Science and Mathematical Logic So far we assumed a single-agent environment, but what if there are more agents and
Adversarial Search. Soleymani. Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5
 Adversarial Search CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2017 Soleymani Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5 Outline Game
Adversarial Search CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2017 Soleymani Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5 Outline Game
Learning to play Dominoes
 Learning to play Dominoes Ivan de Jesus P. Pinto 1, Mateus R. Pereira 1, Luciano Reis Coutinho 1 1 Departamento de Informática Universidade Federal do Maranhão São Luís,MA Brazil navi1921@gmail.com, mateus.rp.slz@gmail.com,
Learning to play Dominoes Ivan de Jesus P. Pinto 1, Mateus R. Pereira 1, Luciano Reis Coutinho 1 1 Departamento de Informática Universidade Federal do Maranhão São Luís,MA Brazil navi1921@gmail.com, mateus.rp.slz@gmail.com,
CS151 - Assignment 2 Mancala Due: Tuesday March 5 at the beginning of class
 CS151 - Assignment 2 Mancala Due: Tuesday March 5 at the beginning of class http://www.clubpenguinsaraapril.com/2009/07/mancala-game-in-club-penguin.html The purpose of this assignment is to program some
CS151 - Assignment 2 Mancala Due: Tuesday March 5 at the beginning of class http://www.clubpenguinsaraapril.com/2009/07/mancala-game-in-club-penguin.html The purpose of this assignment is to program some
MITOCW Project: Backgammon tutor MIT Multicore Programming Primer, IAP 2007
 MITOCW Project: Backgammon tutor MIT 6.189 Multicore Programming Primer, IAP 2007 The following content is provided under a Creative Commons license. Your support will help MIT OpenCourseWare continue
MITOCW Project: Backgammon tutor MIT 6.189 Multicore Programming Primer, IAP 2007 The following content is provided under a Creative Commons license. Your support will help MIT OpenCourseWare continue
TEMPORAL DIFFERENCE LEARNING IN CHINESE CHESS
 TEMPORAL DIFFERENCE LEARNING IN CHINESE CHESS Thong B. Trinh, Anwer S. Bashi, Nikhil Deshpande Department of Electrical Engineering University of New Orleans New Orleans, LA 70148 Tel: (504) 280-7383 Fax:
TEMPORAL DIFFERENCE LEARNING IN CHINESE CHESS Thong B. Trinh, Anwer S. Bashi, Nikhil Deshpande Department of Electrical Engineering University of New Orleans New Orleans, LA 70148 Tel: (504) 280-7383 Fax:
Population Initialization Techniques for RHEA in GVGP
 Population Initialization Techniques for RHEA in GVGP Raluca D. Gaina, Simon M. Lucas, Diego Perez-Liebana Introduction Rolling Horizon Evolutionary Algorithms (RHEA) show promise in General Video Game
Population Initialization Techniques for RHEA in GVGP Raluca D. Gaina, Simon M. Lucas, Diego Perez-Liebana Introduction Rolling Horizon Evolutionary Algorithms (RHEA) show promise in General Video Game
Temporal-Difference Learning in Self-Play Training
 Temporal-Difference Learning in Self-Play Training Clifford Kotnik Jugal Kalita University of Colorado at Colorado Springs, Colorado Springs, Colorado 80918 CLKOTNIK@ATT.NET KALITA@EAS.UCCS.EDU Abstract
Temporal-Difference Learning in Self-Play Training Clifford Kotnik Jugal Kalita University of Colorado at Colorado Springs, Colorado Springs, Colorado 80918 CLKOTNIK@ATT.NET KALITA@EAS.UCCS.EDU Abstract
DELUXE 3 IN 1 GAME SET
 Chess, Checkers and Backgammon August 2012 UPC Code 7-19265-51276-9 HOW TO PLAY CHESS Chess Includes: 16 Dark Chess Pieces 16 Light Chess Pieces Board Start Up Chess is a game played by two players. One
Chess, Checkers and Backgammon August 2012 UPC Code 7-19265-51276-9 HOW TO PLAY CHESS Chess Includes: 16 Dark Chess Pieces 16 Light Chess Pieces Board Start Up Chess is a game played by two players. One
Optimal Yahtzee performance in multi-player games
 Optimal Yahtzee performance in multi-player games Andreas Serra aserra@kth.se Kai Widell Niigata kaiwn@kth.se April 12, 2013 Abstract Yahtzee is a game with a moderately large search space, dependent on
Optimal Yahtzee performance in multi-player games Andreas Serra aserra@kth.se Kai Widell Niigata kaiwn@kth.se April 12, 2013 Abstract Yahtzee is a game with a moderately large search space, dependent on
More Adversarial Search
 More Adversarial Search CS151 David Kauchak Fall 2010 http://xkcd.com/761/ Some material borrowed from : Sara Owsley Sood and others Admin Written 2 posted Machine requirements for mancala Most of the
More Adversarial Search CS151 David Kauchak Fall 2010 http://xkcd.com/761/ Some material borrowed from : Sara Owsley Sood and others Admin Written 2 posted Machine requirements for mancala Most of the
Presentation Overview. Bootstrapping from Game Tree Search. Game Tree Search. Heuristic Evaluation Function
 Presentation Bootstrapping from Joel Veness David Silver Will Uther Alan Blair University of New South Wales NICTA University of Alberta A new algorithm will be presented for learning heuristic evaluation
Presentation Bootstrapping from Joel Veness David Silver Will Uther Alan Blair University of New South Wales NICTA University of Alberta A new algorithm will be presented for learning heuristic evaluation
46.1 Introduction. Foundations of Artificial Intelligence Introduction MCTS in AlphaGo Neural Networks. 46.
 Foundations of Artificial Intelligence May 30, 2016 46. AlphaGo and Outlook Foundations of Artificial Intelligence 46. AlphaGo and Outlook Thomas Keller Universität Basel May 30, 2016 46.1 Introduction
Foundations of Artificial Intelligence May 30, 2016 46. AlphaGo and Outlook Foundations of Artificial Intelligence 46. AlphaGo and Outlook Thomas Keller Universität Basel May 30, 2016 46.1 Introduction
Introduction to Artificial Intelligence CS 151 Programming Assignment 2 Mancala!! Due (in dropbox) Tuesday, September 23, 9:34am
 Tuesday, September 23, 9:34am") Introduction to Artificial Intelligence CS 151 Programming Assignment 2 Mancala!! Due (in dropbox) Tuesday, September 23, 9:34am The purpose of this assignment is to program some of the search algorithms
Introduction to Artificial Intelligence CS 151 Programming Assignment 2 Mancala!! Due (in dropbox) Tuesday, September 23, 9:34am The purpose of this assignment is to program some of the search algorithms
Othello/Reversi using Game Theory techniques Parth Parekh Urjit Singh Bhatia Kushal Sukthankar
 Othello/Reversi using Game Theory techniques Parth Parekh Urjit Singh Bhatia Kushal Sukthankar Othello Rules Two Players (Black and White) 8x8 board Black plays first Every move should Flip over at least
Othello/Reversi using Game Theory techniques Parth Parekh Urjit Singh Bhatia Kushal Sukthankar Othello Rules Two Players (Black and White) 8x8 board Black plays first Every move should Flip over at least
Developing Frogger Player Intelligence Using NEAT and a Score Driven Fitness Function
 Developing Frogger Player Intelligence Using NEAT and a Score Driven Fitness Function Davis Ancona and Jake Weiner Abstract In this report, we examine the plausibility of implementing a NEAT-based solution
Developing Frogger Player Intelligence Using NEAT and a Score Driven Fitness Function Davis Ancona and Jake Weiner Abstract In this report, we examine the plausibility of implementing a NEAT-based solution
CMPUT 657: Heuristic Search
 CMPUT 657: Heuristic Search Assignment 1: Two-player Search Summary You are to write a program to play the game of Lose Checkers. There are two goals for this assignment. First, you want to build the smallest
CMPUT 657: Heuristic Search Assignment 1: Two-player Search Summary You are to write a program to play the game of Lose Checkers. There are two goals for this assignment. First, you want to build the smallest
Adversarial Search and Game Playing
 Games Adversarial Search and Game Playing Russell and Norvig, 3 rd edition, Ch. 5 Games: multi-agent environment q What do other agents do and how do they affect our success? q Cooperative vs. competitive
Games Adversarial Search and Game Playing Russell and Norvig, 3 rd edition, Ch. 5 Games: multi-agent environment q What do other agents do and how do they affect our success? q Cooperative vs. competitive
U.S. REGULATION BACKGAMMON Honest, Fair Play And Sportsmanship Will Take Precedence Over Any Rule - Directors Discretion 2017(a) EDITION*
 EDITION*") U.S. REGULATION BACKGAMMON Honest, Fair Play And Sportsmanship Will Take Precedence Over Any Rule - Directors Discretion 2017(a) EDITION* 1.0 PROPRIETIES 1.1 TERMS. TD-Tournament Director, TS-Tournament
U.S. REGULATION BACKGAMMON Honest, Fair Play And Sportsmanship Will Take Precedence Over Any Rule - Directors Discretion 2017(a) EDITION* 1.0 PROPRIETIES 1.1 TERMS. TD-Tournament Director, TS-Tournament
Foundations of AI. 6. Board Games. Search Strategies for Games, Games with Chance, State of the Art
 Foundations of AI 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Andreas Karwath, Bernhard Nebel, and Martin Riedmiller SA-1 Contents Board Games Minimax
Foundations of AI 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Andreas Karwath, Bernhard Nebel, and Martin Riedmiller SA-1 Contents Board Games Minimax
Five-In-Row with Local Evaluation and Beam Search
 Five-In-Row with Local Evaluation and Beam Search Jiun-Hung Chen and Adrienne X. Wang jhchen@cs axwang@cs Abstract This report provides a brief overview of the game of five-in-row, also known as Go-Moku,
Five-In-Row with Local Evaluation and Beam Search Jiun-Hung Chen and Adrienne X. Wang jhchen@cs axwang@cs Abstract This report provides a brief overview of the game of five-in-row, also known as Go-Moku,
Playing Othello Using Monte Carlo
 June 22, 2007 Abstract This paper deals with the construction of an AI player to play the game Othello. A lot of techniques are already known to let AI players play the game Othello. Some of these techniques
June 22, 2007 Abstract This paper deals with the construction of an AI player to play the game Othello. A lot of techniques are already known to let AI players play the game Othello. Some of these techniques
YourTurnMyTurn.com: Backgammon rules. YourTurnMyTurn.com Copyright 2018 YourTurnMyTurn.com
 YourTurnMyTurn.com: Backgammon rules YourTurnMyTurn.com Copyright 2018 YourTurnMyTurn.com Inhoud Backgammon Rules...1 The board...1 Object of the board game...1 Moving the men...1 Rules for moving the
YourTurnMyTurn.com: Backgammon rules YourTurnMyTurn.com Copyright 2018 YourTurnMyTurn.com Inhoud Backgammon Rules...1 The board...1 Object of the board game...1 Moving the men...1 Rules for moving the
More on games (Ch )
") More on games (Ch. 5.4-5.6) Alpha-beta pruning Previously on CSci 4511... We talked about how to modify the minimax algorithm to prune only bad searches (i.e. alpha-beta pruning) This rule of checking
More on games (Ch. 5.4-5.6) Alpha-beta pruning Previously on CSci 4511... We talked about how to modify the minimax algorithm to prune only bad searches (i.e. alpha-beta pruning) This rule of checking
Creating a Poker Playing Program Using Evolutionary Computation
 Creating a Poker Playing Program Using Evolutionary Computation Simon Olsen and Rob LeGrand, Ph.D. Abstract Artificial intelligence is a rapidly expanding technology. We are surrounded by technology that
Creating a Poker Playing Program Using Evolutionary Computation Simon Olsen and Rob LeGrand, Ph.D. Abstract Artificial intelligence is a rapidly expanding technology. We are surrounded by technology that
Monte Carlo Tree Search
 Monte Carlo Tree Search 1 By the end, you will know Why we use Monte Carlo Search Trees The pros and cons of MCTS How it is applied to Super Mario Brothers and Alpha Go 2 Outline I. Pre-MCTS Algorithms
Monte Carlo Tree Search 1 By the end, you will know Why we use Monte Carlo Search Trees The pros and cons of MCTS How it is applied to Super Mario Brothers and Alpha Go 2 Outline I. Pre-MCTS Algorithms
AI Plays Yun Nie (yunn), Wenqi Hou (wenqihou), Yicheng An (yicheng)
, Wenqi Hou (wenqihou), Yicheng An (yicheng)") AI Plays 2048 Yun Nie (yunn), Wenqi Hou (wenqihou), Yicheng An (yicheng) Abstract The strategy game 2048 gained great popularity quickly. Although it is easy to play, people cannot win the game easily,
AI Plays 2048 Yun Nie (yunn), Wenqi Hou (wenqihou), Yicheng An (yicheng) Abstract The strategy game 2048 gained great popularity quickly. Although it is easy to play, people cannot win the game easily,
CS 331: Artificial Intelligence Adversarial Search II. Outline
 CS 331: Artificial Intelligence Adversarial Search II 1 Outline 1. Evaluation Functions 2. State-of-the-art game playing programs 3. 2 player zero-sum finite stochastic games of perfect information 2 1
CS 331: Artificial Intelligence Adversarial Search II 1 Outline 1. Evaluation Functions 2. State-of-the-art game playing programs 3. 2 player zero-sum finite stochastic games of perfect information 2 1
Game Tree Search. Generalizing Search Problems. Two-person Zero-Sum Games. Generalizing Search Problems. CSC384: Intro to Artificial Intelligence
 CSC384: Intro to Artificial Intelligence Game Tree Search Chapter 6.1, 6.2, 6.3, 6.6 cover some of the material we cover here. Section 6.6 has an interesting overview of State-of-the-Art game playing programs.
CSC384: Intro to Artificial Intelligence Game Tree Search Chapter 6.1, 6.2, 6.3, 6.6 cover some of the material we cover here. Section 6.6 has an interesting overview of State-of-the-Art game playing programs.
On the Design and Training of Bots to Play Backgammon Variants
 On the Design and Training of Bots to Play Backgammon Variants Nikolaos Papahristou, Ioannis Refanidis To cite this version: Nikolaos Papahristou, Ioannis Refanidis. On the Design and Training of Bots
On the Design and Training of Bots to Play Backgammon Variants Nikolaos Papahristou, Ioannis Refanidis To cite this version: Nikolaos Papahristou, Ioannis Refanidis. On the Design and Training of Bots
Foundations of Artificial Intelligence
 Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Bernhard Nebel Albert-Ludwigs-Universität
Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Bernhard Nebel Albert-Ludwigs-Universität
Game Tree Search. CSC384: Introduction to Artificial Intelligence. Generalizing Search Problem. General Games. What makes something a game?
 CSC384: Introduction to Artificial Intelligence Generalizing Search Problem Game Tree Search Chapter 5.1, 5.2, 5.3, 5.6 cover some of the material we cover here. Section 5.6 has an interesting overview
CSC384: Introduction to Artificial Intelligence Generalizing Search Problem Game Tree Search Chapter 5.1, 5.2, 5.3, 5.6 cover some of the material we cover here. Section 5.6 has an interesting overview
By David Anderson SZTAKI (Budapest, Hungary) WPI D2009
 WPI D2009") By David Anderson SZTAKI (Budapest, Hungary) WPI D2009 1997, Deep Blue won against Kasparov Average workstation can defeat best Chess players Computer Chess no longer interesting Go is much harder for
By David Anderson SZTAKI (Budapest, Hungary) WPI D2009 1997, Deep Blue won against Kasparov Average workstation can defeat best Chess players Computer Chess no longer interesting Go is much harder for
How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997)
") How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997) Alan Fern School of Electrical Engineering and Computer Science Oregon State University Deep Mind s vs. Lee Sedol (2016) Watson vs. Ken
How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997) Alan Fern School of Electrical Engineering and Computer Science Oregon State University Deep Mind s vs. Lee Sedol (2016) Watson vs. Ken
Contents. Foundations of Artificial Intelligence. Problems. Why Board Games?
 Contents Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Bernhard Nebel, and Martin Riedmiller Albert-Ludwigs-Universität
Contents Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Bernhard Nebel, and Martin Riedmiller Albert-Ludwigs-Universität
Foundations of Artificial Intelligence
 Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Frank Hutter and Bernhard Nebel Albert-Ludwigs-Universität
Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Frank Hutter and Bernhard Nebel Albert-Ludwigs-Universität
Artificial Intelligence
 Artificial Intelligence Adversarial Search Vibhav Gogate The University of Texas at Dallas Some material courtesy of Rina Dechter, Alex Ihler and Stuart Russell, Luke Zettlemoyer, Dan Weld Adversarial
Artificial Intelligence Adversarial Search Vibhav Gogate The University of Texas at Dallas Some material courtesy of Rina Dechter, Alex Ihler and Stuart Russell, Luke Zettlemoyer, Dan Weld Adversarial
AI Approaches to Ultimate Tic-Tac-Toe
 AI Approaches to Ultimate Tic-Tac-Toe Eytan Lifshitz CS Department Hebrew University of Jerusalem, Israel David Tsurel CS Department Hebrew University of Jerusalem, Israel I. INTRODUCTION This report is
AI Approaches to Ultimate Tic-Tac-Toe Eytan Lifshitz CS Department Hebrew University of Jerusalem, Israel David Tsurel CS Department Hebrew University of Jerusalem, Israel I. INTRODUCTION This report is
ECE 517: Reinforcement Learning in Artificial Intelligence
 ECE 517: Reinforcement Learning in Artificial Intelligence Lecture 17: Case Studies and Gradient Policy October 29, 2015 Dr. Itamar Arel College of Engineering Department of Electrical Engineering and
ECE 517: Reinforcement Learning in Artificial Intelligence Lecture 17: Case Studies and Gradient Policy October 29, 2015 Dr. Itamar Arel College of Engineering Department of Electrical Engineering and
Comp 3211 Final Project - Poker AI
 Comp 3211 Final Project - Poker AI Introduction Poker is a game played with a standard 52 card deck, usually with 4 to 8 players per game. During each hand of poker, players are dealt two cards and must
Comp 3211 Final Project - Poker AI Introduction Poker is a game played with a standard 52 card deck, usually with 4 to 8 players per game. During each hand of poker, players are dealt two cards and must
Game Playing Beyond Minimax. Game Playing Summary So Far. Game Playing Improving Efficiency. Game Playing Minimax using DFS.
 Game Playing Summary So Far Game tree describes the possible sequences of play is a graph if we merge together identical states Minimax: utility values assigned to the leaves Values backed up the tree
Game Playing Summary So Far Game tree describes the possible sequences of play is a graph if we merge together identical states Minimax: utility values assigned to the leaves Values backed up the tree
Computing Science (CMPUT) 496
 496") Computing Science (CMPUT) 496 Search, Knowledge, and Simulations Martin Müller Department of Computing Science University of Alberta mmueller@ualberta.ca Winter 2017 Part IV Knowledge 496 Today - Mar 9
Computing Science (CMPUT) 496 Search, Knowledge, and Simulations Martin Müller Department of Computing Science University of Alberta mmueller@ualberta.ca Winter 2017 Part IV Knowledge 496 Today - Mar 9
Game Playing: Adversarial Search. Chapter 5
 Game Playing: Adversarial Search Chapter 5 Outline Games Perfect play minimax search α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information Games vs. Search
Game Playing: Adversarial Search Chapter 5 Outline Games Perfect play minimax search α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information Games vs. Search
Artificial Intelligence
 Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory AI Challenge One 140 Challenge 1 grades 120 100 80 60 AI Challenge One Transform to graph Explore the
Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory AI Challenge One 140 Challenge 1 grades 120 100 80 60 AI Challenge One Transform to graph Explore the
Triple Challenge.txt
 Triple Challenge 3 Complete Games in 1 Cartridge Chess Checkers Backgammon Playing Instructions For 1 or 2 Players TRIPLE CHALLENGE Triple Challenge.txt TRIPLE CHALLENGE is an exciting breakthrough in
Triple Challenge 3 Complete Games in 1 Cartridge Chess Checkers Backgammon Playing Instructions For 1 or 2 Players TRIPLE CHALLENGE Triple Challenge.txt TRIPLE CHALLENGE is an exciting breakthrough in
Approaching The Royal Game of Ur with Genetic Algorithms and ExpectiMax
 Approaching The Royal Game of Ur with Genetic Algorithms and ExpectiMax Tang, Marco Kwan Ho (20306981) Tse, Wai Ho (20355528) Zhao, Vincent Ruidong (20233835) Yap, Alistair Yun Hee (20306450) Introduction
Approaching The Royal Game of Ur with Genetic Algorithms and ExpectiMax Tang, Marco Kwan Ho (20306981) Tse, Wai Ho (20355528) Zhao, Vincent Ruidong (20233835) Yap, Alistair Yun Hee (20306450) Introduction
6. Games. COMP9414/ 9814/ 3411: Artificial Intelligence. Outline. Mechanical Turk. Origins. origins. motivation. minimax search
 COMP9414/9814/3411 16s1 Games 1 COMP9414/ 9814/ 3411: Artificial Intelligence 6. Games Outline origins motivation Russell & Norvig, Chapter 5. minimax search resource limits and heuristic evaluation α-β
COMP9414/9814/3411 16s1 Games 1 COMP9414/ 9814/ 3411: Artificial Intelligence 6. Games Outline origins motivation Russell & Norvig, Chapter 5. minimax search resource limits and heuristic evaluation α-β
Playing CHIP-8 Games with Reinforcement Learning
 Playing CHIP-8 Games with Reinforcement Learning Niven Achenjang, Patrick DeMichele, Sam Rogers Stanford University Abstract We begin with some background in the history of CHIP-8 games and the use of
Playing CHIP-8 Games with Reinforcement Learning Niven Achenjang, Patrick DeMichele, Sam Rogers Stanford University Abstract We begin with some background in the history of CHIP-8 games and the use of
Game Playing. Philipp Koehn. 29 September 2015
 Game Playing Philipp Koehn 29 September 2015 Outline 1 Games Perfect play minimax decisions α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information 2 games
Game Playing Philipp Koehn 29 September 2015 Outline 1 Games Perfect play minimax decisions α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information 2 games
More on games (Ch )
") More on games (Ch. 5.4-5.6) Announcements Midterm next Tuesday: covers weeks 1-4 (Chapters 1-4) Take the full class period Open book/notes (can use ebook) ^^ No programing/code, internet searches or friends
More on games (Ch. 5.4-5.6) Announcements Midterm next Tuesday: covers weeks 1-4 (Chapters 1-4) Take the full class period Open book/notes (can use ebook) ^^ No programing/code, internet searches or friends
Last update: March 9, Game playing. CMSC 421, Chapter 6. CMSC 421, Chapter 6 1
 Last update: March 9, 2010 Game playing CMSC 421, Chapter 6 CMSC 421, Chapter 6 1 Finite perfect-information zero-sum games Finite: finitely many agents, actions, states Perfect information: every agent
Last update: March 9, 2010 Game playing CMSC 421, Chapter 6 CMSC 421, Chapter 6 1 Finite perfect-information zero-sum games Finite: finitely many agents, actions, states Perfect information: every agent
Learning to Play like an Othello Master CS 229 Project Report. Shir Aharon, Amanda Chang, Kent Koyanagi
 Learning to Play like an Othello Master CS 229 Project Report December 13, 213 1 Abstract This project aims to train a machine to strategically play the game of Othello using machine learning. Prior to
Learning to Play like an Othello Master CS 229 Project Report December 13, 213 1 Abstract This project aims to train a machine to strategically play the game of Othello using machine learning. Prior to
Monte Carlo based battleship agent
 Monte Carlo based battleship agent Written by: Omer Haber, 313302010; Dror Sharf, 315357319 Introduction The game of battleship is a guessing game for two players which has been around for almost a century.
Monte Carlo based battleship agent Written by: Omer Haber, 313302010; Dror Sharf, 315357319 Introduction The game of battleship is a guessing game for two players which has been around for almost a century.
A. Rules of blackjack, representations, and playing blackjack
 CSCI 4150 Introduction to Artificial Intelligence, Fall 2005 Assignment 7 (140 points), out Monday November 21, due Thursday December 8 Learning to play blackjack In this assignment, you will implement
CSCI 4150 Introduction to Artificial Intelligence, Fall 2005 Assignment 7 (140 points), out Monday November 21, due Thursday December 8 Learning to play blackjack In this assignment, you will implement
Hybrid of Evolution and Reinforcement Learning for Othello Players
 Hybrid of Evolution and Reinforcement Learning for Othello Players Kyung-Joong Kim, Heejin Choi and Sung-Bae Cho Dept. of Computer Science, Yonsei University 134 Shinchon-dong, Sudaemoon-ku, Seoul 12-749,
Hybrid of Evolution and Reinforcement Learning for Othello Players Kyung-Joong Kim, Heejin Choi and Sung-Bae Cho Dept. of Computer Science, Yonsei University 134 Shinchon-dong, Sudaemoon-ku, Seoul 12-749,
Foundations of AI. 5. Board Games. Search Strategies for Games, Games with Chance, State of the Art. Wolfram Burgard and Luc De Raedt SA-1
 Foundations of AI 5. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard and Luc De Raedt SA-1 Contents Board Games Minimax Search Alpha-Beta Search Games with
Foundations of AI 5. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard and Luc De Raedt SA-1 Contents Board Games Minimax Search Alpha-Beta Search Games with
Humanization of Computational Learning in Strategy Games
 1 Humanization of Computational Learning in Strategy Games By Benjamin S. Greenberg S.B., C.S. M.I.T., 2015 Submitted to the Department of Electrical Engineering and Computer Science in Partial Fulfillment
1 Humanization of Computational Learning in Strategy Games By Benjamin S. Greenberg S.B., C.S. M.I.T., 2015 Submitted to the Department of Electrical Engineering and Computer Science in Partial Fulfillment
MyPawns OppPawns MyKings OppKings MyThreatened OppThreatened MyWins OppWins Draws
 The Role of Opponent Skill Level in Automated Game Learning Ying Ge and Michael Hash Advisor: Dr. Mark Burge Armstrong Atlantic State University Savannah, Geogia USA 31419-1997 geying@drake.armstrong.edu
The Role of Opponent Skill Level in Automated Game Learning Ying Ge and Michael Hash Advisor: Dr. Mark Burge Armstrong Atlantic State University Savannah, Geogia USA 31419-1997 geying@drake.armstrong.edu
Using Artificial intelligent to solve the game of 2048
 Using Artificial intelligent to solve the game of 2048 Ho Shing Hin (20343288) WONG, Ngo Yin (20355097) Lam Ka Wing (20280151) Abstract The report presents the solver of the game 2048 base on artificial
Using Artificial intelligent to solve the game of 2048 Ho Shing Hin (20343288) WONG, Ngo Yin (20355097) Lam Ka Wing (20280151) Abstract The report presents the solver of the game 2048 base on artificial
Universiteit Leiden Opleiding Informatica
 Universiteit Leiden Opleiding Informatica Predicting the Outcome of the Game Othello Name: Simone Cammel Date: August 31, 2015 1st supervisor: 2nd supervisor: Walter Kosters Jeannette de Graaf BACHELOR
Universiteit Leiden Opleiding Informatica Predicting the Outcome of the Game Othello Name: Simone Cammel Date: August 31, 2015 1st supervisor: 2nd supervisor: Walter Kosters Jeannette de Graaf BACHELOR
School of EECS Washington State University. Artificial Intelligence
 School of EECS Washington State University Artificial Intelligence 1 } Classic AI challenge Easy to represent Difficult to solve } Zero-sum games Total final reward to all players is constant } Perfect
School of EECS Washington State University Artificial Intelligence 1 } Classic AI challenge Easy to represent Difficult to solve } Zero-sum games Total final reward to all players is constant } Perfect
Achieving Desirable Gameplay Objectives by Niched Evolution of Game Parameters
 Achieving Desirable Gameplay Objectives by Niched Evolution of Game Parameters Scott Watson, Andrew Vardy, Wolfgang Banzhaf Department of Computer Science Memorial University of Newfoundland St John s.
Achieving Desirable Gameplay Objectives by Niched Evolution of Game Parameters Scott Watson, Andrew Vardy, Wolfgang Banzhaf Department of Computer Science Memorial University of Newfoundland St John s.
Probability Questions from the Game Pickomino
 Probability Questions from the Game Pickomino Brian Heinold Department of Mathematics and Computer Science Mount St. Mary s University November 5, 2016 1 / 69 a.k.a. Heckmeck am Bratwurmeck Created by
Probability Questions from the Game Pickomino Brian Heinold Department of Mathematics and Computer Science Mount St. Mary s University November 5, 2016 1 / 69 a.k.a. Heckmeck am Bratwurmeck Created by
Set 4: Game-Playing. ICS 271 Fall 2017 Kalev Kask
 Set 4: Game-Playing ICS 271 Fall 2017 Kalev Kask Overview Computer programs that play 2-player games game-playing as search with the complication of an opponent General principles of game-playing and search
Set 4: Game-Playing ICS 271 Fall 2017 Kalev Kask Overview Computer programs that play 2-player games game-playing as search with the complication of an opponent General principles of game-playing and search
CS 4700: Foundations of Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence selman@cs.cornell.edu Module: Adversarial Search R&N: Chapter 5 1 Outline Adversarial Search Optimal decisions Minimax α-β pruning Case study: Deep Blue
CS 4700: Foundations of Artificial Intelligence selman@cs.cornell.edu Module: Adversarial Search R&N: Chapter 5 1 Outline Adversarial Search Optimal decisions Minimax α-β pruning Case study: Deep Blue
Machine Learning Othello Project
 Machine Learning Othello Project Tom Barry The assignment. We have been provided with a genetic programming framework written in Java and an intelligent Othello player( EDGAR ) as well a random player.
Machine Learning Othello Project Tom Barry The assignment. We have been provided with a genetic programming framework written in Java and an intelligent Othello player( EDGAR ) as well a random player.
University of Amsterdam. Encyclopedia of AI project. Tic-Tac-Toe. Authors: Andreas van Cranenburgh Ricus Smid. Supervisor: Maarten van Someren
 University of Amsterdam Encyclopedia of AI project Tic-Tac-Toe Authors: Andreas van Cranenburgh Ricus Smid Supervisor: Maarten van Someren January 27, 2007 Encyclopedia of AI, assignment 5 Tic-tac-toe
University of Amsterdam Encyclopedia of AI project Tic-Tac-Toe Authors: Andreas van Cranenburgh Ricus Smid Supervisor: Maarten van Someren January 27, 2007 Encyclopedia of AI, assignment 5 Tic-tac-toe
42 nd WORLD BG CHAMPIONSHIP Tournament Rules
 42 nd WORLD BG CHAMPIONSHIP Tournament Rules 1. PROPRIETIES 2. REGULATIONS 3. PREPARATION 4. THE GAME 5. DISPUTES 1. PROPRIETIES 1.1 Interpretation These tournament rules cannot and are not meant to cover
42 nd WORLD BG CHAMPIONSHIP Tournament Rules 1. PROPRIETIES 2. REGULATIONS 3. PREPARATION 4. THE GAME 5. DISPUTES 1. PROPRIETIES 1.1 Interpretation These tournament rules cannot and are not meant to cover
Game Playing for a Variant of Mancala Board Game (Pallanguzhi)
") Game Playing for a Variant of Mancala Board Game (Pallanguzhi) Varsha Sankar (SUNet ID: svarsha) 1. INTRODUCTION Game playing is a very interesting area in the field of Artificial Intelligence presently.
Game Playing for a Variant of Mancala Board Game (Pallanguzhi) Varsha Sankar (SUNet ID: svarsha) 1. INTRODUCTION Game playing is a very interesting area in the field of Artificial Intelligence presently.
IMPROVING TOWER DEFENSE GAME AI (DIFFERENTIAL EVOLUTION VS EVOLUTIONARY PROGRAMMING) CHEAH KEEI YUAN
 CHEAH KEEI YUAN") IMPROVING TOWER DEFENSE GAME AI (DIFFERENTIAL EVOLUTION VS EVOLUTIONARY PROGRAMMING) CHEAH KEEI YUAN FACULTY OF COMPUTING AND INFORMATICS UNIVERSITY MALAYSIA SABAH 2014 ABSTRACT The use of Artificial Intelligence
IMPROVING TOWER DEFENSE GAME AI (DIFFERENTIAL EVOLUTION VS EVOLUTIONARY PROGRAMMING) CHEAH KEEI YUAN FACULTY OF COMPUTING AND INFORMATICS UNIVERSITY MALAYSIA SABAH 2014 ABSTRACT The use of Artificial Intelligence
A Study of Machine Learning Methods using the Game of Fox and Geese
 A Study of Machine Learning Methods using the Game of Fox and Geese Kenneth J. Chisholm & Donald Fleming School of Computing, Napier University, 10 Colinton Road, Edinburgh EH10 5DT. Scotland, U.K. k.chisholm@napier.ac.uk
A Study of Machine Learning Methods using the Game of Fox and Geese Kenneth J. Chisholm & Donald Fleming School of Computing, Napier University, 10 Colinton Road, Edinburgh EH10 5DT. Scotland, U.K. k.chisholm@napier.ac.uk
Artificial Intelligence Adversarial Search
 Artificial Intelligence Adversarial Search Adversarial Search Adversarial search problems games They occur in multiagent competitive environments There is an opponent we can t control planning again us!
Artificial Intelligence Adversarial Search Adversarial Search Adversarial search problems games They occur in multiagent competitive environments There is an opponent we can t control planning again us!
Temporal Difference Learning for the Game Tic-Tac-Toe 3D: Applying Structure to Neural Networks
 2015 IEEE Symposium Series on Computational Intelligence Temporal Difference Learning for the Game Tic-Tac-Toe 3D: Applying Structure to Neural Networks Michiel van de Steeg Institute of Artificial Intelligence
2015 IEEE Symposium Series on Computational Intelligence Temporal Difference Learning for the Game Tic-Tac-Toe 3D: Applying Structure to Neural Networks Michiel van de Steeg Institute of Artificial Intelligence