Intelligent Non-Player Character with Deep Learning. Intelligent Non-Player Character with Deep Learning 1
|
|
|
- Crystal Atkins
- 5 years ago
- Views:
Transcription
1 Intelligent Non-Player Character with Deep Learning Meng Zhixiang, Zhang Haoze Supervised by Prof. Michael Lyu CUHK CSE FYP Term 1 Intelligent Non-Player Character with Deep Learning 1

2 Intelligent Non-Player Character with Deep Learning 2

3 Background We all know the results Intelligent Non-Player Character with Deep Learning 3
4 Agenda o Background o Motivation & Objective o Methodologies o Design & Implementation o Results & Discussion o Conclusion Intelligent Non-Player Character with Deep Learning 4
5 Agenda o Background o Development of AI in Go, Chess and Chinese Chess o Difference among Go, Chess and Chinese Chess o Motivation & Objective o Methodologies o Design & Implementation o Results & Discussion o Conclusion Intelligent Non-Player Character with Deep Learning 5
6 Development of AI in Go No Good Results Zen beat Takemiya Masaki at five stones handicap Mar 2012 AlphaGo beat Lee Sedol Mar 2016 Minimax Searching Pruning Monte Carlo Deep Learning Intelligent Non-Player Character with Deep Learning 6

7 Difference between Go and Chess/Chinese Chess Intelligent Non-Player Character with Deep Learning 7
8 Development of AI in Chess Deep Blue beat Garry Kasparov May 1997 Stockfish won TCEC 2013, 2014, 2015 Giraffe plays at the level of an FIDE International Master on a PC Sep 2015 Minimax Searching Evaluation Function Hand-Coded Knowledge Minimax Searching Evaluation Function Hand-Coded Knowledge Deep Reinforcement Learning TCEC: Top Chess Engine Championship FIDE: World Chess Federation Intelligent Non-Player Character with Deep Learning 8
9 Difference between Chess and Chinese Chess Intelligent Non-Player Character with Deep Learning 9
10 Development of AI in Chinese Chess Tiansuo Inspur System beat five Grandmaster players Aug 2006 Chess Nade beat three Master players Nov 2009 Now??? Minimax Searching Alpha-Beta Pruning Hand-Coded Knowledge Minimax Searching Alpha-Beta Pruning Hand-Coded Knowledge Deep Learning??? Intelligent Non-Player Character with Deep Learning 10



11 Motivation Intelligent Non-Player Character with Deep Learning 11
12 Objective Server Human Player User Interface Game AI Intelligent Non-Player Character with Deep Learning 12
13 Agenda o Background o Motivation & Objective o Methodologies o Supervised Learning o Convolutional Neural Network o Design & Implementation o Results & Discussion o Conclusion Intelligent Non-Player Character with Deep Learning 13

14 Supervised Learning o Supervised Learning o the right answer is given o Regression Problem & Classification Problem o Unsupervised Learning o no right answer is given o Clustering Problem Intelligent Non-Player Character with Deep Learning 14

15 Neural Network o Non-linear Hypotheses o Neurons and Brain o Backpropagation Intelligent Non-Player Character with Deep Learning 15


16 Convolutional Neural Network o Feed-forward o Organization of Animal Visual Cortex o Image Recognition Local Receptive Fields Shared Weights and Biases Intelligent Non-Player Character with Deep Learning 16
17 Agenda o Background o Motivation & Objective o Methodologies o Design & Implementation o Project Workflow o Results & Discussion o Conclusion Intelligent Non-Player Character with Deep Learning 17
18 Project Workflow Accuracy Testing Model Design Model Building Model Training Model Testing Real Performance Testing Intelligent Non-Player Character with Deep Learning 18
19 Design Overview Game AI Policy Network Evaluation Network Predict probabilities of next moves Evaluate winning rate Intelligent Non-Player Character with Deep Learning 19
20 Game AI Structure Piece Selector Message Receiver Format Converter Feature Extractor Decision Maker Message Sender Move Selector Intelligent Non-Player Character with Deep Learning 20
21 Feature Channels Feature Channel 1 Feature Channel 2 Feature Channel 3 Feature Channel 4 Feature Channel 5 Feature Channel 6 Feature Channel 7 Feature Channel 8 Feature Channel 9 (only for Move Selector) Pieces belonging to different sides Pieces of Advisor type Pieces of Bishop type Pieces of Cannon type Pieces of King type Pieces of Knight type Pieces of Pawn type Pieces of Rock type Valid moves for the selected piece Intelligent Non-Player Character with Deep Learning 21
22 Feature Channels Chessboard Status 1 st Feature Channel 4 th Feature Channel 9 th Feature Channel Intelligent Non-Player Character with Deep Learning 22

23 Piece Selector & Move Selector Intelligent Non-Player Character with Deep Learning 23
24 Piece Selector & Move Selector Extracted Features First Hidden Convolutional Layer Second Hidden Convolutional Layer Third Hidden Layer (Softmax Layer) Probability Distribution Rectified Linear Unit (ReLU) Intelligent Non-Player Character with Deep Learning 24
25 Selection Strategy o Strategy 1: o Select the piece with highest possibility given by Piece Selector o Select the destination of that piece with highest possibility given by Move Selector o Strategy 2: o Calculate the probability of moving a piece * the probability of a destination of that piece o Select the combination with highest probability Intelligent Non-Player Character with Deep Learning 25
26 Project Workflow Accuracy Testing Model Design Model Building Model Training Model Testing Real Performance Testing Intelligent Non-Player Character with Deep Learning 26

27 TensorFlow o an open source software library o for numerical computation o using data flow graphs o flexibility and portability Intelligent Non-Player Character with Deep Learning 27
28 Project Workflow Accuracy Testing Model Design Model Building Model Training Model Testing Real Performance Testing Intelligent Non-Player Character with Deep Learning 28
29 Training Dataset Collected Game Records Features and Targets Training Dataset for Different NN models Intelligent Non-Player Character with Deep Learning 29

30 FEN Format rnbakab1r/ /1c1111nc1/p1p1p1p1p/ / / P1P1P1P1P/1C11C1111/ /RNBAKABNR, r Intelligent Non-Player Character with Deep Learning 30



31 Format Conversion 炮二平五 马二进三 车一进一 车一平六 车六进七 车九进一 炮八进五 炮五进四 车九平六 前车进一 车六平四 车四进六 炮八平五 炮8平5 马8进7 车9平8 车8进6 马2进1 炮2进7 马7退8 士6进5 将5平6 士5退4 炮5平6 将6平5 Intelligent Non-Player Character with Deep Learning 31
32 Training Strategy o Piece Selector and Move Selector are trained separately o Shuffle the training dataset containing over 1,600,000 moves o Train the models batch by batch o Test the accuracy along the process o An untrained testing dataset containing over 80,000 moves Intelligent Non-Player Character with Deep Learning 32
33 Project Workflow Accuracy Testing Model Design Model Building Model Training Model Testing Real Performance Testing Intelligent Non-Player Character with Deep Learning 33
34 Results Piece Selector Accuracy accuracy = # of correct predictions / total # of test cases prediction: the choice with the highest probability Intelligent Non-Player Character with Deep Learning 34
35 Results Move Selector Accuracy Intelligent Non-Player Character with Deep Learning 35
36 Results Move Selector Accuracy Advisor 89.8% Bishop 91.2% Cannon 54.1% King 79.8% Knight 70.1% Pawn 90.4% Rock 53.6% Move Selector Accuracy Intelligent Non-Player Character with Deep Learning 36

37 Results Intelligent Non-Player Character with Deep Learning 37


38 Results Intelligent Non-Player Character with Deep Learning 38
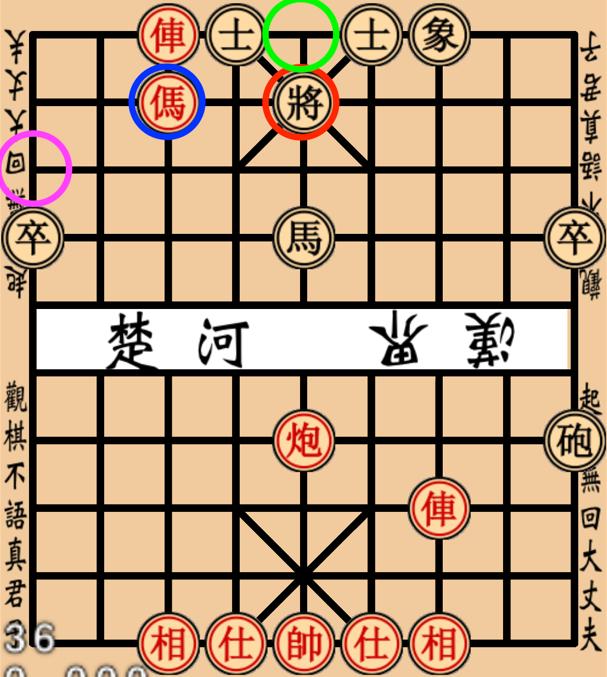
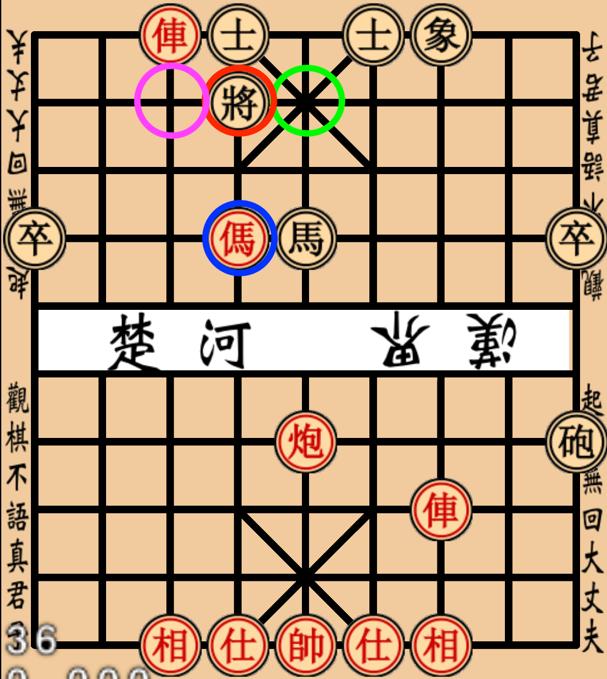
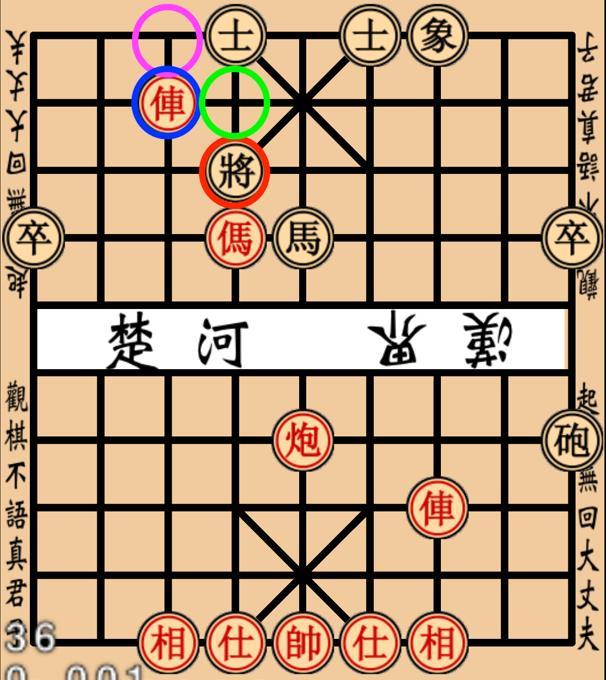
39 Results Intelligent Non-Player Character with Deep Learning 39



40 Results Selection Strategy 1 Selection Strategy 2 Intelligent Non-Player Character with Deep Learning 40
41 Discussion o Possible Reasons: o CNN not deep enough o Training dataset not large enough o Records in training dataset may not be the optimal choices o For one chessboard status, there may be different move choices in training dataset o It s hard to judge which choice is better in current phase Intelligent Non-Player Character with Deep Learning 41
42 Conclusion o Achieved overall high accuracy o Performed badly in some cases o Need further improvement o Reinforcement Learning o Not limited by training dataset o Evaluation Network o To judge which move is better Intelligent Non-Player Character with Deep Learning 42
43 Q&A Intelligent Non-Player Character with Deep Learning 43
Department of Computer Science and Engineering. The Chinese University of Hong Kong. Final Year Project Report LYU1601
 Department of Computer Science and Engineering The Chinese University of Hong Kong 2016 2017 LYU1601 Intelligent Non-Player Character with Deep Learning Prepared by ZHANG Haoze Supervised by Prof. Michael
Department of Computer Science and Engineering The Chinese University of Hong Kong 2016 2017 LYU1601 Intelligent Non-Player Character with Deep Learning Prepared by ZHANG Haoze Supervised by Prof. Michael
How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997)
") How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997) Alan Fern School of Electrical Engineering and Computer Science Oregon State University Deep Mind s vs. Lee Sedol (2016) Watson vs. Ken
How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997) Alan Fern School of Electrical Engineering and Computer Science Oregon State University Deep Mind s vs. Lee Sedol (2016) Watson vs. Ken
46.1 Introduction. Foundations of Artificial Intelligence Introduction MCTS in AlphaGo Neural Networks. 46.
 Foundations of Artificial Intelligence May 30, 2016 46. AlphaGo and Outlook Foundations of Artificial Intelligence 46. AlphaGo and Outlook Thomas Keller Universität Basel May 30, 2016 46.1 Introduction
Foundations of Artificial Intelligence May 30, 2016 46. AlphaGo and Outlook Foundations of Artificial Intelligence 46. AlphaGo and Outlook Thomas Keller Universität Basel May 30, 2016 46.1 Introduction
Mastering Chess and Shogi by Self- Play with a General Reinforcement Learning Algorithm
 Mastering Chess and Shogi by Self- Play with a General Reinforcement Learning Algorithm by Silver et al Published by Google Deepmind Presented by Kira Selby Background u In March 2016, Deepmind s AlphaGo
Mastering Chess and Shogi by Self- Play with a General Reinforcement Learning Algorithm by Silver et al Published by Google Deepmind Presented by Kira Selby Background u In March 2016, Deepmind s AlphaGo
Google DeepMind s AlphaGo vs. world Go champion Lee Sedol
 Google DeepMind s AlphaGo vs. world Go champion Lee Sedol Review of Nature paper: Mastering the game of Go with Deep Neural Networks & Tree Search Tapani Raiko Thanks to Antti Tarvainen for some slides
Google DeepMind s AlphaGo vs. world Go champion Lee Sedol Review of Nature paper: Mastering the game of Go with Deep Neural Networks & Tree Search Tapani Raiko Thanks to Antti Tarvainen for some slides
Andrei Behel AC-43И 1
 Andrei Behel AC-43И 1 History The game of Go originated in China more than 2,500 years ago. The rules of the game are simple: Players take turns to place black or white stones on a board, trying to capture
Andrei Behel AC-43И 1 History The game of Go originated in China more than 2,500 years ago. The rules of the game are simple: Players take turns to place black or white stones on a board, trying to capture
Game-playing: DeepBlue and AlphaGo
 Game-playing: DeepBlue and AlphaGo Brief history of gameplaying frontiers 1990s: Othello world champions refuse to play computers 1994: Chinook defeats Checkers world champion 1997: DeepBlue defeats world
Game-playing: DeepBlue and AlphaGo Brief history of gameplaying frontiers 1990s: Othello world champions refuse to play computers 1994: Chinook defeats Checkers world champion 1997: DeepBlue defeats world
CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH. Santiago Ontañón
 CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH Santiago Ontañón so367@drexel.edu Recall: Adversarial Search Idea: When there is only one agent in the world, we can solve problems using DFS, BFS, ID,
CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH Santiago Ontañón so367@drexel.edu Recall: Adversarial Search Idea: When there is only one agent in the world, we can solve problems using DFS, BFS, ID,
AI in Tabletop Games. Team 13 Josh Charnetsky Zachary Koch CSE Professor Anita Wasilewska
 AI in Tabletop Games Team 13 Josh Charnetsky Zachary Koch CSE 352 - Professor Anita Wasilewska Works Cited Kurenkov, Andrey. a-brief-history-of-game-ai.png. 18 Apr. 2016, www.andreykurenkov.com/writing/a-brief-history-of-game-ai/
AI in Tabletop Games Team 13 Josh Charnetsky Zachary Koch CSE 352 - Professor Anita Wasilewska Works Cited Kurenkov, Andrey. a-brief-history-of-game-ai.png. 18 Apr. 2016, www.andreykurenkov.com/writing/a-brief-history-of-game-ai/
Monte Carlo Tree Search
 Monte Carlo Tree Search 1 By the end, you will know Why we use Monte Carlo Search Trees The pros and cons of MCTS How it is applied to Super Mario Brothers and Alpha Go 2 Outline I. Pre-MCTS Algorithms
Monte Carlo Tree Search 1 By the end, you will know Why we use Monte Carlo Search Trees The pros and cons of MCTS How it is applied to Super Mario Brothers and Alpha Go 2 Outline I. Pre-MCTS Algorithms
School of EECS Washington State University. Artificial Intelligence
 School of EECS Washington State University Artificial Intelligence 1 } Classic AI challenge Easy to represent Difficult to solve } Zero-sum games Total final reward to all players is constant } Perfect
School of EECS Washington State University Artificial Intelligence 1 } Classic AI challenge Easy to represent Difficult to solve } Zero-sum games Total final reward to all players is constant } Perfect
SDS PODCAST EPISODE 110 ALPHAGO ZERO
 SDS PODCAST EPISODE 110 ALPHAGO ZERO Show Notes: http://www.superdatascience.com/110 1 Kirill: This is episode number 110, AlphaGo Zero. Welcome back ladies and gentlemen to the SuperDataSceince podcast.
SDS PODCAST EPISODE 110 ALPHAGO ZERO Show Notes: http://www.superdatascience.com/110 1 Kirill: This is episode number 110, AlphaGo Zero. Welcome back ladies and gentlemen to the SuperDataSceince podcast.
Using Neural Network and Monte-Carlo Tree Search to Play the Game TEN
 Using Neural Network and Monte-Carlo Tree Search to Play the Game TEN Weijie Chen Fall 2017 Weijie Chen Page 1 of 7 1. INTRODUCTION Game TEN The traditional game Tic-Tac-Toe enjoys people s favor. Moreover,
Using Neural Network and Monte-Carlo Tree Search to Play the Game TEN Weijie Chen Fall 2017 Weijie Chen Page 1 of 7 1. INTRODUCTION Game TEN The traditional game Tic-Tac-Toe enjoys people s favor. Moreover,
TD-Leaf(λ) Giraffe: Using Deep Reinforcement Learning to Play Chess. Stefan Lüttgen
 Giraffe: Using Deep Reinforcement Learning to Play Chess. Stefan Lüttgen") TD-Leaf(λ) Giraffe: Using Deep Reinforcement Learning to Play Chess Stefan Lüttgen Motivation Learn to play chess Computer approach different than human one Humans search more selective: Kasparov (3-5
TD-Leaf(λ) Giraffe: Using Deep Reinforcement Learning to Play Chess Stefan Lüttgen Motivation Learn to play chess Computer approach different than human one Humans search more selective: Kasparov (3-5
CSC321 Lecture 23: Go
 CSC321 Lecture 23: Go Roger Grosse Roger Grosse CSC321 Lecture 23: Go 1 / 21 Final Exam Friday, April 20, 9am-noon Last names A Y: Clara Benson Building (BN) 2N Last names Z: Clara Benson Building (BN)
CSC321 Lecture 23: Go Roger Grosse Roger Grosse CSC321 Lecture 23: Go 1 / 21 Final Exam Friday, April 20, 9am-noon Last names A Y: Clara Benson Building (BN) 2N Last names Z: Clara Benson Building (BN)
Artificial Intelligence Search III
 Artificial Intelligence Search III Lecture 5 Content: Search III Quick Review on Lecture 4 Why Study Games? Game Playing as Search Special Characteristics of Game Playing Search Ingredients of 2-Person
Artificial Intelligence Search III Lecture 5 Content: Search III Quick Review on Lecture 4 Why Study Games? Game Playing as Search Special Characteristics of Game Playing Search Ingredients of 2-Person
Foundations of Artificial Intelligence Introduction State of the Art Summary. classification: Board Games: Overview
 Foundations of Artificial Intelligence May 14, 2018 40. Board Games: Introduction and State of the Art Foundations of Artificial Intelligence 40. Board Games: Introduction and State of the Art 40.1 Introduction
Foundations of Artificial Intelligence May 14, 2018 40. Board Games: Introduction and State of the Art Foundations of Artificial Intelligence 40. Board Games: Introduction and State of the Art 40.1 Introduction
Success Stories of Deep RL. David Silver
 Success Stories of Deep RL David Silver Reinforcement Learning (RL) RL is a general-purpose framework for decision-making An agent selects actions Its actions influence its future observations Success
Success Stories of Deep RL David Silver Reinforcement Learning (RL) RL is a general-purpose framework for decision-making An agent selects actions Its actions influence its future observations Success
The Principles Of A.I Alphago
 The Principles Of A.I Alphago YinChen Wu Dr. Hubert Bray Duke Summer Session 20 july 2017 Introduction Go, a traditional Chinese board game, is a remarkable work of art which has been invented for more
The Principles Of A.I Alphago YinChen Wu Dr. Hubert Bray Duke Summer Session 20 july 2017 Introduction Go, a traditional Chinese board game, is a remarkable work of art which has been invented for more
AlphaGo and Artificial Intelligence GUEST LECTURE IN THE GAME OF GO AND SOCIETY
 AlphaGo and Artificial Intelligence HUCK BENNET T (NORTHWESTERN UNIVERSITY) GUEST LECTURE IN THE GAME OF GO AND SOCIETY AT OCCIDENTAL COLLEGE, 10/29/2018 The Game of Go A game for aliens, presidents, and
AlphaGo and Artificial Intelligence HUCK BENNET T (NORTHWESTERN UNIVERSITY) GUEST LECTURE IN THE GAME OF GO AND SOCIETY AT OCCIDENTAL COLLEGE, 10/29/2018 The Game of Go A game for aliens, presidents, and
TTIC 31230, Fundamentals of Deep Learning David McAllester, April AlphaZero
 TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 AlphaZero 1 AlphaGo Fan (October 2015) AlphaGo Defeats Fan Hui, European Go Champion. 2 AlphaGo Lee (March 2016) 3 AlphaGo Zero vs.
TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 AlphaZero 1 AlphaGo Fan (October 2015) AlphaGo Defeats Fan Hui, European Go Champion. 2 AlphaGo Lee (March 2016) 3 AlphaGo Zero vs.
CPS 570: Artificial Intelligence Two-player, zero-sum, perfect-information Games
 CPS 57: Artificial Intelligence Two-player, zero-sum, perfect-information Games Instructor: Vincent Conitzer Game playing Rich tradition of creating game-playing programs in AI Many similarities to search
CPS 57: Artificial Intelligence Two-player, zero-sum, perfect-information Games Instructor: Vincent Conitzer Game playing Rich tradition of creating game-playing programs in AI Many similarities to search
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Adversarial Search Prof. Scott Niekum The University of Texas at Austin [These slides are based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
CS 188: Artificial Intelligence Adversarial Search Prof. Scott Niekum The University of Texas at Austin [These slides are based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
Computer Go: from the Beginnings to AlphaGo. Martin Müller, University of Alberta
 Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk Game of Go Short history - Computer Go from the beginnings to AlphaGo The science behind AlphaGo
Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk Game of Go Short history - Computer Go from the beginnings to AlphaGo The science behind AlphaGo
Deep Learning. Dr. Johan Hagelbäck.
 Deep Learning Dr. Johan Hagelbäck johan.hagelback@lnu.se http://aiguy.org Image Classification Image classification can be a difficult task Some of the challenges we have to face are: Viewpoint variation:
Deep Learning Dr. Johan Hagelbäck johan.hagelback@lnu.se http://aiguy.org Image Classification Image classification can be a difficult task Some of the challenges we have to face are: Viewpoint variation:
CS 331: Artificial Intelligence Adversarial Search II. Outline
 CS 331: Artificial Intelligence Adversarial Search II 1 Outline 1. Evaluation Functions 2. State-of-the-art game playing programs 3. 2 player zero-sum finite stochastic games of perfect information 2 1
CS 331: Artificial Intelligence Adversarial Search II 1 Outline 1. Evaluation Functions 2. State-of-the-art game playing programs 3. 2 player zero-sum finite stochastic games of perfect information 2 1
CSE 473: Artificial Intelligence. Outline
 CSE 473: Artificial Intelligence Adversarial Search Dan Weld Based on slides from Dan Klein, Stuart Russell, Pieter Abbeel, Andrew Moore and Luke Zettlemoyer (best illustrations from ai.berkeley.edu) 1
CSE 473: Artificial Intelligence Adversarial Search Dan Weld Based on slides from Dan Klein, Stuart Russell, Pieter Abbeel, Andrew Moore and Luke Zettlemoyer (best illustrations from ai.berkeley.edu) 1
Foundations of Artificial Intelligence
 Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Bernhard Nebel Albert-Ludwigs-Universität
Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Bernhard Nebel Albert-Ludwigs-Universität
Automated Suicide: An Antichess Engine
 Automated Suicide: An Antichess Engine Jim Andress and Prasanna Ramakrishnan 1 Introduction Antichess (also known as Suicide Chess or Loser s Chess) is a popular variant of chess where the objective of
Automated Suicide: An Antichess Engine Jim Andress and Prasanna Ramakrishnan 1 Introduction Antichess (also known as Suicide Chess or Loser s Chess) is a popular variant of chess where the objective of
Foundations of Artificial Intelligence
 Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Frank Hutter and Bernhard Nebel Albert-Ludwigs-Universität
Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Frank Hutter and Bernhard Nebel Albert-Ludwigs-Universität
Foundations of Artificial Intelligence
 Foundations of Artificial Intelligence 42. Board Games: Alpha-Beta Search Malte Helmert University of Basel May 16, 2018 Board Games: Overview chapter overview: 40. Introduction and State of the Art 41.
Foundations of Artificial Intelligence 42. Board Games: Alpha-Beta Search Malte Helmert University of Basel May 16, 2018 Board Games: Overview chapter overview: 40. Introduction and State of the Art 41.
CS 4700: Foundations of Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence selman@cs.cornell.edu Module: Adversarial Search R&N: Chapter 5 Part II 1 Outline Game Playing Optimal decisions Minimax α-β pruning Case study: Deep Blue
CS 4700: Foundations of Artificial Intelligence selman@cs.cornell.edu Module: Adversarial Search R&N: Chapter 5 Part II 1 Outline Game Playing Optimal decisions Minimax α-β pruning Case study: Deep Blue
AI, AlphaGo and computer Hex
 a math and computing story computing.science university of alberta 2018 march thanks Computer Research Hex Group Michael Johanson, Yngvi Björnsson, Morgan Kan, Nathan Po, Jack van Rijswijck, Broderick
a math and computing story computing.science university of alberta 2018 march thanks Computer Research Hex Group Michael Johanson, Yngvi Björnsson, Morgan Kan, Nathan Po, Jack van Rijswijck, Broderick
CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions
 CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions Slides by Svetlana Lazebnik, 9/2016 Modified by Mark Hasegawa Johnson, 9/2017 Types of game environments Perfect
CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions Slides by Svetlana Lazebnik, 9/2016 Modified by Mark Hasegawa Johnson, 9/2017 Types of game environments Perfect
CS885 Reinforcement Learning Lecture 13c: June 13, Adversarial Search [RusNor] Sec
![CS885 Reinforcement Learning Lecture 13c: June 13, Adversarial Search [RusNor] Sec](/thumbs/89/98879037.jpg "CS885 Reinforcement Learning Lecture 13c: June 13, Adversarial Search [RusNor] Sec") CS885 Reinforcement Learning Lecture 13c: June 13, 2018 Adversarial Search [RusNor] Sec. 5.1-5.4 CS885 Spring 2018 Pascal Poupart 1 Outline Minimax search Evaluation functions Alpha-beta pruning CS885
CS885 Reinforcement Learning Lecture 13c: June 13, 2018 Adversarial Search [RusNor] Sec. 5.1-5.4 CS885 Spring 2018 Pascal Poupart 1 Outline Minimax search Evaluation functions Alpha-beta pruning CS885
Experiments with Tensor Flow Roman Weber (Geschäftsführer) Richard Schmid (Senior Consultant)
 Richard Schmid (Senior Consultant)") Experiments with Tensor Flow 23.05.2017 Roman Weber (Geschäftsführer) Richard Schmid (Senior Consultant) WEBGATE CONSULTING Gegründet Mitarbeiter CH Inhaber geführt IT Anbieter Partner 2001 Ex 29 Beratung
Experiments with Tensor Flow 23.05.2017 Roman Weber (Geschäftsführer) Richard Schmid (Senior Consultant) WEBGATE CONSULTING Gegründet Mitarbeiter CH Inhaber geführt IT Anbieter Partner 2001 Ex 29 Beratung
Artificial Intelligence. Minimax and alpha-beta pruning
 Artificial Intelligence Minimax and alpha-beta pruning In which we examine the problems that arise when we try to plan ahead to get the best result in a world that includes a hostile agent (other agent
Artificial Intelligence Minimax and alpha-beta pruning In which we examine the problems that arise when we try to plan ahead to get the best result in a world that includes a hostile agent (other agent
Augmenting Self-Learning In Chess Through Expert Imitation
 Augmenting Self-Learning In Chess Through Expert Imitation Michael Xie Department of Computer Science Stanford University Stanford, CA 94305 xie@cs.stanford.edu Gene Lewis Department of Computer Science
Augmenting Self-Learning In Chess Through Expert Imitation Michael Xie Department of Computer Science Stanford University Stanford, CA 94305 xie@cs.stanford.edu Gene Lewis Department of Computer Science
Improving MCTS and Neural Network Communication in Computer Go
 Improving MCTS and Neural Network Communication in Computer Go Joshua Keller Oscar Perez Worcester Polytechnic Institute a Major Qualifying Project Report submitted to the faculty of Worcester Polytechnic
Improving MCTS and Neural Network Communication in Computer Go Joshua Keller Oscar Perez Worcester Polytechnic Institute a Major Qualifying Project Report submitted to the faculty of Worcester Polytechnic
Mastering the game of Go without human knowledge
 Mastering the game of Go without human knowledge David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton,
Mastering the game of Go without human knowledge David Silver, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker, Matthew Lai, Adrian Bolton,
Learning Deep Networks from Noisy Labels with Dropout Regularization
 Learning Deep Networks from Noisy Labels with Dropout Regularization Ishan Jindal*, Matthew Nokleby*, Xuewen Chen** *Department of Electrical and Computer Engineering **Department of Computer Science Wayne
Learning Deep Networks from Noisy Labels with Dropout Regularization Ishan Jindal*, Matthew Nokleby*, Xuewen Chen** *Department of Electrical and Computer Engineering **Department of Computer Science Wayne
Adversarial Search. Soleymani. Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5
 Adversarial Search CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2017 Soleymani Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5 Outline Game
Adversarial Search CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2017 Soleymani Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5 Outline Game
CS 387: GAME AI BOARD GAMES. 5/24/2016 Instructor: Santiago Ontañón
 CS 387: GAME AI BOARD GAMES 5/24/2016 Instructor: Santiago Ontañón santi@cs.drexel.edu Class website: https://www.cs.drexel.edu/~santi/teaching/2016/cs387/intro.html Reminders Check BBVista site for the
CS 387: GAME AI BOARD GAMES 5/24/2016 Instructor: Santiago Ontañón santi@cs.drexel.edu Class website: https://www.cs.drexel.edu/~santi/teaching/2016/cs387/intro.html Reminders Check BBVista site for the
Adversarial Search. Human-aware Robotics. 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: Slides for this lecture are here:
 Adversarial Search 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: q Slides for this lecture are here: http://www.public.asu.edu/~yzhan442/teaching/cse471/lectures/adversarial.pdf Slides are largely based
Adversarial Search 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: q Slides for this lecture are here: http://www.public.asu.edu/~yzhan442/teaching/cse471/lectures/adversarial.pdf Slides are largely based
Minimax Trees: Utility Evaluation, Tree Evaluation, Pruning
 Minimax Trees: Utility Evaluation, Tree Evaluation, Pruning CSCE 315 Programming Studio Fall 2017 Project 2, Lecture 2 Adapted from slides of Yoonsuck Choe, John Keyser Two-Person Perfect Information Deterministic
Minimax Trees: Utility Evaluation, Tree Evaluation, Pruning CSCE 315 Programming Studio Fall 2017 Project 2, Lecture 2 Adapted from slides of Yoonsuck Choe, John Keyser Two-Person Perfect Information Deterministic
Machine Learning and RF Spectrum Intelligence Gathering
 A CRFS White Paper December 2017 Machine Learning and RF Spectrum Intelligence Gathering Dr. Michael Knott Research Engineer CRFS Ltd. Contents Introduction 3 Guiding principles 3 Machine learning for
A CRFS White Paper December 2017 Machine Learning and RF Spectrum Intelligence Gathering Dr. Michael Knott Research Engineer CRFS Ltd. Contents Introduction 3 Guiding principles 3 Machine learning for
V. Adamchik Data Structures. Game Trees. Lecture 1. Apr. 05, Plan: 1. Introduction. 2. Game of NIM. 3. Minimax
 Game Trees Lecture 1 Apr. 05, 2005 Plan: 1. Introduction 2. Game of NIM 3. Minimax V. Adamchik 2 ü Introduction The search problems we have studied so far assume that the situation is not going to change.
Game Trees Lecture 1 Apr. 05, 2005 Plan: 1. Introduction 2. Game of NIM 3. Minimax V. Adamchik 2 ü Introduction The search problems we have studied so far assume that the situation is not going to change.
Radio Deep Learning Efforts Showcase Presentation
 Radio Deep Learning Efforts Showcase Presentation November 2016 hume@vt.edu www.hume.vt.edu Tim O Shea Senior Research Associate Program Overview Program Objective: Rethink fundamental approaches to how
Radio Deep Learning Efforts Showcase Presentation November 2016 hume@vt.edu www.hume.vt.edu Tim O Shea Senior Research Associate Program Overview Program Objective: Rethink fundamental approaches to how
Design and Implementation of Magic Chess
 Design and Implementation of Magic Chess Wen-Chih Chen 1, Shi-Jim Yen 2, Jr-Chang Chen 3, and Ching-Nung Lin 2 Abstract: Chinese dark chess is a stochastic game which is modified to a single-player puzzle
Design and Implementation of Magic Chess Wen-Chih Chen 1, Shi-Jim Yen 2, Jr-Chang Chen 3, and Ching-Nung Lin 2 Abstract: Chinese dark chess is a stochastic game which is modified to a single-player puzzle
MyPawns OppPawns MyKings OppKings MyThreatened OppThreatened MyWins OppWins Draws
 The Role of Opponent Skill Level in Automated Game Learning Ying Ge and Michael Hash Advisor: Dr. Mark Burge Armstrong Atlantic State University Savannah, Geogia USA 31419-1997 geying@drake.armstrong.edu
The Role of Opponent Skill Level in Automated Game Learning Ying Ge and Michael Hash Advisor: Dr. Mark Burge Armstrong Atlantic State University Savannah, Geogia USA 31419-1997 geying@drake.armstrong.edu
COMP219: COMP219: Artificial Intelligence Artificial Intelligence Dr. Annabel Latham Lecture 12: Game Playing Overview Games and Search
 COMP19: Artificial Intelligence COMP19: Artificial Intelligence Dr. Annabel Latham Room.05 Ashton Building Department of Computer Science University of Liverpool Lecture 1: Game Playing 1 Overview Last
COMP19: Artificial Intelligence COMP19: Artificial Intelligence Dr. Annabel Latham Room.05 Ashton Building Department of Computer Science University of Liverpool Lecture 1: Game Playing 1 Overview Last
CITS3001. Algorithms, Agents and Artificial Intelligence. Semester 2, 2016 Tim French
 CITS3001 Algorithms, Agents and Artificial Intelligence Semester 2, 2016 Tim French School of Computer Science & Software Eng. The University of Western Australia 8. Game-playing AIMA, Ch. 5 Objectives
CITS3001 Algorithms, Agents and Artificial Intelligence Semester 2, 2016 Tim French School of Computer Science & Software Eng. The University of Western Australia 8. Game-playing AIMA, Ch. 5 Objectives
Adversarial Search. CS 486/686: Introduction to Artificial Intelligence
 Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 Introduction So far we have only been concerned with a single agent Today, we introduce an adversary! 2 Outline Games Minimax search
Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 Introduction So far we have only been concerned with a single agent Today, we introduce an adversary! 2 Outline Games Minimax search
INTRODUCTION TO DEEP LEARNING. Steve Tjoa June 2013
 INTRODUCTION TO DEEP LEARNING Steve Tjoa kiemyang@gmail.com June 2013 Acknowledgements http://ufldl.stanford.edu/wiki/index.php/ UFLDL_Tutorial http://youtu.be/ayzoubkuf3m http://youtu.be/zmnoatzigik 2
INTRODUCTION TO DEEP LEARNING Steve Tjoa kiemyang@gmail.com June 2013 Acknowledgements http://ufldl.stanford.edu/wiki/index.php/ UFLDL_Tutorial http://youtu.be/ayzoubkuf3m http://youtu.be/zmnoatzigik 2
Game Playing. Garry Kasparov and Deep Blue. 1997, GM Gabriel Schwartzman's Chess Camera, courtesy IBM.
 Game Playing Garry Kasparov and Deep Blue. 1997, GM Gabriel Schwartzman's Chess Camera, courtesy IBM. Game Playing In most tree search scenarios, we have assumed the situation is not going to change whilst
Game Playing Garry Kasparov and Deep Blue. 1997, GM Gabriel Schwartzman's Chess Camera, courtesy IBM. Game Playing In most tree search scenarios, we have assumed the situation is not going to change whilst
Foundations of AI. 6. Board Games. Search Strategies for Games, Games with Chance, State of the Art
 Foundations of AI 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Andreas Karwath, Bernhard Nebel, and Martin Riedmiller SA-1 Contents Board Games Minimax
Foundations of AI 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Andreas Karwath, Bernhard Nebel, and Martin Riedmiller SA-1 Contents Board Games Minimax
Contents. Foundations of Artificial Intelligence. Problems. Why Board Games?
 Contents Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Bernhard Nebel, and Martin Riedmiller Albert-Ludwigs-Universität
Contents Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Bernhard Nebel, and Martin Riedmiller Albert-Ludwigs-Universität
Foundations of AI. 6. Adversarial Search. Search Strategies for Games, Games with Chance, State of the Art. Wolfram Burgard & Bernhard Nebel
 Foundations of AI 6. Adversarial Search Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard & Bernhard Nebel Contents Game Theory Board Games Minimax Search Alpha-Beta Search
Foundations of AI 6. Adversarial Search Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard & Bernhard Nebel Contents Game Theory Board Games Minimax Search Alpha-Beta Search
COMP219: Artificial Intelligence. Lecture 13: Game Playing
 CMP219: Artificial Intelligence Lecture 13: Game Playing 1 verview Last time Search with partial/no observations Belief states Incremental belief state search Determinism vs non-determinism Today We will
CMP219: Artificial Intelligence Lecture 13: Game Playing 1 verview Last time Search with partial/no observations Belief states Incremental belief state search Determinism vs non-determinism Today We will
An Introduction to Artificial Intelligence, Machine Learning, and Neural networks. Carola F. Berger
 An Introduction to Artificial Intelligence, Machine Learning, and Neural networks ATA58 Carola F. Berger Outline What is Artificial Intelligence (AI)? What does it do? How does it work? Will there be a
An Introduction to Artificial Intelligence, Machine Learning, and Neural networks ATA58 Carola F. Berger Outline What is Artificial Intelligence (AI)? What does it do? How does it work? Will there be a
Game Playing AI. Dr. Baldassano Yu s Elite Education
 Game Playing AI Dr. Baldassano chrisb@princeton.edu Yu s Elite Education Last 2 weeks recap: Graphs Graphs represent pairwise relationships Directed/undirected, weighted/unweights Common algorithms: Shortest
Game Playing AI Dr. Baldassano chrisb@princeton.edu Yu s Elite Education Last 2 weeks recap: Graphs Graphs represent pairwise relationships Directed/undirected, weighted/unweights Common algorithms: Shortest
Artificial Intelligence
 Artificial Intelligence CS482, CS682, MW 1 2:15, SEM 201, MS 227 Prerequisites: 302, 365 Instructor: Sushil Louis, sushil@cse.unr.edu, http://www.cse.unr.edu/~sushil Games and game trees Multi-agent systems
Artificial Intelligence CS482, CS682, MW 1 2:15, SEM 201, MS 227 Prerequisites: 302, 365 Instructor: Sushil Louis, sushil@cse.unr.edu, http://www.cse.unr.edu/~sushil Games and game trees Multi-agent systems
TEMPORAL DIFFERENCE LEARNING IN CHINESE CHESS
 TEMPORAL DIFFERENCE LEARNING IN CHINESE CHESS Thong B. Trinh, Anwer S. Bashi, Nikhil Deshpande Department of Electrical Engineering University of New Orleans New Orleans, LA 70148 Tel: (504) 280-7383 Fax:
TEMPORAL DIFFERENCE LEARNING IN CHINESE CHESS Thong B. Trinh, Anwer S. Bashi, Nikhil Deshpande Department of Electrical Engineering University of New Orleans New Orleans, LA 70148 Tel: (504) 280-7383 Fax:
Game Playing State-of-the-Art CSE 473: Artificial Intelligence Fall Deterministic Games. Zero-Sum Games 10/13/17. Adversarial Search
 CSE 473: Artificial Intelligence Fall 2017 Adversarial Search Mini, pruning, Expecti Dieter Fox Based on slides adapted Luke Zettlemoyer, Dan Klein, Pieter Abbeel, Dan Weld, Stuart Russell or Andrew Moore
CSE 473: Artificial Intelligence Fall 2017 Adversarial Search Mini, pruning, Expecti Dieter Fox Based on slides adapted Luke Zettlemoyer, Dan Klein, Pieter Abbeel, Dan Weld, Stuart Russell or Andrew Moore
Lecture 14. Questions? Friday, February 10 CS 430 Artificial Intelligence - Lecture 14 1
 Lecture 14 Questions? Friday, February 10 CS 430 Artificial Intelligence - Lecture 14 1 Outline Chapter 5 - Adversarial Search Alpha-Beta Pruning Imperfect Real-Time Decisions Stochastic Games Friday,
Lecture 14 Questions? Friday, February 10 CS 430 Artificial Intelligence - Lecture 14 1 Outline Chapter 5 - Adversarial Search Alpha-Beta Pruning Imperfect Real-Time Decisions Stochastic Games Friday,
6. Games. COMP9414/ 9814/ 3411: Artificial Intelligence. Outline. Mechanical Turk. Origins. origins. motivation. minimax search
 COMP9414/9814/3411 16s1 Games 1 COMP9414/ 9814/ 3411: Artificial Intelligence 6. Games Outline origins motivation Russell & Norvig, Chapter 5. minimax search resource limits and heuristic evaluation α-β
COMP9414/9814/3411 16s1 Games 1 COMP9414/ 9814/ 3411: Artificial Intelligence 6. Games Outline origins motivation Russell & Norvig, Chapter 5. minimax search resource limits and heuristic evaluation α-β
CSC 578 Neural Networks and Deep Learning
 CSC 578 Neural Networks and Deep Learning Fall 2018/19 6. Convolutional Neural Networks (Some figures adapted from NNDL book) 1 Convolution Neural Networks 1. Convolutional Neural Networks Convolution,
CSC 578 Neural Networks and Deep Learning Fall 2018/19 6. Convolutional Neural Networks (Some figures adapted from NNDL book) 1 Convolution Neural Networks 1. Convolutional Neural Networks Convolution,
GPU ACCELERATED DEEP LEARNING WITH CUDNN
 GPU ACCELERATED DEEP LEARNING WITH CUDNN Larry Brown Ph.D. March 2015 AGENDA 1 Introducing cudnn and GPUs 2 Deep Learning Context 3 cudnn V2 4 Using cudnn 2 Introducing cudnn and GPUs 3 HOW GPU ACCELERATION
GPU ACCELERATED DEEP LEARNING WITH CUDNN Larry Brown Ph.D. March 2015 AGENDA 1 Introducing cudnn and GPUs 2 Deep Learning Context 3 cudnn V2 4 Using cudnn 2 Introducing cudnn and GPUs 3 HOW GPU ACCELERATION
Adversarial Search Aka Games
 Adversarial Search Aka Games Chapter 5 Some material adopted from notes by Charles R. Dyer, U of Wisconsin-Madison Overview Game playing State of the art and resources Framework Game trees Minimax Alpha-beta
Adversarial Search Aka Games Chapter 5 Some material adopted from notes by Charles R. Dyer, U of Wisconsin-Madison Overview Game playing State of the art and resources Framework Game trees Minimax Alpha-beta
Chess Algorithms Theory and Practice. Rune Djurhuus Chess Grandmaster / September 23, 2013
 Chess Algorithms Theory and Practice Rune Djurhuus Chess Grandmaster runed@ifi.uio.no / runedj@microsoft.com September 23, 2013 1 Content Complexity of a chess game History of computer chess Search trees
Chess Algorithms Theory and Practice Rune Djurhuus Chess Grandmaster runed@ifi.uio.no / runedj@microsoft.com September 23, 2013 1 Content Complexity of a chess game History of computer chess Search trees
Adversarial Search. CS 486/686: Introduction to Artificial Intelligence
 Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 AccessAbility Services Volunteer Notetaker Required Interested? Complete an online application using your WATIAM: https://york.accessiblelearning.com/uwaterloo/
Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 AccessAbility Services Volunteer Notetaker Required Interested? Complete an online application using your WATIAM: https://york.accessiblelearning.com/uwaterloo/
Generating an appropriate sound for a video using WaveNet.
 Australian National University College of Engineering and Computer Science Master of Computing Generating an appropriate sound for a video using WaveNet. COMP 8715 Individual Computing Project Taku Ueki
Australian National University College of Engineering and Computer Science Master of Computing Generating an appropriate sound for a video using WaveNet. COMP 8715 Individual Computing Project Taku Ueki
History and Philosophical Underpinnings
 History and Philosophical Underpinnings Last Class Recap game-theory why normal search won t work minimax algorithm brute-force traversal of game tree for best move alpha-beta pruning how to improve on
History and Philosophical Underpinnings Last Class Recap game-theory why normal search won t work minimax algorithm brute-force traversal of game tree for best move alpha-beta pruning how to improve on
BayesChess: A computer chess program based on Bayesian networks
 BayesChess: A computer chess program based on Bayesian networks Antonio Fernández and Antonio Salmerón Department of Statistics and Applied Mathematics University of Almería Abstract In this paper we introduce
BayesChess: A computer chess program based on Bayesian networks Antonio Fernández and Antonio Salmerón Department of Statistics and Applied Mathematics University of Almería Abstract In this paper we introduce
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Adversarial Search Instructor: Stuart Russell University of California, Berkeley Game Playing State-of-the-Art Checkers: 1950: First computer player. 1959: Samuel s self-taught
CS 188: Artificial Intelligence Adversarial Search Instructor: Stuart Russell University of California, Berkeley Game Playing State-of-the-Art Checkers: 1950: First computer player. 1959: Samuel s self-taught
Deep learning with Othello
 COMP 4801 Final year Project Deep learning with Othello Application and analysis of deep neural networks and tree search on Othello Sun Peigen (3035084548) Worked with Nian Xiaodong (3035087112) and Xu
COMP 4801 Final year Project Deep learning with Othello Application and analysis of deep neural networks and tree search on Othello Sun Peigen (3035084548) Worked with Nian Xiaodong (3035087112) and Xu
Ar#ficial)Intelligence!!
Intelligence!!") Introduc*on! Ar#ficial)Intelligence!! Roman Barták Department of Theoretical Computer Science and Mathematical Logic So far we assumed a single-agent environment, but what if there are more agents and
Introduc*on! Ar#ficial)Intelligence!! Roman Barták Department of Theoretical Computer Science and Mathematical Logic So far we assumed a single-agent environment, but what if there are more agents and
CSE 40171: Artificial Intelligence. Adversarial Search: Games and Optimality
 CSE 40171: Artificial Intelligence Adversarial Search: Games and Optimality 1 What is a game? Game Playing State-of-the-Art Checkers: 1950: First computer player. 1994: First computer champion: Chinook
CSE 40171: Artificial Intelligence Adversarial Search: Games and Optimality 1 What is a game? Game Playing State-of-the-Art Checkers: 1950: First computer player. 1994: First computer champion: Chinook
Game Playing: Adversarial Search. Chapter 5
 Game Playing: Adversarial Search Chapter 5 Outline Games Perfect play minimax search α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information Games vs. Search
Game Playing: Adversarial Search Chapter 5 Outline Games Perfect play minimax search α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information Games vs. Search
The Art of Neural Nets
 The Art of Neural Nets Marco Tavora marcotav65@gmail.com Preamble The challenge of recognizing artists given their paintings has been, for a long time, far beyond the capability of algorithms. Recent advances
The Art of Neural Nets Marco Tavora marcotav65@gmail.com Preamble The challenge of recognizing artists given their paintings has been, for a long time, far beyond the capability of algorithms. Recent advances
CS 4700: Foundations of Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence selman@cs.cornell.edu Module: Adversarial Search R&N: Chapter 5 1 Outline Adversarial Search Optimal decisions Minimax α-β pruning Case study: Deep Blue
CS 4700: Foundations of Artificial Intelligence selman@cs.cornell.edu Module: Adversarial Search R&N: Chapter 5 1 Outline Adversarial Search Optimal decisions Minimax α-β pruning Case study: Deep Blue
Artificial Intelligence Adversarial Search
 Artificial Intelligence Adversarial Search Adversarial Search Adversarial search problems games They occur in multiagent competitive environments There is an opponent we can t control planning again us!
Artificial Intelligence Adversarial Search Adversarial Search Adversarial search problems games They occur in multiagent competitive environments There is an opponent we can t control planning again us!
CSE 40171: Artificial Intelligence. Adversarial Search: Game Trees, Alpha-Beta Pruning; Imperfect Decisions
 CSE 40171: Artificial Intelligence Adversarial Search: Game Trees, Alpha-Beta Pruning; Imperfect Decisions 30 4-2 4 max min -1-2 4 9??? Image credit: Dan Klein and Pieter Abbeel, UC Berkeley CS 188 31
CSE 40171: Artificial Intelligence Adversarial Search: Game Trees, Alpha-Beta Pruning; Imperfect Decisions 30 4-2 4 max min -1-2 4 9??? Image credit: Dan Klein and Pieter Abbeel, UC Berkeley CS 188 31
ELE 408 Final Project
 ELE 408 Final Project Chess AI game played over the Network Domenic Ferri Brandon Lian Project Goal: The project goal is to create a single player versus AI chess game using socket programming to establish
ELE 408 Final Project Chess AI game played over the Network Domenic Ferri Brandon Lian Project Goal: The project goal is to create a single player versus AI chess game using socket programming to establish
Today. Types of Game. Games and Search 1/18/2010. COMP210: Artificial Intelligence. Lecture 10. Game playing
 COMP10: Artificial Intelligence Lecture 10. Game playing Trevor Bench-Capon Room 15, Ashton Building Today We will look at how search can be applied to playing games Types of Games Perfect play minimax
COMP10: Artificial Intelligence Lecture 10. Game playing Trevor Bench-Capon Room 15, Ashton Building Today We will look at how search can be applied to playing games Types of Games Perfect play minimax
AI & Machine Learning. By Jan Øye Lindroos
 AI & Machine Learning By Jan Øye Lindroos About This Talk Brief introduction to AI: Definition and Characteristics Machine Learning: Types of ML, example algorithms Historical Overview: 1940-Present Present
AI & Machine Learning By Jan Øye Lindroos About This Talk Brief introduction to AI: Definition and Characteristics Machine Learning: Types of ML, example algorithms Historical Overview: 1940-Present Present
Game playing. Chapter 5, Sections 1 6
 Game playing Chapter 5, Sections 1 6 Artificial Intelligence, spring 2013, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 5, Sections 1 6 1 Outline Games Perfect play
Game playing Chapter 5, Sections 1 6 Artificial Intelligence, spring 2013, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 5, Sections 1 6 1 Outline Games Perfect play
Ch.4 AI and Games. Hantao Zhang. The University of Iowa Department of Computer Science. hzhang/c145
 Ch.4 AI and Games Hantao Zhang http://www.cs.uiowa.edu/ hzhang/c145 The University of Iowa Department of Computer Science Artificial Intelligence p.1/29 Chess: Computer vs. Human Deep Blue is a chess-playing
Ch.4 AI and Games Hantao Zhang http://www.cs.uiowa.edu/ hzhang/c145 The University of Iowa Department of Computer Science Artificial Intelligence p.1/29 Chess: Computer vs. Human Deep Blue is a chess-playing
Decoding Brainwave Data using Regression
 Decoding Brainwave Data using Regression Justin Kilmarx: The University of Tennessee, Knoxville David Saffo: Loyola University Chicago Lucien Ng: The Chinese University of Hong Kong Mentor: Dr. Xiaopeng
Decoding Brainwave Data using Regression Justin Kilmarx: The University of Tennessee, Knoxville David Saffo: Loyola University Chicago Lucien Ng: The Chinese University of Hong Kong Mentor: Dr. Xiaopeng
Adversarial Search. CMPSCI 383 September 29, 2011
 Adversarial Search CMPSCI 383 September 29, 2011 1 Why are games interesting to AI? Simple to represent and reason about Must consider the moves of an adversary Time constraints Russell & Norvig say: Games,
Adversarial Search CMPSCI 383 September 29, 2011 1 Why are games interesting to AI? Simple to represent and reason about Must consider the moves of an adversary Time constraints Russell & Norvig say: Games,
Introduction to Machine Learning
 Introduction to Machine Learning Deep Learning Barnabás Póczos Credits Many of the pictures, results, and other materials are taken from: Ruslan Salakhutdinov Joshua Bengio Geoffrey Hinton Yann LeCun 2
Introduction to Machine Learning Deep Learning Barnabás Póczos Credits Many of the pictures, results, and other materials are taken from: Ruslan Salakhutdinov Joshua Bengio Geoffrey Hinton Yann LeCun 2
Applying Modern Reinforcement Learning to Play Video Games. Computer Science & Engineering Leung Man Ho Supervisor: Prof. LYU Rung Tsong Michael
 Applying Modern Reinforcement Learning to Play Video Games Computer Science & Engineering Leung Man Ho Supervisor: Prof. LYU Rung Tsong Michael Outline Term 1 Review Term 2 Objectives Experiments & Results
Applying Modern Reinforcement Learning to Play Video Games Computer Science & Engineering Leung Man Ho Supervisor: Prof. LYU Rung Tsong Michael Outline Term 1 Review Term 2 Objectives Experiments & Results
Demystifying Machine Learning
 Demystifying Machine Learning By Simon Agius Muscat Software Engineer with RightBrain PyMalta, 19/07/18 http://www.rightbrain.com.mt 0. Talk outline 1. Explain the reasoning behind my talk 2. Defining
Demystifying Machine Learning By Simon Agius Muscat Software Engineer with RightBrain PyMalta, 19/07/18 http://www.rightbrain.com.mt 0. Talk outline 1. Explain the reasoning behind my talk 2. Defining
Recent Progress in Computer Go. Martin Müller University of Alberta Edmonton, Canada
 Recent Progress in Computer Go Martin Müller University of Alberta Edmonton, Canada 40 Years of Computer Go 1960 s: initial ideas 1970 s: first serious program - Reitman & Wilcox 1980 s: first PC programs,
Recent Progress in Computer Go Martin Müller University of Alberta Edmonton, Canada 40 Years of Computer Go 1960 s: initial ideas 1970 s: first serious program - Reitman & Wilcox 1980 s: first PC programs,
XiangQi Jing Sai Gui Ze 象棋竞赛规则 Laws of Xiangqi 2011 中国象棋协会审定
 XiangQi Jing Sai Gui Ze 象棋竞赛规则 Laws of Xiangqi 2011 中国象棋协会审定 UNOFFICIAL TRANSLATION by Jim Png Hau Cheng. Disclaimer: This translation below represent an individual s effort to try to help people who do
XiangQi Jing Sai Gui Ze 象棋竞赛规则 Laws of Xiangqi 2011 中国象棋协会审定 UNOFFICIAL TRANSLATION by Jim Png Hau Cheng. Disclaimer: This translation below represent an individual s effort to try to help people who do
Artificial Intelligence
 Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory AI Challenge One 140 Challenge 1 grades 120 100 80 60 AI Challenge One Transform to graph Explore the
Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory AI Challenge One 140 Challenge 1 grades 120 100 80 60 AI Challenge One Transform to graph Explore the
Lesson 08. Convolutional Neural Network. Ing. Marek Hrúz, Ph.D. Katedra Kybernetiky Fakulta aplikovaných věd Západočeská univerzita v Plzni.
 Lesson 08 Convolutional Neural Network Ing. Marek Hrúz, Ph.D. Katedra Kybernetiky Fakulta aplikovaných věd Západočeská univerzita v Plzni Lesson 08 Convolution we will consider 2D convolution the result
Lesson 08 Convolutional Neural Network Ing. Marek Hrúz, Ph.D. Katedra Kybernetiky Fakulta aplikovaných věd Západočeská univerzita v Plzni Lesson 08 Convolution we will consider 2D convolution the result
Decision Making in Multiplayer Environments Application in Backgammon Variants
 Decision Making in Multiplayer Environments Application in Backgammon Variants PhD Thesis by Nikolaos Papahristou AI researcher Department of Applied Informatics Thessaloniki, Greece Contributions Expert
Decision Making in Multiplayer Environments Application in Backgammon Variants PhD Thesis by Nikolaos Papahristou AI researcher Department of Applied Informatics Thessaloniki, Greece Contributions Expert
Data-Starved Artificial Intelligence
 Data-Starved Artificial Intelligence Data-Starved Artificial Intelligence This material is based upon work supported by the Assistant Secretary of Defense for Research and Engineering under Air Force Contract
Data-Starved Artificial Intelligence Data-Starved Artificial Intelligence This material is based upon work supported by the Assistant Secretary of Defense for Research and Engineering under Air Force Contract
Othello/Reversi using Game Theory techniques Parth Parekh Urjit Singh Bhatia Kushal Sukthankar
 Othello/Reversi using Game Theory techniques Parth Parekh Urjit Singh Bhatia Kushal Sukthankar Othello Rules Two Players (Black and White) 8x8 board Black plays first Every move should Flip over at least
Othello/Reversi using Game Theory techniques Parth Parekh Urjit Singh Bhatia Kushal Sukthankar Othello Rules Two Players (Black and White) 8x8 board Black plays first Every move should Flip over at least