Monte Carlo Tree Search. Simon M. Lucas
|
|
|
- Amber Henry
- 6 years ago
- Views:
Transcription

1 Monte Carlo Tree Search Simon M. Lucas
2 Outline MCTS: The Excitement! A tutorial: how it works Important heuristics: RAVE / AMAF Applications to video games and real-time control
3 The Excitement Game playing before MCTS MCTS and GO MCTS and General Game Playing


4 Conventional Game Tree Search Minimax with alpha-beta pruning, transposition tables Works well when: A good heuristic value function is known The branching factor is modest E.g. Chess, Deep Blue, Rybka etc.

5 Go Much tougher for computers High branching factor No good heuristic value function Although progress has been steady, it will take many decades of research and development before world-championship calibre go programs exist. Jonathan Schaeffer, 2001
6 Monte Carlo Tree Search (MCTS) Revolutionised the world of computer go Best GGP players (2008, 2009) use MCTS More CPU cycles leads to smarter play Typically lin / log: each doubling of CPU time adds a constant to playing strength Uses statistics of deep look-ahead from randomised roll-outs Anytime algorithm
7 Fuego versus GnuGo (from Fuego paper, IEEE T-CIAIG vol2 # 4)
8 General Game Playing (GGP) and Artificial General Intelligence (AGI) Original goal of AI was to develop general purpose machine intelligence Being good at a specific game is not a good test of this it s narrow AI But being able to play any game seems like a good test of AGI Hence general game playing (GGP)
9 GGP: How it works Games specified in predicate logic Two phases: GGP agents are given time to teach themselves how to play the game Then play commences on a time-limited basis Wonderful stuff! Great challenge for machine learning, But interesting to see which methods work best... Current best players all use MCTS
10 MCTS Tutorial How it works: MCTS general concepts Algorithm UCT formula Alternatives to UCT RAVE / AMAF Heuristics
11 MCTS Builds and searches an asymmetric game tree to make each move Phases are: Tree search: select node to expand using tree policy Perform random roll-out to end of game when true value is known Back the value up the tree
12 Sample MCTS Tree (fig from CadiaPlayer, Bjornsson and Finsson, IEEE T-CIAIG)
13 MCTS Algorithm for Action Selection repeat N times { // N might be between 100 and 1,000,000 // set up data structure to record line of play visited = new List<Node>() // select node to expand node = root visited.add(node) while (node is not a leaf) { node = select(node, node.children) // e.g. UCT selection visited.add(node) } // add a new child to the tree newchild = expand(node) visited.add(newchild) value = rollout(newchild) for (node : visited) // update the statistics of tree nodes traversed node.updatestats(value); } } return action that leads from root node to most valued child
14 Each iteration starts at the root Follows tree policy to reach a leaf node Then perform a random roll-out from there Node N is then added to tree Value of T backpropagated up tree MCTS Operation (fig from CadiaPlayer, Bjornsson and Finsson, IEEE T-CIAIG)
15 Upper Confidence Bounds on Trees (UCT) Node Selection Policy From Kocsis and Szepesvari (2006) Converges to optimal policy given infinite number of roll-outs Often not used in practice!
16 Tree Construction Example See Olivier Teytaud s slides from AIGamesNetwork.org summer 2010 MCTS workshop
17 AMAF / RAVE Heuristic Strictly speaking: each iteration should only update the value of a single child of the root node The child of the root node is the first move to be played AMAF (All Moves as First Move) is a type of RAVE heuristic (Rapid Action Value Estimate) the terms are often synonymous
18 How AMAF works Player A is player to move During an iteration (tree search + rollout) update the values in the AMAF table of all moves made by player A Add an AMAF term to the node selection policy Can also apply this to moves of opponent player?
19 Should AMAF work? Yes: a move might be good irrespective of when it is player (e.g. playing in the corner in Othello is ALWAYS a good move) No: the value of a move can depend very much on when it is player E.g. playing next to a corner in Othelo is usually bad, but might sometimes be very good Fact: works very well in some games (Go, Hex) Challenge: how to adapt similar principles for other games (Pac-Man)?
20 Improving MCTS Default roll-out policy is to make uniform random moves Can potentially improve on this by biasing move selections: Toward moves that players are more likely to make Can either program the heuristic a knowledgebased approach Or learn it (Temporal Difference Learning) Some promising work already done on this
21 MCTS for Video Games and Real-Time Control Requirements: Need a fast and accurate forward model i.e. taking action a in state s leads to state s (or a known probability distribution over a set of states) If no such model exists, then could maybe learn it? How accurate does the model need to be? For games, such a model always exists But may need to simplify it


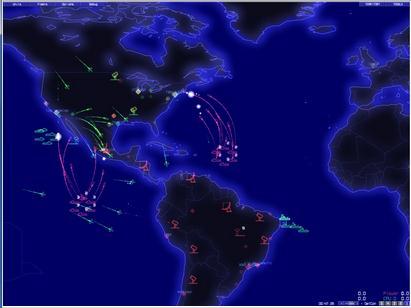
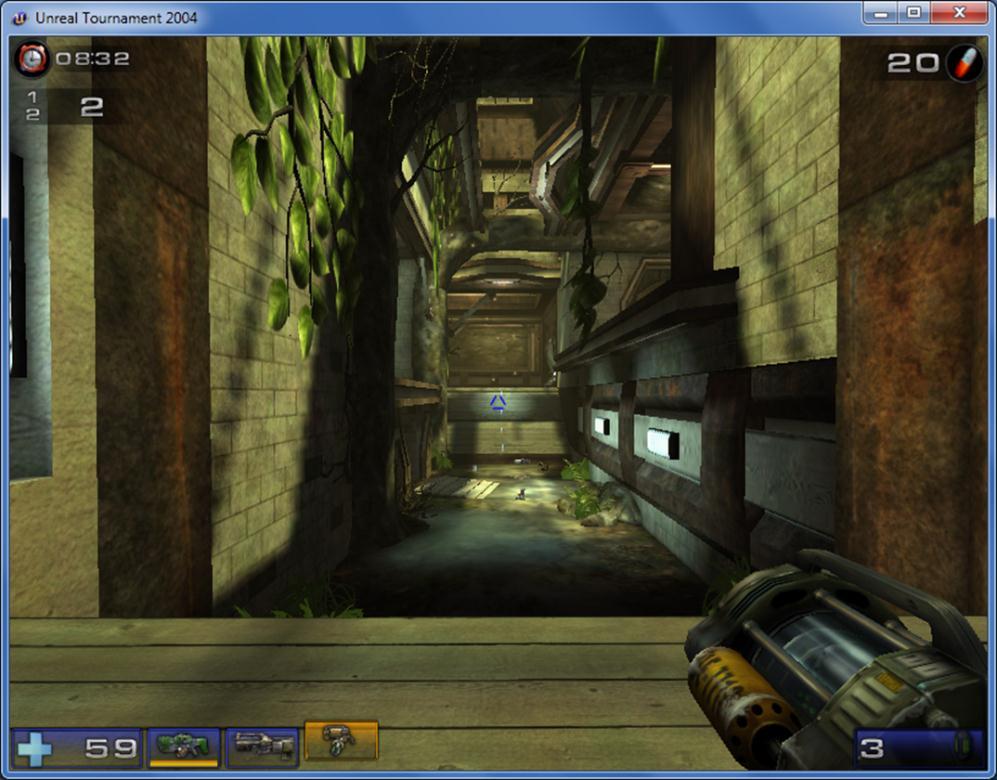
22 Sample Games
23 MCTS Real-Time Approaches State space abstraction: Quantise state space mix of MCTS and Dynamic Programming search graph rather than tree Temporal Abstraction Don t need to make different actions 60 times per second! Instead, current action is usually the same (or predictable from) the previous one Action abstraction Consider higher-level action space
24 Initial Results on Video Games Tron (Google AI challenge) MCTS worked ok Ms Pac-Man Works brilliantly when given good ghost models Still works better than other techniques we ve tried when the ghost models are unknown
25 MCTS and Learning Some work already on this (Silver and Sutton, ICML 2008) Important step towards AGI (Artificial General Intelligence) MCTS that never learns anything is clearly missing some tricks Can be integrated very neatly with TD Learning
26 Multi-objective MCTS Currently the value of a node is expressed as a scalar quantity Can MCTS be improved by making this multidimensional E.g. for a line of play, balance effectiveness with variability / fun
27 Some Remarks MCTS: you have to get your hands dirty! The theory is not there yet (personal opinion) To work, roll-outs must be informative i.e. they must return information How NOT to use MCTS A planning domain where a long string of random actions is unlikely to reach goal Would need to bias roll-outs in some way to overcome this
28 Some More Remarks MCTS: a crazy idea that works surprisingly well! How well does it work? If there is a more applicable alternative (e.g. standard game tree search on a fully enumerated tree), MCTS may be terrible by comparison Best for tough problems for which other methods don t work
CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH. Santiago Ontañón
 CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH Santiago Ontañón so367@drexel.edu Recall: Adversarial Search Idea: When there is only one agent in the world, we can solve problems using DFS, BFS, ID,
CS 380: ARTIFICIAL INTELLIGENCE MONTE CARLO SEARCH Santiago Ontañón so367@drexel.edu Recall: Adversarial Search Idea: When there is only one agent in the world, we can solve problems using DFS, BFS, ID,
A Bandit Approach for Tree Search
 A An Example in Computer-Go Department of Statistics, University of Michigan March 27th, 2008 A 1 Bandit Problem K-Armed Bandit UCB Algorithms for K-Armed Bandit Problem 2 Classical Tree Search UCT Algorithm
A An Example in Computer-Go Department of Statistics, University of Michigan March 27th, 2008 A 1 Bandit Problem K-Armed Bandit UCB Algorithms for K-Armed Bandit Problem 2 Classical Tree Search UCT Algorithm
Adversarial Reasoning: Sampling-Based Search with the UCT algorithm. Joint work with Raghuram Ramanujan and Ashish Sabharwal
 Adversarial Reasoning: Sampling-Based Search with the UCT algorithm Joint work with Raghuram Ramanujan and Ashish Sabharwal Upper Confidence bounds for Trees (UCT) n The UCT algorithm (Kocsis and Szepesvari,
Adversarial Reasoning: Sampling-Based Search with the UCT algorithm Joint work with Raghuram Ramanujan and Ashish Sabharwal Upper Confidence bounds for Trees (UCT) n The UCT algorithm (Kocsis and Szepesvari,
Game-playing: DeepBlue and AlphaGo
 Game-playing: DeepBlue and AlphaGo Brief history of gameplaying frontiers 1990s: Othello world champions refuse to play computers 1994: Chinook defeats Checkers world champion 1997: DeepBlue defeats world
Game-playing: DeepBlue and AlphaGo Brief history of gameplaying frontiers 1990s: Othello world champions refuse to play computers 1994: Chinook defeats Checkers world champion 1997: DeepBlue defeats world
Adversarial Search. CS 486/686: Introduction to Artificial Intelligence
 Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 Introduction So far we have only been concerned with a single agent Today, we introduce an adversary! 2 Outline Games Minimax search
Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 Introduction So far we have only been concerned with a single agent Today, we introduce an adversary! 2 Outline Games Minimax search
Monte Carlo Tree Search and AlphaGo. Suraj Nair, Peter Kundzicz, Kevin An, Vansh Kumar
 Monte Carlo Tree Search and AlphaGo Suraj Nair, Peter Kundzicz, Kevin An, Vansh Kumar Zero-Sum Games and AI A player s utility gain or loss is exactly balanced by the combined gain or loss of opponents:
Monte Carlo Tree Search and AlphaGo Suraj Nair, Peter Kundzicz, Kevin An, Vansh Kumar Zero-Sum Games and AI A player s utility gain or loss is exactly balanced by the combined gain or loss of opponents:
CS 387: GAME AI BOARD GAMES
 CS 387: GAME AI BOARD GAMES 5/28/2015 Instructor: Santiago Ontañón santi@cs.drexel.edu Class website: https://www.cs.drexel.edu/~santi/teaching/2015/cs387/intro.html Reminders Check BBVista site for the
CS 387: GAME AI BOARD GAMES 5/28/2015 Instructor: Santiago Ontañón santi@cs.drexel.edu Class website: https://www.cs.drexel.edu/~santi/teaching/2015/cs387/intro.html Reminders Check BBVista site for the
Adversarial Search. CS 486/686: Introduction to Artificial Intelligence
 Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 AccessAbility Services Volunteer Notetaker Required Interested? Complete an online application using your WATIAM: https://york.accessiblelearning.com/uwaterloo/
Adversarial Search CS 486/686: Introduction to Artificial Intelligence 1 AccessAbility Services Volunteer Notetaker Required Interested? Complete an online application using your WATIAM: https://york.accessiblelearning.com/uwaterloo/
Comparison of Monte Carlo Tree Search Methods in the Imperfect Information Card Game Cribbage
 Comparison of Monte Carlo Tree Search Methods in the Imperfect Information Card Game Cribbage Richard Kelly and David Churchill Computer Science Faculty of Science Memorial University {richard.kelly, dchurchill}@mun.ca
Comparison of Monte Carlo Tree Search Methods in the Imperfect Information Card Game Cribbage Richard Kelly and David Churchill Computer Science Faculty of Science Memorial University {richard.kelly, dchurchill}@mun.ca
Computer Go: from the Beginnings to AlphaGo. Martin Müller, University of Alberta
 Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk Game of Go Short history - Computer Go from the beginnings to AlphaGo The science behind AlphaGo
Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk Game of Go Short history - Computer Go from the beginnings to AlphaGo The science behind AlphaGo
More on games (Ch )
") More on games (Ch. 5.4-5.6) Alpha-beta pruning Previously on CSci 4511... We talked about how to modify the minimax algorithm to prune only bad searches (i.e. alpha-beta pruning) This rule of checking
More on games (Ch. 5.4-5.6) Alpha-beta pruning Previously on CSci 4511... We talked about how to modify the minimax algorithm to prune only bad searches (i.e. alpha-beta pruning) This rule of checking
Set 4: Game-Playing. ICS 271 Fall 2017 Kalev Kask
 Set 4: Game-Playing ICS 271 Fall 2017 Kalev Kask Overview Computer programs that play 2-player games game-playing as search with the complication of an opponent General principles of game-playing and search
Set 4: Game-Playing ICS 271 Fall 2017 Kalev Kask Overview Computer programs that play 2-player games game-playing as search with the complication of an opponent General principles of game-playing and search
Playout Search for Monte-Carlo Tree Search in Multi-Player Games
 Playout Search for Monte-Carlo Tree Search in Multi-Player Games J. (Pim) A.M. Nijssen and Mark H.M. Winands Games and AI Group, Department of Knowledge Engineering, Faculty of Humanities and Sciences,
Playout Search for Monte-Carlo Tree Search in Multi-Player Games J. (Pim) A.M. Nijssen and Mark H.M. Winands Games and AI Group, Department of Knowledge Engineering, Faculty of Humanities and Sciences,
CSC321 Lecture 23: Go
 CSC321 Lecture 23: Go Roger Grosse Roger Grosse CSC321 Lecture 23: Go 1 / 21 Final Exam Friday, April 20, 9am-noon Last names A Y: Clara Benson Building (BN) 2N Last names Z: Clara Benson Building (BN)
CSC321 Lecture 23: Go Roger Grosse Roger Grosse CSC321 Lecture 23: Go 1 / 21 Final Exam Friday, April 20, 9am-noon Last names A Y: Clara Benson Building (BN) 2N Last names Z: Clara Benson Building (BN)
Unit-III Chap-II Adversarial Search. Created by: Ashish Shah 1
 Unit-III Chap-II Adversarial Search Created by: Ashish Shah 1 Alpha beta Pruning In case of standard ALPHA BETA PRUNING minimax tree, it returns the same move as minimax would, but prunes away branches
Unit-III Chap-II Adversarial Search Created by: Ashish Shah 1 Alpha beta Pruning In case of standard ALPHA BETA PRUNING minimax tree, it returns the same move as minimax would, but prunes away branches
Adversarial Search (Game Playing)
") Artificial Intelligence Adversarial Search (Game Playing) Chapter 5 Adapted from materials by Tim Finin, Marie desjardins, and Charles R. Dyer Outline Game playing State of the art and resources Framework
Artificial Intelligence Adversarial Search (Game Playing) Chapter 5 Adapted from materials by Tim Finin, Marie desjardins, and Charles R. Dyer Outline Game playing State of the art and resources Framework
ARTIFICIAL INTELLIGENCE (CS 370D)
") Princess Nora University Faculty of Computer & Information Systems ARTIFICIAL INTELLIGENCE (CS 370D) (CHAPTER-5) ADVERSARIAL SEARCH ADVERSARIAL SEARCH Optimal decisions Min algorithm α-β pruning Imperfect,
Princess Nora University Faculty of Computer & Information Systems ARTIFICIAL INTELLIGENCE (CS 370D) (CHAPTER-5) ADVERSARIAL SEARCH ADVERSARIAL SEARCH Optimal decisions Min algorithm α-β pruning Imperfect,
A Study of UCT and its Enhancements in an Artificial Game
 A Study of UCT and its Enhancements in an Artificial Game David Tom and Martin Müller Department of Computing Science, University of Alberta, Edmonton, Canada, T6G 2E8 {dtom, mmueller}@cs.ualberta.ca Abstract.
A Study of UCT and its Enhancements in an Artificial Game David Tom and Martin Müller Department of Computing Science, University of Alberta, Edmonton, Canada, T6G 2E8 {dtom, mmueller}@cs.ualberta.ca Abstract.
Foundations of Artificial Intelligence
 Foundations of Artificial Intelligence 42. Board Games: Alpha-Beta Search Malte Helmert University of Basel May 16, 2018 Board Games: Overview chapter overview: 40. Introduction and State of the Art 41.
Foundations of Artificial Intelligence 42. Board Games: Alpha-Beta Search Malte Helmert University of Basel May 16, 2018 Board Games: Overview chapter overview: 40. Introduction and State of the Art 41.
Artificial Intelligence. Minimax and alpha-beta pruning
 Artificial Intelligence Minimax and alpha-beta pruning In which we examine the problems that arise when we try to plan ahead to get the best result in a world that includes a hostile agent (other agent
Artificial Intelligence Minimax and alpha-beta pruning In which we examine the problems that arise when we try to plan ahead to get the best result in a world that includes a hostile agent (other agent
CS 387/680: GAME AI BOARD GAMES
 CS 387/680: GAME AI BOARD GAMES 6/2/2014 Instructor: Santiago Ontañón santi@cs.drexel.edu TA: Alberto Uriarte office hours: Tuesday 4-6pm, Cyber Learning Center Class website: https://www.cs.drexel.edu/~santi/teaching/2014/cs387-680/intro.html
CS 387/680: GAME AI BOARD GAMES 6/2/2014 Instructor: Santiago Ontañón santi@cs.drexel.edu TA: Alberto Uriarte office hours: Tuesday 4-6pm, Cyber Learning Center Class website: https://www.cs.drexel.edu/~santi/teaching/2014/cs387-680/intro.html
Lecture 14. Questions? Friday, February 10 CS 430 Artificial Intelligence - Lecture 14 1
 Lecture 14 Questions? Friday, February 10 CS 430 Artificial Intelligence - Lecture 14 1 Outline Chapter 5 - Adversarial Search Alpha-Beta Pruning Imperfect Real-Time Decisions Stochastic Games Friday,
Lecture 14 Questions? Friday, February 10 CS 430 Artificial Intelligence - Lecture 14 1 Outline Chapter 5 - Adversarial Search Alpha-Beta Pruning Imperfect Real-Time Decisions Stochastic Games Friday,
Monte Carlo Tree Search
 Monte Carlo Tree Search 1 By the end, you will know Why we use Monte Carlo Search Trees The pros and cons of MCTS How it is applied to Super Mario Brothers and Alpha Go 2 Outline I. Pre-MCTS Algorithms
Monte Carlo Tree Search 1 By the end, you will know Why we use Monte Carlo Search Trees The pros and cons of MCTS How it is applied to Super Mario Brothers and Alpha Go 2 Outline I. Pre-MCTS Algorithms
More on games (Ch )
") More on games (Ch. 5.4-5.6) Announcements Midterm next Tuesday: covers weeks 1-4 (Chapters 1-4) Take the full class period Open book/notes (can use ebook) ^^ No programing/code, internet searches or friends
More on games (Ch. 5.4-5.6) Announcements Midterm next Tuesday: covers weeks 1-4 (Chapters 1-4) Take the full class period Open book/notes (can use ebook) ^^ No programing/code, internet searches or friends
MONTE-CARLO TWIXT. Janik Steinhauer. Master Thesis 10-08
 MONTE-CARLO TWIXT Janik Steinhauer Master Thesis 10-08 Thesis submitted in partial fulfilment of the requirements for the degree of Master of Science of Artificial Intelligence at the Faculty of Humanities
MONTE-CARLO TWIXT Janik Steinhauer Master Thesis 10-08 Thesis submitted in partial fulfilment of the requirements for the degree of Master of Science of Artificial Intelligence at the Faculty of Humanities
Artificial Intelligence
 Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory AI Challenge One 140 Challenge 1 grades 120 100 80 60 AI Challenge One Transform to graph Explore the
Artificial Intelligence Jeff Clune Assistant Professor Evolving Artificial Intelligence Laboratory AI Challenge One 140 Challenge 1 grades 120 100 80 60 AI Challenge One Transform to graph Explore the
Monte-Carlo Tree Search for the Simultaneous Move Game Tron
 Monte-Carlo Tree Search for the Simultaneous Move Game Tron N.G.P. Den Teuling June 27, 2011 Abstract Monte-Carlo Tree Search (MCTS) has been successfully applied to many games, particularly in Go. In
Monte-Carlo Tree Search for the Simultaneous Move Game Tron N.G.P. Den Teuling June 27, 2011 Abstract Monte-Carlo Tree Search (MCTS) has been successfully applied to many games, particularly in Go. In
CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions
 CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions Slides by Svetlana Lazebnik, 9/2016 Modified by Mark Hasegawa Johnson, 9/2017 Types of game environments Perfect
CS440/ECE448 Lecture 11: Stochastic Games, Stochastic Search, and Learned Evaluation Functions Slides by Svetlana Lazebnik, 9/2016 Modified by Mark Hasegawa Johnson, 9/2017 Types of game environments Perfect
CS 440 / ECE 448 Introduction to Artificial Intelligence Spring 2010 Lecture #5
 CS 440 / ECE 448 Introduction to Artificial Intelligence Spring 2010 Lecture #5 Instructor: Eyal Amir Grad TAs: Wen Pu, Yonatan Bisk Undergrad TAs: Sam Johnson, Nikhil Johri Topics Game playing Game trees
CS 440 / ECE 448 Introduction to Artificial Intelligence Spring 2010 Lecture #5 Instructor: Eyal Amir Grad TAs: Wen Pu, Yonatan Bisk Undergrad TAs: Sam Johnson, Nikhil Johri Topics Game playing Game trees
Algorithms for Data Structures: Search for Games. Phillip Smith 27/11/13
 Algorithms for Data Structures: Search for Games Phillip Smith 27/11/13 Search for Games Following this lecture you should be able to: Understand the search process in games How an AI decides on the best
Algorithms for Data Structures: Search for Games Phillip Smith 27/11/13 Search for Games Following this lecture you should be able to: Understand the search process in games How an AI decides on the best
TTIC 31230, Fundamentals of Deep Learning David McAllester, April AlphaZero
 TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 AlphaZero 1 AlphaGo Fan (October 2015) AlphaGo Defeats Fan Hui, European Go Champion. 2 AlphaGo Lee (March 2016) 3 AlphaGo Zero vs.
TTIC 31230, Fundamentals of Deep Learning David McAllester, April 2017 AlphaZero 1 AlphaGo Fan (October 2015) AlphaGo Defeats Fan Hui, European Go Champion. 2 AlphaGo Lee (March 2016) 3 AlphaGo Zero vs.
Exploration exploitation in Go: UCT for Monte-Carlo Go
 Exploration exploitation in Go: UCT for Monte-Carlo Go Sylvain Gelly(*) and Yizao Wang(*,**) (*)TAO (INRIA), LRI, UMR (CNRS - Univ. Paris-Sud) University of Paris-Sud, Orsay, France sylvain.gelly@lri.fr
Exploration exploitation in Go: UCT for Monte-Carlo Go Sylvain Gelly(*) and Yizao Wang(*,**) (*)TAO (INRIA), LRI, UMR (CNRS - Univ. Paris-Sud) University of Paris-Sud, Orsay, France sylvain.gelly@lri.fr
Learning from Hints: AI for Playing Threes
 Learning from Hints: AI for Playing Threes Hao Sheng (haosheng), Chen Guo (cguo2) December 17, 2016 1 Introduction The highly addictive stochastic puzzle game Threes by Sirvo LLC. is Apple Game of the
Learning from Hints: AI for Playing Threes Hao Sheng (haosheng), Chen Guo (cguo2) December 17, 2016 1 Introduction The highly addictive stochastic puzzle game Threes by Sirvo LLC. is Apple Game of the
Monte-Carlo Tree Search Enhancements for Havannah
 Monte-Carlo Tree Search Enhancements for Havannah Jan A. Stankiewicz, Mark H.M. Winands, and Jos W.H.M. Uiterwijk Department of Knowledge Engineering, Maastricht University j.stankiewicz@student.maastrichtuniversity.nl,
Monte-Carlo Tree Search Enhancements for Havannah Jan A. Stankiewicz, Mark H.M. Winands, and Jos W.H.M. Uiterwijk Department of Knowledge Engineering, Maastricht University j.stankiewicz@student.maastrichtuniversity.nl,
CS 229 Final Project: Using Reinforcement Learning to Play Othello
 CS 229 Final Project: Using Reinforcement Learning to Play Othello Kevin Fry Frank Zheng Xianming Li ID: kfry ID: fzheng ID: xmli 16 December 2016 Abstract We built an AI that learned to play Othello.
CS 229 Final Project: Using Reinforcement Learning to Play Othello Kevin Fry Frank Zheng Xianming Li ID: kfry ID: fzheng ID: xmli 16 December 2016 Abstract We built an AI that learned to play Othello.
Feature Learning Using State Differences
 Feature Learning Using State Differences Mesut Kirci and Jonathan Schaeffer and Nathan Sturtevant Department of Computing Science University of Alberta Edmonton, Alberta, Canada {kirci,nathanst,jonathan}@cs.ualberta.ca
Feature Learning Using State Differences Mesut Kirci and Jonathan Schaeffer and Nathan Sturtevant Department of Computing Science University of Alberta Edmonton, Alberta, Canada {kirci,nathanst,jonathan}@cs.ualberta.ca
Generalized Game Trees
 Generalized Game Trees Richard E. Korf Computer Science Department University of California, Los Angeles Los Angeles, Ca. 90024 Abstract We consider two generalizations of the standard two-player game
Generalized Game Trees Richard E. Korf Computer Science Department University of California, Los Angeles Los Angeles, Ca. 90024 Abstract We consider two generalizations of the standard two-player game
Virtual Global Search: Application to 9x9 Go
 Virtual Global Search: Application to 9x9 Go Tristan Cazenave LIASD Dept. Informatique Université Paris 8, 93526, Saint-Denis, France cazenave@ai.univ-paris8.fr Abstract. Monte-Carlo simulations can be
Virtual Global Search: Application to 9x9 Go Tristan Cazenave LIASD Dept. Informatique Université Paris 8, 93526, Saint-Denis, France cazenave@ai.univ-paris8.fr Abstract. Monte-Carlo simulations can be
46.1 Introduction. Foundations of Artificial Intelligence Introduction MCTS in AlphaGo Neural Networks. 46.
 Foundations of Artificial Intelligence May 30, 2016 46. AlphaGo and Outlook Foundations of Artificial Intelligence 46. AlphaGo and Outlook Thomas Keller Universität Basel May 30, 2016 46.1 Introduction
Foundations of Artificial Intelligence May 30, 2016 46. AlphaGo and Outlook Foundations of Artificial Intelligence 46. AlphaGo and Outlook Thomas Keller Universität Basel May 30, 2016 46.1 Introduction
Foundations of AI. 6. Adversarial Search. Search Strategies for Games, Games with Chance, State of the Art. Wolfram Burgard & Bernhard Nebel
 Foundations of AI 6. Adversarial Search Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard & Bernhard Nebel Contents Game Theory Board Games Minimax Search Alpha-Beta Search
Foundations of AI 6. Adversarial Search Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard & Bernhard Nebel Contents Game Theory Board Games Minimax Search Alpha-Beta Search
CS-E4800 Artificial Intelligence
 CS-E4800 Artificial Intelligence Jussi Rintanen Department of Computer Science Aalto University March 9, 2017 Difficulties in Rational Collective Behavior Individual utility in conflict with collective
CS-E4800 Artificial Intelligence Jussi Rintanen Department of Computer Science Aalto University March 9, 2017 Difficulties in Rational Collective Behavior Individual utility in conflict with collective
CS 4700: Foundations of Artificial Intelligence
 CS 4700: Foundations of Artificial Intelligence selman@cs.cornell.edu Module: Adversarial Search R&N: Chapter 5 1 Outline Adversarial Search Optimal decisions Minimax α-β pruning Case study: Deep Blue
CS 4700: Foundations of Artificial Intelligence selman@cs.cornell.edu Module: Adversarial Search R&N: Chapter 5 1 Outline Adversarial Search Optimal decisions Minimax α-β pruning Case study: Deep Blue
Adversarial Search Aka Games
 Adversarial Search Aka Games Chapter 5 Some material adopted from notes by Charles R. Dyer, U of Wisconsin-Madison Overview Game playing State of the art and resources Framework Game trees Minimax Alpha-beta
Adversarial Search Aka Games Chapter 5 Some material adopted from notes by Charles R. Dyer, U of Wisconsin-Madison Overview Game playing State of the art and resources Framework Game trees Minimax Alpha-beta
43.1 Introduction. Foundations of Artificial Intelligence Introduction Monte-Carlo Methods Monte-Carlo Tree Search. 43.
 May 6, 20 3. : Introduction 3. : Introduction Malte Helmert University of Basel May 6, 20 3. Introduction 3.2 3.3 3. Summary May 6, 20 / 27 May 6, 20 2 / 27 Board Games: Overview 3. : Introduction Introduction
May 6, 20 3. : Introduction 3. : Introduction Malte Helmert University of Basel May 6, 20 3. Introduction 3.2 3.3 3. Summary May 6, 20 / 27 May 6, 20 2 / 27 Board Games: Overview 3. : Introduction Introduction
Generalized Rapid Action Value Estimation
 Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2015) Generalized Rapid Action Value Estimation Tristan Cazenave LAMSADE - Universite Paris-Dauphine Paris,
Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2015) Generalized Rapid Action Value Estimation Tristan Cazenave LAMSADE - Universite Paris-Dauphine Paris,
Recent Progress in Computer Go. Martin Müller University of Alberta Edmonton, Canada
 Recent Progress in Computer Go Martin Müller University of Alberta Edmonton, Canada 40 Years of Computer Go 1960 s: initial ideas 1970 s: first serious program - Reitman & Wilcox 1980 s: first PC programs,
Recent Progress in Computer Go Martin Müller University of Alberta Edmonton, Canada 40 Years of Computer Go 1960 s: initial ideas 1970 s: first serious program - Reitman & Wilcox 1980 s: first PC programs,
CS 771 Artificial Intelligence. Adversarial Search
 CS 771 Artificial Intelligence Adversarial Search Typical assumptions Two agents whose actions alternate Utility values for each agent are the opposite of the other This creates the adversarial situation
CS 771 Artificial Intelligence Adversarial Search Typical assumptions Two agents whose actions alternate Utility values for each agent are the opposite of the other This creates the adversarial situation
Module 3. Problem Solving using Search- (Two agent) Version 2 CSE IIT, Kharagpur
 Version 2 CSE IIT, Kharagpur") Module 3 Problem Solving using Search- (Two agent) 3.1 Instructional Objective The students should understand the formulation of multi-agent search and in detail two-agent search. Students should b familiar
Module 3 Problem Solving using Search- (Two agent) 3.1 Instructional Objective The students should understand the formulation of multi-agent search and in detail two-agent search. Students should b familiar
Artificial Intelligence Search III
 Artificial Intelligence Search III Lecture 5 Content: Search III Quick Review on Lecture 4 Why Study Games? Game Playing as Search Special Characteristics of Game Playing Search Ingredients of 2-Person
Artificial Intelligence Search III Lecture 5 Content: Search III Quick Review on Lecture 4 Why Study Games? Game Playing as Search Special Characteristics of Game Playing Search Ingredients of 2-Person
Programming an Othello AI Michael An (man4), Evan Liang (liange)
, Evan Liang (liange)") Programming an Othello AI Michael An (man4), Evan Liang (liange) 1 Introduction Othello is a two player board game played on an 8 8 grid. Players take turns placing stones with their assigned color (black
Programming an Othello AI Michael An (man4), Evan Liang (liange) 1 Introduction Othello is a two player board game played on an 8 8 grid. Players take turns placing stones with their assigned color (black
Adversary Search. Ref: Chapter 5
 Adversary Search Ref: Chapter 5 1 Games & A.I. Easy to measure success Easy to represent states Small number of operators Comparison against humans is possible. Many games can be modeled very easily, although
Adversary Search Ref: Chapter 5 1 Games & A.I. Easy to measure success Easy to represent states Small number of operators Comparison against humans is possible. Many games can be modeled very easily, although
Lecture 5: Game Playing (Adversarial Search)
") Lecture 5: Game Playing (Adversarial Search) CS 580 (001) - Spring 2018 Amarda Shehu Department of Computer Science George Mason University, Fairfax, VA, USA February 21, 2018 Amarda Shehu (580) 1 1 Outline
Lecture 5: Game Playing (Adversarial Search) CS 580 (001) - Spring 2018 Amarda Shehu Department of Computer Science George Mason University, Fairfax, VA, USA February 21, 2018 Amarda Shehu (580) 1 1 Outline
Application of UCT Search to the Connection Games of Hex, Y, *Star, and Renkula!
 Application of UCT Search to the Connection Games of Hex, Y, *Star, and Renkula! Tapani Raiko and Jaakko Peltonen Helsinki University of Technology, Adaptive Informatics Research Centre, P.O. Box 5400,
Application of UCT Search to the Connection Games of Hex, Y, *Star, and Renkula! Tapani Raiko and Jaakko Peltonen Helsinki University of Technology, Adaptive Informatics Research Centre, P.O. Box 5400,
Implementation of Upper Confidence Bounds for Trees (UCT) on Gomoku
 on Gomoku") Implementation of Upper Confidence Bounds for Trees (UCT) on Gomoku Guanlin Zhou (gz2250), Nan Yu (ny2263), Yanqing Dai (yd2369), Yingtao Zhong (yz3276) 1. Introduction: Reinforcement Learning for Gomoku
Implementation of Upper Confidence Bounds for Trees (UCT) on Gomoku Guanlin Zhou (gz2250), Nan Yu (ny2263), Yanqing Dai (yd2369), Yingtao Zhong (yz3276) 1. Introduction: Reinforcement Learning for Gomoku
Adversarial Search. Human-aware Robotics. 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: Slides for this lecture are here:
 Adversarial Search 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: q Slides for this lecture are here: http://www.public.asu.edu/~yzhan442/teaching/cse471/lectures/adversarial.pdf Slides are largely based
Adversarial Search 2018/01/25 Chapter 5 in R&N 3rd Ø Announcement: q Slides for this lecture are here: http://www.public.asu.edu/~yzhan442/teaching/cse471/lectures/adversarial.pdf Slides are largely based
Creating a Havannah Playing Agent
 Creating a Havannah Playing Agent B. Joosten August 27, 2009 Abstract This paper delves into the complexities of Havannah, which is a 2-person zero-sum perfectinformation board game. After determining
Creating a Havannah Playing Agent B. Joosten August 27, 2009 Abstract This paper delves into the complexities of Havannah, which is a 2-person zero-sum perfectinformation board game. After determining
How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997)
") How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997) Alan Fern School of Electrical Engineering and Computer Science Oregon State University Deep Mind s vs. Lee Sedol (2016) Watson vs. Ken
How AI Won at Go and So What? Garry Kasparov vs. Deep Blue (1997) Alan Fern School of Electrical Engineering and Computer Science Oregon State University Deep Mind s vs. Lee Sedol (2016) Watson vs. Ken
Artificial Intelligence. 4. Game Playing. Prof. Bojana Dalbelo Bašić Assoc. Prof. Jan Šnajder
 Artificial Intelligence 4. Game Playing Prof. Bojana Dalbelo Bašić Assoc. Prof. Jan Šnajder University of Zagreb Faculty of Electrical Engineering and Computing Academic Year 2017/2018 Creative Commons
Artificial Intelligence 4. Game Playing Prof. Bojana Dalbelo Bašić Assoc. Prof. Jan Šnajder University of Zagreb Faculty of Electrical Engineering and Computing Academic Year 2017/2018 Creative Commons
Enhancements for Monte-Carlo Tree Search in Ms Pac-Man
 Enhancements for Monte-Carlo Tree Search in Ms Pac-Man Tom Pepels June 19, 2012 Abstract In this paper enhancements for the Monte-Carlo Tree Search (MCTS) framework are investigated to play Ms Pac-Man.
Enhancements for Monte-Carlo Tree Search in Ms Pac-Man Tom Pepels June 19, 2012 Abstract In this paper enhancements for the Monte-Carlo Tree Search (MCTS) framework are investigated to play Ms Pac-Man.
AIs may use randomness to finally master this ancient game of strategy
 07.GoPlayingAIs.NA.indd 48 6/13/14 1:30 PM ggo-bot, AIs may use randomness to finally master this ancient game of strategy By Jonathan Schaeffer, Martin Müller & Akihiro Kishimoto Photography by Dan Saelinger
07.GoPlayingAIs.NA.indd 48 6/13/14 1:30 PM ggo-bot, AIs may use randomness to finally master this ancient game of strategy By Jonathan Schaeffer, Martin Müller & Akihiro Kishimoto Photography by Dan Saelinger
mywbut.com Two agent games : alpha beta pruning
 Two agent games : alpha beta pruning 1 3.5 Alpha-Beta Pruning ALPHA-BETA pruning is a method that reduces the number of nodes explored in Minimax strategy. It reduces the time required for the search and
Two agent games : alpha beta pruning 1 3.5 Alpha-Beta Pruning ALPHA-BETA pruning is a method that reduces the number of nodes explored in Minimax strategy. It reduces the time required for the search and
Programming Project 1: Pacman (Due )
") Programming Project 1: Pacman (Due 8.2.18) Registration to the exams 521495A: Artificial Intelligence Adversarial Search (Min-Max) Lectured by Abdenour Hadid Adjunct Professor, CMVS, University of Oulu
Programming Project 1: Pacman (Due 8.2.18) Registration to the exams 521495A: Artificial Intelligence Adversarial Search (Min-Max) Lectured by Abdenour Hadid Adjunct Professor, CMVS, University of Oulu
Game Playing AI Class 8 Ch , 5.4.1, 5.5
 Game Playing AI Class Ch. 5.-5., 5.4., 5.5 Bookkeeping HW Due 0/, :59pm Remaining CSP questions? Cynthia Matuszek CMSC 6 Based on slides by Marie desjardin, Francisco Iacobelli Today s Class Clear criteria
Game Playing AI Class Ch. 5.-5., 5.4., 5.5 Bookkeeping HW Due 0/, :59pm Remaining CSP questions? Cynthia Matuszek CMSC 6 Based on slides by Marie desjardin, Francisco Iacobelli Today s Class Clear criteria
Computer Science and Software Engineering University of Wisconsin - Platteville. 4. Game Play. CS 3030 Lecture Notes Yan Shi UW-Platteville
 Computer Science and Software Engineering University of Wisconsin - Platteville 4. Game Play CS 3030 Lecture Notes Yan Shi UW-Platteville Read: Textbook Chapter 6 What kind of games? 2-player games Zero-sum
Computer Science and Software Engineering University of Wisconsin - Platteville 4. Game Play CS 3030 Lecture Notes Yan Shi UW-Platteville Read: Textbook Chapter 6 What kind of games? 2-player games Zero-sum
V. Adamchik Data Structures. Game Trees. Lecture 1. Apr. 05, Plan: 1. Introduction. 2. Game of NIM. 3. Minimax
 Game Trees Lecture 1 Apr. 05, 2005 Plan: 1. Introduction 2. Game of NIM 3. Minimax V. Adamchik 2 ü Introduction The search problems we have studied so far assume that the situation is not going to change.
Game Trees Lecture 1 Apr. 05, 2005 Plan: 1. Introduction 2. Game of NIM 3. Minimax V. Adamchik 2 ü Introduction The search problems we have studied so far assume that the situation is not going to change.
Foundations of AI. 6. Board Games. Search Strategies for Games, Games with Chance, State of the Art
 Foundations of AI 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Andreas Karwath, Bernhard Nebel, and Martin Riedmiller SA-1 Contents Board Games Minimax
Foundations of AI 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Andreas Karwath, Bernhard Nebel, and Martin Riedmiller SA-1 Contents Board Games Minimax
Adversarial Search and Game Playing. Russell and Norvig: Chapter 5
 Adversarial Search and Game Playing Russell and Norvig: Chapter 5 Typical case 2-person game Players alternate moves Zero-sum: one player s loss is the other s gain Perfect information: both players have
Adversarial Search and Game Playing Russell and Norvig: Chapter 5 Typical case 2-person game Players alternate moves Zero-sum: one player s loss is the other s gain Perfect information: both players have
Foundations of Artificial Intelligence
 Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Frank Hutter and Bernhard Nebel Albert-Ludwigs-Universität
Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Frank Hutter and Bernhard Nebel Albert-Ludwigs-Universität
COMP219: COMP219: Artificial Intelligence Artificial Intelligence Dr. Annabel Latham Lecture 12: Game Playing Overview Games and Search
 COMP19: Artificial Intelligence COMP19: Artificial Intelligence Dr. Annabel Latham Room.05 Ashton Building Department of Computer Science University of Liverpool Lecture 1: Game Playing 1 Overview Last
COMP19: Artificial Intelligence COMP19: Artificial Intelligence Dr. Annabel Latham Room.05 Ashton Building Department of Computer Science University of Liverpool Lecture 1: Game Playing 1 Overview Last
UCD : Upper Confidence bound for rooted Directed acyclic graphs
 UCD : Upper Confidence bound for rooted Directed acyclic graphs Abdallah Saffidine a, Tristan Cazenave a, Jean Méhat b a LAMSADE Université Paris-Dauphine Paris, France b LIASD Université Paris 8 Saint-Denis
UCD : Upper Confidence bound for rooted Directed acyclic graphs Abdallah Saffidine a, Tristan Cazenave a, Jean Méhat b a LAMSADE Université Paris-Dauphine Paris, France b LIASD Université Paris 8 Saint-Denis
Enhancements for Monte-Carlo Tree Search in Ms Pac-Man
 Enhancements for Monte-Carlo Tree Search in Ms Pac-Man Tom Pepels Mark H.M. Winands Abstract In this paper enhancements for the Monte-Carlo Tree Search (MCTS) framework are investigated to play Ms Pac-Man.
Enhancements for Monte-Carlo Tree Search in Ms Pac-Man Tom Pepels Mark H.M. Winands Abstract In this paper enhancements for the Monte-Carlo Tree Search (MCTS) framework are investigated to play Ms Pac-Man.
Adversarial Search and Game- Playing C H A P T E R 6 C M P T : S P R I N G H A S S A N K H O S R A V I
 Adversarial Search and Game- Playing C H A P T E R 6 C M P T 3 1 0 : S P R I N G 2 0 1 1 H A S S A N K H O S R A V I Adversarial Search Examine the problems that arise when we try to plan ahead in a world
Adversarial Search and Game- Playing C H A P T E R 6 C M P T 3 1 0 : S P R I N G 2 0 1 1 H A S S A N K H O S R A V I Adversarial Search Examine the problems that arise when we try to plan ahead in a world
CS229 Project: Building an Intelligent Agent to play 9x9 Go
 CS229 Project: Building an Intelligent Agent to play 9x9 Go Shawn Hu Abstract We build an AI to autonomously play the board game of Go at a low amateur level. Our AI uses the UCT variation of Monte Carlo
CS229 Project: Building an Intelligent Agent to play 9x9 Go Shawn Hu Abstract We build an AI to autonomously play the board game of Go at a low amateur level. Our AI uses the UCT variation of Monte Carlo
6. Games. COMP9414/ 9814/ 3411: Artificial Intelligence. Outline. Mechanical Turk. Origins. origins. motivation. minimax search
 COMP9414/9814/3411 16s1 Games 1 COMP9414/ 9814/ 3411: Artificial Intelligence 6. Games Outline origins motivation Russell & Norvig, Chapter 5. minimax search resource limits and heuristic evaluation α-β
COMP9414/9814/3411 16s1 Games 1 COMP9414/ 9814/ 3411: Artificial Intelligence 6. Games Outline origins motivation Russell & Norvig, Chapter 5. minimax search resource limits and heuristic evaluation α-β
Pruning playouts in Monte-Carlo Tree Search for the game of Havannah
 Pruning playouts in Monte-Carlo Tree Search for the game of Havannah Joris Duguépéroux, Ahmad Mazyad, Fabien Teytaud, Julien Dehos To cite this version: Joris Duguépéroux, Ahmad Mazyad, Fabien Teytaud,
Pruning playouts in Monte-Carlo Tree Search for the game of Havannah Joris Duguépéroux, Ahmad Mazyad, Fabien Teytaud, Julien Dehos To cite this version: Joris Duguépéroux, Ahmad Mazyad, Fabien Teytaud,
Contents. Foundations of Artificial Intelligence. Problems. Why Board Games?
 Contents Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Bernhard Nebel, and Martin Riedmiller Albert-Ludwigs-Universität
Contents Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Wolfram Burgard, Bernhard Nebel, and Martin Riedmiller Albert-Ludwigs-Universität
Score Bounded Monte-Carlo Tree Search
 Score Bounded Monte-Carlo Tree Search Tristan Cazenave and Abdallah Saffidine LAMSADE Université Paris-Dauphine Paris, France cazenave@lamsade.dauphine.fr Abdallah.Saffidine@gmail.com Abstract. Monte-Carlo
Score Bounded Monte-Carlo Tree Search Tristan Cazenave and Abdallah Saffidine LAMSADE Université Paris-Dauphine Paris, France cazenave@lamsade.dauphine.fr Abdallah.Saffidine@gmail.com Abstract. Monte-Carlo
CS 331: Artificial Intelligence Adversarial Search II. Outline
 CS 331: Artificial Intelligence Adversarial Search II 1 Outline 1. Evaluation Functions 2. State-of-the-art game playing programs 3. 2 player zero-sum finite stochastic games of perfect information 2 1
CS 331: Artificial Intelligence Adversarial Search II 1 Outline 1. Evaluation Functions 2. State-of-the-art game playing programs 3. 2 player zero-sum finite stochastic games of perfect information 2 1
Computer Game Programming Board Games
 1-466 Computer Game Programg Board Games Maxim Likhachev Robotics Institute Carnegie Mellon University There Are Still Board Games Maxim Likhachev Carnegie Mellon University 2 Classes of Board Games Two
1-466 Computer Game Programg Board Games Maxim Likhachev Robotics Institute Carnegie Mellon University There Are Still Board Games Maxim Likhachev Carnegie Mellon University 2 Classes of Board Games Two
Last update: March 9, Game playing. CMSC 421, Chapter 6. CMSC 421, Chapter 6 1
 Last update: March 9, 2010 Game playing CMSC 421, Chapter 6 CMSC 421, Chapter 6 1 Finite perfect-information zero-sum games Finite: finitely many agents, actions, states Perfect information: every agent
Last update: March 9, 2010 Game playing CMSC 421, Chapter 6 CMSC 421, Chapter 6 1 Finite perfect-information zero-sum games Finite: finitely many agents, actions, states Perfect information: every agent
CS 387: GAME AI BOARD GAMES. 5/24/2016 Instructor: Santiago Ontañón
 CS 387: GAME AI BOARD GAMES 5/24/2016 Instructor: Santiago Ontañón santi@cs.drexel.edu Class website: https://www.cs.drexel.edu/~santi/teaching/2016/cs387/intro.html Reminders Check BBVista site for the
CS 387: GAME AI BOARD GAMES 5/24/2016 Instructor: Santiago Ontañón santi@cs.drexel.edu Class website: https://www.cs.drexel.edu/~santi/teaching/2016/cs387/intro.html Reminders Check BBVista site for the
Search Depth. 8. Search Depth. Investing. Investing in Search. Jonathan Schaeffer
 Search Depth 8. Search Depth Jonathan Schaeffer jonathan@cs.ualberta.ca www.cs.ualberta.ca/~jonathan So far, we have always assumed that all searches are to a fixed depth Nice properties in that the search
Search Depth 8. Search Depth Jonathan Schaeffer jonathan@cs.ualberta.ca www.cs.ualberta.ca/~jonathan So far, we have always assumed that all searches are to a fixed depth Nice properties in that the search
ボードゲームの着手評価関数の機械学習のためのパタ ーン特徴量の選択と進化. Description Supervisor: 池田心, 情報科学研究科, 博士
 JAIST Reposi https://dspace.j Title ボードゲームの着手評価関数の機械学習のためのパタ ーン特徴量の選択と進化 Author(s)Nguyen, Quoc Huy Citation Issue Date 2014-09 Type Thesis or Dissertation Text version ETD URL http://hdl.handle.net/10119/12287
JAIST Reposi https://dspace.j Title ボードゲームの着手評価関数の機械学習のためのパタ ーン特徴量の選択と進化 Author(s)Nguyen, Quoc Huy Citation Issue Date 2014-09 Type Thesis or Dissertation Text version ETD URL http://hdl.handle.net/10119/12287
Adversarial Search. Soleymani. Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5
 Adversarial Search CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2017 Soleymani Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5 Outline Game
Adversarial Search CE417: Introduction to Artificial Intelligence Sharif University of Technology Spring 2017 Soleymani Artificial Intelligence: A Modern Approach, 3 rd Edition, Chapter 5 Outline Game
CMSC 671 Project Report- Google AI Challenge: Planet Wars
 1. Introduction Purpose The purpose of the project is to apply relevant AI techniques learned during the course with a view to develop an intelligent game playing bot for the game of Planet Wars. Planet
1. Introduction Purpose The purpose of the project is to apply relevant AI techniques learned during the course with a view to develop an intelligent game playing bot for the game of Planet Wars. Planet
Midterm Examination. CSCI 561: Artificial Intelligence
 Midterm Examination CSCI 561: Artificial Intelligence October 10, 2002 Instructions: 1. Date: 10/10/2002 from 11:00am 12:20 pm 2. Maximum credits/points for this midterm: 100 points (corresponding to 35%
Midterm Examination CSCI 561: Artificial Intelligence October 10, 2002 Instructions: 1. Date: 10/10/2002 from 11:00am 12:20 pm 2. Maximum credits/points for this midterm: 100 points (corresponding to 35%
Foundations of Artificial Intelligence
 Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Bernhard Nebel Albert-Ludwigs-Universität
Foundations of Artificial Intelligence 6. Board Games Search Strategies for Games, Games with Chance, State of the Art Joschka Boedecker and Wolfram Burgard and Bernhard Nebel Albert-Ludwigs-Universität
Monte Carlo tree search techniques in the game of Kriegspiel
 Monte Carlo tree search techniques in the game of Kriegspiel Paolo Ciancarini and Gian Piero Favini University of Bologna, Italy 22 IJCAI, Pasadena, July 2009 Agenda Kriegspiel as a partial information
Monte Carlo tree search techniques in the game of Kriegspiel Paolo Ciancarini and Gian Piero Favini University of Bologna, Italy 22 IJCAI, Pasadena, July 2009 Agenda Kriegspiel as a partial information
Applications of Artificial Intelligence and Machine Learning in Othello TJHSST Computer Systems Lab
 Applications of Artificial Intelligence and Machine Learning in Othello TJHSST Computer Systems Lab 2009-2010 Jack Chen January 22, 2010 Abstract The purpose of this project is to explore Artificial Intelligence
Applications of Artificial Intelligence and Machine Learning in Othello TJHSST Computer Systems Lab 2009-2010 Jack Chen January 22, 2010 Abstract The purpose of this project is to explore Artificial Intelligence
TRIAL-BASED HEURISTIC TREE SEARCH FOR FINITE HORIZON MDPS. Thomas Keller and Malte Helmert Presented by: Ryan Berryhill
 TRIAL-BASED HEURISTIC TREE SEARCH FOR FINITE HORIZON MDPS Thomas Keller and Malte Helmert Presented by: Ryan Berryhill Outline Motivation Background THTS framework THTS algorithms Results Motivation Advances
TRIAL-BASED HEURISTIC TREE SEARCH FOR FINITE HORIZON MDPS Thomas Keller and Malte Helmert Presented by: Ryan Berryhill Outline Motivation Background THTS framework THTS algorithms Results Motivation Advances
Ar#ficial)Intelligence!!
Intelligence!!") Introduc*on! Ar#ficial)Intelligence!! Roman Barták Department of Theoretical Computer Science and Mathematical Logic So far we assumed a single-agent environment, but what if there are more agents and
Introduc*on! Ar#ficial)Intelligence!! Roman Barták Department of Theoretical Computer Science and Mathematical Logic So far we assumed a single-agent environment, but what if there are more agents and
Theory and Practice of Artificial Intelligence
 Theory and Practice of Artificial Intelligence Games Daniel Polani School of Computer Science University of Hertfordshire March 9, 2017 All rights reserved. Permission is granted to copy and distribute
Theory and Practice of Artificial Intelligence Games Daniel Polani School of Computer Science University of Hertfordshire March 9, 2017 All rights reserved. Permission is granted to copy and distribute
Small and large MCTS playouts applied to Chinese Dark Chess stochastic game
 Small and large MCTS playouts applied to Chinese Dark Chess stochastic game Nicolas Jouandeau 1 and Tristan Cazenave 2 1 LIASD, Université de Paris 8, France n@ai.univ-paris8.fr 2 LAMSADE, Université Paris-Dauphine,
Small and large MCTS playouts applied to Chinese Dark Chess stochastic game Nicolas Jouandeau 1 and Tristan Cazenave 2 1 LIASD, Université de Paris 8, France n@ai.univ-paris8.fr 2 LAMSADE, Université Paris-Dauphine,
CS 188: Artificial Intelligence
 CS 188: Artificial Intelligence Adversarial Search Instructor: Stuart Russell University of California, Berkeley Game Playing State-of-the-Art Checkers: 1950: First computer player. 1959: Samuel s self-taught
CS 188: Artificial Intelligence Adversarial Search Instructor: Stuart Russell University of California, Berkeley Game Playing State-of-the-Art Checkers: 1950: First computer player. 1959: Samuel s self-taught
Monte-Carlo Tree Search and Minimax Hybrids with Heuristic Evaluation Functions
 Monte-Carlo Tree Search and Minimax Hybrids with Heuristic Evaluation Functions Hendrik Baier and Mark H.M. Winands Games and AI Group, Department of Knowledge Engineering Faculty of Humanities and Sciences,
Monte-Carlo Tree Search and Minimax Hybrids with Heuristic Evaluation Functions Hendrik Baier and Mark H.M. Winands Games and AI Group, Department of Knowledge Engineering Faculty of Humanities and Sciences,
Playing Games. Henry Z. Lo. June 23, We consider writing AI to play games with the following properties:
 Playing Games Henry Z. Lo June 23, 2014 1 Games We consider writing AI to play games with the following properties: Two players. Determinism: no chance is involved; game state based purely on decisions
Playing Games Henry Z. Lo June 23, 2014 1 Games We consider writing AI to play games with the following properties: Two players. Determinism: no chance is involved; game state based purely on decisions
Artificial Intelligence Adversarial Search
 Artificial Intelligence Adversarial Search Adversarial Search Adversarial search problems games They occur in multiagent competitive environments There is an opponent we can t control planning again us!
Artificial Intelligence Adversarial Search Adversarial Search Adversarial search problems games They occur in multiagent competitive environments There is an opponent we can t control planning again us!
By David Anderson SZTAKI (Budapest, Hungary) WPI D2009
 WPI D2009") By David Anderson SZTAKI (Budapest, Hungary) WPI D2009 1997, Deep Blue won against Kasparov Average workstation can defeat best Chess players Computer Chess no longer interesting Go is much harder for
By David Anderson SZTAKI (Budapest, Hungary) WPI D2009 1997, Deep Blue won against Kasparov Average workstation can defeat best Chess players Computer Chess no longer interesting Go is much harder for
Game Engineering CS F-24 Board / Strategy Games
 Game Engineering CS420-2014F-24 Board / Strategy Games David Galles Department of Computer Science University of San Francisco 24-0: Overview Example games (board splitting, chess, Othello) /Max trees
Game Engineering CS420-2014F-24 Board / Strategy Games David Galles Department of Computer Science University of San Francisco 24-0: Overview Example games (board splitting, chess, Othello) /Max trees
School of EECS Washington State University. Artificial Intelligence
 School of EECS Washington State University Artificial Intelligence 1 } Classic AI challenge Easy to represent Difficult to solve } Zero-sum games Total final reward to all players is constant } Perfect
School of EECS Washington State University Artificial Intelligence 1 } Classic AI challenge Easy to represent Difficult to solve } Zero-sum games Total final reward to all players is constant } Perfect