Metrics How to improve performance? CPI MIPS Benchmarks CSC3501 S07 CSC3501 S07. Louisiana State University 4- Performance - 1
|
|
|
- Lee Arnold
- 6 years ago
- Views:
Transcription
1 Performance of Computer Systems Dr. Arjan Durresi Louisiana State University Baton Rouge, LA LSUEd These slides are available at: Louisiana State University 4- Performance - 1 Overview Metrics How to improve performance? CPI MIPS Benchmarks Louisiana State University 4- Performance - 2
2 The Design Process "To Design Is To Represent" Design activity yields description/representation of an object -- Traditional craftsman does not distinguish between the conceptualization and the artifact -- Separation comes about because of complexity -- The concept is captured in one or more representation languages -- This process IS design Design Begins With Requirements -- Functional Capabilities: what it will do -- Performance Characteristics: Speed, Power, Area, Cost,... Louisiana State University 4- Performance - 3 Design Process (cont.) Design Finishes As Assembly -- Design understood in terms of components and how they have been assembled -- Top Down decomposition of complex functions (behaviors) into more primitive functions Datapath -- bottom-up composition of primitive building blocks into more complex assemblies CPU ALU Regs Shifter Nand Gate Control Design is a "creative process," not a simple method Louisiana State University 4- Performance - 4
3 Design Refinement Informal System Requirement Initial Specification Intermediate Specification Final Architectural Description refinement increasing level of detail Intermediate Specification of Implementation Final Internal Specification Physical Implementation Louisiana State University 4- Performance - 5 Design as Search Problem A Strategy 1 Strategy 2 SubProb 1 SubProb2 SubProb3 BB1 BB2 BB3 BBn Design involves educated guesses and verification -- Given the goals, how should these be prioritized? -- Given alternative design pieces, which should be selected? -- Given design space of components & assemblies, which part will yield the best solution? Feasible (good) choices vs. Optimal choices Louisiana State University 4- Performance - 6
4 Measurement and Evaluation Architecture is an iterative process Design -- searching the space of possible designs -- at all levels of computer systems Analysis Creativity Cost / Performance Analysis Bad Ideas Good Ideas Mediocre Ideas Louisiana State University 4- Performance - 7 Measure, Report, and Summarize Make intelligent choices Performance See through the marketing hype Key to understanding underlying organizational motivation Why is some hardware better than others for different programs? What factors of system performance are hardware related? (e.g., Do we need a new machine, or a new operating system?) How does the machine's instruction set affect performance? Louisiana State University 4- Performance - 8
5 Performance Metrics Purchasing perspective given a collection of machines, which has the best performance? least cost? best cost/performance? Design perspective faced with design options, which has the best performance improvement? least cost? best cost/performance? Both require basis for comparison metric for evaluation Our goal is to understand what factors in the architecture contribute to overall system performance and the relative importance (and cost) of these factors Louisiana State University 4- Performance - 9 Which of these airplanes has the best performance? Airplane Passengers Range (mi) Speed (mph) Passenger throughput Boeing ,750 Boeing ,700 BAC/Sud Concorde ,200 Douglas DC ,429 How much faster is the Concorde compared to the 747? How much bigger is the 747 than the Douglas DC-8? Louisiana State University 4- Performance - 10
6 Computer Performance: Basic Metrics Response Time (latency) How long does it take for my job to run? How long does it take to execute a job? How long must I wait for the database query? Throughput How many jobs can the machine run at once? What is the average execution rate? How much work is getting done? Example: Car assembly factory: 4 hours to produce a car (response time) 6 cars per an hour produced (throughput) If we upgrade a machine with a new processor what do we increase? If we add a new machine to the lab what do we increase? Louisiana State University 4- Performance - 11 Computer Performance: Introduction The computer user is interested in response time (or execution time) the time between the start and completion of a given task (program). The manager of a data processing center is interested in throughput the total amount of work done in given time. The computer user wants response time to decrease, while the manager wants throughput increased. Main factors influencing performance of computer system are: processor and memory, input/output controllers and peripherals, compilers, and operating system. Louisiana State University 4- Performance - 12
7 Elapsed Time Execution Time counts everything (disk and memory accesses, I/O, etc.) a useful number, but often not good for comparison purposes CPU time doesn't count I/O or time spent running other programs can be broken up into system time, and user time Our focus: user CPU time time spent executing the lines of code that are "in" our program CPU time is a true measure of processor/memory performance. Performance of processor/memory = 1 / CPU_time Louisiana State University 4- Performance - 13 Book's Definition of Performance For some program running on machine X, Performance X = 1 / Execution time X "X is n times faster than Y" Performance X / Performance Y = n Problem: machine A runs a program in 20 seconds machine B runs the same program in 25 seconds Louisiana State University 4- Performance - 14
8 Analysis of CPU Time CPU time depends on the program which is executed, including: a number of instructions executed, types of instructions executed and their frequency of usage. Computers are constructed is such way that events in hardware are synchronized using a clock. Clock rate is given in Hz (=1/sec). A clock rate defines durations of discrete time intervals called clock cycle times or clock cycle periods: clock_cycle_time = 1/clock_rate (in sec) Thus, when we refer to different instruction types (from performance point of view), we are referring to instructions with different number of clock cycles required (needed) to execute. Louisiana State University 4- Performance - 15 Clock Cycles Instead of reporting execution time in seconds, we often use cycles CPU time = seconds cycles seconds program = program cycle Clock ticks indicate when to start activities (one abstraction): cycle time = time between ticks = seconds per cycle clock rate (frequency) = cycles per second (1 Hz = 1 cycle/sec) time A 4 GHz clock has a time = 250 picoseconds (ps) cycle Louisiana State University 4- Performance - 16
9 Clock Cycles (cont.) Clock rate (MHz, GHz) is inverse of clock cycle time (clock period) CC = 1 / CR one clock period 10 nsec clock cycle => 100 MHz clock rate 5 nsec clock cycle => 200 MHz clock rate 2 nsec clock cycle => 500 MHz clock rate 1 nsec clock cycle => 1 GHz clock rate 500 psec clock cycle => 2 GHz clock rate 250 psec clock cycle => 4 GHz clock rate 200 psec clock cycle => 5 GHz clock rate Louisiana State University 4- Performance - 17 How to Improve Performance seconds program = cycles program seconds cycle So, to improve performance (everything else being equal) you can either (increase or decrease?) the # of required cycles for a program, or the clock cycle time or, said another way, the clock rate. Louisiana State University 4- Performance - 18
10 Example Our favorite program runs in 10 seconds on computer A, which has a 4 GHz. clock. We are trying to help a computer designer build a new machine B, that will run this program in 6 seconds. The designer can use new (or perhaps more expensive) technology to substantially increase the clock rate, but has informed us that this increase will affect the rest of the CPU design, causing machine B to require 1.2 times as many clock cycles as machine A for the same program. What clock rate should we tell the designer to target?" Don't Panic, can easily work this out from basic principles Louisiana State University 4- Performance - 19 Example A program runs in 10s on computer A, at 4GHz How to build a computer B to run this program in 6s The designer has determined that if the clock rate will be increased, it will cause computer B to require 1.2 times more clock cycles than A What clock rate should be used in computer B? CPU clock cycles A CPU clock cycles A CPU time A = 10s = Clock rate A 4 x 10 9 cycles seconds CPU clock cycles A =40 x 10 9 cycles CPU time A = 1.2 x CPU clock cycles A Clock rate B Clock rate B = 8 GHz Louisiana State University 4- Performance - 20
11 Measuring Time using Clock Cycles CPU execution time for program = Clock Cycles for a program x Clock Cycle Time One way to define clock cycles: Clock Cycles for program = Instructions for a program (called Instruction Count ) x Average Clock cycles Per Instruction (called CPI ) CPI the average number of clock cycles per instructions is an important parameter CPI = Clock_cycles_for_a_program/Instruction_count Instruction_count is the number of instructions executed Louisiana State University 4- Performance - 21 Performance Calculation CPU execution time for program = Clock Cycles for program x Clock Cycle Time Substituting for clock cycles: CPU execution time for program = (Instruction Count x CPI) x Clock Cycle Time = Instruction Count x CPI x Clock Cycle Time CPU time = Instructions x Cycles x Seconds Program Instruction Cycle CPU time = Instructions ti x Cycles x Seconds Program Instruction Cycle CPU time = Seconds Program Louisiana State University 4- Performance - 22
12 How Calculate the 3 Components? Clock Cycle Time: in specification of computer (Clock Rate in advertisements) Instruction Count: Count instructions in loop of small program Use simulator to count instructions Hardware counter in spec. register (most CPUs) CPI= Clock_cycles_for_a_program/Instruction_count Calculate: Execution Time / Clock cycle time Instruction_count Hardware counter in special register (most CPUs) Louisiana State University 4- Performance - 23 How many cycles are required for a program? Could assume that number of cycles equals number of instructions 1st instructio on 2nd instructio on 3rd instructio on 4th 5th 6th... time This assumption is incorrect, different instructions take different amounts of time on different machines. Why? hint: remember that these are machine instructions, not lines of C code Louisiana State University 4- Performance - 24
13 Different numbers of cycles for different instructions time Multiplication takes more time than addition Floating point operations take longer than integer ones Accessing memory takes more time than accessing registers Important point: changing the cycle time often changes the number of cycles required for various instructions (more later) Louisiana State University 4- Performance - 25 Phases in Instruction Execution We can divide the execution of an instruction into the following five stages: Instruction fetch Instruction decode and register fetch Execution, effective address or brunch calculation Memory access (for lw and sw instructions only) Register write back (for ALU and lw instructions) Louisiana State University 4- Performance - 26
14 Sequential Execution of 3 LW Instructions Assumed are the following delays: Memory access = 2 nsec, ALU operation = 2 nsec, Register file access = 1 nsec; Program Execution order lw r1, 100(r0) lw r2, 200(r0) lw r2, 200(r0) IF Reg ALU MEM Reg 8 ns IF Reg ALU MEM Reg 8 ns 8 ns Every lw instruction needs 8 nsec to execute. In this course, we are designing processor that Executes instructions sequentially. Louisiana State University 4- Performance - 27 A given program will require Now that we understand cycles some number of instructions (machine instructions) some number of cycles some number of seconds We have a vocabulary that relates these quantities: cycle time (seconds per cycle) clock rate (cycles per second) CPI (cycles per instruction) a floating point intensive application might have a higher CPI MIPS (millions of instructions per second) this would be higher for a program using simple instructions Louisiana State University 4- Performance - 28
15 Performance Performance is determined by execution time Do any of the other variables equal performance? # of cycles to execute program? # of instructions in program? # of cycles per second? average # of cycles per instruction? average # of instructions per second? Common pitfall: thinking one of the variables is indicative of performance when it really isn t. Louisiana State University 4- Performance - 29 CPI Example Suppose we have two implementations of the same instruction set architecture (ISA). For some program, Machine A has a clock cycle time of 250 ps and a CPI of 2.0 Machine B has a clock cycle time of 500 ps and a CPI of 1.2 What machine is faster for this program, and by how much? If two machines have the same ISA which of our quantities (e.g., clock rate, CPI, execution time, # of instructions, MIPS) will always be identical? Louisiana State University 4- Performance - 30
16 CPI Example CPU clock cycles A = I x 2.0 ; CPU clock cycles B = I x 1.2 CPU time A = CPU clock cycles A x CPU clock time A = I x 2.0 x 250ps=Ix500ps CPU time A = CPU clock cycles A x CPU clock time A = I x 1.2 x 500ps=Ix600ps CPU time B = 1.2 CPU time A Instruction count x CPI CPU time = Clock rate Louisiana State University 4- Performance - 31 CPU clock cycles = (CPI i x C i ) CPI C i is the count of the number of instructions of class i, i CPI i is the average number per instructions for that class. Louisiana State University 4- Performance - 32
17 Computer Performance CPI inst count Cycle time CPU time = Seconds = Instructions x Cycles x Seconds Program Program Instruction Cycle Program Inst Count CPI Clock Rate X Compiler X (X) Inst. Set. X X Organization X X Technology X Louisiana State University 4- Performance - 33 # of Instructions Example A compiler designer is trying to decide between two code sequences for a particular machine. Based on the hardware implementation, there are three different classes of instructions: Class A, Class B, and Class C, and they require one, two, and three cycles (respectively). The first code sequence has 5 instructions: 2 of A, 1 of B, and 2 of C The second sequence has 6 instructions: 4 of A, 1 of B, and 1 of C. Which sequence will be faster? How much? What is the CPI for each sequence? Louisiana State University 4- Performance - 34
18 # of Instructions Example CPU clock cycles 1 = (CPI i x C i ) = (2x1)+(1x2)+(2x3) = 10 cycles CPU clock cycles 2 = (CPI i x C i ) = (4x1)+(1x2)+(1x3) = 9 cycles CPI 1 = 10/2 = 2 CPI 2 = 9/6 = 1.5 When comparing, all three factors: clock rate, number of instructions, and CPI should be compared Louisiana State University 4- Performance - 35 CPU Time: Example Consider an implementation of MIPS ISA with 500 MHz clock and each ALU instruction takes 3 clock cycles, each branch/jump instruction takes 2 clock cycles, each sw instruction takes 4 clock cycles, each lw instruction takes 5 clock cycles. Also, consider a program that during its execution executes: x=200 million ALU instructions y=55 million branch/jump instructions z=25 million sw instructions w=20 million lw instructions Find CPU time. Louisiana State University 4- Performance - 36
19 CPU Time: Example 1 (continued) Approach 1: Clock cycles for a program = (x 3 + y 2 + z 4 + w 5) = = clock cycles CPU_time = Clock cycles for a program / Clock rate = = / = 1.82 sec Approach 2: CPI = Clock cycles for a program / Instructions count CPI = (x 3 + y 2 + z 4 + w 5)/ (x + y + z + w) = 3.03 clock cycles/ instruction CPU time = Instruction count CPI / Clock rate = =(x+y+z+w) 3.03 / = = / = 1.82 sec Louisiana State University 4- Performance - 37 CPU Time: Example 2 Consider another implementation of MIPS ISA with 1 GHz clock and each ALU instruction takes 4 clock cycles, each branch/jump instruction takes 3 clock cycles, each sw instruction ti takes 5 clock cycles, each lw instruction takes 6 clock cycles. Also, consider the same program as in Example 1. Find CPI and CPU time. CPI = (x 4 + y 3 + z 5 + w 6)/ (x + y + z + w) = 4.03 clock cycles/ instruction CPU time = Instruction count CPI / Clock rate = (x+y+z+w) 4.03 / = / = 1.21 sec Louisiana State University 4- Performance - 38
20 Analysis of CPU Performance Equation CPU time = Instruction count * CPI / Clock rate How to improve (i.e. decrease) CPU time: Clock rate: hardware technology & organization, CPI: organization, ISA and compiler technology, Instruction count: ISA & compiler technology. Many potential performance improvement techniques primarily il improve one component with small or predictable impact on the other two. Louisiana State University 4- Performance - 39 Calculating Components of CPU time For an existing processor it is easy to obtain the CPU time (i.e. the execution time) by measurement, and the clock rate is known. But, it is difficult to figure out the instruction count or CPI. Newer processors, MIPS64 processor is such an example, include counters for instructions executed and for clock cycles. Those can be helpful to programmers trying to understand and tune the performance of an application. Also, different simulation techniques and queuing theory could be used to obtain values for components of the execution (CPU) time. Louisiana State University 4- Performance - 40
21 Attempting to Calculate CPI The table below indicates frequency of all instruction types execu ted in a typical program and, from the reference manual, we are provided with a number of cycles per instruction for each type. Instruction Type Frequency Cycles ALU instruction 50% 4 Load instruction 30% 5 Store instruction 5% 4 Branch instruction 15% 2 CPI = 0.5* * * *2 = 4 cycles/instruction The calculation may not be necessary correct since the numbers for cycles per instruction given don t account for pipeline effects. Louisiana State University 4- Performance - 41 A Simple Example Op Freq CPI i Freq x CPI i ALU 50% 1. Load 20% 5 Store 10% 3 Branch 20% 2 Σ = How much faster would the machine be if a better data cache reduced the average load time to 2 cycles? How does this compare with using branch prediction to shave a cycle off the branch time? What if two ALU instructions could be executed at once? Louisiana State University 4- Performance - 42
22 A Simple Example Op Freq CPI i Freq x CPI i ALU 50% 1.5 Load 20% Store 10% 3.3 Branch 20% 2.4 Σ = How much faster would the machine be if a better data cache reduced the average load time to 2 cycles? CPU time new = 1.6 x IC x CC so 2.2/1.6 2/1 means 37.5% faster How does this compare with using branch prediction to shave a cycle off the branch time? CPU time new = 2.0 x IC x CC so 2.2/2.0 means 10% faster What if two ALU instructions could be executed at once? CPU time new = 1.95 x IC x CC so 2.2/1.95 means 12.8% faster 2.2 Louisiana State University 4- Performance - 43 Pipelining: Its Natural! Laundry Example Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, and fold Washer takes 30 minutes A B C D Dryer takes 40 minutes Folder takes 20 minutes Louisiana State University 4- Performance - 44
23 T a s k O r d e r A B C D Sequential Laundry 6 PM Midnight Time Sequential laundry takes 6 hours for 4 loads If they learned pipelining, how long would laundry take? Louisiana State University 4- Performance - 45 Pipelined Laundry Start work ASAP 6 PM Midnight Time T a s k O r d e r A B C D Pipelined laundry takes 3.5 hours for 4 loads Louisiana State University 4- Performance - 46
24 T a s k O r d e r A B C D Pipelining Lessons 6 PM Time Pipelining doesn t help latency of single task, it helps throughput of entire workload Pipeline rate limited by slowest pipeline stage Multiple tasks operating simultaneously Potential speedup = Number pipe stages Unbalanced lengths of pipe stages reduces speedup Time to fill pipeline and time to drain it reduces speedup Louisiana State University 4- Performance - 47 Computer Pipelines Execute billions of instructions, so throughput is what matters What is desirable in instruction sets for pipelining? Variable length instructions vs. all instructions same length? Memory operands part of any operation vs. memory operands only in loads or stores? Register operand many places in instruction format vs. registers s located in same place? Louisiana State University 4- Performance - 48
25 Pipeline Executing 3 LW Instructions Assuming delays as in the sequential case and pipelined processor with a clock cycle time of 2 nsec lw r1, 100(r0) lw r2, 200(r0) lw r2, 200(r0) Note that registers are written during the first part of a cycle and read during the second part of the same cycle. Pipelining doesn t help to execute a single instruction, it may improve performance by increasing instruction throughput; Louisiana State University 4- Performance - 49 MIPS One alternative to time is the metric MIPS (Million Instructions per Second) MIPS = Instruction count Execution time x 10 6 MIPS does not take into account the capabilities of instructions MIPS varies among programs on the same computer MIPS can vary inversely with performance Louisiana State University 4- Performance - 50
26 MIPS example Two different compilers are being tested for a 4 GHz. machine with three different classes of instructions: Class A, Class B, and Class C, which require one, two, and three cycles (respectively). Both compilers are used to produce code for a large piece of software. The first compiler's code uses 5 million Class A instructions, 1 million Class B instructions, and 1 million Class C instructions. The second compiler's code uses 10 million Class A instructions, 1 million Class B instructions, and 1 million Class C instructions. Which sequence will be faster according to MIPS? Which sequence will be faster according to execution time? Louisiana State University 4- Performance - 51 Execution time = MIPS example CPU clock cycles Clock rate CPU clock cycles = = = 9 1 (CPI i x C i ) ((5x1) (1x2) (1x3))x10 10x10 CPU clock cycles 2 = (CPI i x C i ) = ((10x1) + (1x2) + (1x3))x10 9 = 15x10 9 Execution time 1 = 2.5 seconds Execution time 2 = 3.75 seconds MIPS = MIPS 1 = 2800 MIPS 2 = 3200 Instruction count Execution time x 10 6 Louisiana State University 4- Performance - 52
27 Quantitative Performance Measures Another popular, misleading and essentially useless measure was peak MIPS. That is a MIPS obtained using an instruction mix that minimizes the CPI, even if that instruction mix is totally impractical. Computer manufacturers still occasionally announce products using peak MIPS as a metric, often neglecting to include the work peak. Another popular alternative to execution time was million floating point operations per second MFLOPS: Number of floating point operations in a program MFLOPS = Execution time * 10 6 Because it is based on operations in the program rather than on instructions, MFLOPS has a stronger claim than MIPS to being a fair comparison between different machines. MFLOPS are not applicable outside floating-point performance. Louisiana State University 4- Performance - 53 Benchmarks Performance best determined by running a real application Use programs typical of expected workload Or, typical of expected class of applications e.g., compilers/editors, scientific applications, graphics, etc. Small benchmarks nice for architects and designers easy to standardize can be abused SPEC (System Performance Evaluation Cooperative) was founded in late 1980s companies have agreed on a set of real program and inputs valuable indicator of performance (and compiler technology) can still be abused Louisiana State University 4- Performance - 54
28 SPEC Benchmark Suites The SPEC benchmarks are real programs, modified for portability and to minimize the role of I/O in overall benchmark performance. Example: Optimizer GNU C compiler. First in 1989, SPEC89 was introduced with 4 integer programs and 6 floating point programs, providing a single SPECmarks. SPEC92 had 5 integer programs and 14 floating point programs, and provided SPECint92 and SPECfp92. SPEC95 provided d SPECint_base95, SPECfp_base95. SPEC CPU2000 has 12 integer benchmarks and 14 floating point benchmarks, and provides CINT2000 and CFP2000. Louisiana State University 4- Performance - 55 Benchmark Games An embarrassed Intel Corp. acknowledged Friday that a bug in a software program known as a compiler had led the company to overstate the speed of its microprocessor chips on an industry benchmark by 10 percent. However, industry analysts said the coding error was a sad commentary on a common industry practice of cheating on standardized performance tests The error was pointed out to Intel two days ago by a competitor, Motorola came in a test known as SPECint92 Intel acknowledged that it had optimized its compiler to improve its test scores. The company had also said that it did not like the practice but felt to compelled to make the optimizations because its competitors were doing the same thing At the heart of Intel s problem is the practice of tuning compiler programs to recognize certain computing problems in the test and then substituting special handwritten pieces of code Saturday, January 6, 1996 New York Times Louisiana State University 4- Performance - 56


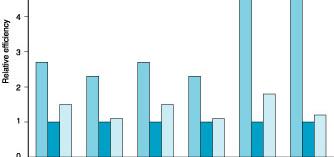
29 SPEC 89 Compiler enhancements and performance SPEC performance ratio gcc espresso spice doduc nasa7 li eqntott matrix300 fpppp tomcatv Benchmark Compiler Enhanced compiler Louisiana State University 4- Performance - 57 SPEC CPU2000 Louisiana State University 4- Performance - 58
30 SPEC 2000 Does doubling the clock rate double the performance? Can a machine with a slower clock rate have better performance? Pentium 4 CFP2000 Pentium 4 CINT Pentium 1.6/0.6 GHz Pentium 2.4/1.2 GHz Pentium 1.2/0.8 GHz Pentium III CINT Pentium III CFP Clock rate in MHz 0.0 SPECINT2000 SPECFP2000 SPECINT2000 SPECFP2000 SPECINT2000 SPECFP2000 Always on/maximum clock Laptop mode/adaptive clock Minimum power/minimum clock Benchmark and power mode Louisiana State University 4- Performance - 59 SPEC 2000 Ratio Pentium III Pentium IV CINT2000/Clock [MHz] CFP2000/Clock [MHz] CINT 2000 CPI of Pentium 4 is 1.3 times that of Pentium 3 (0.47/0.36) How come these numbers are reversed for CFP? Pentium 4 provides a new set of instructions (Streaming SIMD) So both CPI and instruction count are different Louisiana State University 4- Performance - 60
31 Performance Example We are interested in two implementations of two similar but still different ISA, one with and one without special real number instructions. Both machine have 1000MHz clock. Machine With Floating Point Hardware - MFP implements real number operations directly with the following characteristics: real number multiply instruction requires 6 clock cycles real number add instruction requires 4 clock cycles real number divide instruction requires 20 clock cycles Any other instruction (including integer instructions) requires 2 clock cycles Louisiana State University 4- Performance - 61 Performance Example Machine with No Floating Point Hardware - MNFP does not support real number instructions, but all its instructions are identical to non-real number instructions of MFP. Each MNFP instruction ti (including integer instructions) ti takes 2 clock cycles. Thus, MNFP is identical to MFP without real number instructions. Any real number operation (in a program) has to be emulated by an appropriate software subroutine (i.e. compiler has to insert an appropriate sequence of integer instructions for each real number operation). The number of integer instructions needed to implement each real number operations is as follows: real number multiply needs 30 integer instructions real number add needs 20 integer instructions real number divide needs 50 integer instructions Louisiana State University 4- Performance - 62

32 Performance Example Consider Program P with the following mix of operations: real number multiply 10% real number add 15% real number divide 5% other instructions 70% A. Find MIPS rating for both machine. CPI MFP = = 3.6 clocks/instr CPI MNFP = 2 MIPS MFP rating = clock rate CPI * 10 = MIPS MNFP rating =500 According to MIPS rating, MNFP is better than MFP!? Louisiana State University 4- Performance - 63 Performance Example B. If Program P on MFP needs 300,000,000 instructions, find the time to execute this program on each machine. CPU_time MFP = / = 1.08 sec CPU_time MNFP = / = 5.52 sec Louisiana State University 4- Performance - 64
33 Performance Example C. Calculate MFLOPS for both computers. Number of floating gpoint operations in a program MFLOPS = Execution time * 10 6 MFLOPS MFP = / = 83.3 MFLOPS MNFP = / = 16.3 Louisiana State University 4- Performance - 65 Experiment Phone a major computer retailer and tell them you are having trouble deciding between two different computers, specifically you are confused about the processors strengths and weaknesses (e.g., Pentium 4 at 2Ghz vs. Celeron M at 1.4 Ghz ) What kind of response are you likely to get? What kind of response could you give a friend with the same question? Louisiana State University 4- Performance - 66

34 Performance Louisiana State University 4- Performance - 67 Performance Louisiana State University 4- Performance - 68
35 Summarizing Performance Louisiana State University 4- Performance - 69 Summarizing Performance Louisiana State University 4- Performance - 70

36 Geometric mean. where Execution time ratio i is the execution time, normalized to the reference computer, for the i th program of a total of n in the workload, and Louisiana State University 4- Performance - 71 Mean The geometric mean is independent of which data series we use for normalization because it has the property The advantage of the geometric mean is that it is independent of the running times of the individual programs, and it doesn t matter which computer is used for normalization The drawback to using geometric means of execution times is that they violate our fundamental principle of performance measurement they do not predict execution time. The ideal solution is to measure a real workload and weight the programs according to their frequency of execution. Louisiana State University 4- Performance - 72
37 Amdahl's Law Execution Time After Improvement = Execution Time Unaffected +( Execution Time Affected / Amount of Improvement ) Example: "Suppose a program runs in 100 seconds on a machine, with multiply responsible for 80 seconds of this time. How much do we have to improve the speed of multiplication if we want the program to run 4 times faster?" How about making it 5 times faster? Principle: Make the common case fast Louisiana State University 4- Performance - 73 ExTimenew = ExTimeold 1 Amdahl s Law Fractionenhanced ( Fractionenhanced ) + Speedup enhanced Speedup overall = ExTime ExTime old new = ( 1 Fraction ) enhanced 1 + Fraction Speedup enhanced enhanced Best you could ever hope to do: Speedup = maximum Fraction ( ) enhanced Louisiana State University 4- Performance - 74
38 Example Suppose we enhance a machine making all floating-point instructions run five times faster. If the execution time of some benchmark before the floating-point enhancement is 10 seconds, what will the speedup be if half of the 10 seconds is spent executing floating-point instructions? We are looking for a benchmark to show off the new floatingpoint unit described above, and want the overall benchmark to show a speedup of 3. One benchmark we are considering runs for 100 seconds with the old floating-point hardware. How much of the execution time would floating-point instructions have to account for in this program in order to yield our desired speedup on this benchmark? Louisiana State University 4- Performance - 75 Performance is specific to a particular program/s Remember Total execution time is a consistent summary of performance For a given architecture performance increases come from: increases in clock rate (without adverse CPI affects) improvements in processor organization that lower CPI compiler enhancements that lower CPI and/or instruction count Algorithm/Language choices that affect instruction count Pitfall: expecting improvement in one aspect of a machine s performance to affect the total performance Louisiana State University 4- Performance - 76
39 The Art of Performance Evaluation: The Ratio Game If you can t convince them, confuse them. Truman s Law Throughput in Transaction per Second System Workload 1 Workload 2 A B Comparing the Average Throughput System Workload 1 Workload 2 Average A B The two systems are equally good. Louisiana State University 4- Performance - 77 The Ratio Game 1 Throughput in Transaction per Second System Workload 1 Workload 2 A B Throughput will Respect to System B System Workload 1 Workload 2 Average A B System A is better than system B! Louisiana State University 4- Performance - 78
40 The Ratio Game 2 Throughput in Transaction per Second System Workload 1 Workload 2 A B Throughput will Respect to System A System Workload 1 Workload 2 Average A B System B is better than system A!! The problem is with taking the average of ratios Louisiana State University 4- Performance - 79 Ratio Game with Percentages System A Test 1 Total Pass % Pass Percent of test passed System B Test 1 Total Pass % Pass Percent of total tests passed Which is better A or B? Louisiana State University 4- Performance - 80
41 Ratio Game with Percentages (Cont.) Both alternatives have the problem of incomparable bases. In Alternative 1, the base is the total number of times the experiment is repeated on a system, which is different for the two systems. In Alternative 2, the base is sum of repetitions of the two experiments together, which is also different for the two systems. Louisiana State University 4- Performance - 81 The Art of Performance Evaluation: Benchmark to benchmark v. trans. To subject (a system) to a series of tests in order to obtain prearranged results not available on competitive systems S. Kelly-Bootle The Devil s DP Dictionary Benchmarking is the process of comparing two systems using standard d well known benchmarks. Louisiana State University 4- Performance - 82
42 Misleading by Benchmarking 1 Different configuration may be used to run the same workload on two systems. Different Dff amount of fmemory, m disks The compilers may be wired to optimize the workload. For example, eliminating recognized loops Test specification may be written so that they are biased towards one machine. For example, if the specifications are written based on an existing environment. A synchronized job sequence may be used. It is possible to manipulate a job sequence so that CPU-bound and I/O-bound steps synchronize to give a better overall performance. Louisiana State University 4- Performance - 83 Misleading by Benchmarking 2 The workload may be arbitrary picked. The workload might not be representative of real-world applications. Very small benchmarks may be used. For example, such small benchmarks can give 100% cache hits, thereby ignoring the inefficiency of memory and cache organization. May not show the effect of I/O overhead. Few instructions in a loop: By judicious choice of instructions in the loop, the results can be skewed by any amount desired. Benchmarks may be manually translated to optimize the performance. Often need to manually translated on different systems. The performance may then depend on the ability of the translator than on the system under test. Louisiana State University 4- Performance - 84
43 Summary Instruction complexity is only one variable lower instruction count vs. higher CPI / lower clock rate Design Principles: simplicity favors regularity smaller is faster good design demands compromise make the common case fast Instruction set architecture a very important abstraction indeed! Performance measurement more art than science. Louisiana State University 4- Performance - 85
CS Computer Architecture Spring Lecture 04: Understanding Performance
 CS 35101 Computer Architecture Spring 2008 Lecture 04: Understanding Performance Taken from Mary Jane Irwin (www.cse.psu.edu/~mji) and Kevin Schaffer [Adapted from Computer Organization and Design, Patterson
CS 35101 Computer Architecture Spring 2008 Lecture 04: Understanding Performance Taken from Mary Jane Irwin (www.cse.psu.edu/~mji) and Kevin Schaffer [Adapted from Computer Organization and Design, Patterson
ECE473 Computer Architecture and Organization. Pipeline: Introduction
 Computer Architecture and Organization Pipeline: Introduction Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 11.1 The Laundry Analogy Student A,
Computer Architecture and Organization Pipeline: Introduction Lecturer: Prof. Yifeng Zhu Fall, 2015 Portions of these slides are derived from: Dave Patterson UCB Lec 11.1 The Laundry Analogy Student A,
Measuring and Evaluating Computer System Performance
 Measuring and Evaluating Computer System Performance Performance Marches On... But what is performance? The bottom line: Performance Car Time to Bay Area Speed Passengers Throughput (pmph) Ferrari 3.1
Measuring and Evaluating Computer System Performance Performance Marches On... But what is performance? The bottom line: Performance Car Time to Bay Area Speed Passengers Throughput (pmph) Ferrari 3.1
Pipelining A B C D. Readings: Example: Doing the laundry. Ann, Brian, Cathy, & Dave. each have one load of clothes to wash, dry, and fold
 Pipelining Readings: 4.5-4.8 Example: Doing the laundry Ann, Brian, Cathy, & Dave A B C D each have one load of clothes to wash, dry, and fold Washer takes 30 minutes Dryer takes 40 minutes Folder takes
Pipelining Readings: 4.5-4.8 Example: Doing the laundry Ann, Brian, Cathy, & Dave A B C D each have one load of clothes to wash, dry, and fold Washer takes 30 minutes Dryer takes 40 minutes Folder takes
A B C D. Ann, Brian, Cathy, & Dave each have one load of clothes to wash, dry, and fold. Time
 Pipelining Readings: 4.5-4.8 Example: Doing the laundry A B C D Ann, Brian, Cathy, & Dave each have one load of clothes to wash, dry, and fold Washer takes 30 minutes Dryer takes 40 minutes Folder takes
Pipelining Readings: 4.5-4.8 Example: Doing the laundry A B C D Ann, Brian, Cathy, & Dave each have one load of clothes to wash, dry, and fold Washer takes 30 minutes Dryer takes 40 minutes Folder takes
Lecture 4: Introduction to Pipelining
 Lecture 4: Introduction to Pipelining Pipelining Laundry Example Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, and fold Washer takes 30 minutes A B C D Dryer takes 40 minutes Folder
Lecture 4: Introduction to Pipelining Pipelining Laundry Example Ann, Brian, Cathy, Dave each have one load of clothes to wash, dry, and fold Washer takes 30 minutes A B C D Dryer takes 40 minutes Folder
Lecture Topics. Announcements. Today: Pipelined Processors (P&H ) Next: continued. Milestone #4 (due 2/23) Milestone #5 (due 3/2)
 Next: continued. Milestone #4 (due 2/23) Milestone #5 (due 3/2)") Lecture Topics Today: Pipelined Processors (P&H 4.5-4.10) Next: continued 1 Announcements Milestone #4 (due 2/23) Milestone #5 (due 3/2) 2 1 ISA Implementations Three different strategies: single-cycle
Lecture Topics Today: Pipelined Processors (P&H 4.5-4.10) Next: continued 1 Announcements Milestone #4 (due 2/23) Milestone #5 (due 3/2) 2 1 ISA Implementations Three different strategies: single-cycle
Performance Metrics, Amdahl s Law
 ecture 26 Computer Science 61C Spring 2017 March 20th, 2017 Performance Metrics, Amdahl s Law 1 New-School Machine Structures (It s a bit more complicated!) Software Hardware Parallel Requests Assigned
ecture 26 Computer Science 61C Spring 2017 March 20th, 2017 Performance Metrics, Amdahl s Law 1 New-School Machine Structures (It s a bit more complicated!) Software Hardware Parallel Requests Assigned
CS429: Computer Organization and Architecture
 CS429: Computer Organization and Architecture Dr. Bill Young Department of Computer Sciences University of Texas at Austin Last updated: November 8, 2017 at 09:27 CS429 Slideset 14: 1 Overview What s wrong
CS429: Computer Organization and Architecture Dr. Bill Young Department of Computer Sciences University of Texas at Austin Last updated: November 8, 2017 at 09:27 CS429 Slideset 14: 1 Overview What s wrong
CS 110 Computer Architecture Lecture 11: Pipelining
 CS 110 Computer Architecture Lecture 11: Pipelining Instructor: Sören Schwertfeger http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on
CS 110 Computer Architecture Lecture 11: Pipelining Instructor: Sören Schwertfeger http://shtech.org/courses/ca/ School of Information Science and Technology SIST ShanghaiTech University Slides based on
7/11/2012. Single Cycle (Review) CSE 2021: Computer Organization. Multi-Cycle Implementation. Single Cycle with Jump. Pipelining Analogy
 CSE 2021: Computer Organization. Multi-Cycle Implementation. Single Cycle with Jump. Pipelining Analogy") CSE 2021: Computer Organization Single Cycle (Review) Lecture-10 CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan CSE-2021 July-12-2012 2 Single Cycle with Jump Multi-Cycle Implementation
CSE 2021: Computer Organization Single Cycle (Review) Lecture-10 CPU Design : Pipelining-1 Overview, Datapath and control Shakil M. Khan CSE-2021 July-12-2012 2 Single Cycle with Jump Multi-Cycle Implementation
Suggested Readings! Lecture 12" Introduction to Pipelining! Example: We have to build x cars...! ...Each car takes 6 steps to build...! ! Readings!
 1! CSE 30321 Lecture 12 Introduction to Pipelining! CSE 30321 Lecture 12 Introduction to Pipelining! 2! Suggested Readings!! Readings!! H&P: Chapter 4.5-4.7!! (Over the next 3-4 lectures)! Lecture 12"
1! CSE 30321 Lecture 12 Introduction to Pipelining! CSE 30321 Lecture 12 Introduction to Pipelining! 2! Suggested Readings!! Readings!! H&P: Chapter 4.5-4.7!! (Over the next 3-4 lectures)! Lecture 12"
Pipelined Processor Design
 Pipelined Processor Design COE 38 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Pipelining versus Serial
Pipelined Processor Design COE 38 Computer Architecture Prof. Muhamed Mudawar Computer Engineering Department King Fahd University of Petroleum and Minerals Presentation Outline Pipelining versus Serial
Chapter 4. Pipelining Analogy. The Processor. Pipelined laundry: overlapping execution. Parallelism improves performance. Four loads: Non-stop:
 Chapter 4 The Processor Part II Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup p = 2n/(0.5n + 1.5) 4 =
Chapter 4 The Processor Part II Pipelining Analogy Pipelined laundry: overlapping execution Parallelism improves performance Four loads: Speedup = 8/3.5 = 2.3 Non-stop: Speedup p = 2n/(0.5n + 1.5) 4 =
Performance Metrics. Computer Architecture. Outline. Objectives. Basic Performance Metrics. Basic Performance Metrics
 Computer Architecture Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr nizamettinaydin@gmail.com Performance Metrics http://www.yildiz.edu.tr/~naydin 1 2 Objectives How can we meaningfully measure and compare
Computer Architecture Prof. Dr. Nizamettin AYDIN naydin@yildiz.edu.tr nizamettinaydin@gmail.com Performance Metrics http://www.yildiz.edu.tr/~naydin 1 2 Objectives How can we meaningfully measure and compare
CS 6290 Evaluation & Metrics
 CS 6290 Evaluation & Metrics Performance Two common measures Latency (how long to do X) Also called response time and execution time Throughput (how often can it do X) Example of car assembly line Takes
CS 6290 Evaluation & Metrics Performance Two common measures Latency (how long to do X) Also called response time and execution time Throughput (how often can it do X) Example of car assembly line Takes
CS420/520 Computer Architecture I
 CS42/52 Computer rchitecture I Designing a Pipeline Processor (C4: ppendix ) Dr. Xiaobo Zhou Department of Computer Science CS42/52 pipeline. UC. Colorado Springs dapted from UCB97 & UCB3 Branch Jump Recap:
CS42/52 Computer rchitecture I Designing a Pipeline Processor (C4: ppendix ) Dr. Xiaobo Zhou Department of Computer Science CS42/52 pipeline. UC. Colorado Springs dapted from UCB97 & UCB3 Branch Jump Recap:
CMSC 611: Advanced Computer Architecture
 CMSC 611: Advanced Computer Architecture Pipelining Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science
CMSC 611: Advanced Computer Architecture Pipelining Some material adapted from Mohamed Younis, UMBC CMSC 611 Spr 2003 course slides Some material adapted from Hennessy & Patterson / 2003 Elsevier Science
IF ID EX MEM WB 400 ps 225 ps 350 ps 450 ps 300 ps
 CSE 30321 Computer Architecture I Fall 2010 Homework 06 Pipelined Processors 85 points Assigned: November 2, 2010 Due: November 9, 2010 PLEASE DO THE ASSIGNMENT ON THIS HANDOUT!!! Problem 1: (25 points)
CSE 30321 Computer Architecture I Fall 2010 Homework 06 Pipelined Processors 85 points Assigned: November 2, 2010 Due: November 9, 2010 PLEASE DO THE ASSIGNMENT ON THIS HANDOUT!!! Problem 1: (25 points)
EECE 321: Computer Organiza5on
 EECE 321: Computer Organiza5on Mohammad M. Mansour Dept. of Electrical and Compute Engineering American University of Beirut Lecture 21: Pipelining Processor Pipelining Same principles can be applied to
EECE 321: Computer Organiza5on Mohammad M. Mansour Dept. of Electrical and Compute Engineering American University of Beirut Lecture 21: Pipelining Processor Pipelining Same principles can be applied to
CS4617 Computer Architecture
 1/26 CS4617 Computer Architecture Lecture 2 Dr J Vaughan September 10, 2014 2/26 Amdahl s Law Speedup = Execution time for entire task without using enhancement Execution time for entire task using enhancement
1/26 CS4617 Computer Architecture Lecture 2 Dr J Vaughan September 10, 2014 2/26 Amdahl s Law Speedup = Execution time for entire task without using enhancement Execution time for entire task using enhancement
CS61c: Introduction to Synchronous Digital Systems
 CS61c: Introduction to Synchronous Digital Systems J. Wawrzynek March 4, 2006 Optional Reading: P&H, Appendix B 1 Instruction Set Architecture Among the topics we studied thus far this semester, was the
CS61c: Introduction to Synchronous Digital Systems J. Wawrzynek March 4, 2006 Optional Reading: P&H, Appendix B 1 Instruction Set Architecture Among the topics we studied thus far this semester, was the
CS152 Computer Architecture and Engineering Lecture 3: ReviewTechnology & Delay Modeling. September 3, 1997
 CS152 Computer Architecture and Engineering Lecture 3: ReviewTechnology & Delay Modeling September 3, 1997 Dave Patterson (httpcsberkeleyedu/~patterson) lecture slides: http://www-insteecsberkeleyedu/~cs152/
CS152 Computer Architecture and Engineering Lecture 3: ReviewTechnology & Delay Modeling September 3, 1997 Dave Patterson (httpcsberkeleyedu/~patterson) lecture slides: http://www-insteecsberkeleyedu/~cs152/
Administrative Issues
 dministrative Issues Text book ($56.69 in mazon.com) Scanned problem set Email list Homework 1 announced, due 01/13/10 Quiz, 01/15/10 Graduate students meeting Relevant chapters in textbook? Technology
dministrative Issues Text book ($56.69 in mazon.com) Scanned problem set Email list Homework 1 announced, due 01/13/10 Quiz, 01/15/10 Graduate students meeting Relevant chapters in textbook? Technology
Final Report: DBmbench
 18-741 Final Report: DBmbench Yan Ke (yke@cs.cmu.edu) Justin Weisz (jweisz@cs.cmu.edu) Dec. 8, 2006 1 Introduction Conventional database benchmarks, such as the TPC-C and TPC-H, are extremely computationally
18-741 Final Report: DBmbench Yan Ke (yke@cs.cmu.edu) Justin Weisz (jweisz@cs.cmu.edu) Dec. 8, 2006 1 Introduction Conventional database benchmarks, such as the TPC-C and TPC-H, are extremely computationally
Chapter 16 - Instruction-Level Parallelism and Superscalar Processors
 Chapter 16 - Instruction-Level Parallelism and Superscalar Processors Luis Tarrataca luis.tarrataca@gmail.com CEFET-RJ L. Tarrataca Chapter 16 - Superscalar Processors 1 / 78 Table of Contents I 1 Overview
Chapter 16 - Instruction-Level Parallelism and Superscalar Processors Luis Tarrataca luis.tarrataca@gmail.com CEFET-RJ L. Tarrataca Chapter 16 - Superscalar Processors 1 / 78 Table of Contents I 1 Overview
Assessing and. Rui Wang, Assistant professor Dept. of Information and Communication Tongji University.
 Assessing and Understanding Performance Rui Wang, Assistant professor Dept. of Information and Communication Tongji University it Email: ruiwang@tongji.edu.cn 4.1 Introduction Pi Primary reason for examining
Assessing and Understanding Performance Rui Wang, Assistant professor Dept. of Information and Communication Tongji University it Email: ruiwang@tongji.edu.cn 4.1 Introduction Pi Primary reason for examining
CSE 305: Computer Architecture
 CSE 305: Computer Architecture Tanvir Ahmed Khan takhandipu@gmail.com Department of Computer Science and Engineering Bangladesh University of Engineering and Technology. September 6, 2015 1/16 Recap 2/16
CSE 305: Computer Architecture Tanvir Ahmed Khan takhandipu@gmail.com Department of Computer Science and Engineering Bangladesh University of Engineering and Technology. September 6, 2015 1/16 Recap 2/16
IF ID EX MEM WB 400 ps 225 ps 350 ps 450 ps 300 ps
 CSE 30321 Computer Architecture I Fall 2011 Homework 06 Pipelined Processors 75 points Assigned: November 1, 2011 Due: November 8, 2011 PLEASE DO THE ASSIGNMENT ON THIS HANDOUT!!! Problem 1: (15 points)
CSE 30321 Computer Architecture I Fall 2011 Homework 06 Pipelined Processors 75 points Assigned: November 1, 2011 Due: November 8, 2011 PLEASE DO THE ASSIGNMENT ON THIS HANDOUT!!! Problem 1: (15 points)
CSE502: Computer Architecture Welcome to CSE 502
 Welcome to CSE 502 Introduction & Review Today s Lecture Course Overview Course Topics Grading Logistics Academic Integrity Policy Homework Quiz Key basic concepts for Computer Architecture Course Overview
Welcome to CSE 502 Introduction & Review Today s Lecture Course Overview Course Topics Grading Logistics Academic Integrity Policy Homework Quiz Key basic concepts for Computer Architecture Course Overview
Single vs. Mul2- cycle MIPS. Single Clock Cycle Length
 Single vs. Mul2- cycle MIPS Single Clock Cycle Length Suppose we have 2ns 2ns ister read 2ns ister write 2ns ory read 2ns ory write 2ns 2ns What is the clock cycle length? 1 Single Cycle Length Worst case
Single vs. Mul2- cycle MIPS Single Clock Cycle Length Suppose we have 2ns 2ns ister read 2ns ister write 2ns ory read 2ns ory write 2ns 2ns What is the clock cycle length? 1 Single Cycle Length Worst case
Best Instruction Per Cycle Formula >>>CLICK HERE<<<
 Best Instruction Per Cycle Formula 6 Performance tuning, 7 Perceived performance, 8 Performance Equation, 9 See also is the average instructions per cycle (IPC) for this benchmark. Even. Click Card to
Best Instruction Per Cycle Formula 6 Performance tuning, 7 Perceived performance, 8 Performance Equation, 9 See also is the average instructions per cycle (IPC) for this benchmark. Even. Click Card to
Instructor: Dr. Mainak Chaudhuri. Instructor: Dr. S. K. Aggarwal. Instructor: Dr. Rajat Moona
 NPTEL Online - IIT Kanpur Instructor: Dr. Mainak Chaudhuri Instructor: Dr. S. K. Aggarwal Course Name: Department: Program Optimization for Multi-core Architecture Computer Science and Engineering IIT
NPTEL Online - IIT Kanpur Instructor: Dr. Mainak Chaudhuri Instructor: Dr. S. K. Aggarwal Course Name: Department: Program Optimization for Multi-core Architecture Computer Science and Engineering IIT
Computer Hardware. Pipeline
 Computer Hardware Pipeline Conventional Datapath 2.4 ns is required to perform a single operation (i.e. 416.7 MHz). Register file MUX B 0.6 ns Clock 0.6 ns 0.2 ns Function unit 0.8 ns MUX D 0.2 ns c. Production
Computer Hardware Pipeline Conventional Datapath 2.4 ns is required to perform a single operation (i.e. 416.7 MHz). Register file MUX B 0.6 ns Clock 0.6 ns 0.2 ns Function unit 0.8 ns MUX D 0.2 ns c. Production
Project 5: Optimizer Jason Ansel
 Project 5: Optimizer Jason Ansel Overview Project guidelines Benchmarking Library OoO CPUs Project Guidelines Use optimizations from lectures as your arsenal If you decide to implement one, look at Whale
Project 5: Optimizer Jason Ansel Overview Project guidelines Benchmarking Library OoO CPUs Project Guidelines Use optimizations from lectures as your arsenal If you decide to implement one, look at Whale
Pipelined Beta. Handouts: Lecture Slides. Where are the registers? Spring /10/01. L16 Pipelined Beta 1
 Pipelined Beta Where are the registers? Handouts: Lecture Slides L16 Pipelined Beta 1 Increasing CPU Performance MIPS = Freq CPI MIPS = Millions of Instructions/Second Freq = Clock Frequency, MHz CPI =
Pipelined Beta Where are the registers? Handouts: Lecture Slides L16 Pipelined Beta 1 Increasing CPU Performance MIPS = Freq CPI MIPS = Millions of Instructions/Second Freq = Clock Frequency, MHz CPI =
Computer Architecture
 Computer Architecture An Introduction Virendra Singh Associate Professor Computer Architecture and Dependable Systems Lab Department of Electrical Engineering Indian Institute of Technology Bombay http://www.ee.iitb.ac.in/~viren/
Computer Architecture An Introduction Virendra Singh Associate Professor Computer Architecture and Dependable Systems Lab Department of Electrical Engineering Indian Institute of Technology Bombay http://www.ee.iitb.ac.in/~viren/
Overview. 1 Trends in Microprocessor Architecture. Computer architecture. Computer architecture
 Overview 1 Trends in Microprocessor Architecture R05 Robert Mullins Computer architecture Scaling performance and CMOS Where have performance gains come from? Modern superscalar processors The limits of
Overview 1 Trends in Microprocessor Architecture R05 Robert Mullins Computer architecture Scaling performance and CMOS Where have performance gains come from? Modern superscalar processors The limits of
Chapter 3. H/w s/w interface. hardware software Vijaykumar ECE495K Lecture Notes: Chapter 3 1
 Chapter 3 hardware software H/w s/w interface Problems Algorithms Prog. Lang & Interfaces Instruction Set Architecture Microarchitecture (Organization) Circuits Devices (Transistors) Bits 29 Vijaykumar
Chapter 3 hardware software H/w s/w interface Problems Algorithms Prog. Lang & Interfaces Instruction Set Architecture Microarchitecture (Organization) Circuits Devices (Transistors) Bits 29 Vijaykumar
UNIT-III POWER ESTIMATION AND ANALYSIS
 UNIT-III POWER ESTIMATION AND ANALYSIS In VLSI design implementation simulation software operating at various levels of design abstraction. In general simulation at a lower-level design abstraction offers
UNIT-III POWER ESTIMATION AND ANALYSIS In VLSI design implementation simulation software operating at various levels of design abstraction. In general simulation at a lower-level design abstraction offers
CS61C : Machine Structures
 inst.eecs.bekeley.edu/~cs61c CS61C : Machine Stuctues Lectue 29 Intoduction to Pipelined Execution Lectue PSOE Dan Gacia www.cs.bekeley.edu/~ddgacia Bionic Eyes let blind see! Johns Hopkins eseaches have
inst.eecs.bekeley.edu/~cs61c CS61C : Machine Stuctues Lectue 29 Intoduction to Pipelined Execution Lectue PSOE Dan Gacia www.cs.bekeley.edu/~ddgacia Bionic Eyes let blind see! Johns Hopkins eseaches have
SATSim: A Superscalar Architecture Trace Simulator Using Interactive Animation
 SATSim: A Superscalar Architecture Trace Simulator Using Interactive Animation Mark Wolff Linda Wills School of Electrical and Computer Engineering Georgia Institute of Technology {wolff,linda.wills}@ece.gatech.edu
SATSim: A Superscalar Architecture Trace Simulator Using Interactive Animation Mark Wolff Linda Wills School of Electrical and Computer Engineering Georgia Institute of Technology {wolff,linda.wills}@ece.gatech.edu
Department Computer Science and Engineering IIT Kanpur
 NPTEL Online - IIT Bombay Course Name Parallel Computer Architecture Department Computer Science and Engineering IIT Kanpur Instructor Dr. Mainak Chaudhuri file:///e /parallel_com_arch/lecture1/main.html[6/13/2012
NPTEL Online - IIT Bombay Course Name Parallel Computer Architecture Department Computer Science and Engineering IIT Kanpur Instructor Dr. Mainak Chaudhuri file:///e /parallel_com_arch/lecture1/main.html[6/13/2012
Evolution of DSP Processors. Kartik Kariya EE, IIT Bombay
 Evolution of DSP Processors Kartik Kariya EE, IIT Bombay Agenda Expected features of DSPs Brief overview of early DSPs Multi-issue DSPs Case Study: VLIW based Processor (SPXK5) for Mobile Applications
Evolution of DSP Processors Kartik Kariya EE, IIT Bombay Agenda Expected features of DSPs Brief overview of early DSPs Multi-issue DSPs Case Study: VLIW based Processor (SPXK5) for Mobile Applications
Advances in Antenna Measurement Instrumentation and Systems
 Advances in Antenna Measurement Instrumentation and Systems Steven R. Nichols, Roger Dygert, David Wayne MI Technologies Suwanee, Georgia, USA Abstract Since the early days of antenna pattern recorders,
Advances in Antenna Measurement Instrumentation and Systems Steven R. Nichols, Roger Dygert, David Wayne MI Technologies Suwanee, Georgia, USA Abstract Since the early days of antenna pattern recorders,
7/19/2012. IF for Load (Review) CSE 2021: Computer Organization. EX for Load (Review) ID for Load (Review) WB for Load (Review) MEM for Load (Review)
 CSE 2021: Computer Organization. EX for Load (Review) ID for Load (Review) WB for Load (Review) MEM for Load (Review)") CSE 2021: Computer Organization IF for Load (Review) Lecture-11 CPU Design : Pipelining-2 Review, Hazards Shakil M. Khan CSE-2021 July-19-2012 2 ID for Load (Review) EX for Load (Review) CSE-2021 July-19-2012
CSE 2021: Computer Organization IF for Load (Review) Lecture-11 CPU Design : Pipelining-2 Review, Hazards Shakil M. Khan CSE-2021 July-19-2012 2 ID for Load (Review) EX for Load (Review) CSE-2021 July-19-2012
CSE 2021: Computer Organization
 CSE 2021: Computer Organization Lecture-11 CPU Design : Pipelining-2 Review, Hazards Shakil M. Khan IF for Load (Review) CSE-2021 July-14-2011 2 ID for Load (Review) CSE-2021 July-14-2011 3 EX for Load
CSE 2021: Computer Organization Lecture-11 CPU Design : Pipelining-2 Review, Hazards Shakil M. Khan IF for Load (Review) CSE-2021 July-14-2011 2 ID for Load (Review) CSE-2021 July-14-2011 3 EX for Load
Introduction (concepts and definitions)
") Objectives: Introduction (digital system design concepts and definitions). Advantages and drawbacks of digital techniques compared with analog. Digital Abstraction. Synchronous and Asynchronous Systems.
Objectives: Introduction (digital system design concepts and definitions). Advantages and drawbacks of digital techniques compared with analog. Digital Abstraction. Synchronous and Asynchronous Systems.
REAL TIME DIGITAL SIGNAL PROCESSING. Introduction
 REAL TIME DIGITAL SIGNAL Introduction Why Digital? A brief comparison with analog. PROCESSING Seminario de Electrónica: Sistemas Embebidos Advantages The BIG picture Flexibility. Easily modifiable and
REAL TIME DIGITAL SIGNAL Introduction Why Digital? A brief comparison with analog. PROCESSING Seminario de Electrónica: Sistemas Embebidos Advantages The BIG picture Flexibility. Easily modifiable and
6.S084 Tutorial Problems L19 Control Hazards in Pipelined Processors
 6.S084 Tutorial Problems L19 Control Hazards in Pipelined Processors Options for dealing with data and control hazards: stall, bypass, speculate 6.S084 Worksheet - 1 of 10 - L19 Control Hazards in Pipelined
6.S084 Tutorial Problems L19 Control Hazards in Pipelined Processors Options for dealing with data and control hazards: stall, bypass, speculate 6.S084 Worksheet - 1 of 10 - L19 Control Hazards in Pipelined
Computer Architecture
 Computer Architecture Lecture 01 Arkaprava Basu www.csa.iisc.ac.in Acknowledgements Several of the slides in the deck are from Luis Ceze (Washington), Nima Horanmand (Stony Brook), Mark Hill, David Wood,
Computer Architecture Lecture 01 Arkaprava Basu www.csa.iisc.ac.in Acknowledgements Several of the slides in the deck are from Luis Ceze (Washington), Nima Horanmand (Stony Brook), Mark Hill, David Wood,
Technology Timeline. Transistors ICs (General) SRAMs & DRAMs Microprocessors SPLDs CPLDs ASICs. FPGAs. The Design Warrior s Guide to.
 SRAMs & DRAMs Microprocessors SPLDs CPLDs ASICs. FPGAs. The Design Warrior s Guide to.") FPGAs 1 CMPE 415 Technology Timeline 1945 1950 1955 1960 1965 1970 1975 1980 1985 1990 1995 2000 Transistors ICs (General) SRAMs & DRAMs Microprocessors SPLDs CPLDs ASICs FPGAs The Design Warrior s Guide
FPGAs 1 CMPE 415 Technology Timeline 1945 1950 1955 1960 1965 1970 1975 1980 1985 1990 1995 2000 Transistors ICs (General) SRAMs & DRAMs Microprocessors SPLDs CPLDs ASICs FPGAs The Design Warrior s Guide
CSE502: Computer Architecture CSE 502: Computer Architecture
 CSE 502: Computer Architecture Out-of-Order Schedulers Data-Capture Scheduler Dispatch: read available operands from ARF/ROB, store in scheduler Commit: Missing operands filled in from bypass Issue: When
CSE 502: Computer Architecture Out-of-Order Schedulers Data-Capture Scheduler Dispatch: read available operands from ARF/ROB, store in scheduler Commit: Missing operands filled in from bypass Issue: When
EE241 - Spring 2004 Advanced Digital Integrated Circuits. Announcements. Borivoje Nikolic. Lecture 15 Low-Power Design: Supply Voltage Scaling
 EE241 - Spring 2004 Advanced Digital Integrated Circuits Borivoje Nikolic Lecture 15 Low-Power Design: Supply Voltage Scaling Announcements Homework #2 due today Midterm project reports due next Thursday
EE241 - Spring 2004 Advanced Digital Integrated Circuits Borivoje Nikolic Lecture 15 Low-Power Design: Supply Voltage Scaling Announcements Homework #2 due today Midterm project reports due next Thursday
Datorstödd Elektronikkonstruktion
 Datorstödd Elektronikkonstruktion [Computer Aided Design of Electronics] Zebo Peng, Petru Eles and Gert Jervan Embedded Systems Laboratory IDA, Linköping University http://www.ida.liu.se/~tdts80/~tdts80
Datorstödd Elektronikkonstruktion [Computer Aided Design of Electronics] Zebo Peng, Petru Eles and Gert Jervan Embedded Systems Laboratory IDA, Linköping University http://www.ida.liu.se/~tdts80/~tdts80
CMOS Process Variations: A Critical Operation Point Hypothesis
 CMOS Process Variations: A Critical Operation Point Hypothesis Janak H. Patel Department of Electrical and Computer Engineering University of Illinois at Urbana-Champaign jhpatel@uiuc.edu Computer Systems
CMOS Process Variations: A Critical Operation Point Hypothesis Janak H. Patel Department of Electrical and Computer Engineering University of Illinois at Urbana-Champaign jhpatel@uiuc.edu Computer Systems
IJCSIET--International Journal of Computer Science information and Engg., Technologies ISSN
 An efficient add multiplier operator design using modified Booth recoder 1 I.K.RAMANI, 2 V L N PHANI PONNAPALLI 2 Assistant Professor 1,2 PYDAH COLLEGE OF ENGINEERING & TECHNOLOGY, Visakhapatnam,AP, India.
An efficient add multiplier operator design using modified Booth recoder 1 I.K.RAMANI, 2 V L N PHANI PONNAPALLI 2 Assistant Professor 1,2 PYDAH COLLEGE OF ENGINEERING & TECHNOLOGY, Visakhapatnam,AP, India.
Asanovic/Devadas Spring Pipeline Hazards. Krste Asanovic Laboratory for Computer Science M.I.T.
 Pipeline Hazards Krste Asanovic Laboratory for Computer Science M.I.T. Pipelined DLX Datapath without interlocks and jumps 31 0x4 RegDst RegWrite inst Inst rs1 rs2 rd1 ws wd rd2 GPRs Imm Ext A B OpSel
Pipeline Hazards Krste Asanovic Laboratory for Computer Science M.I.T. Pipelined DLX Datapath without interlocks and jumps 31 0x4 RegDst RegWrite inst Inst rs1 rs2 rd1 ws wd rd2 GPRs Imm Ext A B OpSel
How cryptographic benchmarking goes wrong. Thanks to NIST 60NANB12D261 for funding this work, and for not reviewing these slides in advance.
 How cryptographic benchmarking goes wrong 1 Daniel J. Bernstein Thanks to NIST 60NANB12D261 for funding this work, and for not reviewing these slides in advance. PRESERVE, ending 2015.06.30, was a European
How cryptographic benchmarking goes wrong 1 Daniel J. Bernstein Thanks to NIST 60NANB12D261 for funding this work, and for not reviewing these slides in advance. PRESERVE, ending 2015.06.30, was a European
RISC Central Processing Unit
 RISC Central Processing Unit Lan-Da Van ( 范倫達 ), Ph. D. Department of Computer Science National Chiao Tung University Taiwan, R.O.C. Spring, 2014 ldvan@cs.nctu.edu.tw http://www.cs.nctu.edu.tw/~ldvan/
RISC Central Processing Unit Lan-Da Van ( 范倫達 ), Ph. D. Department of Computer Science National Chiao Tung University Taiwan, R.O.C. Spring, 2014 ldvan@cs.nctu.edu.tw http://www.cs.nctu.edu.tw/~ldvan/
EECS 470. Lecture 9. MIPS R10000 Case Study. Fall 2018 Jon Beaumont
 MIPS R10000 Case Study Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Multiprocessor SGI Origin Using MIPS R10K Many thanks to Prof. Martin and Roth of University of Pennsylvania for
MIPS R10000 Case Study Fall 2018 Jon Beaumont http://www.eecs.umich.edu/courses/eecs470 Multiprocessor SGI Origin Using MIPS R10K Many thanks to Prof. Martin and Roth of University of Pennsylvania for
Digital Signal Processors principles, use & application to PS systems.
 Digital Signal Processors principles, use & application to PS systems. Maria Elena Angoletta PS Seminar, 30 May 2002 TOPICS 1. Overview & history 2. Current scenery 3. Features 4. DSP choice criteria 5.
Digital Signal Processors principles, use & application to PS systems. Maria Elena Angoletta PS Seminar, 30 May 2002 TOPICS 1. Overview & history 2. Current scenery 3. Features 4. DSP choice criteria 5.
Instruction Scheduling for Low Power Dissipation in High Performance Microprocessors
 Instruction Scheduling for Low Power Dissipation in High Performance Microprocessors Abstract Mark C. Toburen Thomas M. Conte Department of Electrical and Computer Engineering North Carolina State University
Instruction Scheduling for Low Power Dissipation in High Performance Microprocessors Abstract Mark C. Toburen Thomas M. Conte Department of Electrical and Computer Engineering North Carolina State University
Digital Integrated CircuitDesign
 Digital Integrated CircuitDesign Lecture 13 Building Blocks (Multipliers) Register Adder Shift Register Adib Abrishamifar EE Department IUST Acknowledgement This lecture note has been summarized and categorized
Digital Integrated CircuitDesign Lecture 13 Building Blocks (Multipliers) Register Adder Shift Register Adib Abrishamifar EE Department IUST Acknowledgement This lecture note has been summarized and categorized
Chapter 3 Digital Logic Structures
 Chapter 3 Digital Logic Structures Transistor: Building Block of Computers Microprocessors contain millions of transistors Intel Pentium 4 (2): 48 million IBM PowerPC 75FX (22): 38 million IBM/Apple PowerPC
Chapter 3 Digital Logic Structures Transistor: Building Block of Computers Microprocessors contain millions of transistors Intel Pentium 4 (2): 48 million IBM PowerPC 75FX (22): 38 million IBM/Apple PowerPC
The Metrics and Designs of an Arithmetic Logic Function over
 The Metrics and Designs of an Arithmetic Logic Function over 2002-2015 Jimmy Vallejo Department of Electrical and Computer Engineering University of Central Flida Orlando, FL 32816-2362 Abstract There
The Metrics and Designs of an Arithmetic Logic Function over 2002-2015 Jimmy Vallejo Department of Electrical and Computer Engineering University of Central Flida Orlando, FL 32816-2362 Abstract There
# σ& # = ' ( # %". σ. # + %- %"0 (1) Evaluating the partial derivatives: (2) %- (3) %- %"0
 Evaluating the partial derivatives: (2) %- (3) %- %0") Reading: Santrock, Studley and Hayes ( ); Ricci, Merrit and Hayes ( ). 1) Introduction a) At this point we have separated masses and converted ion currents to stable, amplified analog voltages. Now what?
Reading: Santrock, Studley and Hayes ( ); Ricci, Merrit and Hayes ( ). 1) Introduction a) At this point we have separated masses and converted ion currents to stable, amplified analog voltages. Now what?
Dr. D. M. Akbar Hussain
 Course Objectives: To enable the students to learn some more practical facts about DSP architectures. Objective is that they can apply this knowledge to map any digital filtering algorithm and related
Course Objectives: To enable the students to learn some more practical facts about DSP architectures. Objective is that they can apply this knowledge to map any digital filtering algorithm and related
On the Rules of Low-Power Design
 On the Rules of Low-Power Design (and Why You Should Break Them) Prof. Todd Austin University of Michigan austin@umich.edu A long time ago, in a not so far away place The Rules of Low-Power Design P =
On the Rules of Low-Power Design (and Why You Should Break Them) Prof. Todd Austin University of Michigan austin@umich.edu A long time ago, in a not so far away place The Rules of Low-Power Design P =
Subra Ganesan DSP 1.
 DSP 1 Subra Ganesan Professor, Computer Science and Engineering Associate Director, Product Development and Manufacturing Center, Oakland University, Rochester, MI 48309 Email: ganesan@oakland.edu Topics
DSP 1 Subra Ganesan Professor, Computer Science and Engineering Associate Director, Product Development and Manufacturing Center, Oakland University, Rochester, MI 48309 Email: ganesan@oakland.edu Topics
Dynamic Scheduling I
 basic pipeline started with single, in-order issue, single-cycle operations have extended this basic pipeline with multi-cycle operations multiple issue (superscalar) now: dynamic scheduling (out-of-order
basic pipeline started with single, in-order issue, single-cycle operations have extended this basic pipeline with multi-cycle operations multiple issue (superscalar) now: dynamic scheduling (out-of-order
Data Acquisition & Computer Control
 Chapter 4 Data Acquisition & Computer Control Now that we have some tools to look at random data we need to understand the fundamental methods employed to acquire data and control experiments. The personal
Chapter 4 Data Acquisition & Computer Control Now that we have some tools to look at random data we need to understand the fundamental methods employed to acquire data and control experiments. The personal
Introduction to co-simulation. What is HW-SW co-simulation?
 Introduction to co-simulation CPSC489-501 Hardware-Software Codesign of Embedded Systems Mahapatra-TexasA&M-Fall 00 1 What is HW-SW co-simulation? A basic definition: Manipulating simulated hardware with
Introduction to co-simulation CPSC489-501 Hardware-Software Codesign of Embedded Systems Mahapatra-TexasA&M-Fall 00 1 What is HW-SW co-simulation? A basic definition: Manipulating simulated hardware with
CS 147: Computer Systems Performance Analysis
 CS 147: Computer Systems Performance Analysis Mistakes in Graphical Presentation CS 147: Computer Systems Performance Analysis Mistakes in Graphical Presentation 1 / 45 Overview Excess Information Multiple
CS 147: Computer Systems Performance Analysis Mistakes in Graphical Presentation CS 147: Computer Systems Performance Analysis Mistakes in Graphical Presentation 1 / 45 Overview Excess Information Multiple
1) Fixed point [15 points] a) What are the primary reasons we might use fixed point rather than floating point? [2]
![1) Fixed point [15 points] a) What are the primary reasons we might use fixed point rather than floating point? [2]](/thumbs/96/126801547.jpg "1) Fixed point [15 points] a) What are the primary reasons we might use fixed point rather than floating point? [2]") 473 Fall 2018 Homework 2 Answers Due on Gradescope by 5pm on December 11 th. 165 points. Notice that the last problem is a group assignment (groups of 2 or 3). Digital Signal Processing and other specialized
473 Fall 2018 Homework 2 Answers Due on Gradescope by 5pm on December 11 th. 165 points. Notice that the last problem is a group assignment (groups of 2 or 3). Digital Signal Processing and other specialized
Outline Simulators and such. What defines a simulator? What about emulation?
 Outline Simulators and such Mats Brorsson & Mladen Nikitovic ICT Dept of Electronic, Computer and Software Systems (ECS) What defines a simulator? Why are simulators needed? Classifications Case studies
Outline Simulators and such Mats Brorsson & Mladen Nikitovic ICT Dept of Electronic, Computer and Software Systems (ECS) What defines a simulator? Why are simulators needed? Classifications Case studies
RISC Design: Pipelining
 RISC Design: Pipelining Virendra Singh Associate Professor Computer Architecture and Dependable Systems Lab Department of Electrical Engineering Indian Institute of Technology Bombay http://www.ee.iitb.ac.in/~viren/
RISC Design: Pipelining Virendra Singh Associate Professor Computer Architecture and Dependable Systems Lab Department of Electrical Engineering Indian Institute of Technology Bombay http://www.ee.iitb.ac.in/~viren/
CS 61C: Great Ideas in Computer Architecture Finite State Machines, Functional Units
 CS 61C: Great Ideas in Computer Architecture Finite State Machines, Functional Units Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Machine Interpretation
CS 61C: Great Ideas in Computer Architecture Finite State Machines, Functional Units Instructors: Vladimir Stojanovic and Nicholas Weaver http://inst.eecs.berkeley.edu/~cs61c/sp16 1 Machine Interpretation
Challenges of in-circuit functional timing testing of System-on-a-Chip
 Challenges of in-circuit functional timing testing of System-on-a-Chip David and Gregory Chudnovsky Institute for Mathematics and Advanced Supercomputing Polytechnic Institute of NYU Deep sub-micron devices
Challenges of in-circuit functional timing testing of System-on-a-Chip David and Gregory Chudnovsky Institute for Mathematics and Advanced Supercomputing Polytechnic Institute of NYU Deep sub-micron devices
Lesson 7. Digital Signal Processors
 Lesson 7 Digital Signal Processors Instructional Objectives After going through this lesson the student would learn o Architecture of a Real time Signal Processing Platform o Different Errors introduced
Lesson 7 Digital Signal Processors Instructional Objectives After going through this lesson the student would learn o Architecture of a Real time Signal Processing Platform o Different Errors introduced
Plan 9 in Technicolor
 Plan 9 in Technicolor Russ Cox Harvard College Bell Labs, Lucent Technologies rsc@plan9.bell-labs.com August 23, 1999 Bitblt 1 Invented in 1975 at Xerox PARC. Used on the Blit and in released Plan 9. bitblt(dst,
Plan 9 in Technicolor Russ Cox Harvard College Bell Labs, Lucent Technologies rsc@plan9.bell-labs.com August 23, 1999 Bitblt 1 Invented in 1975 at Xerox PARC. Used on the Blit and in released Plan 9. bitblt(dst,
EE382V-ICS: System-on-a-Chip (SoC) Design
 Design") EE38V-CS: System-on-a-Chip (SoC) Design Hardware Synthesis and Architectures Source: D. Gajski, S. Abdi, A. Gerstlauer, G. Schirner, Embedded System Design: Modeling, Synthesis, Verification, Chapter 6:
EE38V-CS: System-on-a-Chip (SoC) Design Hardware Synthesis and Architectures Source: D. Gajski, S. Abdi, A. Gerstlauer, G. Schirner, Embedded System Design: Modeling, Synthesis, Verification, Chapter 6:
Arithmetic Structures for Inner-Product and Other Computations Based on a Latency-Free Bit-Serial Multiplier Design
 Arithmetic Structures for Inner-Product and Other Computations Based on a Latency-Free Bit-Serial Multiplier Design Steve Haynal and Behrooz Parhami Department of Electrical and Computer Engineering University
Arithmetic Structures for Inner-Product and Other Computations Based on a Latency-Free Bit-Serial Multiplier Design Steve Haynal and Behrooz Parhami Department of Electrical and Computer Engineering University
Trace Based Switching For A Tightly Coupled Heterogeneous Core
 Trace Based Switching For A Tightly Coupled Heterogeneous Core Shru% Padmanabha, Andrew Lukefahr, Reetuparna Das, Sco@ Mahlke Micro- 46 December 2013 University of Michigan Electrical Engineering and Computer
Trace Based Switching For A Tightly Coupled Heterogeneous Core Shru% Padmanabha, Andrew Lukefahr, Reetuparna Das, Sco@ Mahlke Micro- 46 December 2013 University of Michigan Electrical Engineering and Computer
Design Challenges in Multi-GHz Microprocessors
 Design Challenges in Multi-GHz Microprocessors Bill Herrick Director, Alpha Microprocessor Development www.compaq.com Introduction Moore s Law ( Law (the trend that the demand for IC functions and the
Design Challenges in Multi-GHz Microprocessors Bill Herrick Director, Alpha Microprocessor Development www.compaq.com Introduction Moore s Law ( Law (the trend that the demand for IC functions and the
What is a Simulation? Simulation & Modeling. Why Do Simulations? Emulators versus Simulators. Why Do Simulations? Why Do Simulations?
 What is a Simulation? Simulation & Modeling Introduction and Motivation A system that represents or emulates the behavior of another system over time; a computer simulation is one where the system doing
What is a Simulation? Simulation & Modeling Introduction and Motivation A system that represents or emulates the behavior of another system over time; a computer simulation is one where the system doing
Fall 2015 COMP Operating Systems. Lab #7
 Fall 2015 COMP 3511 Operating Systems Lab #7 Outline Review and examples on virtual memory Motivation of Virtual Memory Demand Paging Page Replacement Q. 1 What is required to support dynamic memory allocation
Fall 2015 COMP 3511 Operating Systems Lab #7 Outline Review and examples on virtual memory Motivation of Virtual Memory Demand Paging Page Replacement Q. 1 What is required to support dynamic memory allocation
REVOLUTIONIZING THE COMPUTING LANDSCAPE AND BEYOND.
 December 3-6, 2018 Santa Clara Convention Center CA, USA REVOLUTIONIZING THE COMPUTING LANDSCAPE AND BEYOND. https://tmt.knect365.com/risc-v-summit @risc_v ACCELERATING INFERENCING ON THE EDGE WITH RISC-V
December 3-6, 2018 Santa Clara Convention Center CA, USA REVOLUTIONIZING THE COMPUTING LANDSCAPE AND BEYOND. https://tmt.knect365.com/risc-v-summit @risc_v ACCELERATING INFERENCING ON THE EDGE WITH RISC-V
Unit-6 PROGRAMMABLE INTERRUPT CONTROLLERS 8259A-PROGRAMMABLE INTERRUPT CONTROLLER (PIC) INTRODUCTION
 INTRODUCTION") M i c r o p r o c e s s o r s a n d M i c r o c o n t r o l l e r s P a g e 1 PROGRAMMABLE INTERRUPT CONTROLLERS 8259A-PROGRAMMABLE INTERRUPT CONTROLLER (PIC) INTRODUCTION Microcomputer system design requires
M i c r o p r o c e s s o r s a n d M i c r o c o n t r o l l e r s P a g e 1 PROGRAMMABLE INTERRUPT CONTROLLERS 8259A-PROGRAMMABLE INTERRUPT CONTROLLER (PIC) INTRODUCTION Microcomputer system design requires
Author: Yih-Yih Lin. Correspondence: Yih-Yih Lin Hewlett-Packard Company MR Forest Street Marlboro, MA USA
 4 th European LS-DYNA Users Conference MPP / Linux Cluster / Hardware I A Correlation Study between MPP LS-DYNA Performance and Various Interconnection Networks a Quantitative Approach for Determining
4 th European LS-DYNA Users Conference MPP / Linux Cluster / Hardware I A Correlation Study between MPP LS-DYNA Performance and Various Interconnection Networks a Quantitative Approach for Determining
Vector Arithmetic Logic Unit Amit Kumar Dutta JIS College of Engineering, Kalyani, WB, India
 Vol. 2 Issue 2, December -23, pp: (75-8), Available online at: www.erpublications.com Vector Arithmetic Logic Unit Amit Kumar Dutta JIS College of Engineering, Kalyani, WB, India Abstract: Real time operation
Vol. 2 Issue 2, December -23, pp: (75-8), Available online at: www.erpublications.com Vector Arithmetic Logic Unit Amit Kumar Dutta JIS College of Engineering, Kalyani, WB, India Abstract: Real time operation
ΕΠΛ 605: Προχωρημένη Αρχιτεκτονική
 ΕΠΛ 605: Προχωρημένη Αρχιτεκτονική Υπολογιστών Presentation of UniServer Horizon 2020 European project findings: X-Gene server chips, voltage-noise characterization, high-bandwidth voltage measurements,
ΕΠΛ 605: Προχωρημένη Αρχιτεκτονική Υπολογιστών Presentation of UniServer Horizon 2020 European project findings: X-Gene server chips, voltage-noise characterization, high-bandwidth voltage measurements,
AN FPGA IMPLEMENTATION OF ALAMOUTI S TRANSMIT DIVERSITY TECHNIQUE
 AN FPGA IMPLEMENTATION OF ALAMOUTI S TRANSMIT DIVERSITY TECHNIQUE Chris Dick Xilinx, Inc. 2100 Logic Dr. San Jose, CA 95124 Patrick Murphy, J. Patrick Frantz Rice University - ECE Dept. 6100 Main St. -
AN FPGA IMPLEMENTATION OF ALAMOUTI S TRANSMIT DIVERSITY TECHNIQUE Chris Dick Xilinx, Inc. 2100 Logic Dr. San Jose, CA 95124 Patrick Murphy, J. Patrick Frantz Rice University - ECE Dept. 6100 Main St. -
Lec 24: Parallel Processors. Announcements
 Lec 24: Parallel Processors Kavita ala CS 3410, Fall 2008 Computer Science Cornell University P 3 out Hack n Seek nnouncements The goal is to have fun with it Recitations today will talk about it Pizza
Lec 24: Parallel Processors Kavita ala CS 3410, Fall 2008 Computer Science Cornell University P 3 out Hack n Seek nnouncements The goal is to have fun with it Recitations today will talk about it Pizza
ECOM 4311 Digital System Design using VHDL. Chapter 9 Sequential Circuit Design: Practice
 ECOM 4311 Digital System Design using VHDL Chapter 9 Sequential Circuit Design: Practice Outline 1. Poor design practice and remedy 2. More counters 3. Register as fast temporary storage 4. Pipelined circuit
ECOM 4311 Digital System Design using VHDL Chapter 9 Sequential Circuit Design: Practice Outline 1. Poor design practice and remedy 2. More counters 3. Register as fast temporary storage 4. Pipelined circuit
Introduction. Reading: Chapter 1. Courtesy of Dr. Dansereau, Dr. Brown, Dr. Vranesic, Dr. Harris, and Dr. Choi.
 Introduction Reading: Chapter 1 Courtesy of Dr. Dansereau, Dr. Brown, Dr. Vranesic, Dr. Harris, and Dr. Choi http://csce.uark.edu +1 (479) 575-6043 yrpeng@uark.edu Why study logic design? Obvious reasons
Introduction Reading: Chapter 1 Courtesy of Dr. Dansereau, Dr. Brown, Dr. Vranesic, Dr. Harris, and Dr. Choi http://csce.uark.edu +1 (479) 575-6043 yrpeng@uark.edu Why study logic design? Obvious reasons
How a processor can permute n bits in O(1) cycles
 cycles") How a processor can permute n bits in O(1) cycles Ruby Lee, Zhijie Shi, Xiao Yang Princeton Architecture Lab for Multimedia and Security (PALMS) Department of Electrical Engineering Princeton University
How a processor can permute n bits in O(1) cycles Ruby Lee, Zhijie Shi, Xiao Yang Princeton Architecture Lab for Multimedia and Security (PALMS) Department of Electrical Engineering Princeton University
Product Information Using the SENT Communications Output Protocol with A1341 and A1343 Devices
 Product Information Using the SENT Communications Output Protocol with A1341 and A1343 Devices By Nevenka Kozomora Allegro MicroSystems supports the Single-Edge Nibble Transmission (SENT) protocol in certain
Product Information Using the SENT Communications Output Protocol with A1341 and A1343 Devices By Nevenka Kozomora Allegro MicroSystems supports the Single-Edge Nibble Transmission (SENT) protocol in certain
LECTURE 8. Pipelining: Datapath and Control
 LECTURE 8 Pipelining: Datapath and Control PIPELINED DATAPATH As with the single-cycle and multi-cycle implementations, we will start by looking at the datapath for pipelining. We already know that pipelining
LECTURE 8 Pipelining: Datapath and Control PIPELINED DATAPATH As with the single-cycle and multi-cycle implementations, we will start by looking at the datapath for pipelining. We already know that pipelining
Video Enhancement Algorithms on System on Chip
 International Journal of Scientific and Research Publications, Volume 2, Issue 4, April 2012 1 Video Enhancement Algorithms on System on Chip Dr.Ch. Ravikumar, Dr. S.K. Srivatsa Abstract- This paper presents
International Journal of Scientific and Research Publications, Volume 2, Issue 4, April 2012 1 Video Enhancement Algorithms on System on Chip Dr.Ch. Ravikumar, Dr. S.K. Srivatsa Abstract- This paper presents