CS 771 Artificial Intelligence. Adversarial Search
|
|
|
- Robyn Camilla Patrick
- 5 years ago
- Views:
Transcription
1 CS 771 Artificial Intelligence Adversarial Search
2 Typical assumptions Two agents whose actions alternate Utility values for each agent are the opposite of the other This creates the adversarial situation Fully observable environments In game theory terms: Deterministic, turn-taking, zero-sum games of perfect information Generalizes to stochastic games, multiple players, non zero-sum, etc.
3 Game tree (-player, deterministic, turns) How do we search this tree to find the optimal move?
4 Games Adversarial search or games are interesting because they are too hard to solve Chess has an average branching factor of 35 Games often go to 5 moves Search tree has about 35 1 or nodes (however search graph has about 1 4 distinct nodes) Games, like real world, therefore require the ability to make some decision even when the optimal decision is infeasible Games also penalize inefficiency severely
5 Why does efficiency matter? An implementation of A* search that is half as efficient will simple take twice as long to run to completion A chess program that is half as efficient in using its available time probably will be beaten into the ground, other things being equal Therefore, how to optimally use time is a very important issue Pruning allows ignore portion of the search tree that makes no difference to the final choice Heuristic evaluation functions allow us to approximate true utility of a state without doing a complete search
6 Search no adversary Search versus Games Solution is (heuristic) method for finding goal Heuristics and CSP techniques can find optimal solution Evaluation function: estimate of cost from start to goal through given node Examples: path planning, scheduling activities Games adversary Solution is strategy strategy specifies move for every possible opponent reply Time limits force an approximate solution Evaluation function: evaluate goodness of game position Examples: chess, checkers, Othello, backgammon
7 Two players: MAX and MIN Games as Search MAX moves first and they take turns until the game is over Winner gets reward, loser gets penalty Zero sum means the sum of the reward and the penalty is a constant Formal definition as a search problem: Initial state: Set-up specified by the rules, e.g., initial board configuration of chess. Player(s): Defines which player has the move in a state. Actions(s): Returns the set of legal moves in a state. Result(s,a): Transition model defines the result of a move. also refered to as Successor function: list of (move,state) pairs specifying legal moves. Terminal-Test(s): Is the game finished? True if finished, false otherwise. Utility function(s,p): Gives numerical value of terminal state s for player p. E.g., win (+1), lose (-1), and draw () in tic-tac-toe. E.g., win (+1), lose (), and draw (1/) in chess. MAX uses search tree to determine next move
8 Game tree (-player, deterministic, turns) How many terminal nodes does this search tree have? 9!=36,88 How do we search this tree to find the optimal move?
9 Optimal decisions in games In a normal search, optimal solution is a sequence of actions leading to a goal state,- a terminal state which is a win In adversarial search MIN has something to say about it MAX must find a contingent strategy, which specifies MAX s move in the initial state Then, MAX s moves in the states resulting from every possible response by MIN Then, MAX s move in the states resulting from every possible response by MIN to those moves, and so on
10 An optimal procedure: The Min-Max method Designed to find the optimal strategy for Max and find best move: 1. Generate the whole game tree, down to the leaves. Apply utility (payoff) function to each leaf 3. Back-up values from leaves through branch nodes: 1. a Max node computes the Max of its child values. a Min node computes the Min of its child values 4. At root: choose the move leading to the child of highest value
11 Game Trees - This game ends after one move each by MAX and MIN - In game parlance, we say that this tree is one move deep, consisting of each half moves, each of which is called a ply
12 The Min-Max method 1. Given a game tree, optimal strategy can be determined from the minimax value of each node, written as MINIMAX(n). The minimax value of a node is (for MAX) of being in the corresponding state,, assuming that both players play optimally its utility 3. Given a choice 1. MAX prefers to move to a state of maximum value. Whereas, MIN prefers a state of minimum value
13 Two-Ply Game Tree
14 Two-Ply Game Tree
15 Two-Ply Game Tree The minimax decision Minimax maximizes the utility for the worst-case outcome for max
16 Pseudocode for Minimax Algorithm function MINIMAX-DECISION(state) returns an action inputs: state, current state in game return arg max a ACTIONS(state) MIN-VALUE(Result(state,a)) function MAX-VALUE(state) returns a utility value if TERMINAL-TEST(state) then return UTILITY(state) v for a in ACTIONS(state) do v MAX(v,MIN-VALUE(Result(state,a))) return v function MIN-VALUE(state) returns a utility value if TERMINAL-TEST(state) then return UTILITY(state) v + for a in ACTIONS(state) do v MIN(v,MAX-VALUE(Result(state,a))) return v
17 Complete? Yes (if tree is finite) Optimal? Properties of Minimax Yes (against an optimal opponent). Can it be beaten by an opponent playing sub-optimally? No. (Why not?) Time complexity? O(b m ) Space complexity? O(bm) (depth-first search, generate all actions at once) O(m) (backtracking search, generate actions one at a time)
18 Game Tree Size Tic-Tac-Toe b 5 legal actions per state on average, total of 9 plies in game ply = one action by one player, move = two plies 5 9 = 1,953,15 9! = 36,88 (Computer goes first) 8! = 4,3 (Computer goes second) exact solution quite reasonable Chess b 35 (approximate average branching factor) d 1 (depth of game tree for typical game) b d nodes!! exact solution completely infeasible It is usually impossible to develop the whole search tree
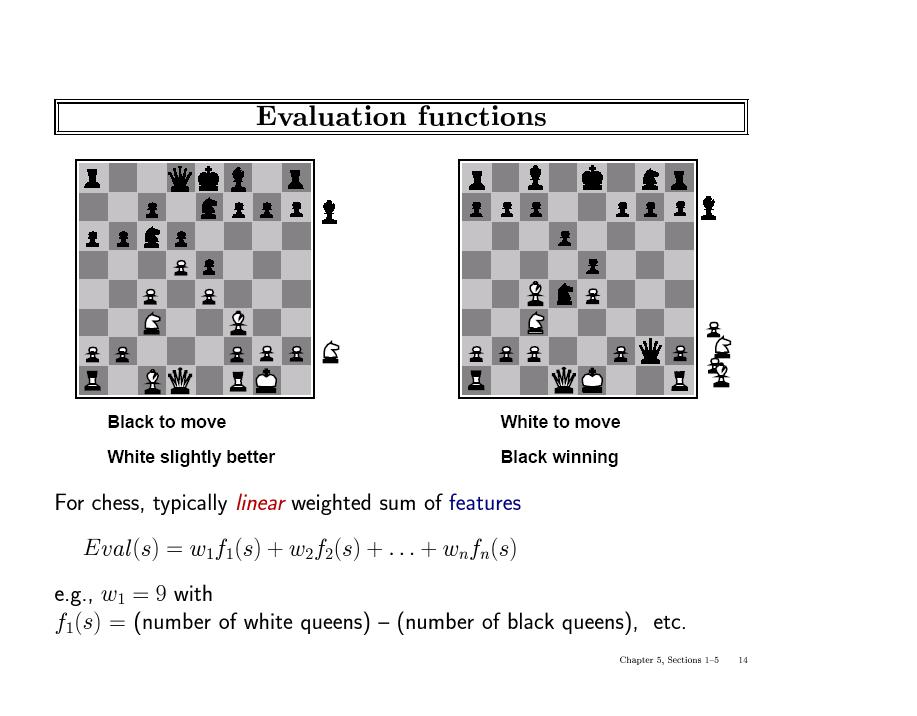
19 Static (Heuristic) Evaluation Functions An Evaluation Function: Estimates how good the current board configuration is for a player Typically, evaluates how good it is for the player, how good it is for the opponent, then subtract the opponent s score from the player s Othello: Number of white pieces - Number of black pieces Chess: Value of all white pieces - Value of all black pieces Typical values from -infinity (loss) to +infinity (win) or [-1, +1]. If the board evaluation is X for a player, it s -X for the opponent Zero-sum game
20
21
22 Applying MiniMax to tic-tac-toe The static evaluation function heuristic
23 Backup Values
24
25
26
27 Alpha-Beta Pruning Exploiting the Fact of an Adversary If a position is provably bad: It is NO USE expending search time to find out exactly how bad If the adversary can force a bad position: It is NO USE expending search time to find out the good positions that the adversary won t let you achieve anyway Bad = not better than we already know we can achieve elsewhere Contrast to normal search: ANY node might be a winner ALL nodes must be considered (A* avoids this through knowledge, i.e., heuristics)
28 Alpha-Beta Pruning Problem with minimax search is that number of game states it has to examine is exponential in the depth of the tree We can not eliminate the exponent, but can effectively cut it in half The trick is that it is possible to compute the correct minimax decision without looking at every node of the game tree One way to achieve this is to use alpha-beta pruning While applied to a standard minimax tree, it returns the same move as minimax would, but prunes away branches that can not possibly influence the final decision
29 Alpha-Beta Pruning The general principle is this Consider a node n somewhere in the tree such that the payer has an option to moving to that node If player has a better choice (node) m, either at the parent node of n or at any choice point further up then node n will never be reached in actual play So once we have found out enough about n to reach this conclusion (by examining some of its descendants), we can prune it
30 Alpha-Beta Example Do DF-search until first leaf Range of possible values [-,+ ] [-, + ]
31 Alpha-Beta Example [-,+ ] [-,3]
32 Alpha-Beta Example [-,+ ] [-,3]
33 Alpha-Beta Example [3,+ ] [3,3]
34 Alpha-Beta Example [3,+ ] [3,3]
35 Alpha-Beta Example [3,+ ] [3,3] [-,]
36 Alpha-Beta Example [3,+ ] T h i s n o d e i s w o r s e f o r M A X [3,3] [-,]
37 Alpha-Beta Example [3,14], [3,3] [-,] [-,14]
38 Alpha-Beta Example [3,5], [3,3] [,] [-,5]
39 Alpha-Beta Example [3,3] [3,3] [,] [,]
40 Alpha-Beta Example [3,3] [3,3] [-,] [,]
41 General alpha-beta pruning Consider a node n in the tree where the player has a choice of moving to n If player has a better choice m at: Parent node of n Or any choice point further up Then n will never be reached in play Hence, when that much is known about n, it can be pruned
42 Alpha-beta Algorithm Depth first search only considers nodes along a single path from root at any time a = highest-value choice found at any choice point of path for MAX (initially, a = infinity) b = lowest-value choice found at any choice point of path for MIN (initially, b = +infinity) Pass current values of a and b down to child nodes during search Update values of a and b during search: MAX updates a at MAX nodes MIN updates b at MIN nodes Prune remaining branches at a node when a b
43 When to Prune? Prune whenever a b Prune below a Max node whose alpha value becomes greater than or equal to the beta value of its ancestors Max nodes update alpha based on children s returned values Prune below a Min node whose beta value becomes less than or equal to the alpha value of its ancestors Min nodes update beta based on children s returned values
44 Alpha-Beta Example Revisited Do DF-search until first leaf a, b, initial values a= b =+ a, b, passed to kids a= b =+
45 Alpha-Beta Example Revisited a = highest-value choice found at any choice point of path for MAX (initially, a = infinity) b = lowest-value choice found at any choice point of path for MIN (initially, b = +infinity) a= b =+ a= b =3 MIN updates b, based on kids
46 Alpha-Beta Example Revisited a = highest-value choice found at any choice point of path for MAX (initially, a = infinity) b = lowest-value choice found at any choice point of path for MIN (initially, b = +infinity) a= b =+ a= b =3 MIN updates b, based on kids. No change.
47 Alpha-Beta Example Revisited a = highest-value choice found at any choice point of path for MAX (initially, a = infinity) b = lowest-value choice found at any choice point of path for MIN (initially, b = +infinity) MAX updates a, based on kids. a=3 b =+ 3 is returned as node value.
48 Alpha-Beta Example Revisited a = highest-value choice found at any choice point of path for MAX (initially, a = infinity) b = lowest-value choice found at any choice point of path for MIN (initially, b = +infinity) a=3 b =+ a, b, passed to kids a=3 b =+
49 Alpha-Beta Example Revisited a = highest-value choice found at any choice point of path for MAX (initially, a = infinity) b = lowest-value choice found at any choice point of path for MIN (initially, b = +infinity) a=3 b =+ MIN updates b, based on kids. a=3 b =
50 Alpha-Beta Example Revisited a = highest-value choice found at any choice point of path for MAX (initially, a = infinity) b = lowest-value choice found at any choice point of path for MIN (initially, b = +infinity) a=3 b =+ a=3 b = a b, so prune.
51 Alpha-Beta Example Revisited a = highest-value choice found at any choice point of path for MAX (initially, a = infinity) b = lowest-value choice found at any choice point of path for MIN (initially, b = +infinity) MAX updates a, based on kids. No change. a=3 b =+ is returned as node value.
52 Alpha-Beta Example Revisited a = highest-value choice found at any choice point of path for MAX (initially, a = infinity) b = lowest-value choice found at any choice point of path for MIN (initially, b = +infinity) a=3 b =+, a, b, passed to kids a=3 b =+
53 Alpha-Beta Example Revisited a = highest-value choice found at any choice point of path for MAX (initially, a = infinity) b = lowest-value choice found at any choice point of path for MIN (initially, b = +infinity) a=3 b =+, MIN updates b, based on kids. a=3 b =14
54 Alpha-Beta Example Revisited a = highest-value choice found at any choice point of path for MAX (initially, a = infinity) b = lowest-value choice found at any choice point of path for MIN (initially, b = +infinity) a=3 b =+, MIN updates b, based on kids. a=3 b =5
55 Alpha-Beta Example Revisited a = highest-value choice found at any choice point of path for MAX (initially, a = infinity) b = lowest-value choice found at any choice point of path for MIN (initially, b = +infinity) a=3 b =+ is returned as node value.
56 Alpha-Beta Example Revisited a = highest-value choice found at any choice point of path for MAX (initially, a = infinity) b = lowest-value choice found at any choice point of path for MIN (initially, b = +infinity) Max calculates the same node value, and makes the same move!
57 Example
58 Example
59 Example
60 Example
61 Example
62 Example
63 Example
64 Example
65 Example
66 Example
67 Example
68 Example
69 Example
70 Example
71 Example
72 Example
73 Example
74 Example
75 Example
76 Example
77 Example
78 Example
79 Example
80 Example
81 Example
82 Example
83 Example
84 Effectiveness of Alpha-Beta Search Worst-Case branches are ordered so that no pruning takes place. In this case alpha-beta gives no improvement over exhaustive search Best-Case each player s best move is the left-most child (i.e., evaluated first) in practice, performance is closer to best rather than worstcase In practice often get O(b (m/) ) rather than O(b m ) this is the same as having a branching factor of sqrt(b), (sqrt(b)) m = b (m/),i.e., we effectively go from b to square root of b e.g., in chess go from b ~ 35 to b ~ 6 this permits much deeper search in the same amount of time
85 Final Comments about Alpha-Beta Pruning Pruning does not affect final results Entire subtree can be pruned Good move ordering improves effectiveness of pruning Repeated states are again possible Store them in memory = transposition table
86 Pseudocode for Alpha-Beta Algorithm function ALPHA-BETA-SEARCH(state) returns an action inputs: state, current state in game v MAX-VALUE(state, -, + ) return the action in ACTIONS(state) with value v
87 Pseudocode for Alpha-Beta Algorithm function ALPHA-BETA-SEARCH(state) returns an action inputs: state, current state in game v MAX-VALUE(state, -, + ) return the action in ACTIONS(state) with value v function MAX-VALUE(state,a, b) returns a utility value if TERMINAL-TEST(state) then return UTILITY(state) v - for a in ACTIONS(state) do v MAX(v,MIN-VALUE(Result(s,a), a, b)) if v b then return v a MAX(a,v) return v (MIN-VALUE is defined analogously)
88 Example -which nodes can be pruned?
89 Answer to Example Max -which nodes can be pruned? Min Max Answer: NONE! Because the most favorable nodes for both are explored last (i.e., in the diagram, are on the right-hand side)
90 Second Example (the exact mirror image of the first example) -which nodes can be pruned?
91 Answer to Second Example (the exact mirror image of the first example) Max -which nodes can be pruned? Min Max Answer: LOTS! Because the most favorable nodes for both are explored first (i.e., in the diagram, are on the left-hand side)
92 The State of Play Checkers: Chinook ended 4-year-reign of human world champion Marion Tinsley in 1994 Chess: Deep Blue defeated human world champion Garry Kasparov in a six-game match in 1997 Othello: human champions refuse to compete against computers: they are too good Go: human champions refuse to compete against computers: they are too bad b > 3 (!) See (e.g.) for more information

93
94 Deep Blue 1957: Herbert Simon within 1 years a computer will beat the world chess champion 1997: Deep Blue beats Kasparov Parallel machine with 3 processors for software and 48 VLSI processors for hardware search Searched 16 million nodes per second on average Generated up to 3 billion positions per move Reached depth 14 routinely Uses iterative-deepening alpha-beta search with transpositioning Can explore beyond depth-limit for interesting moves
95 Summary Game playing is best modeled as a search problem Game trees represent alternate computer/opponent moves Evaluation functions estimate the quality of a given board configuration for the Max player Minimax is a procedure which chooses moves by assuming that the opponent will always choose the move which is best for them Alpha-Beta is a procedure which can prune large parts of the search tree and allow search to go deeper For many well-known games, computer algorithms based on heuristic search match or out-perform human world experts
Game-Playing & Adversarial Search
 Game-Playing & Adversarial Search This lecture topic: Game-Playing & Adversarial Search (two lectures) Chapter 5.1-5.5 Next lecture topic: Constraint Satisfaction Problems (two lectures) Chapter 6.1-6.4,
Game-Playing & Adversarial Search This lecture topic: Game-Playing & Adversarial Search (two lectures) Chapter 5.1-5.5 Next lecture topic: Constraint Satisfaction Problems (two lectures) Chapter 6.1-6.4,
Adversarial Search and Game- Playing C H A P T E R 6 C M P T : S P R I N G H A S S A N K H O S R A V I
 Adversarial Search and Game- Playing C H A P T E R 6 C M P T 3 1 0 : S P R I N G 2 0 1 1 H A S S A N K H O S R A V I Adversarial Search Examine the problems that arise when we try to plan ahead in a world
Adversarial Search and Game- Playing C H A P T E R 6 C M P T 3 1 0 : S P R I N G 2 0 1 1 H A S S A N K H O S R A V I Adversarial Search Examine the problems that arise when we try to plan ahead in a world
Game-Playing & Adversarial Search Alpha-Beta Pruning, etc.
 Game-Playing & Adversarial Search Alpha-Beta Pruning, etc. First Lecture Today (Tue 12 Jul) Read Chapter 5.1, 5.2, 5.4 Second Lecture Today (Tue 12 Jul) Read Chapter 5.3 (optional: 5.5+) Next Lecture (Thu
Game-Playing & Adversarial Search Alpha-Beta Pruning, etc. First Lecture Today (Tue 12 Jul) Read Chapter 5.1, 5.2, 5.4 Second Lecture Today (Tue 12 Jul) Read Chapter 5.3 (optional: 5.5+) Next Lecture (Thu
Game-playing AIs: Games and Adversarial Search FINAL SET (w/ pruning study examples) AIMA
 AIMA") Game-playing AIs: Games and Adversarial Search FINAL SET (w/ pruning study examples) AIMA 5.1-5.2 Games: Outline of Unit Part I: Games as Search Motivation Game-playing AI successes Game Trees Evaluation
Game-playing AIs: Games and Adversarial Search FINAL SET (w/ pruning study examples) AIMA 5.1-5.2 Games: Outline of Unit Part I: Games as Search Motivation Game-playing AI successes Game Trees Evaluation
Set 4: Game-Playing. ICS 271 Fall 2017 Kalev Kask
 Set 4: Game-Playing ICS 271 Fall 2017 Kalev Kask Overview Computer programs that play 2-player games game-playing as search with the complication of an opponent General principles of game-playing and search
Set 4: Game-Playing ICS 271 Fall 2017 Kalev Kask Overview Computer programs that play 2-player games game-playing as search with the complication of an opponent General principles of game-playing and search
Adversarial Search and Game Playing
 Games Adversarial Search and Game Playing Russell and Norvig, 3 rd edition, Ch. 5 Games: multi-agent environment q What do other agents do and how do they affect our success? q Cooperative vs. competitive
Games Adversarial Search and Game Playing Russell and Norvig, 3 rd edition, Ch. 5 Games: multi-agent environment q What do other agents do and how do they affect our success? q Cooperative vs. competitive
Games and Adversarial Search II
 Games and Adversarial Search II Alpha-Beta Pruning (AIMA 5.3) Some slides adapted from Richard Lathrop, USC/ISI, CS 271 Review: The Minimax Rule Idea: Make the best move for MAX assuming that MIN always
Games and Adversarial Search II Alpha-Beta Pruning (AIMA 5.3) Some slides adapted from Richard Lathrop, USC/ISI, CS 271 Review: The Minimax Rule Idea: Make the best move for MAX assuming that MIN always
Artificial Intelligence 1: game playing
 Artificial Intelligence 1: game playing Lecturer: Tom Lenaerts Institut de Recherches Interdisciplinaires et de Développements en Intelligence Artificielle (IRIDIA) Université Libre de Bruxelles Outline
Artificial Intelligence 1: game playing Lecturer: Tom Lenaerts Institut de Recherches Interdisciplinaires et de Développements en Intelligence Artificielle (IRIDIA) Université Libre de Bruxelles Outline
ARTIFICIAL INTELLIGENCE (CS 370D)
") Princess Nora University Faculty of Computer & Information Systems ARTIFICIAL INTELLIGENCE (CS 370D) (CHAPTER-5) ADVERSARIAL SEARCH ADVERSARIAL SEARCH Optimal decisions Min algorithm α-β pruning Imperfect,
Princess Nora University Faculty of Computer & Information Systems ARTIFICIAL INTELLIGENCE (CS 370D) (CHAPTER-5) ADVERSARIAL SEARCH ADVERSARIAL SEARCH Optimal decisions Min algorithm α-β pruning Imperfect,
Artificial Intelligence. Minimax and alpha-beta pruning
 Artificial Intelligence Minimax and alpha-beta pruning In which we examine the problems that arise when we try to plan ahead to get the best result in a world that includes a hostile agent (other agent
Artificial Intelligence Minimax and alpha-beta pruning In which we examine the problems that arise when we try to plan ahead to get the best result in a world that includes a hostile agent (other agent
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Adversarial Search Instructor: Stuart Russell University of California, Berkeley Game Playing State-of-the-Art Checkers: 1950: First computer player. 1959: Samuel s self-taught
CS 188: Artificial Intelligence Adversarial Search Instructor: Stuart Russell University of California, Berkeley Game Playing State-of-the-Art Checkers: 1950: First computer player. 1959: Samuel s self-taught
Adversarial Search. CMPSCI 383 September 29, 2011
 Adversarial Search CMPSCI 383 September 29, 2011 1 Why are games interesting to AI? Simple to represent and reason about Must consider the moves of an adversary Time constraints Russell & Norvig say: Games,
Adversarial Search CMPSCI 383 September 29, 2011 1 Why are games interesting to AI? Simple to represent and reason about Must consider the moves of an adversary Time constraints Russell & Norvig say: Games,
Artificial Intelligence Adversarial Search
 Artificial Intelligence Adversarial Search Adversarial Search Adversarial search problems games They occur in multiagent competitive environments There is an opponent we can t control planning again us!
Artificial Intelligence Adversarial Search Adversarial Search Adversarial search problems games They occur in multiagent competitive environments There is an opponent we can t control planning again us!
Adversarial Search. Soleymani. Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5
 Adversarial Search CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2017 Soleymani Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5 Outline Game
Adversarial Search CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2017 Soleymani Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5 Outline Game
Artificial Intelligence, CS, Nanjing University Spring, 2018, Yang Yu. Lecture 4: Search 3.
 Artificial Intelligence, CS, Nanjing University Spring, 2018, Yang Yu Lecture 4: Search 3 http://cs.nju.edu.cn/yuy/course_ai18.ashx Previously... Path-based search Uninformed search Depth-first, breadth
Artificial Intelligence, CS, Nanjing University Spring, 2018, Yang Yu Lecture 4: Search 3 http://cs.nju.edu.cn/yuy/course_ai18.ashx Previously... Path-based search Uninformed search Depth-first, breadth
Game Playing: Adversarial Search. Chapter 5
 Game Playing: Adversarial Search Chapter 5 Outline Games Perfect play minimax search α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information Games vs. Search
Game Playing: Adversarial Search Chapter 5 Outline Games Perfect play minimax search α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information Games vs. Search
Programming Project 1: Pacman (Due )
") Programming Project 1: Pacman (Due 8.2.18) Registration to the exams 521495A: Artificial Intelligence Adversarial Search (Min-Max) Lectured by Abdenour Hadid Adjunct Professor, CMVS, University of Oulu
Programming Project 1: Pacman (Due 8.2.18) Registration to the exams 521495A: Artificial Intelligence Adversarial Search (Min-Max) Lectured by Abdenour Hadid Adjunct Professor, CMVS, University of Oulu
Lecture 5: Game Playing (Adversarial Search)
") Lecture 5: Game Playing (Adversarial Search) CS 580 (001) - Spring 2018 Amarda Shehu Department of Computer Science George Mason University, Fairfax, VA, USA February 21, 2018 Amarda Shehu (580) 1 1 Outline
Lecture 5: Game Playing (Adversarial Search) CS 580 (001) - Spring 2018 Amarda Shehu Department of Computer Science George Mason University, Fairfax, VA, USA February 21, 2018 Amarda Shehu (580) 1 1 Outline
Adversarial Search. Human-aware Robotics. 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: Slides for this lecture are here:
 Adversarial Search 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: q Slides for this lecture are here: http://www.public.asu.edu/~yzhan442/teaching/cse471/lectures/adversarial.pdf Slides are largely based
Adversarial Search 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: q Slides for this lecture are here: http://www.public.asu.edu/~yzhan442/teaching/cse471/lectures/adversarial.pdf Slides are largely based
Adversarial Search 1
 Adversarial Search 1 Adversarial Search The ghosts trying to make pacman loose Can not come up with a giant program that plans to the end, because of the ghosts and their actions Goal: Eat lots of dots
Adversarial Search 1 Adversarial Search The ghosts trying to make pacman loose Can not come up with a giant program that plans to the end, because of the ghosts and their actions Goal: Eat lots of dots
Adversarial Search and Game Playing. Russell and Norvig: Chapter 5
 Adversarial Search and Game Playing Russell and Norvig: Chapter 5 Typical case 2-person game Players alternate moves Zero-sum: one player s loss is the other s gain Perfect information: both players have
Adversarial Search and Game Playing Russell and Norvig: Chapter 5 Typical case 2-person game Players alternate moves Zero-sum: one player s loss is the other s gain Perfect information: both players have
CS 380: ARTIFICIAL INTELLIGENCE ADVERSARIAL SEARCH. Santiago Ontañón
 CS 380: ARTIFICIAL INTELLIGENCE ADVERSARIAL SEARCH Santiago Ontañón so367@drexel.edu Recall: Problem Solving Idea: represent the problem we want to solve as: State space Actions Goal check Cost function
CS 380: ARTIFICIAL INTELLIGENCE ADVERSARIAL SEARCH Santiago Ontañón so367@drexel.edu Recall: Problem Solving Idea: represent the problem we want to solve as: State space Actions Goal check Cost function
CS 5522: Artificial Intelligence II
 CS 5522: Artificial Intelligence II Adversarial Search Instructor: Alan Ritter Ohio State University [These slides were adapted from CS188 Intro to AI at UC Berkeley. All materials available at http://ai.berkeley.edu.]
CS 5522: Artificial Intelligence II Adversarial Search Instructor: Alan Ritter Ohio State University [These slides were adapted from CS188 Intro to AI at UC Berkeley. All materials available at http://ai.berkeley.edu.]
Game Playing State-of-the-Art
 Adversarial Search [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188 materials are available at http://ai.berkeley.edu.] Game Playing State-of-the-Art
Adversarial Search [These slides were created by Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley. All CS188 materials are available at http://ai.berkeley.edu.] Game Playing State-of-the-Art
Game playing. Chapter 5. Chapter 5 1
 Game playing Chapter 5 Chapter 5 1 Outline Games Perfect play minimax decisions α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information Chapter 5 2 Types of
Game playing Chapter 5 Chapter 5 1 Outline Games Perfect play minimax decisions α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information Chapter 5 2 Types of
CSE 40171: Artificial Intelligence. Adversarial Search: Games and Optimality
 CSE 40171: Artificial Intelligence Adversarial Search: Games and Optimality 1 What is a game? Game Playing State-of-the-Art Checkers: 1950: First computer player. 1994: First computer champion: Chinook
CSE 40171: Artificial Intelligence Adversarial Search: Games and Optimality 1 What is a game? Game Playing State-of-the-Art Checkers: 1950: First computer player. 1994: First computer champion: Chinook
CS 188: Artificial Intelligence Spring Announcements
 CS 188: Artificial Intelligence Spring 2011 Lecture 7: Minimax and Alpha-Beta Search 2/9/2011 Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein 1 Announcements W1 out and due Monday 4:59pm P2
CS 188: Artificial Intelligence Spring 2011 Lecture 7: Minimax and Alpha-Beta Search 2/9/2011 Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein 1 Announcements W1 out and due Monday 4:59pm P2
Artificial Intelligence
 Artificial Intelligence Adversarial Search Instructors: David Suter and Qince Li Course Delivered @ Harbin Institute of Technology [Many slides adapted from those created by Dan Klein and Pieter Abbeel
Artificial Intelligence Adversarial Search Instructors: David Suter and Qince Li Course Delivered @ Harbin Institute of Technology [Many slides adapted from those created by Dan Klein and Pieter Abbeel
Game playing. Chapter 5, Sections 1 6
 Game playing Chapter 5, Sections 1 6 Artificial Intelligence, spring 2013, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 5, Sections 1 6 1 Outline Games Perfect play
Game playing Chapter 5, Sections 1 6 Artificial Intelligence, spring 2013, Peter Ljunglöf; based on AIMA Slides c Stuart Russel and Peter Norvig, 2004 Chapter 5, Sections 1 6 1 Outline Games Perfect play
Game Playing State of the Art
 Game Playing State of the Art Checkers: Chinook ended 40 year reign of human world champion Marion Tinsley in 1994. Used an endgame database defining perfect play for all positions involving 8 or fewer
Game Playing State of the Art Checkers: Chinook ended 40 year reign of human world champion Marion Tinsley in 1994. Used an endgame database defining perfect play for all positions involving 8 or fewer
CS 331: Artificial Intelligence Adversarial Search II. Outline
 CS 331: Artificial Intelligence Adversarial Search II 1 Outline 1. Evaluation Functions 2. State-of-the-art game playing programs 3. 2 player zero-sum finite stochastic games of perfect information 2 1
CS 331: Artificial Intelligence Adversarial Search II 1 Outline 1. Evaluation Functions 2. State-of-the-art game playing programs 3. 2 player zero-sum finite stochastic games of perfect information 2 1
mywbut.com Two agent games : alpha beta pruning
 Two agent games : alpha beta pruning 1 3.5 Alpha-Beta Pruning ALPHA-BETA pruning is a method that reduces the number of nodes explored in Minimax strategy. It reduces the time required for the search and
Two agent games : alpha beta pruning 1 3.5 Alpha-Beta Pruning ALPHA-BETA pruning is a method that reduces the number of nodes explored in Minimax strategy. It reduces the time required for the search and
CS 380: ARTIFICIAL INTELLIGENCE
 CS 380: ARTIFICIAL INTELLIGENCE ADVERSARIAL SEARCH 10/23/2013 Santiago Ontañón santi@cs.drexel.edu https://www.cs.drexel.edu/~santi/teaching/2013/cs380/intro.html Recall: Problem Solving Idea: represent
CS 380: ARTIFICIAL INTELLIGENCE ADVERSARIAL SEARCH 10/23/2013 Santiago Ontañón santi@cs.drexel.edu https://www.cs.drexel.edu/~santi/teaching/2013/cs380/intro.html Recall: Problem Solving Idea: represent
Game Playing State-of-the-Art. CS 188: Artificial Intelligence. Behavior from Computation. Video of Demo Mystery Pacman. Adversarial Search
 CS 188: Artificial Intelligence Adversarial Search Instructor: Marco Alvarez University of Rhode Island (These slides were created/modified by Dan Klein, Pieter Abbeel, Anca Dragan for CS188 at UC Berkeley)
CS 188: Artificial Intelligence Adversarial Search Instructor: Marco Alvarez University of Rhode Island (These slides were created/modified by Dan Klein, Pieter Abbeel, Anca Dragan for CS188 at UC Berkeley)
Game playing. Chapter 6. Chapter 6 1
 Game playing Chapter 6 Chapter 6 1 Outline Games Perfect play minimax decisions α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information Chapter 6 2 Games vs.
Game playing Chapter 6 Chapter 6 1 Outline Games Perfect play minimax decisions α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information Chapter 6 2 Games vs.
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Adversarial Search Prof. Scott Niekum The University of Texas at Austin [These slides are based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
CS 188: Artificial Intelligence Adversarial Search Prof. Scott Niekum The University of Texas at Austin [These slides are based on those of Dan Klein and Pieter Abbeel for CS188 Intro to AI at UC Berkeley.
Today. Types of Game. Games and Search 1/18/2010. COMP210: Artificial Intelligence. Lecture 10. Game playing
 COMP10: Artificial Intelligence Lecture 10. Game playing Trevor Bench-Capon Room 15, Ashton Building Today We will look at how search can be applied to playing games Types of Games Perfect play minimax
COMP10: Artificial Intelligence Lecture 10. Game playing Trevor Bench-Capon Room 15, Ashton Building Today We will look at how search can be applied to playing games Types of Games Perfect play minimax
Foundations of Artificial Intelligence
 Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Frank Hutter and Bernhard Nebel Albert-Ludwigs-Universität
Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Frank Hutter and Bernhard Nebel Albert-Ludwigs-Universität
Foundations of Artificial Intelligence
 Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Bernhard Nebel Albert-Ludwigs-Universität
Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Bernhard Nebel Albert-Ludwigs-Universität
Adversarial Search (Game Playing)
") Artificial Intelligence Adversarial Search (Game Playing) Chapter 5 Adapted from materials by Tim Finin, Marie desjardins, and Charles R. Dyer Outline Game playing State of the art and resources Framework
Artificial Intelligence Adversarial Search (Game Playing) Chapter 5 Adapted from materials by Tim Finin, Marie desjardins, and Charles R. Dyer Outline Game playing State of the art and resources Framework
Announcements. CS 188: Artificial Intelligence Spring Game Playing State-of-the-Art. Overview. Game Playing. GamesCrafters
 CS 188: Artificial Intelligence Spring 2011 Announcements W1 out and due Monday 4:59pm P2 out and due next week Friday 4:59pm Lecture 7: Mini and Alpha-Beta Search 2/9/2011 Pieter Abbeel UC Berkeley Many
CS 188: Artificial Intelligence Spring 2011 Announcements W1 out and due Monday 4:59pm P2 out and due next week Friday 4:59pm Lecture 7: Mini and Alpha-Beta Search 2/9/2011 Pieter Abbeel UC Berkeley Many
Adversarial Search: Game Playing. Reading: Chapter
 Adversarial Search: Game Playing Reading: Chapter 6.5-6.8 1 Games and AI Easy to represent, abstract, precise rules One of the first tasks undertaken by AI (since 1950) Better than humans in Othello and
Adversarial Search: Game Playing Reading: Chapter 6.5-6.8 1 Games and AI Easy to represent, abstract, precise rules One of the first tasks undertaken by AI (since 1950) Better than humans in Othello and
Adversarial Search. Hal Daumé III. Computer Science University of Maryland CS 421: Introduction to Artificial Intelligence 9 Feb 2012
 1 Hal Daumé III (me@hal3.name) Adversarial Search Hal Daumé III Computer Science University of Maryland me@hal3.name CS 421: Introduction to Artificial Intelligence 9 Feb 2012 Many slides courtesy of Dan
1 Hal Daumé III (me@hal3.name) Adversarial Search Hal Daumé III Computer Science University of Maryland me@hal3.name CS 421: Introduction to Artificial Intelligence 9 Feb 2012 Many slides courtesy of Dan
Adversarial Search. Read AIMA Chapter CIS 421/521 - Intro to AI 1
 Adversarial Search Read AIMA Chapter 5.2-5.5 CIS 421/521 - Intro to AI 1 Adversarial Search Instructors: Dan Klein and Pieter Abbeel University of California, Berkeley [These slides were created by Dan
Adversarial Search Read AIMA Chapter 5.2-5.5 CIS 421/521 - Intro to AI 1 Adversarial Search Instructors: Dan Klein and Pieter Abbeel University of California, Berkeley [These slides were created by Dan
COMP219: COMP219: Artificial Intelligence Artificial Intelligence Dr. Annabel Latham Lecture 12: Game Playing Overview Games and Search
 COMP19: Artificial Intelligence COMP19: Artificial Intelligence Dr. Annabel Latham Room.05 Ashton Building Department of Computer Science University of Liverpool Lecture 1: Game Playing 1 Overview Last
COMP19: Artificial Intelligence COMP19: Artificial Intelligence Dr. Annabel Latham Room.05 Ashton Building Department of Computer Science University of Liverpool Lecture 1: Game Playing 1 Overview Last
CSE 473: Artificial Intelligence. Outline
 CSE 473: Artificial Intelligence Adversarial Search Dan Weld Based on slides from Dan Klein, Stuart Russell, Pieter Abbeel, Andrew Moore and Luke Zettlemoyer (best illustrations from ai.berkeley.edu) 1
CSE 473: Artificial Intelligence Adversarial Search Dan Weld Based on slides from Dan Klein, Stuart Russell, Pieter Abbeel, Andrew Moore and Luke Zettlemoyer (best illustrations from ai.berkeley.edu) 1
Game Playing. Philipp Koehn. 29 September 2015
 Game Playing Philipp Koehn 29 September 2015 Outline 1 Games Perfect play minimax decisions α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information 2 games
Game Playing Philipp Koehn 29 September 2015 Outline 1 Games Perfect play minimax decisions α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information 2 games
Game playing. Outline
 Game playing Chapter 6, Sections 1 8 CS 480 Outline Perfect play Resource limits α β pruning Games of chance Games of imperfect information Games vs. search problems Unpredictable opponent solution is
Game playing Chapter 6, Sections 1 8 CS 480 Outline Perfect play Resource limits α β pruning Games of chance Games of imperfect information Games vs. search problems Unpredictable opponent solution is
Games vs. search problems. Game playing Chapter 6. Outline. Game tree (2-player, deterministic, turns) Types of games. Minimax
 Types of games. Minimax") Game playing Chapter 6 perfect information imperfect information Types of games deterministic chess, checkers, go, othello battleships, blind tictactoe chance backgammon monopoly bridge, poker, scrabble
Game playing Chapter 6 perfect information imperfect information Types of games deterministic chess, checkers, go, othello battleships, blind tictactoe chance backgammon monopoly bridge, poker, scrabble
CS 188: Artificial Intelligence Spring 2007
 CS 188: Artificial Intelligence Spring 2007 Lecture 7: CSP-II and Adversarial Search 2/6/2007 Srini Narayanan ICSI and UC Berkeley Many slides over the course adapted from Dan Klein, Stuart Russell or
CS 188: Artificial Intelligence Spring 2007 Lecture 7: CSP-II and Adversarial Search 2/6/2007 Srini Narayanan ICSI and UC Berkeley Many slides over the course adapted from Dan Klein, Stuart Russell or
Game playing. Chapter 6. Chapter 6 1
 Game playing Chapter 6 Chapter 6 1 Outline Games Perfect play minimax decisions α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information Chapter 6 2 Games vs.
Game playing Chapter 6 Chapter 6 1 Outline Games Perfect play minimax decisions α β pruning Resource limits and approximate evaluation Games of chance Games of imperfect information Chapter 6 2 Games vs.
CS 2710 Foundations of AI. Lecture 9. Adversarial search. CS 2710 Foundations of AI. Game search
 CS 2710 Foundations of AI Lecture 9 Adversarial search Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square CS 2710 Foundations of AI Game search Game-playing programs developed by AI researchers since
CS 2710 Foundations of AI Lecture 9 Adversarial search Milos Hauskrecht milos@cs.pitt.edu 5329 Sennott Square CS 2710 Foundations of AI Game search Game-playing programs developed by AI researchers since
Games CSE 473. Kasparov Vs. Deep Junior August 2, 2003 Match ends in a 3 / 3 tie!
 Games CSE 473 Kasparov Vs. Deep Junior August 2, 2003 Match ends in a 3 / 3 tie! Games in AI In AI, games usually refers to deteristic, turntaking, two-player, zero-sum games of perfect information Deteristic:
Games CSE 473 Kasparov Vs. Deep Junior August 2, 2003 Match ends in a 3 / 3 tie! Games in AI In AI, games usually refers to deteristic, turntaking, two-player, zero-sum games of perfect information Deteristic:
Artificial Intelligence
 Artificial Intelligence Adversarial Search Vibhav Gogate The University of Texas at Dallas Some material courtesy of Rina Dechter, Alex Ihler and Stuart Russell, Luke Zettlemoyer, Dan Weld Adversarial
Artificial Intelligence Adversarial Search Vibhav Gogate The University of Texas at Dallas Some material courtesy of Rina Dechter, Alex Ihler and Stuart Russell, Luke Zettlemoyer, Dan Weld Adversarial
Lecture 14. Questions? Friday, February 10 CS 430 Artificial Intelligence - Lecture 14 1
 Lecture 14 Questions? Friday, February 10 CS 430 Artificial Intelligence - Lecture 14 1 Outline Chapter 5 - Adversarial Search Alpha-Beta Pruning Imperfect Real-Time Decisions Stochastic Games Friday,
Lecture 14 Questions? Friday, February 10 CS 430 Artificial Intelligence - Lecture 14 1 Outline Chapter 5 - Adversarial Search Alpha-Beta Pruning Imperfect Real-Time Decisions Stochastic Games Friday,
Adversarial Search Aka Games
 Adversarial Search Aka Games Chapter 5 Some material adopted from notes by Charles R. Dyer, U of Wisconsin-Madison Overview Game playing State of the art and resources Framework Game trees Minimax Alpha-beta
Adversarial Search Aka Games Chapter 5 Some material adopted from notes by Charles R. Dyer, U of Wisconsin-Madison Overview Game playing State of the art and resources Framework Game trees Minimax Alpha-beta
Game Playing. Why do AI researchers study game playing? 1. It s a good reasoning problem, formal and nontrivial.
 Game Playing Why do AI researchers study game playing? 1. It s a good reasoning problem, formal and nontrivial. 2. Direct comparison with humans and other computer programs is easy. 1 What Kinds of Games?
Game Playing Why do AI researchers study game playing? 1. It s a good reasoning problem, formal and nontrivial. 2. Direct comparison with humans and other computer programs is easy. 1 What Kinds of Games?
Games vs. search problems. Adversarial Search. Types of games. Outline
 Games vs. search problems Unpredictable opponent solution is a strategy specifying a move for every possible opponent reply dversarial Search Chapter 5 Time limits unlikely to find goal, must approximate
Games vs. search problems Unpredictable opponent solution is a strategy specifying a move for every possible opponent reply dversarial Search Chapter 5 Time limits unlikely to find goal, must approximate
Artificial Intelligence. Topic 5. Game playing
 Artificial Intelligence Topic 5 Game playing broadening our world view dealing with incompleteness why play games? perfect decisions the Minimax algorithm dealing with resource limits evaluation functions
Artificial Intelligence Topic 5 Game playing broadening our world view dealing with incompleteness why play games? perfect decisions the Minimax algorithm dealing with resource limits evaluation functions
ADVERSARIAL SEARCH. Today. Reading. Goals. AIMA Chapter , 5.7,5.8
 ADVERSARIAL SEARCH Today Reading AIMA Chapter 5.1-5.5, 5.7,5.8 Goals Introduce adversarial games Minimax as an optimal strategy Alpha-beta pruning (Real-time decisions) 1 Questions to ask Were there any
ADVERSARIAL SEARCH Today Reading AIMA Chapter 5.1-5.5, 5.7,5.8 Goals Introduce adversarial games Minimax as an optimal strategy Alpha-beta pruning (Real-time decisions) 1 Questions to ask Were there any
Game Playing State-of-the-Art CSE 473: Artificial Intelligence Fall Deterministic Games. Zero-Sum Games 10/13/17. Adversarial Search
 CSE 473: Artificial Intelligence Fall 2017 Adversarial Search Mini, pruning, Expecti Dieter Fox Based on slides adapted Luke Zettlemoyer, Dan Klein, Pieter Abbeel, Dan Weld, Stuart Russell or Andrew Moore
CSE 473: Artificial Intelligence Fall 2017 Adversarial Search Mini, pruning, Expecti Dieter Fox Based on slides adapted Luke Zettlemoyer, Dan Klein, Pieter Abbeel, Dan Weld, Stuart Russell or Andrew Moore
CS 188: Artificial Intelligence Spring Game Playing in Practice
 CS 188: Artificial Intelligence Spring 2006 Lecture 23: Games 4/18/2006 Dan Klein UC Berkeley Game Playing in Practice Checkers: Chinook ended 40-year-reign of human world champion Marion Tinsley in 1994.
CS 188: Artificial Intelligence Spring 2006 Lecture 23: Games 4/18/2006 Dan Klein UC Berkeley Game Playing in Practice Checkers: Chinook ended 40-year-reign of human world champion Marion Tinsley in 1994.
CS 188: Artificial Intelligence. Overview
 CS 188: Artificial Intelligence Lecture 6 and 7: Search for Games Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein 1 Overview Deterministic zero-sum games Minimax Limited depth and evaluation
CS 188: Artificial Intelligence Lecture 6 and 7: Search for Games Pieter Abbeel UC Berkeley Many slides adapted from Dan Klein 1 Overview Deterministic zero-sum games Minimax Limited depth and evaluation
ADVERSARIAL SEARCH 5.1 GAMES
 5 DVERSRIL SERCH In which we examine the problems that arise when we try to plan ahead in a world where other agents are planning against us. 5.1 GMES GME ZERO-SUM GMES PERFECT INFORMTION Chapter 2 introduced
5 DVERSRIL SERCH In which we examine the problems that arise when we try to plan ahead in a world where other agents are planning against us. 5.1 GMES GME ZERO-SUM GMES PERFECT INFORMTION Chapter 2 introduced
CS 1571 Introduction to AI Lecture 12. Adversarial search. CS 1571 Intro to AI. Announcements
 CS 171 Introduction to AI Lecture 1 Adversarial search Milos Hauskrecht milos@cs.pitt.edu 39 Sennott Square Announcements Homework assignment is out Programming and experiments Simulated annealing + Genetic
CS 171 Introduction to AI Lecture 1 Adversarial search Milos Hauskrecht milos@cs.pitt.edu 39 Sennott Square Announcements Homework assignment is out Programming and experiments Simulated annealing + Genetic
Contents. Foundations of Artificial Intelligence. Problems. Why Board Games?
 Contents Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Bernhard Nebel, and Martin Riedmiller Albert-Ludwigs-Universität
Contents Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Bernhard Nebel, and Martin Riedmiller Albert-Ludwigs-Universität
Adversarial search (game playing)
") Adversarial search (game playing) References Russell and Norvig, Artificial Intelligence: A modern approach, 2nd ed. Prentice Hall, 2003 Nilsson, Artificial intelligence: A New synthesis. McGraw Hill,
Adversarial search (game playing) References Russell and Norvig, Artificial Intelligence: A modern approach, 2nd ed. Prentice Hall, 2003 Nilsson, Artificial intelligence: A New synthesis. McGraw Hill,
Game-playing AIs: Games and Adversarial Search I AIMA
 Game-playing AIs: Games and Adversarial Search I AIMA 5.1-5.2 Games: Outline of Unit Part I: Games as Search Motivation Game-playing AI successes Game Trees Evaluation Functions Part II: Adversarial Search
Game-playing AIs: Games and Adversarial Search I AIMA 5.1-5.2 Games: Outline of Unit Part I: Games as Search Motivation Game-playing AI successes Game Trees Evaluation Functions Part II: Adversarial Search
Game Playing AI Class 8 Ch , 5.4.1, 5.5
 Game Playing AI Class Ch. 5.-5., 5.4., 5.5 Bookkeeping HW Due 0/, :59pm Remaining CSP questions? Cynthia Matuszek CMSC 6 Based on slides by Marie desjardin, Francisco Iacobelli Today s Class Clear criteria
Game Playing AI Class Ch. 5.-5., 5.4., 5.5 Bookkeeping HW Due 0/, :59pm Remaining CSP questions? Cynthia Matuszek CMSC 6 Based on slides by Marie desjardin, Francisco Iacobelli Today s Class Clear criteria
Intuition Mini-Max 2
 Games Today Saying Deep Blue doesn t really think about chess is like saying an airplane doesn t really fly because it doesn t flap its wings. Drew McDermott I could feel I could smell a new kind of intelligence
Games Today Saying Deep Blue doesn t really think about chess is like saying an airplane doesn t really fly because it doesn t flap its wings. Drew McDermott I could feel I could smell a new kind of intelligence
CPS331 Lecture: Search in Games last revised 2/16/10
 CPS331 Lecture: Search in Games last revised 2/16/10 Objectives: 1. To introduce mini-max search 2. To introduce the use of static evaluation functions 3. To introduce alpha-beta pruning Materials: 1.
CPS331 Lecture: Search in Games last revised 2/16/10 Objectives: 1. To introduce mini-max search 2. To introduce the use of static evaluation functions 3. To introduce alpha-beta pruning Materials: 1.
Last update: March 9, Game playing. CMSC 421, Chapter 6. CMSC 421, Chapter 6 1
 Last update: March 9, 2010 Game playing CMSC 421, Chapter 6 CMSC 421, Chapter 6 1 Finite perfect-information zero-sum games Finite: finitely many agents, actions, states Perfect information: every agent
Last update: March 9, 2010 Game playing CMSC 421, Chapter 6 CMSC 421, Chapter 6 1 Finite perfect-information zero-sum games Finite: finitely many agents, actions, states Perfect information: every agent
Announcements. Homework 1. Project 1. Due tonight at 11:59pm. Due Friday 2/8 at 4:00pm. Electronic HW1 Written HW1
 Announcements Homework 1 Due tonight at 11:59pm Project 1 Electronic HW1 Written HW1 Due Friday 2/8 at 4:00pm CS 188: Artificial Intelligence Adversarial Search and Game Trees Instructors: Sergey Levine
Announcements Homework 1 Due tonight at 11:59pm Project 1 Electronic HW1 Written HW1 Due Friday 2/8 at 4:00pm CS 188: Artificial Intelligence Adversarial Search and Game Trees Instructors: Sergey Levine
Adversarial Search Lecture 7
 Lecture 7 How can we use search to plan ahead when other agents are planning against us? 1 Agenda Games: context, history Searching via Minimax Scaling α β pruning Depth-limiting Evaluation functions Handling
Lecture 7 How can we use search to plan ahead when other agents are planning against us? 1 Agenda Games: context, history Searching via Minimax Scaling α β pruning Depth-limiting Evaluation functions Handling
Games we will consider. CS 331: Artificial Intelligence Adversarial Search. What makes games hard? Formal Definition of a Game.
 Games we will consider CS 331: rtificial ntelligence dversarial Search Deterministic Discrete states and decisions Finite number of states and decisions Perfect information i.e. fully observable Two agents
Games we will consider CS 331: rtificial ntelligence dversarial Search Deterministic Discrete states and decisions Finite number of states and decisions Perfect information i.e. fully observable Two agents
School of EECS Washington State University. Artificial Intelligence
 School of EECS Washington State University Artificial Intelligence 1 } Classic AI challenge Easy to represent Difficult to solve } Zero-sum games Total final reward to all players is constant } Perfect
School of EECS Washington State University Artificial Intelligence 1 } Classic AI challenge Easy to represent Difficult to solve } Zero-sum games Total final reward to all players is constant } Perfect
CS 440 / ECE 448 Introduction to Artificial Intelligence Spring 2010 Lecture #5
 CS 440 / ECE 448 Introduction to Artificial Intelligence Spring 2010 Lecture #5 Instructor: Eyal Amir Grad TAs: Wen Pu, Yonatan Bisk Undergrad TAs: Sam Johnson, Nikhil Johri Topics Game playing Game trees
CS 440 / ECE 448 Introduction to Artificial Intelligence Spring 2010 Lecture #5 Instructor: Eyal Amir Grad TAs: Wen Pu, Yonatan Bisk Undergrad TAs: Sam Johnson, Nikhil Johri Topics Game playing Game trees
Adversary Search. Ref: Chapter 5
 Adversary Search Ref: Chapter 5 1 Games & A.I. Easy to measure success Easy to represent states Small number of operators Comparison against humans is possible. Many games can be modeled very easily, although
Adversary Search Ref: Chapter 5 1 Games & A.I. Easy to measure success Easy to represent states Small number of operators Comparison against humans is possible. Many games can be modeled very easily, although
CSE 573: Artificial Intelligence Autumn 2010
 CSE 573: Artificial Intelligence Autumn 2010 Lecture 4: Adversarial Search 10/12/2009 Luke Zettlemoyer Based on slides from Dan Klein Many slides over the course adapted from either Stuart Russell or Andrew
CSE 573: Artificial Intelligence Autumn 2010 Lecture 4: Adversarial Search 10/12/2009 Luke Zettlemoyer Based on slides from Dan Klein Many slides over the course adapted from either Stuart Russell or Andrew
ADVERSARIAL SEARCH. Today. Reading. Goals. AIMA Chapter Read , Skim 5.7
 ADVERSARIAL SEARCH Today Reading AIMA Chapter Read 5.1-5.5, Skim 5.7 Goals Introduce adversarial games Minimax as an optimal strategy Alpha-beta pruning 1 Adversarial Games People like games! Games are
ADVERSARIAL SEARCH Today Reading AIMA Chapter Read 5.1-5.5, Skim 5.7 Goals Introduce adversarial games Minimax as an optimal strategy Alpha-beta pruning 1 Adversarial Games People like games! Games are
Adversarial Search. Chapter 5. Mausam (Based on slides of Stuart Russell, Andrew Parks, Henry Kautz, Linda Shapiro) 1
 1") Adversarial Search Chapter 5 Mausam (Based on slides of Stuart Russell, Andrew Parks, Henry Kautz, Linda Shapiro) 1 Game Playing Why do AI researchers study game playing? 1. It s a good reasoning problem,
Adversarial Search Chapter 5 Mausam (Based on slides of Stuart Russell, Andrew Parks, Henry Kautz, Linda Shapiro) 1 Game Playing Why do AI researchers study game playing? 1. It s a good reasoning problem,
ADVERSARIAL SEARCH. Chapter 5
 ADVERSARIAL SEARCH Chapter 5... every game of skill is susceptible of being played by an automaton. from Charles Babbage, The Life of a Philosopher, 1832. Outline Games Perfect play minimax decisions α
ADVERSARIAL SEARCH Chapter 5... every game of skill is susceptible of being played by an automaton. from Charles Babbage, The Life of a Philosopher, 1832. Outline Games Perfect play minimax decisions α
CS 331: Artificial Intelligence Adversarial Search. Games we will consider
 CS 331: rtificial ntelligence dversarial Search 1 Games we will consider Deterministic Discrete states and decisions Finite number of states and decisions Perfect information ie. fully observable Two agents
CS 331: rtificial ntelligence dversarial Search 1 Games we will consider Deterministic Discrete states and decisions Finite number of states and decisions Perfect information ie. fully observable Two agents
Game Playing. Dr. Richard J. Povinelli. Page 1. rev 1.1, 9/14/2003
 Game Playing Dr. Richard J. Povinelli rev 1.1, 9/14/2003 Page 1 Objectives You should be able to provide a definition of a game. be able to evaluate, compare, and implement the minmax and alpha-beta algorithms,
Game Playing Dr. Richard J. Povinelli rev 1.1, 9/14/2003 Page 1 Objectives You should be able to provide a definition of a game. be able to evaluate, compare, and implement the minmax and alpha-beta algorithms,
COMP219: Artificial Intelligence. Lecture 13: Game Playing
 CMP219: Artificial Intelligence Lecture 13: Game Playing 1 verview Last time Search with partial/no observations Belief states Incremental belief state search Determinism vs non-determinism Today We will
CMP219: Artificial Intelligence Lecture 13: Game Playing 1 verview Last time Search with partial/no observations Belief states Incremental belief state search Determinism vs non-determinism Today We will
Outline. Game playing. Types of games. Games vs. search problems. Minimax. Game tree (2-player, deterministic, turns) Games
 Games") utline Games Game playing Perfect play minimax decisions α β pruning Resource limits and approximate evaluation Chapter 6 Games of chance Games of imperfect information Chapter 6 Chapter 6 Games vs. search
utline Games Game playing Perfect play minimax decisions α β pruning Resource limits and approximate evaluation Chapter 6 Games of chance Games of imperfect information Chapter 6 Chapter 6 Games vs. search
The very people who admit students into the ICS graduate programs will give advice and answer questions about graduate school applications.
 ICS FACULTY PANEL ON IMPROVING YOUR GRADUATE SCHOOL APPLICATION Wednesday, 18 Oct., 2017, 11:00am-12:50pm, in DBH-011 **** Pizza, soft drinks, and refreshments will be served. **** Wondering what to do
ICS FACULTY PANEL ON IMPROVING YOUR GRADUATE SCHOOL APPLICATION Wednesday, 18 Oct., 2017, 11:00am-12:50pm, in DBH-011 **** Pizza, soft drinks, and refreshments will be served. **** Wondering what to do
Local Search. Hill Climbing. Hill Climbing Diagram. Simulated Annealing. Simulated Annealing. Introduction to Artificial Intelligence
 Introduction to Artificial Intelligence V22.0472-001 Fall 2009 Lecture 6: Adversarial Search Local Search Queue-based algorithms keep fallback options (backtracking) Local search: improve what you have
Introduction to Artificial Intelligence V22.0472-001 Fall 2009 Lecture 6: Adversarial Search Local Search Queue-based algorithms keep fallback options (backtracking) Local search: improve what you have
CS 4700: Foundations of Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence selman@cs.cornell.edu Module: Adversarial Search R&N: Chapter 5 1 Outline Adversarial Search Optimal decisions Minimax α-β pruning Case study: Deep Blue
CS 4700: Foundations of Artificial Intelligence selman@cs.cornell.edu Module: Adversarial Search R&N: Chapter 5 1 Outline Adversarial Search Optimal decisions Minimax α-β pruning Case study: Deep Blue
Adversarial Search. Rob Platt Northeastern University. Some images and slides are used from: AIMA CS188 UC Berkeley
 Adversarial Search Rob Platt Northeastern University Some images and slides are used from: AIMA CS188 UC Berkeley What is adversarial search? Adversarial search: planning used to play a game such as chess
Adversarial Search Rob Platt Northeastern University Some images and slides are used from: AIMA CS188 UC Berkeley What is adversarial search? Adversarial search: planning used to play a game such as chess
Outline. Game Playing. Game Problems. Game Problems. Types of games Playing a perfect game. Playing an imperfect game
 Outline Game Playing ECE457 Applied Artificial Intelligence Fall 2007 Lecture #5 Types of games Playing a perfect game Minimax search Alpha-beta pruning Playing an imperfect game Real-time Imperfect information
Outline Game Playing ECE457 Applied Artificial Intelligence Fall 2007 Lecture #5 Types of games Playing a perfect game Minimax search Alpha-beta pruning Playing an imperfect game Real-time Imperfect information
Computer Science and Software Engineering University of Wisconsin - Platteville. 4. Game Play. CS 3030 Lecture Notes Yan Shi UW-Platteville
 Computer Science and Software Engineering University of Wisconsin - Platteville 4. Game Play CS 3030 Lecture Notes Yan Shi UW-Platteville Read: Textbook Chapter 6 What kind of games? 2-player games Zero-sum
Computer Science and Software Engineering University of Wisconsin - Platteville 4. Game Play CS 3030 Lecture Notes Yan Shi UW-Platteville Read: Textbook Chapter 6 What kind of games? 2-player games Zero-sum
Ch.4 AI and Games. Hantao Zhang. The University of Iowa Department of Computer Science. hzhang/c145
 Ch.4 AI and Games Hantao Zhang http://www.cs.uiowa.edu/ hzhang/c145 The University of Iowa Department of Computer Science Artificial Intelligence p.1/29 Chess: Computer vs. Human Deep Blue is a chess-playing
Ch.4 AI and Games Hantao Zhang http://www.cs.uiowa.edu/ hzhang/c145 The University of Iowa Department of Computer Science Artificial Intelligence p.1/29 Chess: Computer vs. Human Deep Blue is a chess-playing
Artificial Intelligence Search III
 Artificial Intelligence Search III Lecture 5 Content: Search III Quick Review on Lecture 4 Why Study Games? Game Playing as Search Special Characteristics of Game Playing Search Ingredients of 2-Person
Artificial Intelligence Search III Lecture 5 Content: Search III Quick Review on Lecture 4 Why Study Games? Game Playing as Search Special Characteristics of Game Playing Search Ingredients of 2-Person
ADVERSARIAL SEARCH 5.1 GAMES
 5 ADVERSARIAL SEARCH In which we examine the problems that arise when we try to plan ahead in a world where other agents are planning against us. 5.1 GAMES GAME ZERO-SUM GAMES PERFECT INFORMATION Chapter
5 ADVERSARIAL SEARCH In which we examine the problems that arise when we try to plan ahead in a world where other agents are planning against us. 5.1 GAMES GAME ZERO-SUM GAMES PERFECT INFORMATION Chapter
Games (adversarial search problems)
") Mustafa Jarrar: Lecture Notes on Games, Birzeit University, Palestine Fall Semester, 204 Artificial Intelligence Chapter 6 Games (adversarial search problems) Dr. Mustafa Jarrar Sina Institute, University
Mustafa Jarrar: Lecture Notes on Games, Birzeit University, Palestine Fall Semester, 204 Artificial Intelligence Chapter 6 Games (adversarial search problems) Dr. Mustafa Jarrar Sina Institute, University
Module 3. Problem Solving using Search- (Two agent) Version 2 CSE IIT, Kharagpur
 Version 2 CSE IIT, Kharagpur") Module 3 Problem Solving using Search- (Two agent) 3.1 Instructional Objective The students should understand the formulation of multi-agent search and in detail two-agent search. Students should b familiar
Module 3 Problem Solving using Search- (Two agent) 3.1 Instructional Objective The students should understand the formulation of multi-agent search and in detail two-agent search. Students should b familiar
Announcements. CS 188: Artificial Intelligence Fall Local Search. Hill Climbing. Simulated Annealing. Hill Climbing Diagram
 CS 188: Artificial Intelligence Fall 2008 Lecture 6: Adversarial Search 9/16/2008 Dan Klein UC Berkeley Many slides over the course adapted from either Stuart Russell or Andrew Moore 1 Announcements Project
CS 188: Artificial Intelligence Fall 2008 Lecture 6: Adversarial Search 9/16/2008 Dan Klein UC Berkeley Many slides over the course adapted from either Stuart Russell or Andrew Moore 1 Announcements Project
Foundations of AI. 6. Adversarial Search. Search Strategies for Games, Games with Chance, State of the Art. Wolfram Burgard & Bernhard Nebel
 Foundations of AI 6. Adversarial Search Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard & Bernhard Nebel Contents Game Theory Board Games Minimax Search Alpha-Beta Search
Foundations of AI 6. Adversarial Search Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard & Bernhard Nebel Contents Game Theory Board Games Minimax Search Alpha-Beta Search
Artificial Intelligence
 Artificial Intelligence CS482, CS682, MW 1 2:15, SEM 201, MS 227 Prerequisites: 302, 365 Instructor: Sushil Louis, sushil@cse.unr.edu, http://www.cse.unr.edu/~sushil Games and game trees Multi-agent systems
Artificial Intelligence CS482, CS682, MW 1 2:15, SEM 201, MS 227 Prerequisites: 302, 365 Instructor: Sushil Louis, sushil@cse.unr.edu, http://www.cse.unr.edu/~sushil Games and game trees Multi-agent systems