Artificial Intelligence and Games Playing Games
|
|
|
- Austin Brown
- 5 years ago
- Views:
Transcription
1 Artificial Intelligence and Games Playing Games Georgios N. Julian

2 Your readings from gameaibook.org Chapter: 3
3 Reminder: Artificial Intelligence and Games Making computers able to do things which currently only humans can do in games

4 What do humans do with games? Play them Study them Build content for them levels, maps, art, characters, missions Design and develop them Do marketing Make a statement Make money!
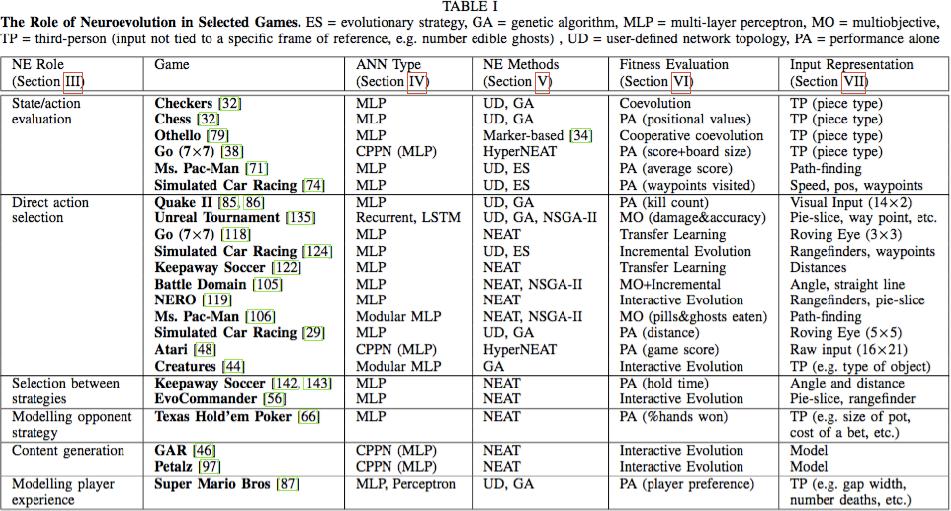
5 Model Players Play Games Game AI Generate Content G. N. Yannakakis and J. Togelius, Artificial Intelligence and Games, Springer Nature, 2018.
6 Model Players Play Games Game AI Generate Content G. N. Yannakakis and J. Togelius, Artificial Intelligence and Games, Springer Nature, 2018.
7 Why use AI to Play Games? Playing to win vs playing for experience For experience: human-like, fun, believable, predictable...? Playing in the player role vs. playing in a non-player role
8 Win Player Motivation Games as AI testbeds, AI that challenges players, Simulation-based testing Examples Board Game AI (TD-Gammon, Chinook, Deep Blue, AlphaGo, Libratus), Jeopardy! (Watson), StarCraft Non-Player Motivation Playing roles that humans would not (want to) play, Game balancing Examples Rubber banding Experience Motivation Simulation-based testing, Game demonstrations Examples Game Turing Tests (2kBot Prize/Mario), Persona Modelling Motivation Believable and human-like agents Examples AI that: acts as an adversary, provides assistance, is emotively expressive, tells a story,
9 Win Player Motivation Games as AI testbeds, AI that challenges players, Simulation-based testing Examples Board Game AI (TD-Gammon, Chinook, Deep Blue, AlphaGo, Libratus), Jeopardy! (Watson), StarCraft Non-Player Motivation Playing roles that humans would not (want to) play, Game balancing Examples Rubber banding Experience Motivation Simulation-based testing, Game demonstrations Examples Game Turing Tests (2kBot Prize/Mario),Persona Modelling Motivation Believable and human-like agents Examples AI that: acts as an adversary, provides assistance, is emotively expressive, tells a story,
10 Win Player Motivation Games as AI testbeds, AI that challenges players, Simulation-based testing Examples Board Game AI (TD-Gammon, Chinook, Deep Blue, AlphaGo, Libratus), Jeopardy! (Watson), StarCraft Non-Player Motivation Playing roles that humans would not (want to) play, Game balancing Examples Rubber banding Experience Motivation Simulation-based testing, Game demonstrations Examples Game Turing Tests (2kBot Prize/Mario),Persona Modelling Motivation Believable and human-like agents Examples AI that: acts as an adversary, provides assistance, is emotively expressive, tells a story,
11 Win Player Motivation Games as AI testbeds, AI that challenges players, Simulation-based testing Examples Board Game AI (TD-Gammon, Chinook, Deep Blue, AlphaGo, Libratus), Jeopardy! (Watson), StarCraft Non-Player Motivation Playing roles that humans would not (want to) play, Game balancing Examples Rubber banding Experience Motivation Simulation-based testing, Game demonstrations Examples Game Turing Tests (2kBot Prize/Mario), Persona Modelling Motivation Believable and human-like agents Examples AI that: acts as an adversary, provides assistance, is emotively expressive, tells a story,
12 Win Player Motivation Games as AI testbeds, AI that challenges players, Simulation-based testing Examples Board Game AI (TD-Gammon, Chinook, Deep Blue, AlphaGo, Libratus), Jeopardy! (Watson), StarCraft Non-Player Motivation Playing roles that humans would not (want to) play, Game balancing Examples Rubber banding Experience Motivation Simulation-based testing, Game demonstrations Examples Game Turing Tests (2kBot Prize/Mario),Persona Modelling Motivation Believable and human-like agents Examples AI that: acts as an adversary, provides assistance, is emotively expressive, tells a story,
13 Some Considerations
14 Game (and AI) Design Considerations When designing AI It is crucial to know the characteristics of the game you are playing and the characteristics of the algorithms you are about to design These collectively determine what type of algorithms can be effective
15 Characteristics of Games Number of Players Type: Adversarial? Cooperative? Both? Action Space and Branching Factor Stochasticity Observability Time Granularity
16 Number of Players Single-player e.g. puzzles and time-trial racing One-and-a-half-player e.g. campaign mode of an FPS with nontrivial NPCs Two-player e.g. Chess, Checkers and Spacewar! Multi-player e.g. League of Legends (Riot Games, 2009), the Mario Kart (Nintendo, ) series and the online modes of most FPS games.
 Non-deterministic (e.g. Ms Pac-Man, StarCraft, )")
17 Stochasticity The degree of randomness in the game Does the game violate the Markov property? Deterministic (e.g. Pac-Man, Go, Atari 2600 games) Non-deterministic (e.g. Ms Pac-Man, StarCraft, )
 Imperfect (hidden) Information (e.")
18 Observability How much does our agent know about the game? Perfect Information (e.g. Zork, Colossal Cave Adventurer) Imperfect (hidden) Information (e.g. Halo, Super Mario Bros)
19 Action Space and Branching Factor How many actions are there available for the player? From two (e.g. Flappy Bird) to many (e.g. StarCraft).
? Turn-based (e.g. Chess) Real-time (e.g. StarCraft)")
20 Time Granularity How many turns (or ticks) until the end (of a session)? Turn-based (e.g. Chess) Real-time (e.g. StarCraft)
21 Imperfect Information Perfect Information Observability Checkers Chess Go Pac-Man Atari 2600 Ms Pac-Man Ludo Monopoly Backgammon Time Granularity Super Mario Bros Halo StarCraft Battleship Scrabble Poker Turn-Based Real-Time Deterministic Non-deterministic Stochasticity

22 Characteristics of Games: Some Examples Chess Two-player adversarial, deterministic, fully observable, bf ~35, ~70 turns Go Two-player adversarial, deterministic, fully observable, bf ~350, ~150 turns Backgammon Two-player adversarial, stochastic, fully observable, bf ~250, ~55 turns
 1 player, deterministic, fully observable, bf 6,")

23 Characteristics of Games: Some Examples Frogger (Atari 2600) 1 player, deterministic, fully observable, bf 6, hundreds of ticks Montezuma's revenge (Atari 2600) 1 player, deterministic, partially observable, bf 6, tens of thousands of ticks
24 Characteristics of Games: Some Examples Halo series 1.5 player, deterministic, partially observable, bf??, tens of thousands of ticks StarCraft 2-4 players, stochastic, partially observable, bf > a million, tens of thousands of ticks
25 Characteristics of AI Algorithm Design Key questions How is the game state represented? Is there a forward model available? Do you have time to train? How many games are you playing?
26 Game State Representation Games differ wither regards to their output Text adventures Text Board games Positions of board pieces Graphical video games Moving graphics and/or sound The same game can be represented in different ways! The representation matters greatly to an algorithm playing the game Example: Representing a racing game First-person view out of the windscreen of the car rendered in 3D Overhead view of the track rendering the track and various cars in 2D. List of positions and velocities of all cars (along with a model of the track) Set of angles and distances to other cars (and track edges)
27 Forward Model A forward model is a simulator of the game Given s and α s Is the model fast? Is it accurate? Tree search is applicable only when a forward model is available!
28 What if We don t have a model (or a bad or slow model), but we have training time, what do we do? Train function approximators to select actions or evaluate states For example, deep neural networks using gradient descent or evolution
29 Life without a forward model Sad! We could learn a direct mapping from state to action Or some kind of forward model Even a simple forward model could be useful for shallow searches, if combined with a state value function
 over time i.e., machine learning")
30 Training Time AI distinction with regards to time: AI that decides what to do by examining possible actions and future states e.g. tree search AI that learns a model (such as a policy) over time i.e., machine learning
31 Number of Games Will AI play one game? Specific game playing Will AI play more than one games? General game-playing
32 Problem: Overfitting!

33 Solution: General Game-playing Can we construct AI that can play many games?
34 How Can AI Play Games? Different methods are suitable, depending on: The characteristics of the game How you apply AI to the game Why you want to make a game-playing There is no single best method (duh!) Often, hybrid (chimeric) architectures do best


35 Surely, deep RL is the best algorithm for playing games

36

37 How Would you Play Super Mario Bros?
38 How Can AI Play Games: An Overview Planning-Based requires forward model Uninformed search (e.g. best-first, breadth-first) Informed search (e.g. A*) Evolutionary algorithms Reinforcement Learning requires training time TD-learning / approximate dynamic programming Evolutionary algorithms Supervised Learning requires play traces Neural nets, k-nn, SVMs, Decision Trees, etc. Random requires nothing Behaviour authoring requires human ingenuity and time
39 Life with a model
40 How Can AI Play Games Planning-Based requires forward model Uninformed search (e.g. best-first, breadth-first) Informed search (e.g. A*) Adversarial search (e.g. Minimax, MCTS) Evolutionary algorithms But path-planning does not require a forward model Search in physical space
41 A Different Viewpoint Planning-Based Classic Tree Search (e.g. best-first, breadth-first, A*, Minimax) Stochastic Tree Search (e.g. MCTS) Evolutionary Planning (e.g. rolling horizon) Planning with Symbolic Representations (e.g. STRIPS)
42 Classic Tree Search
43 Informed Search (A*)
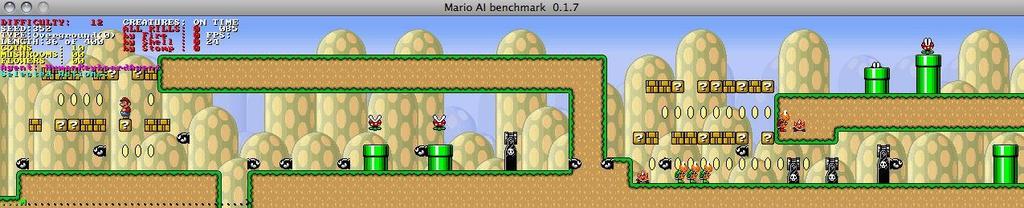
44 A* in Mario: Current Position Goal: right border of screen current node
45 A* in Mario: Child Nodes jump right, jump left, jump, speed current node right, speed
46 A* in Mario: Best First current node right, speed
47 A* in Mario: Evaluate Node current node right, speed

48 A* in Mario: Backtrack right, jump, speed current node right, speed
49 A* in Mario: Next State current node
50 S current node A* in Mario: Create Child Nodes
51 A* in Mario: Best first current node
52 So why was A* successful?
53 Limitations of A*
54 Stochastic Tree Search

55 Monte Carlo Tree Search The best new tree search algorithm you hopefully already know about When invented, revolutionized computer Go
 Default (simulation) policy: random playout until")
56 Monte Carlo Tree Search Tree policy: choose which node to expand (not necessarily leaf of tree) Default (simulation) policy: random playout until end of game
57 UCB1 Criterion MCTS as a multi-armed bandit problem Every time a node (action) is to be selected within the existing tree, the choice may be modelled as an independent multi-armed bandit problem. A child node j is selected to maximise: Constant positive (exploration) parameter Times parent node has been visited Times child j has been visited
58 MCTS Goes Real-Time Limited roll-out budget Heuristic knowledge becomes important Action space is fine-grained Take macro-actions otherwise planning will be very short-term Maybe no terminal node in sight Use a heuristic Tune simulation depth Next state function may be expensive Consider making a simpler abstraction
59 MCTS for Mario Jacobsen, Greve, Togelius: Monte Mario: Platforming with MCTS. GECCO 2014.
60 MCTS Modifications Modification Mean Score Avg. T Left Vanilla MCTS (Avg.) Vanilla MCTS (Max) 2098*** 153 Mixmax (0.125) Macro Actions Partial Expansion Roulette Wheel Selection Hole Detection 4196** 134 Limited Actions 4141* 137 (Robin Baumgarten s A*) 4289*** 169
61 A* Still Rules Several MCTS configurations get the same score as A* It seems that A* is playing essentially optimally But what if we modify the problem?
62 Making a Mess of Mario Introduce action noise: 20% of actions are replaced with a random action Destroys A* MCTS handles this much better AI Mean Score MCTS (X-PRHL) 1770 A* agent 1342**
63 MCTS in Commercial Games

 Large search space Grows exponentially with number of resources")
64 Example: Total War Rome II Task Management System Resource Allocation (match resources to tasks) Typically many tasks.. but few resources Large search space, little time Resource Coordination (determine the best set of actions given resources & their targets) Large search space Grows exponentially with number of resources Expensive pathfinding queries MCTS-based planner to achieve constant worst-case performance
65 Evolutionary Planning
66 Evolutionary Planning Basic idea: Don t search for a sequence of actions starting from an initial point Optimize the whole action sequence instead! Search the space of complete action sequences for those that have maximum utility. Evaluate the utility of a given action sequence by taking all the actions in the sequence in simulation, and observing the value of the state reached after taking all those actions.
67 Evolutionary Planning Any optimization algorithm is applicable Evolutionary algorithms are popular so far; e.g. Rolling horizon evolution in TSP Competitive agents in General Video Game AI Competition Online evolution outperforms MCTS in Hero Academy Evolutionary planning performs better than varieties of tree search in simple StarCraft scenarios A method at birth still a lot to come!
68 Planning with Symbolic Representations

69 Planning with Symbolic Representations Planning on the level of in-game actions requires a fast forward model However one can plan in an abstract representation of the game s state space. Typically, a language based on first-order logic represents events, states and actions, and tree search is applied to find paths from current state to end state. Example: STRIPS-based representation used in Shakey, the world s first digital mobile robot Game example: F.E.A.R. (Sierra Entertainment, 2005) agent planners by Jeff Orkin
70 Life without a model
71 How Can AI Play Games? Reinforcement learning (requires training time) TD-learning/approximate dynamic programming Deep RL/Deep Q-N, Evolutionary algorithms

72 RL Problem
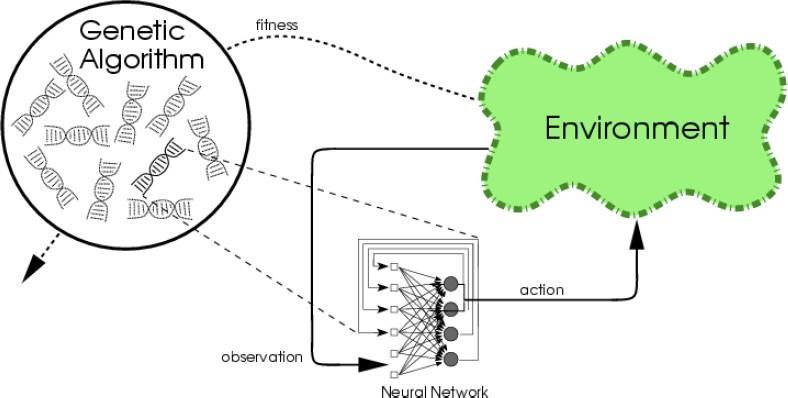
73 (Neuro)Evolution as a RL Problem
74 Evolutionary Algorithms Stochastic global optimization algorithms Inspired by Darwinian natural evolution Extremely domain-general, widely used in practice
75 Simple μ+λ Evolutionary Strategy Create a population of μ+λ individuals At each generation Evaluate all individuals in the population Sort by fitness Remove the worst λ individuals Replace with mutated copies of the μ best individuals
76 Evolving ANNs Ms Pac-Man Example 1 2 w0 1 w0 2 w1 3 w1 4 w1 5 w0 n w0 1 w0 2 w1 3 w1 4 w1 5 w0 n P w0 1 w0 2 w1 3 w1 4 w1 5 w0 n Fitness value f 2
: Neuroevolution in games. TCIAIG.")
77 Neuroevolution has been used broadly Sebastian Risi and Julian Togelius (2016): Neuroevolution in games. TCIAIG.
78



79 Procedural Personas Given utilities (rewards) show me believable gameplay Useful for human-standard game testing RL MCTS Neuroevolution Inverse RL Liapis, Antonios, Christoffer Holmgård, Georgios N. Yannakakis, and Julian Togelius. "Procedural personas as critics for dungeon generation." In European Conference on the Applications of Evolutionary Computation, pp Springer, Cham, 2015.
80 Q-learning Off-policy reinforcement learning method in the temporal difference family Learn a mapping from (state, action) to value Every time you get a reward (e.g. win, lose, score), propagate this back through all states Use the max value from each state
81 Agent consists of two components: 1. Value-function (Q-function) 2. Policy
82 Representing Q(s,α) with ANNs s t a t Q(s t,a t )
83 Training the ANN Q-function Training is performed on-line using the Q-values from the agent s state transitions For Q-learning: input: s t, a t maxq(s t 1,a) target: r t a

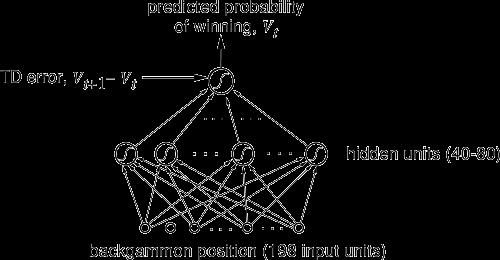
84 TD-Gammon (Teusaro, 1992)
85 Deep Q-learning Use Q-learning with deep neural nets In practice, several additions useful/necessary Experience replay: chop up the training data so as to remove correlations between successive states Niels Justesen, Philip Bontrager, Sebastian Risi, Julian Togelius: Deep Learning for Video Game Playing. ArXiv.

86 Deep Q Network (DQN) Ms Pac-Man Example Reward Convolution Rectifier Rectifier Action


87 Arcade Learning Environment
88 Arcade Learning Environment Based on an Atari 2600 emulator Atari: very successful but very simple 128 byte memory, no random number generator A couple of dozen games available (hundreds made for the Atari) Agents are fed the raw screen data (pixels) Most successful agents based on deep learning

89

90


91 Convolution Convolution Fully connected Fully connected No input
92 Video Pinball Boxing Breakout Star Gunner Robotank Atlantis Crazy Climber Gopher Demon Attack Name This Game Krull Assault Road Runner Kangaroo James Bond Tennis Pong Space Invaders Beam Rider Tutankham Kung-Fu Master Freeway Time Pilot Enduro Fishing Derby Up and Down Ice Hockey Q*bert H.E.R.O. Asterix Battle Zone Wizard of Wor Chopper Command Centipede Bank Heist River Raid Zaxxon Amidar Alien Venture Seaquest Double Dunk Bowling Ms. Pac-Man Asteroids Frostbite Gravitar Private Eye Montezuma's Revenge At human-level or above Below human-level DQN Best linear learner Results: not bad! but not general ,000 4,500%

93 Justesen et al. (2017). Deep learning for video game playing. arxiv preprint arxiv:
94 How Can AI Play Games? Supervised learning (requires play traces to learn from) Neural networks, k-nearest neighbours, SVMs etc.
95 Which Games Can AI Play?


96 Which Games Can AI Play? Board games Adversarial planning, tree search Card games Reinforcement learning, tree search
97 Which Games Can AI Play? Classic arcade games Pac-Man and the like: Tree search, RL Super Mario Bros: Planning, RL, Supervised learning Arcade learning environment: RL General Video Game AI: Tree search, RL


98 Which Games Can AI Play? Strategy games Different approaches might work best for the different tasks (e.g. strategy, tactics, micro management in StarCraft)

99 Which Games Can AI Play? Racing games Supervised learning, RL

100 Which Games Can AI Play? Shooters UT2004: Neuroevolution, imitation learning Doom: (Deep) RL in VizDoom

101 Which Games Can AI Play? Serious games Ad-hoc designed believable agent architectures, expressive agents, conversational agents

102 Which Games Can AI Play? Interactive fiction AI as NLP, AI for virtual cinematography, Deep learning (LSTM, Deep Q networks) for text processing and generation
103 Model Players Play Games Game AI Generate Content G. N. Yannakakis and J. Togelius, Artificial Intelligence and Games, Springer, 2018.
104 Thank you! gameaibook.org
Analysis of Vanilla Rolling Horizon Evolution Parameters in General Video Game Playing
 Analysis of Vanilla Rolling Horizon Evolution Parameters in General Video Game Playing Raluca D. Gaina, Jialin Liu, Simon M. Lucas, Diego Perez-Liebana Introduction One of the most promising techniques
Analysis of Vanilla Rolling Horizon Evolution Parameters in General Video Game Playing Raluca D. Gaina, Jialin Liu, Simon M. Lucas, Diego Perez-Liebana Introduction One of the most promising techniques
Population Initialization Techniques for RHEA in GVGP
 Population Initialization Techniques for RHEA in GVGP Raluca D. Gaina, Simon M. Lucas, Diego Perez-Liebana Introduction Rolling Horizon Evolutionary Algorithms (RHEA) show promise in General Video Game
Population Initialization Techniques for RHEA in GVGP Raluca D. Gaina, Simon M. Lucas, Diego Perez-Liebana Introduction Rolling Horizon Evolutionary Algorithms (RHEA) show promise in General Video Game
Video Games As Environments For Learning And Planning: What s Next? Julian Togelius
 Video Games As Environments For Learning And Planning: What s Next? Julian Togelius A very selective history Othello Backgammon Checkers Chess Go Poker Super/Infinite Mario Bros Ms. Pac-Man Crappy Atari
Video Games As Environments For Learning And Planning: What s Next? Julian Togelius A very selective history Othello Backgammon Checkers Chess Go Poker Super/Infinite Mario Bros Ms. Pac-Man Crappy Atari
Monte Carlo Tree Search
 Monte Carlo Tree Search 1 By the end, you will know Why we use Monte Carlo Search Trees The pros and cons of MCTS How it is applied to Super Mario Brothers and Alpha Go 2 Outline I. Pre-MCTS Algorithms
Monte Carlo Tree Search 1 By the end, you will know Why we use Monte Carlo Search Trees The pros and cons of MCTS How it is applied to Super Mario Brothers and Alpha Go 2 Outline I. Pre-MCTS Algorithms
CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions
 CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions Slides by Svetlana Lazebnik, 9/2016 Modified by Mark Hasegawa Johnson, 9/2017 Types of game environments Perfect
CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions Slides by Svetlana Lazebnik, 9/2016 Modified by Mark Hasegawa Johnson, 9/2017 Types of game environments Perfect
AI in Computer Games. AI in Computer Games. Goals. Game A(I?) History Game categories
 History Game categories") AI in Computer Games why, where and how AI in Computer Games Goals Game categories History Common issues and methods Issues in various game categories Goals Games are entertainment! Important that things
AI in Computer Games why, where and how AI in Computer Games Goals Game categories History Common issues and methods Issues in various game categories Goals Games are entertainment! Important that things
CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH. Santiago Ontañón
 CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH Santiago Ontañón so367@drexel.edu Recall: Adversarial Search Idea: When there is only one agent in the world, we can solve problems using DFS, BFS, ID,
CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH Santiago Ontañón so367@drexel.edu Recall: Adversarial Search Idea: When there is only one agent in the world, we can solve problems using DFS, BFS, ID,
Set 4: Game-Playing. ICS 271 Fall 2017 Kalev Kask
 Set 4: Game-Playing ICS 271 Fall 2017 Kalev Kask Overview Computer programs that play 2-player games game-playing as search with the complication of an opponent General principles of game-playing and search
Set 4: Game-Playing ICS 271 Fall 2017 Kalev Kask Overview Computer programs that play 2-player games game-playing as search with the complication of an opponent General principles of game-playing and search
Poker AI: Equilibrium, Online Resolving, Deep Learning and Reinforcement Learning
 Poker AI: Equilibrium, Online Resolving, Deep Learning and Reinforcement Learning Nikolai Yakovenko NVidia ADLR Group -- Santa Clara CA Columbia University Deep Learning Seminar April 2017 Poker is a Turn-Based
Poker AI: Equilibrium, Online Resolving, Deep Learning and Reinforcement Learning Nikolai Yakovenko NVidia ADLR Group -- Santa Clara CA Columbia University Deep Learning Seminar April 2017 Poker is a Turn-Based
Game-playing: DeepBlue and AlphaGo
 Game-playing: DeepBlue and AlphaGo Brief history of gameplaying frontiers 1990s: Othello world champions refuse to play computers 1994: Chinook defeats Checkers world champion 1997: DeepBlue defeats world
Game-playing: DeepBlue and AlphaGo Brief history of gameplaying frontiers 1990s: Othello world champions refuse to play computers 1994: Chinook defeats Checkers world champion 1997: DeepBlue defeats world
DeepMind Self-Learning Atari Agent
 DeepMind Self-Learning Atari Agent Human-level control through deep reinforcement learning Nature Vol 518, Feb 26, 2015 The Deep Mind of Demis Hassabis Backchannel / Medium.com interview with David Levy
DeepMind Self-Learning Atari Agent Human-level control through deep reinforcement learning Nature Vol 518, Feb 26, 2015 The Deep Mind of Demis Hassabis Backchannel / Medium.com interview with David Levy
Game AI Challenges: Past, Present, and Future
 Game AI Challenges: Past, Present, and Future Professor Michael Buro Computing Science, University of Alberta, Edmonton, Canada www.skatgame.net/cpcc2018.pdf 1/ 35 AI / ML Group @ University of Alberta
Game AI Challenges: Past, Present, and Future Professor Michael Buro Computing Science, University of Alberta, Edmonton, Canada www.skatgame.net/cpcc2018.pdf 1/ 35 AI / ML Group @ University of Alberta
Who am I? AI in Computer Games. Goals. AI in Computer Games. History Game A(I?)
") Who am I? AI in Computer Games why, where and how Lecturer at Uppsala University, Dept. of information technology AI, machine learning and natural computation Gamer since 1980 Olle Gällmo AI in Computer
Who am I? AI in Computer Games why, where and how Lecturer at Uppsala University, Dept. of information technology AI, machine learning and natural computation Gamer since 1980 Olle Gällmo AI in Computer
Decision Making in Multiplayer Environments Application in Backgammon Variants
 Decision Making in Multiplayer Environments Application in Backgammon Variants PhD Thesis by Nikolaos Papahristou AI researcher Department of Applied Informatics Thessaloniki, Greece Contributions Expert
Decision Making in Multiplayer Environments Application in Backgammon Variants PhD Thesis by Nikolaos Papahristou AI researcher Department of Applied Informatics Thessaloniki, Greece Contributions Expert
Adversarial Search Lecture 7
 Lecture 7 How can we use search to plan ahead when other agents are planning against us? 1 Agenda Games: context, history Searching via Minimax Scaling α β pruning Depth-limiting Evaluation functions Handling
Lecture 7 How can we use search to plan ahead when other agents are planning against us? 1 Agenda Games: context, history Searching via Minimax Scaling α β pruning Depth-limiting Evaluation functions Handling
CS325 Artificial Intelligence Ch. 5, Games!
 CS325 Artificial Intelligence Ch. 5, Games! Cengiz Günay, Emory Univ. vs. Spring 2013 Günay Ch. 5, Games! Spring 2013 1 / 19 AI in Games A lot of work is done on it. Why? Günay Ch. 5, Games! Spring 2013
CS325 Artificial Intelligence Ch. 5, Games! Cengiz Günay, Emory Univ. vs. Spring 2013 Günay Ch. 5, Games! Spring 2013 1 / 19 AI in Games A lot of work is done on it. Why? Günay Ch. 5, Games! Spring 2013
CSC321 Lecture 23: Go
 CSC321 Lecture 23: Go Roger Grosse Roger Grosse CSC321 Lecture 23: Go 1 / 21 Final Exam Friday, April 20, 9am-noon Last names A Y: Clara Benson Building (BN) 2N Last names Z: Clara Benson Building (BN)
CSC321 Lecture 23: Go Roger Grosse Roger Grosse CSC321 Lecture 23: Go 1 / 21 Final Exam Friday, April 20, 9am-noon Last names A Y: Clara Benson Building (BN) 2N Last names Z: Clara Benson Building (BN)
Monte Carlo Tree Search and AlphaGo. Suraj Nair, Peter Kundzicz, Kevin An, Vansh Kumar
 Monte Carlo Tree Search and AlphaGo Suraj Nair, Peter Kundzicz, Kevin An, Vansh Kumar Zero-Sum Games and AI A player s utility gain or loss is exactly balanced by the combined gain or loss of opponents:
Monte Carlo Tree Search and AlphaGo Suraj Nair, Peter Kundzicz, Kevin An, Vansh Kumar Zero-Sum Games and AI A player s utility gain or loss is exactly balanced by the combined gain or loss of opponents:
Playing CHIP-8 Games with Reinforcement Learning
 Playing CHIP-8 Games with Reinforcement Learning Niven Achenjang, Patrick DeMichele, Sam Rogers Stanford University Abstract We begin with some background in the history of CHIP-8 games and the use of
Playing CHIP-8 Games with Reinforcement Learning Niven Achenjang, Patrick DeMichele, Sam Rogers Stanford University Abstract We begin with some background in the history of CHIP-8 games and the use of
46.1 Introduction. Foundations of Artificial Intelligence Introduction MCTS in AlphaGo Neural Networks. 46.
 Foundations of Artificial Intelligence May 30, 2016 46. AlphaGo and Outlook Foundations of Artificial Intelligence 46. AlphaGo and Outlook Thomas Keller Universität Basel May 30, 2016 46.1 Introduction
Foundations of Artificial Intelligence May 30, 2016 46. AlphaGo and Outlook Foundations of Artificial Intelligence 46. AlphaGo and Outlook Thomas Keller Universität Basel May 30, 2016 46.1 Introduction
Programming Project 1: Pacman (Due )
") Programming Project 1: Pacman (Due 8.2.18) Registration to the exams 521495A: Artificial Intelligence Adversarial Search (Min-Max) Lectured by Abdenour Hadid Adjunct Professor, CMVS, University of Oulu
Programming Project 1: Pacman (Due 8.2.18) Registration to the exams 521495A: Artificial Intelligence Adversarial Search (Min-Max) Lectured by Abdenour Hadid Adjunct Professor, CMVS, University of Oulu
Outline. Game Playing. Game Problems. Game Problems. Types of games Playing a perfect game. Playing an imperfect game
 Outline Game Playing ECE457 Applied Artificial Intelligence Fall 2007 Lecture #5 Types of games Playing a perfect game Minimax search Alpha-beta pruning Playing an imperfect game Real-time Imperfect information
Outline Game Playing ECE457 Applied Artificial Intelligence Fall 2007 Lecture #5 Types of games Playing a perfect game Minimax search Alpha-beta pruning Playing an imperfect game Real-time Imperfect information
Rolling Horizon Evolution Enhancements in General Video Game Playing
 Rolling Horizon Evolution Enhancements in General Video Game Playing Raluca D. Gaina University of Essex Colchester, UK Email: rdgain@essex.ac.uk Simon M. Lucas University of Essex Colchester, UK Email:
Rolling Horizon Evolution Enhancements in General Video Game Playing Raluca D. Gaina University of Essex Colchester, UK Email: rdgain@essex.ac.uk Simon M. Lucas University of Essex Colchester, UK Email:
Evolutionary Computation for Creativity and Intelligence. By Darwin Johnson, Alice Quintanilla, and Isabel Tweraser
 Evolutionary Computation for Creativity and Intelligence By Darwin Johnson, Alice Quintanilla, and Isabel Tweraser Introduction to NEAT Stands for NeuroEvolution of Augmenting Topologies (NEAT) Evolves
Evolutionary Computation for Creativity and Intelligence By Darwin Johnson, Alice Quintanilla, and Isabel Tweraser Introduction to NEAT Stands for NeuroEvolution of Augmenting Topologies (NEAT) Evolves
6. Games. COMP9414/ 9814/ 3411: Artificial Intelligence. Outline. Mechanical Turk. Origins. origins. motivation. minimax search
 COMP9414/9814/3411 16s1 Games 1 COMP9414/ 9814/ 3411: Artificial Intelligence 6. Games Outline origins motivation Russell & Norvig, Chapter 5. minimax search resource limits and heuristic evaluation α-β
COMP9414/9814/3411 16s1 Games 1 COMP9414/ 9814/ 3411: Artificial Intelligence 6. Games Outline origins motivation Russell & Norvig, Chapter 5. minimax search resource limits and heuristic evaluation α-β
CS 440 / ECE 448 Introduction to Artificial Intelligence Spring 2010 Lecture #5
 CS 440 / ECE 448 Introduction to Artificial Intelligence Spring 2010 Lecture #5 Instructor: Eyal Amir Grad TAs: Wen Pu, Yonatan Bisk Undergrad TAs: Sam Johnson, Nikhil Johri Topics Game playing Game trees
CS 440 / ECE 448 Introduction to Artificial Intelligence Spring 2010 Lecture #5 Instructor: Eyal Amir Grad TAs: Wen Pu, Yonatan Bisk Undergrad TAs: Sam Johnson, Nikhil Johri Topics Game playing Game trees
Artificial Intelligence
 Artificial Intelligence CS482, CS682, MW 1 2:15, SEM 201, MS 227 Prerequisites: 302, 365 Instructor: Sushil Louis, sushil@cse.unr.edu, http://www.cse.unr.edu/~sushil Games and game trees Multi-agent systems
Artificial Intelligence CS482, CS682, MW 1 2:15, SEM 201, MS 227 Prerequisites: 302, 365 Instructor: Sushil Louis, sushil@cse.unr.edu, http://www.cse.unr.edu/~sushil Games and game trees Multi-agent systems
Adversarial Search. CS 486/686: Introduction to Artificial Intelligence
 Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 AccessAbility Services Volunteer Notetaker Required Interested? Complete an online application using your WATIAM: https://york.accessiblelearning.com/uwaterloo/
Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 AccessAbility Services Volunteer Notetaker Required Interested? Complete an online application using your WATIAM: https://york.accessiblelearning.com/uwaterloo/
Adversarial Search. CS 486/686: Introduction to Artificial Intelligence
 Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 Introduction So far we have only been concerned with a single agent Today, we introduce an adversary! 2 Outline Games Minimax search
Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 Introduction So far we have only been concerned with a single agent Today, we introduce an adversary! 2 Outline Games Minimax search
How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997)
") How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997) Alan Fern School of Electrical Engineering and Computer Science Oregon State University Deep Mind s vs. Lee Sedol (2016) Watson vs. Ken
How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997) Alan Fern School of Electrical Engineering and Computer Science Oregon State University Deep Mind s vs. Lee Sedol (2016) Watson vs. Ken
Artificial Intelligence for Games
 Artificial Intelligence for Games CSC404: Video Game Design Elias Adum Let s talk about AI Artificial Intelligence AI is the field of creating intelligent behaviour in machines. Intelligence understood
Artificial Intelligence for Games CSC404: Video Game Design Elias Adum Let s talk about AI Artificial Intelligence AI is the field of creating intelligent behaviour in machines. Intelligence understood
Success Stories of Deep RL. David Silver
 Success Stories of Deep RL David Silver Reinforcement Learning (RL) RL is a general-purpose framework for decision-making An agent selects actions Its actions influence its future observations Success
Success Stories of Deep RL David Silver Reinforcement Learning (RL) RL is a general-purpose framework for decision-making An agent selects actions Its actions influence its future observations Success
Game-Playing & Adversarial Search
 Game-Playing & Adversarial Search This lecture topic: Game-Playing & Adversarial Search (two lectures) Chapter 5.1-5.5 Next lecture topic: Constraint Satisfaction Problems (two lectures) Chapter 6.1-6.4,
Game-Playing & Adversarial Search This lecture topic: Game-Playing & Adversarial Search (two lectures) Chapter 5.1-5.5 Next lecture topic: Constraint Satisfaction Problems (two lectures) Chapter 6.1-6.4,
Adversarial Search. Soleymani. Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5
 Adversarial Search CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2017 Soleymani Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5 Outline Game
Adversarial Search CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2017 Soleymani Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5 Outline Game
School of EECS Washington State University. Artificial Intelligence
 School of EECS Washington State University Artificial Intelligence 1 } Classic AI challenge Easy to represent Difficult to solve } Zero-sum games Total final reward to all players is constant } Perfect
School of EECS Washington State University Artificial Intelligence 1 } Classic AI challenge Easy to represent Difficult to solve } Zero-sum games Total final reward to all players is constant } Perfect
Games and Adversarial Search
 1 Games and Adversarial Search BBM 405 Fundamentals of Artificial Intelligence Pinar Duygulu Hacettepe University Slides are mostly adapted from AIMA, MIT Open Courseware and Svetlana Lazebnik (UIUC) Spring
1 Games and Adversarial Search BBM 405 Fundamentals of Artificial Intelligence Pinar Duygulu Hacettepe University Slides are mostly adapted from AIMA, MIT Open Courseware and Svetlana Lazebnik (UIUC) Spring
Artificial Intelligence
 Artificial Intelligence CS482, CS682, MW 1 2:15, SEM 201, MS 227 Prerequisites: 302, 365 Instructor: Sushil Louis, sushil@cse.unr.edu, http://www.cse.unr.edu/~sushil Non-classical search - Path does not
Artificial Intelligence CS482, CS682, MW 1 2:15, SEM 201, MS 227 Prerequisites: 302, 365 Instructor: Sushil Louis, sushil@cse.unr.edu, http://www.cse.unr.edu/~sushil Non-classical search - Path does not
Learning from Hints: AI for Playing Threes
 Learning from Hints: AI for Playing Threes Hao Sheng (haosheng), Chen Guo (cguo2) December 17, 2016 1 Introduction The highly addictive stochastic puzzle game Threes by Sirvo LLC. is Apple Game of the
Learning from Hints: AI for Playing Threes Hao Sheng (haosheng), Chen Guo (cguo2) December 17, 2016 1 Introduction The highly addictive stochastic puzzle game Threes by Sirvo LLC. is Apple Game of the
CS 387: GAME AI BOARD GAMES. 5/24/2016 Instructor: Santiago Ontañón
 CS 387: GAME AI BOARD GAMES 5/24/2016 Instructor: Santiago Ontañón santi@cs.drexel.edu Class website: https://www.cs.drexel.edu/~santi/teaching/2016/cs387/intro.html Reminders Check BBVista site for the
CS 387: GAME AI BOARD GAMES 5/24/2016 Instructor: Santiago Ontañón santi@cs.drexel.edu Class website: https://www.cs.drexel.edu/~santi/teaching/2016/cs387/intro.html Reminders Check BBVista site for the
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Adversarial Search Instructor: Stuart Russell University of California, Berkeley Game Playing State-of-the-Art Checkers: 1950: First computer player. 1959: Samuel s self-taught
CS 188: Artificial Intelligence Adversarial Search Instructor: Stuart Russell University of California, Berkeley Game Playing State-of-the-Art Checkers: 1950: First computer player. 1959: Samuel s self-taught
Reinforcement Learning in Games Autonomous Learning Systems Seminar
 Reinforcement Learning in Games Autonomous Learning Systems Seminar Matthias Zöllner Intelligent Autonomous Systems TU-Darmstadt zoellner@rbg.informatik.tu-darmstadt.de Betreuer: Gerhard Neumann Abstract
Reinforcement Learning in Games Autonomous Learning Systems Seminar Matthias Zöllner Intelligent Autonomous Systems TU-Darmstadt zoellner@rbg.informatik.tu-darmstadt.de Betreuer: Gerhard Neumann Abstract
CS 380: ARTIFICIAL INTELLIGENCE ADVERSARIAL SEARCH. Santiago Ontañón
 CS 380: ARTIFICIAL INTELLIGENCE ADVERSARIAL SEARCH Santiago Ontañón so367@drexel.edu Recall: Problem Solving Idea: represent the problem we want to solve as: State space Actions Goal check Cost function
CS 380: ARTIFICIAL INTELLIGENCE ADVERSARIAL SEARCH Santiago Ontañón so367@drexel.edu Recall: Problem Solving Idea: represent the problem we want to solve as: State space Actions Goal check Cost function
Google DeepMind s AlphaGo vs. world Go champion Lee Sedol
 Google DeepMind s AlphaGo vs. world Go champion Lee Sedol Review of Nature paper: Mastering the game of Go with Deep Neural Networks & Tree Search Tapani Raiko Thanks to Antti Tarvainen for some slides
Google DeepMind s AlphaGo vs. world Go champion Lee Sedol Review of Nature paper: Mastering the game of Go with Deep Neural Networks & Tree Search Tapani Raiko Thanks to Antti Tarvainen for some slides
DIT411/TIN175, Artificial Intelligence. Peter Ljunglöf. 2 February, 2018
 DIT411/TIN175, Artificial Intelligence Chapters 4 5: Non-classical and adversarial search CHAPTERS 4 5: NON-CLASSICAL AND ADVERSARIAL SEARCH DIT411/TIN175, Artificial Intelligence Peter Ljunglöf 2 February,
DIT411/TIN175, Artificial Intelligence Chapters 4 5: Non-classical and adversarial search CHAPTERS 4 5: NON-CLASSICAL AND ADVERSARIAL SEARCH DIT411/TIN175, Artificial Intelligence Peter Ljunglöf 2 February,
Adversarial Search and Game Playing
 Games Adversarial Search and Game Playing Russell and Norvig, 3 rd edition, Ch. 5 Games: multi-agent environment q What do other agents do and how do they affect our success? q Cooperative vs. competitive
Games Adversarial Search and Game Playing Russell and Norvig, 3 rd edition, Ch. 5 Games: multi-agent environment q What do other agents do and how do they affect our success? q Cooperative vs. competitive
TTIC 31230, Fundamentals of Deep Learning David McAllester, April AlphaZero
 TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 AlphaZero 1 AlphaGo Fan (October 2015) AlphaGo Defeats Fan Hui, European Go Champion. 2 AlphaGo Lee (March 2016) 3 AlphaGo Zero vs.
TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 AlphaZero 1 AlphaGo Fan (October 2015) AlphaGo Defeats Fan Hui, European Go Champion. 2 AlphaGo Lee (March 2016) 3 AlphaGo Zero vs.
CS 387/680: GAME AI BOARD GAMES
 CS 387/680: GAME AI BOARD GAMES 6/2/2014 Instructor: Santiago Ontañón santi@cs.drexel.edu TA: Alberto Uriarte office hours: Tuesday 4-6pm, Cyber Learning Center Class website: https://www.cs.drexel.edu/~santi/teaching/2014/cs387-680/intro.html
CS 387/680: GAME AI BOARD GAMES 6/2/2014 Instructor: Santiago Ontañón santi@cs.drexel.edu TA: Alberto Uriarte office hours: Tuesday 4-6pm, Cyber Learning Center Class website: https://www.cs.drexel.edu/~santi/teaching/2014/cs387-680/intro.html
TD-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play
 NOTE Communicated by Richard Sutton TD-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play Gerald Tesauro IBM Thomas 1. Watson Research Center, I? 0. Box 704, Yorktozon Heights, NY 10598
NOTE Communicated by Richard Sutton TD-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play Gerald Tesauro IBM Thomas 1. Watson Research Center, I? 0. Box 704, Yorktozon Heights, NY 10598
Adversarial Reasoning: Sampling-Based Search with the UCT algorithm. Joint work with Raghuram Ramanujan and Ashish Sabharwal
 Adversarial Reasoning: Sampling-Based Search with the UCT algorithm Joint work with Raghuram Ramanujan and Ashish Sabharwal Upper Confidence bounds for Trees (UCT) n The UCT algorithm (Kocsis and Szepesvari,
Adversarial Reasoning: Sampling-Based Search with the UCT algorithm Joint work with Raghuram Ramanujan and Ashish Sabharwal Upper Confidence bounds for Trees (UCT) n The UCT algorithm (Kocsis and Szepesvari,
TD-Leaf(λ) Giraffe: Using Deep Reinforcement Learning to Play Chess. Stefan Lüttgen
 Giraffe: Using Deep Reinforcement Learning to Play Chess. Stefan Lüttgen") TD-Leaf(λ) Giraffe: Using Deep Reinforcement Learning to Play Chess Stefan Lüttgen Motivation Learn to play chess Computer approach different than human one Humans search more selective: Kasparov (3-5
TD-Leaf(λ) Giraffe: Using Deep Reinforcement Learning to Play Chess Stefan Lüttgen Motivation Learn to play chess Computer approach different than human one Humans search more selective: Kasparov (3-5
Creating an Agent of Doom: A Visual Reinforcement Learning Approach
 Creating an Agent of Doom: A Visual Reinforcement Learning Approach Michael Lowney Department of Electrical Engineering Stanford University mlowney@stanford.edu Robert Mahieu Department of Electrical Engineering
Creating an Agent of Doom: A Visual Reinforcement Learning Approach Michael Lowney Department of Electrical Engineering Stanford University mlowney@stanford.edu Robert Mahieu Department of Electrical Engineering
These are the slides accompanying the book Artificial Intelligence and Games through the gameaibook.org website
 These are the slides accompanying the book Artificial Intelligence and Games through the gameaibook.org website 1 Some reasons why a course on game AI is time-relevant and important 2 Some potential learning
These are the slides accompanying the book Artificial Intelligence and Games through the gameaibook.org website 1 Some reasons why a course on game AI is time-relevant and important 2 Some potential learning
Learning to play Dominoes
 Learning to play Dominoes Ivan de Jesus P. Pinto 1, Mateus R. Pereira 1, Luciano Reis Coutinho 1 1 Departamento de Informática Universidade Federal do Maranhão São Luís,MA Brazil navi1921@gmail.com, mateus.rp.slz@gmail.com,
Learning to play Dominoes Ivan de Jesus P. Pinto 1, Mateus R. Pereira 1, Luciano Reis Coutinho 1 1 Departamento de Informática Universidade Federal do Maranhão São Luís,MA Brazil navi1921@gmail.com, mateus.rp.slz@gmail.com,
CS 387: GAME AI BOARD GAMES
 CS 387: GAME AI BOARD GAMES 5/28/2015 Instructor: Santiago Ontañón santi@cs.drexel.edu Class website: https://www.cs.drexel.edu/~santi/teaching/2015/cs387/intro.html Reminders Check BBVista site for the
CS 387: GAME AI BOARD GAMES 5/28/2015 Instructor: Santiago Ontañón santi@cs.drexel.edu Class website: https://www.cs.drexel.edu/~santi/teaching/2015/cs387/intro.html Reminders Check BBVista site for the
Announcements. Homework 1. Project 1. Due tonight at 11:59pm. Due Friday 2/8 at 4:00pm. Electronic HW1 Written HW1
 Announcements Homework 1 Due tonight at 11:59pm Project 1 Electronic HW1 Written HW1 Due Friday 2/8 at 4:00pm CS 188: Artificial Intelligence Adversarial Search and Game Trees Instructors: Sergey Levine
Announcements Homework 1 Due tonight at 11:59pm Project 1 Electronic HW1 Written HW1 Due Friday 2/8 at 4:00pm CS 188: Artificial Intelligence Adversarial Search and Game Trees Instructors: Sergey Levine
Game Playing: Adversarial Search. Chapter 5
 Game Playing: Adversarial Search Chapter 5 Outline Games Perfect play minimax search α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information Games vs. Search
Game Playing: Adversarial Search Chapter 5 Outline Games Perfect play minimax search α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information Games vs. Search
Computing Science (CMPUT) 496
 496") Computing Science (CMPUT) 496 Search, Knowledge, and Simulations Martin Müller Department of Computing Science University of Alberta mmueller@ualberta.ca Winter 2017 Part IV Knowledge 496 Today - Mar 9
Computing Science (CMPUT) 496 Search, Knowledge, and Simulations Martin Müller Department of Computing Science University of Alberta mmueller@ualberta.ca Winter 2017 Part IV Knowledge 496 Today - Mar 9
Advanced Game AI. Level 6 Search in Games. Prof Alexiei Dingli
 Advanced Game AI Level 6 Search in Games Prof Alexiei Dingli MCTS? MCTS Based upon Selec=on Expansion Simula=on Back propaga=on Enhancements The Mul=- Armed Bandit Problem At each step pull one arm Noisy/random
Advanced Game AI Level 6 Search in Games Prof Alexiei Dingli MCTS? MCTS Based upon Selec=on Expansion Simula=on Back propaga=on Enhancements The Mul=- Armed Bandit Problem At each step pull one arm Noisy/random
More on games (Ch )
") More on games (Ch. 5.4-5.6) Announcements Midterm next Tuesday: covers weeks 1-4 (Chapters 1-4) Take the full class period Open book/notes (can use ebook) ^^ No programing/code, internet searches or friends
More on games (Ch. 5.4-5.6) Announcements Midterm next Tuesday: covers weeks 1-4 (Chapters 1-4) Take the full class period Open book/notes (can use ebook) ^^ No programing/code, internet searches or friends
CS440/ECE448 Lecture 9: Minimax Search. Slides by Svetlana Lazebnik 9/2016 Modified by Mark Hasegawa-Johnson 9/2017
 CS440/ECE448 Lecture 9: Minimax Search Slides by Svetlana Lazebnik 9/2016 Modified by Mark Hasegawa-Johnson 9/2017 Why study games? Games are a traditional hallmark of intelligence Games are easy to formalize
CS440/ECE448 Lecture 9: Minimax Search Slides by Svetlana Lazebnik 9/2016 Modified by Mark Hasegawa-Johnson 9/2017 Why study games? Games are a traditional hallmark of intelligence Games are easy to formalize
HyperNEAT-GGP: A HyperNEAT-based Atari General Game Player. Matthew Hausknecht, Piyush Khandelwal, Risto Miikkulainen, Peter Stone
 -GGP: A -based Atari General Game Player Matthew Hausknecht, Piyush Khandelwal, Risto Miikkulainen, Peter Stone Motivation Create a General Video Game Playing agent which learns from visual representations
-GGP: A -based Atari General Game Player Matthew Hausknecht, Piyush Khandelwal, Risto Miikkulainen, Peter Stone Motivation Create a General Video Game Playing agent which learns from visual representations
Computer Go: from the Beginnings to AlphaGo. Martin Müller, University of Alberta
 Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk Game of Go Short history - Computer Go from the beginnings to AlphaGo The science behind AlphaGo
Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk Game of Go Short history - Computer Go from the beginnings to AlphaGo The science behind AlphaGo
Adversarial Search. Human-aware Robotics. 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: Slides for this lecture are here:
 Adversarial Search 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: q Slides for this lecture are here: http://www.public.asu.edu/~yzhan442/teaching/cse471/lectures/adversarial.pdf Slides are largely based
Adversarial Search 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: q Slides for this lecture are here: http://www.public.asu.edu/~yzhan442/teaching/cse471/lectures/adversarial.pdf Slides are largely based
CS-E4800 Artificial Intelligence
 CS-E4800 Artificial Intelligence Jussi Rintanen Department of Computer Science Aalto University March 9, 2017 Difficulties in Rational Collective Behavior Individual utility in conflict with collective
CS-E4800 Artificial Intelligence Jussi Rintanen Department of Computer Science Aalto University March 9, 2017 Difficulties in Rational Collective Behavior Individual utility in conflict with collective
High-Level Representations for Game-Tree Search in RTS Games
 Artificial Intelligence in Adversarial Real-Time Games: Papers from the AIIDE Workshop High-Level Representations for Game-Tree Search in RTS Games Alberto Uriarte and Santiago Ontañón Computer Science
Artificial Intelligence in Adversarial Real-Time Games: Papers from the AIIDE Workshop High-Level Representations for Game-Tree Search in RTS Games Alberto Uriarte and Santiago Ontañón Computer Science
Artificial Intelligence
 Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory AI Challenge One 140 Challenge 1 grades 120 100 80 60 AI Challenge One Transform to graph Explore the
Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory AI Challenge One 140 Challenge 1 grades 120 100 80 60 AI Challenge One Transform to graph Explore the
arxiv: v1 [cs.ne] 3 May 2018
![arxiv: v1 [cs.ne] 3 May 2018](/thumbs/86/93513162.jpg "arxiv: v1 [cs.ne] 3 May 2018") VINE: An Open Source Interactive Data Visualization Tool for Neuroevolution Uber AI Labs San Francisco, CA 94103 {ruiwang,jeffclune,kstanley}@uber.com arxiv:1805.01141v1 [cs.ne] 3 May 2018 ABSTRACT Recent
VINE: An Open Source Interactive Data Visualization Tool for Neuroevolution Uber AI Labs San Francisco, CA 94103 {ruiwang,jeffclune,kstanley}@uber.com arxiv:1805.01141v1 [cs.ne] 3 May 2018 ABSTRACT Recent
Comparison of Monte Carlo Tree Search Methods in the Imperfect Information Card Game Cribbage
 Comparison of Monte Carlo Tree Search Methods in the Imperfect Information Card Game Cribbage Richard Kelly and David Churchill Computer Science Faculty of Science Memorial University {richard.kelly, dchurchill}@mun.ca
Comparison of Monte Carlo Tree Search Methods in the Imperfect Information Card Game Cribbage Richard Kelly and David Churchill Computer Science Faculty of Science Memorial University {richard.kelly, dchurchill}@mun.ca
Game Playing State-of-the-Art CSE 473: Artificial Intelligence Fall Deterministic Games. Zero-Sum Games 10/13/17. Adversarial Search
 CSE 473: Artificial Intelligence Fall 2017 Adversarial Search Mini, pruning, Expecti Dieter Fox Based on slides adapted Luke Zettlemoyer, Dan Klein, Pieter Abbeel, Dan Weld, Stuart Russell or Andrew Moore
CSE 473: Artificial Intelligence Fall 2017 Adversarial Search Mini, pruning, Expecti Dieter Fox Based on slides adapted Luke Zettlemoyer, Dan Klein, Pieter Abbeel, Dan Weld, Stuart Russell or Andrew Moore
Prof. Sameer Singh CS 175: PROJECTS IN AI (IN MINECRAFT) WINTER April 6, 2017
 WINTER April 6, 2017") Prof. Sameer Singh CS 175: PROJECTS IN AI (IN MINECRAFT) WINTER 2017 April 6, 2017 Upcoming Misc. Check out course webpage and schedule Check out Canvas, especially for deadlines Do the survey by tomorrow,
Prof. Sameer Singh CS 175: PROJECTS IN AI (IN MINECRAFT) WINTER 2017 April 6, 2017 Upcoming Misc. Check out course webpage and schedule Check out Canvas, especially for deadlines Do the survey by tomorrow,
Adversarial search (game playing)
") Adversarial search (game playing) References Russell and Norvig, Artificial Intelligence: A modern approach, 2nd ed. Prentice Hall, 2003 Nilsson, Artificial intelligence: A New synthesis. McGraw Hill,
Adversarial search (game playing) References Russell and Norvig, Artificial Intelligence: A modern approach, 2nd ed. Prentice Hall, 2003 Nilsson, Artificial intelligence: A New synthesis. McGraw Hill,
MFF UK Prague
 MFF UK Prague 25.10.2018 Source: https://wall.alphacoders.com/big.php?i=324425 Adapted from: https://wall.alphacoders.com/big.php?i=324425 1996, Deep Blue, IBM AlphaGo, Google, 2015 Source: istan HONDA/AFP/GETTY
MFF UK Prague 25.10.2018 Source: https://wall.alphacoders.com/big.php?i=324425 Adapted from: https://wall.alphacoders.com/big.php?i=324425 1996, Deep Blue, IBM AlphaGo, Google, 2015 Source: istan HONDA/AFP/GETTY
DeepStack: Expert-Level AI in Heads-Up No-Limit Poker. Surya Prakash Chembrolu
 DeepStack: Expert-Level AI in Heads-Up No-Limit Poker Surya Prakash Chembrolu AI and Games AlphaGo Go Watson Jeopardy! DeepBlue -Chess Chinook -Checkers TD-Gammon -Backgammon Perfect Information Games
DeepStack: Expert-Level AI in Heads-Up No-Limit Poker Surya Prakash Chembrolu AI and Games AlphaGo Go Watson Jeopardy! DeepBlue -Chess Chinook -Checkers TD-Gammon -Backgammon Perfect Information Games
TGD3351 Game Algorithms TGP2281 Games Programming III. in my own words, better known as Game AI
 TGD3351 Game Algorithms TGP2281 Games Programming III in my own words, better known as Game AI An Introduction to Video Game AI A round of introduction In a nutshell B.CS (GD Specialization) Game Design
TGD3351 Game Algorithms TGP2281 Games Programming III in my own words, better known as Game AI An Introduction to Video Game AI A round of introduction In a nutshell B.CS (GD Specialization) Game Design
Artificial Intelligence Adversarial Search
 Artificial Intelligence Adversarial Search Adversarial Search Adversarial search problems games They occur in multiagent competitive environments There is an opponent we can t control planning again us!
Artificial Intelligence Adversarial Search Adversarial Search Adversarial search problems games They occur in multiagent competitive environments There is an opponent we can t control planning again us!
CMSC 671 Project Report- Google AI Challenge: Planet Wars
 1. Introduction Purpose The purpose of the project is to apply relevant AI techniques learned during the course with a view to develop an intelligent game playing bot for the game of Planet Wars. Planet
1. Introduction Purpose The purpose of the project is to apply relevant AI techniques learned during the course with a view to develop an intelligent game playing bot for the game of Planet Wars. Planet
Foundations of AI. 6. Adversarial Search. Search Strategies for Games, Games with Chance, State of the Art. Wolfram Burgard & Bernhard Nebel
 Foundations of AI 6. Adversarial Search Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard & Bernhard Nebel Contents Game Theory Board Games Minimax Search Alpha-Beta Search
Foundations of AI 6. Adversarial Search Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard & Bernhard Nebel Contents Game Theory Board Games Minimax Search Alpha-Beta Search
ARTIFICIAL INTELLIGENCE (CS 370D)
") Princess Nora University Faculty of Computer & Information Systems ARTIFICIAL INTELLIGENCE (CS 370D) (CHAPTER-5) ADVERSARIAL SEARCH ADVERSARIAL SEARCH Optimal decisions Min algorithm α-β pruning Imperfect,
Princess Nora University Faculty of Computer & Information Systems ARTIFICIAL INTELLIGENCE (CS 370D) (CHAPTER-5) ADVERSARIAL SEARCH ADVERSARIAL SEARCH Optimal decisions Min algorithm α-β pruning Imperfect,
Games CSE 473. Kasparov Vs. Deep Junior August 2, 2003 Match ends in a 3 / 3 tie!
 Games CSE 473 Kasparov Vs. Deep Junior August 2, 2003 Match ends in a 3 / 3 tie! Games in AI In AI, games usually refers to deteristic, turntaking, two-player, zero-sum games of perfect information Deteristic:
Games CSE 473 Kasparov Vs. Deep Junior August 2, 2003 Match ends in a 3 / 3 tie! Games in AI In AI, games usually refers to deteristic, turntaking, two-player, zero-sum games of perfect information Deteristic:
More on games (Ch )
") More on games (Ch. 5.4-5.6) Alpha-beta pruning Previously on CSci 4511... We talked about how to modify the minimax algorithm to prune only bad searches (i.e. alpha-beta pruning) This rule of checking
More on games (Ch. 5.4-5.6) Alpha-beta pruning Previously on CSci 4511... We talked about how to modify the minimax algorithm to prune only bad searches (i.e. alpha-beta pruning) This rule of checking
Unit-III Chap-II Adversarial Search. Created by: Ashish Shah 1
 Unit-III Chap-II Adversarial Search Created by: Ashish Shah 1 Alpha beta Pruning In case of standard ALPHA BETA PRUNING minimax tree, it returns the same move as minimax would, but prunes away branches
Unit-III Chap-II Adversarial Search Created by: Ashish Shah 1 Alpha beta Pruning In case of standard ALPHA BETA PRUNING minimax tree, it returns the same move as minimax would, but prunes away branches
Mattel Intellivision
 Intellivision 4-Tris ABPA Backgammon ABPA Backgammon: Made in Hong Kong Advanced Dungeons & Dragons Advanced Dungeons & Dragons: Made in Hong Kong Advanced Dungeons & Dragons: White Label Advanced Dungeons
Intellivision 4-Tris ABPA Backgammon ABPA Backgammon: Made in Hong Kong Advanced Dungeons & Dragons Advanced Dungeons & Dragons: Made in Hong Kong Advanced Dungeons & Dragons: White Label Advanced Dungeons
CS 188: Artificial Intelligence Spring 2007
 CS 188: Artificial Intelligence Spring 2007 Lecture 7: CSP-II and Adversarial Search 2/6/2007 Srini Narayanan ICSI and UC Berkeley Many slides over the course adapted from Dan Klein, Stuart Russell or
CS 188: Artificial Intelligence Spring 2007 Lecture 7: CSP-II and Adversarial Search 2/6/2007 Srini Narayanan ICSI and UC Berkeley Many slides over the course adapted from Dan Klein, Stuart Russell or
AI in Games: Achievements and Challenges. Yuandong Tian Facebook AI Research
 AI in Games: Achievements and Challenges Yuandong Tian Facebook AI Research Game as a Vehicle of AI Infinite supply of fully labeled data Controllable and replicable Low cost per sample Faster than real-time
AI in Games: Achievements and Challenges Yuandong Tian Facebook AI Research Game as a Vehicle of AI Infinite supply of fully labeled data Controllable and replicable Low cost per sample Faster than real-time
Game Playing Beyond Minimax. Game Playing Summary So Far. Game Playing Improving Efficiency. Game Playing Minimax using DFS.
 Game Playing Summary So Far Game tree describes the possible sequences of play is a graph if we merge together identical states Minimax: utility values assigned to the leaves Values backed up the tree
Game Playing Summary So Far Game tree describes the possible sequences of play is a graph if we merge together identical states Minimax: utility values assigned to the leaves Values backed up the tree
Artificial Intelligence Search III
 Artificial Intelligence Search III Lecture 5 Content: Search III Quick Review on Lecture 4 Why Study Games? Game Playing as Search Special Characteristics of Game Playing Search Ingredients of 2-Person
Artificial Intelligence Search III Lecture 5 Content: Search III Quick Review on Lecture 4 Why Study Games? Game Playing as Search Special Characteristics of Game Playing Search Ingredients of 2-Person
Outline. Introduction to AI. Artificial Intelligence. What is an AI? What is an AI? Agents Environments
 Outline Introduction to AI ECE457 Applied Artificial Intelligence Fall 2007 Lecture #1 What is an AI? Russell & Norvig, chapter 1 Agents s Russell & Norvig, chapter 2 ECE457 Applied Artificial Intelligence
Outline Introduction to AI ECE457 Applied Artificial Intelligence Fall 2007 Lecture #1 What is an AI? Russell & Norvig, chapter 1 Agents s Russell & Norvig, chapter 2 ECE457 Applied Artificial Intelligence
Pengju
 Introduction to AI Chapter05 Adversarial Search: Game Playing Pengju Ren@IAIR Outline Types of Games Formulation of games Perfect-Information Games Minimax and Negamax search α-β Pruning Pruning more Imperfect
Introduction to AI Chapter05 Adversarial Search: Game Playing Pengju Ren@IAIR Outline Types of Games Formulation of games Perfect-Information Games Minimax and Negamax search α-β Pruning Pruning more Imperfect
Ar#ficial)Intelligence!!
Intelligence!!") Introduc*on! Ar#ficial)Intelligence!! Roman Barták Department of Theoretical Computer Science and Mathematical Logic So far we assumed a single-agent environment, but what if there are more agents and
Introduc*on! Ar#ficial)Intelligence!! Roman Barták Department of Theoretical Computer Science and Mathematical Logic So far we assumed a single-agent environment, but what if there are more agents and
Chapter Overview. Games
 Chapter Overview u Motivation u Objectives u and AI u and Search u Perfect Decisions u Imperfect Decisions u Alpha-Beta Pruning u with Chance u and Computers u Important Concepts and Terms u Chapter Summary
Chapter Overview u Motivation u Objectives u and AI u and Search u Perfect Decisions u Imperfect Decisions u Alpha-Beta Pruning u with Chance u and Computers u Important Concepts and Terms u Chapter Summary
COMP219: COMP219: Artificial Intelligence Artificial Intelligence Dr. Annabel Latham Lecture 12: Game Playing Overview Games and Search
 COMP19: Artificial Intelligence COMP19: Artificial Intelligence Dr. Annabel Latham Room.05 Ashton Building Department of Computer Science University of Liverpool Lecture 1: Game Playing 1 Overview Last
COMP19: Artificial Intelligence COMP19: Artificial Intelligence Dr. Annabel Latham Room.05 Ashton Building Department of Computer Science University of Liverpool Lecture 1: Game Playing 1 Overview Last
Applying Modern Reinforcement Learning to Play Video Games. Computer Science & Engineering Leung Man Ho Supervisor: Prof. LYU Rung Tsong Michael
 Applying Modern Reinforcement Learning to Play Video Games Computer Science & Engineering Leung Man Ho Supervisor: Prof. LYU Rung Tsong Michael Outline Term 1 Review Term 2 Objectives Experiments & Results
Applying Modern Reinforcement Learning to Play Video Games Computer Science & Engineering Leung Man Ho Supervisor: Prof. LYU Rung Tsong Michael Outline Term 1 Review Term 2 Objectives Experiments & Results
TGD3351 Game Algorithms TGP2281 Games Programming III. in my own words, better known as Game AI
 TGD3351 Game Algorithms TGP2281 Games Programming III in my own words, better known as Game AI An Introduction to Video Game AI In a nutshell B.CS (GD Specialization) Game Design Fundamentals Game Physics
TGD3351 Game Algorithms TGP2281 Games Programming III in my own words, better known as Game AI An Introduction to Video Game AI In a nutshell B.CS (GD Specialization) Game Design Fundamentals Game Physics
CS 380: ARTIFICIAL INTELLIGENCE
 CS 380: ARTIFICIAL INTELLIGENCE ADVERSARIAL SEARCH 10/23/2013 Santiago Ontañón santi@cs.drexel.edu https://www.cs.drexel.edu/~santi/teaching/2013/cs380/intro.html Recall: Problem Solving Idea: represent
CS 380: ARTIFICIAL INTELLIGENCE ADVERSARIAL SEARCH 10/23/2013 Santiago Ontañón santi@cs.drexel.edu https://www.cs.drexel.edu/~santi/teaching/2013/cs380/intro.html Recall: Problem Solving Idea: represent
Intuition Mini-Max 2
 Games Today Saying Deep Blue doesn t really think about chess is like saying an airplane doesn t really fly because it doesn t flap its wings. Drew McDermott I could feel I could smell a new kind of intelligence
Games Today Saying Deep Blue doesn t really think about chess is like saying an airplane doesn t really fly because it doesn t flap its wings. Drew McDermott I could feel I could smell a new kind of intelligence
VISUAL ANALOGIES BETWEEN ATARI GAMES FOR STUDYING TRANSFER LEARNING IN RL
 VISUAL ANALOGIES BETWEEN ATARI GAMES FOR STUDYING TRANSFER LEARNING IN RL Doron Sobol 1, Lior Wolf 1,2 & Yaniv Taigman 2 1 School of Computer Science, Tel-Aviv University 2 Facebook AI Research ABSTRACT
VISUAL ANALOGIES BETWEEN ATARI GAMES FOR STUDYING TRANSFER LEARNING IN RL Doron Sobol 1, Lior Wolf 1,2 & Yaniv Taigman 2 1 School of Computer Science, Tel-Aviv University 2 Facebook AI Research ABSTRACT
arxiv: v1 [cs.ai] 24 Apr 2017
![arxiv: v1 [cs.ai] 24 Apr 2017](/thumbs/84/89160939.jpg "arxiv: v1 [cs.ai] 24 Apr 2017") Analysis of Vanilla Rolling Horizon Evolution Parameters in General Video Game Playing Raluca D. Gaina, Jialin Liu, Simon M. Lucas, Diego Pérez-Liébana School of Computer Science and Electronic Engineering,
Analysis of Vanilla Rolling Horizon Evolution Parameters in General Video Game Playing Raluca D. Gaina, Jialin Liu, Simon M. Lucas, Diego Pérez-Liébana School of Computer Science and Electronic Engineering,
Hierarchical Controller for Robotic Soccer
 Hierarchical Controller for Robotic Soccer Byron Knoll Cognitive Systems 402 April 13, 2008 ABSTRACT RoboCup is an initiative aimed at advancing Artificial Intelligence (AI) and robotics research. This
Hierarchical Controller for Robotic Soccer Byron Knoll Cognitive Systems 402 April 13, 2008 ABSTRACT RoboCup is an initiative aimed at advancing Artificial Intelligence (AI) and robotics research. This
April 25, Competing and cooperating with AI. Pantelis P. Analytis. Human behavior in Chess. Competing with AI. Cooperative machines?
 April 25, 2018 1 / 47 1 2 3 4 5 6 2 / 47 The case of chess 3 / 47 chess The first stage was the orientation phase, in which the subject assessed the situation determined a very general idea of what to
April 25, 2018 1 / 47 1 2 3 4 5 6 2 / 47 The case of chess 3 / 47 chess The first stage was the orientation phase, in which the subject assessed the situation determined a very general idea of what to
Playing Atari Games with Deep Reinforcement Learning
 Playing Atari Games with Deep Reinforcement Learning 1 Playing Atari Games with Deep Reinforcement Learning Varsha Lalwani (varshajn@iitk.ac.in) Masare Akshay Sunil (amasare@iitk.ac.in) IIT Kanpur CS365A
Playing Atari Games with Deep Reinforcement Learning 1 Playing Atari Games with Deep Reinforcement Learning Varsha Lalwani (varshajn@iitk.ac.in) Masare Akshay Sunil (amasare@iitk.ac.in) IIT Kanpur CS365A